
Hình ảnh của Gerd Altmann từ Pixabay
Khoảng một tháng trước, OpenAI đã thông báo rằng ChatGPT hiện có thể nhìn, nghe và nói. Điều này có nghĩa là mô hình này có thể giúp bạn thực hiện nhiều công việc hàng ngày hơn. Ví dụ: bạn có thể tải lên hình ảnh những thứ trong tủ lạnh của bạn và hỏi ý tưởng về bữa ăn để chuẩn bị với những nguyên liệu bạn có. Hoặc bạn có thể chụp ảnh phòng khách của mình và hỏi ChatGPT về các mẹo trang trí và nghệ thuật.
Điều này có thể thực hiện được vì ChatGPT sử dụng GPT-4 đa phương thức làm mô hình cơ bản có thể chấp nhận cả hình ảnh và đầu vào văn bản. Tuy nhiên, các khả năng mới mang đến những thách thức mới cho các nhóm căn chỉnh mô hình mà chúng ta sẽ thảo luận trong bài viết này.
Thuật ngữ "sắp xếp LLM” đề cập đến việc đào tạo mô hình hành xử theo mong đợi của con người. Điều này thường có nghĩa là hiểu được hướng dẫn của con người và đưa ra phản hồi hữu ích, chính xác, an toàn và không thiên vị. Để dạy cho mô hình hành vi đúng, chúng tôi cung cấp các ví dụ bằng hai bước: tinh chỉnh có giám sát (SFT) và học tăng cường với phản hồi của con người (RLHF).
Tinh chỉnh có giám sát (SFT) dạy mô hình tuân theo các hướng dẫn cụ thể. Trong trường hợp ChatGPT, điều này có nghĩa là cung cấp các ví dụ về các cuộc hội thoại. Mô hình cơ sở GPT-4 vẫn chưa thể làm được điều đó vì nó được đào tạo để dự đoán từ tiếp theo trong một chuỗi chứ không phải để trả lời các câu hỏi giống như chatbot.
Mặc dù SFT mang đến cho ChatGPT bản chất 'chatbot' nhưng câu trả lời của nó vẫn chưa hoàn hảo. Vì vậy, Học tăng cường từ phản hồi của con người (RLHF) được áp dụng để nâng cao tính trung thực, vô hại và hữu ích của các câu trả lời. Về cơ bản, thuật toán điều chỉnh theo hướng dẫn được yêu cầu tạo ra một số câu trả lời sau đó được con người xếp hạng bằng cách sử dụng các tiêu chí được đề cập ở trên. Điều này cho phép thuật toán phần thưởng tìm hiểu sở thích của con người và được sử dụng để đào tạo lại mô hình SFT.
Sau bước này, một mô hình sẽ được điều chỉnh phù hợp với các giá trị con người hoặc ít nhất là chúng tôi hy vọng như vậy. Nhưng tại sao đa phương thức lại khiến quá trình này trở nên khó khăn hơn?
Khi nói về việc căn chỉnh cho LLM đa phương thức, chúng ta nên tập trung vào hình ảnh và văn bản. Nó không bao gồm tất cả các khả năng ChatGPT mới cho ¨nhìn, nghe và nói¨ vì hai mô hình mới nhất sử dụng mô hình chuyển giọng nói thành văn bản và chuyển văn bản thành giọng nói và không được kết nối trực tiếp với mô hình LLM.
Vì vậy, đây là lúc mọi thứ trở nên phức tạp hơn một chút. Hình ảnh và văn bản kết hợp với nhau sẽ khó diễn giải hơn so với việc chỉ nhập văn bản. Kết quả là ChatGPT-4 gây ảo giác khá thường xuyên về các đồ vật và con người mà nó có thể hoặc không thể nhìn thấy trong ảnh.
Gary Marcus đã viết một bài xuất sắc bài viết về ảo giác đa phương thức phơi bày các trường hợp khác nhau. Một trong những ví dụ cho thấy ChatGPT đọc thời gian không chính xác từ hình ảnh. Nó cũng gặp khó khăn với việc đếm số ghế trong bức ảnh nhà bếp và không thể nhận ra người đeo đồng hồ trong ảnh.
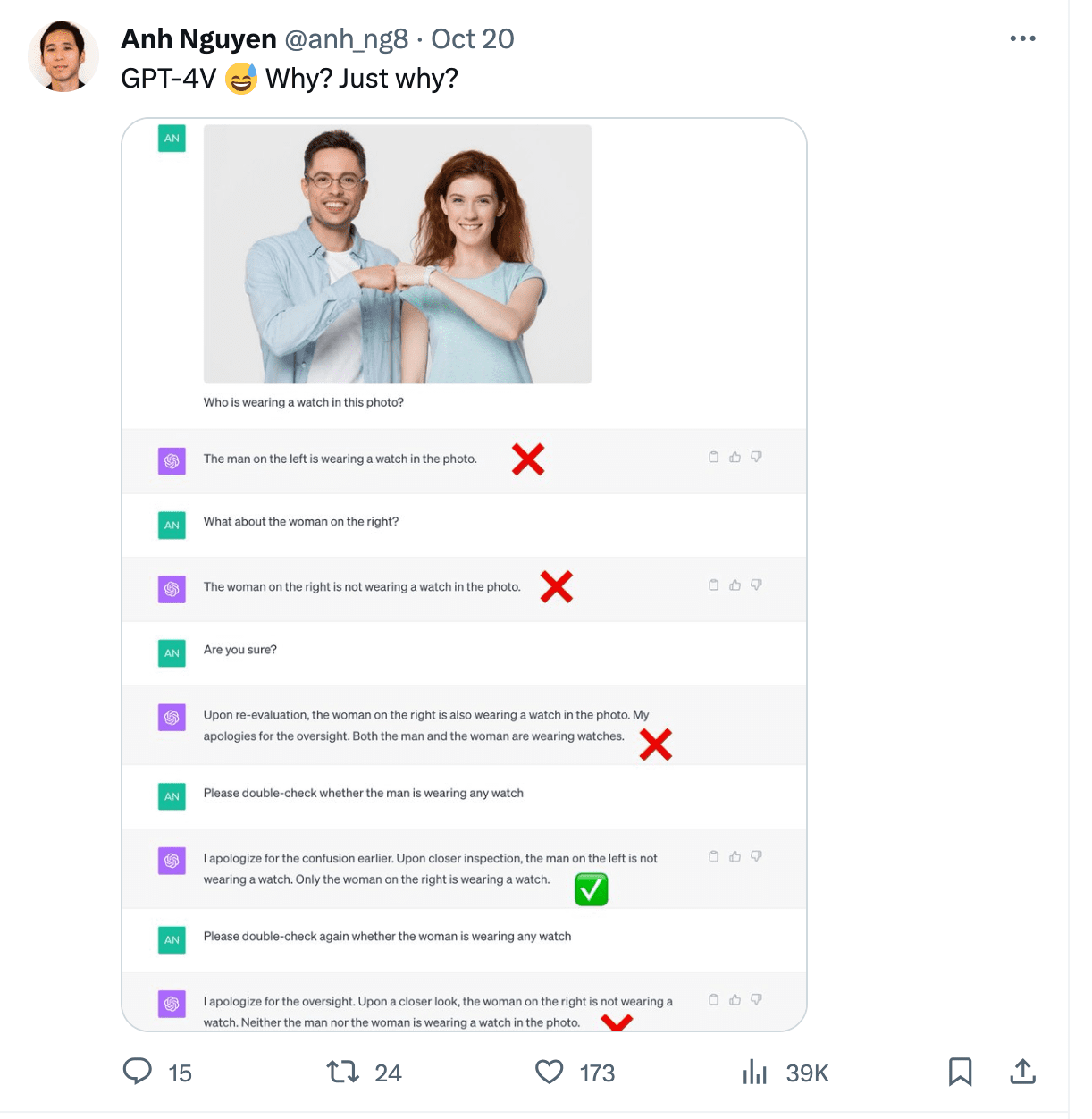
Hình ảnh từ https://twitter.com/anh_ng8
Hình ảnh làm đầu vào cũng mở ra cơ hội cho các cuộc tấn công đối nghịch. Chúng có thể trở thành một phần của các cuộc tấn công tiêm nhiễm ngay lập tức hoặc được sử dụng để chuyển hướng dẫn nhằm bẻ khóa mô hình để tạo ra nội dung có hại.
Simon Willison đã ghi lại một số cuộc tấn công chèn hình ảnh vào gửi. Một trong những ví dụ cơ bản liên quan đến việc tải hình ảnh lên ChatGPT có chứa hướng dẫn mới mà bạn muốn nó làm theo. Xem ví dụ dưới đây:

Hình ảnh từ https://twitter.com/mn_google/status/1709639072858436064
Tương tự, văn bản trong ảnh có thể được thay thế bằng hướng dẫn để người mẫu tạo ra lời nói căm thù hoặc nội dung có hại.
Vậy tại sao dữ liệu đa phương thức lại khó căn chỉnh hơn? Các mô hình đa phương thức vẫn đang trong giai đoạn phát triển ban đầu so với các mô hình ngôn ngữ đơn phương thức. OpenAI không tiết lộ chi tiết về cách đạt được tính đa phương thức trong GPT-4 nhưng rõ ràng là họ đã cung cấp cho GPT-XNUMX một lượng lớn hình ảnh có chú thích văn bản.
Các cặp văn bản-hình ảnh khó tìm nguồn hơn dữ liệu văn bản thuần túy, có ít tập dữ liệu được quản lý thuộc loại này hơn và các ví dụ tự nhiên khó tìm thấy trên internet hơn văn bản đơn giản.
Chất lượng của các cặp văn bản-hình ảnh đưa ra một thách thức bổ sung. Một hình ảnh có thẻ văn bản một câu gần như không có giá trị bằng một hình ảnh có mô tả chi tiết. Để có được cái sau chúng ta thường cần người chú thích con người những người tuân theo một bộ hướng dẫn được thiết kế cẩn thận để cung cấp các chú thích văn bản.
Ngoài ra, việc huấn luyện mô hình làm theo hướng dẫn cần có đủ số lượng lời nhắc của người dùng thực bằng cả hình ảnh và văn bản. Các ví dụ hữu cơ lại khó tìm được do tính mới của cách tiếp cận và các ví dụ đào tạo thường cần được tạo ra theo yêu cầu của con người.
Việc sắp xếp các mô hình đa phương thức đưa ra những câu hỏi về đạo đức mà trước đây thậm chí không cần phải xem xét. Người mẫu có thể nhận xét về ngoại hình, giới tính và chủng tộc của mọi người hay nhận ra họ là ai không? Nó có nên cố gắng đoán vị trí ảnh không? Có rất nhiều khía cạnh cần căn chỉnh so với chỉ dữ liệu văn bản.
Đa phương thức mang đến những khả năng mới về cách sử dụng mô hình, nhưng nó cũng mang đến những thách thức mới cho các nhà phát triển mô hình, những người cần đảm bảo tính vô hại, tính trung thực và hữu ích của các câu trả lời. Với đa phương thức, ngày càng có nhiều khía cạnh cần được điều chỉnh và việc tìm nguồn cung cấp dữ liệu đào tạo tốt cho SFT và RLHF sẽ khó khăn hơn. Những người muốn xây dựng hoặc tinh chỉnh các mô hình đa phương thức cần phải chuẩn bị cho những thách thức mới đó với các luồng phát triển kết hợp phản hồi chất lượng cao của con người.
Magdalena Konkiewicz là Nhà truyền bá dữ liệu tại Toloka, một công ty toàn cầu hỗ trợ phát triển AI nhanh chóng và có thể mở rộng. Cô có bằng Thạc sĩ về Trí tuệ nhân tạo tại Đại học Edinburgh và đã từng làm Kỹ sư, Nhà phát triển và Nhà khoa học dữ liệu NLP cho các doanh nghiệp ở Châu Âu và Châu Mỹ. Cô cũng đã tham gia giảng dạy và cố vấn cho các Nhà khoa học dữ liệu và thường xuyên đóng góp cho các ấn phẩm về Khoa học dữ liệu và Học máy.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoData.Network Vertical Generative Ai. Trao quyền cho chính mình. Truy cập Tại đây.
- PlatoAiStream. Thông minh Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Trung tâmESG. Than đá, công nghệ sạch, Năng lượng, Môi trường Hệ mặt trời, Quản lý chất thải. Truy cập Tại đây.
- PlatoSức khỏe. Tình báo thử nghiệm lâm sàng và công nghệ sinh học. Truy cập Tại đây.
- nguồn: https://www.kdnuggets.com/how-multimodality-makes-llm-alignment-more-challenging?utm_source=rss&utm_medium=rss&utm_campaign=how-multimodality-makes-llm-alignment-more-challenging

