النماذج الأساسية (FMs) هي نماذج كبيرة للتعلم الآلي (ML) تم تدريبها على مجموعة واسعة من مجموعات البيانات غير المسماة والمعممة. توفر FMs، كما يوحي الاسم، الأساس لبناء تطبيقات أكثر تخصصًا في المراحل النهائية، وهي فريدة من نوعها في قدرتها على التكيف. يمكنهم أداء مجموعة واسعة من المهام المختلفة، مثل معالجة اللغة الطبيعية، وتصنيف الصور، والتنبؤ بالاتجاهات، وتحليل المشاعر، والإجابة على الأسئلة. هذا النطاق والقدرة على التكيف للأغراض العامة هما ما يجعل FMs مختلفًا عن نماذج التعلم الآلي التقليدية. FMs متعددة الوسائط. يعملون مع أنواع مختلفة من البيانات مثل النص والفيديو والصوت والصور. تعد نماذج اللغات الكبيرة (LLMs) نوعًا من FM ويتم تدريبها مسبقًا على كميات هائلة من البيانات النصية وعادةً ما يكون لها استخدامات تطبيقية مثل إنشاء النص أو روبوتات الدردشة الذكية أو التلخيص.
يسهل تدفق البيانات التدفق المستمر للمعلومات المتنوعة والحديثة، مما يعزز قدرة النماذج على التكيف وإنشاء مخرجات أكثر دقة وذات صلة بالسياق. يتيح هذا التكامل الديناميكي لتدفق البيانات الذكاء الاصطناعي التوليدي التطبيقات للاستجابة السريعة للظروف المتغيرة، وتحسين قدرتها على التكيف والأداء العام في مختلف المهام.
لفهم ذلك بشكل أفضل، تخيل روبوت الدردشة الذي يساعد المسافرين في حجز رحلاتهم. في هذا السيناريو، يحتاج برنامج الدردشة الآلي إلى الوصول في الوقت الفعلي إلى مخزون شركات الطيران وحالة الرحلة ومخزون الفنادق وآخر تغييرات الأسعار والمزيد. تأتي هذه البيانات عادةً من أطراف ثالثة، ويحتاج المطورون إلى إيجاد طريقة لاستيعاب هذه البيانات ومعالجة تغييرات البيانات فور حدوثها.
المعالجة المجمعة ليست هي الأفضل في هذا السيناريو. عندما تتغير البيانات بسرعة، قد تؤدي معالجتها دفعة واحدة إلى استخدام بيانات قديمة بواسطة برنامج الدردشة الآلي، مما يوفر معلومات غير دقيقة للعميل، مما يؤثر على تجربة العميل الشاملة. ومع ذلك، يمكن لمعالجة التدفق تمكين برنامج الدردشة الآلي من الوصول إلى البيانات في الوقت الفعلي والتكيف مع التغييرات في التوفر والسعر، مما يوفر أفضل توجيه للعميل ويعزز تجربة العميل.
مثال آخر هو حل المراقبة والمراقبة المعتمد على الذكاء الاصطناعي حيث يقوم مديرو FM بمراقبة المقاييس الداخلية للنظام في الوقت الفعلي وإصدار التنبيهات. عندما يعثر النموذج على قيمة قياس شاذة أو غير طبيعية، يجب أن يصدر تنبيهًا على الفور ويخطر المشغل. ومع ذلك، فإن قيمة هذه البيانات المهمة تتضاءل بشكل كبير مع مرور الوقت. من المفترض أن يتم استلام هذه الإشعارات في غضون ثوانٍ أو حتى أثناء حدوثها. إذا تلقى المشغلون هذه الإشعارات بعد دقائق أو ساعات من حدوثها، فلن تكون هذه المعرفة قابلة للتنفيذ ومن المحتمل أن تفقد قيمتها. يمكنك العثور على حالات استخدام مماثلة في صناعات أخرى مثل البيع بالتجزئة وتصنيع السيارات والطاقة والصناعة المالية.
في هذا المنشور، نناقش سبب كون تدفق البيانات عنصرًا حاسمًا في تطبيقات الذكاء الاصطناعي التوليدية نظرًا لطبيعتها في الوقت الفعلي. نناقش قيمة خدمات تدفق بيانات AWS مثل Amazon Managed Streaming لأباتشي كافكا (أمازون MSK) ، الأمازون كينسيس دفق البيانات, خدمة أمازون المُدارة لـ Apache Flinkو أمازون كينسيس داتا فايرهاوس في بناء تطبيقات الذكاء الاصطناعي التوليدية.
التعلم في السياق
يتم تدريب LLMs باستخدام البيانات في الوقت المناسب وليس لديهم القدرة الكامنة على الوصول إلى البيانات الجديدة في وقت الاستدلال. ومع ظهور بيانات جديدة، سيتعين عليك تحسين النموذج أو تدريبه بشكل مستمر. هذه ليست عملية مكلفة فحسب، ولكنها أيضًا محدودة جدًا من الناحية العملية لأن معدل توليد البيانات الجديدة يفوق بكثير سرعة الضبط الدقيق. بالإضافة إلى ذلك، يفتقر حاملو ماجستير إدارة الأعمال إلى الفهم السياقي ويعتمدون فقط على بيانات التدريب الخاصة بهم، وبالتالي يكونون عرضة للهلوسة. وهذا يعني أنه يمكنهم توليد استجابة بطلاقة ومتماسكة وسليمة من الناحية النحوية ولكنها غير صحيحة في الواقع. كما أنها خالية من الملاءمة والتخصيص والسياق.
ومع ذلك، تتمتع LLMs بالقدرة على التعلم من البيانات التي يتلقونها من السياق للاستجابة بشكل أكثر دقة دون تعديل أوزان النموذج. هذا يسمي التعلم في السياق، ويمكن استخدامها لإنتاج إجابات مخصصة أو تقديم استجابة دقيقة في سياق سياسات المؤسسة.
على سبيل المثال، في chatbot، يمكن أن تتعلق أحداث البيانات بمخزون رحلات الطيران والفنادق أو تغيرات الأسعار التي يتم استيعابها باستمرار في محرك تخزين متدفق. علاوة على ذلك، تتم تصفية أحداث البيانات وإثرائها وتحويلها إلى تنسيق قابل للاستهلاك باستخدام معالج الدفق. يتم توفير النتيجة للتطبيق عن طريق الاستعلام عن أحدث لقطة. يتم تحديث اللقطة باستمرار من خلال معالجة الدفق؛ ولذلك، يتم توفير البيانات الحديثة في سياق مطالبة المستخدم بالنموذج. يتيح ذلك للنموذج التكيف مع أحدث التغييرات في السعر والتوافر. يوضح الرسم البياني التالي سير عمل التعلم الأساسي في السياق.
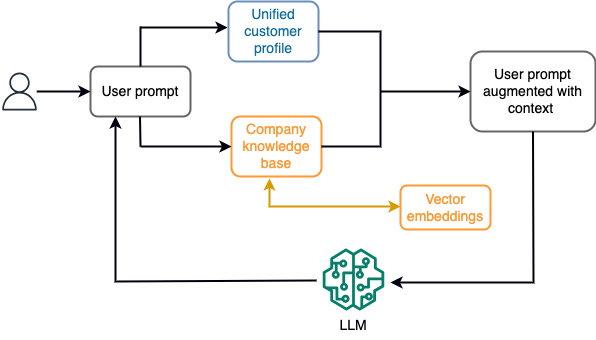
أسلوب التعلم في السياق الشائع الاستخدام هو استخدام تقنية تسمى "الجيل المعزز للاسترجاع" (RAG). في RAG، يمكنك تقديم المعلومات ذات الصلة مثل السياسات الأكثر صلة وسجلات العملاء بالإضافة إلى سؤال المستخدم إلى الموجه. بهذه الطريقة، يقوم LLM بإنشاء إجابة لسؤال المستخدم باستخدام المعلومات الإضافية المقدمة كسياق. لمعرفة المزيد عن RAG، راجع الإجابة على الأسئلة باستخدام Retrieval Augmented Generation مع نماذج الأساس في Amazon SageMaker JumpStart.
يمكن لتطبيق الذكاء الاصطناعي التوليدي القائم على RAG أن ينتج فقط استجابات عامة بناءً على بيانات التدريب الخاصة به والوثائق ذات الصلة في قاعدة المعرفة. لا يكون هذا الحل كافيًا عند توقع استجابة شخصية في الوقت الفعلي تقريبًا من التطبيق. على سبيل المثال، من المتوقع أن يأخذ برنامج الدردشة الآلي للسفر في الاعتبار الحجوزات الحالية للمستخدم، ومخزون الفنادق ورحلات الطيران المتوفرة، والمزيد. علاوة على ذلك، فإن البيانات الشخصية للعملاء ذات الصلة (المعروفة باسم ملف تعريف العميل الموحد) عادة ما يكون عرضة للتغيير. إذا تم استخدام عملية مجمعة لتحديث قاعدة بيانات ملف تعريف مستخدم الذكاء الاصطناعي التوليدي، فقد يتلقى العميل ردودًا غير مرضية بناءً على البيانات القديمة.
في هذا المنشور، نناقش تطبيق معالجة التدفق لتعزيز حل RAG المستخدم لبناء وكلاء الإجابة على الأسئلة مع سياق بدءًا من الوصول في الوقت الفعلي إلى ملفات تعريف العملاء الموحدة وقاعدة المعرفة التنظيمية.
تحديثات ملف تعريف العميل في الوقت الفعلي تقريبًا
يتم عادةً توزيع سجلات العملاء عبر مخازن البيانات داخل المؤسسة. لكي يتمكن تطبيق الذكاء الاصطناعي التوليدي الخاص بك من توفير ملف تعريف عميل ذي صلة ودقيق وحديث، فمن الضروري إنشاء خطوط أنابيب بيانات متدفقة يمكنها تنفيذ تحليل الهوية وتجميع ملف التعريف عبر مخازن البيانات الموزعة. تستوعب وظائف البث باستمرار بيانات جديدة لمزامنتها عبر الأنظمة ويمكنها إجراء الإثراء والتحويلات والصلات والتجميعات عبر النوافذ الزمنية بشكل أكثر كفاءة. تحتوي أحداث التقاط بيانات التغيير (CDC) على معلومات حول السجل المصدر والتحديثات وبيانات التعريف مثل الوقت والمصدر والتصنيف (إدراج أو تحديث أو حذف) وبادئ التغيير.
يوضح الرسم التخطيطي التالي مثالاً لسير العمل لاستيعاب تدفق CDC ومعالجته لملفات تعريف العملاء الموحدة.

في هذا القسم، نناقش المكونات الرئيسية لنمط تدفق CDC المطلوب لدعم تطبيقات الذكاء الاصطناعي التوليدية المستندة إلى RAG.
استيعاب تدفق CDC
النسخ المتماثل لـ CDC هو عملية تجمع تغييرات البيانات من نظام مصدر (عادةً عن طريق قراءة سجلات المعاملات أو السجلات الثنائية) وتكتب أحداث CDC بنفس الترتيب الذي حدثت فيه في دفق البيانات أو الموضوع. يتضمن ذلك التقاطًا قائمًا على السجل باستخدام أدوات مثل خدمة ترحيل قاعدة بيانات AWS (AWS DMS) أو موصلات مفتوحة المصدر مثل Debezium للاتصال بـ Apache Kafka. يعد Apache Kafka Connect جزءًا من بيئة Apache Kafka، مما يسمح باستيعاب البيانات من مصادر مختلفة وتسليمها إلى مجموعة متنوعة من الوجهات. يمكنك تشغيل موصل Apache Kafka الخاص بك اتصال أمازون MSK في غضون دقائق دون القلق بشأن التكوين والإعداد وتشغيل مجموعة Apache Kafka. ما عليك سوى تحميل التعليمات البرمجية المجمعة للموصل الخاص بك إلى خدمة تخزين أمازون البسيطة (Amazon S3) وقم بإعداد الموصل الخاص بك باستخدام التكوين المحدد لحمل العمل الخاص بك.
هناك أيضًا طرق أخرى لالتقاط تغييرات البيانات. على سبيل المثال، الأمازون DynamoDB يوفر ميزة لتدفق بيانات مراكز السيطرة على الأمراض (CDC) إلى تدفقات أمازون DynamoDB أو تدفقات بيانات Kinesis. يوفر Amazon S3 مشغلًا لاستدعاء AWS لامدا تعمل عند تخزين مستند جديد.
تخزين التدفق
يعمل تخزين الدفق كمخزن مؤقت وسيط لتخزين أحداث CDC قبل معالجتها. يوفر تخزين البث تخزينًا موثوقًا لبيانات التدفق. حسب التصميم، فهو متاح بدرجة عالية ومرن في حالة فشل الأجهزة أو العقد ويحافظ على ترتيب الأحداث كما هي مكتوبة. يمكن للتخزين المتدفق تخزين أحداث البيانات إما بشكل دائم أو لفترة زمنية محددة. يسمح هذا لمعالجات الدفق بالقراءة من جزء من الدفق في حالة حدوث فشل أو الحاجة إلى إعادة المعالجة. Kinesis Data Streams هي خدمة تدفق بيانات بدون خادم تجعل من السهل التقاط تدفقات البيانات ومعالجتها وتخزينها على نطاق واسع. Amazon MSK هي خدمة مُدارة بالكامل ومتاحة بدرجة عالية وآمنة تقدمها AWS لتشغيل Apache Kafka.
معالجة التدفق
يجب تصميم أنظمة معالجة التدفق للتوازي للتعامل مع إنتاجية البيانات العالية. يجب عليهم تقسيم دفق الإدخال بين المهام المتعددة التي تعمل على عقد حسابية متعددة. يجب أن تكون المهام قادرة على إرسال نتيجة عملية واحدة إلى العملية التالية عبر الشبكة، مما يجعل من الممكن معالجة البيانات بالتوازي أثناء تنفيذ عمليات مثل الانضمام والتصفية والإثراء والتجميع. يجب أن تكون تطبيقات معالجة التدفق قادرة على معالجة الأحداث فيما يتعلق بوقت الحدث لحالات الاستخدام حيث يمكن أن تصل الأحداث متأخرة أو يعتمد الحساب الصحيح على وقت وقوع الأحداث بدلاً من وقت النظام. لمزيد من المعلومات، راجع مفاهيم الوقت: وقت الحدث ووقت المعالجة.
تُنتج عمليات التدفق نتائج بشكل مستمر في شكل أحداث بيانات يجب إخراجها إلى النظام المستهدف. يمكن أن يكون النظام المستهدف هو أي نظام يمكنه التكامل مباشرة مع العملية أو عبر التخزين المتدفق كما هو الحال في الوسيط. اعتمادًا على إطار العمل الذي تختاره لمعالجة التدفق، سيكون لديك خيارات مختلفة للأنظمة المستهدفة اعتمادًا على موصلات الحوض المتوفرة. إذا قررت كتابة النتائج إلى وحدة تخزين متدفقة وسيطة، فيمكنك إنشاء عملية منفصلة تقرأ الأحداث وتطبق التغييرات على النظام المستهدف، مثل تشغيل موصل حوض Apache Kafka. بغض النظر عن الخيار الذي تختاره، تحتاج بيانات مركز السيطرة على الأمراض إلى معالجة إضافية نظرًا لطبيعتها. نظرًا لأن أحداث CDC تحمل معلومات حول التحديثات أو عمليات الحذف، فمن المهم دمجها في النظام المستهدف بالترتيب الصحيح. إذا تم تطبيق التغييرات بالترتيب الخاطئ، فسيكون النظام المستهدف غير متزامن مع مصدره.
اباتشي فلينك هو إطار عمل قوي لمعالجة التدفق معروف بزمن الاستجابة المنخفض وقدرات الإنتاجية العالية. وهو يدعم معالجة وقت الحدث، ودلالات المعالجة لمرة واحدة بالضبط، والتسامح العالي مع الأخطاء. بالإضافة إلى ذلك، فهو يوفر دعمًا أصليًا لبيانات مراكز السيطرة على الأمراض (CDC) عبر بنية خاصة تسمى الجداول الديناميكية. تحاكي الجداول الديناميكية جداول قاعدة البيانات المصدر وتوفر تمثيلاً عموديًا لبيانات التدفق. تتغير البيانات الموجودة في الجداول الديناميكية مع كل حدث تتم معالجته. يمكن إلحاق السجلات الجديدة أو تحديثها أو حذفها في أي وقت. تقوم الجداول الديناميكية بتجريد المنطق الإضافي الذي تحتاج إلى تنفيذه لكل عملية سجل (إدراج، تحديث، حذف) بشكل منفصل. لمزيد من المعلومات، راجع الجداول الديناميكية.
بدافع خدمة أمازون المُدارة لـ Apache Flink، يمكنك تشغيل وظائف Apache Flink والتكامل مع خدمات AWS الأخرى. لا توجد خوادم ومجموعات لإدارتها، ولا توجد بنية أساسية للحوسبة والتخزين لإعدادها.
غراء AWS هي خدمة استخراج وتحويل وتحميل (ETL) مُدارة بالكامل، مما يعني أن AWS تتولى توفير البنية التحتية وتوسيع نطاقها وصيانتها نيابةً عنك. على الرغم من أنه معروف في المقام الأول بقدرات ETL، إلا أنه يمكن استخدام AWS Glue أيضًا لتطبيقات تدفق Spark. يمكن أن يتفاعل AWS Glue مع خدمات تدفق البيانات مثل Kinesis Data Streams وAmazon MSK لمعالجة بيانات CDC وتحويلها. يمكن أيضًا أن يتكامل AWS Glue بسلاسة مع خدمات AWS الأخرى مثل Lambda، وظائف خطوة AWSوDynamoDB، مما يوفر لك نظامًا بيئيًا شاملاً لبناء وإدارة مسارات معالجة البيانات.
ملف تعريف العميل الموحد
يتطلب التغلب على توحيد ملف تعريف العميل عبر مجموعة متنوعة من أنظمة المصدر تطوير خطوط بيانات قوية. أنت بحاجة إلى خطوط أنابيب بيانات يمكنها جلب جميع السجلات ومزامنتها في مخزن بيانات واحد. يوفر مخزن البيانات هذا لمؤسستك عرضًا شاملاً لسجلات العملاء اللازمة لتحقيق الكفاءة التشغيلية لتطبيقات الذكاء الاصطناعي التوليدية المستندة إلى RAG. لبناء مخزن البيانات هذا، سيكون مخزن البيانات غير المنظم هو الأفضل.
يعد الرسم البياني للهوية بنية مفيدة لإنشاء ملف تعريف موحد للعميل لأنه يدمج ويدمج بيانات العميل من مصادر مختلفة، ويضمن دقة البيانات وإلغاء البيانات المكررة، ويقدم تحديثات في الوقت الفعلي، ويربط الرؤى عبر الأنظمة، ويتيح التخصيص، ويعزز تجربة العملاء، و يدعم الامتثال التنظيمي. يعمل ملف تعريف العميل الموحد هذا على تمكين تطبيق الذكاء الاصطناعي التوليدي من فهم العملاء والتفاعل معهم بشكل فعال، والالتزام بلوائح خصوصية البيانات، مما يؤدي في النهاية إلى تعزيز تجارب العملاء ودفع نمو الأعمال. يمكنك بناء حل الرسم البياني للهوية الخاص بك باستخدام أمازون نبتون، خدمة قاعدة بيانات رسومية سريعة وموثوقة ومُدارة بالكامل.
توفر AWS عددًا قليلًا من عروض خدمات تخزين NoSQL المُدارة وبدون خادم للكائنات ذات القيمة الأساسية غير المنظمة. أمازون دوكومنت دي بي (مع التوافق مع MongoDB) هي مؤسسة سريعة وقابلة للتطوير ومتاحة للغاية ومُدارة بالكامل قاعدة بيانات الوثيقة الخدمة التي تدعم أحمال عمل JSON الأصلية. DynamoDB هي خدمة قاعدة بيانات NoSQL مُدارة بالكامل وتوفر أداءً سريعًا ويمكن التنبؤ به مع قابلية التوسع بسلاسة.
تحديثات قاعدة المعرفة التنظيمية في الوقت الفعلي تقريبًا
على غرار سجلات العملاء، يتم عزل مستودعات المعرفة الداخلية مثل سياسات الشركة والمستندات التنظيمية عبر أنظمة التخزين. عادةً ما تكون هذه بيانات غير منظمة ويتم تحديثها بطريقة غير تدريجية. يعد استخدام البيانات غير المنظمة لتطبيقات الذكاء الاصطناعي فعالاً باستخدام التضمين المتجه، وهي تقنية لتمثيل البيانات عالية الأبعاد مثل الملفات النصية والصور والملفات الصوتية كأرقام رقمية متعددة الأبعاد.
توفر AWS عدة خدمات محرك ناقلات، مثل أمازون أوبن سيرش سيرفرليس, أمازون كندراو إصدار متوافق مع Amazon Aurora PostgreSQL مع ملحق pgvector لتخزين تضمينات المتجهات. يمكن لتطبيقات الذكاء الاصطناعي التوليدية تحسين تجربة المستخدم عن طريق تحويل موجه المستخدم إلى ناقل واستخدامه للاستعلام عن محرك المتجه لاسترداد المعلومات ذات الصلة بالسياق. يتم بعد ذلك تمرير كل من بيانات الموجه والمتجه المستردة إلى LLM لتلقي استجابة أكثر دقة وتخصيصًا.
يوضح الرسم البياني التالي مثالاً لسير عمل معالجة التدفق لتضمينات المتجهات.
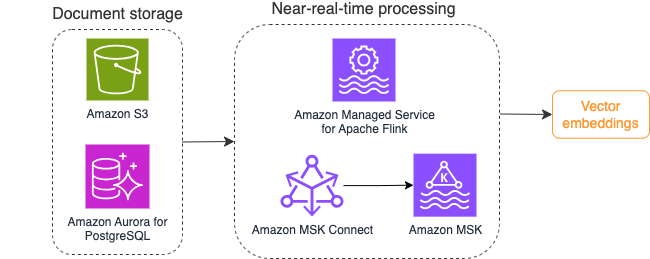
يجب تحويل محتويات قاعدة المعرفة إلى تضمينات متجهة قبل كتابتها إلى مخزن بيانات المتجهات. أمازون بيدروك or الأمازون SageMaker يمكن أن تساعدك في الوصول إلى النموذج الذي تختاره وكشف نقطة نهاية خاصة لهذا التحويل. علاوة على ذلك، يمكنك استخدام مكتبات مثل LangChain للتكامل مع نقاط النهاية هذه. يمكن أن يساعدك إنشاء عملية مجمعة في تحويل محتوى قاعدة المعرفة الخاصة بك إلى بيانات متجهة وتخزينها في قاعدة بيانات متجهة في البداية. ومع ذلك، تحتاج إلى الاعتماد على فاصل زمني لإعادة معالجة المستندات لمزامنة قاعدة بيانات المتجهات الخاصة بك مع التغييرات في محتوى قاعدة المعرفة الخاصة بك. مع وجود عدد كبير من المستندات، قد تكون هذه العملية غير فعالة. بين هذه الفواصل الزمنية، سيتلقى مستخدمو تطبيق الذكاء الاصطناعي التوليدي لديك إجابات وفقًا للمحتوى القديم، أو سيتلقون إجابة غير دقيقة لأن المحتوى الجديد لم يتم توجيهه بعد.
تعد معالجة التدفق حلاً مثاليًا لهذه التحديات. يقوم بإنتاج الأحداث وفقًا للمستندات الموجودة في البداية ويراقب النظام المصدر وينشئ حدث تغيير المستند بمجرد حدوثه. يمكن تخزين هذه الأحداث في مخزن البث وانتظار معالجتها بواسطة مهمة البث. تقوم مهمة الدفق بقراءة هذه الأحداث، وتحميل محتوى المستند، وتحويل المحتويات إلى مجموعة من الرموز المميزة للكلمات ذات الصلة. يتحول كل رمز مميز أيضًا إلى بيانات متجهة عبر استدعاء واجهة برمجة التطبيقات (API) إلى FM المضمن. يتم إرسال النتائج للتخزين إلى مخزن المتجهات عبر مشغل الحوض.
إذا كنت تستخدم Amazon S3 لتخزين مستنداتك، فيمكنك إنشاء بنية مصدر حدث استنادًا إلى مشغلات تغيير كائن S3 لـ Lambda. يمكن لوظيفة Lambda إنشاء حدث بالتنسيق المطلوب وكتابته على وحدة تخزين البث لديك.
يمكنك أيضًا استخدام Apache Flink للتشغيل كمهمة دفق. يوفر Apache Flink موصل مصدر FileSystem الأصلي، والذي يمكنه اكتشاف الملفات الموجودة وقراءة محتوياتها في البداية. بعد ذلك، يمكنه مراقبة نظام الملفات الخاص بك بشكل مستمر بحثًا عن الملفات الجديدة والتقاط محتواها. يدعم الموصل قراءة مجموعة من الملفات من أنظمة الملفات الموزعة مثل Amazon S3 أو HDFS بتنسيق نص عادي، وAvro، وCSV، وParquet، والمزيد، وينتج سجلًا متدفقًا. باعتبارها خدمة مُدارة بالكامل، تعمل الخدمة المُدارة لـ Apache Flink على إزالة الحمل التشغيلي لنشر وظائف Flink وصيانتها، مما يسمح لك بالتركيز على إنشاء تطبيقات البث وتوسيع نطاقها. من خلال التكامل السلس مع خدمات البث AWS مثل Amazon MSK أو Kinesis Data Streams، فإنه يوفر ميزات مثل القياس التلقائي والأمان والمرونة، مما يوفر تطبيقات Flink موثوقة وفعالة للتعامل مع بيانات البث في الوقت الفعلي.
بناءً على تفضيلات DevOps الخاصة بك، يمكنك الاختيار بين Kinesis Data Streams أو Amazon MSK لتخزين سجلات التدفق. يعمل Kinesis Data Streams على تبسيط تعقيدات إنشاء وإدارة تطبيقات البيانات المتدفقة المخصصة، مما يسمح لك بالتركيز على استخلاص الرؤى من بياناتك بدلاً من صيانة البنية التحتية. غالبًا ما يختار العملاء الذين يستخدمون Apache Kafka Amazon MSK نظرًا لبساطته وقابلية التوسع والاعتمادية في الإشراف على مجموعات Apache Kafka داخل بيئة AWS. باعتبارها خدمة مُدارة بالكامل، تواجه Amazon MSK التعقيدات التشغيلية المرتبطة بنشر مجموعات Apache Kafka وصيانتها، مما يتيح لك التركيز على إنشاء تطبيقات البث وتوسيعها.
نظرًا لأن تكامل RESTful API يناسب طبيعة هذه العملية، فأنت بحاجة إلى إطار عمل يدعم نمط الإثراء ذو الحالة عبر استدعاءات RESTful API لتتبع حالات الفشل وإعادة محاولة الطلب الفاشل. Apache Flink مرة أخرى هو إطار عمل يمكنه إجراء عمليات ذات حالة بسرعة الذاكرة. لفهم أفضل الطرق لإجراء مكالمات API عبر Apache Flink، راجع أنماط إثراء البيانات المتدفقة الشائعة في Amazon Kinesis Data Analytics لـ Apache Flink.
يوفر Apache Flink موصلات حوض أصلية لكتابة البيانات إلى مخازن البيانات المتجهة مثل Amazon Aurora لـ PostgreSQL مع pgvector أو خدمة Amazon OpenSearch مع VectorDB. وبدلاً من ذلك، يمكنك تنظيم مخرجات مهمة Flink (البيانات الموجهة) في موضوع MSK أو دفق بيانات Kinesis. توفر خدمة OpenSearch الدعم لللاستيعاب الأصلي من تدفقات بيانات Kinesis أو موضوعات MSK. لمزيد من المعلومات، راجع تقديم Amazon MSK كمصدر لـ Amazon OpenSearch Ingestion و تحميل البيانات المتدفقة من Amazon Kinesis Data Streams.
تحليلات ردود الفعل والضبط الدقيق
من المهم لمديري عمليات البيانات ومطوري الذكاء الاصطناعي/تعلم الآلة الحصول على نظرة ثاقبة حول أداء تطبيق الذكاء الاصطناعي التوليدي وFMs المستخدمة. ولتحقيق ذلك، تحتاج إلى إنشاء خطوط بيانات تحسب بيانات مؤشر الأداء الرئيسي (KPI) المهمة استنادًا إلى تعليقات المستخدمين ومجموعة متنوعة من سجلات ومقاييس التطبيق. تعد هذه المعلومات مفيدة لأصحاب المصلحة للحصول على معلومات ثاقبة في الوقت الفعلي حول أداء FM والتطبيق ورضا المستخدمين بشكل عام حول جودة الدعم الذي يتلقونه من تطبيقك. تحتاج أيضًا إلى جمع سجل المحادثة وتخزينه لمزيد من الضبط الدقيق لأعضاء FM لديك لتحسين قدرتهم على أداء المهام الخاصة بالمجال.
تتناسب حالة الاستخدام هذه جيدًا مع مجال تحليلات التدفق. يجب أن يقوم تطبيقك بتخزين كل محادثة في وحدة التخزين المتدفقة. يمكن لتطبيقك أن يطالب المستخدمين بتقييمهم لدقة كل إجابة ورضاهم العام. يمكن أن تكون هذه البيانات بتنسيق خيار ثنائي أو نص حر. يمكن تخزين هذه البيانات في دفق بيانات Kinesis أو موضوع MSK، وتتم معالجتها لإنشاء مؤشرات الأداء الرئيسية في الوقت الفعلي. يمكنك تشغيل FMs على تحليل مشاعر المستخدمين. يمكن لـ FMs تحليل كل إجابة وتعيين فئة رضا المستخدم.
تسمح بنية Apache Flink بتجميع البيانات المعقدة عبر نوافذ زمنية. كما يوفر أيضًا دعمًا لاستعلام SQL عبر تدفق أحداث البيانات. لذلك، باستخدام Apache Flink، يمكنك تحليل مدخلات المستخدم الأولية بسرعة وإنشاء مؤشرات الأداء الرئيسية في الوقت الفعلي عن طريق كتابة استعلامات SQL مألوفة. لمزيد من المعلومات، راجع واجهة برمجة تطبيقات الجدول وSQL.
بدافع خدمة أمازون المُدارة لـ Apache Flink Studio، يمكنك إنشاء تطبيقات معالجة التدفق Apache Flink وتشغيلها باستخدام SQL وPython وScala القياسية في دفتر ملاحظات تفاعلي. يتم تشغيل أجهزة الكمبيوتر المحمولة في الاستوديو بواسطة Apache Zeppelin وتستخدم Apache Flink كمحرك معالجة التدفق. تجمع دفاتر ملاحظات الاستوديو بين هذه التقنيات بسلاسة لجعل التحليلات المتقدمة حول تدفقات البيانات في متناول المطورين من جميع مجموعات المهارات. من خلال دعم الوظائف المحددة من قبل المستخدم (UDFs)، يسمح Apache Flink ببناء عوامل تشغيل مخصصة للتكامل مع الموارد الخارجية مثل FMs لأداء مهام معقدة مثل تحليل المشاعر. يمكنك استخدام UDFs لحساب مقاييس مختلفة أو إثراء البيانات الأولية لتعليقات المستخدمين برؤى إضافية مثل مشاعر المستخدم. لمعرفة المزيد عن هذا النمط، راجع معالجة مخاوف العملاء بشكل استباقي في الوقت الفعلي باستخدام GenAI وFlink وApache Kafka وKinesis.
باستخدام الخدمة المُدارة لـ Apache Flink Studio، يمكنك نشر دفتر ملاحظات Studio الخاص بك كمهمة بث بنقرة واحدة. يمكنك استخدام موصلات الحوض الأصلية التي يوفرها Apache Flink لإرسال المخرجات إلى وحدة التخزين التي تختارها أو تنظيمها في دفق بيانات Kinesis أو موضوع MSK. الأمازون الأحمر وخدمة OpenSearch كلاهما مثاليان لتخزين البيانات التحليلية. يوفر كلا المحركين دعم الاستيعاب الأصلي من Kinesis Data Streams وAmazon MSK عبر خط تدفق منفصل إلى بحيرة البيانات أو مستودع البيانات للتحليل.
يستخدم Amazon Redshift لغة SQL لتحليل البيانات المنظمة وشبه المنظمة عبر مستودعات البيانات وبحيرات البيانات، باستخدام الأجهزة المصممة من قبل AWS والتعلم الآلي لتقديم أفضل أداء من حيث السعر على نطاق واسع. توفر خدمة OpenSearch إمكانات التصور التي تدعمها لوحات معلومات OpenSearch وKibana (الإصدارات 1.5 إلى 7.10).
يمكنك استخدام نتائج هذا التحليل مع بيانات موجه المستخدم لضبط FM عند الحاجة. SageMaker هي الطريقة الأكثر مباشرة لضبط أجهزة FM الخاصة بك. يوفر استخدام Amazon S3 مع SageMaker تكاملاً قويًا وسلسًا لتحسين نماذجك. يُعد Amazon S3 حلاً متينًا وقابلاً للتطوير لتخزين العناصر، مما يتيح تخزين واسترجاع مجموعات البيانات الكبيرة وبيانات التدريب والعناصر النموذجية بشكل مباشر. SageMaker هي خدمة ML مُدارة بالكامل تعمل على تبسيط دورة حياة ML بأكملها. باستخدام Amazon S3 كواجهة تخزين خلفية لـ SageMaker، يمكنك الاستفادة من قابلية التوسع والموثوقية والفعالية من حيث التكلفة لـ Amazon S3، مع دمجها بسلاسة مع إمكانات التدريب والنشر في SageMaker. يتيح هذا المزيج إدارة البيانات بكفاءة، ويسهل تطوير النماذج التعاونية، ويتأكد من تبسيط سير عمل تعلم الآلة وقابليته للتطوير، مما يؤدي في النهاية إلى تعزيز المرونة والأداء الشامل لعملية تعلم الآلة. لمزيد من المعلومات، راجع قم بضبط Falcon 7B وغيره من برامج LLM على Amazon SageMaker باستخدام @remote Decorator.
باستخدام موصل حوض نظام الملفات، يمكن لوظائف Apache Flink تسليم البيانات إلى Amazon S3 بتنسيق مفتوح (مثل JSON وAvro وParquet والمزيد) ككائنات بيانات. إذا كنت تفضل إدارة بحيرة البيانات الخاصة بك باستخدام إطار عمل بحيرة بيانات المعاملات (مثل Apache Hudi أو Apache Iceberg أو Delta Lake)، فإن كل هذه الأطر توفر موصلًا مخصصًا لـ Apache Flink. لمزيد من التفاصيل، راجع إنشاء خط أنابيب من مصدر إلى بيانات بزمن انتقال منخفض باستخدام Amazon MSK Connect و Apache Flink و Apache Hudi.
نبذة عامة
بالنسبة لتطبيق ذكاء اصطناعي توليدي يعتمد على نموذج RAG، تحتاج إلى التفكير في بناء نظامين لتخزين البيانات، وتحتاج إلى إنشاء عمليات بيانات تجعلها محدثة مع جميع الأنظمة المصدر. لا تكفي المهام المجمعة التقليدية لمعالجة حجم وتنوع البيانات التي تحتاجها للتكامل مع تطبيق الذكاء الاصطناعي التوليدي الخاص بك. يؤدي التأخير في معالجة التغييرات في أنظمة المصدر إلى استجابة غير دقيقة ويقلل من كفاءة تطبيق الذكاء الاصطناعي التوليدي الخاص بك. يمكّنك تدفق البيانات من استيعاب البيانات من مجموعة متنوعة من قواعد البيانات عبر أنظمة مختلفة. كما يسمح لك بتحويل البيانات وإثرائها والانضمام إليها وتجميعها عبر العديد من المصادر بكفاءة في الوقت الفعلي تقريبًا. يوفر تدفق البيانات بنية بيانات مبسطة لجمع وتحويل ردود أفعال المستخدمين أو تعليقاتهم في الوقت الفعلي على استجابات التطبيق، مما يساعدك على تسليم النتائج وتخزينها في بحيرة بيانات لضبط النموذج بشكل دقيق. يساعدك تدفق البيانات أيضًا على تحسين مسارات البيانات من خلال معالجة أحداث التغيير فقط، مما يسمح لك بالاستجابة لتغييرات البيانات بسرعة وكفاءة أكبر.
معرفة المزيد عن خدمات تدفق البيانات من AWS وابدأ في إنشاء حل تدفق البيانات الخاص بك.
حول المؤلف
 علي العليمي هو مهندس حلول متخصص في البث في AWS. ينصح علي عملاء AWS بأفضل الممارسات المعمارية ويساعدهم على تصميم أنظمة بيانات تحليلات في الوقت الفعلي تكون موثوقة وآمنة وفعالة وفعالة من حيث التكلفة. يعمل بشكل رجعي من حالات استخدام العميل ويصمم حلول البيانات لحل مشاكل أعمالهم. قبل الانضمام إلى AWS ، دعم علي العديد من عملاء القطاع العام وشركاء AWS الاستشاريين في رحلة تحديث التطبيقات الخاصة بهم والانتقال إلى السحابة.
علي العليمي هو مهندس حلول متخصص في البث في AWS. ينصح علي عملاء AWS بأفضل الممارسات المعمارية ويساعدهم على تصميم أنظمة بيانات تحليلات في الوقت الفعلي تكون موثوقة وآمنة وفعالة وفعالة من حيث التكلفة. يعمل بشكل رجعي من حالات استخدام العميل ويصمم حلول البيانات لحل مشاكل أعمالهم. قبل الانضمام إلى AWS ، دعم علي العديد من عملاء القطاع العام وشركاء AWS الاستشاريين في رحلة تحديث التطبيقات الخاصة بهم والانتقال إلى السحابة.
 امتياز (طاز) سيد هي الشركة الرائدة عالميًا في مجال التقنية للتحليلات في AWS. إنه يستمتع بالتفاعل مع المجتمع في كل ما يتعلق بالبيانات والتحليلات. ويمكن الوصول إليه عن طريق لينكدين:.
امتياز (طاز) سيد هي الشركة الرائدة عالميًا في مجال التقنية للتحليلات في AWS. إنه يستمتع بالتفاعل مع المجتمع في كل ما يتعلق بالبيانات والتحليلات. ويمكن الوصول إليه عن طريق لينكدين:.
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- PlatoData.Network Vertical Generative Ai. تمكين نفسك. الوصول هنا.
- أفلاطونايستريم. ذكاء Web3. تضخيم المعرفة. الوصول هنا.
- أفلاطون كربون، كلينتك ، الطاقة، بيئة، شمسي، إدارة المخلفات. الوصول هنا.
- أفلاطون هيلث. التكنولوجيا الحيوية وذكاء التجارب السريرية. الوصول هنا.
- المصدر https://aws.amazon.com/blogs/big-data/exploring-real-time-streaming-for-generative-ai-applications/

