如今,所有行業的客戶(無論是金融服務、醫療保健和生命科學、旅遊和酒店、媒體和娛樂、電信、軟體即服務(SaaS),甚至專有模型提供商)都在使用大型語言模型(LLM ) 來建立問答 (QnA) 聊天機器人、搜尋引擎和知識庫等應用程式。這些 生成AI 應用程式不僅用於自動化現有業務流程,還能夠改變使用這些應用程式的客戶的體驗。隨著法學碩士(LLM)的進步,例如 Mixtral-8x7B 指令,架構的衍生品,例如 專家組合(教育部),客戶不斷尋找提高生成式人工智慧應用程式效能和準確性的方法,同時允許他們有效地使用更廣泛的封閉和開源模型。
通常使用多種技術來提高法學碩士輸出的準確性和性能,例如使用 參數高效微調(PEFT), 從人類反饋中強化學習 (RLHF),並表演 知識昇華。但是,在建立生成式 AI 應用程式時,您可以使用替代解決方案,該解決方案允許動態合併外部知識,並允許您控制用於生成的信息,而無需微調現有的基礎模型。這就是檢索增強生成(RAG)的用武之地,特別是針對生成式人工智慧應用程序,而不是我們討論過的更昂貴、更強大的微調替代方案。如果您在日常任務中實施複雜的RAG 應用程序,您可能會遇到RAG 系統的常見挑戰,例如檢索不準確、文件大小和複雜性增加以及上下文溢出,這可能會嚴重影響生成答案的品質和可靠性。
這篇文章討論了使用 LangChain 和父文檔檢索器等工具以及上下文壓縮等技術來提高響應準確性的 RAG 模式,以便開發人員能夠改進現有的生成式 AI 應用程式。
解決方案概述
在這篇文章中,我們示範如何使用 Mixtral-8x7B Instruct 文字產生與 BGE Large En 嵌入模型相結合,使用父文檔檢索器工具和上下文壓縮技術在 Amazon SageMaker 筆記本上高效建立 RAG QnA 系統。下圖說明了該解決方案的架構。
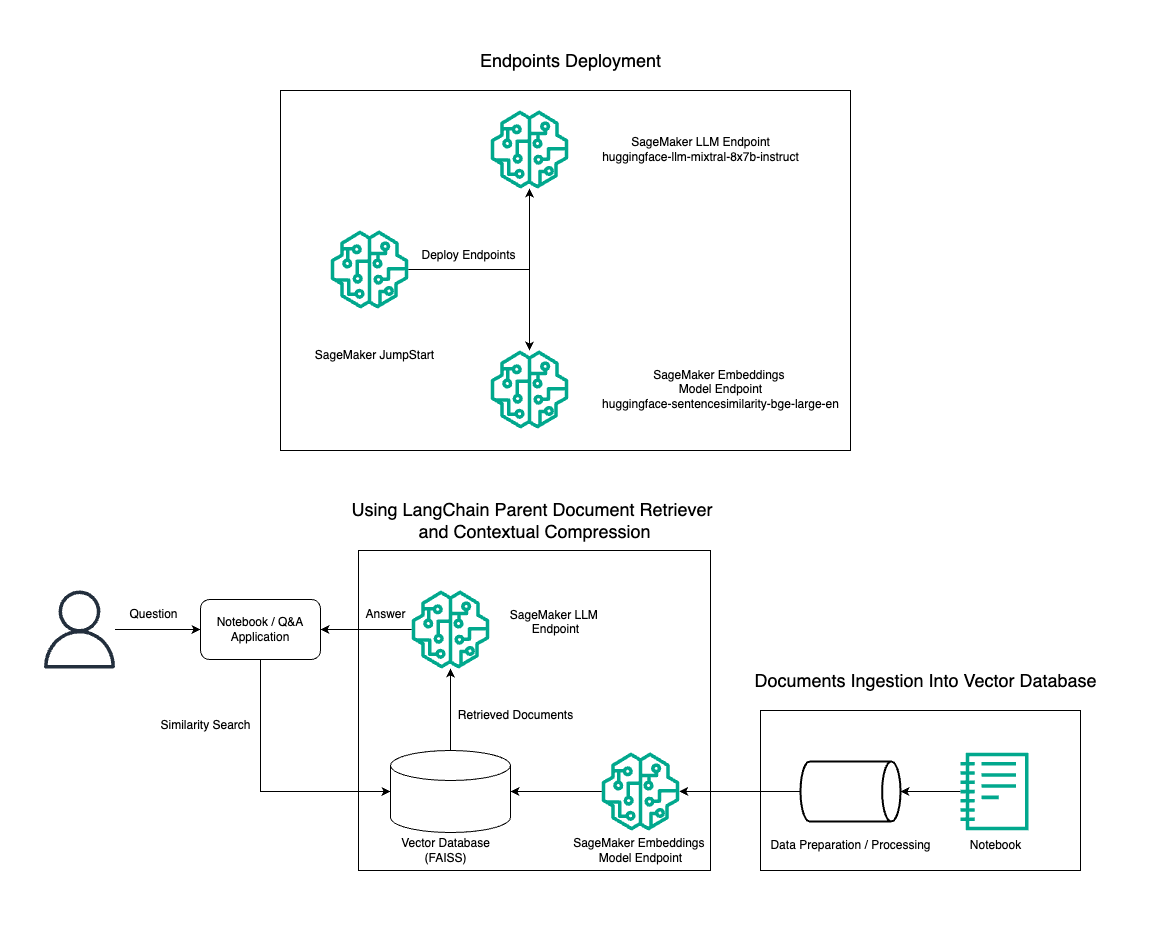
您只需點擊幾下即可部署此解決方案 亞馬遜SageMaker JumpStart,一個完全託管的平台,為內容編寫、程式碼生成、問答、文案寫作、摘要、分類和資訊檢索等各種用例提供最先進的基礎模型。它提供了一系列預先訓練的模型,您可以快速輕鬆地部署這些模型,從而加速機器學習 (ML) 應用程式的開發和部署。 SageMaker JumpStart 的關鍵組件之一是模型中心,它提供了大量預訓練模型,例如 Mixtral-8x7B,適用於各種任務。
Mixtral-8x7B 使用 MoE 架構。這種架構允許神經網路的不同部分專注於不同的任務,有效地將工作負載分配給多個專家。與傳統架構相比,這種方法可以有效率地訓練和部署更大的模型。
MoE 架構的主要優勢之一是其可擴展性。透過將工作負載分配給多個專家,MoE 模型可以在更大的資料集上進行訓練,並獲得比相同規模的傳統模型更好的效能。此外,MoE 模型在推理過程中可以更加高效,因為對於給定的輸入只需要啟動一部分專家。
有關 AWS 上的 Mixtral-8x7B Instruct 的更多信息,請參閱 Mixtral-8x7B 現已在 Amazon SageMaker JumpStart 中提供。 Mixtral-8x7B 模型在寬鬆的 Apache 2.0 許可證下提供,可以不受限制地使用。
在這篇文章中,我們討論如何使用 浪鏈 創建有效且更有效率的 RAG 應用程式。 LangChain 是一個開源 Python 庫,旨在使用 LLM 建立應用程式。它提供了一個模組化且靈活的框架,用於將法學碩士與其他組件(例如知識庫、檢索系統和其他人工智慧工具)相結合,以創建強大且可自訂的應用程式。
我們將逐步介紹如何使用 Mixtral-8x7B 在 SageMaker 上建立 RAG 管道。我們將 Mixtral-8x7B Instruct 文字產生模型與 BGE Large En 嵌入模型結合使用,在 SageMaker 筆記本上使用 RAG 創建高效的 QnA 系統。我們使用 ml.t3.medium 實例來示範如何透過 SageMaker JumpStart 部署 LLM,可以透過 SageMaker 產生的 API 端點進行存取。此設定允許使用 LangChain 探索、實驗和優化先進的 RAG 技術。我們還說明了將 FAISS Embedding 儲存整合到 RAG 工作流程中,強調其在儲存和檢索嵌入以增強系統效能方面的作用。
我們對 SageMaker Notebook 進行了簡要演練。有關更詳細的逐步說明,請參閱 SageMaker Jumpstart GitHub 儲存庫上使用 Mixtral 的進階 RAG 模式.
對高階 RAG 模式的需求
高級 RAG 模式對於提高法學碩士當前處理、理解和生成類人文本的能力至關重要。隨著文件的大小和複雜性的增加,在單一嵌入中表示文件的多個方面可能會導致特異性的喪失。雖然捕捉文件的一般本質很重要,但識別和表示其中的不同子上下文也同樣重要。這是您在處理較大文件時經常面臨的挑戰。 RAG 的另一個挑戰是,在檢索時,您不知道文件儲存系統在攝取時將處理的特定查詢。這可能會導致與查詢最相關的資訊被隱藏在文字中(上下文溢出)。為了減少故障並改進現有的 RAG 架構,您可以使用高級 RAG 模式(父文檔檢索器和上下文壓縮)來減少檢索錯誤、提高答案品質並支援複雜的問題處理。
透過本文討論的技術,您可以解決與外部知識檢索和整合相關的關鍵挑戰,使您的應用程式能夠提供更精確和上下文感知的回應。
在以下部分中,我們將探討如何 父親文檔檢索器 和 上下文壓縮 可以幫助您解決我們討論過的一些問題。
父親文檔檢索器
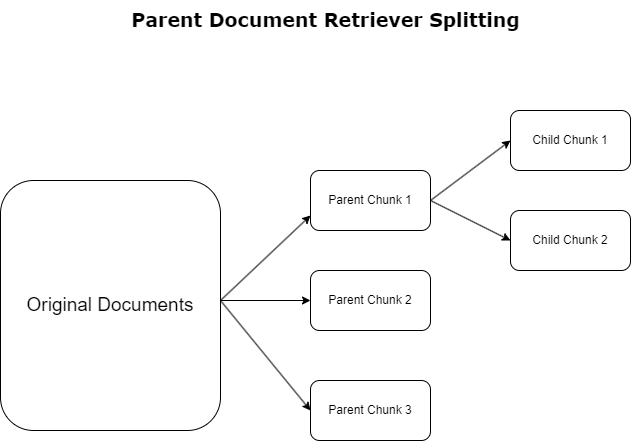
在上一節中,我們強調了 RAG 應用程式在處理大量文件時遇到的挑戰。為了應對這些挑戰, 父親文檔檢索器 對傳入文件進行分類和指定 父親文件。這些文件因其綜合性而受到認可,但並未以其原始形式直接用於嵌入。父文檔檢索器不是將整個文件壓縮為單一嵌入,而是將這些父文件分解為 子檔案。每個子文檔都從更廣泛的父文檔中捕獲不同的方面或主題。在識別這些子片段之後,將單獨的嵌入分配給每個子片段,並捕獲它們特定的主題本質(參見下圖)。在檢索期間,呼叫父文檔。該技術提供了有針對性且廣泛的搜尋能力,為法學碩士提供了更廣闊的視角。父文檔檢索器為法學碩士提供了雙重優勢:子文檔嵌入的特殊性用於精確和相關的信息檢索,再加上調用父文檔以生成響應,這通過分層且全面的上下文豐富了法學碩士的輸出。
上下文壓縮
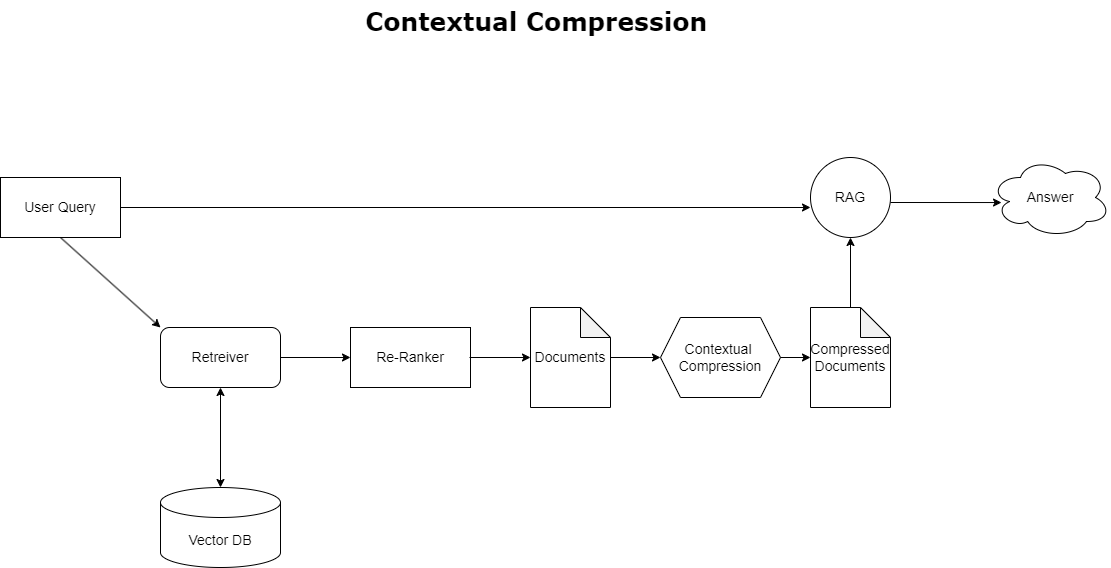
為了解決前面討論的上下文溢出問題,您可以使用 上下文壓縮 根據查詢的上下文壓縮和過濾檢索到的文檔,因此僅保留和處理相關資訊。這是透過組合用於初始文件獲取的基本檢索器和用於透過削減文件內容或完全根據相關性排除它們來精煉這些文件的文檔壓縮器來實現的,如下圖所示。這種由上下文壓縮檢索器推動的簡化方法透過提供一種從大量資訊中僅提取和利用重要資訊的方法,大大提高了 RAG 應用程式的效率。它正面解決了資訊過載和不相關資料處理的問題,從而提高了響應品質、更具成本效益的法學碩士操作以及更順暢的整體檢索過程。從本質上講,它是一個根據當前查詢自訂資訊的過濾器,使其成為旨在優化 RAG 應用程式以獲得更好效能和用戶滿意度的開發人員急需的工具。
條件:
如果您是 SageMaker 新手,請參閱 Amazon SageMaker 開髮指南.
在開始使用解決方案之前, 創建一個 AWS 賬戶。建立 AWS 帳戶時,您將獲得單一登入 (SSO) 身份,可完全存取該帳戶中的所有 AWS 服務和資源。此身分稱為 AWS 帳戶 根用戶.
登錄 AWS管理控制台 使用您用於建立帳戶的電子郵件地址和密碼,您可以完全存取帳戶中的所有 AWS 資源。我們強烈建議您不要使用 root 使用者執行日常任務,即使是管理任務。
相反,堅持 安全最佳實踐 in AWS身份和訪問管理 (IAM),以及 建立管理使用者和群組。然後安全地鎖定根用戶憑證並使用它們僅執行少數帳戶和服務管理任務。
Mixtral-8x7b 模型需要 ml.g5.48xlarge 實例。 SageMaker JumpStart 提供了一種存取和部署 100 多種不同開源和第三方基礎模型的簡化方法。為了 從 SageMaker JumpStart 啟動端點以託管 Mixtral-8x7B,您可能需要請求增加服務配額才能存取 ml.g5.48xlarge 執行個體以供端點使用。你可以 請求服務配額增加 透過控制台, AWS命令行界面 (AWS CLI) 或允許存取這些附加資源的 API。
設定 SageMaker 筆記本實例並安裝依賴項
首先,建立一個 SageMaker 筆記本實例並安裝所需的依賴項。請參閱 GitHub回購 以確保設定成功。設定筆記本實例後,您可以部署模型。
您也可以在您首選的整合開發環境 (IDE) 上本機執行筆記本。確保您已安裝 Jupyter 筆記本實驗室。
部署模型
在 SageMaker JumpStart 上部署 Mixtral-8X7B Instruct LLM 模型:
在 SageMaker JumpStart 上部署 BGE Large En 嵌入模型:
設定浪鏈
導入所有必要的函式庫並部署 Mixtral-8x7B 模型和 BGE Large En 嵌入模型後,現在可以設定 LangChain。有關逐步說明,請參閱 GitHub回購.
資料準備
在這篇文章中,我們使用亞馬遜幾年來的致股東信作為文本語料庫來執行 QnA。有關準備資料的更詳細步驟,請參閱 GitHub回購.
問題回答
準備好資料後,您可以使用 LangChain 提供的包裝器,它包裝向量儲存並取得 LLM 的輸入。此包裝器執行以下步驟:
- 採取輸入問題。
- 建立問題嵌入。
- 取得相關文件。
- 將文件和問題合併到提示中。
- 使用提示呼叫模型並以可讀的方式產生答案。
現在向量儲存已就位,您可以開始提問:
常規獵犬鏈
在前面的場景中,我們探索了快速、直接的方法來獲得您的問題的上下文感知答案。現在,讓我們在 RetrievalQA 的幫助下看看一個更具可自訂性的選項,您可以在其中使用 chain_type 參數自訂如何將取得的文件新增至提示中。另外,為了控制應檢索多少相關文檔,您可以更改以下程式碼中的 k 參數以查看不同的輸出。在許多情況下,您可能想知道法學碩士使用哪些原始文件來產生答案。您可以使用以下命令在輸出中取得這些文檔 return_source_documents,它會傳回新增到 LLM 提示上下文中的文件。 RetrievalQA 還允許您提供特定於模型的自訂提示範本。
我們問一個問題:
父文檔檢索器鏈
讓我們看看更高級的 RAG 選項 父親文檔檢索器。在進行文件檢索時,您可能會遇到儲存小塊文件以實現準確嵌入和儲存較大文件以保留更多上下文之間的權衡。父文檔檢索器透過分割和儲存小資料塊來實現這種平衡。
我們使用了 parent_splitter 將原始文件分成更大的區塊,稱為父文檔和 child_splitter 從原始文檔建立較小的子文檔:
然後使用嵌入在向量儲存中對子文件進行索引。這使得能夠基於相似性有效檢索相關子文檔。為了檢索相關訊息,父文檔檢索器首先從向量儲存中獲取子文檔。然後,它會尋找這些子文檔的父 ID,並傳回對應的較大父文檔。
我們問一個問題:
情境壓縮鏈
讓我們看看另一個高級 RAG 選項,稱為 上下文壓縮。檢索的一項挑戰是,當您將資料提取到系統中時,我們通常不知道文檔儲存系統將面臨的特定查詢。這意味著與查詢最相關的資訊可能被隱藏在包含大量不相關文字的文件中。透過您的申請傳遞完整的文件可能會導致更昂貴的法學碩士通話和更差的回應。
上下文壓縮檢索器解決了從文件儲存系統檢索相關資訊的挑戰,其中相關資料可能隱藏在包含大量文字的文件中。透過根據給定的查詢上下文壓縮和過濾檢索到的文檔,僅傳回最相關的資訊。
要使用上下文壓縮檢索器,您需要:
- 基礎尋回犬 – 這是根據查詢從儲存系統取得文件的初始檢索器
- 文件壓縮器 – 此元件會取得最初擷取的文檔,並透過減少單一文件的內容或完全刪除不相關的文件來縮短它們,使用查詢上下文來確定相關性
使用 LLM 鏈提取器添加上下文壓縮
首先,用一個包裹你的基礎獵犬 ContextualCompressionRetriever。您將添加一個 法學碩士鏈提取器,它將迭代最初返回的文檔,並從每個文檔中僅提取與查詢相關的內容。
使用以下命令初始化鏈 ContextualCompressionRetriever 與 LLMChainExtractor 並透過提示傳遞 chain_type_kwargs 論據。
我們問一個問題:
使用 LLM 鏈過濾器過濾文檔
法學碩士鏈過濾器 是一個稍微簡單但更強大的壓縮器,它使用 LLM 鏈來決定過濾掉最初檢索到的文檔以及返回哪些文檔,而無需操作文檔內容:
使用以下命令初始化鏈 ContextualCompressionRetriever 與 LLMChainFilter 並透過提示傳遞 chain_type_kwargs 論據。
我們問一個問題:
比較結果
下表比較了基於技術的不同查詢的結果。
| 技術 | 查詢 1 | 查詢 2 | 競品對比 |
| AWS 是如何發展的? | 亞馬遜為何成功? | ||
| 常規檢索器鏈輸出 | AWS(亞馬遜網路服務)從最初無利可圖的投資發展成為年收入運行率高達 85B 美元且盈利能力強勁的業務,提供廣泛的服務和功能,並成為亞馬遜產品組合的重要組成部分。儘管面臨質疑和短期阻力,AWS 仍持續創新、吸引新客戶並遷移活躍客戶,提供敏捷性、創新、成本效益和安全性等優勢。 AWS 還擴大了其長期投資,包括晶片開發,以提供新功能並改變客戶的可能性。 | 亞馬遜的成功得益於其不斷創新和擴展到新領域,例如技術基礎設施服務、數位閱讀設備、語音驅動的個人助理以及第三方市場等新商業模式。從其履行和運輸網路的快速擴張可以看出,其快速擴展業務的能力也有助於其成功。此外,亞馬遜注重流程優化和效率提升,從而提高了生產力並降低了成本。亞馬遜商業的例子凸顯了該公司在不同領域利用其電子商務和物流優勢的能力。 | 根據常規檢索器鏈的響應,我們注意到,儘管它提供了很長的答案,但它存在上下文溢出問題,並且未能提及語料庫中有關響應所提供查詢的任何重要細節。常規檢索鏈無法捕捉深度或上下文洞察的細微差別,可能會遺失文件的關鍵方面。 |
| 父親文檔檢索器輸出 | AWS(亞馬遜網路服務)於 2 年首次推出功能貧乏的彈性運算雲端 (EC2006) 服務,僅在世界某個地區的一個資料中心提供一個實例大小,且僅使用 Linux 作業系統實例,並且沒有許多關鍵功能,如監控、負載平衡、自動擴充或持久性儲存。然而,AWS 的成功使他們能夠快速迭代並添加缺少的功能,最終擴展到提供各種風格、大小以及運算、儲存和網路的最佳化,並開發自己的晶片 (Graviton) 以進一步提高價格和效能。 AWS 的迭代創新流程需要 20 多年的時間對財務和人力資源進行大量投資,通常遠早於支出,以滿足客戶需求並改善長期客戶體驗、忠誠度和股東回報。 | 亞馬遜的成功得益於其不斷創新、適應不斷變化的市場條件並滿足各個細分市場客戶需求的能力。這一點在 Amazon Business 的成功中得到了體現,該公司透過為企業客戶提供選擇、價值和便利,年銷售額已增長至約 35B 美元。亞馬遜在電子商務和物流能力方面的投資也催生了 Buy with Prime 等服務,幫助擁有直接面向消費者網站的商家推動從瀏覽到購買的轉換。 | 父文檔檢索器更深入研究了 AWS 成長策略的細節,包括根據客戶回饋添加新功能的迭代過程,以及從功能貧乏的初始發佈到佔據市場主導地位的詳細過程,同時提供上下文豐富的回應。回應涵蓋了廣泛的方面,從技術創新和市場策略到組織效率和客戶關注點,提供了對成功因素的整體看法並提供了範例。這可以歸因於父文檔檢索器具有針對性且廣泛的搜尋功能。 |
| LLM 鏈提取器:上下文壓縮輸出 | AWS 最初是亞馬遜內部的一個小項目,需要大量的資本投資,並面臨來自公司內部和外部的質疑。然而,AWS 相對於潛在競爭對手處於領先地位,並相信它能為客戶和亞馬遜帶來的價值。 AWS 做出了持續投資的長期承諾,從而在 3,300 年推出了 2022 多項新功能和服務。AWS 改變了客戶管理其技術基礎設施的方式,並已成為年收入 85B 美元、盈利能力強勁的企業。 AWS 也持續改進其產品,例如在首次推出後透過附加功能和服務增強 EC2。 | 根據所提供的背景,亞馬遜的成功可歸因於其從圖書銷售平台到擁有充滿活力的第三方賣家生態系統的全球市場的戰略擴張、對 AWS 的早期投資、引入 Kindle 和 Alexa 的創新以及大幅增長2019 年至2022 年的年收入增加。這種增長導致了履行中心佔地面積的擴大、最後一英里運輸網絡的創建以及新的分揀中心網絡的建設,這些網絡針對生產力和成本降低進行了優化。 | LLM鏈提取器在全面覆蓋要點和避免不必要的深度之間保持平衡。它會動態調整查詢的上下文,因此輸出是直接相關且全面的。 |
| LLM 鏈過濾器:上下文壓縮輸出 | AWS(亞馬遜網路服務)最初推出的功能貧乏,但根據客戶回饋快速迭代以添加必要的功能,從而不斷發展。這種方法使 AWS 能夠在 2 年推出功能有限的 EC2006,然後不斷添加新功能,例如額外的執行個體大小、資料中心、區域、作業系統選項、監控工具、負載平衡、自動擴展和持久性儲存。隨著時間的推移,AWS 透過專注於客戶需求、敏捷性、創新、成本效率和安全性,從功能匱乏的服務轉變為價值數十億美元的業務。 AWS 目前的年收入運作率為 85B 美元,每年提供 3,300 多項新功能和服務,滿足從新創公司到跨國公司和公共部門組織的廣泛客戶需求。 | 亞馬遜的成功得益於其創新的商業模式、持續的技術進步和策略組織變革。該公司不斷透過引入新理念來顛覆傳統產業,例如各種產品和服務的電子商務平台、第三方市場、雲端基礎設施服務 (AWS)、Kindle 電子閱讀器和 Alexa 語音驅動的個人助理。此外,亞馬遜還進行了結構性改革以提高效率,例如重組其美國配送網路以降低成本和縮短交貨時間,進一步促進其成功。 | 與 LLM 鏈提取器類似,LLM 鏈過濾器可確保雖然涵蓋了關鍵點,但對於尋求簡潔和上下文答案的客戶來說,輸出是有效的。 |
透過比較這些不同的技術,我們可以看到,在詳細描述AWS 從簡單服務到複雜的數十億美元實體的轉變,或解釋亞馬遜的戰略成功等上下文中,常規檢索器鏈缺乏更複雜的技術所提供的精確度,導致資訊的針對性較差。儘管所討論的先進技術之間幾乎沒有明顯的差異,但它們比常規檢索器鏈提供的資訊豐富得多。
對於醫療保健、電信和金融服務等行業希望在其應用程式中實施RAG 的客戶來說,常規檢索器鏈在提供精度、避免冗餘和有效壓縮資訊方面的限制使其不太適合滿足這些需求。到更先進的父文檔檢索器和上下文壓縮技術。這些技術能夠將大量資訊提煉成您所需的集中、有影響力的見解,同時幫助提高性價比。
清理
運行完筆記本後,刪除您建立的資源,以避免對正在使用的資源產生費用:
結論
在這篇文章中,我們提出了一個解決方案,讓您可以實作父文檔檢索器和上下文壓縮鏈技術,以增強法學碩士處理和產生資訊的能力。我們使用 SageMaker JumpStart 提供的 Mixtral-8x7B Instruct 和 BGE Large En 模型測試了這些先進的 RAG 技術。我們還探索了使用持久性儲存進行嵌入和文件區塊以及與企業資料儲存的整合。
我們所採用的技術不僅改進了法學碩士模型存取和整合外部知識的方式,而且還顯著提高了其輸出的品質、相關性和效率。透過將大型文本語料庫的檢索與語言生成功能相結合,這些先進的 RAG 技術使法學碩士能夠產生更真實、連貫且適合上下文的回應,從而增強其在各種自然語言處理任務中的表現。
SageMaker JumpStart 是此解決方案的核心。透過 SageMaker JumpStart,您可以存取各種開源和閉源模型,從而簡化 ML 入門流程並實現快速實驗和部署。若要開始部署此解決方案,請導覽至 GitHub回購.
關於作者
 尼森·維傑斯瓦蘭 是 AWS 的解決方案架構師。他的重點領域是生成式 AI 和 AWS AI 加速器。他擁有電腦科學和生物資訊學士學位。 Niithiyn 與 Generative AI GTM 團隊密切合作,在多個方面為 AWS 客戶提供支持,並加速他們對生成式 AI 的採用。他是達拉斯小牛隊的狂熱粉絲,喜歡收集運動鞋。
尼森·維傑斯瓦蘭 是 AWS 的解決方案架構師。他的重點領域是生成式 AI 和 AWS AI 加速器。他擁有電腦科學和生物資訊學士學位。 Niithiyn 與 Generative AI GTM 團隊密切合作,在多個方面為 AWS 客戶提供支持,並加速他們對生成式 AI 的採用。他是達拉斯小牛隊的狂熱粉絲,喜歡收集運動鞋。
 塞巴斯蒂安·布斯蒂略 是 AWS 的解決方案架構師。他專注於人工智慧/機器學習技術,對生成式人工智慧和運算加速器充滿熱情。在 AWS,他幫助客戶透過生成式 AI 釋放商業價值。當他不工作時,他喜歡沖泡一杯完美的精品咖啡,並與妻子一起探索世界。
塞巴斯蒂安·布斯蒂略 是 AWS 的解決方案架構師。他專注於人工智慧/機器學習技術,對生成式人工智慧和運算加速器充滿熱情。在 AWS,他幫助客戶透過生成式 AI 釋放商業價值。當他不工作時,他喜歡沖泡一杯完美的精品咖啡,並與妻子一起探索世界。
 阿曼多·迪亞茲 是 AWS 的解決方案架構師。他專注於生成人工智慧、人工智慧/機器學習和數據分析。在 AWS,Armando 幫助客戶將尖端的生成式 AI 功能整合到他們的系統中,從而促進創新和競爭優勢。當他不工作時,他喜歡與妻子和家人共度時光、遠足和環遊世界。
阿曼多·迪亞茲 是 AWS 的解決方案架構師。他專注於生成人工智慧、人工智慧/機器學習和數據分析。在 AWS,Armando 幫助客戶將尖端的生成式 AI 功能整合到他們的系統中,從而促進創新和競爭優勢。當他不工作時,他喜歡與妻子和家人共度時光、遠足和環遊世界。
 法魯克·薩比爾博士 是 AWS 的高級人工智能和機器學習專家解決方案架構師。 他擁有德克薩斯大學奧斯汀分校的電氣工程博士和碩士學位,以及佐治亞理工學院的計算機科學碩士學位。 他擁有超過 15 年的工作經驗,也喜歡教授和指導大學生。 在 AWS,他幫助客戶制定和解決他們在數據科學、機器學習、計算機視覺、人工智能、數值優化和相關領域的業務問題。 他和他的家人居住在得克薩斯州達拉斯,喜歡旅行和長途旅行。
法魯克·薩比爾博士 是 AWS 的高級人工智能和機器學習專家解決方案架構師。 他擁有德克薩斯大學奧斯汀分校的電氣工程博士和碩士學位,以及佐治亞理工學院的計算機科學碩士學位。 他擁有超過 15 年的工作經驗,也喜歡教授和指導大學生。 在 AWS,他幫助客戶制定和解決他們在數據科學、機器學習、計算機視覺、人工智能、數值優化和相關領域的業務問題。 他和他的家人居住在得克薩斯州達拉斯,喜歡旅行和長途旅行。
 馬可普尼奧 是一名解決方案架構師,專注於生成式 AI 策略、應用 AI 解決方案和進行研究以協助客戶在 AWS 上實現超大規模。 Marco 是一位數位原生雲端顧問,在金融科技、醫療保健和生命科學、軟體即服務以及最近的電信行業擁有豐富的經驗。他是一位合格的技術專家,對機器學習、人工智慧和併購充滿熱情。 Marco 住在華盛頓州西雅圖,喜歡在空閒時間寫作、閱讀、運動和建立應用程式。
馬可普尼奧 是一名解決方案架構師,專注於生成式 AI 策略、應用 AI 解決方案和進行研究以協助客戶在 AWS 上實現超大規模。 Marco 是一位數位原生雲端顧問,在金融科技、醫療保健和生命科學、軟體即服務以及最近的電信行業擁有豐富的經驗。他是一位合格的技術專家,對機器學習、人工智慧和併購充滿熱情。 Marco 住在華盛頓州西雅圖,喜歡在空閒時間寫作、閱讀、運動和建立應用程式。
 AJ 迪米內 是 AWS 的解決方案架構師。他專注於生成人工智慧、無伺服器運算和數據分析。他是機器學習技術領域社群的活躍成員/導師,並發表了多篇有關各種 AI/ML 主題的科學論文。他與從新創公司到大型企業的客戶合作開發 AWSome 生成式人工智慧解決方案。他特別熱衷於利用大型語言模型進行高階數據分析,並探索解決現實世界挑戰的實際應用程式。工作之餘,AJ 喜歡旅行,目前已去過 53 個國家/地區,目標是造訪世界上每個國家。
AJ 迪米內 是 AWS 的解決方案架構師。他專注於生成人工智慧、無伺服器運算和數據分析。他是機器學習技術領域社群的活躍成員/導師,並發表了多篇有關各種 AI/ML 主題的科學論文。他與從新創公司到大型企業的客戶合作開發 AWSome 生成式人工智慧解決方案。他特別熱衷於利用大型語言模型進行高階數據分析,並探索解決現實世界挑戰的實際應用程式。工作之餘,AJ 喜歡旅行,目前已去過 53 個國家/地區,目標是造訪世界上每個國家。

