簡介
人工智慧和機器學習的出現徹底改變了我們與資訊互動的方式,使檢索、理解和利用資訊變得更加容易。在本實務指南中,我們探索建立由 LLamA2 和 LLamAIndex 提供支援的複雜問答助手,利用最先進的語言模型和索引框架輕鬆導覽大量 PDF 文件。本教程旨在為開發人員、資料科學家和技術愛好者提供工具和知識,以建立站在 NLP 領域巨人肩膀上的檢索增強生成 (RAG) 系統。
為了揭開人工智慧驅動問答助理創建的神秘面紗,本指南充當了複雜的理論概念與其在現實場景中的實際應用之間的橋樑。透過將LLamA2的高階語言理解能力與LLamAIndex的高效資訊檢索能力結合,我們的目標是建立一個能夠精確回答問題的系統,並加深我們對NLP領域的潛力和挑戰的理解。本文為愛好者和專業人士提供了全面的路線圖,強調了尖端模型與不斷變化的資訊科技需求之間的協同作用。

學習目標
- 使用 Hugging Face 的 LLamA2 模型開發 RAG 系統。
- 整合多個 PDF 文件。
- 索引文檔以進行高效率檢索。
- 製作一個查詢系統。
- 創造一個能夠回答各種問題的強大助手。
- 注重實際實施而不僅僅是理論方面。
- 參與動手編碼和實際應用。
- 讓 NLP 的複雜世界變得觸手可及、引人入勝。
目錄
LLamA2 型號
LLamA2 是自然語言處理領域的創新燈塔,突破了語言模型的可能性界限。其架構專為提高效率和效果而設計,可實現前所未有的理解和生成類人文本。與 BERT 和 GPT 等前輩不同,LLamA2 提供了一種更細緻的語言處理方法,使其特別適合需要深度理解的任務,例如回答問題。它在從摘要到翻譯的各種 NLP 任務中的實用性,展示了其解決複雜語言挑戰的多功能性和能力。

了解 LLamAIndex
索引是任何高效資訊檢索系統的支柱。 LLamAIndex 是一個專為文件索引和查詢而設計的框架,它透過提供無縫方式來管理大量文件而脫穎而出。這不僅僅是存儲資訊;它是為了讓它在眨眼之間就可以存取和檢索。

LLamAIndex 的重要性怎麼強調都不為過,因為它可以跨廣泛的資料庫進行即時查詢處理,確保我們的問答助理能夠從全面的知識庫中提供及時、準確的答案。
標記化和嵌入
理解語言模型的第一步是將文字分解為可管理的片段,這個過程稱為標記化。這項基礎任務對於準備資料以進行進一步處理至關重要。在標記化之後,嵌入的概念開始發揮作用,將單字和句子轉換為數值向量。
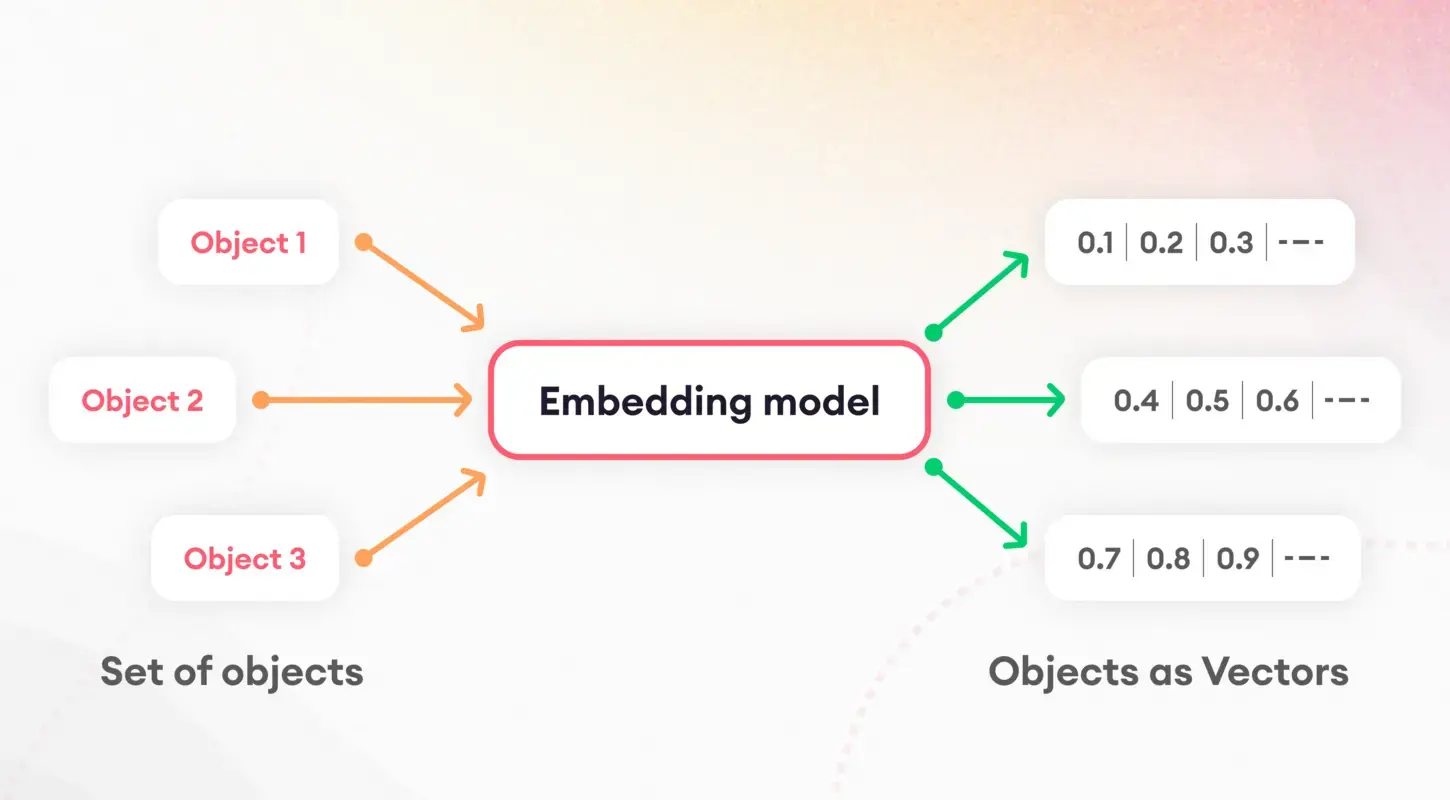
這些嵌入捕捉了語言特徵的本質,使模型能夠識別和利用文字的潛在語義屬性。特別是,句子嵌入在文件相似性和檢索等任務中發揮關鍵作用,構成了我們索引策略的基礎。
模型量化
模型量化提出了一種提高問答助手性能和效率的策略。透過降低模型數值計算的精確度,我們可以顯著減小其大小並加快推理時間。雖然需要在精度和效率之間進行權衡,但此過程在資源受限的環境(例如行動裝置或 Web 應用程式)中尤其有價值。透過仔細的應用,量化使我們能夠保持高水準的準確性,同時受益於減少的延遲和儲存要求。
ServiceContext和查詢引擎
LLamAIndex 中的 ServiceContext 是管理資源和配置的中心樞紐,確保我們的系統平穩且有效率地運作。膠水將我們的應用程式粘合在一起,從而實現了應用程式之間的無縫集成 LLamA2模型、嵌入過程和索引文件。另一方面,查詢引擎是處理使用者查詢的主力,利用索引資料快速取得相關資訊。這種雙重設定確保我們的問答助理可以輕鬆處理複雜的查詢,為使用者提供快速、準確的答案。
執行
讓我們深入了解實施情況。請注意,我使用 Google Colab 來建立此專案。
!pip install pypdf
!pip install -q transformers einops accelerate langchain bitsandbytes
!pip install sentence_transformers
!pip install llama_index這些命令透過安裝必要的函式庫來奠定基礎,包括用於模型互動的轉換器和用於嵌入的sentence_transformers。 llama_index 的安裝對於我們的索引框架至關重要。
接下來,我們初始化元件(確保在 Google Colab 的「檔案」部分中建立一個名為「data」的資料夾,然後將 PDF 上傳到該資料夾中):
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader, ServiceContext
from llama_index.llms.huggingface import HuggingFaceLLM
from llama_index.core.prompts.prompts import SimpleInputPrompt
# Reading documents and setting up the system prompt
documents = SimpleDirectoryReader("/content/data").load_data()
system_prompt = """
You are a Q&A assistant. Your goal is to answer questions based on the given documents.
"""
query_wrapper_prompt = SimpleInputPrompt設定環境並閱讀文件後,我們製作了一個系統提示來指導 LLamA2 模型的回應。此範本有助於確保模型的輸出符合我們對準確性和相關性的期望。
!huggingface-cli login
上面的指令是存取 Hugging Face 龐大模型儲存庫的入口網站。它需要一個令牌來進行身份驗證。
您需要訪問以下連結: 擁抱臉 (確保您先登入 Hugging Face),然後建立一個新令牌,為專案提供名稱,選擇“類型”為“讀取”,然後按一下“產生令牌”。
此步驟強調了保護和個人化開發環境的重要性。
import torch
llm = HuggingFaceLLM(
context_window=4096,
max_new_tokens=256,
generate_kwargs={"temperature": 0.0, "do_sample": False},
system_prompt=system_prompt,
query_wrapper_prompt=query_wrapper_prompt,
tokenizer_name="meta-llama/Llama-2-7b-chat-hf",
model_name="meta-llama/Llama-2-7b-chat-hf",
device_map="auto",
model_kwargs={"torch_dtype": torch.float16, "load_in_8bit":True}
)在這裡,我們使用為我們的問答系統定制的特定參數來初始化 LLamA2 模型。這種設置突出了模型的多功能性以及適應不同環境和應用的能力。
from langchain.embeddings.huggingface import HuggingFaceEmbeddings
from llama_index.embeddings.langchain import LangchainEmbedding
embed_model = LangchainEmbedding(
HuggingFaceEmbeddings(model_name="sentence-transformers/all-mpnet-base-v2"))嵌入模型的選擇對於捕獲文件的語義本質至關重要。透過使用句子轉換器,我們確保我們的系統能夠準確地衡量文字內容的相似性和相關性,從而提高索引過程的效率。
service_context = ServiceContext.from_defaults(
chunk_size=1024,
llm=llm,
embed_model=embed_model
)ServiceContext 使用預設設定進行實例化,連結我們的 LLamA2 模型並將模型嵌入到一個內聚框架中。此步驟可確保所有系統元件協調一致並準備好進行索引和查詢操作。
index = VectorStoreIndex.from_documents(documents, service_context=service_context)
query_engine = index.as_query_engine()這些行標誌著我們的設定過程的高潮,我們在其中索引文件並準備查詢引擎。此設定對於將資料準備轉變為可操作的見解至關重要,使我們的問答助理能夠根據索引內容回應查詢。
response = query_engine.query("Give me a Summary of the PDF in 10 pointers.")
print(response)最後,我們透過查詢系統以取得從我們的文件集合中得出的摘要和見解來測試我們的系統。這次互動展示了我們問答助理的實用性,並展示了LLamA2、LLamAIndex和底層的無縫集成 自然語言處理技術 這使得這成為可能。
輸出:

道德和法律影響
開發人工智慧驅動的問答系統將一些道德和法律考慮因素放在首位。解決訓練資料中的潛在偏差至關重要,並確保回應的公平性和中立性。此外,遵守資料隱私法規至關重要,因為這些系統通常處理敏感資訊。開發人員必須勤奮和誠信地應對這些挑戰,致力於維護使用者和所提供資訊完整性的道德原則。
未來的方向和挑戰
從多模式互動到特定領域的應用程序,問答系統領域已經成熟,充滿了創新機會。然而,這些進步也帶來了自身的挑戰,包括擴展以適應大量文件集合以及確保使用者查詢的多樣性。 LLamA2 等模型和 LLamAIndex 等索引框架的持續開發和完善對於克服這些障礙並突破 NLP 可能性的界限至關重要。
案例研究和例子
問答系統(例如客戶服務機器人和教育工具)的實際實施強調了 LLamA2 和 LLamAIndex 等技術的多功能性和影響力。這些案例研究展示了人工智慧在不同產業的實際應用,突顯了成功案例和經驗教訓,為未來發展提供了寶貴的見解。
結論
本指南涵蓋了建立基於 PDF 的問答助理的整個過程,從 LLamA2 和 LLamAIndex 的基本概念到實際的實施步驟。隨著我們不斷探索和擴展人工智慧在資訊檢索和處理方面的能力,改變我們與知識的互動的潛力是無限的。有了這些工具和見解,邁向更聰明、回應更靈敏的系統的旅程才剛開始。
關鍵要點
- 徹底改變資訊互動:人工智慧和機器學習的整合(以 LLamA2 和 LLamAIndex 為代表)改變了我們存取和利用資訊的方式,為能夠輕鬆瀏覽大量 PDF 文件的複雜問答助理鋪平了道路。
- 理論與應用之間的實用橋樑:本指南彌合了理論概念與實際實現之間的差距,使開發人員和技術愛好者能夠構建利用最先進的 NLP 模型和索引框架的檢索增強生成 (RAG) 系統。
- 高效索引的重要性:LLamAIndex 透過對大量文件集合建立索引,在高效資訊檢索中發揮至關重要的作用。這確保了對使用者查詢的及時、準確的回應,並增強了問答助理的整體功能。
- 效能和效率最佳化:模型量化等技術可提高問答助理的效能和效率,從而在不影響準確性的情況下減少延遲和儲存要求。
- 道德考量與未來方向:開發人工智慧驅動的問答系統需要解決道德和法律影響,包括減少偏見和資料隱私。展望未來,問答系統的進步帶來了創新機會,同時也對使用者查詢的可擴展性和多樣性提出了挑戰
常見問題
答。 LLamA2 提供了一種更細緻的語言處理方法,支援深度理解任務,例如回答問題。其架構優先考慮效率和有效性,使其在各種 NLP 任務中具有通用性。
答。 LLamAIndex 是一個文件索引和查詢框架,可促進跨廣泛資料庫的即時查詢處理。它確保問答助理能夠從全面的知識庫中快速檢索相關資訊。
答。嵌入,特別是句子嵌入,捕捉文字內容的語意本質,從而能夠準確衡量相似性和相關性。這增強了索引過程的效率,並提高了助理提供相關回應的能力。
答。模型量化透過減少數值計算的大小來優化效能和效率,從而減少延遲和儲存需求。雖然在精度和效率之間進行了權衡,但它在資源有限的環境中很有價值。
答。開發人員必須解決訓練資料中的潛在偏差,確保回應的公平性和中立性,並遵守資料隱私法規。堅持道德原則可以保護使用者並維護問答助理提供的資訊的完整性。

