Bài báo này đã được xuất bản như một phần của Blogathon Khoa học Dữ liệu.
Giới thiệu về Người giới thiệu nhà hàng
Bây giờ hãy tưởng tượng lần cuối cùng khi bạn muốn đặt một số quần áo và điều bạn biết là bạn muốn có được một chiếc áo sơ mi / áo sơ mi với họa tiết chấm bi như thời trang của chúng nhưng một khi bạn đã ở trên amazon, bạn phải vật lộn trong việc tìm kiếm thiết kế tốt nhất như có thể có hơn hàng triệu chiếc áo sơ mi họa tiết chấm bi trong trường hợp đó, điều bạn thích là cuộn đến phần được đề xuất và 40% số lần bạn đặt mua các mặt hàng từ các tab được đề xuất.
Vì vậy, vấn đề này giải thích cho các giao dịch mua hàng lớn trong thương mại điện tử và các ứng dụng dựa trên nội dung điện tử, không chỉ hai thứ này mà danh sách này cứ tiếp diễn.
Nghiên cứu điển hình này được xây dựng dựa trên bộ dữ liệu được cung cấp bởi www.akeedapp.com là một ứng dụng giao đồ ăn trực tuyến dựa trên Muscat. Nó cho phép khách hàng ở Oman đặt món ăn từ các nhà hàng yêu thích của họ và được giao đến địa chỉ của họ. Tập dữ liệu cho cuộc thi này đã được công khai tại đây và cuộc thi này đã kết thúc vào ngày 16 tháng 2020 năm XNUMX.
Cuộc thi dựa trên phương pháp tiếp cận học tập có giám sát mà bạn được đưa ra với mục tiêu là liệu một khách hàng có khả năng đặt món ăn từ một nhà cung cấp hay không dựa trên nhiều thông tin khác nhau về cả khách hàng và nhà cung cấp. Nhưng chúng tôi sẽ sử dụng điều này như một cách tiếp cận học tập không giám sát, nơi chúng tôi sẽ sử dụng tất cả dữ liệu quan trọng để tìm ra nơi khách hàng có thể đặt món ăn của mình, điều này sẽ tiết kiệm thời gian và công sức của họ và do đó, đặt món ăn nhiều hơn.
Ở đây, chúng tôi được cung cấp các tệp CSV khác nhau, mỗi tệp có các giá trị cụ thể, chẳng hạn như khách hàng.csv có các giá trị của khoảng 15500 người dùng khác nhau sẽ có liên quan để dự đoán việc mua hàng của khách hàng, nhà cung cấp.csv bao gồm 100 nhà cung cấp duy nhất cho biết về xếp hạng nhà cung cấp, sản phẩm mà họ phục vụ và order.csv hoạt động như một bảng tham gia có thể được sử dụng để nối tất cả các tệp csv và tạo một ma trận mới.
Vấn đề kinh doanh
=> Đề xuất các nhà cung cấp / nhà hàng cho người tiêu dùng mà họ có nhiều khả năng đặt hàng nhất
Đường ống dòng chảy
Xử lý trước dữ liệu => Tạo đối tượng => Phân tích dữ liệu khám phá => đặt vấn đề này là bài toán hồi quy với xếp hạng thứ tự là mục tiêu => tìm tính năng quan trọng bằng cách chỉnh sửa một chút với các tính năng như thêm tính năng hoàn thành ma trận => tính quan trọng của đồ thị và chỉ lấy những các tính năng có tác động đáng kể => tạo ma trận mới chỉ sử dụng các yếu tố quan trọng và xây dựng sự tương đồng giữa người dùng-người dùng, nhà cung cấp => dự đoán hầu hết các nhà cung cấp tương tự với xếp hạng trung bình cao hơn 4 dựa trên sự tương đồng giữa người dùng và nhà cung cấp
Chỉ số lỗi
ở đây vì chúng tôi đặt đây là một vấn đề hồi quy, do đó số liệu tốt nhất mà chúng tôi có thể sử dụng là Lỗi bình phương trung bình gốc (RMSE) nằm trong khoảng (0-4). Bình phương trung bình gốc chính xác như đã đặt tên, ở đây xi là giá trị thực trong khi x ^ i là giá trị dự đoán hoặc đầu ra mô hình và N ở đây là tổng số hàng trong tập dữ liệu

1. Tải dữ liệu
bạn có thể tải xuống dữ liệu từ tại đây. Dữ liệu chúng tôi sẽ cho chúng tôi
- train_locations.csv - vĩ độ và kinh độ cho các vị trí khác nhau của từng khách hàng.
- train_customers.csv - thông tin chi tiết của từng khách hàng.
- order.csv - đơn đặt hàng mà khách hàng đào tạo_customers.csv thực hiện.
- nhà cung cấp.csv - nhà cung cấp mà khách hàng có thể đặt hàng.
Nhập dữ liệu này vào cùng một thư mục nơi bạn sẽ tạo sổ ghi chép của mình. Như bạn có thể thấy dữ liệu ở đây bao gồm 4 tệp khác nhau, vì vậy chúng tôi cần xử lý trước từng tệp và nối chúng dựa trên khóa ngoại chính của chúng, chúng tôi sẽ sử dụng phương pháp nối bên trong để hợp nhất tất cả các tệp dựa trên customer_id và vendor_id từ order.csv.
2. Nhập thư viện
import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns from datetime import datetime from time import mktime from xgboost import XGBRegressor, plot_importance from sklearn.model_selection import train_test_split, GridSearchCV from sklearn.metrics import hasrsine nhập radian, sqrt từ tqdm nhập tqdm từ nhập bất ngờ Reader, Dataset, BaselineOnly, SVDpp, KNNBaseline từ tensorflow.test nhập gpu_device_name nhập dưa chua từ sklearn.metrics nhập mean_squared_error, make_scorer từ chế độ nhập thống kê cảnh báo nhập khẩu cảnh báo.filterwarnings ('bỏ qua')
3. Xử lý trước dữ liệu
Đây là bước quan trọng vì có rất nhiều tính năng không hữu ích và không có tầm quan trọng bằng cách chỉ có một giá trị duy nhất hoặc có, vì vậy chúng ta cần loại bỏ từng tính năng bắt đầu bằng
Nhà cung cấp.csv
Tệp vendors.csv chứa khoảng 56 tính năng và hầu hết chúng đều vô dụng. chúng tôi phải tìm các tính năng vô dụng loại bỏ chúng, kiểm tra xem một số tính năng có yêu cầu sửa đổi hoặc nâng cấp tính năng nào đó hay không, sau đó thay thế tất cả các giá trị NaN bằng giá trị thay thế tốt nhất dựa trên các giá trị tính năng tương ứng của chúng.
Khách hàng.csv
Tệp customer.csv chứa khoảng 8 tính năng mà từ đó DOB, trạng thái, tạo_at và cập nhật_at không hữu ích vì DOB rất thưa thớt trong khi trạng thái chỉ chứa 35 giá trị có trạng thái = 0 từ 34674 giá trị và điều này sẽ ảnh hưởng đến các mô hình cuối của chúng tôi. Vì vậy, tốt hơn là loại bỏ cả những hàng có trạng thái = 0
Order.csv
Order.csv chứa 26 tính năng nhưng ở đây chúng tôi có thể thấy hầu hết mọi người đã xếp hạng 0, điều này là không thể. cần xóa tất cả các hàng không được xếp hạng và tất cả những hàng có xếp hạng là 0
Vì ngày giao hàng cho hầu hết các hàng không có giá trị nên không thể sử dụng để xác định dữ liệu về bản chất là thời gian, trong khi chúng ta có thể tạo một thời gian tính năng mới được thực hiện là thời gian từ đó thực phẩm được đặt hàng cho đến khi đơn đặt hàng nào được khách hàng nhận nhiều nhất khách hàng không quan tâm đến thời gian chuẩn bị và thời gian giao hàng. Họ chỉ quan tâm đến việc một khi họ đặt đồ ăn, mất bao lâu để một ứng dụng giao hàng cho họ.
Bây giờ, hãy bỏ tất cả các tính năng vô dụng không tăng thêm giá trị là order_accepted_time, driver_accepted_time, ready_for_pickup_time, delivery_time
Hợp nhất tất cả để tạo Final.csv
Tạo khung dữ liệu cuối cùng bằng cách tham gia cung cấp cho nhà cung cấp.csv, khách hàng.csv trên đơn đặt hàng.csv sử dụng phương pháp kết hợp bên trong

bản quyền https://www.softwaretestinghelp.com/inner-join-vs-outer-join/
Bây giờ hãy áp dụng khoảng cách hasrsine để tìm khoảng cách địa lý giữa vị trí của khách hàng và vị trí của nhà cung cấp.
Cả hai đều giống nhau và chúng tôi có thể bỏ một thẻ từ cả hai, vì vậy chúng tôi muốn bỏ thẻ nhà cung cấp và sử dụng tên thẻ nhà cung cấp để tạo một tính năng mới và chuyển đổi tất cả customer_id từ chuỗi số nguyên
4. Phân tích dữ liệu khám phá
Ở đây, chúng tôi cố gắng tìm ra một số thông tin chi tiết hữu ích về dữ liệu sau khi chúng tôi thực hiện xong tất cả việc dọn dẹp và xử lý trước dữ liệu vì quá trình xử lý dữ liệu chỉ là đặt ra một số câu hỏi hay
Khách hàng đánh giá gì cho nhà hàng trên mỗi đơn đặt hàng?

Nó cho thấy hầu hết người dùng có xu hướng đưa ra xếp hạng nhân hậu tốt hoặc hầu hết các nhà cung cấp đang cung cấp thực phẩm chất lượng cực kỳ tốt
Xếp hạng trung bình trước đây cho mỗi nhà cung cấp trông như thế nào?

Nó cũng cho thấy rằng hầu hết các nhà cung cấp được xếp hạng trung bình từ 4.0 đến 5 và không có nhà cung cấp nào có xếp hạng dưới 3
Khoảng cách giao hàng tính bằng KM cho mỗi đơn hàng là bao nhiêu?

Nó cho thấy khoảng cách giao hàng trung bình là gần 6km với phần trăm thứ 25 gần 3km và phần trăm thứ 75 gần 10km và hầu hết các đơn hàng được giao trong khoảng 10km
Có bao nhiêu khách hàng đặt món ăn từ nhà hàng hoặc nhà cung cấp yêu thích của họ?

ở đây chúng ta có thể thấy rất ít người đặt đồ ăn từ những nhà cung cấp yêu thích
Làm thế nào nhiều đơn đặt hàng một khách hàng?

Ở đây từ cả PDF và CDF, chúng ta có thể thấy rằng hầu hết người dùng có xu hướng đặt rất ít đơn đặt hàng thậm chí dưới 50 trong khi một số khách hàng đặt trên 600 đơn hàng cũng có thể là những cử nhân hoặc sinh viên thường đặt đồ ăn.
Mỗi nhà hàng nhận được bao nhiêu đơn hàng?

Điều này hóa ra hầu hết là cạnh tranh lành mạnh trong khi chỉ 10% nhà cung cấp nhận được hơn 1500 đơn đặt hàng trong một khoảng thời gian nhất định
Có bao nhiêu khách hàng đang đặt hàng từ bao nhiêu nhà hàng khác nhau?

Điều này cho thấy rằng người dùng đã bình chọn cho tối đa 15 nhà cung cấp và dữ liệu trông lành mạnh
5. Hệ thống khuyến nghị
Hệ thống khuyến nghị hoặc hệ thống giới thiệu là một loại hệ thống lọc thông tin sử dụng các tính năng khác nhau được cung cấp về người dùng và sản phẩm và cố gắng dự đoán các cặp tương tự nhất để xác định các sản phẩm tốt nhất theo sở thích của người dùng mà người dùng có nhiều khả năng tiêu thụ nhất và trả lại tích cực Phản hồi. Để áp dụng kỹ thuật nghe có vẻ nặng nề này, những gì nó sử dụng ở trung tâm của nó là khoảng cách, hãy hiểu nó giống như một thứ phân cụm trong đó hầu hết các kỹ thuật tương tự vẫn ở gần nhau và càng gần 2 thứ thì khả năng chúng sẽ giống hệt nhau.
Hệ thống đề xuất thuộc 2 loại
1. Hệ thống đề xuất dựa trên nội dung
Loại hệ thống khuyến nghị này rất hữu ích để giải quyết các vấn đề khởi động nguội. Tại đây, bạn sử dụng thói quen chi tiêu trong quá khứ của người dùng và chi tiết đơn đặt hàng trước đây của họ cùng với hồ sơ trong quá khứ của nhà cung cấp để theo dõi xếp hạng mà họ có nhiều khả năng cung cấp cho đơn đặt hàng cụ thể đó, điều này cuối cùng hóa ra là một trong những loại tập dữ liệu rất quen thuộc của chúng tôi đó là hồi quy. Tại đây, chúng tôi có thể sử dụng xếp hạng nhà cung cấp cho mỗi đơn đặt hàng làm mục tiêu và lấy dữ liệu khác làm đầu vào và đào tạo mô hình Hồi quy giúp chúng tôi dự đoán xếp hạng mà người dùng sẽ đưa ra và dựa vào đó chúng tôi có thể đề xuất những nhà hàng có xu hướng ăn ngon xếp hạng trở lên 4 xếp hạng.
2. Lọc cộng tác
Đây có thể hiểu là những điểm tương đồng giữa 2 thứ dù có thể là người dùng hay vật phẩm. Vì chúng chỉ là những điểm tương đồng nên chúng không phụ thuộc vào việc hiểu dữ liệu hoàn toàn nhưng chúng cũng phát sinh một vấn đề khởi đầu nguội đó là bất cứ khi nào bạn có người dùng mới, phương pháp này không thành công vì bạn không có dữ liệu xếp hạng về người dùng.
Lọc cộng tác giữa người dùng và người dùng
ví dụ: nếu khách hàng 1 đánh giá nhà cung cấp 113, 71, 34 với 5 sao và khách hàng 2 xếp hạng nhà cung cấp 113, 40,71 và bạn biết rằng khách hàng 3 đặt đồ ăn và xếp hạng nhà cung cấp 71 với 5 sao thì khả năng rất cao là anh ta cũng sẽ xếp hạng nhà cung cấp 113 với xếp hạng 5 sao. Tại đây, bạn có thể tìm thấy mức độ giống nhau của cả hai người dùng đang sử dụng ma trận tương tự có thể là bất kỳ nhưng chúng tôi đang sử dụng tính tương tự cosine ở đây là


Đây là một gif rất tốt thể hiện sự tương đồng giữa người dùng và người dùng. Ở đây, bạn có thể thấy câu hỏi cơ bản là liệu người dùng có thích một chiếc máy tính xách tay dựa trên trải nghiệm của họ với bảng điều khiển, sách và một số hình ảnh hay không
Lọc cộng tác mục-mục
Điều này dựa trên sự tương đồng giữa sản phẩm và sản phẩm hoặc trong trường hợp của chúng tôi, chúng tôi có thể nói sự giống nhau giữa nhà hàng và nhà hàng dựa trên thời gian giao thức ăn, các mặt hàng mà họ cung cấp xếp hạng trung bình của nhà cung cấp, v.v. tất cả các tính năng không phụ thuộc đều phụ thuộc vào nhà cung cấp và điều này có thể hiểu được bằng cách ví dụ: khách hàng 1 đặt hàng thức ăn từ nhà cung cấp 113, người cung cấp cho họ món lắc và sinh tố cùng với một chiếc bánh mì kẹp thịt và anh ta cũng đặt hàng thức ăn từ nhà cung cấp 40, người cũng cung cấp món lắc và đồ uống cùng với các loại mì ống thì, trong trường hợp đó, rất có khả năng khách hàng 1 muốn ăn một số thức ăn cùng với đồ lắc hoặc sinh tố mỗi ngày, vì vậy bất cứ khi nào chúng tôi giới thiệu cho họ một khách hàng, chúng tôi cần quan tâm đến đồ uống và giới thiệu những nhà hàng cung cấp thức ăn lắc cùng
6. Lựa chọn mô hình
Từ cuộc thảo luận được tổ chức ở trên, chúng tôi biết rằng chúng tôi cần một mô hình Hồi quy có thể cung cấp cho chúng tôi tầm quan trọng của tính năng vì tầm quan trọng của tính năng sẽ được sử dụng và vì các kích thước ở đây không quá lớn, chúng tôi có thể sử dụng các thuật toán tăng độ dốc hoặc hồi quy tuyến tính nhưng trong khi làm việc với XGBRegression chúng ta cần quan tâm đến việc trang bị quá mức cho các mô hình của mình vì nó có thể là một vấn đề lớn. Ngoài ra, XGBRegression hỗ trợ đào tạo GPU giúp chúng tôi đào tạo mô hình của mình nhanh hơn.
Với cuộc thảo luận này, chúng tôi đủ thuyết phục để sử dụng XGBRegressor làm mô hình hồi quy của chúng tôi
7. Điều chỉnh siêu tham số
Chúng tôi sẽ sử dụng CV tìm kiếm lưới để có được siêu tham số tốt nhất với xgboost và điều này có thể được thực hiện bằng cách sử dụng chức năng này, chúng tôi sẽ sử dụng chức năng tính điểm tự xác định cho điểm RMSE trong hoạt động cv Tìm kiếm lưới với thuật toán XGBoost hỗ trợ GPU
Bây giờ, hãy chuyển kết quả của đoạn mã này sang Hồi quy thực tế của chúng tôi
Ở đây, chúng tôi sẽ sử dụng đầu ra của hàm hyperparamter để tốt nhất cho mô hình đường hầm tốt nhất của chúng tôi, sau đó chúng tôi sẽ vẽ biểu đồ huấn luyện so với tổn thất thử nghiệm cho mỗi công cụ ước tính một sự thay đổi biểu đồ trong RMSE thử nghiệm và huấn luyện RMSE trông như thế nào

Điều này có thể được sử dụng để phát hiện thời tiết một mô hình có quá phù hợp hay không
bây giờ sau khi điều chỉnh mô hình của chúng tôi, chúng tôi sẽ kiểm tra phân phối RMSE sau n công cụ ước tính

Từ đó, chúng tôi có thể quan sát thấy rằng hầu hết các vakue có RMSE <0.5 là tích cực và chúng tôi có thể sử dụng điều này để dự đoán dữ liệu của mình
8. Thư viện bất ngờ
Thư viện Surprise được xây dựng cho các hệ thống đề xuất trong đó nó sử dụng người dùng, mặt hàng và xếp hạng để dự đoán xếp hạng cho tương tác của người dùng với mặt hàng. đối với điều này, nó ngụ ý các mô hình khác nhau như SVD, phân tích nhân tử ma trận KNN và nhiều mô hình khác mà bạn có thể sử dụng để dự đoán và sau này bạn có thể sử dụng chúng như một tính năng và tìm các thay đổi trong giá trị RMSE
Để áp dụng thư viện bất ngờ, chúng ta cần khởi tạo tập dữ liệu của mình dưới dạng tập huấn luyện và tập kiểm tra
từ nhập bất ngờ Reader, Dataset
reader = Reader (rating_scale = (1,5))
# tạo đoạn dữ liệu từ khung dữ liệu ...
train_data = Dataset.load_from_df (X_train [['customer_id', 'vendor_id', 'vendor_rating_x']], trình đọc)
Trainet = train_data.build_full_trainset ()
# chúng tôi chỉ thêm cả hai khi chúng tôi
testset = list (zip (X_test.customer_id.values, X_test.vendor_id.values, X_test.vendor_rating_x.values))
cho đến đây, chúng tôi đã tạo ra các bộ đào tạo và thử nghiệm của mình
Mô hình cơ sở
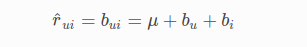
μ: Giá trị trung bình của tất cả các lần đào tạo trong dữ liệu đào tạo.
bu: Thành kiến của người dùng
bi: Item bias (thành kiến về phim)
Ở đây chúng tôi đào tạo mô hình của mình và lưu xếp hạng đầu ra vào cả tệp đào tạo và kiểm tra
Mô hình SVD
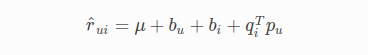
q_i - Biểu diễn của mục (phim) trong không gian yếu tố tiềm ẩn
p_u - Đại diện của người dùng trong không gian yếu tố tiềm ẩn mới
KNN

ở đây cái đầu tiên dựa trên chỉ số người dùng-người dùng trong khi cái thứ hai dựa trên chỉ số mặt hàng
bui - Dự đoán cơ sở xếp hạng của (người dùng, phim)
Nki (u) - Bộ K tương tự người dùng (hàng xóm) của người dùng (u) ai đánh giá phim (i)
sim (u, v) – Tương tự giữa những người dùng u và v
- Nói chung, nó sẽ là tương tự cosine hoặc hệ số tương quan Pearson.
- Nhưng chúng tôi sử dụng hệ số tương quan Pearson-baseline được thu nhỏ, dựa trên sự tương đồng của pearson Baseline (chúng tôi lấy các dự đoán về đường cơ sở thay vì xếp hạng trung bình của người dùng / mặt hàng)
9. Lập kế hoạch kết quả
Bây giờ hãy cho phép biểu đồ tầm quan trọng của tính năng và chỉ lấy một số tính năng hạn chế có xu hướng có tác động đáng kể trong hệ thống khuyến nghị của chúng tôi

Từ đây, chúng ta có thể thấy rằng chúng ta chỉ có thể sử dụng customer_id, grand_total, time_taken, deliverydistance, vendor_rating_y, vendor_id và chuyển nó vào mô hình hồi quy
Thêm từng đầu ra của từng tính năng một vào giá trị huấn luyện và kiểm tra của chúng tôi và sau đó thu được giá trị RMSE cho từng mô hình hồi quy với các tính năng khác nhau mà chúng tôi thu được

Ở đây, chúng ta có thể quan sát thấy rằng các mô hình với các tính năng rất hạn chế có xu hướng cho kết quả tốt hơn các mô hình có các tính năng bổ sung, điều này cũng làm rõ một quan niệm sai lầm của nhiều người rằng dữ liệu nhiều chiều hơn luôn có xu hướng cho kết quả tốt hơn
10. Phương pháp tiếp cận dựa trên lọc cộng tác với các tính năng đã chọn
Sự giống nhau giữa khách hàng và khách hàng
Bây giờ, chúng tôi sẽ sử dụng các tính năng đã được sử dụng trong các tính năng đã chọn để xây dựng chỉ số bằng cách đưa ra tất cả các tiêu chuẩn tính năng và tính toán tính tương đồng cosin giữa từng tính năng của mỗi hàng và cuối cùng sẽ sử dụng điều này để tính toán các chỉ số tổng thể
Sự giống nhau giữa nhà cung cấp và nhà cung cấp
Ở đây, chúng tôi đã được cung cấp 100 nhà cung cấp khác nhau và chúng tôi sẽ sử dụng các tính năng đã chọn ngoại trừ cả customer_id và vendor_id để có được các chỉ số tương đồng cosine giữa cả hai
Điều này có thể được thực hiện bằng cách sử dụng
11. Kiểm tra
chúng tôi có thể kiểm tra hệ thống giới thiệu của mình bằng cách sử dụng
nhập id khách hàng trong khoảng 0-100
4 ************************************************* ************************************************** * các nhà cung cấp được đề xuất hàng đầu là ********************************************* ************************************************** ***** 1 bạn có thể đăng ký nhà cung cấp với id: 113 2 bạn có thể đăng ký nhà cung cấp với id: 298 3 bạn có thể đăng ký nhà cung cấp với id: 310
12. Triển khai
Để triển khai mã này, chúng tôi sẽ sử dụng stream lit và heroku để triển khai
Ở đây chúng tôi tạo một thanh trượt cho id khách hàng nằm trong phạm vi -1,1000 ở đây nếu id khách hàng được để -1 hơn nó cho phép tùy chọn đề xuất theo nhà cung cấp và tìm kiếm hầu hết các nhà cung cấp tương tự theo mối quan hệ giữa nhà cung cấp và nhà cung cấp

Khác nó hoạt động dựa trên sự giống nhau của khách hàng

Kết luận về Người giới thiệu
Nghiên cứu điển hình này thảo luận về các phương pháp tiếp cận khác nhau có thể được sử dụng trong quá trình xây dựng hệ thống khuyến nghị thông thường khi chúng tôi sửa đổi cách sử dụng của tập dữ liệu này, do đó chúng tôi không thể so sánh nó với những người khác. Chúng tôi cũng biết rằng không phải ngày càng nhiều tính năng luôn tốt, đôi khi việc loại bỏ một số tính năng sẽ làm tăng giá trị đáng kể cho các mô hình của chúng tôi và nghiên cứu điển hình này cũng thảo luận về cách tiếp cận để hiểu một doanh nghiệp trước khi giải quyết một vấn đề mà nếu không có thì chúng tôi đã thắng ' không thể thấy rằng chúng tôi cần loại bỏ xếp hạng 0 với tỷ lệ xuất hiện cao.
Khi đường cong giá trị RMSE cho thấy rằng ngay cả khi giá trị trung bình gần 0.75 trung bình thấp hơn 0.5, có nghĩa là có rất nhiều cơ hội đề xuất chính xác cũng nhìn thấy đường cong RMSE thử nghiệm đào tạo của chúng tôi trên mỗi kỷ nguyên, chúng tôi biết rằng cả mô hình của chúng tôi không phù hợp cũng như không quá phù hợp
Chúng tôi có thể sử dụng sự tương đồng giữa khách hàng và khách hàng để dự đoán với một số thông số đã chọn
Những điều rút ra về Người giới thiệu
- Chúng tôi đã thảo luận về các cách tiếp cận khác nhau để xây dựng hệ thống tư vấn
- Loại bỏ tính năng cũng có thể dẫn đến tăng hiệu suất của mô hình
- Các cách chuyển đổi vấn đề hệ thống khuyến nghị thành vấn đề hồi quy
- Đã học cách sử dụng thư viện bất ngờ để nhận các tính năng mới
Bạn có thể nhận được máy tính xách tay ipython từ đây
Phương tiện hiển thị trong bài viết này không thuộc sở hữu của Analytics Vidhya và được sử dụng theo quyết định riêng của Tác giả.

