Các chỉ số là một yếu tố quan trọng của học máy. Liên quan đến các nhiệm vụ phân loại, có nhiều loại số liệu khác nhau cho phép bạn đánh giá hiệu suất của các mô hình học máy. Tuy nhiên, có thể khó để chọn một cái phù hợp cho nhiệm vụ của bạn trong tầm tay.
Trong bài viết này, tôi sẽ đi qua 4 số liệu phân loại phổ biến: Độ chính xác, Độ chính xác, Thu hồi và ROC liên quan đến Hồi quy logistic.
Băt đâu nao…
Hồi quy logistic là một dạng Học có giám sát - khi thuật toán học trên một tập dữ liệu được gắn nhãn và phân tích dữ liệu đào tạo. Hồi quy logistic thường được sử dụng cho các vấn đề phân loại nhị phân dựa trên 'chức năng logistic' của nó.
Phân loại nhị phân có thể đại diện cho các lớp của chúng dưới dạng: tích cực / tiêu cực, 1/0 hoặc Đúng / Sai.
Hàm logistic còn được gọi là hàm Sigmoid lấy bất kỳ số nào có giá trị thực và ánh xạ nó thành giá trị từ 0 đến 1. Nó có thể được biểu diễn toán học như sau:
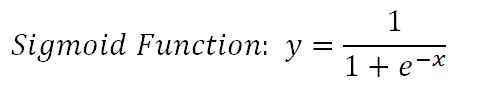
def sigmoid (z): trả về 1.0 / (1 + np.exp (-z))
Phân loại là dự đoán một nhãn và sau đó xác định một đối tượng thuộc thể loại nào dựa trên các thông số khác nhau.
Để đo lường mô hình phân loại của chúng tôi hoạt động tốt như thế nào khi đưa ra những dự đoán này, chúng tôi sử dụng các chỉ số phân loại. Nó đo lường hiệu suất của mô hình học máy của chúng tôi, giúp chúng tôi tin tưởng rằng các kết quả đầu ra này có thể được sử dụng nhiều hơn nữa trong các quy trình ra quyết định.
Hiệu suất thường được trình bày trong phạm vi từ 0 đến 1, trong đó điểm 1 thể hiện sự hoàn hảo.
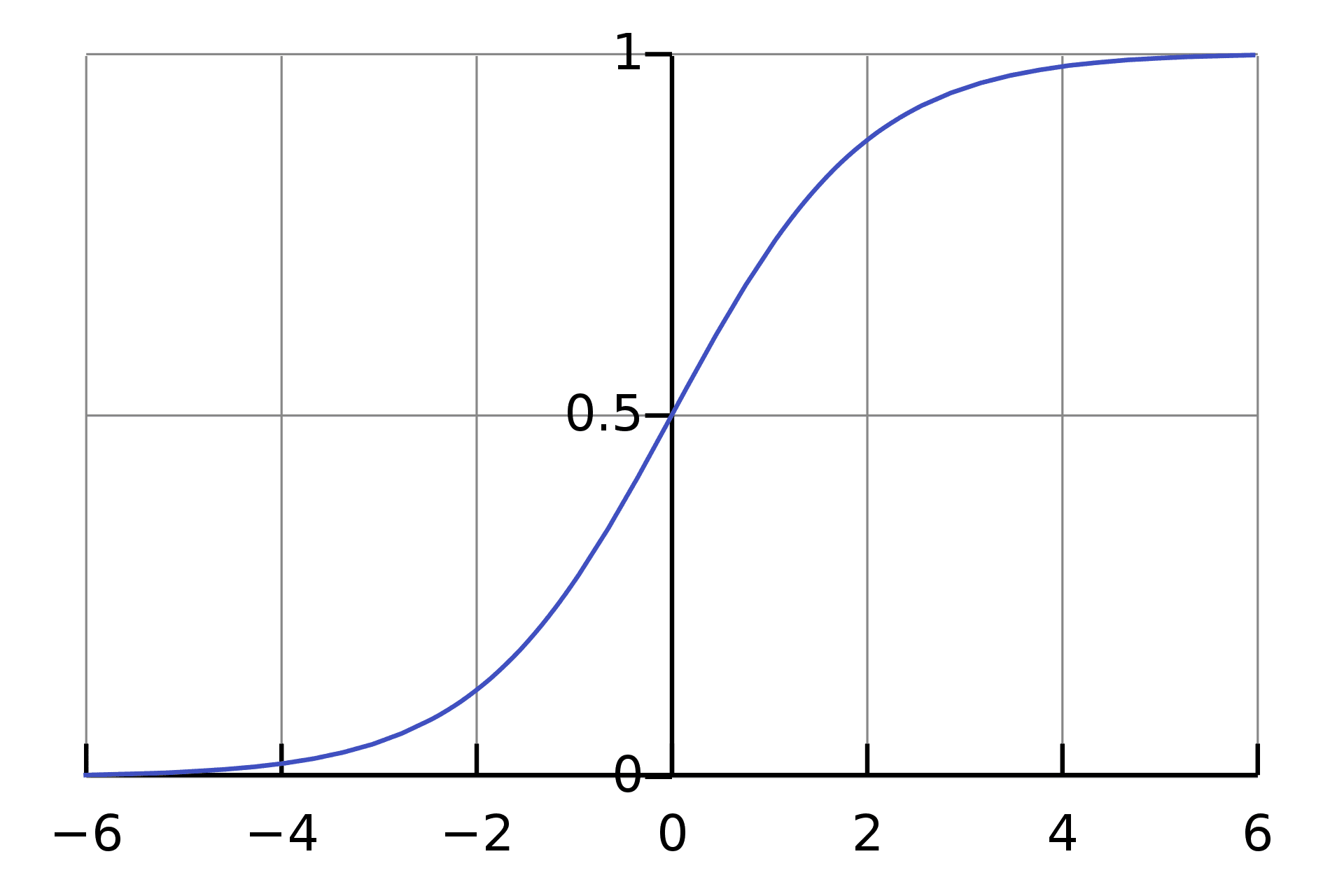
Nếu chúng ta sử dụng phạm vi từ 0 đến 1 để biểu thị hiệu suất của mô hình, điều gì sẽ xảy ra khi giá trị là 0.5? Như chúng ta đã biết từ các lớp toán đầu tiên, nếu xác suất lớn hơn 0.5, chúng ta làm tròn thành 1 (dương) - nếu không, nó là 0 (âm).
Điều đó nghe có vẻ ổn, nhưng bây giờ khi bạn đang sử dụng các mô hình phân loại để giúp xác định đầu ra của các trường hợp thực tế. Chúng ta cần chắc chắn 100% rằng đầu ra đã được phân loại chính xác.
Ví dụ, hồi quy logistic được sử dụng để phát hiện các email spam. Nếu xác suất email đó là spam dựa trên thực tế là nó trên 0.5, thì điều này có thể gây rủi ro vì chúng tôi có thể đưa một email quan trọng vào thư mục spam. Mong muốn và nhu cầu về hiệu suất của mô hình có độ chính xác cao trở nên nhạy cảm hơn đối với các nhiệm vụ liên quan đến sức khỏe và tài chính.
Do đó, việc sử dụng khái niệm ngưỡng của các giá trị trên ngưỡng giá trị có xu hướng là 1 và giá trị dưới giá trị ngưỡng có xu hướng bằng 0 có thể gây ra thách thức.
Mặc dù có tùy chọn để điều chỉnh giá trị ngưỡng, nhưng nó vẫn làm tăng nguy cơ chúng tôi phân loại không chính xác. Ví dụ, có một ngưỡng thấp sẽ phân loại chính xác phần lớn các lớp tích cực, nhưng bên trong tích cực sẽ chứa các lớp tiêu cực - ngược lại nếu chúng ta có một ngưỡng cao.
Vì vậy, hãy tìm hiểu cách các số liệu phân loại này có thể giúp chúng tôi đo lường hiệu suất của mô hình hồi quy logistic của chúng tôi
tính chính xác
Chúng tôi sẽ bắt đầu với độ chính xác vì đó là tính năng thường được sử dụng nhiều nhất, đặc biệt là đối với người mới bắt đầu.
Độ chính xác được định nghĩa là số dự đoán đúng trên tổng số dự đoán:
độ chính xác = đúng_predictions / total_predictions
Tuy nhiên, chúng tôi có thể mở rộng thêm về điều này bằng cách sử dụng:
- Thực sự Tích cực (TP) - bạn đã dự đoán là tích cực và nó thực sự là tích cực
- True Negative (TN) - bạn đã dự đoán là tiêu cực và nó thực sự là âm
- Tích cực Sai (FP) - bạn đã dự đoán là tích cực và nó thực sự là tiêu cực
- Sai phủ định (FN) - bạn đã dự đoán là tiêu cực và nó thực sự là tích cực
Vì vậy, chúng ta có thể nói các dự đoán đúng là TN + TP, trong khi dự đoán sai là FP + FN. Phương trình bây giờ có thể được định nghĩa lại là:
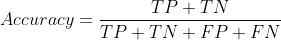
Để tìm độ chính xác của mô hình của bạn, bạn sẽ làm như sau:
score = LogisticRegression.score (X_test, y_test) print ('Điểm độ chính xác của bài kiểm tra', điểm số)
Hoặc bạn cũng có thể sử dụng thư viện sklearn:
từ sklearn.metrics nhập độ chính xác_score precision_score (y_train, y_pred)
Tuy nhiên, sử dụng chỉ số độ chính xác để đo lường hiệu suất của mô hình của bạn thường là không đủ. Đây là nơi chúng tôi cần các số liệu khác.
Độ chính xác và thu hồi
Nếu chúng ta muốn kiểm tra thêm "độ chính xác" trong các lớp khác nhau, nơi chúng ta muốn đảm bảo rằng khi mô hình dự đoán dương tính, thì nó thực sự là dương tính - chúng ta sử dụng độ chính xác. Chúng tôi cũng có thể gọi đây là Giá trị Dự đoán Tích cực, có thể được định nghĩa là:
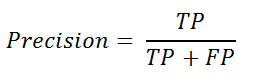
từ sklearn.metrics nhập precision_score
Nếu chúng ta muốn kiểm tra thêm "độ chính xác" trong các lớp khác nhau, nơi chúng ta muốn đảm bảo rằng khi mô hình dự đoán âm, nó thực sự là âm - chúng ta sử dụng phép thu hồi. Nhớ lại là công thức tương tự như độ nhạy và có thể được định nghĩa là:
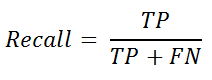
từ sklearn.metrics nhập summon_score
Sử dụng cả độ chính xác và thu hồi đều là những thước đo hữu ích khi có sự mất cân bằng trong các quan sát giữa hai lớp. Ví dụ, có nhiều hơn một lớp (1) và chỉ một vài lớp khác (0) trong tập dữ liệu.
Để tăng độ chính xác của mô hình, bạn sẽ cần có ít FP hơn và không phải lo lắng về FN. Trong khi đó, nếu bạn muốn tăng thu hồi, bạn sẽ cần có ít FN hơn và không phải lo lắng về FP.
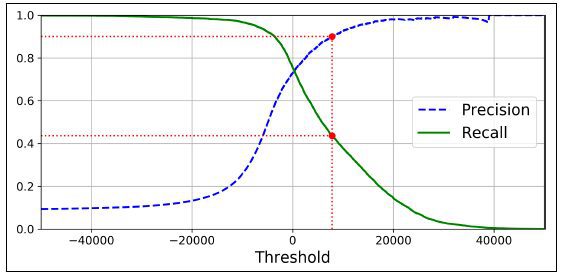
Nâng cao ngưỡng phân loại làm giảm dương tính giả - tăng độ chính xác. Việc nâng cao ngưỡng phân loại sẽ làm giảm các kết quả dương tính thực sự hoặc giữ cho chúng giống nhau, trong khi tăng các âm tính giả hoặc giữ chúng giống nhau. - giảm thu hồi hoặc giữ cho nó liên tục.
Thật không may, không thể có độ chính xác và giá trị thu hồi cao. Nếu bạn tăng độ chính xác, nó sẽ giảm thu hồi - ngược lại. Điều này được gọi là sự cân bằng về độ chính xác / thu hồi.
Đường cong ROC
Khi nói đến độ chính xác, chúng tôi quan tâm đến việc giảm FP và để nhớ lại, chúng tôi quan tâm đến việc giảm FN. Tuy nhiên, có một số liệu mà chúng ta có thể sử dụng để hạ thấp cả FP và FN - nó được gọi là đường cong Đặc tính hoạt động của máy thu hay còn gọi là đường cong ROC.
Nó vẽ biểu đồ tỷ lệ dương tính giả (trục x) so với tỷ lệ dương tính thực (trục y).
- Tỷ lệ Tích cực Thực sự = TP / (TP + FN)
- Tỷ lệ dương tính giả = FP / (FP + TN)
Tỷ lệ dương tính thực sự còn được gọi là độ nhạy, và tỷ lệ dương tính giả còn được gọi là tỷ lệ độ đặc hiệu ngược.
- Độ đặc hiệu = TN / (TN + FP)
Nếu các giá trị trên trục x bao gồm các giá trị nhỏ hơn, điều này cho thấy FP thấp hơn và TN cao hơn. Nếu các giá trị trên trục y bao gồm các giá trị lớn hơn, điều này cho thấy TP cao hơn và FN thấp hơn.
ROC trình bày hiệu suất của một mô hình phân loại ở tất cả các ngưỡng phân loại, như sau:

Ví dụ:

AUC
Khi nói đến đường cong ROC, bạn có thể cũng đã nghe đến Khu vực dưới đường cong (AUC). Nó chính xác như những gì nó nói - khu vực dưới đường cong. Nếu bạn muốn biết đường cong của bạn tốt đến mức nào, bạn tính điểm ROC AUC. AUC đo lường hiệu suất trên tất cả các ngưỡng phân loại có thể có.
Bạn có càng nhiều diện tích dưới đường cong thì càng tốt - điểm ROC AUC càng cao. Đây là khi FN và FP đều bằng 1 - hoặc nếu chúng ta tham khảo biểu đồ ở trên, đó là khi tỷ lệ dương tính thực là 0 và tỷ lệ dương tính giả là XNUMX.
từ sklearn.metrics nhập roc_auc_score
Hình ảnh dưới đây cho thấy thứ tự tăng dần của các dự đoán hồi quy logistic. Nếu giá trị AUC là 0.0, chúng ta có thể nói rằng các dự đoán là hoàn toàn sai. Nếu giá trị AUC là 1.0, chúng ta có thể nói rằng các dự đoán là hoàn toàn chính xác.

Để tóm tắt lại, chúng ta đã xem xét hồi quy logistic là gì, chỉ số phân loại là gì và các vấn đề với ngưỡng với các giải pháp, chẳng hạn như độ chính xác, độ chính xác, thu hồi và đường cong ROC.
Có rất nhiều số liệu phân loại khác trên mạng, chẳng hạn như ma trận nhầm lẫn, điểm F1, điểm F2, v.v. Tất cả đều có sẵn để giúp bạn hiểu rõ hơn về hiệu suất của mô hình của bạn.
Nisha Arya là Nhà khoa học dữ liệu và Nhà văn kỹ thuật tự do. Cô ấy đặc biệt quan tâm đến việc cung cấp lời khuyên hoặc hướng dẫn nghề nghiệp về Khoa học Dữ liệu và kiến thức dựa trên lý thuyết về Khoa học Dữ liệu. Cô cũng mong muốn khám phá những cách khác nhau mà Trí tuệ nhân tạo có thể mang lại / có thể mang lại lợi ích cho sự trường tồn của cuộc sống con người. Một người ham học hỏi, tìm cách mở rộng kiến thức công nghệ và kỹ năng viết của mình, đồng thời giúp hướng dẫn người khác.

