يعد الحصول على إجابات دقيقة ومفيدة من كميات هائلة من النصوص قدرة مثيرة تتيحها نماذج اللغة الكبيرة (LLMs). عند إنشاء تطبيقات LLM، غالبًا ما يكون من الضروري الاتصال بمصادر البيانات الخارجية والاستعلام عنها لتوفير السياق ذي الصلة بالنموذج. أحد الأساليب الشائعة هو استخدام تقنية الاسترجاع المعزز (RAG) لإنشاء أنظمة الأسئلة والأجوبة التي تفهم المعلومات المعقدة وتوفر استجابات طبيعية للاستفسارات. يسمح RAG للنماذج بالاستفادة من قواعد المعرفة الواسعة وتقديم حوار يشبه الإنسان لتطبيقات مثل برامج الدردشة الآلية ومساعدي البحث في المؤسسات.
في هذا المقال، نستكشف كيفية تسخير قوة اللاما, اللاما 2-70B-دردشةو لانجشين لبناء تطبيقات أسئلة وأجوبة قوية. باستخدام هذه التقنيات الحديثة، يمكنك استيعاب مجموعة النصوص وفهرسة المعرفة المهمة وإنشاء نص يجيب على أسئلة المستخدمين بدقة ووضوح.
اللاما 2-70B-دردشة
Llama 2-70B-Chat عبارة عن LLM قوية تتنافس مع العارضات الرائدات. تم تدريبه مسبقًا على تريليوني رمز نصي، وصممته Meta لاستخدامه في مساعدة المستخدمين في الدردشة. يتم الحصول على بيانات ما قبل التدريب من البيانات المتاحة للجمهور وتنتهي اعتبارًا من سبتمبر 2022، وتنتهي بيانات الضبط الدقيق في يوليو 2023. لمزيد من التفاصيل حول عملية تدريب النموذج، واعتبارات السلامة، والتعلم، والاستخدامات المقصودة، راجع الورقة اللاما 2: نماذج الدردشة الأساسية والمضبوطة بشكل دقيق. نماذج Llama 2 متاحة على أمازون سيج ميكر جومب ستارت لنشر سريع ومباشر.
اللاما
اللاما هو إطار بيانات يتيح بناء تطبيقات LLM. فهو يوفر أدوات توفر موصلات بيانات لاستيعاب بياناتك الحالية بمصادر وتنسيقات متنوعة (ملفات PDF، والمستندات، وواجهات برمجة التطبيقات، وSQL، والمزيد). سواء كانت لديك بيانات مخزنة في قواعد بيانات أو في ملفات PDF، فإن LlamaIndex يجعل من السهل استخدام تلك البيانات في LLMs. كما نوضح في هذا المنشور، تجعل واجهات برمجة تطبيقات LlamaIndex الوصول إلى البيانات أمرًا سهلاً وتمكنك من إنشاء تطبيقات LLM وسير عمل مخصصة قوية.
إذا كنت تقوم بالتجربة والبناء باستخدام LLM، فمن المحتمل أنك على دراية بـ LangChain، الذي يوفر إطارًا قويًا، مما يبسط تطوير ونشر التطبيقات التي تدعم LLM. على غرار LangChain، يقدم LlamaIndex عددًا من الأدوات، بما في ذلك موصلات البيانات وفهارس البيانات والمحركات ووكلاء البيانات، بالإضافة إلى تكامل التطبيقات مثل الأدوات وإمكانية المراقبة والتتبع والتقييم. يركز LlamaIndex على سد الفجوة بين البيانات وLLMs القوية، وتبسيط مهام البيانات بميزات سهلة الاستخدام. تم تصميم LlamaIndex وتحسينه خصيصًا لبناء تطبيقات البحث والاسترجاع، مثل RAG، لأنه يوفر واجهة بسيطة للاستعلام عن LLMs واسترداد المستندات ذات الصلة.
حل نظرة عامة
في هذا المنشور، نوضح كيفية إنشاء تطبيق يستند إلى RAG باستخدام LlamaIndex وLLM. يوضح الرسم التخطيطي التالي البنية خطوة بخطوة لهذا الحل الموضحة في الأقسام التالية.
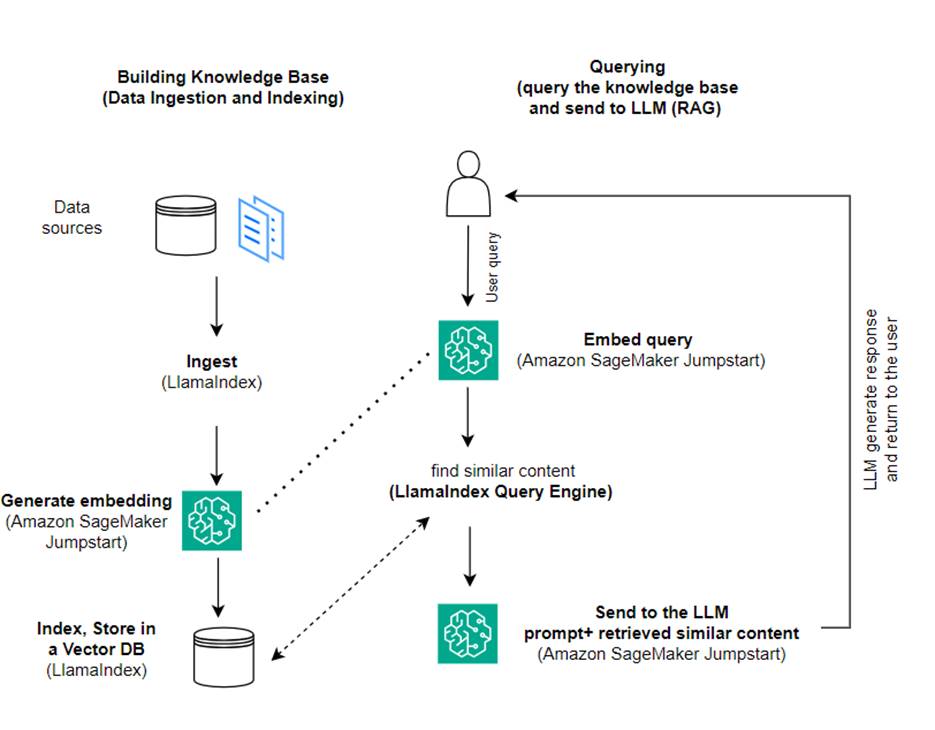
يجمع RAG بين استرجاع المعلومات وتوليد اللغة الطبيعية لإنتاج استجابات أكثر ثاقبة. عندما يُطلب منك ذلك، يقوم RAG أولاً بالبحث في مجموعات النص لاسترداد الأمثلة الأكثر صلة بالإدخال. أثناء إنشاء الاستجابة، يأخذ النموذج في الاعتبار هذه الأمثلة لزيادة قدراته. من خلال دمج المقاطع المسترجعة ذات الصلة، تميل استجابات RAG إلى أن تكون أكثر واقعية وتماسكًا واتساقًا مع السياق مقارنةً بالنماذج التوليدية الأساسية. يستفيد إطار عمل الاسترجاع-الإنشاء هذا من نقاط القوة في كل من الاسترجاع والتوليد، مما يساعد على معالجة مشكلات مثل التكرار ونقص السياق الذي يمكن أن ينشأ من نماذج المحادثة الانحدارية البحتة. تقدم RAG نهجًا فعالاً لبناء وكلاء المحادثة ومساعدي الذكاء الاصطناعي من خلال استجابات سياقية عالية الجودة.
يتكون بناء الحل من الخطوات التالية:
- اقامة أمازون ساجميكر ستوديو كبيئة التطوير وتثبيت التبعيات المطلوبة.
- انشر نموذج التضمين من مركز Amazon SageMaker JumpStart.
- قم بتنزيل البيانات الصحفية لاستخدامها كقاعدة معرفية خارجية لدينا.
- أنشئ فهرسًا من النشرات الصحفية لتتمكن من الاستعلام عنه وإضافته كسياق إضافي للموجه.
- الاستعلام عن قاعدة المعرفة.
- أنشئ تطبيق أسئلة وأجوبة باستخدام وكلاء LlamaIndex وLangChain.
كل الكود الموجود في هذا المنشور متاح في جيثب ريبو.
المتطلبات الأساسية المسبقة
في هذا المثال، تحتاج إلى حساب AWS بنطاق SageMaker ومناسب إدارة الهوية والوصول AWS (IAM) أذونات. للحصول على تعليمات إعداد الحساب، راجع أنشئ حساب AWS. إذا لم يكن لديك مجال SageMaker بالفعل، فارجع إلى مجال أمازون سيج ميكر نظرة عامة لإنشاء واحدة. في هذه التدوينة نستخدم AmazonSageMakerFullAccess دور. من غير المستحسن استخدام بيانات الاعتماد هذه في بيئة إنتاج. بدلاً من ذلك، يجب عليك إنشاء دور واستخدامه بأذونات ذات امتيازات أقل. يمكنك أيضًا استكشاف كيف يمكنك استخدامها مدير دور Amazon SageMaker لبناء وإدارة أدوار IAM المستندة إلى الشخصية لتلبية احتياجات التعلم الآلي الشائعة مباشرةً من خلال وحدة تحكم SageMaker.
بالإضافة إلى ذلك، تحتاج إلى الوصول إلى الحد الأدنى من أحجام المثيلات التالية:
- ml.g5.2xlarge لاستخدام نقطة النهاية عند نشر معانقة الوجه GPT-J نموذج تضمين النص
- ml.g5.48xlarge لاستخدام نقطة النهاية عند نشر نقطة نهاية نموذج Llama 2-Chat
لزيادة حصتك، راجع طلب زيادة الحصة.
انشر نموذج تضمين GPT-J باستخدام SageMaker JumpStart
يمنحك هذا القسم خيارين عند نشر نماذج SageMaker JumpStart. يمكنك استخدام النشر المستند إلى التعليمات البرمجية باستخدام التعليمات البرمجية المتوفرة، أو استخدام واجهة مستخدم SageMaker JumpStart (UI).
النشر باستخدام SageMaker Python SDK
يمكنك استخدام SageMaker Python SDK لنشر LLMs، كما هو موضح في ملف الكود متوفر في المستودع. أكمل الخطوات التالية:
- قم بتعيين حجم المثيل الذي سيتم استخدامه لنشر نموذج التضمين باستخدام
instance_type = "ml.g5.2xlarge" - حدد موقع معرف النموذج الذي سيتم استخدامه للتضمين. في SageMaker JumpStart، يتم تعريفه على أنه
model_id = "huggingface-textembedding-gpt-j-6b-fp16" - قم باسترجاع حاوية النموذج المدربة مسبقًا ونشرها للاستدلال.
سوف يقوم SageMaker بإرجاع اسم نقطة نهاية النموذج والرسالة التالية عند نشر نموذج التضمين بنجاح:
النشر باستخدام SageMaker JumpStart في SageMaker Studio
لنشر النموذج باستخدام SageMaker JumpStart في Studio، أكمل الخطوات التالية:
- في وحدة تحكم SageMaker Studio، اختر JumpStart في جزء التنقل.

- ابحث عن نموذج GPT-J 6B Embedding FP16 واختره.
- اختر نشر وقم بتخصيص تكوين النشر.

- في هذا المثال، نحتاج إلى مثيل ml.g5.2xlarge، وهو المثيل الافتراضي الذي يقترحه SageMaker JumpStart.
- اختر نشر مرة أخرى لإنشاء نقطة النهاية.
ستستغرق نقطة النهاية حوالي 5 إلى 10 دقائق لتكون في الخدمة.

بعد نشر نموذج التضمينات، من أجل استخدام تكامل LangChain مع واجهات برمجة تطبيقات SageMaker، تحتاج إلى إنشاء وظيفة للتعامل مع المدخلات (النص الخام) وتحويلها إلى عمليات التضمين باستخدام النموذج. يمكنك القيام بذلك عن طريق إنشاء فئة تسمى ContentHandler، الذي يأخذ JSON من بيانات الإدخال، ويعيد JSON من تضمينات النص: class ContentHandler(EmbeddingsContentHandler).
قم بتمرير اسم نقطة نهاية النموذج إلى ContentHandler وظيفة لتحويل النص وإرجاع التضمينات:
يمكنك تحديد موقع اسم نقطة النهاية إما في مخرجات SDK أو في تفاصيل النشر في واجهة مستخدم SageMaker JumpStart.
يمكنك اختبار ذلك ContentHandler تعمل الوظيفة ونقطة النهاية كما هو متوقع عن طريق إدخال بعض النصوص الأولية وتشغيل الملف embeddings.embed_query(text) وظيفة. يمكنك استخدام المثال المقدم text = "Hi! It's time for the beach" أو جرب النص الخاص بك.
قم بنشر واختبار Llama 2-Chat باستخدام SageMaker JumpStart
يمكنك الآن نشر النموذج القادر على إجراء محادثات تفاعلية مع المستخدمين. في هذه الحالة، نختار أحد نماذج Llama 2-chat، والتي يتم التعرف عليها عبر
يجب نشر النموذج إلى نقطة نهاية في الوقت الفعلي باستخدام predictor = my_model.deploy(). سيُرجع SageMaker اسم نقطة النهاية للنموذج، والذي يمكنك استخدامه لـ endpoint_name متغير للرجوع إليه لاحقا.
قمت بتعريف أ print_dialogue وظيفة لإرسال المدخلات إلى نموذج الدردشة وتلقي استجابة الإخراج الخاصة به. تتضمن الحمولة معلمات فائقة للنموذج، بما في ذلك ما يلي:
- max_new_tokens - يشير إلى الحد الأقصى لعدد الرموز التي يمكن للنموذج توليدها في مخرجاته.
- top_p - يشير إلى الاحتمالية التراكمية للرموز المميزة التي يمكن للنموذج الاحتفاظ بها عند إنشاء مخرجاته
- درجة الحرارة - يشير إلى عشوائية المخرجات الناتجة عن النموذج. تزيد درجة الحرارة التي تزيد عن 0 أو تساوي 1 من مستوى العشوائية، في حين أن درجة الحرارة 0 ستولد الرموز المميزة الأكثر احتمالًا.
يجب عليك تحديد المعلمات الفائقة الخاصة بك بناءً على حالة الاستخدام الخاصة بك واختبارها بشكل مناسب. تتطلب النماذج مثل عائلة Llama تضمين معلمة إضافية تشير إلى أنك قرأت وقبلت اتفاقية ترخيص المستخدم النهائي (EULA):
لاختبار النموذج، استبدل قسم المحتوى الخاص بحمولة الإدخال: "content": "what is the recipe of mayonnaise?". يمكنك استخدام القيم النصية الخاصة بك وتحديث المعلمات الفائقة لفهمها بشكل أفضل.
على غرار نشر نموذج التضمين، يمكنك نشر Llama-70B-Chat باستخدام واجهة مستخدم SageMaker JumpStart:
- في وحدة تحكم SageMaker Studio ، اختر بداية القفز في جزء التنقل
- ابحث عن واختر ملف
Llama-2-70b-Chat model - اقبل اتفاقية ترخيص المستخدم النهائي واختر نشر، باستخدام المثيل الافتراضي مرة أخرى
على غرار نموذج التضمين، يمكنك استخدام تكامل LangChain عن طريق إنشاء قالب معالج المحتوى للمدخلات والمخرجات لنموذج الدردشة الخاص بك. في هذه الحالة، يمكنك تعريف المدخلات على أنها تلك الواردة من المستخدم، والإشارة إلى أنها تخضع لـ system prompt. system prompt يُعلم النموذج بدوره في مساعدة المستخدم في حالة استخدام معينة.
يتم بعد ذلك تمرير معالج المحتوى هذا عند استدعاء النموذج، بالإضافة إلى المعلمات الفائقة والسمات المخصصة المذكورة أعلاه (قبول اتفاقية ترخيص المستخدم النهائي). يمكنك تحليل كل هذه السمات باستخدام الكود التالي:
عندما تكون نقطة النهاية متاحة، يمكنك اختبار أنها تعمل كما هو متوقع. يمكنك التحديث llm("what is amazon sagemaker?") مع النص الخاص بك. تحتاج أيضًا إلى تحديد المحدد ContentHandler لاستدعاء LLM باستخدام LangChain، كما هو موضح في الكود ومقتطف الكود التالي:
استخدم LlamaIndex لبناء RAG
للمتابعة، قم بتثبيت LlamaIndex لإنشاء تطبيق RAG. يمكنك تثبيت LlamaIndex باستخدام النقطة: pip install llama_index
تحتاج أولاً إلى تحميل بياناتك (قاعدة المعرفة) على LlamaIndex للفهرسة. يتضمن ذلك بضع خطوات:
- اختر أداة تحميل البيانات:
يوفر LlamaIndex عددًا من موصلات البيانات المتوفرة على لاماهاب لأنواع البيانات الشائعة مثل JSON وCSV والملفات النصية، بالإضافة إلى مصادر البيانات الأخرى، مما يسمح لك باستيعاب مجموعة متنوعة من مجموعات البيانات. في هذه التدوينة نستخدم SimpleDirectoryReader لاستيعاب بعض ملفات PDF كما هو موضح في الكود. نموذج البيانات الخاص بنا عبارة عن بيانين صحفيين من Amazon في نسخة PDF في تصريحات صحفيه مجلد في مستودع التعليمات البرمجية لدينا. بعد تحميل ملفات PDF، يمكنك أن ترى أنه تم تحويلها إلى قائمة مكونة من 11 عنصرًا.
بدلاً من تحميل المستندات مباشرةً، يمكنك أيضًا إخفاء الملف Document يعترض عليه Node الكائنات قبل إرسالها إلى الفهرس. الاختيار بين إرسال كامل Document كائن إلى الفهرس أو تحويل المستند إلى Node تعتمد الكائنات قبل الفهرسة على حالة الاستخدام المحددة وبنية بياناتك. يعد أسلوب العقد بشكل عام خيارًا جيدًا للمستندات الطويلة، حيث تريد تقسيم واسترداد أجزاء معينة من المستند بدلاً من المستند بأكمله. لمزيد من المعلومات، راجع الوثائق / العقد.
- قم بإنشاء مثيل للمحمل وتحميل المستندات:
تعمل هذه الخطوة على تهيئة فئة المُحمل وأي تكوين مطلوب، مثل تجاهل الملفات المخفية. لمزيد من التفاصيل، راجع قارئ الدليل البسيط.
- اتصل بالمحمل
load_dataطريقة لتحليل ملفاتك وبياناتك المصدرية وتحويلها إلى كائنات مستند LlamaIndex، جاهزة للفهرسة والاستعلام. يمكنك استخدام الكود التالي لإكمال عملية استيعاب البيانات والتحضير للبحث عن النص الكامل باستخدام إمكانيات الفهرسة والاسترجاع الخاصة بـ LlamaIndex:
- بناء الفهرس:
الميزة الرئيسية لـ LlamaIndex هي قدرته على إنشاء فهارس منظمة على البيانات، والتي يتم تمثيلها كمستندات أو عقد. تسهل الفهرسة الاستعلام الفعال عن البيانات. نقوم بإنشاء فهرسنا باستخدام مخزن المتجهات الافتراضي في الذاكرة وبتكوين الإعداد المحدد لدينا. مؤشر اللاما الإعدادات هو كائن تكوين يوفر موارد وإعدادات شائعة الاستخدام لعمليات الفهرسة والاستعلام في تطبيق LlamaIndex. إنه يعمل ككائن مفرد، بحيث يسمح لك بتعيين التكوينات العامة، بينما يسمح لك أيضًا بتجاوز مكونات محددة محليًا عن طريق تمريرها مباشرة إلى الواجهات (مثل LLMs ونماذج التضمين) التي تستخدمها. عندما لا يتم توفير مكون معين بشكل صريح، يعود إطار عمل LlamaIndex إلى الإعدادات المحددة في ملف Settings كائن كافتراضي عالمي. لاستخدام نماذج التضمين وLLM الخاصة بنا مع LangChain وتكوين Settings نحن بحاجة إلى تثبيت llama_index.embeddings.langchain و llama_index.llms.langchain. يمكننا تكوين Settings الكائن كما في الكود التالي:
افتراضيا، VectorStoreIndex يستخدم في الذاكرة SimpleVectorStore تمت تهيئته كجزء من سياق التخزين الافتراضي. في حالات الاستخدام الواقعية، غالبًا ما تحتاج إلى الاتصال بمخازن المتجهات الخارجية مثل خدمة Amazon OpenSearch. لمزيد من التفاصيل ، يرجى الرجوع إلى محرك المتجهات لـ Amazon OpenSearch Serverless.
يمكنك الآن تشغيل الأسئلة والأجوبة على مستنداتك باستخدام query_engine من لاما إندكس. للقيام بذلك، قم بتمرير الفهرس الذي قمت بإنشائه مسبقًا للاستعلامات واطرح سؤالك. محرك الاستعلام هو واجهة عامة للاستعلام عن البيانات. يأخذ استعلامًا باللغة الطبيعية كمدخل ويعيد استجابة غنية. عادةً ما يتم إنشاء محرك الاستعلام فوق واحد أو أكثر الفهارس استخدام المستردون.
يمكنك أن ترى أن حل RAG قادر على استرداد الإجابة الصحيحة من المستندات المقدمة:
استخدم أدوات ووكلاء LangChain
Loader فصل. تم تصميم المُحمل لتحميل البيانات إلى LlamaIndex أو لاحقًا كأداة في ملف وكيل لانج تشين. يمنحك هذا المزيد من القوة والمرونة لاستخدام هذا كجزء من التطبيق الخاص بك. عليك أن تبدأ بتحديد الخاص بك أداة من فئة وكيل LangChain. تقوم الوظيفة التي تمررها إلى أداتك بالاستعلام عن الفهرس الذي أنشأته على مستنداتك باستخدام LlamaIndex.
ثم تقوم بتحديد النوع الصحيح من الوكيل الذي ترغب في استخدامه لتنفيذ RAG الخاص بك. في هذه الحالة، يمكنك استخدام chat-zero-shot-react-description عامل. باستخدام هذا الوكيل، سيستخدم LLM الأداة المتاحة (في هذا السيناريو، RAG على قاعدة المعرفة) لتقديم الاستجابة. يمكنك بعد ذلك تهيئة الوكيل عن طريق تمرير أداتك وLLM ونوع الوكيل:
تستطيع أن ترى الوكيل يمر thoughts, actionsو observation ، استخدم الأداة (في هذا السيناريو، الاستعلام عن المستندات المفهرسة)؛ وإرجاع النتيجة:
يمكنك العثور على رمز التنفيذ الشامل في المرفق جيثب ريبو.
تنظيف
لتجنب التكاليف غير الضرورية، يمكنك تنظيف مواردك، إما عبر مقتطفات التعليمات البرمجية التالية أو واجهة مستخدم Amazon JumpStart.
لاستخدام Boto3 SDK، استخدم التعليمة البرمجية التالية لحذف نقطة نهاية نموذج تضمين النص ونقطة نهاية نموذج إنشاء النص، بالإضافة إلى تكوينات نقطة النهاية:
لاستخدام وحدة تحكم SageMaker، أكمل الخطوات التالية:
- في وحدة تحكم SageMaker، ضمن الاستدلال في جزء التنقل، اختر نقاط النهاية
- ابحث عن نقاط نهاية التضمين وإنشاء النص.
- في صفحة تفاصيل نقطة النهاية، اختر حذف.
- اختر حذف مرة أخرى للتأكيد.
وفي الختام
بالنسبة لحالات الاستخدام التي تركز على البحث والاسترجاع، يوفر LlamaIndex إمكانات مرنة. إنه يتفوق في الفهرسة والاسترجاع لحاملي LLM، مما يجعله أداة قوية للاستكشاف العميق للبيانات. يمكّنك LlamaIndex من إنشاء فهارس بيانات منظمة، واستخدام LLMs المتنوعة، وزيادة البيانات لتحسين أداء LLM، والاستعلام عن البيانات باللغة الطبيعية.
أظهر هذا المنشور بعض المفاهيم والقدرات الأساسية لـ LlamaIndex. لقد استخدمنا GPT-J للتضمين وLlama 2-Chat باعتباره LLM لإنشاء تطبيق RAG، ولكن يمكنك استخدام أي نموذج مناسب بدلاً من ذلك. يمكنك استكشاف المجموعة الشاملة من النماذج المتوفرة على SageMaker JumpStart.
لقد أظهرنا أيضًا كيف يمكن لـ LlamaIndex توفير أدوات قوية ومرنة للاتصال بالبيانات وفهرستها واسترجاعها ودمجها مع أطر عمل أخرى مثل LangChain. من خلال عمليات تكامل LlamaIndex وLangChain، يمكنك إنشاء تطبيقات LLM أكثر قوة وتنوعًا وثاقبة.
حول المؤلف
 الدكتورة رومينا شريفبور هو أحد كبار مهندسي حلول التعلم الآلي والذكاء الاصطناعي في Amazon Web Services (AWS). لقد أمضت أكثر من 10 سنوات في قيادة تصميم وتنفيذ الحلول المبتكرة الشاملة التي تم تمكينها من خلال التقدم في تعلم الآلة والذكاء الاصطناعي. مجالات اهتمام رومينا هي معالجة اللغة الطبيعية، ونماذج اللغة الكبيرة، وعمليات MLOps.
الدكتورة رومينا شريفبور هو أحد كبار مهندسي حلول التعلم الآلي والذكاء الاصطناعي في Amazon Web Services (AWS). لقد أمضت أكثر من 10 سنوات في قيادة تصميم وتنفيذ الحلول المبتكرة الشاملة التي تم تمكينها من خلال التقدم في تعلم الآلة والذكاء الاصطناعي. مجالات اهتمام رومينا هي معالجة اللغة الطبيعية، ونماذج اللغة الكبيرة، وعمليات MLOps.
 نيكول بينتو هو مهندس حلول متخصص في الذكاء الاصطناعي/تعلم الآلة ومقره في سيدني، أستراليا. خلفيتها في مجال الرعاية الصحية والخدمات المالية تمنحها منظورًا فريدًا في حل مشكلات العملاء. إنها متحمسة لتمكين العملاء من خلال التعلم الآلي وتمكين الجيل القادم من النساء في مجال العلوم والتكنولوجيا والهندسة والرياضيات.
نيكول بينتو هو مهندس حلول متخصص في الذكاء الاصطناعي/تعلم الآلة ومقره في سيدني، أستراليا. خلفيتها في مجال الرعاية الصحية والخدمات المالية تمنحها منظورًا فريدًا في حل مشكلات العملاء. إنها متحمسة لتمكين العملاء من خلال التعلم الآلي وتمكين الجيل القادم من النساء في مجال العلوم والتكنولوجيا والهندسة والرياضيات.
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- PlatoData.Network Vertical Generative Ai. تمكين نفسك. الوصول هنا.
- أفلاطونايستريم. ذكاء Web3. تضخيم المعرفة. الوصول هنا.
- أفلاطون كربون، كلينتك ، الطاقة، بيئة، شمسي، إدارة المخلفات. الوصول هنا.
- أفلاطون هيلث. التكنولوجيا الحيوية وذكاء التجارب السريرية. الوصول هنا.
- المصدر https://aws.amazon.com/blogs/machine-learning/build-knowledge-powered-conversational-applications-using-llamaindex-and-llama-2-chat/

