
图片作者
支撑数据科学的领域之一是机器学习。因此,如果您想进入数据科学领域,了解机器学习是您需要采取的第一步。
但你从哪儿开始呢?您首先要了解两种主要类型的机器学习算法之间的区别。只有在那之后,我们才能讨论初学者应该优先学习的各个算法。
算法之间的主要区别在于它们的学习方式。

图片作者
监督学习算法 接受训练 标记数据集。该数据集充当学习的监督(因此得名),因为它包含的一些数据已经被标记为正确答案。基于此输入,算法可以学习并将该学习应用到其余数据。
另一方面, 无监督学习算法 学习在 未标记的数据集,这意味着它们可以在没有人类指导的情况下寻找数据模式。
您可以阅读更多详细信息 机器学习算法 和学习类型。
还有一些其他类型的机器学习,但不适合初学者。
每种类型的机器学习都采用算法来解决两个主要的不同问题。
同样,还有一些任务,但它们不适合初学者。

图片作者
监督学习任务
数据复原测试 是预测一个的任务 数值,被称为 连续结果变量或因变量。预测基于预测变量或自变量。
考虑预测油价或气温。
分类 用于预测 类别(类别) 输入数据的。这 结果变量 这是 分类或离散.
考虑预测邮件是否是垃圾邮件,或者患者是否会患上某种疾病。
无监督学习任务
聚类 手段 将数据划分为子集或簇。目标是尽可能自然地对数据进行分组。这意味着同一簇内的数据点彼此之间比其他簇中的数据点更相似。
降维 指减少数据集中输入变量的数量。这基本上意味着 将数据集减少到很少的变量,同时仍然捕捉其本质.
以下是我将介绍的算法的概述。
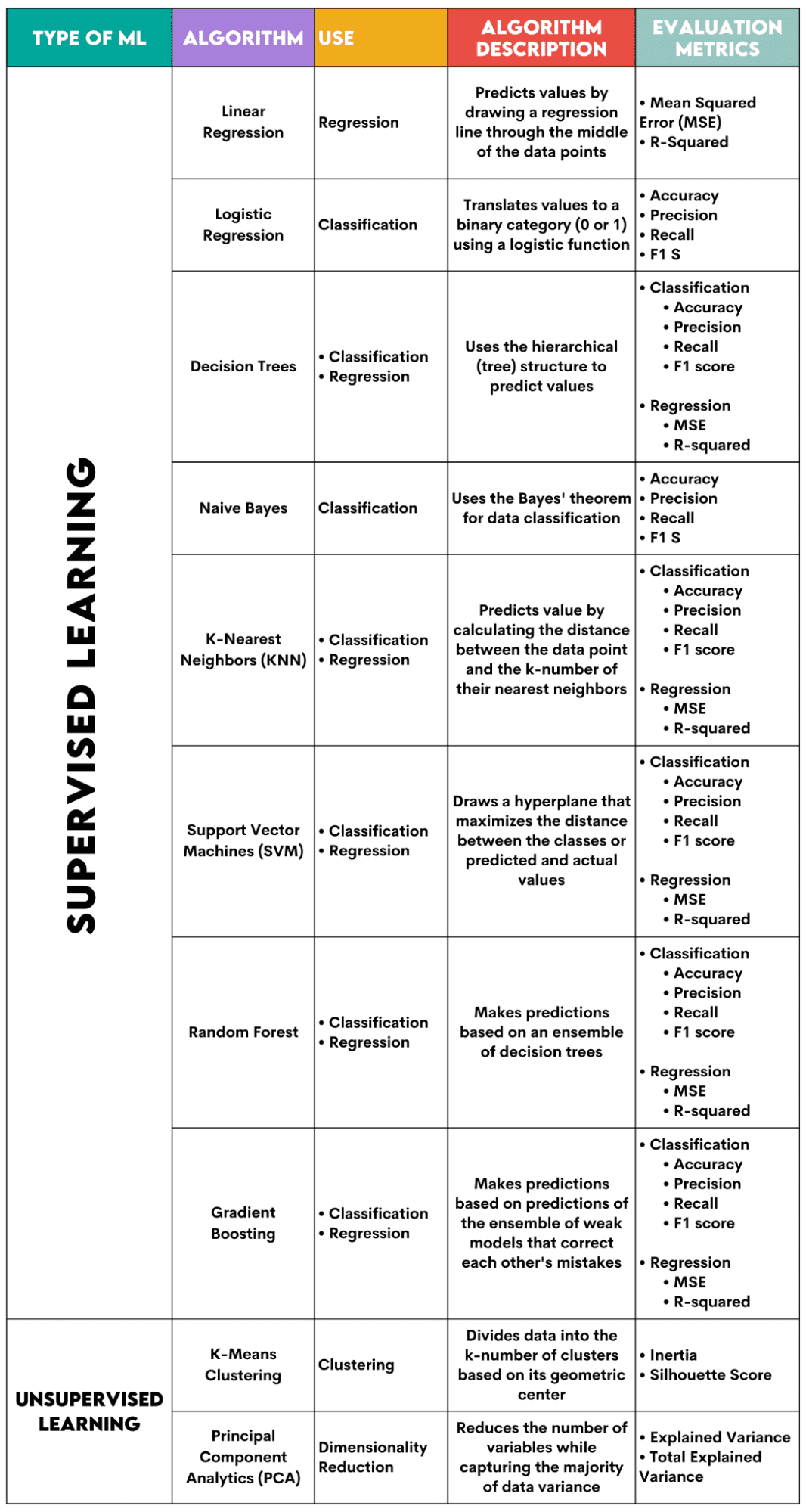
图片作者
监督学习算法
在为您的问题选择算法时,了解该算法用于什么任务非常重要。
作为一名数据科学家,您可能会使用以下方法在 Python 中应用这些算法 scikit学习库。尽管它(几乎)可以为您完成所有工作,但建议您至少了解每种算法内部工作原理的一般原理。
最后,在训练算法之后,您应该评估它的性能。为此,每种算法都有一些标准指标。
1. 线性回归
用于: 数据复原测试
描述: 线性回归画一条直线 称为变量之间的回归线。这条线大约穿过数据点的中间,从而最大限度地减少估计误差。它显示基于自变量值的因变量的预测值。
评估指标:
- 均方误差 (MSE):表示平方误差的平均值,该误差是实际值与预测值之间的差异。值越低,算法性能越好。
- R-平方:表示自变量可以预测的因变量的方差百分比。对于此度量,您应该努力使其尽可能接近 1。
2.逻辑回归
用于: 分类
描述: 它使用 逻辑函数 将数据值转换为二进制类别,即 0 或 1。这是使用阈值完成的,通常设置为 0.5。二进制结果使该算法非常适合预测二进制结果,例如 YES/NO、TRUE/FALSE 或 0/1。
评估指标:
- 准确度:正确预测与总体预测之间的比率。越接近1越好。
- Precision:模型在积极预测中的准确性的衡量标准;显示为正确的积极预测与总预期积极结果之间的比率。越接近1越好。
- 回想一下:它也衡量模型在积极预测中的准确性。它表示为正确的积极预测与课堂上进行的总观察之间的比率。阅读有关这些指标的更多信息 此处.
- F1分数:模型召回率和精度的调和平均值。越接近1越好。
3. 决策树
用于: 回归与分类
描述: 决策树 是使用分层或树结构来预测值或类别的算法。根节点代表整个数据集,然后根据变量值分为决策节点、分支和叶子。
评估指标:
- 准确率、精确率、召回率和 F1 分数 -> 用于分类
- MSE,R 平方 -> 用于回归
4. 朴素贝叶斯
用于: 分类
描述: 这是一系列分类算法,使用 贝叶斯定理,这意味着它们假设类内的特征之间是独立的。
评估指标:
- 准确性
- 平台精度
- 记得
- F1分数
5.K-最近邻(KNN)
用于: 回归与分类
描述: 它计算测试数据与实际数据之间的距离 k-最近数据点的数量 从训练数据中。测试数据属于“邻居”数量较多的类别。对于回归,预测值是选择的 k 个训练点的平均值。
评估指标:
- 准确率、精确率、召回率和 F1 分数 -> 用于分类
- MSE,R 平方 -> 用于回归
6. 支持向量机(SVM)
用于: 回归与分类
描述: 该算法绘制了一个 超平面 分离不同类别的数据。它位于距每个类别最近点的最大距离处。数据点与超平面的距离越远,它就越属于它的类别。对于回归,原理类似:超平面最大化预测值和实际值之间的距离。
评估指标:
- 准确率、精确率、召回率和 F1 分数 -> 用于分类
- MSE,R 平方 -> 用于回归
7. 随机森林
用于: 回归与分类
描述: 随机森林算法 使用决策树集合,然后形成决策森林。该算法的预测是基于许多决策树的预测。数据将分配给获得最多票数的类别。对于回归,预测值是所有树的预测值的平均值。
评估指标:
- 准确率、精确率、召回率和 F1 分数 -> 用于分类
- MSE,R 平方 -> 用于回归
8. 梯度提升
用于: 回归与分类
描述: 这些算法 使用一组弱模型,每个后续模型都会识别并纠正先前模型的错误。重复这个过程直到误差(损失函数)最小化。
评估指标:
- 准确率、精确率、召回率和 F1 分数 -> 用于分类
- MSE,R 平方 -> 用于回归
无监督学习算法
9. K-Means 聚类
用于: 聚类
描述: 算法 将数据集划分为 k 个簇,每个簇由其代表 质心或几何中心。通过将数据划分为 k 个簇的迭代过程,目标是最小化数据点与其簇质心之间的距离。另一方面,它还尝试最大化这些数据点与其他簇质心的距离。简单来说,属于同一簇的数据应该与其他簇的数据尽可能相似,并且尽可能不同。
评估指标:
- 惯量:每个数据点到最近的簇质心的距离的平方和。惯性值越低,集群越紧凑。
- Silhouette Score:它衡量簇的内聚性(数据在其自身簇内的相似性)和分离性(数据与其他簇的差异)。该分数的值范围为 -1 到 +1。值越高,数据与其集群的匹配程度越高,与其他集群的匹配程度越差。
10.主成分分析(PCA)
用于: 降维
描述: 算法 通过构造新变量(主成分)减少使用的变量数量,同时仍尝试最大化捕获的数据方差。换句话说,它将数据限制为其最常见的组成部分,同时又不丢失数据的本质。
评估指标:
- 解释方差:每个主成分覆盖的方差百分比。
- 总解释方差:所有主成分覆盖的方差百分比。
机器学习是数据科学的重要组成部分。通过这十种算法,您将涵盖机器学习中最常见的任务。当然,本概述仅让您大致了解每种算法的工作原理。所以,这只是一个开始。
现在,你需要学习如何在Python中实现这些算法并解决实际问题。在这方面,我建议使用 scikit-learn。不仅因为它是一个相对易于使用的 ML 库,还因为它 广泛的材料 关于机器学习算法。
内特·罗西迪 是一名数据科学家,负责产品策略。他还是教授分析学的兼职教授,并且是 StrataScratch 的创始人,该平台帮助数据科学家利用顶级公司的真实面试问题准备面试。 Nate 撰写有关职业市场最新趋势的文章、提供面试建议、分享数据科学项目,并涵盖 SQL 的所有内容。
- SEO 支持的内容和 PR 分发。 今天得到放大。
- PlatoData.Network 垂直生成人工智能。 赋予自己力量。 访问这里。
- 柏拉图爱流。 Web3 智能。 知识放大。 访问这里。
- 柏拉图ESG。 碳, 清洁科技, 能源, 环境, 太阳能, 废物管理。 访问这里。
- 柏拉图健康。 生物技术和临床试验情报。 访问这里。
- Sumber: https://www.kdnuggets.com/a-beginner-guide-to-the-top-10-machine-learning-algorithms?utm_source=rss&utm_medium=rss&utm_campaign=a-beginners-guide-to-the-top-10-machine-learning-algorithms

