Xử lý dữ liệu luồng cho phép bạn hành động trên dữ liệu trong thời gian thực. Phân tích dữ liệu theo thời gian thực có thể giúp bạn có phản hồi kịp thời và tối ưu hóa đồng thời cải thiện trải nghiệm tổng thể của khách hàng.
Apache Flash là một khung tính toán phân tán cho phép xử lý dữ liệu theo thời gian thực có trạng thái. Nó cung cấp một bộ API duy nhất để xây dựng các công việc hàng loạt và phát trực tuyến, giúp các nhà phát triển dễ dàng làm việc với dữ liệu giới hạn và không giới hạn. Apache Flink cung cấp các mức độ trừu tượng khác nhau để đáp ứng nhiều trường hợp sử dụng xử lý sự kiện khác nhau.
Phân tích dữ liệu Amazon Kinesis là dịch vụ AWS cung cấp cơ sở hạ tầng serverless để chạy các ứng dụng Apache Flink. Điều này giúp các nhà phát triển dễ dàng xây dựng các ứng dụng Apache Flink có tính sẵn sàng cao, có khả năng chịu lỗi và có khả năng mở rộng mà không cần phải trở thành chuyên gia xây dựng, định cấu hình và duy trì các cụm Apache Flink trên AWS.
Khối lượng công việc truyền dữ liệu thường yêu cầu dữ liệu trong luồng phải được làm phong phú thông qua các nguồn bên ngoài (chẳng hạn như cơ sở dữ liệu hoặc các luồng dữ liệu khác). Ví dụ: giả sử bạn đang nhận dữ liệu tọa độ từ thiết bị GPS và cần hiểu cách các tọa độ này ánh xạ với các vị trí địa lý thực tế; bạn cần làm phong phú nó bằng dữ liệu định vị địa lý. Bạn có thể sử dụng một số phương pháp để làm phong phú dữ liệu thời gian thực của mình trong Kinesis Data Analytics tùy thuộc vào trường hợp sử dụng và mức độ trừu tượng của Apache Flink. Mỗi phương pháp có tác động khác nhau đến thông lượng, lưu lượng mạng và mức sử dụng CPU (hoặc bộ nhớ). Trong bài đăng này, chúng tôi đề cập đến các phương pháp này và thảo luận về lợi ích và nhược điểm của chúng.
Các mẫu làm giàu dữ liệu
Làm giàu dữ liệu là một quá trình bổ sung bối cảnh bổ sung và nâng cao dữ liệu được thu thập. Dữ liệu bổ sung thường được thu thập từ nhiều nguồn khác nhau. Định dạng và tần suất cập nhật dữ liệu có thể dao động từ một lần trong một tháng đến nhiều lần trong một giây. Bảng sau đây hiển thị một số ví dụ về các nguồn, định dạng và tần suất cập nhật khác nhau.
| Ngày | Định dạng | Tần số cập nhật |
| Phạm vi địa chỉ IP theo quốc gia | CSV | Mỗi tháng một lần |
| Sơ đồ tổ chức công ty | JSON | Hai lần một năm |
| Tên máy theo ID | CSV | Một lần một ngày |
| Thông tin nhân viên | Bảng (Cơ sở dữ liệu quan hệ) | Một vài lần một ngày |
| Thông tin khách hàng | Bảng (Cơ sở dữ liệu phi quan hệ) | Một vài lần một giờ |
| Yêu cầu của khách hàng | Bảng (Cơ sở dữ liệu quan hệ) | Nhiều lần một giây |
Dựa trên trường hợp sử dụng, ứng dụng làm giàu dữ liệu của bạn có thể có các yêu cầu khác nhau về độ trễ, thông lượng hoặc các yếu tố khác. Phần còn lại của bài đăng sẽ đi sâu hơn vào các mô hình làm giàu dữ liệu khác nhau trong Kinesis Data Analytics, được liệt kê trong bảng sau cùng với các đặc điểm chính của chúng. Bạn có thể chọn mẫu tốt nhất dựa trên sự cân bằng giữa các đặc điểm này.
| Mô hình làm giàu | Độ trễ | Thông lượng | Độ chính xác nếu dữ liệu tham chiếu thay đổi | Sử dụng bộ nhớ | phức tạp |
| Tải trước dữ liệu tham chiếu trong bộ nhớ Trình quản lý tác vụ Apache Flink | Thấp | Cao | Thấp | Cao | Thấp |
| Tải trước dữ liệu tham chiếu được phân vùng ở trạng thái Apache Flink | Thấp | Cao | Thấp | Thấp | Thấp |
| Tải trước dữ liệu tham chiếu được phân vùng định kỳ ở trạng thái Apache Flink | Thấp | Cao | Trung bình | Thấp | Trung bình |
| Tra cứu không đồng bộ trên mỗi bản ghi với bản đồ không có thứ tự | Trung bình | Trung bình | Cao | Thấp | Thấp |
| Tra cứu không đồng bộ trên mỗi bản ghi từ hệ thống bộ đệm bên ngoài | Thấp hoặc Trung bình (Tùy thuộc vào việc triển khai và lưu trữ Cache) | Trung bình | Cao | Thấp | Trung bình |
| Làm phong phú các luồng bằng API bảng | Thấp | Cao | Cao | Thấp – Trung bình (tùy thuộc vào toán tử nối đã chọn) | Thấp |
Làm phong phú dữ liệu phát trực tuyến bằng cách tải trước dữ liệu tham chiếu
Khi dữ liệu tham chiếu có kích thước nhỏ và có tính chất tĩnh (ví dụ: dữ liệu quốc gia bao gồm mã quốc gia và tên quốc gia), bạn nên làm phong phú dữ liệu phát trực tuyến của mình bằng cách tải trước dữ liệu tham chiếu. Bạn có thể thực hiện việc này theo một số cách.
Để xem cách triển khai mã để tải trước dữ liệu tham chiếu theo nhiều cách khác nhau, hãy tham khảo Repo GitHub. Làm theo hướng dẫn trong kho GitHub để chạy mã và hiểu mô hình dữ liệu.
Tải trước dữ liệu tham chiếu trong bộ nhớ Trình quản lý tác vụ Apache Flink
Phương pháp làm giàu đơn giản nhất và cũng nhanh nhất là tải dữ liệu làm giàu vào từng bộ nhớ heap của trình quản lý tác vụ Apache Flink. Để thực hiện phương pháp này, bạn tạo một lớp mới bằng cách mở rộng lớp RichFlatMapFunction lớp trừu tượng Bạn xác định một biến tĩnh toàn cục trong định nghĩa lớp của mình. Biến có thể thuộc bất kỳ loại nào, hạn chế duy nhất là nó phải mở rộng java.io.Serializable-Ví dụ, java.util.HashMap. Trong open() phương thức, bạn xác định một logic tải dữ liệu tĩnh vào biến đã xác định của mình. Các open() phương thức này luôn được gọi đầu tiên, trong quá trình khởi tạo từng tác vụ trong trình quản lý tác vụ của Apache Flink, điều này đảm bảo toàn bộ dữ liệu tham chiếu được tải trước khi quá trình xử lý bắt đầu. Bạn triển khai logic xử lý của mình bằng cách ghi đè processElement() phương pháp. Bạn triển khai logic xử lý của mình và truy cập dữ liệu tham chiếu bằng khóa của nó từ biến toàn cục đã xác định.
Sơ đồ kiến trúc sau đây hiển thị tải dữ liệu tham chiếu đầy đủ trong từng vùng tác vụ của trình quản lý tác vụ.
Phương pháp này có những lợi ích sau:
- Dễ để thực hiện
- Độ trễ thấp
- Có thể hỗ trợ thông lượng cao
Tuy nhiên, nó có những nhược điểm sau:
- Nếu dữ liệu tham chiếu có kích thước lớn, trình quản lý tác vụ Apache Flink có thể hết bộ nhớ.
- Dữ liệu tham khảo có thể trở nên cũ theo thời gian.
- Nhiều bản sao của cùng một dữ liệu tham chiếu được tải vào từng vùng tác vụ của trình quản lý tác vụ.
- Dữ liệu tham chiếu phải nhỏ để vừa với bộ nhớ được phân bổ cho một khe tác vụ. Trong Kinesis Data Analytics, mỗi Đơn vị xử lý Kinesis (KPU) có 4 GB bộ nhớ, trong đó 3 GB có thể được sử dụng cho bộ nhớ heap. Nếu như
ParallelismPerKPUtrong Kinesis Data Analytics được đặt thành 1, một vùng tác vụ chạy trong mỗi trình quản lý tác vụ và vùng tác vụ có thể sử dụng toàn bộ 3 GB bộ nhớ heap. Nếu nhưParallelismPerKPUđược đặt thành giá trị lớn hơn 1, bộ nhớ heap 3 GB sẽ được phân bổ trên nhiều vùng tác vụ trong trình quản lý tác vụ. Nếu bạn đang triển khai Apache Flink ở Amazon EMR hoặc ở chế độ tự quản lý, bạn có thể điều chỉnhtaskmanager.memory.task.heap.sizeđể tăng bộ nhớ heap của trình quản lý tác vụ.
Tải trước dữ liệu tham chiếu được phân vùng ở trạng thái Apache Flink
Theo cách tiếp cận này, dữ liệu tham chiếu được tải và lưu giữ trong kho lưu trữ trạng thái Apache Flink khi bắt đầu ứng dụng Apache Flink. Để tối ưu hóa việc sử dụng bộ nhớ, trước tiên luồng dữ liệu chính được chia cho một trường được chỉ định thông qua keyBy() toán tử trên tất cả các vị trí nhiệm vụ. Hơn nữa, chỉ phần dữ liệu tham chiếu tương ứng với từng vị trí tác vụ mới được tải vào kho lưu trữ trạng thái.
Điều này đạt được trong Apache Flink bằng cách tạo lớp PartitionPreLoadEnrichmentData, mở rộng RichFlatMapFunction lớp trừu tượng Trong phương thức open, bạn ghi đè ValueStateDescriptor phương pháp để tạo một trạng thái xử lý. Trong ví dụ được tham chiếu, bộ mô tả được đặt tên locationRefData, loại khóa trạng thái là Chuỗi và loại giá trị là Location. Trong mã này, chúng tôi sử dụng ValueState so với MapState bởi vì chúng tôi chỉ giữ dữ liệu tham chiếu vị trí cho một khóa cụ thể. Ví dụ: khi chúng tôi truy vấn Amazon S3 để lấy dữ liệu tham chiếu vị trí, chúng tôi truy vấn vai trò cụ thể và lấy một vị trí cụ thể làm giá trị.
Trong Apache Flink, ValueState được sử dụng để giữ một giá trị cụ thể cho một khóa, trong khi MapState được sử dụng để giữ sự kết hợp của các cặp khóa-giá trị.
Kỹ thuật này hữu ích khi bạn có một tập dữ liệu tĩnh lớn khó có thể chứa toàn bộ bộ nhớ cho từng phân vùng.
Sơ đồ kiến trúc sau đây hiển thị tải dữ liệu tham chiếu cho khóa cụ thể cho từng phân vùng của luồng.
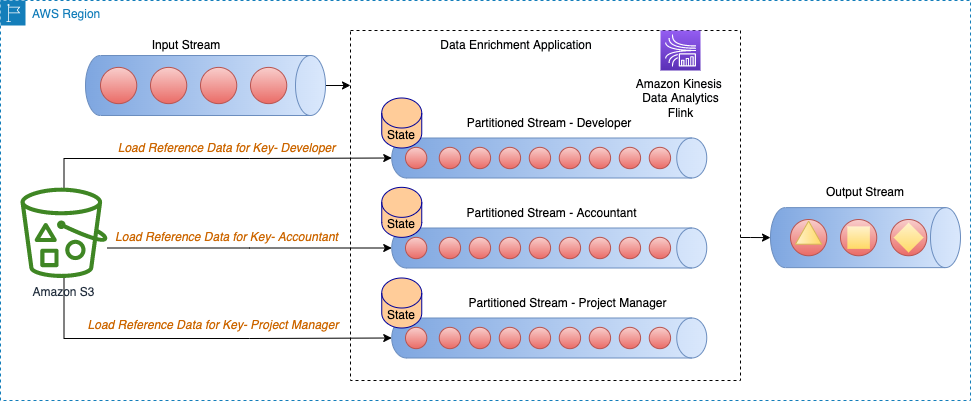
Ví dụ: dữ liệu tham chiếu của chúng tôi trong mã GitHub mẫu có các vai trò được ánh xạ tới từng tòa nhà. Vì luồng được phân chia theo vai trò nên chỉ cần tải thông tin tòa nhà cụ thể cho mỗi vai trò cho từng phân vùng dưới dạng dữ liệu tham chiếu.
Phương pháp này có những lợi ích sau:
- Độ trễ thấp.
- Có thể hỗ trợ thông lượng cao.
- Dữ liệu tham chiếu cho phân vùng cụ thể được tải ở trạng thái có khóa.
- Trong Kinesis Data Analytics, kho lưu trữ trạng thái mặc định được định cấu hình là RocksDB. RocksDB có thể sử dụng một phần đáng kể 1 GB bộ nhớ được quản lý và 50 GB dung lượng ổ đĩa do mỗi KPU cung cấp. Điều này cung cấp đủ chỗ cho dữ liệu tham khảo phát triển.
Tuy nhiên, nó có những nhược điểm sau:
- Dữ liệu tham khảo có thể trở nên cũ theo thời gian
Tải trước dữ liệu tham chiếu được phân vùng định kỳ ở Trạng thái Flink của Apache
Cách tiếp cận này là sự tinh chỉnh của kỹ thuật trước đó, trong đó mỗi dữ liệu tham chiếu được phân vùng được tải lại định kỳ để làm mới dữ liệu tham chiếu. Điều này rất hữu ích nếu dữ liệu tham chiếu của bạn thỉnh thoảng thay đổi.
Sơ đồ kiến trúc sau đây hiển thị tải dữ liệu tham chiếu định kỳ cho khóa cụ thể cho từng phân vùng của luồng.

Theo cách tiếp cận này, lớp PeriodicPerPartitionLoadEnrichmentData được tạo ra, mở rộng KeyedProcessFunction lớp học. Tương tự như mẫu trước, trong ngữ cảnh của ví dụ GitHub, ValueState được khuyến nghị ở đây vì mỗi phân vùng chỉ tải một giá trị duy nhất cho khóa. Tương tự như đã đề cập trước đó, trong open phương pháp, bạn xác định ValueStateDescriptor để xử lý trạng thái giá trị và xác định bối cảnh thời gian chạy để truy cập trạng thái.
Trong processElement phương thức, tải trạng thái giá trị và đính kèm dữ liệu tham chiếu (trong ví dụ GitHub được tham chiếu, buildingNo vào dữ liệu khách hàng). Đồng thời đăng ký dịch vụ hẹn giờ để được gọi khi thời gian xử lý vượt quá thời gian nhất định. Trong mã mẫu, dịch vụ hẹn giờ được lên lịch để gọi theo định kỳ (ví dụ: 60 giây một lần). bên trong onTimer phương thức, cập nhật trạng thái bằng cách thực hiện lệnh gọi để tải lại dữ liệu tham chiếu cho vai trò cụ thể.
Phương pháp này có những lợi ích sau:
- Độ trễ thấp.
- Có thể hỗ trợ thông lượng cao.
- Dữ liệu tham chiếu cho các phân vùng cụ thể được tải ở trạng thái có khóa.
- Dữ liệu tham khảo được làm mới định kỳ.
- Trong Kinesis Data Analytics, kho lưu trữ trạng thái mặc định được định cấu hình là RocksDB. Ngoài ra, 50 GB dung lượng ổ đĩa được cung cấp bởi mỗi KPU. Điều này cung cấp đủ chỗ cho dữ liệu tham khảo phát triển.
Tuy nhiên, nó có những nhược điểm sau:
- Nếu dữ liệu tham chiếu thay đổi thường xuyên, ứng dụng vẫn có dữ liệu cũ tùy thuộc vào tần suất tải lại trạng thái
- Ứng dụng có thể phải đối mặt với tình trạng tải đột biến trong quá trình tải lại dữ liệu tham chiếu
Làm phong phú thêm dữ liệu phát trực tuyến bằng cách tra cứu trên mỗi bản ghi
Mặc dù việc tải trước dữ liệu tham chiếu mang lại độ trễ thấp và thông lượng cao nhưng nó có thể không phù hợp với một số loại khối lượng công việc nhất định, chẳng hạn như sau:
- Cập nhật dữ liệu tham khảo với tần suất cao
- Apache Flink cần thực hiện lệnh gọi bên ngoài để tính toán logic nghiệp vụ
- Độ chính xác của đầu ra rất quan trọng và ứng dụng không nên sử dụng dữ liệu cũ
Thông thường, đối với các loại trường hợp sử dụng này, nhà phát triển đánh đổi thông lượng cao và độ trễ thấp để có được độ chính xác của dữ liệu. Trong phần này, bạn tìm hiểu về một số cách triển khai phổ biến để làm phong phú dữ liệu trên mỗi bản ghi cũng như những lợi ích và bất lợi của chúng.
Tra cứu không đồng bộ trên mỗi bản ghi với bản đồ không có thứ tự
Trong quá trình triển khai tra cứu đồng bộ trên mỗi bản ghi, ứng dụng Apache Flink phải đợi cho đến khi nhận được phản hồi sau khi gửi mọi yêu cầu. Điều này khiến bộ xử lý không hoạt động trong một khoảng thời gian xử lý đáng kể. Thay vào đó, ứng dụng có thể gửi yêu cầu cho các phần tử khác trong luồng trong khi chờ phản hồi cho phần tử đầu tiên. Bằng cách này, thời gian chờ đợi được phân bổ theo nhiều yêu cầu và do đó làm tăng thông lượng của quy trình. Apache Flink cung cấp I/O không đồng bộ để truy cập dữ liệu ngoài. Trong khi sử dụng mẫu này, bạn phải quyết định giữa unorderedWait (trong đó nó phát ra kết quả cho toán tử tiếp theo ngay khi nhận được phản hồi, không quan tâm đến thứ tự của phần tử trên luồng) và orderedWait (trong đó nó đợi cho đến khi tất cả các thao tác I/O trên máy bay hoàn tất, sau đó gửi kết quả cho toán tử tiếp theo theo thứ tự giống như các phần tử ban đầu được đặt trên luồng). Thông thường, khi người tiêu dùng ở hạ lưu bỏ qua thứ tự của các phần tử trong luồng, unorderedWait cung cấp thông lượng tốt hơn và ít thời gian nhàn rỗi hơn. Thăm nom Làm phong phú luồng dữ liệu của bạn một cách không đồng bộ bằng cách sử dụng Kinesis Data Analytics cho Apache Flink để tìm hiểu thêm về mẫu này.
Sơ đồ kiến trúc sau đây cho thấy cách ứng dụng Apache Flink trên Kinesis Data Analytics thực hiện lệnh gọi không đồng bộ tới công cụ cơ sở dữ liệu bên ngoài (ví dụ: Máy phát điện Amazon) cho mọi sự kiện trong luồng chính.
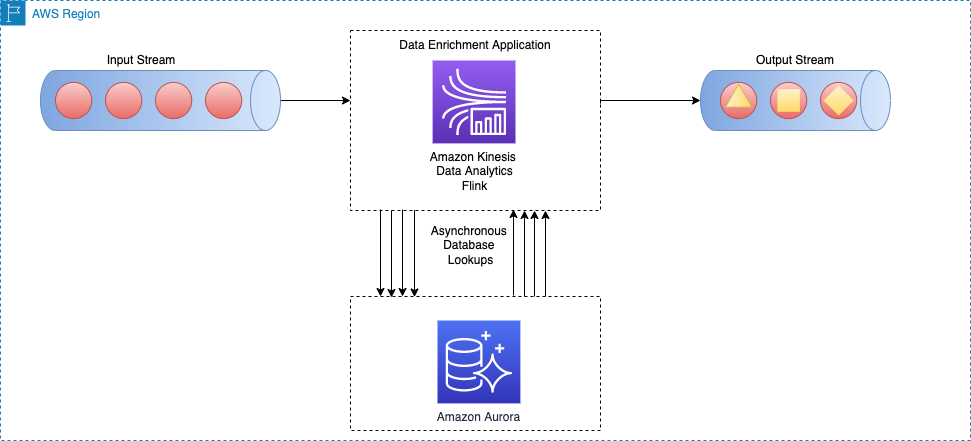
Phương pháp này có những lợi ích sau:
- Vẫn khá đơn giản và dễ thực hiện
- Đọc dữ liệu tham khảo cập nhật nhất
Tuy nhiên, nó có những nhược điểm sau:
- Nó tạo ra tải đọc lớn cho hệ thống bên ngoài (ví dụ: công cụ cơ sở dữ liệu hoặc API bên ngoài) lưu trữ dữ liệu tham chiếu
- Nhìn chung, nó có thể không phù hợp với các hệ thống yêu cầu thông lượng cao với độ trễ thấp
Tra cứu không đồng bộ trên mỗi bản ghi từ hệ thống bộ đệm bên ngoài
Một cách để nâng cao mẫu trước đó là sử dụng hệ thống bộ nhớ đệm để nâng cao thời gian đọc cho mỗi lệnh gọi I/O tra cứu. Bạn có thể dùng Bộ đệm Amazon Elasti cho bộ nhớ đệm, giúp tăng tốc hiệu suất ứng dụng và cơ sở dữ liệu hoặc làm kho lưu trữ dữ liệu chính cho các trường hợp sử dụng không yêu cầu độ bền như cửa hàng phiên, bảng xếp hạng trò chơi, phát trực tuyến và phân tích. ElastiCache tương thích với Redis và Memcached.
Để mẫu này hoạt động, bạn phải triển khai mẫu bộ đệm để điền dữ liệu vào bộ lưu trữ bộ đệm. Bạn có thể chọn giữa cách tiếp cận chủ động hoặc phản ứng tùy thuộc vào mục tiêu ứng dụng và yêu cầu về độ trễ của bạn. Để biết thêm thông tin, hãy tham khảo Mẫu bộ nhớ đệm.
Sơ đồ kiến trúc sau đây cho thấy cách ứng dụng Apache Flink gọi để đọc dữ liệu tham chiếu từ bộ lưu trữ bộ nhớ đệm bên ngoài (ví dụ: Amazon ElastiCache dành cho Redis). Các thay đổi dữ liệu phải được sao chép từ cơ sở dữ liệu chính (ví dụ: Amazon cực quang) vào bộ nhớ đệm bằng cách triển khai một trong các mẫu bộ nhớ đệm.
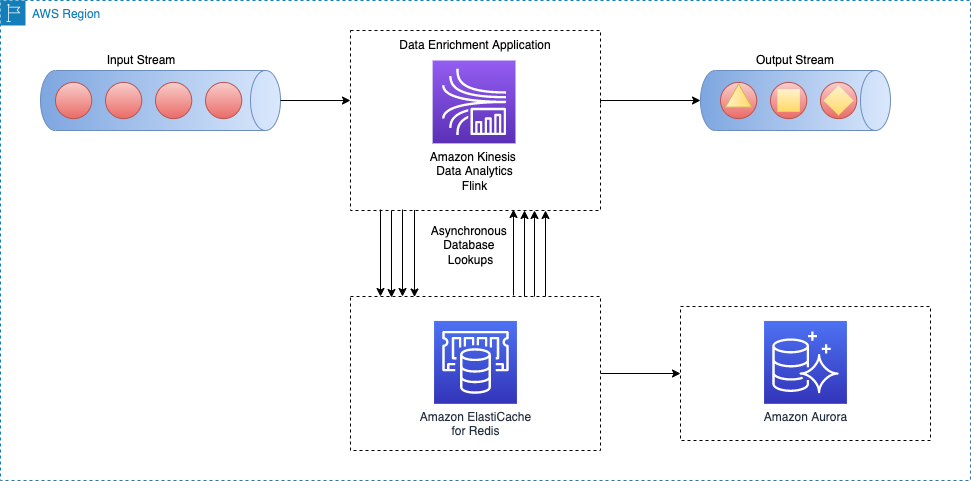
Việc triển khai mẫu làm giàu dữ liệu này tương tự như mẫu tra cứu không đồng bộ trên mỗi bản ghi; điểm khác biệt duy nhất là ứng dụng Apache Flink tạo kết nối với bộ lưu trữ bộ nhớ đệm thay vì kết nối với cơ sở dữ liệu chính.
Phương pháp này có những lợi ích sau:
- Thông lượng tốt hơn vì bộ nhớ đệm có thể tăng tốc hiệu suất ứng dụng và cơ sở dữ liệu
- Bảo vệ nguồn dữ liệu chính khỏi lưu lượng đọc được tạo bởi ứng dụng xử lý luồng
- Có thể cung cấp độ trễ đọc thấp hơn cho mỗi cuộc gọi tra cứu
- Nhìn chung, có thể không phù hợp với các hệ thống có thông lượng từ trung bình đến cao muốn cải thiện độ mới của dữ liệu
Tuy nhiên, nó có những nhược điểm sau:
- Độ phức tạp bổ sung của việc triển khai mẫu bộ đệm để điền và đồng bộ hóa dữ liệu giữa cơ sở dữ liệu chính và bộ lưu trữ bộ đệm
- Có khả năng ứng dụng xử lý luồng Apache Flink đọc dữ liệu tham chiếu cũ tùy thuộc vào mẫu bộ nhớ đệm nào được triển khai
- Tùy thuộc vào mẫu bộ đệm đã chọn (chủ động hoặc phản ứng), thời gian phản hồi cho mỗi I/O bổ sung có thể khác nhau, do đó thời gian xử lý tổng thể của luồng có thể không thể đoán trước được
Ngoài ra, bạn có thể tránh những sự phức tạp này bằng cách sử dụng Trình kết nối JDBC của Apache Flink cho API Flink SQL. Chúng tôi sẽ thảo luận chi tiết hơn về dữ liệu luồng làm giàu thông qua API Flink SQL ở phần sau của bài đăng này.
Làm phong phú dữ liệu luồng qua luồng khác
Trong mẫu này, dữ liệu trong luồng chính được bổ sung thêm dữ liệu tham chiếu trong luồng dữ liệu khác. Mẫu này phù hợp với các trường hợp sử dụng trong đó dữ liệu tham chiếu được cập nhật thường xuyên và có thể thực hiện thu thập dữ liệu thay đổi (CDC) và xuất bản các sự kiện lên dịch vụ truyền dữ liệu như Apache Kafka hoặc Luồng dữ liệu Amazon Kinesis. Mẫu này hữu ích trong các trường hợp sử dụng sau, ví dụ:
- Đơn đặt hàng của khách hàng được xuất bản lên luồng dữ liệu Kinesis, sau đó kết hợp với thông tin thanh toán của khách hàng trong một luồng dữ liệu. Luồng DynamoDB
- Các sự kiện dữ liệu được thu thập từ các thiết bị IoT sẽ được làm phong phú bằng dữ liệu tham chiếu trong bảng ở Dịch vụ cơ sở dữ liệu quan hệ của Amazon (RDS của Amazon)
- Các sự kiện nhật ký mạng sẽ được bổ sung thêm tên máy trên địa chỉ IP nguồn (và đích)
Sơ đồ kiến trúc sau đây cho thấy cách ứng dụng Apache Flink trên Kinesis Data Analytics kết hợp dữ liệu trong luồng chính với dữ liệu CDC trong luồng DynamoDB.

Để làm phong phú thêm dữ liệu phát trực tuyến từ một luồng khác, chúng tôi sử dụng một luồng chung để kết hợp các mẫu luồng mà chúng tôi sẽ giải thích trong các phần sau.
Làm phong phú luồng bằng API bảng
API bảng Flink của Apache cung cấp mức độ trừu tượng cao hơn để làm việc với các sự kiện dữ liệu. Với API bảng, bạn có thể xác định luồng dữ liệu của mình dưới dạng bảng và đính kèm lược đồ dữ liệu vào đó.
Trong mẫu này, bạn xác định các bảng cho từng luồng dữ liệu rồi nối các bảng đó để đạt được mục tiêu làm giàu dữ liệu. Hỗ trợ API bảng Flink của Apache các loại điều kiện tham gia khác nhau, như nối trong và nối ngoài. Tuy nhiên, bạn muốn tránh những thứ đó nếu bạn đang xử lý các luồng không giới hạn vì những luồng đó tốn nhiều tài nguyên. Để hạn chế việc sử dụng tài nguyên và chạy các phép nối một cách hiệu quả, bạn nên sử dụng các phép nối khoảng thời gian hoặc tạm thời. Phép nối khoảng yêu cầu một vị từ đẳng thức nối và một điều kiện nối giới hạn thời gian ở cả hai phía. Để hiểu rõ hơn cách thực hiện nối khoảng, hãy tham khảo Bắt đầu với API Apache Flink SQL trong Kinesis Data Analytics Studio.
So với các phép nối khoảng thời gian, các phép nối bảng tạm thời không hoạt động với một khoảng thời gian trong đó các phiên bản khác nhau của bản ghi được lưu giữ. Các bản ghi từ luồng chính luôn được nối với phiên bản tương ứng của dữ liệu tham chiếu tại thời điểm được chỉ định bởi hình mờ. Do đó, số phiên bản của dữ liệu tham chiếu vẫn còn ở trạng thái ít hơn.
Lưu ý rằng dữ liệu tham chiếu có thể có hoặc không có yếu tố thời gian được liên kết với nó. Nếu không, bạn có thể cần thêm phần tử thời gian xử lý để kết hợp với luồng dựa trên thời gian.
Trong đoạn mã ví dụ sau, update_time cột được thêm vào currency_rates bảng tham chiếu từ siêu dữ liệu thu thập dữ liệu thay đổi, chẳng hạn như Debezium. Hơn nữa, nó được sử dụng để xác định một watermark chiến lược cho bảng.
Về các tác giả
 Ali Alemi là Kiến trúc sư giải pháp chuyên gia phát trực tuyến tại AWS. Ali tư vấn cho khách hàng AWS các phương pháp hay nhất về kiến trúc và giúp họ thiết kế hệ thống dữ liệu phân tích thời gian thực đáng tin cậy, an toàn, hiệu quả và tiết kiệm chi phí. Anh ấy nghiên cứu ngược lại các trường hợp sử dụng của khách hàng và thiết kế các giải pháp dữ liệu để giải quyết các vấn đề kinh doanh của họ. Trước khi gia nhập AWS, Ali đã hỗ trợ một số khách hàng khu vực công và các đối tác tư vấn AWS trong hành trình hiện đại hóa ứng dụng của họ và chuyển sang đám mây.
Ali Alemi là Kiến trúc sư giải pháp chuyên gia phát trực tuyến tại AWS. Ali tư vấn cho khách hàng AWS các phương pháp hay nhất về kiến trúc và giúp họ thiết kế hệ thống dữ liệu phân tích thời gian thực đáng tin cậy, an toàn, hiệu quả và tiết kiệm chi phí. Anh ấy nghiên cứu ngược lại các trường hợp sử dụng của khách hàng và thiết kế các giải pháp dữ liệu để giải quyết các vấn đề kinh doanh của họ. Trước khi gia nhập AWS, Ali đã hỗ trợ một số khách hàng khu vực công và các đối tác tư vấn AWS trong hành trình hiện đại hóa ứng dụng của họ và chuyển sang đám mây.
 Subham Rakshit là Kiến trúc sư giải pháp chuyên gia phát trực tuyến dành cho phân tích tại AWS có trụ sở tại Vương quốc Anh. Anh làm việc với khách hàng để thiết kế và xây dựng nền tảng tìm kiếm và phát trực tuyến dữ liệu giúp họ đạt được mục tiêu kinh doanh của mình. Ngoài công việc, anh thích dành thời gian giải các câu đố ghép hình với con gái mình.
Subham Rakshit là Kiến trúc sư giải pháp chuyên gia phát trực tuyến dành cho phân tích tại AWS có trụ sở tại Vương quốc Anh. Anh làm việc với khách hàng để thiết kế và xây dựng nền tảng tìm kiếm và phát trực tuyến dữ liệu giúp họ đạt được mục tiêu kinh doanh của mình. Ngoài công việc, anh thích dành thời gian giải các câu đố ghép hình với con gái mình.
 Tiến sĩ Sam Mokhtari là Kiến trúc sư giải pháp cấp cao tại AWS. Lĩnh vực chuyên sâu chính của ông là dữ liệu và phân tích, đồng thời ông đã xuất bản hơn 30 bài báo có ảnh hưởng trong lĩnh vực này. Ông cũng là cố vấn phân tích và dữ liệu đáng kính, người đã lãnh đạo một số dự án triển khai quy mô lớn trong các ngành khác nhau, bao gồm năng lượng, y tế, viễn thông và vận tải.
Tiến sĩ Sam Mokhtari là Kiến trúc sư giải pháp cấp cao tại AWS. Lĩnh vực chuyên sâu chính của ông là dữ liệu và phân tích, đồng thời ông đã xuất bản hơn 30 bài báo có ảnh hưởng trong lĩnh vực này. Ông cũng là cố vấn phân tích và dữ liệu đáng kính, người đã lãnh đạo một số dự án triển khai quy mô lớn trong các ngành khác nhau, bao gồm năng lượng, y tế, viễn thông và vận tải.

