فاؤنڈیشن ماڈلز (FMs) بڑے مشین لرننگ (ML) ماڈلز ہیں جنہیں بغیر لیبل والے اور عام ڈیٹا سیٹس کے وسیع اسپیکٹرم پر تربیت دی جاتی ہے۔ FMs، جیسا کہ نام سے پتہ چلتا ہے، مزید خصوصی ڈاؤن اسٹریم ایپلی کیشنز بنانے کی بنیاد فراہم کرتے ہیں، اور اپنی موافقت میں منفرد ہیں۔ وہ مختلف کاموں کی ایک وسیع رینج انجام دے سکتے ہیں، جیسے کہ قدرتی زبان کی پروسیسنگ، تصویروں کی درجہ بندی کرنا، رجحانات کی پیشن گوئی کرنا، جذبات کا تجزیہ کرنا، اور سوالات کا جواب دینا۔ یہ پیمانہ اور عام مقصد کی موافقت وہ ہے جو FMs کو روایتی ML ماڈلز سے مختلف بناتی ہے۔ ایف ایم ملٹی موڈل ہیں۔ وہ مختلف ڈیٹا کی اقسام جیسے کہ ٹیکسٹ، ویڈیو، آڈیو اور امیجز کے ساتھ کام کرتے ہیں۔ بڑے لینگوئج ماڈلز (LLMs) FM کی ایک قسم ہیں اور متنی ڈیٹا کی وسیع مقدار پر پہلے سے تربیت یافتہ ہوتے ہیں اور عام طور پر اطلاق کے استعمال ہوتے ہیں جیسے کہ ٹیکسٹ جنریشن، ذہین چیٹ بوٹس، یا خلاصہ۔
سٹریمنگ ڈیٹا متنوع اور تازہ ترین معلومات کے مسلسل بہاؤ کو سہولت فراہم کرتا ہے، جس سے ماڈلز کی موافقت اور زیادہ درست، سیاق و سباق سے متعلقہ نتائج پیدا کرنے کی صلاحیت میں اضافہ ہوتا ہے۔ اسٹریمنگ ڈیٹا کا یہ متحرک انضمام قابل بناتا ہے۔ پیدا کرنے والا AI مختلف کاموں میں ان کی موافقت اور مجموعی کارکردگی کو بہتر بنانے، بدلتے ہوئے حالات کا فوری جواب دینے کے لیے ایپلی کیشنز۔
اس کو بہتر طور پر سمجھنے کے لیے، ایک چیٹ بوٹ کا تصور کریں جو مسافروں کو اپنا سفر بک کرنے میں مدد کرتا ہے۔ اس منظر نامے میں، چیٹ بوٹ کو ایئر لائن کی انوینٹری، فلائٹ اسٹیٹس، ہوٹل کی انوینٹری، قیمتوں میں ہونے والی تازہ ترین تبدیلیوں، اور بہت کچھ تک حقیقی وقت تک رسائی کی ضرورت ہے۔ یہ ڈیٹا عام طور پر فریق ثالث کی طرف سے آتا ہے، اور ڈویلپرز کو اس ڈیٹا کو ہضم کرنے کا طریقہ تلاش کرنے اور ڈیٹا میں ہونے والی تبدیلیوں پر کارروائی کرنے کی ضرورت ہوتی ہے۔
بیچ پروسیسنگ اس منظر نامے میں بہترین فٹ نہیں ہے۔ جب ڈیٹا تیزی سے تبدیل ہوتا ہے، تو اسے بیچ میں پروسیس کرنے کے نتیجے میں چیٹ بوٹ کے ذریعے باسی ڈیٹا استعمال کیا جا سکتا ہے، جو گاہک کو غلط معلومات فراہم کرتا ہے، جس سے صارف کے مجموعی تجربے پر اثر پڑتا ہے۔ تاہم، سٹریم پروسیسنگ چیٹ بوٹ کو ریئل ٹائم ڈیٹا تک رسائی حاصل کرنے اور دستیابی اور قیمت میں ہونے والی تبدیلیوں کو اپنانے کے قابل بنا سکتی ہے، جو گاہک کو بہترین رہنمائی فراہم کرتی ہے اور کسٹمر کے تجربے کو بڑھاتی ہے۔
ایک اور مثال AI سے چلنے والا مشاہدہ اور نگرانی کا حل ہے جہاں FMs سسٹم کے ریئل ٹائم اندرونی میٹرکس کی نگرانی کرتے ہیں اور الرٹس تیار کرتے ہیں۔ جب ماڈل کو کوئی بے ضابطگی یا غیر معمولی میٹرک قدر ملتی ہے، تو اسے فوری طور پر ایک الرٹ پیش کرنا چاہیے اور آپریٹر کو مطلع کرنا چاہیے۔ تاہم، اس طرح کے اہم ڈیٹا کی قدر وقت کے ساتھ نمایاں طور پر کم ہو جاتی ہے۔ یہ اطلاعات مثالی طور پر سیکنڈوں میں موصول ہو جانی چاہئیں یا اس کے ہونے کے دوران بھی۔ اگر آپریٹرز کو یہ اطلاعات ان کے ہونے کے چند منٹ یا گھنٹوں بعد موصول ہوتی ہیں، تو ایسی بصیرت قابل عمل نہیں ہے اور ممکنہ طور پر اس کی قدر کھو چکی ہے۔ آپ دیگر صنعتوں جیسے خوردہ، کار مینوفیکچرنگ، توانائی، اور مالیاتی صنعت میں اسی طرح کے استعمال کے معاملات تلاش کر سکتے ہیں۔
اس پوسٹ میں، ہم اس بات پر بات کرتے ہیں کہ ڈیٹا سٹریمنگ اصل وقت کی نوعیت کی وجہ سے تخلیقی AI ایپلی کیشنز کا ایک اہم جزو کیوں ہے۔ ہم AWS ڈیٹا اسٹریمنگ سروسز کی قدر پر تبادلہ خیال کرتے ہیں جیسے ایمیزون نے اپاچی کافکا کے لیے سٹریمنگ کا انتظام کیا۔ (ایمیزون MSK) Amazon Kinesis ڈیٹا اسٹریمز, Apache Flink کے لیے Amazon کے زیر انتظام سروس، اور ایمیزون کائنیسس ڈیٹا فائر ہوز تخلیقی AI ایپلی کیشنز کی تعمیر میں۔
سیاق و سباق میں سیکھنا
LLMs کو پوائنٹ ان ٹائم ڈیٹا کے ساتھ تربیت دی جاتی ہے اور ان میں قیاس وقت پر تازہ ڈیٹا تک رسائی کی کوئی موروثی صلاحیت نہیں ہوتی ہے۔ جیسا کہ نیا ڈیٹا ظاہر ہوتا ہے، آپ کو ماڈل کو مسلسل ٹھیک کرنا یا مزید تربیت دینا ہوگی۔ یہ نہ صرف ایک مہنگا آپریشن ہے، بلکہ عملی طور پر بھی بہت محدود ہے کیونکہ نئے ڈیٹا بنانے کی شرح فائن ٹیوننگ کی رفتار سے کہیں زیادہ ہے۔ مزید برآں، LLMs میں سیاق و سباق کی سمجھ کی کمی ہوتی ہے اور وہ مکمل طور پر اپنے تربیتی ڈیٹا پر انحصار کرتے ہیں، اور اس وجہ سے وہ فریب کاری کا شکار ہوتے ہیں۔ اس کا مطلب ہے کہ وہ روانی، مربوط، اور نحوی طور پر آواز پیدا کر سکتے ہیں لیکن حقیقت میں غلط جواب دے سکتے ہیں۔ وہ مطابقت، شخصیت سازی اور سیاق و سباق سے بھی خالی ہیں۔
تاہم، LLMs کے پاس سیاق و سباق سے موصول ہونے والے ڈیٹا سے سیکھنے کی صلاحیت ہوتی ہے تاکہ وہ ماڈل کے وزن میں ترمیم کیے بغیر زیادہ درست طریقے سے جواب دیں۔ اسے کہتے ہیں۔ سیاق و سباق کی تعلیم، اور ذاتی نوعیت کے جوابات تیار کرنے یا تنظیم کی پالیسیوں کے تناظر میں درست جواب فراہم کرنے کے لیے استعمال کیا جا سکتا ہے۔
مثال کے طور پر، ایک چیٹ بوٹ میں، ڈیٹا ایونٹس کا تعلق پروازوں اور ہوٹلوں کی انوینٹری یا قیمتوں میں ہونے والی تبدیلیوں سے ہو سکتا ہے جو مسلسل اسٹریمنگ سٹوریج انجن میں داخل کی جاتی ہیں۔ مزید برآں، ڈیٹا ایونٹس کو اسٹریم پروسیسر کا استعمال کرتے ہوئے فلٹر، افزودہ اور قابل استعمال فارمیٹ میں تبدیل کیا جاتا ہے۔ نتیجہ تازہ ترین سنیپ شاٹ سے استفسار کر کے ایپلیکیشن کو دستیاب کرایا جاتا ہے۔ اسنیپ شاٹ سٹریم پروسیسنگ کے ذریعے مسلسل اپ ڈیٹ ہوتا رہتا ہے۔ لہذا، تازہ ترین ڈیٹا ماڈل کو صارف کے پرامپٹ کے تناظر میں فراہم کیا جاتا ہے۔ یہ ماڈل کو قیمت اور دستیابی میں تازہ ترین تبدیلیوں کے مطابق ڈھالنے کی اجازت دیتا ہے۔ مندرجہ ذیل خاکہ سیاق و سباق میں سیکھنے کے ایک بنیادی ورک فلو کو واضح کرتا ہے۔
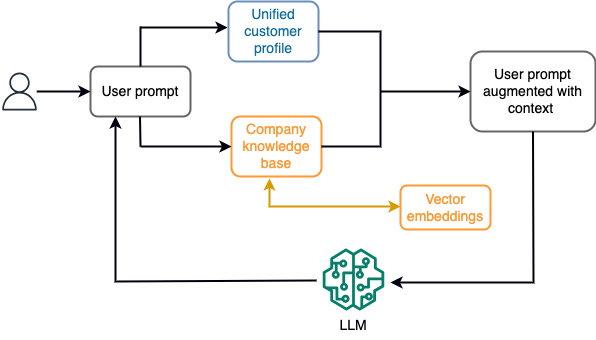
سیاق و سباق میں سیکھنے کا ایک عام طریقہ استعمال کیا جاتا ہے جسے Retrieval Augmented Generation (RAG) کہا جاتا ہے۔ RAG میں، آپ پرامپٹ پر صارف کے سوال کے ساتھ متعلقہ معلومات جیسے کہ انتہائی متعلقہ پالیسی اور کسٹمر ریکارڈ فراہم کرتے ہیں۔ اس طرح، LLM سیاق و سباق کے طور پر فراہم کردہ اضافی معلومات کا استعمال کرتے ہوئے صارف کے سوال کا جواب تیار کرتا ہے۔ RAG کے بارے میں مزید جاننے کے لیے، رجوع کریں۔ ایمیزون سیج میکر جمپ اسٹارٹ میں فاؤنڈیشن ماڈلز کے ساتھ ریٹریول اگمنٹڈ جنریشن کا استعمال کرتے ہوئے سوالوں کا جواب.
RAG پر مبنی جنریٹو AI ایپلیکیشن اپنے تربیتی ڈیٹا اور علمی بنیاد میں متعلقہ دستاویزات کی بنیاد پر صرف عمومی ردعمل پیدا کر سکتی ہے۔ یہ حل اس وقت کم پڑ جاتا ہے جب ایپلیکیشن سے قریب قریب حقیقی وقت میں ذاتی نوعیت کے جواب کی توقع کی جاتی ہے۔ مثال کے طور پر، ایک ٹریول چیٹ بوٹ سے توقع کی جاتی ہے کہ وہ صارف کی موجودہ بکنگ، دستیاب ہوٹل اور فلائٹ انوینٹری، اور مزید بہت کچھ پر غور کرے۔ مزید یہ کہ، متعلقہ کسٹمر کا ذاتی ڈیٹا (عام طور پر کے نام سے جانا جاتا ہے۔ متحد کسٹمر پروفائل) عام طور پر تبدیلی کے تابع ہوتا ہے۔ اگر تخلیقی AI کے صارف پروفائل ڈیٹا بیس کو اپ ڈیٹ کرنے کے لیے بیچ کے عمل کو استعمال کیا جاتا ہے، تو صارف کو پرانے ڈیٹا کی بنیاد پر غیر اطمینان بخش جوابات مل سکتے ہیں۔
اس پوسٹ میں، ہم سٹریم پروسیسنگ کے اطلاق پر تبادلہ خیال کرتے ہیں تاکہ ایک RAG حل کو بہتر بنایا جا سکے جس کا استعمال سوالوں کے جواب دینے والے ایجنٹوں کو سیاق و سباق کے ساتھ صارف کے متحد پروفائلز اور تنظیمی علمی بنیاد تک حقیقی وقت تک رسائی کے ساتھ کیا جائے۔
قریب قریب ریئل ٹائم کسٹمر پروفائل اپ ڈیٹس
گاہک کے ریکارڈ عام طور پر کسی تنظیم کے اندر ڈیٹا اسٹورز میں تقسیم کیے جاتے ہیں۔ متعلقہ، درست اور تازہ ترین کسٹمر پروفائل فراہم کرنے کے لیے آپ کی جنریٹیو AI ایپلیکیشن کے لیے، اسٹریمنگ ڈیٹا پائپ لائنز بنانا بہت ضروری ہے جو تقسیم شدہ ڈیٹا اسٹورز میں شناختی حل اور پروفائل کو جمع کر سکے۔ سٹریمنگ جابز سسٹم میں مطابقت پذیری کے لیے مسلسل نئے ڈیٹا کو ہضم کرتی ہیں اور وقت کی کھڑکیوں میں افزودگی، تبدیلیاں، جوائنز اور مجموعے کو زیادہ مؤثر طریقے سے انجام دے سکتی ہیں۔ ڈیٹا کیپچر کو تبدیل کریں (CDC) ایونٹس میں سورس ریکارڈ، اپ ڈیٹس، اور میٹا ڈیٹا جیسے وقت، ماخذ، درجہ بندی (داخل کرنا، اپ ڈیٹ کرنا یا حذف کرنا) اور تبدیلی کے آغاز کرنے والے کے بارے میں معلومات ہوتی ہیں۔
مندرجہ ذیل خاکہ سی ڈی سی اسٹریمنگ ادخال اور متحد کسٹمر پروفائلز کے لیے پروسیسنگ کے لیے ایک مثالی ورک فلو کی وضاحت کرتا ہے۔

اس سیکشن میں، ہم RAG پر مبنی جنریٹو AI ایپلی کیشنز کو سپورٹ کرنے کے لیے درکار CDC اسٹریمنگ پیٹرن کے اہم اجزاء پر تبادلہ خیال کرتے ہیں۔
سی ڈی سی اسٹریمنگ ادخال
سی ڈی سی ریپلیکٹر ایک ایسا عمل ہے جو ماخذ کے نظام سے ڈیٹا کی تبدیلیوں کو اکٹھا کرتا ہے (عام طور پر ٹرانزیکشن لاگز یا بِن لاگز پڑھ کر) اور سی ڈی سی کے واقعات کو بالکل اسی ترتیب کے ساتھ لکھتا ہے جو وہ کسی سٹریمنگ ڈیٹا سٹریم یا موضوع میں پیش آئے تھے۔ اس میں ٹولز کے ساتھ لاگ پر مبنی کیپچر شامل ہے جیسے AWS ڈیٹا بیس مائیگریشن سروس (AWS DMS) یا اوپن سورس کنیکٹر جیسے ڈیبیزیم برائے اپاچی کافکا کنیکٹ۔ اپاچی کافکا کنیکٹ اپاچی کافکا ماحول کا حصہ ہے، جس سے ڈیٹا مختلف ذرائع سے حاصل کیا جا سکتا ہے اور مختلف مقامات تک پہنچایا جا سکتا ہے۔ آپ اپنا اپاچی کافکا کنیکٹر چلا سکتے ہیں۔ ایمیزون ایم ایس کے کنیکٹ اپاچی کافکا کلسٹر کی ترتیب، سیٹ اپ اور آپریٹنگ کے بارے میں فکر کیے بغیر منٹوں میں۔ آپ کو صرف اپنے کنیکٹر کا مرتب کردہ کوڈ اپ لوڈ کرنے کی ضرورت ہے۔ ایمیزون سادہ اسٹوریج سروس (Amazon S3) اور اپنے کنیکٹر کو اپنے کام کے بوجھ کی مخصوص کنفیگریشن کے ساتھ سیٹ اپ کریں۔
ڈیٹا کی تبدیلیوں کو کیپچر کرنے کے دوسرے طریقے بھی ہیں۔ مثال کے طور پر، ایمیزون ڈائنومو ڈی بی کو سی ڈی سی ڈیٹا کو اسٹریم کرنے کے لیے ایک خصوصیت فراہم کرتا ہے۔ Amazon DynamoDB اسٹریمز یا Kinesis ڈیٹا اسٹریمز۔ ایمیزون ایس 3 ایک ٹرگر فراہم کرتا ہے۔ او ڈبلیو ایس لامبڈا۔ فنکشن جب ایک نئی دستاویز کو ذخیرہ کیا جاتا ہے.
اسٹریمنگ اسٹوریج
سٹریمنگ سٹوریج فنکشنز کو انٹرمیڈیٹ بفر کے طور پر CDC ایونٹس کو پروسیس ہونے سے پہلے اسٹور کرنے کے لیے۔ اسٹریمنگ اسٹوریج ڈیٹا کو اسٹریم کرنے کے لیے قابل اعتماد اسٹوریج فراہم کرتا ہے۔ ڈیزائن کے لحاظ سے، یہ ہارڈ ویئر یا نوڈ کی ناکامیوں کے لیے انتہائی دستیاب اور لچکدار ہے اور واقعات کے لکھے ہوئے ترتیب کو برقرار رکھتا ہے۔ اسٹریمنگ اسٹوریج ڈیٹا ایونٹس کو مستقل طور پر یا ایک مقررہ مدت کے لیے اسٹور کر سکتی ہے۔ اگر کوئی ناکامی ہو یا دوبارہ پروسیسنگ کی ضرورت ہو تو یہ سٹریم پروسیسرز کو سٹریم کے کچھ حصے سے پڑھنے کی اجازت دیتا ہے۔ Kinesis Data Streams ایک سرور لیس سٹریمنگ ڈیٹا سروس ہے جو ڈیٹا اسٹریمز کو پیمانے پر کیپچر، پروسیس، اور اسٹور کرنے کو سیدھا بناتی ہے۔ Amazon MSK Apache Kafka چلانے کے لیے AWS کے ذریعے فراہم کردہ مکمل طور پر منظم، انتہائی دستیاب، اور محفوظ سروس ہے۔
اسٹریم پروسیسنگ
سٹریم پروسیسنگ سسٹمز کو متوازی کے لیے ڈیزائن کیا جانا چاہیے تاکہ ہائی ڈیٹا تھرو پٹ کو ہینڈل کیا جا سکے۔ انہیں ان پٹ اسٹریم کو ایک سے زیادہ کمپیوٹ نوڈس پر چلنے والے متعدد کاموں کے درمیان تقسیم کرنا چاہیے۔ کاموں کو نیٹ ورک پر ایک آپریشن کے نتیجے کو دوسرے کو بھیجنے کے قابل ہونا چاہئے، جوائن، فلٹرنگ، افزودگی، اور جمع کرنے جیسے کاموں کو انجام دیتے ہوئے متوازی طور پر ڈیٹا کی پروسیسنگ کو ممکن بناتا ہے۔ سٹریم پروسیسنگ ایپلی کیشنز کو ایونٹ کے وقت کے حوالے سے ایونٹس پر کارروائی کرنے کے قابل ہونا چاہیے جہاں واقعات دیر سے پہنچ سکتے ہیں یا درست حساب کتاب سسٹم کے وقت کے بجائے واقعات کے پیش آنے والے وقت پر منحصر ہے۔ مزید معلومات کے لیے رجوع کریں۔ وقت کے تصورات: تقریب کا وقت اور پروسیسنگ کا وقت.
سٹریم کے عمل مسلسل اعداد و شمار کے واقعات کی شکل میں نتائج پیدا کرتے ہیں جن کو ٹارگٹ سسٹم میں آؤٹ پٹ کرنے کی ضرورت ہوتی ہے۔ ایک ٹارگٹ سسٹم کوئی بھی ایسا سسٹم ہو سکتا ہے جو براہ راست عمل کے ساتھ یا سٹریمنگ سٹوریج کے ذریعے ثالثی کی طرح ضم کر سکے۔ اسٹریم پروسیسنگ کے لیے آپ جس فریم ورک کا انتخاب کرتے ہیں اس پر منحصر ہے، دستیاب سنک کنیکٹرز کے لحاظ سے آپ کے پاس ٹارگٹ سسٹمز کے لیے مختلف اختیارات ہوں گے۔ اگر آپ نتائج کو درمیانی سٹریمنگ سٹوریج پر لکھنے کا فیصلہ کرتے ہیں، تو آپ ایک الگ عمل بنا سکتے ہیں جو واقعات کو پڑھتا ہے اور ٹارگٹ سسٹم میں تبدیلیاں لاگو کرتا ہے، جیسے کہ اپاچی کافکا سنک کنیکٹر چلانا۔ اس سے قطع نظر کہ آپ جو بھی آپشن منتخب کرتے ہیں، سی ڈی سی ڈیٹا کو اس کی نوعیت کی وجہ سے اضافی ہینڈلنگ کی ضرورت ہوتی ہے۔ چونکہ CDC ایونٹس اپ ڈیٹس یا ڈیلیٹ کے بارے میں معلومات رکھتے ہیں، اس لیے یہ ضروری ہے کہ وہ ٹارگٹ سسٹم میں صحیح ترتیب میں ضم ہوں۔ اگر تبدیلیوں کو غلط ترتیب میں لاگو کیا جاتا ہے، تو ہدف کا نظام اپنے ماخذ کے ساتھ ہم آہنگی سے باہر ہو جائے گا۔
اپاچی فلنک ایک طاقتور اسٹریم پروسیسنگ فریم ورک ہے جو اپنی کم تاخیر اور اعلی تھرو پٹ صلاحیتوں کے لیے جانا جاتا ہے۔ یہ ایونٹ ٹائم پروسیسنگ، بالکل ایک بار پروسیسنگ سیمنٹکس، اور ہائی فالٹ ٹولرنس کو سپورٹ کرتا ہے۔ مزید برآں، یہ CDC ڈیٹا کے لیے مقامی مدد فراہم کرتا ہے جسے ایک خاص ڈھانچہ کہتے ہیں۔ متحرک میزیں. ڈائنامک ٹیبلز سورس ڈیٹا بیس ٹیبلز کی نقل کرتی ہیں اور اسٹریمنگ ڈیٹا کی کالم نما نمائندگی فراہم کرتی ہیں۔ متحرک جدولوں میں ڈیٹا ہر اس واقعہ کے ساتھ تبدیل ہوتا ہے جس پر کارروائی ہوتی ہے۔ نئے ریکارڈز کو کسی بھی وقت شامل، اپ ڈیٹ، یا حذف کیا جا سکتا ہے۔ ڈائنامک ٹیبلز آپ کو ہر ریکارڈ آپریشن (داخل، اپ ڈیٹ، ڈیلیٹ) کے لیے الگ سے لاگو کرنے کے لیے درکار اضافی منطق کا خلاصہ کرتی ہیں۔ مزید معلومات کے لیے رجوع کریں۔ متحرک میزیں.
ساتھ Apache Flink کے لیے Amazon کے زیر انتظام سروسآپ Apache Flink جابز چلا سکتے ہیں اور دیگر AWS سروسز کے ساتھ ضم کر سکتے ہیں۔ انتظام کرنے کے لیے کوئی سرورز اور کلسٹرز نہیں ہیں، اور ترتیب دینے کے لیے کوئی کمپیوٹ اور اسٹوریج انفراسٹرکچر نہیں ہے۔
AWS گلو ایک مکمل طور پر منظم ایکسٹریکٹ، ٹرانسفارم، اور لوڈ (ETL) سروس ہے، جس کا مطلب ہے کہ AWS آپ کے لیے انفراسٹرکچر کی فراہمی، اسکیلنگ اور دیکھ بھال کو ہینڈل کرتا ہے۔ اگرچہ یہ بنیادی طور پر اپنی ETL صلاحیتوں کے لیے جانا جاتا ہے، لیکن AWS Glue کو Spark سٹریمنگ ایپلی کیشنز کے لیے بھی استعمال کیا جا سکتا ہے۔ AWS Glue CDC ڈیٹا کو پروسیسنگ اور تبدیل کرنے کے لیے سٹریمنگ ڈیٹا سروسز جیسے Kinesis Data Streams اور Amazon MSK کے ساتھ بات چیت کر سکتا ہے۔ AWS Glue بغیر کسی رکاوٹ کے دیگر AWS خدمات جیسے کہ Lambda کے ساتھ ضم کر سکتا ہے، AWS اسٹیپ فنکشنز، اور DynamoDB، آپ کو ڈیٹا پروسیسنگ پائپ لائنوں کی تعمیر اور انتظام کے لیے ایک جامع ماحولیاتی نظام فراہم کرتا ہے۔
متحد کسٹمر پروفائل
مختلف سورس سسٹمز میں کسٹمر پروفائل کے اتحاد پر قابو پانے کے لیے مضبوط ڈیٹا پائپ لائنز کی ترقی کی ضرورت ہے۔ آپ کو ڈیٹا پائپ لائنز کی ضرورت ہے جو تمام ریکارڈز کو ایک ڈیٹا سٹور میں لا اور سنکرونائز کر سکیں۔ یہ ڈیٹا سٹور آپ کی تنظیم کو مکمل کسٹمر ریکارڈ ویو فراہم کرتا ہے جو RAG پر مبنی جنریٹو AI ایپلی کیشنز کی آپریشنل کارکردگی کے لیے درکار ہے۔ اس طرح کے ڈیٹا اسٹور کی تعمیر کے لیے، غیر ساختہ ڈیٹا اسٹور بہترین ہوگا۔
ایک شناختی گراف ایک متحد کسٹمر پروفائل بنانے کے لیے ایک مفید ڈھانچہ ہے کیونکہ یہ مختلف ذرائع سے کسٹمر ڈیٹا کو یکجا اور انضمام کرتا ہے، ڈیٹا کی درستگی اور تخفیف کو یقینی بناتا ہے، ریئل ٹائم اپ ڈیٹس پیش کرتا ہے، کراس سسٹم بصیرت کو جوڑتا ہے، پرسنلائزیشن کو قابل بناتا ہے، کسٹمر کے تجربے کو بڑھاتا ہے، اور ریگولیٹری تعمیل کی حمایت کرتا ہے۔ یہ متحد کسٹمر پروفائل تخلیقی AI ایپلیکیشن کو مؤثر طریقے سے صارفین کو سمجھنے اور ان کے ساتھ منسلک ہونے، اور ڈیٹا پرائیویسی کے ضوابط پر عمل کرنے کی طاقت دیتا ہے، بالآخر صارفین کے تجربات کو بڑھاتا ہے اور کاروبار کی ترقی کو آگے بڑھاتا ہے۔ آپ اپنا شناختی گراف حل استعمال کر کے بنا سکتے ہیں۔ ایمیزون نیپچون، ایک تیز، قابل اعتماد، مکمل طور پر منظم گراف ڈیٹا بیس سروس۔
AWS غیر منظم کلیدی قدر والی اشیاء کے لیے چند دیگر منظم اور سرور کے بغیر NoSQL اسٹوریج سروس کی پیشکش فراہم کرتا ہے۔ ایمیزون دستاویز ڈی بی (MongoDB مطابقت کے ساتھ) ایک تیز، قابل توسیع، انتہائی دستیاب، اور مکمل طور پر منظم انٹرپرائز ہے دستاویز ڈیٹا بیس خدمت جو مقامی JSON کام کے بوجھ کو سپورٹ کرتی ہے۔ DynamoDB ایک مکمل طور پر منظم NoSQL ڈیٹابیس سروس ہے جو ہموار اسکیل ایبلٹی کے ساتھ تیز رفتار اور متوقع کارکردگی فراہم کرتی ہے۔
قریب قریب حقیقی وقت میں تنظیمی علم کی بنیاد کی تازہ کاری
گاہک کے ریکارڈ کی طرح، اندرونی معلومات کے ذخیرے جیسے کہ کمپنی کی پالیسیاں اور تنظیمی دستاویزات کو تمام سٹوریج سسٹمز میں بند کر دیا جاتا ہے۔ یہ عام طور پر غیر ساختہ ڈیٹا ہوتا ہے اور اسے غیر اضافی انداز میں اپ ڈیٹ کیا جاتا ہے۔ AI ایپلی کیشنز کے لیے غیر ساختہ ڈیٹا کا استعمال ویکٹر ایمبیڈنگز کا استعمال کرتے ہوئے مؤثر ہے، جو کہ اعلی جہتی ڈیٹا جیسے ٹیکسٹ فائلز، امیجز اور آڈیو فائلوں کو کثیر جہتی عددی کے طور پر پیش کرنے کی تکنیک ہے۔
AWS کئی فراہم کرتا ہے۔ ویکٹر انجن کی خدمات، جیسے ایمیزون اوپن سرچ سرور لیس, ایمیزون کیندر، اور Amazon Aurora PostgreSQL- ہم آہنگ ایڈیشن ویکٹر ایمبیڈنگز کو ذخیرہ کرنے کے لیے پی جی ویکٹر ایکسٹینشن کے ساتھ۔ جنریٹو AI ایپلیکیشنز صارف کے تجربے کو ویکٹر میں تبدیل کر کے صارف کے تجربے کو بڑھا سکتی ہیں اور اسے ویکٹر انجن سے استفسار کرنے کے لیے استعمال کر سکتی ہیں تاکہ سیاق و سباق سے متعلقہ معلومات کو بازیافت کیا جا سکے۔ پرامپٹ اور حاصل کردہ ویکٹر ڈیٹا دونوں کو مزید درست اور ذاتی نوعیت کا جواب حاصل کرنے کے لیے پھر LLM کو بھیج دیا جاتا ہے۔
مندرجہ ذیل خاکہ ویکٹر ایمبیڈنگز کے لیے اسٹریم پروسیسنگ ورک فلو کی مثال پیش کرتا ہے۔
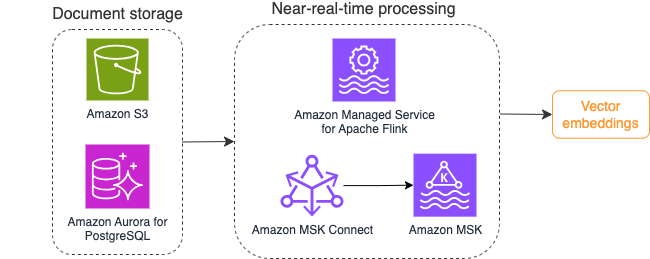
ویکٹر ڈیٹا اسٹور پر لکھے جانے سے پہلے نالج بیس مواد کو ویکٹر ایمبیڈنگز میں تبدیل کرنے کی ضرورت ہے۔ ایمیزون بیڈرک or ایمیزون سیج میکر آپ کو اپنی پسند کے ماڈل تک رسائی حاصل کرنے اور اس تبدیلی کے لیے ایک پرائیویٹ اینڈ پوائنٹ کو سامنے لانے میں مدد کر سکتا ہے۔ مزید برآں، آپ ان اختتامی نقطوں کے ساتھ ضم کرنے کے لیے LangChain جیسی لائبریریوں کا استعمال کر سکتے ہیں۔ بیچ کے عمل کو بنانے سے آپ کو اپنے علم کی بنیاد کے مواد کو ویکٹر ڈیٹا میں تبدیل کرنے اور اسے ابتدائی طور پر ویکٹر ڈیٹا بیس میں اسٹور کرنے میں مدد مل سکتی ہے۔ تاہم، آپ کو اپنے ویکٹر ڈیٹا بیس کو اپنے نالج بیس مواد میں تبدیلیوں کے ساتھ ہم آہنگ کرنے کے لیے دستاویزات کو دوبارہ پروسیس کرنے کے لیے وقفہ پر انحصار کرنے کی ضرورت ہے۔ دستاویزات کی ایک بڑی تعداد کے ساتھ، یہ عمل غیر موثر ہو سکتا ہے. ان وقفوں کے درمیان، آپ کے جنریٹیو AI ایپلیکیشن کے صارفین کو پرانے مواد کے مطابق جواب موصول ہوں گے، یا غلط جواب موصول ہوں گے کیونکہ نیا مواد ابھی ویکٹرائز نہیں ہوا ہے۔
سٹریم پروسیسنگ ان چیلنجوں کے لیے ایک مثالی حل ہے۔ یہ ابتدائی طور پر موجودہ دستاویزات کے مطابق واقعات تیار کرتا ہے اور سورس سسٹم کی مزید نگرانی کرتا ہے اور جیسے ہی وہ ہوتا ہے دستاویز میں تبدیلی کا واقعہ بناتا ہے۔ یہ ایونٹس اسٹریمنگ اسٹوریج میں اسٹور کیے جاسکتے ہیں اور اسٹریمنگ جاب کے ذریعے پروسیس ہونے کا انتظار کریں۔ ایک سلسلہ بندی کا کام ان واقعات کو پڑھتا ہے، دستاویز کے مواد کو لوڈ کرتا ہے، اور مواد کو الفاظ کے متعلقہ ٹوکنز کی صف میں تبدیل کرتا ہے۔ ہر ٹوکن مزید ویکٹر ڈیٹا میں ایک API کال کے ذریعے ایمبیڈنگ FM میں تبدیل ہو جاتا ہے۔ سٹوریج کے لیے نتائج ویکٹر اسٹوریج کو سنک آپریٹر کے ذریعے بھیجے جاتے ہیں۔
اگر آپ اپنی دستاویزات کو ذخیرہ کرنے کے لیے Amazon S3 استعمال کر رہے ہیں، تو آپ Lambda کے لیے S3 آبجیکٹ کی تبدیلی کے محرکات پر مبنی ایک ایونٹ سورس آرکیٹیکچر بنا سکتے ہیں۔ لیمبڈا فنکشن مطلوبہ فارمیٹ میں ایونٹ بنا سکتا ہے اور اسے آپ کے اسٹریمنگ اسٹوریج میں لکھ سکتا ہے۔
آپ اسٹریمنگ جاب کے طور پر چلانے کے لیے اپاچی فلنک کا استعمال بھی کر سکتے ہیں۔ Apache Flink مقامی فائل سسٹم سورس کنیکٹر فراہم کرتا ہے، جو موجودہ فائلوں کو دریافت کرسکتا ہے اور ان کے مواد کو ابتدائی طور پر پڑھ سکتا ہے۔ اس کے بعد، یہ نئی فائلوں کے لیے آپ کے فائل سسٹم کی مسلسل نگرانی کر سکتا ہے اور ان کے مواد کو پکڑ سکتا ہے۔ کنیکٹر تقسیم شدہ فائل سسٹمز جیسے Amazon S3 یا HDFS سے سادہ متن، Avro، CSV، Parquet، اور مزید کے فارمیٹ کے ساتھ فائلوں کے ایک سیٹ کو پڑھنے کی حمایت کرتا ہے، اور ایک سٹریمنگ ریکارڈ تیار کرتا ہے۔ ایک مکمل طور پر منظم سروس کے طور پر، Apache Flink کے لیے Managed Service Flink جابز کی تعیناتی اور برقرار رکھنے کے آپریشنل اوور ہیڈ کو ہٹا دیتی ہے، جس سے آپ اپنی اسٹریمنگ ایپلی کیشنز کی تعمیر اور اسکیلنگ پر توجہ مرکوز کر سکتے ہیں۔ AWS سٹریمنگ سروسز جیسے Amazon MSK یا Kinesis Data Streams میں ہموار انضمام کے ساتھ، یہ خودکار اسکیلنگ، سیکورٹی، اور لچک جیسی خصوصیات فراہم کرتا ہے، ریئل ٹائم اسٹریمنگ ڈیٹا کو ہینڈل کرنے کے لیے قابل اعتماد اور موثر Flink ایپلی کیشنز فراہم کرتا ہے۔
اپنی DevOps ترجیح کی بنیاد پر، آپ سٹریمنگ ریکارڈز کو ذخیرہ کرنے کے لیے Kinesis Data Streams یا Amazon MSK کے درمیان انتخاب کر سکتے ہیں۔ Kinesis Data Streams اپنی مرضی کے مطابق اسٹریمنگ ڈیٹا ایپلی کیشنز کو بنانے اور ان کا نظم کرنے کی پیچیدگیوں کو آسان بناتا ہے، جس سے آپ انفراسٹرکچر کی دیکھ بھال کے بجائے اپنے ڈیٹا سے بصیرت حاصل کرنے پر توجہ مرکوز کر سکتے ہیں۔ Apache Kafka استعمال کرنے والے صارفین اکثر Amazon MSK کا انتخاب کرتے ہیں کیونکہ وہ AWS ماحول میں اپاچی کافکا کلسٹرز کی نگرانی میں اس کی سیدھی سادی، اسکیل ایبلٹی، اور انحصار کی وجہ سے ہوتے ہیں۔ ایک مکمل طور پر منظم سروس کے طور پر، Amazon MSK اپاچی کافکا کلسٹرز کی تعیناتی اور دیکھ بھال سے منسلک آپریشنل پیچیدگیوں کو سنبھالتا ہے، جس سے آپ اپنی اسٹریمنگ ایپلی کیشنز کی تعمیر اور توسیع پر توجہ مرکوز کر سکتے ہیں۔
چونکہ ایک RESTful API انضمام اس عمل کی نوعیت کے مطابق ہے، آپ کو ایک ایسے فریم ورک کی ضرورت ہے جو RESTful API کالز کے ذریعے ناکامیوں کا سراغ لگانے اور ناکام درخواست کے لیے دوبارہ کوشش کرنے کے لیے ریاستی افزودگی کے پیٹرن کو سپورٹ کرے۔ اپاچی فلنک دوبارہ ایک ایسا فریم ورک ہے جو یادداشت کی رفتار میں اسٹیٹفول آپریشن کرسکتا ہے۔ Apache Flink کے ذریعے API کال کرنے کے بہترین طریقوں کو سمجھنے کے لیے، ملاحظہ کریں۔ Apache Flink کے لیے Amazon Kinesis Data Analytics میں سٹریمنگ ڈیٹا کی افزودگی کے عمومی نمونے۔.
اپاچی فلنک ویکٹر ڈیٹا اسٹورز کو ڈیٹا لکھنے کے لیے مقامی سنک کنیکٹر فراہم کرتا ہے جیسے کہ Amazon Aurora for PostgreSQL کے ساتھ pgvector یا ایمیزون اوپن سرچ سروس ویکٹر ڈی بی کے ساتھ۔ متبادل طور پر، آپ Flink جاب کے آؤٹ پٹ (ویکٹرائزڈ ڈیٹا) کو MSK کے موضوع یا Kinesis ڈیٹا اسٹریم میں اسٹیج کر سکتے ہیں۔ OpenSearch سروس Kinesis ڈیٹا اسٹریمز یا MSK کے موضوعات سے مقامی ادخال کے لیے معاونت فراہم کرتی ہے۔ مزید معلومات کے لیے رجوع کریں۔ Amazon MSK کو Amazon OpenSearch Ingestion کے ذریعہ کے طور پر متعارف کرایا جا رہا ہے۔ اور Amazon Kinesis ڈیٹا اسٹریمز سے سٹریمنگ ڈیٹا لوڈ ہو رہا ہے۔.
فیڈ بیک اینالیٹکس اور فائن ٹیوننگ
ڈیٹا آپریشن مینیجرز اور AI/ML ڈویلپرز کے لیے جنریٹو AI ایپلی کیشن اور استعمال میں FMs کی کارکردگی کے بارے میں بصیرت حاصل کرنا ضروری ہے۔ اسے حاصل کرنے کے لیے، آپ کو ڈیٹا پائپ لائنز بنانے کی ضرورت ہے جو صارف کے تاثرات اور ایپلیکیشن لاگ اور میٹرکس کی مختلف قسم کی بنیاد پر اہم کلیدی کارکردگی اشارے (KPI) ڈیٹا کا حساب لگاتی ہے۔ یہ معلومات اسٹیک ہولڈرز کے لیے مفید ہے کہ وہ FM کی کارکردگی، ایپلیکیشن، اور آپ کی درخواست سے موصول ہونے والی سپورٹ کے معیار کے بارے میں صارف کے مجموعی اطمینان کے بارے میں حقیقی وقت میں بصیرت حاصل کریں۔ آپ کو اپنے FMs کو مزید بہتر بنانے کے لیے گفتگو کی سرگزشت کو جمع اور ذخیرہ کرنے کی بھی ضرورت ہے تاکہ ڈومین کے مخصوص کاموں کو انجام دینے میں ان کی صلاحیت کو بہتر بنایا جا سکے۔
یہ استعمال کیس اسٹریمنگ اینالیٹکس ڈومین میں بہت اچھی طرح فٹ بیٹھتا ہے۔ آپ کی ایپلیکیشن کو ہر گفتگو کو اسٹریمنگ اسٹوریج میں اسٹور کرنا چاہیے۔ آپ کی درخواست صارفین کو ہر جواب کی درستگی اور ان کے مجموعی اطمینان کے بارے میں ان کی درجہ بندی کا اشارہ دے سکتی ہے۔ یہ ڈیٹا بائنری انتخاب یا مفت فارم ٹیکسٹ کی شکل میں ہو سکتا ہے۔ اس ڈیٹا کو Kinesis ڈیٹا سٹریم یا MSK موضوع میں ذخیرہ کیا جا سکتا ہے، اور حقیقی وقت میں KPIs بنانے کے لیے کارروائی کی جا سکتی ہے۔ آپ FMs کو صارفین کے جذبات کے تجزیہ کے لیے کام کر سکتے ہیں۔ FMs ہر جواب کا تجزیہ کر سکتے ہیں اور صارف کے اطمینان کا ایک زمرہ تفویض کر سکتے ہیں۔
اپاچی فلنک کا فن تعمیر وقت کی کھڑکیوں پر پیچیدہ ڈیٹا اکٹھا کرنے کی اجازت دیتا ہے۔ یہ ڈیٹا ایونٹس کے سلسلے میں SQL استفسار کے لیے بھی معاونت فراہم کرتا ہے۔ لہذا، اپاچی فلنک کا استعمال کرتے ہوئے، آپ فوری طور پر خام صارف کے ان پٹ کا تجزیہ کر سکتے ہیں اور واقف SQL سوالات لکھ کر حقیقی وقت میں KPIs تیار کر سکتے ہیں۔ مزید معلومات کے لیے رجوع کریں۔ ٹیبل API اور SQL.
ساتھ اپاچی فلنک اسٹوڈیو کے لیے ایمیزون کے زیر انتظام سروس، آپ ایک انٹرایکٹو نوٹ بک میں معیاری SQL، Python، اور Scala کا استعمال کرتے ہوئے Apache Flink سٹریم پروسیسنگ ایپلی کیشنز بنا اور چلا سکتے ہیں۔ اسٹوڈیو نوٹ بکس Apache Zeppelin سے چلتی ہیں اور Apache Flink کو اسٹریم پروسیسنگ انجن کے طور پر استعمال کرتی ہیں۔ سٹوڈیو نوٹ بک بغیر کسی رکاوٹ کے ان ٹیکنالوجیز کو یکجا کرتی ہیں تاکہ ڈیٹا اسٹریمز پر جدید تجزیات کو تمام مہارت کے سیٹ کے ڈویلپرز کے لیے قابل رسائی بنایا جا سکے۔ یوزر ڈیفائنڈ فنکشنز (UDFs) کے لیے تعاون کے ساتھ، Apache Flink اپنی مرضی کے مطابق آپریٹرز کی تعمیر کی اجازت دیتا ہے تاکہ وہ جذباتی تجزیہ جیسے پیچیدہ کاموں کو انجام دینے کے لیے بیرونی وسائل جیسے FMs کے ساتھ مل سکے۔ آپ UDFs کا استعمال مختلف میٹرکس کی گنتی کے لیے کر سکتے ہیں یا صارف کے تاثرات کے خام ڈیٹا کو اضافی بصیرت کے ساتھ بڑھا سکتے ہیں جیسے صارف کے جذبات۔ اس پیٹرن کے بارے میں مزید جاننے کے لیے، رجوع کریں۔ GenAI، Flink، Apache Kafka، اور Kinesis کے ساتھ حقیقی وقت میں صارفین کی تشویش کو فعال طور پر حل کرنا.
Apache Flink Studio کے لیے منظم سروس کے ساتھ، آپ ایک کلک کے ساتھ اپنی اسٹوڈیو نوٹ بک کو اسٹریمنگ جاب کے طور پر تعینات کر سکتے ہیں۔ آپ اپاچی فلنک کے ذریعہ فراہم کردہ مقامی سنک کنیکٹر استعمال کر سکتے ہیں تاکہ آؤٹ پٹ کو اپنی پسند کے سٹوریج میں بھیج سکیں یا اسے Kinesis ڈیٹا سٹریم یا MSK موضوع میں ترتیب دیں۔ ایمیزون ریڈ شفٹ اور OpenSearch سروس دونوں تجزیاتی ڈیٹا کو ذخیرہ کرنے کے لیے مثالی ہیں۔ دونوں انجن تجزیہ کے لیے ڈیٹا لیک یا ڈیٹا گودام کو علیحدہ اسٹریمنگ پائپ لائن کے ذریعے Kinesis Data Streams اور Amazon MSK سے مقامی ادخال سپورٹ فراہم کرتے ہیں۔
Amazon Redshift ایس کیو ایل کا استعمال ڈیٹا گوداموں اور ڈیٹا لیکس میں ڈھانچے والے اور نیم ساختہ ڈیٹا کا تجزیہ کرنے کے لیے کرتا ہے، AWS ڈیزائن کردہ ہارڈ ویئر اور مشین لرننگ کا استعمال کرتے ہوئے پیمانے پر بہترین قیمت کی کارکردگی فراہم کرتا ہے۔ OpenSearch سروس OpenSearch Dashboards اور Kibana (1.5 سے 7.10 ورژنز) کے ذریعے تقویت یافتہ تصوراتی صلاحیتیں پیش کرتی ہے۔
ضرورت پڑنے پر آپ FM کو ٹھیک کرنے کے لیے صارف کے پرامپٹ ڈیٹا کے ساتھ مل کر اس طرح کے تجزیہ کے نتائج کا استعمال کر سکتے ہیں۔ سیج میکر آپ کے ایف ایم کو ٹھیک کرنے کا سب سے سیدھا طریقہ ہے۔ SageMaker کے ساتھ Amazon S3 کا استعمال آپ کے ماڈلز کو ٹھیک کرنے کے لیے ایک طاقتور اور ہموار انضمام فراہم کرتا ہے۔ Amazon S3 ایک قابل توسیع اور پائیدار آبجیکٹ سٹوریج حل کے طور پر کام کرتا ہے، جو سیدھا سادہ اسٹوریج اور بڑے ڈیٹا سیٹس، تربیتی ڈیٹا، اور ماڈل آرٹفیکٹس کی بازیافت کو قابل بناتا ہے۔ سیج میکر ایک مکمل طور پر منظم ایم ایل سروس ہے جو پورے ایم ایل لائف سائیکل کو آسان بناتی ہے۔ Amazon S3 کو SageMaker کے لیے اسٹوریج بیک اینڈ کے طور پر استعمال کر کے، آپ Amazon S3 کی توسیع پذیری، وشوسنییتا، اور لاگت کی تاثیر سے فائدہ اٹھا سکتے ہیں، جبکہ اسے SageMaker کی تربیت اور تعیناتی کی صلاحیتوں کے ساتھ بغیر کسی رکاوٹ کے ضم کر سکتے ہیں۔ یہ مجموعہ موثر ڈیٹا مینجمنٹ کو قابل بناتا ہے، باہمی تعاون کے ساتھ ماڈل کی ترقی میں سہولت فراہم کرتا ہے، اور اس بات کو یقینی بناتا ہے کہ ML ورک فلو ہموار اور توسیع پذیر ہیں، بالآخر ML عمل کی مجموعی چستی اور کارکردگی کو بڑھاتا ہے۔ مزید معلومات کے لیے رجوع کریں۔ @ریموٹ ڈیکوریٹر کے ساتھ Amazon SageMaker پر Falcon 7B اور دیگر LLMs.
فائل سسٹم سنک کنیکٹر کے ساتھ، Apache Flink جابز ایمیزون S3 کو اوپن فارمیٹ (جیسے JSON، Avro، Parquet، اور مزید) فائلوں کو ڈیٹا آبجیکٹ کے طور پر ڈیلیور کر سکتی ہیں۔ اگر آپ ٹرانزیکشنل ڈیٹا لیک فریم ورک (جیسے Apache Hudi، Apache Iceberg، یا Delta Lake) کا استعمال کرتے ہوئے اپنی ڈیٹا لیک کو منظم کرنے کو ترجیح دیتے ہیں، تو یہ تمام فریم ورک Apache Flink کے لیے ایک حسب ضرورت کنیکٹر فراہم کرتے ہیں۔ مزید تفصیلات کے لیے رجوع کریں۔ Amazon MSK Connect، Apache Flink، اور Apache Hudi کا استعمال کرتے ہوئے کم لیٹینسی سورس ٹو ڈیٹا لیک پائپ لائن بنائیں.
خلاصہ
RAG ماڈل پر مبنی ایک جنریٹو AI ایپلیکیشن کے لیے، آپ کو دو ڈیٹا اسٹوریج سسٹم بنانے پر غور کرنے کی ضرورت ہے، اور آپ کو ڈیٹا آپریشنز بنانے کی ضرورت ہے جو انہیں تمام سورس سسٹم کے ساتھ اپ ٹو ڈیٹ رکھیں۔ روایتی بیچ کی ملازمتیں ڈیٹا کے سائز اور تنوع پر کارروائی کرنے کے لیے کافی نہیں ہیں جس کی آپ کو اپنی تخلیقی AI ایپلیکیشن کے ساتھ ضم کرنے کی ضرورت ہے۔ سورس سسٹم میں ہونے والی تبدیلیوں پر کارروائی کرنے میں تاخیر کے نتیجے میں غلط جواب ہوتا ہے اور آپ کی تخلیقی AI ایپلی کیشن کی کارکردگی کم ہوتی ہے۔ ڈیٹا سٹریمنگ آپ کو مختلف سسٹمز میں مختلف ڈیٹا بیسز سے ڈیٹا داخل کرنے کے قابل بناتی ہے۔ یہ آپ کو بہت سارے ذرائع میں مؤثر طریقے سے قریب حقیقی وقت میں ڈیٹا کو تبدیل کرنے، افزودہ کرنے، شامل کرنے اور جمع کرنے کی بھی اجازت دیتا ہے۔ ڈیٹا اسٹریمنگ صارفین کے ریئل ٹائم ری ایکشنز یا ایپلیکیشن کے جوابات پر تبصرے جمع کرنے اور تبدیل کرنے کے لیے ایک آسان ڈیٹا فن تعمیر فراہم کرتی ہے، جس سے آپ کو ماڈل فائن ٹیوننگ کے لیے ڈیٹا لیک میں نتائج فراہم کرنے اور اسٹور کرنے میں مدد ملتی ہے۔ ڈیٹا اسٹریمنگ آپ کو صرف تبدیلی کے واقعات پر کارروائی کرکے ڈیٹا پائپ لائنوں کو بہتر بنانے میں بھی مدد دیتی ہے، جس سے آپ ڈیٹا کی تبدیلیوں کا زیادہ تیزی اور مؤثر طریقے سے جواب دے سکتے ہیں۔
کے بارے میں مزید معلومات حاصل کریں AWS ڈیٹا اسٹریمنگ سروسز اور اپنا ڈیٹا اسٹریمنگ حل بنانا شروع کریں۔
مصنفین کے بارے میں
 علی علمی۔ AWS میں اسٹریمنگ اسپیشلسٹ سولیوشن آرکیٹیکٹ ہے۔ علی آرکیٹیکچرل بہترین طریقوں کے ساتھ AWS کے صارفین کو مشورہ دیتا ہے اور انہیں حقیقی وقت کے تجزیاتی ڈیٹا سسٹمز ڈیزائن کرنے میں مدد کرتا ہے جو قابل بھروسہ، محفوظ، موثر، اور کم لاگت ہیں۔ وہ گاہک کے استعمال کے معاملات سے پیچھے ہٹ کر کام کرتا ہے اور ان کے کاروباری مسائل کو حل کرنے کے لیے ڈیٹا سلوشن ڈیزائن کرتا ہے۔ AWS میں شامل ہونے سے پہلے، علی نے پبلک سیکٹر کے متعدد صارفین اور AWS مشاورتی شراکت داروں کو ان کے ایپلیکیشن کی جدید کاری کے سفر اور کلاؤڈ میں منتقلی میں تعاون کیا۔
علی علمی۔ AWS میں اسٹریمنگ اسپیشلسٹ سولیوشن آرکیٹیکٹ ہے۔ علی آرکیٹیکچرل بہترین طریقوں کے ساتھ AWS کے صارفین کو مشورہ دیتا ہے اور انہیں حقیقی وقت کے تجزیاتی ڈیٹا سسٹمز ڈیزائن کرنے میں مدد کرتا ہے جو قابل بھروسہ، محفوظ، موثر، اور کم لاگت ہیں۔ وہ گاہک کے استعمال کے معاملات سے پیچھے ہٹ کر کام کرتا ہے اور ان کے کاروباری مسائل کو حل کرنے کے لیے ڈیٹا سلوشن ڈیزائن کرتا ہے۔ AWS میں شامل ہونے سے پہلے، علی نے پبلک سیکٹر کے متعدد صارفین اور AWS مشاورتی شراکت داروں کو ان کے ایپلیکیشن کی جدید کاری کے سفر اور کلاؤڈ میں منتقلی میں تعاون کیا۔
 امتیاز (تاز) سید AWS میں تجزیات کے لیے ورلڈ وائڈ ٹیک لیڈر ہے۔ وہ تمام چیزوں کے ڈیٹا اور تجزیات پر کمیونٹی کے ساتھ مشغول ہونے میں لطف اندوز ہوتا ہے۔ اس کے ذریعے پہنچا جا سکتا ہے۔ لنکڈ.
امتیاز (تاز) سید AWS میں تجزیات کے لیے ورلڈ وائڈ ٹیک لیڈر ہے۔ وہ تمام چیزوں کے ڈیٹا اور تجزیات پر کمیونٹی کے ساتھ مشغول ہونے میں لطف اندوز ہوتا ہے۔ اس کے ذریعے پہنچا جا سکتا ہے۔ لنکڈ.
- SEO سے چلنے والا مواد اور PR کی تقسیم۔ آج ہی بڑھا دیں۔
- پلیٹو ڈیٹا ڈاٹ نیٹ ورک ورٹیکل جنریٹو اے آئی۔ اپنے آپ کو بااختیار بنائیں۔ یہاں تک رسائی حاصل کریں۔
- پلیٹوآئ اسٹریم۔ ویب 3 انٹیلی جنس۔ علم میں اضافہ۔ یہاں تک رسائی حاصل کریں۔
- پلیٹو ای ایس جی۔ کاربن، کلین ٹیک، توانائی ، ماحولیات، شمسی، ویسٹ مینجمنٹ یہاں تک رسائی حاصل کریں۔
- پلیٹو ہیلتھ۔ بائیوٹیک اینڈ کلینیکل ٹرائلز انٹیلی جنس۔ یہاں تک رسائی حاصل کریں۔
- ماخذ: https://aws.amazon.com/blogs/big-data/exploring-real-time-streaming-for-generative-ai-applications/

