أصبحت نماذج اللغات الكبيرة (LLM) شائعة بشكل متزايد، مع استكشاف حالات الاستخدام الجديدة باستمرار. بشكل عام، يمكنك إنشاء تطبيقات مدعومة ببرامج LLM من خلال دمج الهندسة السريعة في التعليمات البرمجية الخاصة بك. ومع ذلك، هناك حالات يكون فيها المطالبة بالحصول على ماجستير في القانون الحالي غير كاف. هذا هو المكان الذي يمكن أن يساعد فيه ضبط النموذج. تتعلق الهندسة السريعة بتوجيه مخرجات النموذج من خلال صياغة مطالبات الإدخال، في حين أن الضبط الدقيق يتعلق بتدريب النموذج على مجموعات بيانات مخصصة لجعله أكثر ملاءمة لمهام أو مجالات محددة.
قبل أن تتمكن من تحسين النموذج، تحتاج إلى العثور على مجموعة بيانات خاصة بالمهمة. إحدى مجموعات البيانات شائعة الاستخدام هي مجموعة بيانات الزحف الشائعة. تحتوي مجموعة Common Crawl على بيتابايت من البيانات، والتي يتم جمعها بانتظام منذ عام 2008، وتحتوي على بيانات صفحات الويب الأولية، ومقتطفات بيانات التعريف، ومقتطفات نصية. بالإضافة إلى تحديد مجموعة البيانات التي يجب استخدامها، يلزم تنظيف البيانات ومعالجتها وفقًا لاحتياجات الضبط الدقيق.
لقد عملنا مؤخرًا مع أحد العملاء الذي أراد إجراء معالجة مسبقة لمجموعة فرعية من أحدث مجموعة بيانات Common Crawl ثم ضبط ماجستير إدارة الأعمال (LLM) الخاص به باستخدام البيانات التي تم تنظيفها. كان العميل يبحث عن كيفية تحقيق ذلك بالطريقة الأكثر فعالية من حيث التكلفة على AWS. بعد مناقشة المتطلبات، أوصينا باستخدام أمازون EMR بدون خادم كمنصة خاصة بهم للمعالجة المسبقة للبيانات. يعد EMR Serverless مناسبًا تمامًا لمعالجة البيانات على نطاق واسع ويلغي الحاجة إلى صيانة البنية التحتية. من حيث التكلفة، يتم فرض الرسوم فقط على أساس الموارد والمدة المستخدمة لكل مهمة. تمكن العميل من المعالجة المسبقة لمئات تيرابايت من البيانات خلال أسبوع باستخدام EMR Serverless. بعد أن قاموا بمعالجة البيانات مسبقًا، استخدموا الأمازون SageMaker لضبط LLM.
في هذا المنشور، نوجهك عبر حالة استخدام العميل والبنية المستخدمة.
في الأقسام التالية، نقدم أولاً مجموعة بيانات الزحف المشترك وكيفية استكشاف البيانات التي نحتاجها وتصفيتها. أمازون أثينا لا يتم فرض رسوم إلا على حجم البيانات التي يتم مسحها ضوئيًا، ويتم استخدامها لاستكشاف البيانات وتصفيتها بسرعة، مع كونها فعالة من حيث التكلفة. يوفر EMR Serverless خيارًا فعالاً من حيث التكلفة ولا يحتاج إلى صيانة لمعالجة بيانات Spark، ويستخدم لمعالجة البيانات التي تمت تصفيتها. التالي نستخدم أمازون سيج ميكر جومب ستارت لضبط نموذج لاما 2 مع مجموعة البيانات المعالجة مسبقا. يوفر SageMaker JumpStart مجموعة من الحلول لحالات الاستخدام الأكثر شيوعًا والتي يمكن نشرها ببضع نقرات فقط. لا تحتاج إلى كتابة أي تعليمات برمجية لضبط LLM مثل Llama 2. وأخيرًا، قمنا بنشر النموذج المضبوط باستخدام الأمازون SageMaker وقارن الاختلافات في مخرجات النص لنفس السؤال بين نماذج Llama 2 الأصلية والمضبوطة بدقة.
يوضح الرسم البياني التالي بنية هذا الحل.
قبل أن تتعمق في تفاصيل الحل، أكمل الخطوات الأساسية التالية:
Common Crawl عبارة عن مجموعة بيانات مفتوحة يتم الحصول عليها من خلال الزحف إلى أكثر من 50 مليار صفحة ويب. ويتضمن كميات هائلة من البيانات غير المنظمة بلغات متعددة، بدءاً من عام 2008 وحتى مستوى البيتابايت. يتم تحديثه بشكل مستمر.
في تدريب GPT-3، تمثل مجموعة بيانات الزحف المشترك 60% من بيانات التدريب الخاصة بها، كما هو موضح في الرسم البياني التالي (المصدر: نماذج اللغة هم متعلمون قليلو الطلقات).
مجموعة بيانات مهمة أخرى جديرة بالذكر هي مجموعة بيانات C4. C4، وهو اختصار لـ Colossal Clean Crawled Corpus، عبارة عن مجموعة بيانات مشتقة من المعالجة اللاحقة لمجموعة بيانات Common Crawl. في ورقة LLaMA الصادرة عن Meta، حددوا مجموعات البيانات المستخدمة، حيث يمثل Common Crawl 67% (باستخدام 3.3 تيرابايت من البيانات) وC4 بنسبة 15% (باستخدام 783 جيجابايت من البيانات). تؤكد الورقة على أهمية دمج البيانات المعالجة مسبقًا بشكل مختلف لتعزيز أداء النموذج. على الرغم من كون بيانات C4 الأصلية جزءًا من Common Crawl، فقد اختارت Meta النسخة المعاد معالجتها من هذه البيانات.
في هذا القسم، نتناول الطرق الشائعة للتفاعل مع مجموعة بيانات الزحف المشترك وتصفيتها ومعالجتها.
تتضمن مجموعة البيانات الأولية Common Crawl ثلاثة أنواع من ملفات البيانات: بيانات صفحة الويب الأولية (WARC)، والبيانات التعريفية (WAT)، واستخراج النص (WET).
يتم تخزين البيانات التي تم جمعها بعد عام 2013 بتنسيق WARC وتتضمن البيانات الوصفية المقابلة (WAT) وبيانات استخراج النص (WET). توجد مجموعة البيانات في Amazon S3، ويتم تحديثها على أساس شهري، ويمكن الوصول إليها مباشرة من خلاله سوق AWS.
$ aws s3 ls s3://commoncrawl/crawl-data/CC-MAIN-2023-23/
PRE segments/
2023-06-21 00:34:08 2164 cc-index-table.paths.gz
2023-06-21 00:34:08 637 cc-index.paths.gz
2023-06-21 05:52:05 2724 index.html
2023-06-21 00:34:09 161064 non200responses.paths.gz
2023-06-21 00:34:10 160888 robotstxt.paths.gz
2023-06-21 00:34:10 480 segment.paths.gz
2023-06-21 00:34:11 161082 warc.paths.gz
2023-06-21 00:34:12 160895 wat.paths.gz
2023-06-21 00:34:12 160898 wet.paths.gzتوفر مجموعة بيانات الزحف المشترك أيضًا جدول فهرس لتصفية البيانات، وهو ما يسمى جدول cc-index.
يعد جدول cc-index فهرسًا للبيانات الموجودة، ويوفر فهرسًا قائمًا على جدول لملفات WARC. فهو يسمح بالبحث السهل عن المعلومات، مثل ملف WARC الذي يتوافق مع عنوان URL محدد.
على سبيل المثال، يمكنك إنشاء جدول Athena لتعيين بيانات cc-index بالكود التالي:
توضح عبارات SQL السابقة كيفية إنشاء جدول Athena وإضافة أقسام وتشغيل الاستعلام.
تصفية البيانات من مجموعة بيانات الزحف المشترك
كما ترون من جملة إنشاء جدول SQL، هناك العديد من الحقول التي يمكن أن تساعد في تصفية البيانات. على سبيل المثال، إذا كنت تريد الحصول على عدد المستندات الصينية خلال فترة محددة، فيمكن أن تكون عبارة SQL كما يلي:
إذا كنت تريد إجراء مزيد من المعالجة، فيمكنك حفظ النتائج في حاوية S3 أخرى.
تحليل البيانات التي تمت تصفيتها
• مستودع الزحف المشترك على GitHub يوفر العديد من أمثلة PySpark لمعالجة البيانات الأولية.
دعونا نلقي نظرة على مثال للتشغيل server_count.py (مثال على البرنامج النصي المقدم من Common Crawl GitHub repo) على البيانات الموجودة في s3://commoncrawl/crawl-data/CC-MAIN-2023-23/segments/1685224643388.45/warc/.
أولاً، أنت بحاجة إلى بيئة Spark، مثل EMR Spark. على سبيل المثال، يمكنك تشغيل Amazon EMR على مجموعة EC2 في us-east-1 (لأن مجموعة البيانات موجودة us-east-1). يمكن أن يساعدك استخدام EMR في مجموعة EC2 في إجراء الاختبارات قبل إرسال المهام إلى بيئة الإنتاج.
بعد تشغيل EMR على مجموعة EC2، يتعين عليك تسجيل الدخول عبر SSH إلى العقدة الأساسية للمجموعة. ثم قم بحزم بيئة Python وأرسل البرنامج النصي (راجع ملف وثائق كوندا لتثبيت مينيكوندا):
قد يستغرق الأمر بعض الوقت لمعالجة كافة المراجع في warc.path. لأغراض العرض التوضيحي، يمكنك تحسين وقت المعالجة باستخدام الاستراتيجيات التالية:
- تحميل الملف
s3://commoncrawl/crawl-data/CC-MAIN-2023-23/warc.paths.gzإلى جهازك المحلي، وقم بفك ضغطه، ثم قم بتحميله على HDFS أو Amazon S3. وذلك لأن الملف .gzip غير قابل للتقسيم. تحتاج إلى فك ضغطه لمعالجة هذا الملف بالتوازي. - تعديل
warc.pathالملف، واحذف معظم أسطره، واحتفظ بسطرين فقط لتسيير المهمة بشكل أسرع.
بعد الانتهاء من المهمة، يمكنك رؤية النتيجة s3://xxxx-common-crawl/output/، على شكل باركيه.
تنفيذ منطق امتلاك مخصص
يوفر Common Crawl GitHub repo طريقة شائعة لمعالجة ملفات WARC. بشكل عام، يمكنك تمديد CCSparkJob لتجاوز طريقة واحدة (process_record)، وهو كافٍ لكثير من الحالات.
دعونا نلقي نظرة على مثال للحصول على تقييمات IMDB للأفلام الحديثة. أولاً، عليك تصفية الملفات الموجودة على موقع IMDB:
ثم يمكنك الحصول على قوائم ملفات WARC التي تحتوي على بيانات مراجعة IMDB، وحفظ أسماء ملفات WARC كقائمة في ملف نصي.
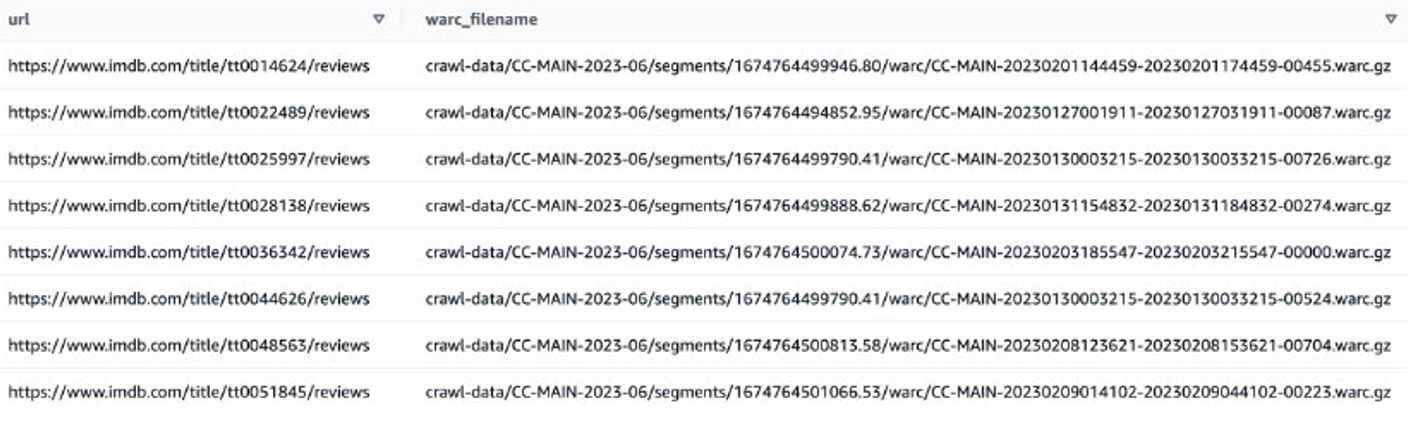
وبدلاً من ذلك، يمكنك استخدام EMR Spark للحصول على قائمة ملفات WARC وتخزينها في Amazon S3. على سبيل المثال:
يجب أن يبدو ملف الإخراج مشابهًا لـ s3://xxxx-common-crawl/warclist/imdb_warclist/part-00000-6af12797-0cdc-4ef2-a438-cf2b935f2ffd-c000.txt.
الخطوة التالية هي استخراج مراجعات المستخدم من ملفات WARC هذه. يمكنك تمديد CCSparkJob لتجاوز process_record() الأسلوب:
يمكنك حفظ البرنامج النصي السابق باسم imdb_extractor.py، والذي ستستخدمه في الخطوات التالية. بعد إعداد البيانات والبرامج النصية، يمكنك استخدام EMR Serverless لمعالجة البيانات التي تمت تصفيتها.
EMR بدون خادم
EMR Serverless هو خيار نشر بدون خادم لتشغيل تطبيقات تحليلات البيانات الضخمة باستخدام أطر عمل مفتوحة المصدر مثل Apache Spark وHive دون تكوين مجموعات أو خوادم وإدارتها وتوسيع نطاقها.
باستخدام EMR Serverless، يمكنك تشغيل أحمال عمل التحليلات على أي نطاق من خلال القياس التلقائي الذي يغير حجم الموارد في ثوانٍ لتلبية أحجام البيانات المتغيرة ومتطلبات المعالجة. يقوم EMR Serverless تلقائيًا بتوسيع نطاق الموارد لأعلى ولأسفل لتوفير المقدار المناسب من السعة لتطبيقك، ولا تدفع إلا مقابل ما تستخدمه.
تعد معالجة مجموعة بيانات الزحف المشترك بشكل عام مهمة معالجة لمرة واحدة، مما يجعلها مناسبة لأحمال عمل EMR بدون خادم.
إنشاء تطبيق EMR بدون خادم
يمكنك إنشاء تطبيق EMR Serverless على وحدة تحكم EMR Studio. أكمل الخطوات التالية:
- في وحدة تحكم استوديو EMR ، اختر التطبيقات مع Serverless في جزء التنقل.
- اختار إنشاء التطبيق.

- أدخل اسمًا للتطبيق واختر إصدار Amazon EMR.
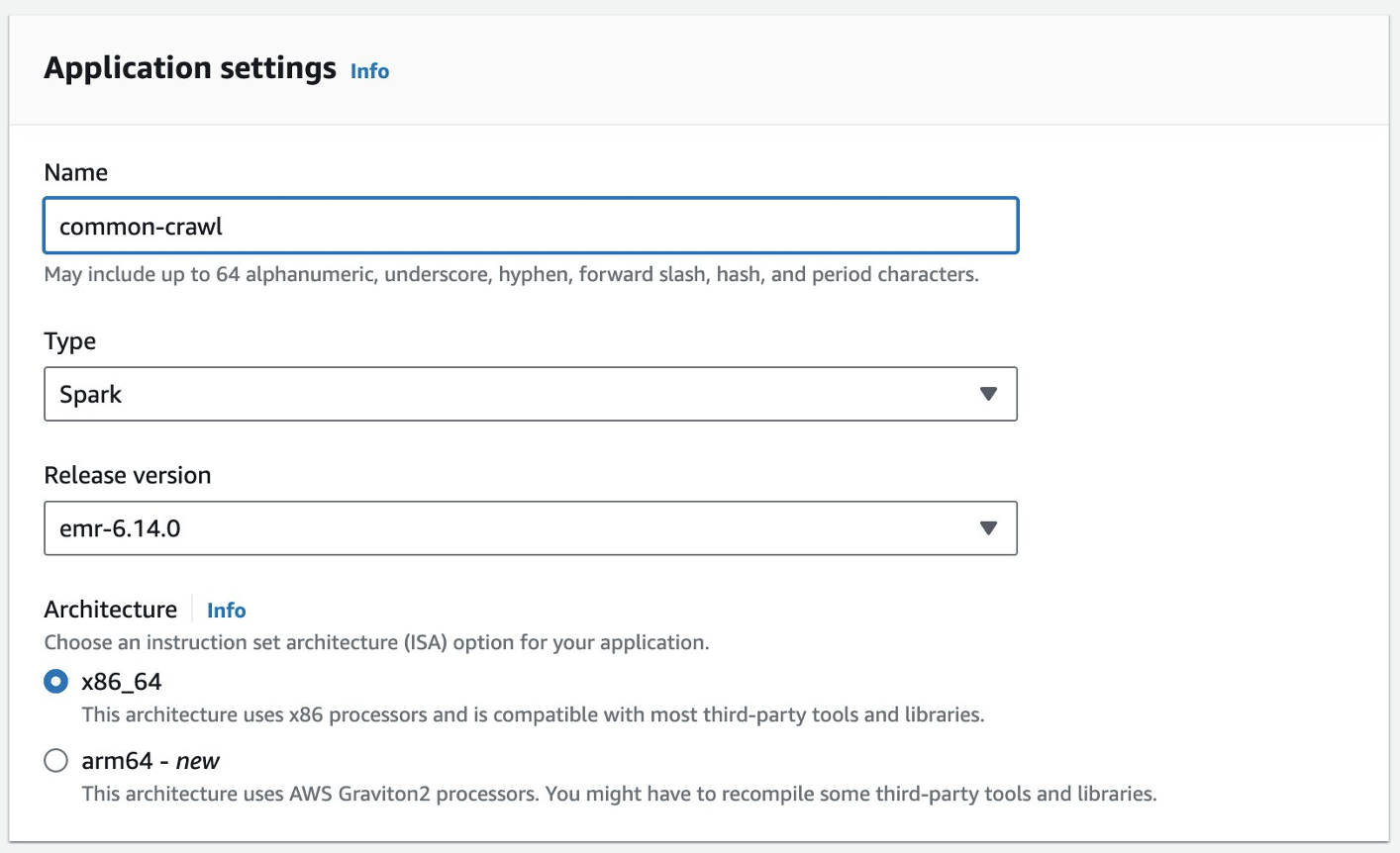
- إذا كان الوصول إلى موارد VPC مطلوبًا، فقم بإضافة إعداد شبكة مخصص.

- اختار إنشاء التطبيق.
ستكون بيئة Spark بدون خادم جاهزة بعد ذلك.
قبل أن تتمكن من إرسال مهمة إلى EMR Spark Serverless، لا تزال بحاجة إلى إنشاء دور تنفيذ. تشير إلى الشروع في العمل مع Amazon EMR Serverless لمزيد من التفاصيل.
معالجة بيانات الزحف الشائعة باستخدام EMR Serverless
بعد أن يصبح تطبيق EMR Spark Serverless جاهزًا، أكمل الخطوات التالية لمعالجة البيانات:
- قم بإعداد بيئة Conda وقم بتحميلها إلى Amazon S3، والتي سيتم استخدامها كبيئة في EMR Spark Serverless.
- قم بتحميل البرامج النصية ليتم تشغيلها إلى مجموعة S3. في المثال التالي، هناك نوعان من البرامج النصية:
- imbd_extractor.py – منطق مخصص لاستخراج المحتويات من مجموعة البيانات. محتويات يمكن العثور عليها في وقت سابق من هذا المنصب.
- cc-pyspark/sparkcc.py - مثال إطار عمل PySpark من ريبو الزحف المشترك على جيثب، وهو أمر ضروري لإدراجه.
- أرسل مهمة PySpark إلى EMR Serverless Spark. حدد المعلمات التالية لتشغيل هذا المثال في بيئتك:
- رقم الاستمارة – معرف التطبيق لتطبيق EMR Serverless الخاص بك.
- تنفيذ الدور-arn – دور التنفيذ بدون خادم EMR الخاص بك. لإنشائه، راجع إنشاء دور وقت التشغيل الوظيفي.
- موقع ملف WARC - موقع ملفات WARC الخاصة بك.
s3://xxxx-common-crawl/warclist/imdb_warclist/part-00000-6af12797-0cdc-4ef2-a438-cf2b935f2ffd-c000.txtيحتوي على قائمة ملفات WARC التي تمت تصفيتها، والتي حصلت عليها سابقًا في هذا المنشور. - spark.sql.warehouse.dir – موقع المستودع الافتراضي (استخدم دليل S3 الخاص بك).
- spark.archives – موقع S3 لبيئة كوندا المعدة.
- spark.submit.pyFiles - البرنامج النصي PySpark المُجهز sparkcc.py.
انظر الكود التالي:
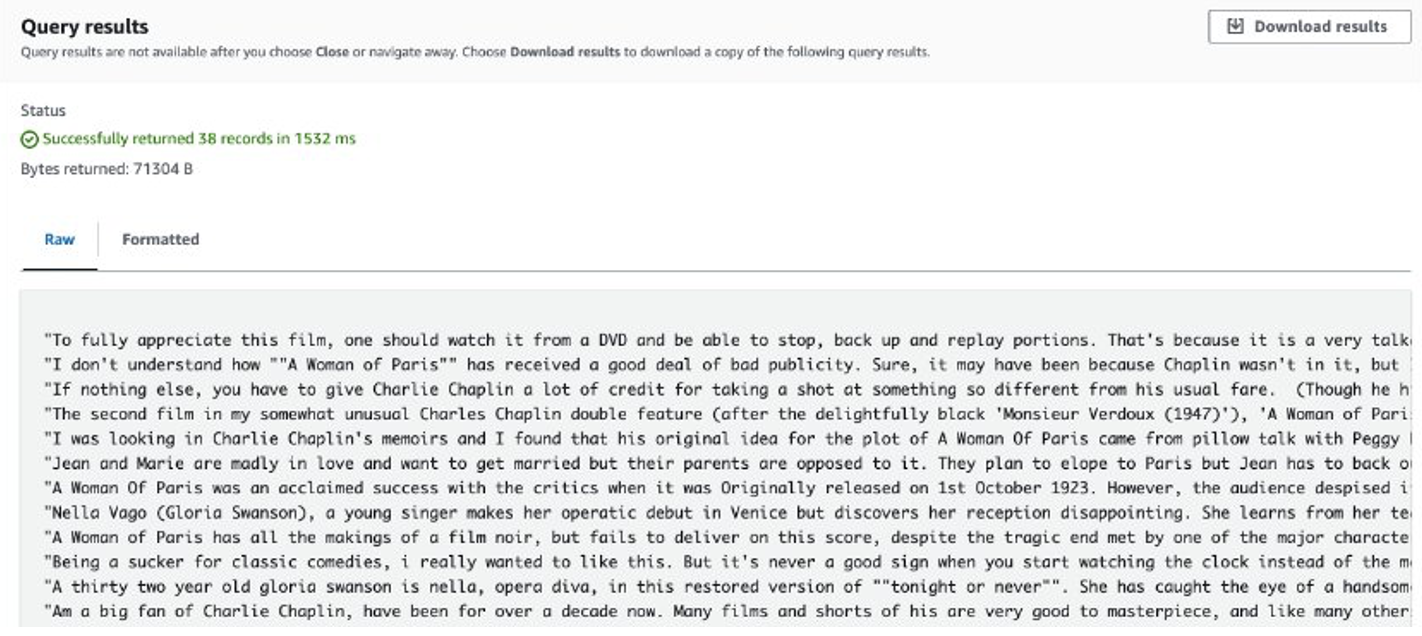
بعد اكتمال المهمة، يتم تخزين المراجعات المستخرجة في Amazon S3. للتحقق من المحتويات، يمكنك استخدام Amazon S3 Select، كما هو موضح في لقطة الشاشة التالية.
الاعتبارات
فيما يلي النقاط التي يجب مراعاتها عند التعامل مع كميات هائلة من البيانات باستخدام تعليمات برمجية مخصصة:
- قد لا تتوفر بعض مكتبات Python التابعة لجهات خارجية في Conda. في مثل هذه الحالات، يمكنك التبديل إلى بيئة Python الافتراضية لإنشاء بيئة تشغيل PySpark.
- إذا كانت هناك كمية هائلة من البيانات المراد معالجتها، فحاول إنشاء واستخدام العديد من تطبيقات EMR Serverless Spark لموازاة ذلك. يتعامل كل تطبيق مع مجموعة فرعية من قوائم الملفات.
- قد تواجه مشكلة تباطؤ في Amazon S3 عند تصفية بيانات الزحف المشترك أو معالجتها. وذلك لأن حاوية S3 التي تخزن البيانات يمكن الوصول إليها بشكل عام، ويمكن للمستخدمين الآخرين الوصول إلى البيانات في نفس الوقت. للتخفيف من هذه المشكلة، يمكنك إضافة آلية إعادة المحاولة أو مزامنة بيانات معينة من حاوية Common Crawl S3 إلى الحاوية الخاصة بك.
قم بضبط Llama 2 باستخدام SageMaker
بعد إعداد البيانات، يمكنك ضبط نموذج Llama 2 باستخدامها. يمكنك القيام بذلك باستخدام SageMaker JumpStart، دون كتابة أي تعليمات برمجية. لمزيد من المعلومات، راجع قم بضبط Llama 2 لإنشاء النص على Amazon SageMaker JumpStart.
في هذا السيناريو، يمكنك إجراء ضبط دقيق للتكيف مع المجال. باستخدام مجموعة البيانات هذه، يتكون الإدخال من ملف CSV أو JSON أو TXT. تحتاج إلى وضع جميع بيانات المراجعة في ملف TXT. للقيام بذلك، يمكنك إرسال مهمة Spark مباشرة إلى EMR Spark Serverless. راجع مقتطف التعليمات البرمجية النموذجي التالي:
بعد الانتهاء من تجهيز بيانات التدريب، قم بإدخال موقع البيانات الخاص به مجموعة بيانات التدريب، ثم اختر قطار.
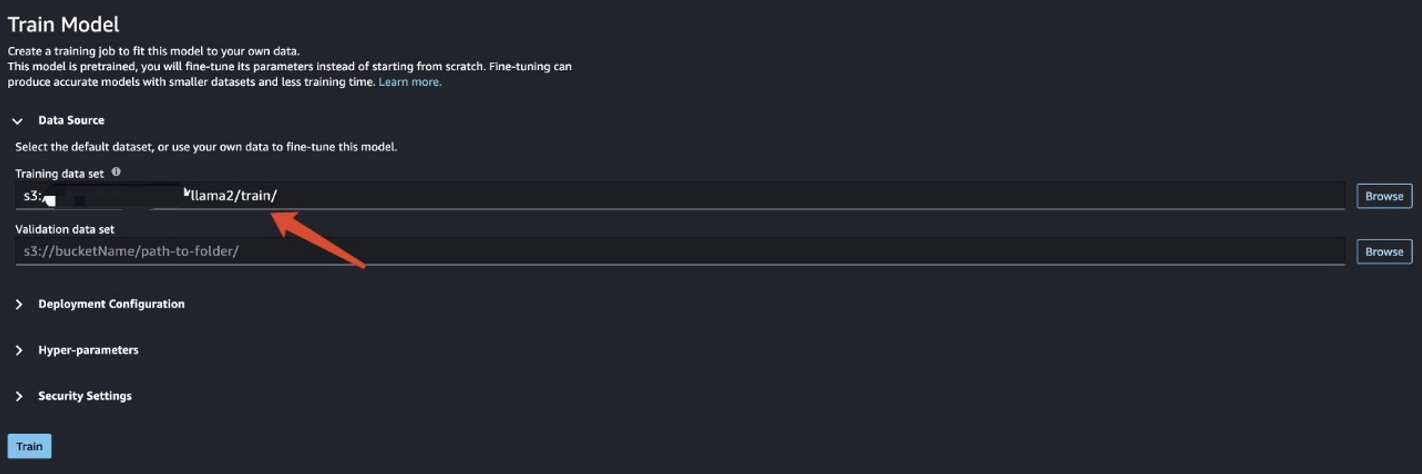
يمكنك تتبع حالة مهمة التدريب.
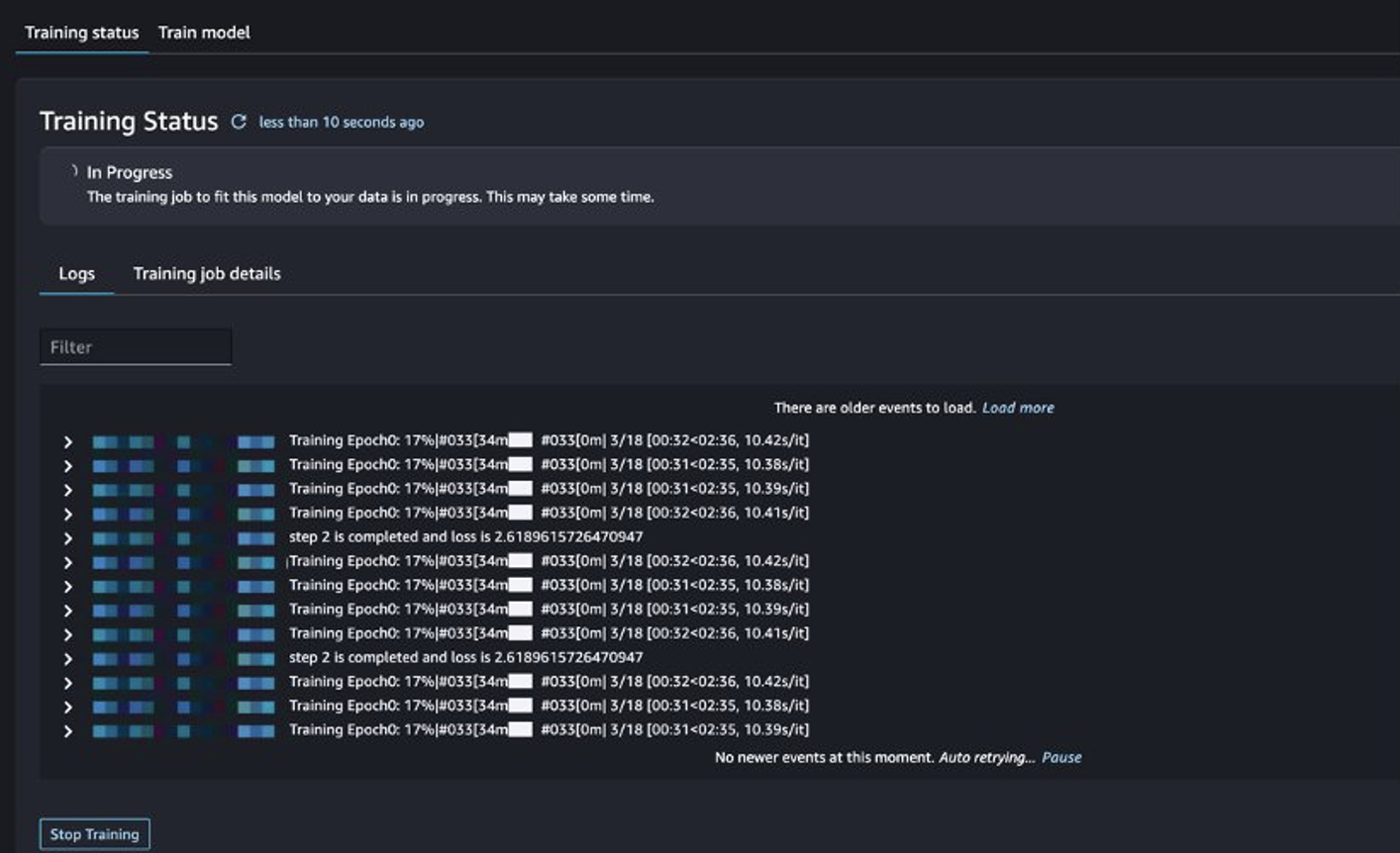
تقييم النموذج المضبوط
بعد الانتهاء من التدريب، اختر نشر في SageMaker JumpStart لنشر نموذجك المضبوط بدقة.

بعد نشر النموذج بنجاح، اختر افتح المفكرة، والذي يعيد توجيهك إلى دفتر Jupyter المُجهز حيث يمكنك تشغيل كود Python الخاص بك.

يمكنك استخدام الصورة Data Science 2.0 وPython 3 kernel لدفتر الملاحظات.

بعد ذلك، يمكنك تقييم النموذج المضبوط والنموذج الأصلي في هذا الكمبيوتر الدفتري.
فيما يلي إجابتان تم إرجاعهما بواسطة النموذج الأصلي والنموذج المحسّن لنفس السؤال.
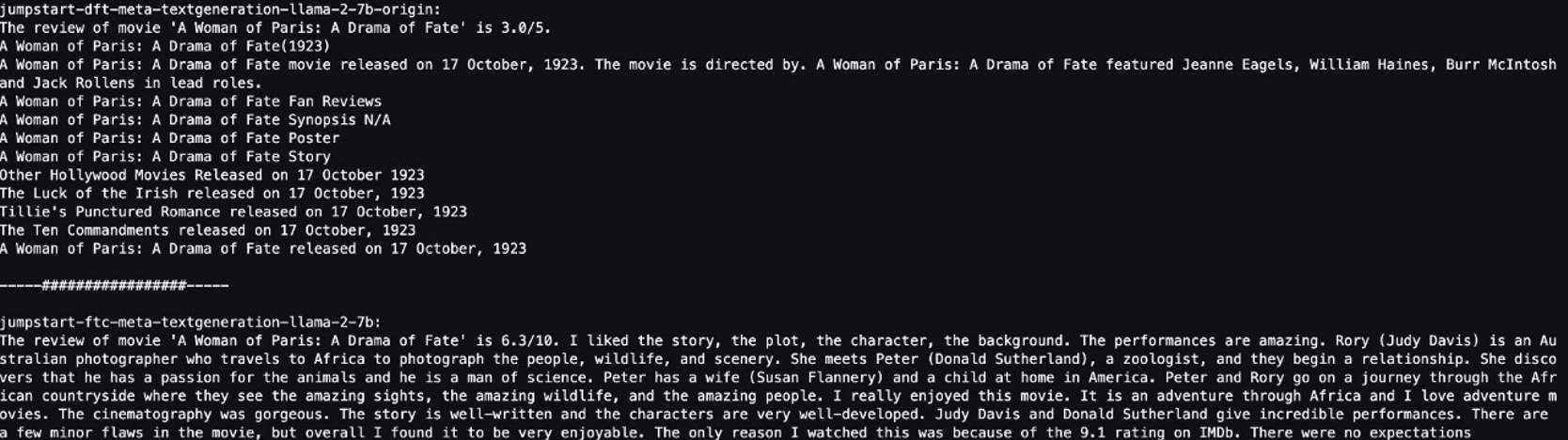
قدمنا لكلا العارضين نفس الجملة: "إن مراجعة فيلم A Woman of Paris: A Drama of Fate هي" ودعناهما يكملان الجملة.
يُخرج النموذج الأصلي جملًا لا معنى لها:
"The review of movie 'A woman of Paris: A Drama of Fate' is 3.0/5.
A Woman of Paris: A Drama of Fate(1923)
A Woman of Paris: A Drama of Fate movie released on 17 October, 1992. The movie is directed by. A Woman of Paris: A Drama of Fate featured Jeanne Eagles, William Haines, Burr McIntosh and Jack Rollens in lead rols.
..."
في المقابل، فإن مخرجات النموذج المضبوط تشبه إلى حد كبير مراجعة الفيلم:
" The review of movie 'A Woman of Paris: A Drama of Fate' is 6.3/10. I liked the story, the plot, the character, the background. The performances are amazing. Rory (Judy Davis) is an Australian photographer who travels to Africa to photograph the people, wildlife, and scenery. She meets Peter (Donald Sutherland), a zoologist, and they begin a relationship..."
من الواضح أن النموذج المضبوط يعمل بشكل أفضل في هذا السيناريو المحدد.
تنظيف
بعد الانتهاء من هذا التمرين، أكمل الخطوات التالية لتنظيف مواردك:
- احذف حاوية S3 الذي يخزن مجموعة البيانات التي تم تنظيفها.
- أوقف بيئة EMR بدون خادم.
- احذف نقطة نهاية SageMaker التي تستضيف نموذج LLM.
- احذف مجال SageMaker الذي يدير دفاتر الملاحظات الخاصة بك.
يجب أن يتوقف التطبيق الذي قمت بإنشائه تلقائيًا بعد 15 دقيقة من عدم النشاط بشكل افتراضي.
بشكل عام، لا تحتاج إلى تنظيف بيئة Athena لأنه لا توجد رسوم عند عدم استخدامها.
وفي الختام
في هذا المنشور، قدمنا مجموعة بيانات Common Crawl وكيفية استخدام EMR Serverless لمعالجة البيانات من أجل الضبط الدقيق لـ LLM. ثم أوضحنا كيفية استخدام SageMaker JumpStart لضبط LLM ونشره بدون أي تعليمات برمجية. لمزيد من حالات استخدام EMR Serverless، راجع أمازون EMR بدون خادم. لمزيد من المعلومات حول استضافة النماذج وضبطها على Amazon SageMaker JumpStart، راجع وثائق Sagemaker JumpStart.
حول المؤلف
 شيجيان تانغ هو مهندس حلول متخصص في التحليلات في Amazon Web Services.
شيجيان تانغ هو مهندس حلول متخصص في التحليلات في Amazon Web Services.
 ماثيو ليم هو مدير أول لهندسة الحلول في Amazon Web Services.
ماثيو ليم هو مدير أول لهندسة الحلول في Amazon Web Services.
 دالي شو هو مهندس حلول متخصص في التحليلات في Amazon Web Services.
دالي شو هو مهندس حلول متخصص في التحليلات في Amazon Web Services.
 يوان جون شياو هو مهندس حلول أول في Amazon Web Services.
يوان جون شياو هو مهندس حلول أول في Amazon Web Services.
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- PlatoData.Network Vertical Generative Ai. تمكين نفسك. الوصول هنا.
- أفلاطونايستريم. ذكاء Web3. تضخيم المعرفة. الوصول هنا.
- أفلاطون كربون، كلينتك ، الطاقة، بيئة، شمسي، إدارة المخلفات. الوصول هنا.
- أفلاطون هيلث. التكنولوجيا الحيوية وذكاء التجارب السريرية. الوصول هنا.
- المصدر https://aws.amazon.com/blogs/big-data/preprocess-and-fine-tune-llms-quickly-and-cost-effectively-using-amazon-emr-serverless-and-amazon-sagemaker/

