Bạn vừa hoàn thành một dự án sử dụng Python. Mã rõ ràng và có thể đọc được, nhưng tiêu chuẩn hiệu suất của bạn không đạt mức tối đa. Bạn mong đợi nhận được kết quả tính bằng mili giây, nhưng thay vào đó, bạn chỉ nhận được vài giây. Bạn làm nghề gì?
Nếu bạn đang đọc bài viết này, có lẽ bạn đã biết rằng Python là ngôn ngữ lập trình thông dịch với ngữ nghĩa động và khả năng đọc cao. Điều đó làm cho nó dễ sử dụng và đọc — nhưng không đủ nhanh cho nhiều trường hợp sử dụng trong thế giới thực.
Vì vậy, có thể có nhiều cách để tăng tốc mã Python của bạn, bao gồm nhưng không giới hạn ở việc sử dụng các cấu trúc dữ liệu hiệu quả cũng như các thuật toán nhanh và hiệu quả. Một số thư viện Python cũng sử dụng C hoặc C++ bên dưới để tăng tốc độ tính toán.
Điều gì sẽ xảy ra nếu bạn đã sử dụng hết tất cả các tùy chọn này? Ở đây có xử lý song song và đi trước một bước là điện toán phân tán. Trong bài đăng này, bạn sẽ tìm hiểu về ba khung phổ biến trong điện toán phân tán trong bối cảnh học máy: PySpark, Dask và Ray.
PySpark như tên gợi ý là một giao diện của Apache Spark trong Python. Nó cho phép người dùng viết các chương trình Spark bằng API Python và cung cấp vỏ PySpark để phân tích dữ liệu tương tác trong môi trường phân tán. Nó hỗ trợ hầu hết tất cả các tính năng của Spark như Truyền phát, MLlib, Spark SQL, DataFrame và Spark Core như hình bên dưới:

1. Truyền trực tuyến
Tính năng phát trực tuyến trong Apache Spark rất dễ sử dụng và có khả năng chống lỗi chạy trên Spark. Nó cung cấp năng lượng cho các hệ thống phân tích và trực quan trong quá trình phát trực tuyến cũng như dữ liệu lịch sử.
2. MLlib
MLlib là một thư viện máy học có thể mở rộng được xây dựng dựa trên khung Spark. Nó hiển thị một bộ API cấp cao nhất quán để tạo và điều chỉnh các quy trình máy học có thể mở rộng.
3. Spark SQL và DataFrame
Nó là một mô-đun Spark để xử lý dữ liệu dạng bảng. Nó cung cấp một lớp trừu tượng phía trên dữ liệu dạng bảng được gọi là DataFrame và có thể hoạt động như một công cụ truy vấn kiểu SQL trong một thiết lập phân tán.
4. Lõi tia lửa
Spark Core là công cụ thực thi chung cơ sở mà trên đó tất cả các chức năng khác được xây dựng. Nó cung cấp Bộ dữ liệu phân tán đàn hồi (RDD) và tính toán trong bộ nhớ.
5. API gấu trúc trên Spark
Pandas API là một mô-đun cho phép xử lý các tính năng và phương pháp của gấu trúc có thể mở rộng. Cú pháp của nó giống như pandas và không yêu cầu người dùng đào tạo về một mô-đun mới. Nó cung cấp một cơ sở mã liền mạch và tích hợp cho gấu trúc (bộ dữ liệu máy nhỏ/máy đơn) và Spark (bộ dữ liệu phân tán lớn).
Dask là một thư viện nguồn mở đa năng dành cho điện toán phân tán, cung cấp giao diện người dùng quen thuộc cho Pandas, Scikit-learning và NumPy.
Nó hiển thị các API cấp cao và cấp thấp cho phép người dùng chạy song song các thuật toán tùy chỉnh trên các máy đơn hoặc máy phân tán.
Nó có hai thành phần:
- Các bộ sưu tập dữ liệu lớn bao gồm các bộ sưu tập Cấp cao như Mảng Dask hoặc mảng NumPy song song, Túi Dask hoặc danh sách song song, Khung dữ liệu Dask hoặc Khung dữ liệu Pandas song song và Scikit-learning song song. Chúng cũng bao gồm các bộ sưu tập Cấp thấp như Trì hoãn và Tương lai giúp dễ dàng thực hiện song song và theo thời gian thực các tác vụ tùy chỉnh.
- Lập lịch tác vụ động cho phép thực hiện các biểu đồ tác vụ theo tỷ lệ song song lên tới các cụm gồm hàng nghìn nút.
Ray là một khung nền tảng duy nhất được sử dụng trong Python phân tán chung cũng như các ứng dụng do AIML cung cấp. Nó tạo thành một thời gian chạy phân tán cốt lõi và một bộ công cụ gồm các thư viện (Ray AI Runtime) để song song hóa tính toán AIML như trong sơ đồ bên dưới:
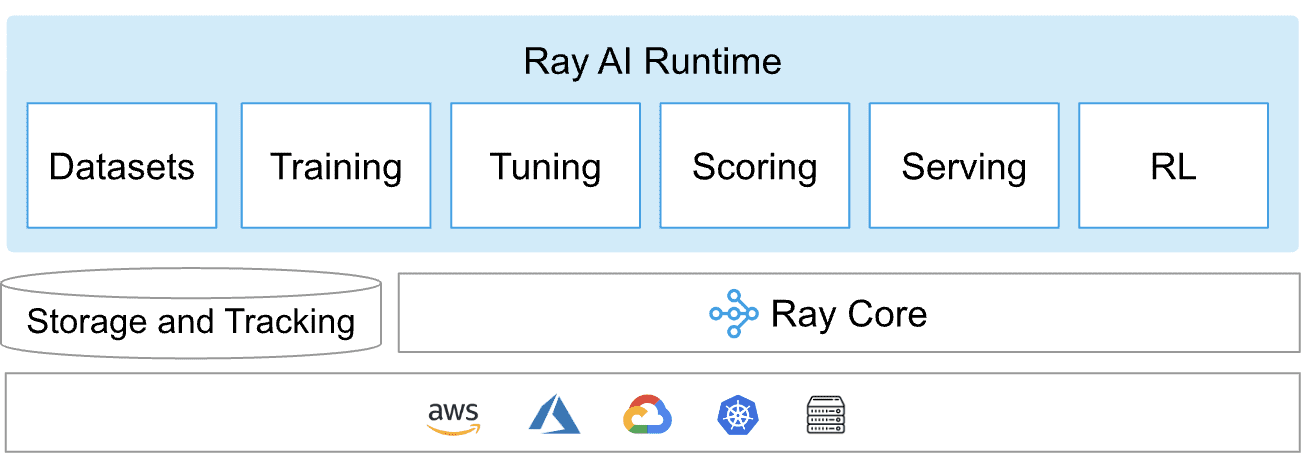
Thời gian chạy Ray AI
Ray AIR hoặc Ray AI Runtime là bộ công cụ một cửa dành cho các ứng dụng ML phân tán, cho phép dễ dàng mở rộng các quy trình công việc riêng lẻ và từ đầu đến cuối. Nó được xây dựng trên các thư viện của Ray cho nhiều tác vụ như tiền xử lý, tính điểm, đào tạo, điều chỉnh, phục vụ, v.v.
lõi tia
Ray Core cung cấp các nguyên hàm cốt lõi như tác vụ (Các hàm không trạng thái được thực thi trong cụm), tác nhân (các quy trình worker có trạng thái được tạo trong cụm) và các đối tượng (Các giá trị bất biến có thể truy cập trên toàn cụm) để xây dựng các ứng dụng phân tán có thể mở rộng.
Ray mở rộng quy mô khối lượng công việc máy học với Ray AIR, đồng thời xây dựng và triển khai các ứng dụng phân tán với Ray Core và Ray Clusters.
Bây giờ bạn đã biết các lựa chọn của mình, câu hỏi tự nhiên là chọn cái nào. Câu trả lời phụ thuộc vào một số yếu tố như nhu cầu kinh doanh cụ thể, sức mạnh cốt lõi của nhóm phát triển, v.v.
Hãy hiểu khuôn khổ nào phù hợp với các yêu cầu cụ thể được liệt kê bên dưới:
- Kích thước: PySpark có khả năng cao nhất khi xử lý khối lượng công việc cực lớn (TB trở lên) trong khi Dask và Ray xử lý khá tốt khối lượng công việc cỡ trung bình.
- Chung: Ray dẫn đầu khi nói đến các giải pháp chung, tiếp theo là PySpark. Trong khi Dask hoàn toàn nhằm mục đích mở rộng quy mô đường ống ML.
- Tốc độ: Ray là tùy chọn tốt nhất cho NLP hoặc các tác vụ chuẩn hóa văn bản sử dụng GPU để tăng tốc độ tính toán. Mặt khác, Dask cung cấp quyền truy cập để đọc nhanh các tệp có cấu trúc đối với các đối tượng DataFrame nhưng bị tụt lại phía sau khi tham gia và hợp nhất chúng. Đây là điểm Spark SQL đạt điểm cao.
- Sự quen thuộc: Đối với các nhóm thiên về cách tìm nạp và lọc dữ liệu của Pandas, Dask dường như là một lựa chọn phù hợp trong khi PySpark dành cho những nhóm đang tìm kiếm giao diện truy vấn giống như SQL.
- Dễ sử dụng: Cả ba công cụ đều được xây dựng trên các nền tảng khác nhau. Mặc dù PySpark chủ yếu dựa trên Java và C++, nhưng Dask hoàn toàn là Python, điều đó có nghĩa là nhóm ML của bạn bao gồm các nhà khoa học dữ liệu có thể dễ dàng theo dõi lại các thông báo lỗi nếu có lỗi xảy ra. Mặt khác, Ray là C ++ trên lõi nhưng khá Pythonic khi nói đến mô-đun AIML (Ray AIR).
- Cài đặt và bảo trì: Ray và Dask đạt điểm cao như nhau khi nói đến chi phí bảo trì. Mặt khác, cơ sở hạ tầng Spark khá phức tạp và khó bảo trì.
- Phổ biến và hỗ trợ: PySpark là người trưởng thành nhất trong tất cả những người thích sự hỗ trợ của cộng đồng nhà phát triển trong khi Dask đứng thứ hai. Ray đầy hứa hẹn về các tính năng có sẵn trong giai đoạn thử nghiệm beta.
- Khả năng tương thích: Trong khi PySpark tích hợp tốt với hệ sinh thái Apache, thì Dask kết hợp khá tốt với các thư viện Python và ML.
Bài đăng này đã thảo luận về cách tăng tốc mã Python ngoài sự lựa chọn thông thường về cấu trúc dữ liệu và thuật toán. Bài viết tập trung vào ba framework nổi tiếng và các thành phần của chúng. Bài đăng có ý định giúp người đọc bằng cách cân nhắc các lựa chọn có sẵn trên một loạt các thuộc tính và bối cảnh kinh doanh nhất định.
Vidhi Chung là nhà lãnh đạo đổi mới AI / ML từng đoạt giải thưởng và là Nhà đạo đức học về AI. Cô ấy làm việc ở nơi giao thoa giữa khoa học dữ liệu, sản phẩm và nghiên cứu để mang lại giá trị kinh doanh và thông tin chi tiết. Cô ấy là người ủng hộ khoa học lấy dữ liệu làm trung tâm và là chuyên gia hàng đầu về quản trị dữ liệu với tầm nhìn xây dựng các giải pháp AI đáng tin cậy.

