今天,我們很高興地宣布 Meta 使用以下方法微調 Code Llama 模型的能力: 亞馬遜SageMaker JumpStart。 Code Llama 大型語言模型 (LLM) 系列是預先訓練和微調的程式碼產生模型的集合,其規模從 7 億到 70 億個參數不等。經過微調的 Code Llama 模型比基本 Code Llama 模型提供了更好的準確性和可解釋性,這一點在其針對 人類評估 和 MBPP 資料集。您可以使用 SageMaker JumpStart 微調和部署 Code Llama 模型 亞馬遜SageMaker Studio 只需點擊幾下或使用 SageMaker Python SDK 即可獲得 UI。 Llama 模型的微調是基於中提供的腳本 llama-recipes GitHub 儲存庫 來自 Meta,使用 PyTorch FSDP、PEFT/LoRA 和 Int8 量化技術。
在這篇文章中,我們將介紹如何透過 SageMaker JumpStart 透過一鍵式 UI 和 SDK 體驗來微調 Code Llama 預訓練模型,如下所示 GitHub存儲庫.
什麼是 SageMaker JumpStart
透過 SageMaker JumpStart,機器學習 (ML) 從業者可以從眾多公開可用的基礎模型中進行選擇。機器學習從業者可以將基礎模型部署到專用的 亞馬遜SageMaker 來自網絡隔離環境的實例,並使用 SageMaker 自定義模型進行模型訓練和部署。
什麼是程式碼駱駝
Code Llama 是一個程式碼專用版本 駱駝2 它是透過在其特定於程式碼的資料集上進一步訓練 Llama 2 並從同一資料集中採樣更多資料而創建的。 Code Llama 具有增強的編碼功能。它可以根據程式碼和自然語言提示產生程式碼和有關程式碼的自然語言(例如,「給我寫一個輸出斐波那契數列的函數」)。您也可以使用它來完成程式碼和調試。它支援當今使用的許多最受歡迎的程式語言,包括 Python、C++、Java、PHP、Typescript (JavaScript)、C#、Bash 等。
為什麼要微調 Code Llama 模型
Meta 發布了 Code Llama 效能基準 HumanEval 和 MBPP 適用於 Python、Java 和 JavaScript 等常見編碼語言。 Code Llama Python 模型在 HumanEval 上的效能在不同的編碼語言和任務中表現出不同的效能,範圍從 38B Python 模型上的 7% 到 57B Python 模型上的 70%。此外,在 SQL 程式語言上經過微調的 Code Llama 模型顯示出更好的結果,這一點在 SQL 評估基準中得到了證明。這些發布的基準凸顯了微調 Code Llama 模型的潛在好處,可實現更好的效能、客製化以及適應特定編碼領域和任務。
透過 SageMaker Studio UI 進行無程式碼微調
若要開始使用 SageMaker Studio 微調 Llama 模型,請完成以下步驟:
- 在 SageMaker Studio 控制台上,選擇 快速啟動 在導航窗格中。
您將找到超過 350 個模型的列表,其中包括開源模型和專有模型。
- 搜尋 Code Llama 模型。

如果您沒有看到 Code Llama 模型,您可以透過關閉並重新啟動來更新您的 SageMaker Studio 版本。有關版本更新的更多信息,請參閱 關閉並更新 Studio 應用程序。您也可以透過選擇找到其他型號變體 探索所有程式碼生成模型 或在搜尋框中搜尋 Code Llama。
SageMaker JumpStart 目前支援 Code Llama 模型的指令微調。以下螢幕截圖顯示了 Code Llama 2 70B 模型的微調頁面。
- 為 訓練資料集位置,您可以指向 亞馬遜簡單存儲服務 (Amazon S3) 儲存桶,包含用於微調的訓練和驗證資料集。
- 設定部署配置、超參數和安全性設定以進行微調。
- 選擇 火車 在 SageMaker ML 實例上啟動微調作業。
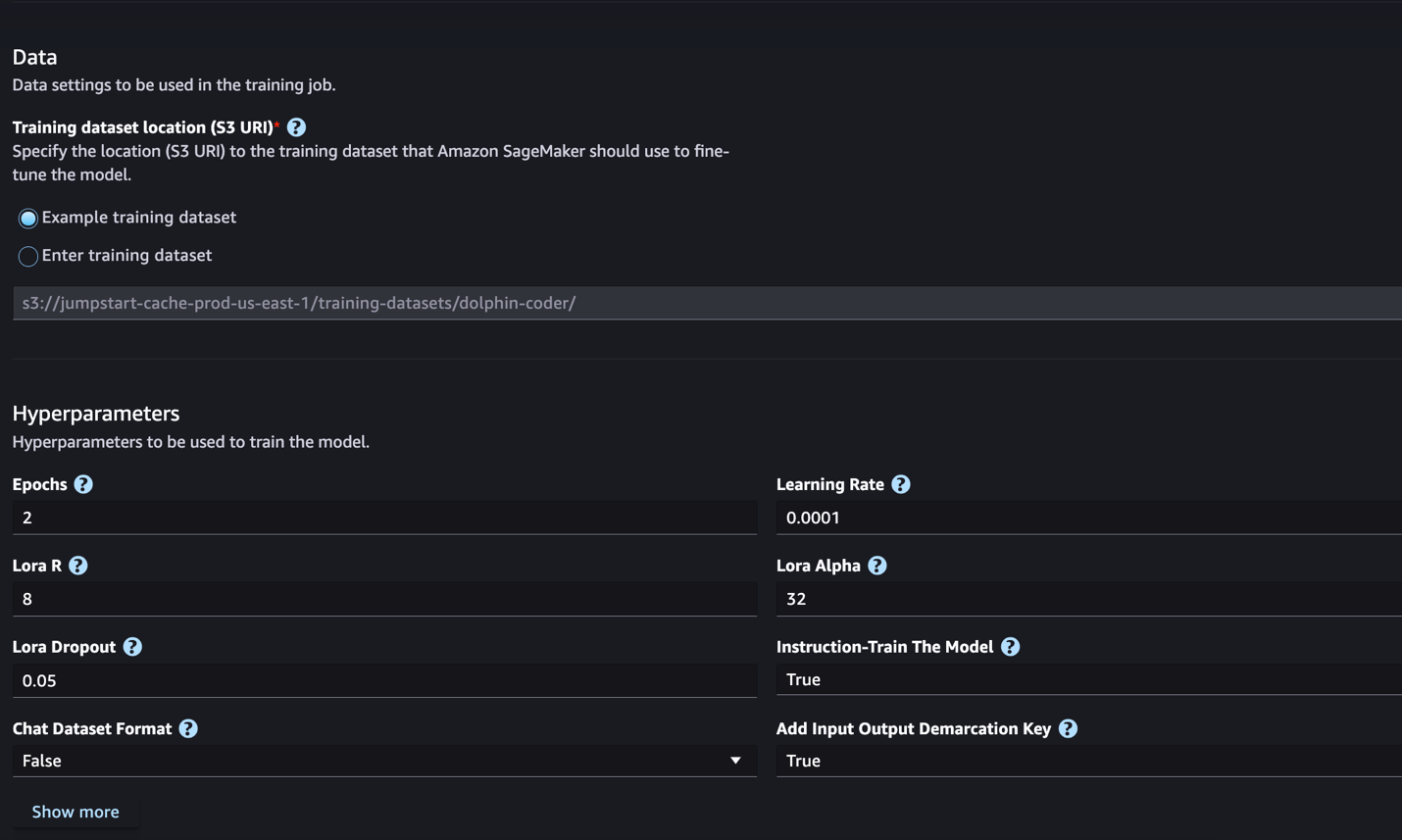
我們將在下一節中討論您需要為指令微調準備的資料集格式。
- 模型微調後,您可以使用 SageMaker JumpStart 上的模型頁面進行部署。
微調完成後,將出現部署微調模型的選項,如下圖所示。

透過 SageMaker Python SDK 進行微調
在本節中,我們將示範如何在指令格式資料集上使用 SageMaker Python SDK 微調 Code LIama 模型。具體來說,該模型針對使用指令描述的一組自然語言處理 (NLP) 任務進行了微調。這有助於透過零樣本提示來提高模型針對看不見的任務的效能。
完成以下步驟來完成您的微調工作。您可以從以下位置取得完整的微調程式碼 GitHub存儲庫.
首先,我們來看看指令微調所需的資料集格式。訓練資料應採用 JSON 行 (.jsonl) 格式,其中每行都是代表資料樣本的字典。所有訓練資料必須位於一個資料夾中。但是,它可以保存在多個 .jsonl 檔案中。以下是 JSON 行格式的範例:
訓練資料夾可以包含 template.json 描述輸入和輸出格式的檔案。以下是一個範例模板:
為了匹配模板,JSON 行文件中的每個範例必須包含 system_prompt, question和 response 字段。在本示範中,我們使用 Dolphin Coder 資料集 來自《擁抱的臉》。
準備好資料集並將其上傳到 S3 儲存桶後,您可以使用以下程式碼開始微調:
您可以直接從估計器部署微調後的模型,如下列程式碼所示。有關詳細信息,請參閱筆記本中的 GitHub存儲庫.
微調技術
Llama 等語言模型的大小超過 10 GB 甚至 100 GB。 微調如此大的模型需要具有非常高的 CUDA 記憶體的實例。 此外,由於模型的大小,訓練這些模型可能會非常緩慢。 因此,為了高效微調,我們使用以下優化:
- 低階適應(LoRA) – 這是一種參數高效微調(PEFT),用於對大型模型進行高效微調。使用此方法,您可以凍結整個模型,並且僅在模型中新增一組可調整參數或圖層。例如,您可以微調不到 7% 的參數,而不是為 Llama 2 7B 訓練所有 1 億個參數。這有助於顯著減少記憶體需求,因為您只需要儲存 1% 參數的梯度、優化器狀態和其他訓練相關資訊。此外,這有助於減少培訓時間和成本。有關此方法的更多詳細信息,請參閱 LoRA:大型語言模型的低秩適應.
- Int8 量化 – 即使採用 LoRA 等最佳化,Llama 70B 等模型仍然太大而無法訓練。為了減少訓練期間的記憶體佔用,您可以在訓練期間使用 Int8 量化。量化通常會降低浮點資料類型的精確度。儘管這減少了儲存模型權重所需的內存,但由於資訊遺失而降低了效能。 Int8 量化僅使用四分之一精度,但不會導致效能下降,因為它不會簡單地丟棄位元。它將資料從一種類型舍入為另一種類型。若要了解 Int8 量化,請參閱 LLM.int8():大規模 Transformer 的 8 位元矩陣乘法.
- 完全分片資料並行 (FSDP) – 這是一種資料並行訓練演算法,它將模型的參數分片到資料平行工作器上,並且可以選擇將部分訓練計算卸載到 CPU。 儘管參數分佈在不同的 GPU 上,但每個微批次的計算都是 GPU 工作執行緒本地的。 它更均勻地對參數進行分片,並透過訓練期間的通訊和計算重疊來實現最佳化的效能。
下表總結了具有不同設定的每個型號的詳細資訊。
| 型號 | 默認設置 | 洛拉+FSDP | LORA + 無 FSDP | Int8 量化 + LORA + 無 FSDP |
| 代碼駱駝 2 7B | 洛拉+FSDP | 是 | 是 | 是 |
| 代碼駱駝 2 13B | 洛拉+FSDP | 是 | 是 | 是 |
| 代碼駱駝 2 34B | INT8 + LORA + 無 FSDP | 沒有 | 沒有 | 是 |
| 代碼駱駝 2 70B | INT8 + LORA + 無 FSDP | 沒有 | 沒有 | 是 |
Llama 模型的微調是基於以下提供的腳本 GitHub回購.
支援的訓練超參數
Code Llama 2 微調支援許多超參數,每個超參數都會影響微調模型的記憶體需求、訓練速度和效能:
- 時代 – 微調演算法通過訓練資料集的次數。 必須是大於 1 的整數。預設值為 5。
- 學習率 – 完成每批訓練範例後模型權重的更新率。 必須是大於 0 的正浮點數。預設值為 1e-4。
- 指令調整 – 是否對模型進行指令訓練。必須是
TrueorFalse。預設為False. - 每個設備訓練批次大小 – 用於訓練的每個 GPU 核心/CPU 的批次大小。 必須是正整數。 預設值為 4。
- 每設備評估批量大小 – 用於評估的每個 GPU 核心/CPU 的批次大小。 必須是正整數。 預設值為 1。
- 最大訓練樣本數 – 為了調試目的或加快訓練速度,請將訓練範例的數量截斷為此值。 值-1表示使用所有訓練樣本。 必須是正整數或-1。 預設值為-1。
- 最大值樣本數 – 為了偵錯目的或加快訓練速度,請將驗證範例的數量截斷為此值。 值 -1 表示使用所有驗證樣本。 必須是正整數或-1。 預設值為-1。
- 最大輸入長度 – 標記化後的最大總輸入序列長度。 超過此長度的序列將會被截斷。 如果-1,
max_input_length設定為最小值 1024 和分詞器定義的最大模型長度。 如果設定為正值,max_input_length設定為提供的值的最小值和model_max_length由分詞器定義。 必須是正整數或-1。 預設值為-1。 - 驗證分割比率 – 如果驗證頻道是
none,從訓練資料中分割訓練驗證的比率必須在 0-1 之間。預設值為 0.2。 - 訓練資料分割種子 – 如果不存在驗證數據,則會修復輸入訓練資料與演算法使用的訓練和驗證資料的隨機分割。 必須是整數。 預設值為 0。
- preprocessing_num_workers – 用於預處理的進程數。 如果
None,主進程用於預處理。 預設為None. - 勞拉_r – Lora R。必須是正整數。 預設值為 8。
- 洛拉阿爾法 ——洛拉·阿爾法。 必須是正整數。 預設值為 32
- 勞拉_輟學 ——洛拉輟學。 必須是 0 到 1 之間的正浮點數。預設值為 0.05。
- int8_量化 - 如果
True,模型載入8位元精度進行訓練。 7B 和 13B 的預設值為False。 70B 的預設值是True. - 啟用_fsdp – 如果為 True,則訓練使用 FSDP。 7B 和 13B 的預設值為 True。 70B 的預設值為 False。注意
int8_quantizationFSDP 不支援。
選擇超參數時,請考慮以下因素:
- 設置
int8_quantization=True減少記憶體需求並加快訓練速度。 - 降低
per_device_train_batch_size和max_input_length減少了記憶體需求,因此可以在較小的實例上運行。 但是,設定非常低的值可能會增加訓練時間。 - 如果您不使用 Int8 量化(
int8_quantization=False),使用 FSDP(enable_fsdp=True)以實現更快、更有效率的培訓。
支援的訓練實例類型
下表總結了訓練不同模型所支援的實例類型。
| 型號 | 默認實例類型 | 支援的實例類型 |
| 代碼駱駝 2 7B | ml.g5.12xlarge |
毫升.g5.12xlarge, 毫升.g5.24xlarge, 毫升.g5.48xlarge, ml.p3dn.24xlarge, ml.g4dn.12xlarge |
| 代碼駱駝 2 13B | ml.g5.12xlarge |
毫升.g5.24xlarge, 毫升.g5.48xlarge, ml.p3dn.24xlarge, ml.g4dn.12xlarge |
| 代碼駱駝 2 70B | ml.g5.48xlarge |
ml.g5.48xlarge ml.p4d.24xlarge |
選擇實例類型時,請考慮以下因素:
- G5 實例提供支援的實例類型中最高效的訓練。 因此,如果您有可用的 G5 實例,則應該使用它們。
- 訓練時間很大程度上取決於 GPU 數量和可用 CUDA 記憶體。 因此,在具有相同 GPU 數量的實例(例如 ml.g5.2xlarge 和 ml.g5.4xlarge)上進行訓練大致相同。 因此,您可以使用更便宜的實例進行訓練(ml.g5.2xlarge)。
- 使用 p3 實例時,將以 32 位元精度進行訓練,因為這些實例不支援 bfloat16。 因此,與 g3 實例相比,在 p5 實例上訓練時,訓練作業將消耗雙倍的 CUDA 記憶體。
若要了解每個實例的訓練成本,請參閱 Amazon EC2 G5實例.
評估
評估是評估微調模型效能的重要步驟。我們提供定性和定量評估,以顯示微調模型相對於非微調模型的改進。在定性評估中,我們展示了微調和非微調模型的範例回應。在定量評估中,我們使用 人類評估,OpenAI 開發的測試套件,用於產生 Python 程式碼,以測試產生正確和準確結果的能力。 HumanEval 儲存庫已獲得 MIT 許可。我們對不同大小的所有 Code LIama 模型的 Python 變體進行了微調(程式碼 LIama Python 7B、13B、34B 和 70B Dolphin Coder 資料集),並在以下部分介紹評估結果。
定性評價
部署微調模型後,您可以開始使用端點產生程式碼。在下面的範例中,我們在測試樣本上展示了基本程式碼 LIama 34B Python 變體和微調程式碼 LIama XNUMXB Python 變體的回應 Dolphin Coder 資料集:
經過微調的 Code Llama 模型除了提供前面查詢的程式碼之外,還產生該方法的詳細解釋和偽代碼。
程式碼 Llama 34b Python 非微調回應:
Code Llama 34B Python 微調回應
地面真相
有趣的是,我們的 Code Llama 34B Python 的微調版本為最長回文子字串提供了基於動態程式設計的解決方案,這與所選測試範例的基本事實中提供的解決方案不同。我們的微調模型詳細解釋了基於動態規劃的解決方案。另一方面,非微調模型在 print 語句(顯示在左側儲存格中)因為輸出 axyzzyx 不是給定字串中最長的回文。就時間複雜度而言,動態規劃解決方案通常優於初始方法。動態規劃解的時間複雜度為 O(n^2),其中 n 是輸入字串的長度。這比非微調模型的初始解決方案更有效,後者的二次時間複雜度為 O(n^2),但最佳化方法較少。
這看起來很有希望!請記住,我們僅對 Code LIama Python 變體進行了 10% 的微調 Dolphin Coder 資料集。還有更多值得探索的地方!
儘管回應中有詳細說明,我們仍然需要檢查解決方案中提供的 Python 程式碼的正確性。接下來,我們使用一個名為的評估框架 人類評估 對 Code LIama 產生的回應執行整合測試,以系統化檢查其品質。
使用 HumanEval 進行定量評估
HumanEval 是一個評估工具,用於評估法學碩士解決基於 Python 的編碼問題的能力,如論文中所述 評估在程式碼上訓練的大型語言模型。具體來說,它由 164 個基於 Python 的原始程式設計問題組成,這些問題評估語言模型根據提供的資訊(如函數簽名、文件字串、正文和單元測試)生成程式碼的能力。
對於每個基於 Python 的程式設計問題,我們將其傳送到部署在 SageMaker 端點上的 Code LIama 模型以取得 k 個回應。接下來,我們對 HumanEval 儲存庫中的整合測試執行 k 個回應中的每一個。如果 k 個回應中的任何一個回應通過了整合測試,我們就認為測試案例成功;否則,失敗。然後我們重複這個過程,計算成功案例的比例,作為最終的評估分數,命名為 pass@k。按照標準做法,我們在評估中將 k 設定為 1,以便每個問題僅產生一個回應並測試它是否通過整合測試。
以下是使用 HumanEval 儲存庫的範例程式碼。您可以使用 SageMaker 端點存取資料集並產生單一回應。有關詳細信息,請參閱筆記本中的 GitHub存儲庫.
下表顯示了在不同模型大小上,微調的 Code LIama Python 模型相對於非微調模型的改進。為了確保正確性,我們還在 SageMaker 端點中部署了未微調的 Code LIama 模型,並執行 Human Eval 評估。這 透過@1 數字(下表中的第一行)與報告中的數字相符 代碼駱駝研究論文。 推理參數一致設定為 "parameters": {"max_new_tokens": 384, "temperature": 0.2}.
從結果中我們可以看到,所有經過微調的 Code LIama Python 變體都比未經微調的模型有了顯著的改進。特別是,程式碼 LIama Python 70B 的效能比未微調的模型高出約 12%。
| . | 7B 蟒蛇 | 13B 蟒蛇 | 34B | 34B 蟒蛇 | 70B 蟒蛇 |
| 預訓練模型效能 (pass@1) | 38.4 | 43.3 | 48.8 | 53.7 | 57.3 |
| 微調模型效能 (pass@1) | 45.12 | 45.12 | 59.1 | 61.5 | 69.5 |
現在您可以嘗試在自己的資料集上微調 Code LIama 模型。
清理
如果您決定不再希望保持 SageMaker 端點運行,您可以使用以下命令將其刪除 適用於Python的AWS開發工具包(Boto3), AWS命令行界面 (AWS CLI) 或 SageMaker 控制台。有關更多信息,請參閱 刪除端點和資源. 此外,您可以 關閉 SageMaker Studio 資源 不再需要的。
結論
在這篇文章中,我們討論了使用 SageMaker JumpStart 微調 Meta 的 Code Llama 2 模型。我們展示了您可以使用 SageMaker Studio 中的 SageMaker JumpStart 控制台或 SageMaker Python SDK 來微調和部署這些模型。我們也討論了微調技術、實例類型和支援的超參數。此外,我們根據我們進行的各種測試概述了優化訓練的建議。正如我們從兩個資料集上微調三個模型的結果中所看到的,與非微調模型相比,微調提高了概括能力。下一步,您可以嘗試使用 GitHub 儲存庫中提供的程式碼在您自己的資料集上微調這些模型,以測試和基準測試案例的結果。
關於作者
 黃鑫博士 是 Amazon SageMaker JumpStart 和 Amazon SageMaker 內置算法的高級應用科學家。 他專注於開發可擴展的機器學習算法。 他的研究興趣是自然語言處理、表格數據的可解釋深度學習以及非參數時空聚類的穩健分析。 他在 ACL、ICDM、KDD 會議和 Royal Statistical Society: Series A 上發表了多篇論文。
黃鑫博士 是 Amazon SageMaker JumpStart 和 Amazon SageMaker 內置算法的高級應用科學家。 他專注於開發可擴展的機器學習算法。 他的研究興趣是自然語言處理、表格數據的可解釋深度學習以及非參數時空聚類的穩健分析。 他在 ACL、ICDM、KDD 會議和 Royal Statistical Society: Series A 上發表了多篇論文。
 維沙爾·亞拉曼恰利 是一名新創解決方案架構師,與早期生成式人工智慧、機器人和自動駕駛汽車公司合作。 Vishaal 與客戶合作提供尖端的 ML 解決方案,並且個人對強化學習、LLM 評估和程式碼產生感興趣。在加入 AWS 之前,Vishaal 是 UCI 的本科生,主修生物資訊學和智慧系統。
維沙爾·亞拉曼恰利 是一名新創解決方案架構師,與早期生成式人工智慧、機器人和自動駕駛汽車公司合作。 Vishaal 與客戶合作提供尖端的 ML 解決方案,並且個人對強化學習、LLM 評估和程式碼產生感興趣。在加入 AWS 之前,Vishaal 是 UCI 的本科生,主修生物資訊學和智慧系統。
 米納克希孫達拉姆·塔達瓦拉揚 在 AWS 擔任 AI/ML 專家。他熱衷於設計、創建和推廣以人為本的數據和分析體驗。 Meena 專注於開發永續系統,為 AWS 的策略客戶提供可衡量的競爭優勢。 Meena 是一位溝通者和設計思想家,致力於透過創新、孵化和民主化推動企業採用新的工作方式。
米納克希孫達拉姆·塔達瓦拉揚 在 AWS 擔任 AI/ML 專家。他熱衷於設計、創建和推廣以人為本的數據和分析體驗。 Meena 專注於開發永續系統,為 AWS 的策略客戶提供可衡量的競爭優勢。 Meena 是一位溝通者和設計思想家,致力於透過創新、孵化和民主化推動企業採用新的工作方式。
 Ashish Khetan 博士 是 Amazon SageMaker 內置算法的高級應用科學家,幫助開發機器學習算法。 他在伊利諾伊大學香檳分校獲得博士學位。 他是機器學習和統計推理領域的活躍研究者,在 NeurIPS、ICML、ICLR、JMLR、ACL 和 EMNLP 會議上發表了多篇論文。
Ashish Khetan 博士 是 Amazon SageMaker 內置算法的高級應用科學家,幫助開發機器學習算法。 他在伊利諾伊大學香檳分校獲得博士學位。 他是機器學習和統計推理領域的活躍研究者,在 NeurIPS、ICML、ICLR、JMLR、ACL 和 EMNLP 會議上發表了多篇論文。

