Tôi đã chuyển sang kỹ thuật dữ liệu từ lĩnh vực phát triển vào năm 2017. Trước đây, tôi đã làm việc mười năm trong lĩnh vực phát triển máy tính để bàn, phụ trợ (chủ yếu là Java) và một chút giao diện người dùng. Mặc dù có kinh nghiệm CNTT dày dặn, nhưng ban đầu không dễ để tìm ra công việc của kỹ sư dữ liệu, họ khác với quản trị viên cơ sở dữ liệu như thế nào, cách họ kết nối với phân tích dữ liệu và họ phải làm gì với Dữ liệu lớn.
Chính sự kỳ diệu của cụm từ “Dữ liệu lớn” đã quyết định những gì tôi đang làm bây giờ (điều này Link cung cấp một định nghĩa vững chắc về Dữ liệu lớn với bộ ba “Khối lượng, Sự đa dạng, Vận tốc” + một video giàu thông tin từ Amazon AWS). Đối với tôi, lĩnh vực Dữ liệu lớn giống như một thử thách mà tôi phải chấp nhận.
Tôi bắt đầu quan tâm nhiều hơn đến các hệ thống phân tán, công nghệ có thể mở rộng và đám mây, đồng thời tham dự các hội nghị nơi các sản phẩm Dữ liệu lớn có liên quan như Hadoop, Kafka, Spark, v.v. được phân tích. Các đồng nghiệp làm việc với Dữ liệu lớn xuất hiện xung quanh tôi và tôi dồn dập đặt câu hỏi cho họ. Đôi khi những câu trả lời tôi nhận được không hoàn toàn rõ ràng, điều này càng thúc đẩy sự tò mò của tôi.

Lần phát hành đầu tiên của Hadoop - nền tảng công khai đầu tiên để lưu trữ và xử lý mảng dữ liệu từ các nguồn phân tán, được tính bằng petabyte - diễn ra vào năm 2006. Ngay sau đó, doanh nghiệp bắt đầu coi Dữ liệu lớn là thứ có thể áp dụng được trong thực tế. Trong thập kỷ tới, hầu hết truyền thông kinh doanh gọi Dữ liệu lớn không gì khác hơn là một “cuộc cách mạng” và một “cuộc đảo chính”.
Tuy nhiên, trong hai hoặc ba năm qua, ảnh hưởng kỳ diệu của Dữ liệu lớn đã yếu đi: kỹ thuật dữ liệu đã thực sự hấp thụ và khiến lĩnh vực này trở nên phổ biến, ít nhất là trong giới chuyên gia CNTT. Dữ liệu lớn ở khắp mọi nơi và nếu dữ liệu kinh doanh không phải là Lớn hôm nay, nó sẽ trở thành Lớn vào ngày mai. Đồng thời, sự chú ý đến các ngành nghề dữ liệu chỉ tăng lên và họ có nhu cầu không kém gì các nhà phát triển Java. Hơn nữa, trung bình các kỹ sư dữ liệu kiếm được nhiều tiền hơn so với các nhà phát triển phụ trợ (các nhà khoa học dữ liệu thậm chí còn được đánh giá cao hơn và chúng ta sẽ hiểu lý do tại sao ở phần sau của bài viết này).
Hôm nay, tôi thấy các nhà phát triển và các chuyên gia CNTT khác xung quanh tôi, những người có cùng câu hỏi về kỹ thuật dữ liệu mà tôi đã có cách đây 6-7 năm. Ở đây tôi đã cố gắng trả lời những câu hỏi phổ biến nhất và theo cách dễ tiếp cận. Tôi không giả vờ bao quát và tôi hoàn toàn hiểu rằng những người khác đã viết đầy đủ hơn và thú vị hơn về một số khía cạnh của nghề nghiệp - đó là lý do tại sao có rất nhiều liên kết trong văn bản.
Tôi hy vọng câu trả lời của tôi sẽ hữu ích cho các kỹ sư dữ liệu mới vào nghề và bất kỳ ai quan tâm đến kỹ thuật dữ liệu.
Kỹ sư dữ liệu là người giúp khách hàng có thể truy cập dữ liệu. Để làm điều này, kỹ sư dữ liệu hiểu chính xác cách thu thập dữ liệu cần thiết và thiết lập một quy trình có thể bao gồm:
- thu thập dữ liệu: giao dịch ngân hàng, đăng ký hệ thống khách hàng thân thiết, định vị địa lý của khách hàng, chỉ số cảm biến trên máy bay, v.v.;
- xóa dữ liệu khỏi lỗi và lặp lại - đảm bảo chất lượng dữ liệu cần thiết;
- chuyển đổi và tổng hợp dữ liệu;
- lưu trữ dữ liệu;
- giao hàng đúng và nhanh theo yêu cầu của khách hàng.
Khái niệm chính ở đây là kho dữ liệu: chúng tôi tải dữ liệu lên đó, chuyển đổi dữ liệu ở đó và dỡ dữ liệu từ đó xuống để phân tích. Theo quy định, việc lưu trữ có tính chất quan hệ, nhưng không giống như Hệ thống quản lý cơ sở dữ liệu giao dịch, nó được sử dụng cho tải phân tích (OLAP).
Điều đó có nghĩa là gì? Tải trọng giao dịch được đặc trưng bởi các phần tương đối nhỏ của dữ liệu được viết và đọc, cùng với số lượng người dùng tiềm năng lớn. Với tải phân tích, tình hình ngược lại: có phần lớn dữ liệu được viết và đọc, cùng với số lượng người dùng hạn chế. Đây là một trong những sắc thái của nghề nghiệp.
Có nhiều tùy chọn để lập mô hình kho lưu trữ, chẳng hạn như cổ điển, Tổ chức Kimball hoặc Inmon, hoặc các phương pháp hiện đại hơn, như Kho dữ liệu. Ngoài ra còn có các tùy chọn lưu trữ quan hệ không nghiêm ngặt, chẳng hạn như Data Lake hoặc nhà hồ — đối với họ, bạn cần xây dựng các quy trình riêng biệt để thu thập dữ liệu cũng như để hình thành trước và tải vào bộ lưu trữ.
Lựa chọn lưu trữ, công cụ để làm việc với dữ liệu, tốc độ xử lý dữ liệu và khả năng mở rộng quy mô đều là mối quan tâm của một kỹ sư dữ liệu. Quản trị viên dữ liệu thường là người chịu trách nhiệm đảm bảo rằng quy trình được định cấu hình hoạt động mà không bị gián đoạn trong một tháng, một năm và hơn thế nữa. Người này khắc phục sự cố và cải thiện năng suất. Hầu hết các kỹ sư dữ liệu cũng có thể làm điều này, nhưng lý tưởng nhất là đó không phải là trách nhiệm của họ.
Về mặt lý tưởng, dữ liệu sẽ được sử dụng như thế nào sau khi được cung cấp cũng không phải là mối quan tâm của kỹ sư dữ liệu. Điều chính là điều chỉnh bộ lưu trữ phù hợp với tải hàng ngày và loại dữ liệu.
Hãy nhớ rằng, các kỹ sư dữ liệu làm cho dữ liệu có thể truy cập được. Họ thu thập dữ liệu từ nhiều nguồn khác nhau, hệ thống hóa, xử lý và nói: “Dữ liệu đây, ai cần — lấy từ đây”. Ví dụ: người dùng doanh nghiệp, chẳng hạn như người quản lý, có thể lấy dữ liệu. Nhưng lý tưởng nhất là một nhà phân tích dữ liệu sẽ lấy dữ liệu trước.
Nhiệm vụ của nhà phân tích dữ liệu là giải thích và trực quan hóa dữ liệu, để tìm ra giá trị kinh doanh nào có thể được trích xuất. Các nhà phân tích dữ liệu sử dụng các mẫu trong dữ liệu để trả lời các câu hỏi kinh doanh, đưa ra dự báo và đưa ra khuyến nghị. Có thể nói rằng các nhà phân tích dữ liệu ảnh hưởng trực tiếp đến việc ra quyết định kinh doanh.
Theo đó, các nhà phân tích dữ liệu đặt ra các nhiệm vụ cho kỹ sư dữ liệu, chẳng hạn như lấy dữ liệu ở đâu để phân tích, những gì cần làm sạch và những gì cần sửa. Đôi khi, một kỹ sư dữ liệu tiến hành giải thích dữ liệu chính và một nhà phân tích dữ liệu chuẩn bị dữ liệu của riêng mình. Nhưng thường thì những quyền hạn này không chồng chéo lên nhau. Tuy nhiên, một nhà phân tích dữ liệu có trình độ cao hiểu dữ liệu phi cấu trúc, biết cách viết các truy vấn SQL phức tạp và viết một đoạn mã nhỏ bằng R hoặc Python.
Nói chung, một kỹ sư dữ liệu có thể là một nhà phân tích dữ liệu và ngược lại. Nếu nhà phân tích dữ liệu chỉ làm việc với các bảng tổng hợp Excel thì họ không liên quan gì đến kỹ thuật dữ liệu.
Trọng tâm của một kỹ sư BI là báo cáo. Đối với các máy khách lớn, kỹ sư BI xác định công cụ BI nào sẽ sử dụng, chẳng hạn như Tableau, Qlik, Power BI, Looker, Sisense, v.v. và định cấu hình chúng. Nhờ một kỹ sư BI, các nhà quản lý công ty có được bảng điều khiển trực quan cho biết mọi thứ đang diễn ra như thế nào trong công ty theo thời gian thực: chỉ trong vòng 10 giây, điểm yếu của công ty sẽ rõ ràng. Nếu người quản lý muốn, họ có thể chuyển đổi báo cáo thành bản trình bày.
Và ai sẽ cấu hình việc phân phối dữ liệu cần thiết đến hệ thống BI? Đúng vậy, một kỹ sư dữ liệu.
Tuy nhiên, trong các công ty nhỏ có tập dữ liệu nhỏ — không có nền tảng hoặc nền tảng cơ sở như MySQL hoặc Oracle — kỹ sư BI định cấu hình đường ống một cách độc lập. Nói chung, từ quan điểm kỹ năng, kỹ sư BI là sự kết hợp giữa kỹ sư dữ liệu và nhà phân tích dữ liệu: người này hiểu những điều cơ bản về tích hợp, xử lý và phân tích dữ liệu và có thể áp dụng kiến thức vào thực tế.
Mặt khác, hầu hết mọi kỹ sư dữ liệu sẽ xây dựng bảng điều khiển trong Tableau, chẳng hạn, mặc dù họ không có đủ kinh nghiệm để biết tất cả các khả năng của ngay cả những hệ thống BI phổ biến nhất. Ngoài ra, bất kỳ hệ thống nào cũng có vòng đời, kể cả hệ thống BI — chúng đang phát triển và cần được theo dõi cũng như cập nhật. Một kỹ sư dữ liệu thường không có thời gian cho việc này, nhưng việc theo dõi và cập nhật hệ thống là ưu tiên hàng đầu của một kỹ sư BI.
Nói tóm lại, chúng thực tế không có điểm chung nào, ngoại trừ việc kỹ sư dữ liệu (bây giờ bạn sẽ hiểu deja vu) thiết lập một hệ thống dữ liệu cần thiết cho nhà khoa học dữ liệu. Nhà khoa học dữ liệu cần dữ liệu này chủ yếu để đào tạo các mô hình sử dụng mạng thần kinh và thuật toán học máy.
Các mô hình được sử dụng trong kinh doanh để dự báo và đưa ra phản hồi tự động. Ví dụ: họ có thể đưa ra câu trả lời cho một công ty môi giới để mua hoặc bán cổ phiếu Apple.
Chủ đề của nhà khoa học dữ liệu bao gồm AI, ML và DL. Ngay cả một kỹ sư dữ liệu cấp cao cũng hiếm khi chạm tới những thứ này trong công việc của mình. Ngoài kỹ năng lập trình, các nhà khoa học dữ liệu còn phải có kỹ năng toán học và kiến thức vững chắc về thống kê.
Vì vậy, một kỹ sư dữ liệu là một quản trị viên dữ liệu, một nhà phân tích dữ liệu và một kỹ sư BI. Nhà phân tích dữ liệu, kỹ sư BI và quản trị viên dữ liệu cũng có thể là một kỹ sư dữ liệu. Và các nhà khoa học dữ liệu là một vũ trụ riêng biệt: họ có chu kỳ sản xuất khác, cơ sở lý thuyết và yêu cầu trình độ chuyên môn khác.
Tôi khuyên các kỹ sư dữ liệu mới vào nghề không nên bỏ qua cơ sở lý thuyết - đại số quan hệ và tính toán phân tán.
Người mới bắt đầu cần tìm hiểu ETL và ELT là gì, và sự khác biệt là gìnằm giữa chúng, ngoài thứ tự khác của các từ Trích xuất, Chuyển đổi và Tải. Họ cần phải hiểu được sự khác biệt giữa SQL và NoSQL. Họ phải làm quen với các lớp nhiệm vụ kỹ thuật dữ liệu và phân tách ở cấp độ cơ bản ít nhất một công cụ chính thống từ mỗi lớp:
- lưu trữ dữ liệu;
- xử lý dữ liệu phân tán;
- dàn nhạc.
Nó cũng hữu ích để biết Chu trình phát triển phần mềm: cách thu thập và ghi lại các yêu cầu cũng như cách phần mềm được phát triển, thử nghiệm và triển khai. Nhìn về tương lai, nhiều kỹ sư dữ liệu viết mã và viết bài kiểm tra tự động, nói cách khác là họ làm được mà không cần người kiểm tra.
Các kỹ sư dữ liệu giao tiếp trực tiếp khá nhiều với khách hàng, bỏ qua các nhà phân tích kinh doanh. Đây là những gì đang xảy ra trong dự án hiện tại của tôi: các kỹ sư dữ liệu đang dịch các tác vụ một cách độc lập từ ngôn ngữ kinh doanh sang ngôn ngữ công nghệ. Điều này có nghĩa là ngay từ đầu cần có sự hiểu biết chung về dữ liệu mà các doanh nghiệp cần và cách các ngân hàng, y tế, bán lẻ, viễn thông, công ty bảo hiểm và doanh nghiệp du lịch sử dụng chúng. Bạn không thể thành công nếu không có các kỹ năng mềm nâng cao và khả năng giao tiếp tiếng Anh tốt. Bạn sẽ cần trình độ tiếng Anh không thấp hơn Trung cấp.
Để bắt đầu, bạn có thể đọc blog bằng tiếng Anh của những người tạo ra công nghệ và công cụ cho kỹ thuật dữ liệu. Trong bài viết này, hầu hết các liên kết chỉ dẫn đến các blog như MongoDB, Qlik, AWS, v.v.
Nếu bạn đã chọn nền tảng mà bạn sắp thành thạo, bạn nên xem tài liệu đào tạo của nhà cung cấp. Các nền tảng chính thống, tự cung tự cấp như Snowflake và Bảng dữ liệu có nhiều tài liệu chất lượng cao với nhiều mức độ phức tạp khác nhau dành cho người mới bắt đầu, người trung cấp và kiến trúc sư. Tất nhiên, họ nhấn mạnh vào sản phẩm của mình.
Các kỹ sư dữ liệu có kinh thánh của riêng họ — DMBOK (Phần kiến thức quản lý dữ liệu). Các phương pháp quản lý dữ liệu được tiêu chuẩn hóa và các phương pháp hay nhất được mô tả ở đây.
Cuốn sách nghiêm túc và có lẽ nhàm chán này được thiết kế cho trình độ cao cấp trở lên. Nó rất hữu ích cho người mới bắt đầu sử dụng làm tài liệu tham khảo. DMBOK sẽ làm nổi bật các khu vực đáng để khám phá — sau đó bạn có thể truy cập blog của nhà cung cấp, nơi mọi thứ được mô tả theo cách thú vị và dễ tiếp cận hơn.
Nhiều kỹ sư dữ liệu biết cách viết mã. Đại đa số khách hàng mong đợi rằng kỹ sư dữ liệu biết SQL và một trong những ngôn ngữ này một cách hoàn hảo, ít nhất là ở cấp độ tập lệnh: Python, Scala, Java, JavaScript, C#.
Một số người trong chúng tôi sử dụng nền tảng mã thấp để tập hợp đường dẫn dữ liệu từ các công cụ làm sẵn (công cụ tích hợp dữ liệu). Trong trường hợp này, đôi khi họ được gọi là nhà phát triển ETL, Kỹ sư tích hợp dữ liệu hoặc tên nào khác. Về cơ bản những người này cũng là kỹ sư dữ liệu, chỉ có chuyên môn về tích hợp dữ liệu.
Họ có thể không biết một số sắc thái của nghề nghiệp. Ví dụ: nếu bạn cần tăng năng suất lên gấp 10 lần, chắc chắn sẽ gặp khó khăn nếu bạn không đưa ra một công cụ cụ thể để mở rộng quy mô và nói: “Hãy làm cái này”.
Nói một cách dễ hiểu, bạn có thể trở thành một kỹ sư dữ liệu ngay cả khi bạn chỉ có khả năng lập trình ở mức tối thiểu. Đồng thời, một kỹ sư dữ liệu chỉ biết các tập lệnh C# vẫn có thể đạt đến cấp độ cao cấp trở lên — giống như một kỹ sư QA không biết cách lập trình (không giống như QAA).
Tôi chỉ có thể nói ở đây về kinh nghiệm của bạn bè và đồng nghiệp cá nhân của tôi, điều này không nhất thiết phản ánh tình hình chung. Tôi hiếm khi gặp những người bước vào nghề hoàn toàn “từ đầu” — hầu hết đều là nhà phát triển hoặc chuyên gia dữ liệu. Hơn nữa, tôi không biết bất kỳ trường hợp nào mà các kỹ sư DevOps chuyển sang kỹ thuật dữ liệu. Có lẽ trung bình họ yêu thích công việc của mình hơn các ngành nghề khác trong lĩnh vực CNTT và đồng thời cũng có nhu cầu cao đến khó tin.
Nhiều kỹ sư dữ liệu khởi đầu là quản trị viên cơ sở dữ liệu hoặc nhà phân tích dữ liệu. Họ đã biết SQL, BI và hiểu cách xử lý dữ liệu. Bạn hoàn toàn có thể giải quyết các nhiệm vụ của một kỹ sư dữ liệu trong một số lĩnh vực chỉ trong sáu tháng với nền tảng như vậy.
Tôi có thể giả định rằng việc trở thành kỹ sư dữ liệu cho một nhà phát triển phụ trợ biết Java và/hoặc Python sẽ dễ dàng và nhanh chóng hơn. Nếu bạn biết Scala, Airflow hoặc Spark thì bạn thực sự đang ở một vị trí tốt.
Hầu như tất cả các công ty đều có cơ sở dữ liệu mà họ làm việc theo thời gian: họ tải lên một cái gì đó ở đó, dỡ bỏ một cái gì đó khác và bằng cách nào đó sử dụng cơ sở dữ liệu, tùy thuộc vào nhu cầu của họ. Ví dụ: nhà phát triển Python viết nền tảng, nhà phân tích kinh doanh và nhà tiếp thị phân tích dữ liệu và đôi khi kết nối quản trị viên hệ thống. Khi rõ ràng rằng cần có một cách tiếp cận có hệ thống và có đủ công việc cho một người, thì một kỹ sư dữ liệu sẽ được gọi để được trợ giúp.
Họ đến gặp chúng tôi và nói: “Chúng tôi có cơ sở dữ liệu của riêng mình, nhưng nó không thể chịu được tải trọng này. Chúng tôi muốn một giải pháp lưu trữ nơi chúng tôi có thể đặt mọi thứ và thực hiện các yêu cầu lớn, nặng nề” (nhân tiện, cũng có những trường hợp ngược lại: không có đủ dung lượng tải trên dung lượng lưu trữ và bạn cần tìm hiểu xem phải làm gì với nó) .
Được rồi, chúng tôi hiểu rằng dữ liệu cần được chuyển sang bộ nhớ trong và được cung cấp. Để làm cho tải trọng cho phép cao hơn, bạn cần phải mở rộng quy mô. Chúng tôi làm rõ các sắc thái: chúng tôi có cần xác thực dữ liệu hay chúng đến với chúng tôi trong sạch? Chúng tôi cần cập nhật/xử lý dữ liệu bao lâu một lần - liệu có đủ để làm như vậy mỗi ngày một lần không hay quá trình này diễn ra liên tục? Có thể có hàng chục yêu cầu tương tự.
Sau khi thu thập các yêu cầu, chúng tôi tiến hành thiết kế hệ thống. Chúng tôi chỉ ra cách chúng tôi sẽ giải quyết vấn đề về mặt công nghệ, với ngăn xếp nào. Đôi khi, khách hàng không chắc chắn về quyết định của họ — trong trường hợp này, chúng tôi hiển thị các tùy chọn thay thế và mô tả ưu và nhược điểm của từng tùy chọn. Điều xảy ra là khách hàng sẵn sàng vượt quá ngân sách được chỉ định nếu họ thấy một tùy chọn hữu ích hơn cho doanh nghiệp.
Chúng ta phải dễ hiểu đối với doanh nghiệp và nói được ngôn ngữ của nó. Nếu khách hàng am hiểu về công nghệ và hiểu rất rõ Data Warehouse khác với Data Lake như thế nào, sau đó chúng tôi cung cấp thêm chi tiết kỹ thuật. Nếu không, chúng tôi tập trung vào những điều cơ bản: chi phí bao nhiêu, mức độ an toàn của bộ lưu trữ và mức độ dễ dàng chuyển sang giải pháp của nhà cung cấp khác.
Chúng tôi chắc chắn sẽ thảo luận về cách chúng tôi sẽ hành động trong các tình huống khẩn cấp và phản ứng như vậy sẽ mất bao lâu.
Như trong hầu hết mọi ngành nghề, sự phát triển có thể là mở rộng (phát triển ra bên ngoài) hoặc bên trong (chiều sâu hơn). Bạn có thể thành thạo một ngăn xếp đến mức bạn sẽ bị coi là một á thần, hãy cúi đầu và yêu cầu thiết lập một thứ gì đó khi không ai khác có thể hiểu được. Bạn cũng có thể nâng cao kỹ năng quản lý của mình, trở thành trưởng nhóm, v.v.
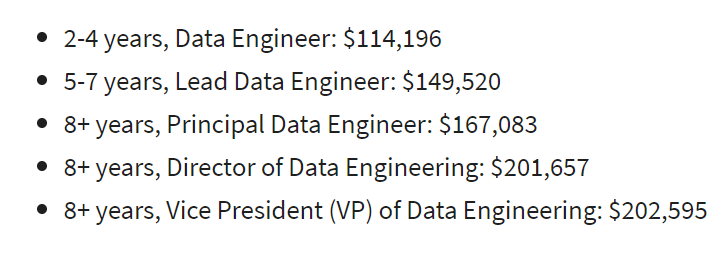
Theo dõi sự nghiệp của một kỹ sư dữ liệu ở Hoa Kỳ, theo Glassdoor
Cách thức mà một kỹ sư dữ liệu phát triển, cùng với danh sách các yêu cầu đối với kỹ sư dữ liệu, sẽ khác nhau tùy theo công ty. Ở công ty của tôi, bậc thang nghề nghiệp trông như thế này: Kỹ sư dữ liệu? Kỹ sư dữ liệu trưởng nhóm? Kiến trúc sư kỹ thuật dữ liệu? Kiến trúc sư giải pháp dữ liệu (DSA).
Kỹ sư dữ liệu. Biết các kiến thức cơ bản về quản lý dữ liệu: mô hình hóa dữ liệu, ELT/ETL, chất lượng dữ liệu, mô hình kho/hồ dữ liệu, hệ thống phân tán. Tự tin hoạt động với ít nhất một ngăn xếp: AWS, Azure, Snowflake, Apache Hadoop, v.v. Cần có SQL, cùng với ít nhất một ngôn ngữ: Scala, Python, Java, C#.
Kỹ sư dữ liệu trưởng nhóm. Người này biết những điều cơ bản về quản lý dữ liệu và kỹ thuật ở mức độ cao. Kỹ năng giao tiếp và giải quyết vấn đề mạnh mẽ. Biết cách quản lý dự án, giao hàng và thay đổi.
Kiến trúc sư kỹ thuật dữ liệu. Theo quy định, đây là người có nguyện vọng đạt được vị trí DSA, nhưng thiếu kinh nghiệm và sự hiểu biết về công nghệ. Người đó biết rõ ít nhất một ngăn xếp và có thể tìm ra các chi tiết kỹ thuật của việc triển khai giải pháp dưới sự hướng dẫn của DSA.
Kiến trúc sư giải pháp dữ liệu. Một chuyên gia về quản lý dữ liệu và kỹ thuật dữ liệu. Người này biết các công nghệ hiện tại để làm việc với dữ liệu ở cấp độ kiến trúc sư và có thể nhanh chóng thành thạo các công nghệ mới. Người này có kỹ năng lãnh đạo, dự án và quản lý thay đổi, cộng với quản lý kỹ thuật, chẳng hạn như quản lý nhóm và bộ phận kỹ thuật.
Các công ty CNTT lớn thường tạo ra các trung tâm năng lực để phát triển các kỹ năng cứng và mềm. Ví dụ: hiện có gần 200 chuyên gia dữ liệu trong DataArt, trong đó có một số người ở Trung tâm Xuất sắc (bao gồm cả tôi). Mục tiêu chính của chúng tôi là giúp các đồng nghiệp chọn hướng mà họ muốn phát triển một cách chuyên nghiệp và giúp họ làm chủ các công nghệ mới. Chúng tôi mang đến cho các chuyên gia dữ liệu cơ hội phát huy hết tiềm năng với tư cách là người cố vấn, diễn giả, chuyên gia kỹ thuật và chuyên gia dịch vụ khách hàng.
Đối với tôi, có vẻ như ngày càng có nhiều sự chú ý hơn đến việc quản lý dữ liệu, hoặc Quản trị dữ liệu. Trước đây, một công ty có thể kết xuất dữ liệu vào Hồ dữ liệu, cuối cùng dữ liệu này biến thành “đầm lầy dữ liệu”: một số dữ liệu khó hiểu, rất khó để tìm ra ai đã đặt cái gì và tại sao. Giờ đây, ở cấp độ kiến trúc, công ty này xem xét việc quản lý dữ liệu từ các quan điểm khác nhau và mô tả cách đảm bảo Chất lượng dữ liệuvà cách xử lý siêu dữ liệu, dữ liệu chính và dữ liệu tham chiếu, v.v. Điều này khó hơn nhiều so với việc xây dựng một đường dẫn ETL.
Một trong những xu hướng là chuyển đổi sang các hệ thống được quản lý bằng đám mây. Tức là chúng tôi không triển khai hệ thống tại nhà mà mua hệ thống làm sẵn, lắp ráp trên đám mây. Chúng tôi có thể có một nhóm yêu cầu cho ít nhất 10 nghìn máy, nhưng chúng tôi không cần phải suy nghĩ về cách mọi thứ được phân phối và chia tỷ lệ ở đó.
Xu hướng không có máy chủ như vậy là một điều rất quan trọng đối với kỹ thuật dữ liệu. Do đó, Dữ liệu lớn mất đi sức hấp dẫn kỳ diệu vì Dữ liệu lớn chủ yếu là về tỷ lệ theo chiều ngang. Nhờ có các đám mây, trọng tâm của các kỹ sư dữ liệu đang chuyển từ mở rộng quy mô sang quản lý dữ liệu. Về mặt khái niệm, truy vấn chính xác hơn bây giờ không phải là cách làm việc với dữ liệu lớn mà là cách quản lý dữ liệu nói chung.
Số lượng công nghệ tăng cao và ngày càng có nhiều công cụ tương tự khác nhau. Hầu như không thể tìm thấy một chuyên gia phù hợp 100% trong ngăn xếp kỹ thuật. Ví dụ, điều này có nghĩa là một kỹ sư dữ liệu ở bất kỳ cấp độ nào cũng phải có kiến thức cần thiết trong thực tế và điều này là bình thường.
Ilya Moshkov là Kỹ sư dữ liệu cấp cao và là thành viên của Trung tâm dữ liệu xuất sắc của DataArt

