مع ظهور الذكاء الاصطناعي التوليدي، يمكن لنماذج الأساس (FMs) الحالية، مثل نماذج اللغات الكبيرة (LLMs) Claude 2 وLlama 2، تنفيذ مجموعة من المهام التوليدية مثل الإجابة على الأسئلة والتلخيص وإنشاء المحتوى على البيانات النصية. ومع ذلك، توجد بيانات العالم الحقيقي في أشكال متعددة، مثل النصوص والصور والفيديو والصوت. خذ مجموعة شرائح PowerPoint، على سبيل المثال. ويمكن أن تحتوي على معلومات في شكل نص، أو مضمنة في الرسوم البيانية والجداول والصور.
في هذا المنشور، نقدم حلاً يستخدم FMs متعدد الوسائط مثل أمازون تيتان التضمين المتعدد الوسائط نموذج و لافا 1.5 وخدمات AWS بما في ذلك أمازون بيدروك و الأمازون SageMaker لأداء مهام توليدية مماثلة على البيانات متعددة الوسائط.
حل نظرة عامة
يوفر الحل تنفيذًا للإجابة على الأسئلة باستخدام المعلومات الموجودة في النص والعناصر المرئية لمجموعة الشرائح. يعتمد التصميم على مفهوم الجيل المعزز للاسترجاع (RAG). تقليديًا، تم ربط RAG بالبيانات النصية التي يمكن معالجتها بواسطة LLMs. في هذا المنشور، نقوم بتوسيع RAG ليشمل الصور أيضًا. يوفر هذا إمكانية بحث قوية لاستخراج المحتوى ذي الصلة بالسياق من العناصر المرئية مثل الجداول والرسوم البيانية بالإضافة إلى النص.
هناك طرق مختلفة لتصميم حل RAG الذي يتضمن الصور. لقد قدمنا نهجًا واحدًا هنا وسنتبعه بنهج بديل في المقالة الثانية من هذه السلسلة المكونة من ثلاثة أجزاء.
يتضمن هذا الحل المكونات التالية:
- نموذج Amazon Titan Multimodal Embeddings - يتم استخدام FM هذا لإنشاء تضمينات للمحتوى الموجود في مجموعة الشرائح المستخدمة في هذا المنشور. كنموذج متعدد الوسائط، يمكن لنموذج Titan هذا معالجة النصوص أو الصور أو مجموعة كمدخلات وإنشاء التضمينات. يُنشئ نموذج Titan Multimodal Embeddings ناقلات (تضمينات) ذات 1,024 بُعدًا ويمكن الوصول إليها عبر Amazon Bedrock.
- مساعد اللغة والرؤية الكبير (LLaVA) – LLaVA هو نموذج متعدد الوسائط مفتوح المصدر للفهم البصري واللغوي ويستخدم لتفسير البيانات الموجودة في الشرائح، بما في ذلك العناصر المرئية مثل الرسوم البيانية والجداول. نحن نستخدم إصدار المعلمة 7 مليار لافا 1.5-7ب في هذا الحل.
- الأمازون SageMaker - يتم نشر نموذج LLaVA على نقطة نهاية SageMaker باستخدام خدمات استضافة SageMaker، ونستخدم نقطة النهاية الناتجة لتشغيل الاستدلالات مقابل نموذج LLaVA. نحن نستخدم أيضًا دفاتر ملاحظات SageMaker لتنسيق هذا الحل وإظهاره بشكل كامل.
- أمازون أوبن سيرش سيرفرليس – OpenSearch Serverless هو تكوين بدون خادم عند الطلب خدمة Amazon OpenSearch. نحن نستخدم OpenSearch Serverless كقاعدة بيانات متجهة لتخزين التضمينات التي تم إنشاؤها بواسطة نموذج Titan Multimodal Embeddings. يعمل الفهرس الذي تم إنشاؤه في مجموعة OpenSearch Serverless بمثابة مخزن متجه لحل RAG الخاص بنا.
- استيعاب Amazon OpenSearch (OSI) - OSI عبارة عن أداة تجميع بيانات مُدارة بالكامل بدون خادم وتقوم بتسليم البيانات إلى نطاقات خدمة OpenSearch ومجموعات OpenSearch Serverless. في هذا المنشور، نستخدم مسار OSI لتوصيل البيانات إلى مخزن المتجهات OpenSearch Serverless.
هندسة الحل
يتكون تصميم الحل من جزأين: الاستيعاب وتفاعل المستخدم. أثناء الاستيعاب، نقوم بمعالجة مجموعة شرائح الإدخال عن طريق تحويل كل شريحة إلى صورة، وإنشاء تضمينات لهذه الصور، ثم ملء مخزن بيانات المتجهات. يتم إكمال هذه الخطوات قبل خطوات تفاعل المستخدم.
في مرحلة تفاعل المستخدم، يتم تحويل سؤال المستخدم إلى تضمينات ويتم تشغيل بحث التشابه في قاعدة بيانات المتجهات للعثور على شريحة يمكن أن تحتوي على إجابات لسؤال المستخدم. نقوم بعد ذلك بتقديم هذه الشريحة (في شكل ملف صورة) إلى نموذج LLaVA وسؤال المستخدم كمطالبة لإنشاء إجابة للاستعلام. كل الكود الخاص بهذا المنشور متاح في GitHub جيثب: الريبو.
يوضح الرسم البياني التالي بنية العرض.
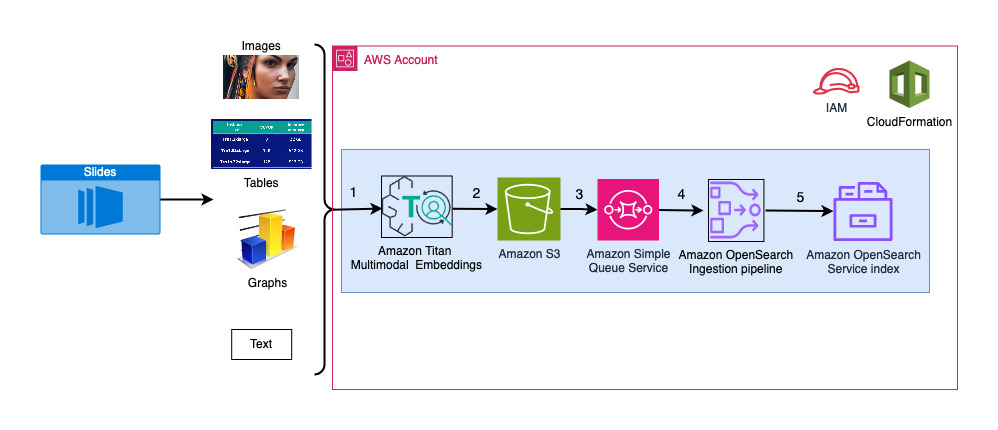
خطوات سير العمل كالتالي:
- يتم تحويل الشرائح إلى ملفات صور (واحدة لكل شريحة) بتنسيق JPG وتمريرها إلى نموذج Titan Multimodal Embeddings لإنشاء التضمينات. في هذه التدوينة، نستخدم مجموعة الشرائح بعنوان تدريب ونشر Stable Diffusion باستخدام AWS Trainium وAWS Inferentia من قمة AWS في تورونتو، يونيو 2023، لتوضيح الحل. تحتوي مجموعة العينات على 31 شريحة، لذلك قمنا بإنشاء 31 مجموعة من التضمينات المتجهة، تحتوي كل منها على 1,024 بُعدًا. نضيف حقول بيانات وصفية إضافية إلى عمليات التضمين المتجهة التي تم إنشاؤها وننشئ ملف JSON. يمكن استخدام حقول البيانات التعريفية الإضافية هذه لإجراء استعلامات بحث غنية باستخدام إمكانات البحث القوية في OpenSearch.
- يتم تجميع التضمينات التي تم إنشاؤها معًا في ملف JSON واحد يتم تحميله إليه خدمة تخزين أمازون البسيطة (أمازون S3).
- بواسطة إشعارات أحداث Amazon S3، يتم وضع حدث في خدمة Amazon Simple Queue Service قائمة انتظار (Amazon SQS).
- يعمل هذا الحدث في قائمة انتظار SQS كمشغل لتشغيل خط أنابيب OSI، والذي بدوره يستوعب البيانات (ملف JSON) كمستندات في فهرس OpenSearch Serverless. لاحظ أنه تم تكوين فهرس OpenSearch Serverless كمصرف لخط الأنابيب هذا ويتم إنشاؤه كجزء من مجموعة OpenSearch Serverless.
يوضح الرسم البياني التالي بنية تفاعل المستخدم.
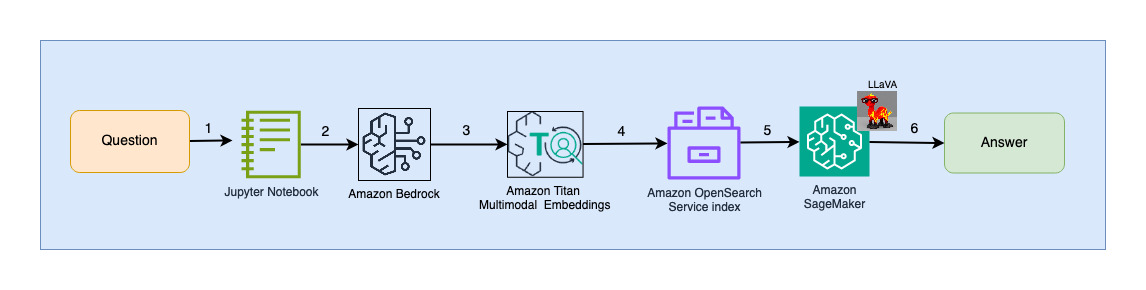
خطوات سير العمل كالتالي:
- يرسل المستخدم سؤالاً يتعلق بمجموعة الشرائح التي تم استيعابها.
- يتم تحويل مدخلات المستخدم إلى عمليات التضمين باستخدام نموذج Titan Multimodal Embeddings الذي يمكن الوصول إليه عبر Amazon Bedrock. يتم إجراء بحث متجه OpenSearch باستخدام هذه التضمينات. نقوم بإجراء بحث عن أقرب جار (k = 1) لاسترداد التضمين الأكثر صلة الذي يطابق استعلام المستخدم. يؤدي الإعداد k=1 إلى استرداد الشريحة الأكثر صلة بسؤال المستخدم.
- تحتوي البيانات التعريفية للاستجابة من OpenSearch Serverless على مسار للصورة المقابلة للشريحة الأكثر صلة.
- يتم إنشاء المطالبة من خلال الجمع بين سؤال المستخدم ومسار الصورة وتقديمها إلى LLaVA المستضافة على SageMaker. نموذج LLaVA قادر على فهم سؤال المستخدم والإجابة عليه من خلال فحص البيانات الموجودة في الصورة.
- يتم إرجاع نتيجة هذا الاستدلال إلى المستخدم.
وتتم مناقشة هذه الخطوات بالتفصيل في الأقسام التالية. انظر النتائج قسم لقطات الشاشة وتفاصيل الإخراج.
المتطلبات الأساسية المسبقة
لتنفيذ الحل المقدم في هذا المنشور ، يجب أن يكون لديك ملف حساب AWS والإلمام بـ FMs وAmazon Bedrock وSageMaker وخدمة OpenSearch.
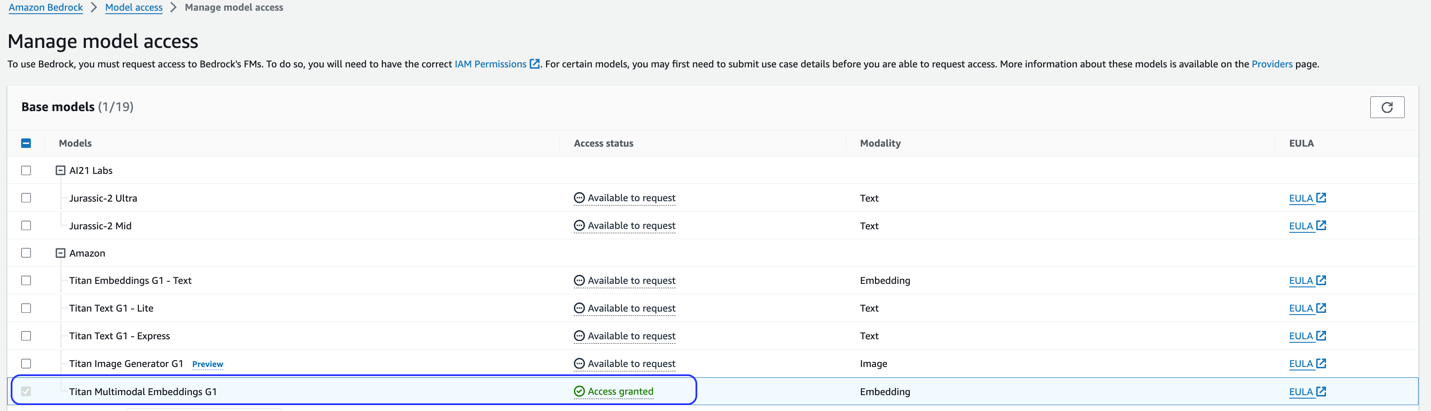
يستخدم هذا الحل نموذج Titan Multimodal Embeddings. تأكد من تمكين هذا النموذج للاستخدام في Amazon Bedrock. في وحدة تحكم Amazon Bedrock، اختر الوصول إلى النموذج في جزء التنقل. إذا تم تمكين Titan Multimodal Embeddings، فسيتم تحديد حالة الوصول تم منح حق الوصول.
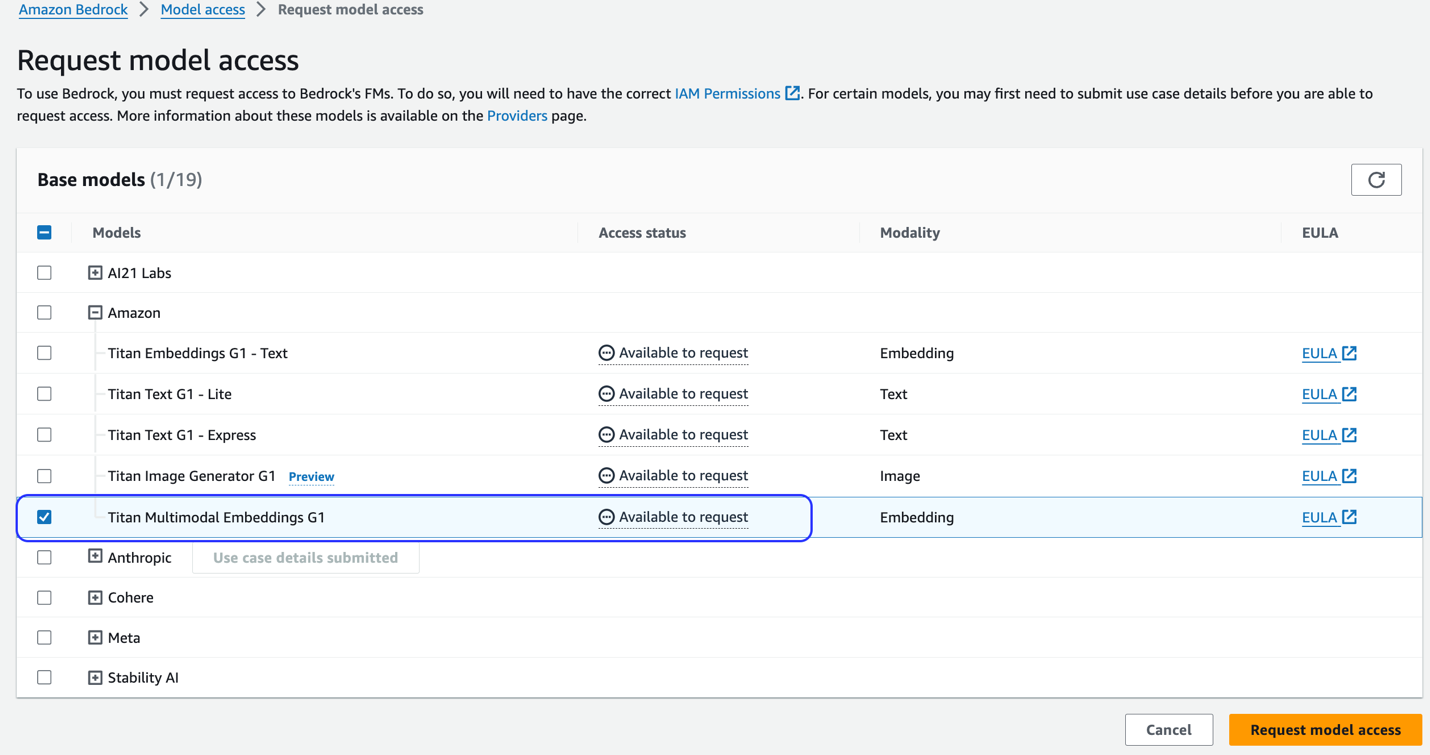
إذا لم يكن النموذج متاحًا، قم بتمكين الوصول إلى النموذج عن طريق الاختيار إدارة الوصول إلى النموذج، واختيار تيتان التضمين المتعدد الوسائط G1والاختيار طلب الوصول إلى النموذج. النموذج متاح للاستخدام على الفور.
استخدم قالب AWS CloudFormation لإنشاء حزمة الحلول
استخدم واحدًا مما يلي تكوين سحابة AWS القوالب (حسب منطقتك) لتشغيل موارد الحل.
| منطقة AWS | لينك |
|---|---|
us-east-1 |
|
us-west-2 |
بعد إنشاء المكدس بنجاح، انتقل إلى المكدس النواتج علامة التبويب في وحدة تحكم AWS CloudFormation ولاحظ القيمة الخاصة بـ MultimodalCollectionEndpointوالذي نستخدمه في الخطوات اللاحقة.
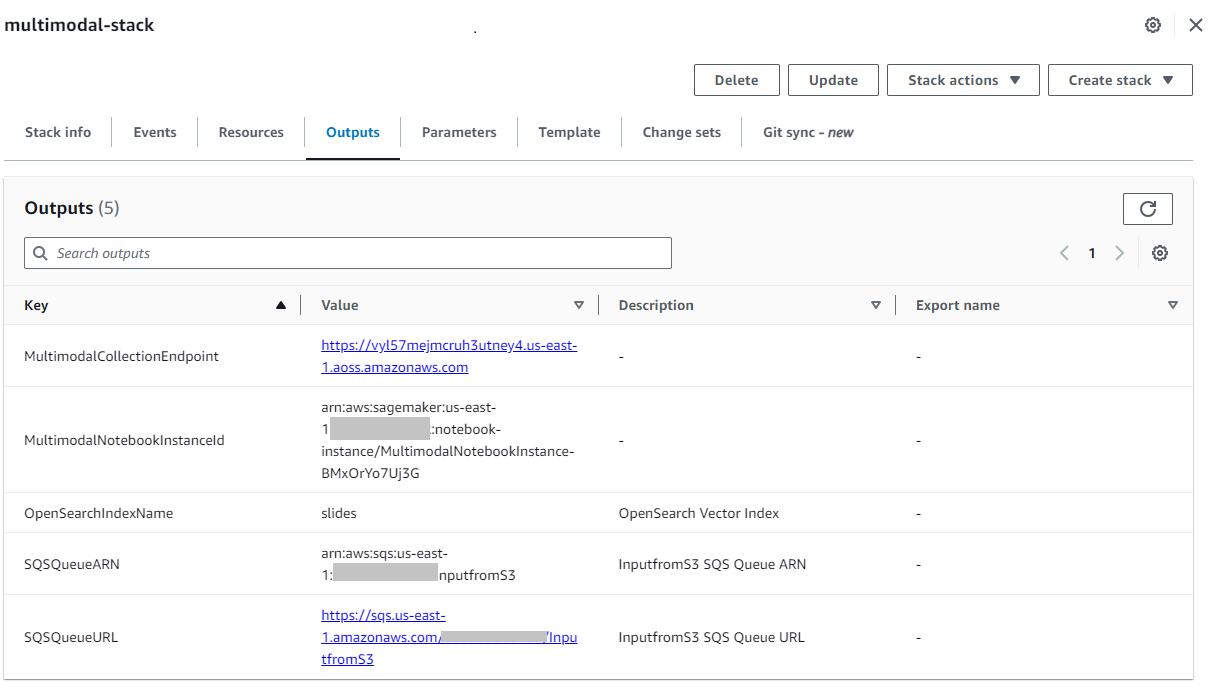
يُنشئ نموذج CloudFormation الموارد التالية:
- أدوار IAM - الأتى إدارة الهوية والوصول AWS يتم إنشاء أدوار (IAM). قم بتحديث هذه الأدوار ليتم تطبيقها أذونات الامتياز الأقل.
SMExecutionRoleمع Amazon S3 وSageMaker وOpenSearch Service وBedrock الوصول الكامل.OSPipelineExecutionRoleمع إمكانية الوصول إلى إجراءات Amazon SQS وOSI محددة.
- دفتر SageMaker - يتم تشغيل كافة التعليمات البرمجية لهذا المنشور عبر هذا الدفتري.
- مجموعة OpenSearch Serverless - هذه هي قاعدة البيانات المتجهة لتخزين واسترجاع التضمينات.
- خط أنابيب OSI – هذا هو خط الأنابيب لاستيعاب البيانات في OpenSearch Serverless.
- دلو S3 - يتم تخزين جميع البيانات الخاصة بهذا المنشور في هذه المجموعة.
- قائمة انتظار SQS - يتم وضع الأحداث الخاصة بتشغيل خط أنابيب OSI في قائمة الانتظار هذه.
يقوم قالب CloudFormation بتكوين مسار OSI مع معالجة Amazon S3 وAmazon SQS كمصدر وفهرس OpenSearch Serverless كمصرف. أي كائنات تم إنشاؤها في مجموعة S3 المحددة والبادئة (multimodal/osi-embeddings-json) سيؤدي إلى تشغيل إشعارات SQS، التي يستخدمها مسار OSI لاستيعاب البيانات في OpenSearch Serverless.
يقوم أيضًا بإنشاء قالب CloudFormation شبكة, التشفيرو الوصول إلى البيانات السياسات المطلوبة لمجموعة OpenSearch Serverless. قم بتحديث هذه السياسات لتطبيق أذونات الامتياز الأقل.
لاحظ أنه تتم الإشارة إلى اسم قالب CloudFormation في دفاتر ملاحظات SageMaker. إذا تم تغيير اسم القالب الافتراضي، فتأكد من تحديثه في globals.py
اختبر المحلول
بعد اكتمال الخطوات المطلوبة وإنشاء مكدس CloudFormation بنجاح، أنت الآن جاهز لاختبار الحل:
- في وحدة تحكم SageMaker ، اختر دفاتر في جزء التنقل.
- إختار ال
MultimodalNotebookInstanceمثيل دفتر الملاحظات واختيار افتح JupyterLab.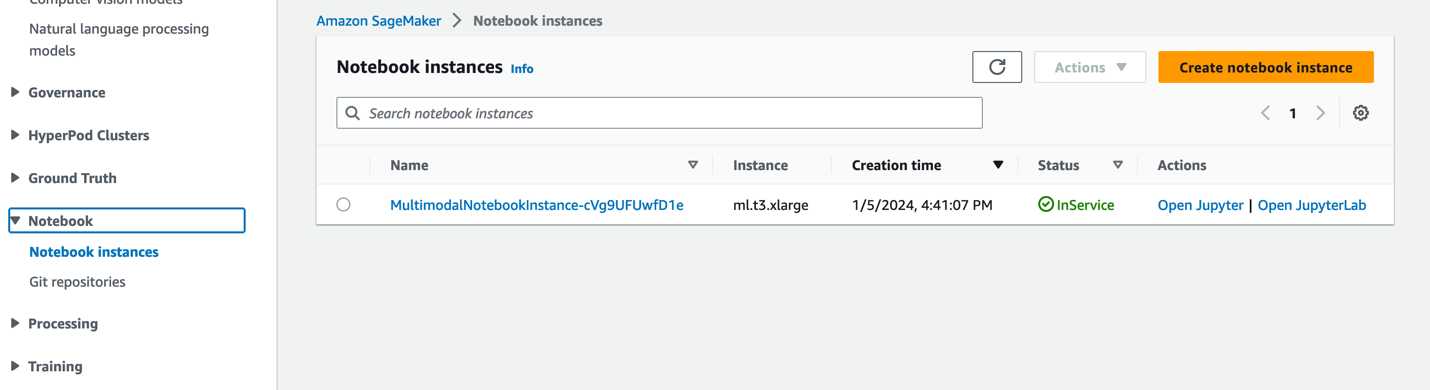
- In متصفح الملفات، انتقل إلى مجلد دفاتر الملاحظات لرؤية دفاتر الملاحظات والملفات الداعمة.
يتم ترقيم دفاتر الملاحظات بالتسلسل الذي يتم تشغيلها به. تصف الإرشادات والتعليقات الموجودة في كل دفتر ملاحظات الإجراءات التي يقوم بها هذا الدفتر. نقوم بتشغيل هذه الدفاتر واحدا تلو الآخر.
- اختار 0_deploy_llava.ipynb لفتحه في JupyterLab.
- على يجري القائمة، اختر قم بتشغيل كافة الخلايا لتشغيل التعليمات البرمجية في هذا الكمبيوتر الدفتري.
ينشر هذا الكمبيوتر الدفتري نموذج LLaVA-v1.5-7B إلى نقطة نهاية SageMaker. في هذا الدفتر، نقوم بتنزيل نموذج LLaVA-v1.5-7B من HuggingFace Hub، واستبدال البرنامج النصي inference.py بـ llava_inference.py، وقم بإنشاء ملف model.tar.gz لهذا النموذج. يتم تحميل ملف model.tar.gz إلى Amazon S3 واستخدامه لنشر النموذج على نقطة نهاية SageMaker. ال llava_inference.py يحتوي البرنامج النصي على رمز إضافي للسماح بقراءة ملف صورة من Amazon S3 وتشغيل الاستدلال عليه.
- اختار 1_data_prep.ipynb لفتحه في JupyterLab.
- على يجري القائمة، اختر قم بتشغيل كافة الخلايا لتشغيل التعليمات البرمجية في هذا الكمبيوتر الدفتري.
يقوم هذا الكمبيوتر الدفتري بتنزيل ملف الشريحة سطح السفينة، يحول كل شريحة إلى تنسيق ملف JPG، ويحملها إلى مجموعة S3 المستخدمة في هذا المنشور.
- اختار 2_data_ingestion.ipynb لفتحه في JupyterLab.
- على يجري القائمة، اختر قم بتشغيل كافة الخلايا لتشغيل التعليمات البرمجية في هذا الكمبيوتر الدفتري.
ونقوم بما يلي في هذا الدفتر:
- نقوم بإنشاء فهرس في مجموعة OpenSearch Serverless. يقوم هذا الفهرس بتخزين بيانات التضمين لمجموعة الشرائح. انظر الكود التالي:
- نحن نستخدم نموذج Titan Multimodal Embeddings لتحويل صور JPG التي تم إنشاؤها في دفتر الملاحظات السابق إلى تضمينات متجهة. يتم تخزين هذه التضمينات وبيانات التعريف الإضافية (مثل مسار S3 لملف الصورة) في ملف JSON ويتم تحميلها إلى Amazon S3. لاحظ أنه تم إنشاء ملف JSON واحد، والذي يحتوي على مستندات لجميع الشرائح (الصور) المحولة إلى تضمينات. يوضح مقتطف التعليمات البرمجية التالي كيفية تحويل الصورة (في شكل سلسلة مشفرة Base64) إلى تضمينات:
- يؤدي هذا الإجراء إلى تشغيل مسار OpenSearch Ingestion، الذي يعالج الملف ويستوعبه في فهرس OpenSearch Serverless. فيما يلي عينة من ملف JSON الذي تم إنشاؤه. (يتم عرض متجه بأربعة أبعاد في رمز المثال. يُنشئ نموذج Titan Multimodal Embeddings 1,024 بُعدًا.)
- اختار 3_rag_inference.ipynb لفتحه في JupyterLab.
- على يجري القائمة، اختر قم بتشغيل كافة الخلايا لتشغيل التعليمات البرمجية في هذا الكمبيوتر الدفتري.
يطبق هذا الكمبيوتر الدفتري حل RAG: نقوم بتحويل سؤال المستخدم إلى تضمينات، والعثور على صورة (شريحة) مماثلة من قاعدة بيانات المتجهات، وتوفير الصورة المستردة إلى LLaVA لإنشاء إجابة لسؤال المستخدم. نستخدم قالب المطالبة التالي:
يوفر مقتطف التعليمات البرمجية التالي سير عمل RAG:
النتائج
فيما يلي تجميع لبعض أسئلة المستخدمين وإجاباتهم الناتجة عن تنفيذنا. ال سؤال يلتقط العمود سؤال المستخدم، و إجابة العمود هو الاستجابة النصية التي تم إنشاؤها بواسطة LLaVA. صورة هي مطابقة الشريحة الأقرب (k = 1) التي يتم إرجاعها بواسطة بحث المتجهات OpenSearch Serverless. تم تفسير هذه الشريحة بواسطة LLaVA لتقديم الإجابة.
نتائج RAG المتعددة الوسائط
| سؤال | إجابة | صورة |
|---|---|---|
| كيف يمكن مقارنة أداء Inf2 بمثيلات EC2 المماثلة؟ أحتاج إلى أرقام. | وفقًا لمجموعة الشرائح، توفر مثيلات Inf2 من AWS Inferentia2 إنتاجية أعلى بما يصل إلى 4x وزمن وصول أقل 10x مقارنة بمثيلات EC2 المماثلة. |  |
| وفقًا لدولاب الموازنة AI/ML، ما الذي توفره خدمات AWS AI/ML؟ | توفر خدمات AWS AI/ML إمكانات أفضل للدولار/المنتج، وإمكانات جديدة، واستثمارًا في الابتكار. | 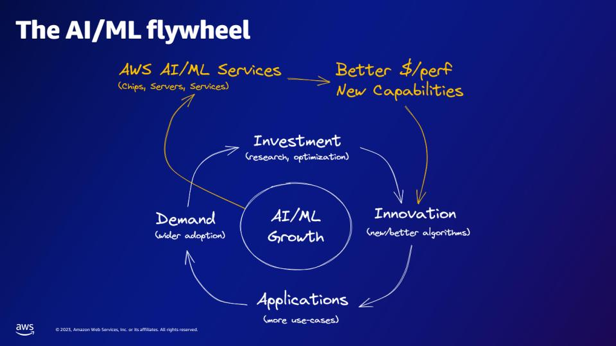 |
| بالمقارنة مع GPT-2، كم عدد المعلمات التي يمتلكها GPT-3؟ ما هو الفرق العددي بين حجم معلمة GPT-2 وGPT-3؟ | وفقًا للشريحة، يحتوي GPT-3 على 175 مليار معلمة، بينما يحتوي GPT-2 على 1.5 مليار معلمة. يبلغ الفرق العددي بين حجم المعلمة لـ GPT-2 وGPT-3 173.5 مليار. | 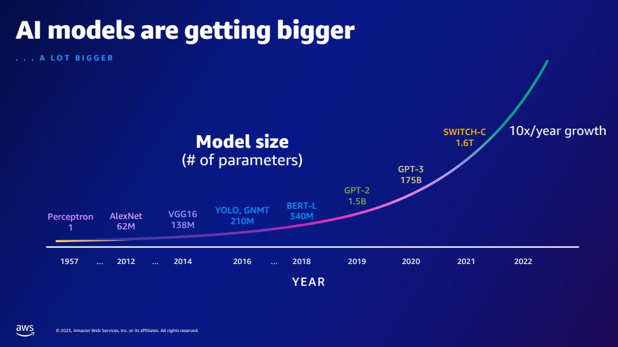 |
| ما هي الكواركات في فيزياء الجسيمات؟ | لم أجد الإجابة على هذا السؤال في مجموعة الشرائح. |  |
لا تتردد في توسيع هذا الحل ليشمل مجموعات الشرائح الخاصة بك. ما عليك سوى تحديث المتغير SLIDE_DECK في globals.py بعنوان URL لمجموعة الشرائح الخاصة بك وتشغيل خطوات العرض المفصلة في القسم السابق.
معلومه- سرية
يمكنك استخدام لوحات معلومات OpenSearch للتفاعل مع OpenSearch API لإجراء اختبارات سريعة على الفهرس والبيانات المستوعبة. تعرض لقطة الشاشة التالية مثال GET للوحة معلومات OpenSearch.
تنظيف
لتجنب تكبد رسوم مستقبلية، احذف الموارد التي قمت بإنشائها. يمكنك القيام بذلك عن طريق حذف المكدس عبر وحدة تحكم CloudFormation.

بالإضافة إلى ذلك، احذف نقطة نهاية استنتاج SageMaker التي تم إنشاؤها لاستدلال LLaVA. يمكنك القيام بذلك عن طريق إلغاء التعليق على خطوة التنظيف 3_rag_inference.ipynb وتشغيل الخلية، أو عن طريق حذف نقطة النهاية عبر وحدة تحكم SageMaker: اختر الإستنباط و النهاية في جزء التنقل، ثم حدد نقطة النهاية واحذفها.
وفي الختام
تقوم المؤسسات بإنشاء محتوى جديد طوال الوقت، وتعد مجموعات الشرائح آلية شائعة تستخدم لمشاركة المعلومات ونشرها داخليًا مع المؤسسة وخارجيًا مع العملاء أو في المؤتمرات. مع مرور الوقت، يمكن أن تظل المعلومات الغنية مدفونة ومخفية في أشكال غير نصية مثل الرسوم البيانية والجداول في مجموعات الشرائح هذه. يمكنك استخدام هذا الحل وقوة FMs متعددة الوسائط مثل نموذج Titan Multimodal Embeddings وLLaVA لاكتشاف معلومات جديدة أو الكشف عن وجهات نظر جديدة حول المحتوى في مجموعات الشرائح.
نحن نشجعك على تعلم المزيد من خلال الاستكشاف أمازون سيج ميكر جومب ستارت, نماذج أمازون تيتانوAmazon Bedrock وOpenSearch Service، وبناء حل باستخدام نموذج التنفيذ المقدم في هذا المنشور.
ابحث عن منشورين إضافيين كجزء من هذه السلسلة. يغطي الجزء الثاني أسلوبًا آخر يمكنك اتباعه للتحدث إلى مجموعة الشرائح الخاصة بك. يقوم هذا الأسلوب بإنشاء وتخزين استنتاجات LLaVA ويستخدم تلك الاستدلالات المخزنة للرد على استعلامات المستخدم. الجزء 2 يقارن النهجين.
عن المؤلفين
 اميت أرورا هو مهندس متخصص في الذكاء الاصطناعي والتعلم الآلي في Amazon Web Services ، مما يساعد عملاء المؤسسات على استخدام خدمات التعلم الآلي المستندة إلى السحابة لتوسيع نطاق ابتكاراتهم بسرعة. وهو أيضًا محاضر مساعد في برنامج علوم وتحليلات بيانات MS في جامعة جورج تاون في واشنطن العاصمة
اميت أرورا هو مهندس متخصص في الذكاء الاصطناعي والتعلم الآلي في Amazon Web Services ، مما يساعد عملاء المؤسسات على استخدام خدمات التعلم الآلي المستندة إلى السحابة لتوسيع نطاق ابتكاراتهم بسرعة. وهو أيضًا محاضر مساعد في برنامج علوم وتحليلات بيانات MS في جامعة جورج تاون في واشنطن العاصمة
 مانجو براساد هو مهندس حلول أول ضمن الحسابات الإستراتيجية في Amazon Web Services. وهي تركز على تقديم التوجيه الفني في مجموعة متنوعة من المجالات، بما في ذلك الذكاء الاصطناعي/التعلم الآلي لعميل الرصد والتقييم البارز. قبل انضمامها إلى AWS، قامت بتصميم وبناء حلول للشركات في قطاع الخدمات المالية وأيضًا للشركات الناشئة.
مانجو براساد هو مهندس حلول أول ضمن الحسابات الإستراتيجية في Amazon Web Services. وهي تركز على تقديم التوجيه الفني في مجموعة متنوعة من المجالات، بما في ذلك الذكاء الاصطناعي/التعلم الآلي لعميل الرصد والتقييم البارز. قبل انضمامها إلى AWS، قامت بتصميم وبناء حلول للشركات في قطاع الخدمات المالية وأيضًا للشركات الناشئة.
 ارشانا اينابودي هو مهندس حلول أول في AWS يدعم العملاء الاستراتيجيين. تتمتع بخبرة تزيد عن عشر سنوات في مساعدة العملاء على تصميم وبناء تحليلات البيانات وحلول قواعد البيانات. إنها متحمسة لاستخدام التكنولوجيا لتوفير القيمة للعملاء وتحقيق نتائج الأعمال.
ارشانا اينابودي هو مهندس حلول أول في AWS يدعم العملاء الاستراتيجيين. تتمتع بخبرة تزيد عن عشر سنوات في مساعدة العملاء على تصميم وبناء تحليلات البيانات وحلول قواعد البيانات. إنها متحمسة لاستخدام التكنولوجيا لتوفير القيمة للعملاء وتحقيق نتائج الأعمال.
 عنتارا رايسة هو مهندس حلول الذكاء الاصطناعي وتعلم الآلة في Amazon Web Services الذي يدعم العملاء الاستراتيجيين المقيمين في دالاس، تكساس. تتمتع أيضًا بخبرة سابقة في العمل مع شركاء المؤسسات الكبيرة في AWS، حيث عملت كمهندس حلول نجاح الشركاء للعملاء الرقميين الأصليين.
عنتارا رايسة هو مهندس حلول الذكاء الاصطناعي وتعلم الآلة في Amazon Web Services الذي يدعم العملاء الاستراتيجيين المقيمين في دالاس، تكساس. تتمتع أيضًا بخبرة سابقة في العمل مع شركاء المؤسسات الكبيرة في AWS، حيث عملت كمهندس حلول نجاح الشركاء للعملاء الرقميين الأصليين.
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- PlatoData.Network Vertical Generative Ai. تمكين نفسك. الوصول هنا.
- أفلاطونايستريم. ذكاء Web3. تضخيم المعرفة. الوصول هنا.
- أفلاطون كربون، كلينتك ، الطاقة، بيئة، شمسي، إدارة المخلفات. الوصول هنا.
- أفلاطون هيلث. التكنولوجيا الحيوية وذكاء التجارب السريرية. الوصول هنا.
- المصدر https://aws.amazon.com/blogs/machine-learning/talk-to-your-slide-deck-using-multimodal-foundation-models-hosted-on-amazon-bedrock-and-amazon-sagemaker-part-1/

