Великі мовні моделі (LLM) зазвичай навчаються на великих загальнодоступних наборах даних, які не залежать від домену. Наприклад, Лама Мета моделі навчаються на таких наборах даних, як CommonCrawl, C4, Вікіпедія та ArXiv. Ці набори даних охоплюють широкий спектр тем і областей. Незважаючи на те, що отримані моделі дають неймовірно хороші результати для загальних завдань, таких як генерація тексту та розпізнавання об’єктів, є докази того, що моделі, навчені з доменно-специфічними наборами даних, можуть ще більше підвищити продуктивність LLM. Наприклад, навчальні дані, які використовуються для BloombergGPT це 51% доменних документів, включаючи фінансові новини, документи та інші фінансові матеріали. Отриманий LLM перевершує LLM, навчених на неспецифічних наборах даних під час тестування на фінансові завдання. Автори BloombergGPT прийшли до висновку, що їхня модель перевершує всі інші перевірені моделі для чотирьох із п’яти фінансових завдань. Модель забезпечила ще кращу продуктивність під час тестування для внутрішніх фінансових завдань Bloomberg із великим відривом — аж на 60 балів краще (зі 100). Хоча ви можете дізнатися більше про комплексні результати оцінювання в папір, наступний зразок, взятий із BloombergGPT стаття може дати вам уявлення про переваги навчання LLM за допомогою даних, що стосуються фінансової сфери. Як показано в прикладі, модель BloombergGPT надала правильні відповіді, тоді як інші моделі, не пов’язані з доменом, мали проблеми:
Ця публікація містить посібник із підготовки магістрів права спеціально для фінансової сфери. Ми охоплюємо наступні ключові сфери:
- Збір і підготовка даних – Рекомендації щодо пошуку та обробки відповідних фінансових даних для ефективного навчання моделей
- Постійне попереднє навчання проти тонкого налаштування – Коли використовувати кожну техніку для оптимізації продуктивності вашого LLM
- Ефективна постійна попередня підготовка – Стратегії оптимізації безперервного процесу попереднього навчання, заощаджуючи час і ресурси
Ця публікація об’єднує досвід групи прикладних наукових досліджень Amazon Finance Technology і команди спеціалістів AWS Worldwide для глобальної фінансової індустрії. Частина вмісту базується на папері Ефективне безперервне попереднє навчання для побудови предметно-спеціальних моделей великих мов.
Збір і підготовка фінансових даних
Постійне попереднє навчання потребує широкомасштабного, високоякісного набору даних для конкретної області. Нижче наведено основні кроки для контролю набору даних домену.
- Визначте джерела даних – Потенційні джерела даних для корпусу домену включають відкритий Інтернет, Вікіпедію, книги, соціальні мережі та внутрішні документи.
- Фільтри доменних даних – Оскільки кінцевою метою є контроль корпусу домену, вам може знадобитися застосувати додаткові кроки, щоб відфільтрувати зразки, які не стосуються цільового домену. Це зменшує непотрібний корпус для постійного попереднього навчання та зменшує витрати на навчання.
- Попередня обробка – Ви можете розглянути серію етапів попередньої обробки, щоб покращити якість даних і ефективність навчання. Наприклад, певні джерела даних можуть містити достатню кількість галасливих токенів; дедуплікація вважається корисним кроком для покращення якості даних і зниження вартості навчання.
Для розробки фінансових LLM ви можете використовувати два важливі джерела даних: News CommonCrawl і файли SEC. Заявка SEC – це фінансовий звіт або інший офіційний документ, поданий до Комісії з цінних паперів і бірж США (SEC). Компанії, зареєстровані на біржі, зобов’язані регулярно подавати різні документи. Це створює велику кількість документів протягом багатьох років. Новини CommonCrawl — це набір даних, випущений CommonCrawl у 2016 році. Він містить новинні статті з новинних сайтів у всьому світі.
Новини CommonCrawl доступні на Служба простого зберігання Amazon (Amazon S3) у commoncrawl відро при crawl-data/CC-NEWS/. Ви можете отримати списки файлів за допомогою Інтерфейс командного рядка AWS (AWS CLI) і таку команду:
In Ефективне безперервне попереднє навчання для побудови предметно-спеціальних моделей великих мов, автори використовують підхід на основі URL-адреси та ключових слів для фільтрації статей фінансових новин від загальних новин. Зокрема, автори ведуть список важливих фінансових новин і набір ключових слів, пов’язаних із фінансовими новинами. Ми визначаємо статтю як фінансову, якщо вона походить від фінансових новин або будь-які ключові слова з’являються в URL-адресі. Цей простий, але ефективний підхід дає змогу визначати фінансові новини не лише з фінансових інформаційних агенцій, але й із фінансових розділів загальних інформаційних агенцій.
Заявки SEC доступні онлайн через базу даних SEC EDGAR (електронний збір, аналіз і пошук), яка забезпечує відкритий доступ до даних. Ви можете отримати файли безпосередньо з EDGAR або скористатися API Amazon SageMaker з кількома рядками коду, для будь-якого періоду часу та для великої кількості тикерів (тобто ідентифікатор, призначений SEC). Щоб дізнатися більше, зверніться до Пошук файлів SEC.
У наведеній нижче таблиці підсумовано ключові деталі обох джерел даних.
| . | Новини CommonCrawl | Подання SEC |
| покриття | 2016-2022 | 1993-2022 |
| Розмір | 25.8 мільярдів слів | 5.1 мільярдів слів |
Автори проходять кілька додаткових етапів попередньої обробки, перш ніж дані будуть подані в навчальний алгоритм. По-перше, ми спостерігаємо, що документи SEC містять шумний текст через видалення таблиць і малюнків, тому автори видаляють короткі речення, які вважаються мітками таблиць або малюнків. По-друге, ми застосовуємо алгоритм хешування, чутливий до місцевості, щоб видалити дублікати нових статей і файлів. Для файлів SEC ми видаляємо дублікати на рівні розділу, а не на рівні документа. Нарешті, ми об’єднуємо документи в довгий рядок, токенізуємо його та розбиваємо токенізацію на фрагменти максимальної вхідної довжини, що підтримується моделлю, яку потрібно навчити. Це покращує пропускну здатність постійного попереднього навчання та зменшує вартість навчання.
Постійне попереднє навчання проти тонкого налаштування
Більшість доступних LLM є загальним призначенням і не мають специфічних для домену можливостей. Домен LLM продемонстрував значну ефективність у медичних, фінансових або наукових областях. Щоб LLM набув предметних знань, існує чотири методи: навчання з нуля, безперервне попереднє навчання, точне налаштування інструкцій щодо завдань предметної області та доповнена генерація пошуку (RAG).
У традиційних моделях тонке налаштування зазвичай використовується для створення моделей для конкретного завдання для домену. Це означає підтримку кількох моделей для кількох завдань, таких як вилучення сутностей, класифікація намірів, аналіз настроїв або відповіді на запитання. З появою LLM потреба підтримувати окремі моделі застаріла через використання таких методів, як навчання в контексті або підказки. Це економить зусилля, необхідні для підтримки стека моделей для пов’язаних, але різних завдань.
Інтуїтивно зрозуміло, що ви можете навчати LLM з нуля, використовуючи дані для конкретної області. Хоча більша частина роботи зі створення доменних LLM зосереджена на навчанні з нуля, це надзвичайно дорого. Наприклад, коштує модель ГПТ-4 більше $ 100 мільйонів тренуватися. Ці моделі навчаються на поєднанні відкритих доменних даних і доменних даних. Постійне попереднє навчання може допомогти моделям отримати предметно-спеціальні знання без витрат на попереднє навчання з нуля, оскільки ви попередньо навчаєте існуючого LLM у відкритому домені лише на даних домену.
За допомогою точного налаштування інструкцій у завданні ви не можете змусити модель отримати знання предметної області, оскільки LLM отримує лише інформацію про домен, що міститься в наборі даних точного налаштування інструкцій. Якщо для тонкого налаштування інструкцій не використовується дуже великий набір даних, цього недостатньо для отримання знань про предметну область. Пошук високоякісних наборів даних інструкцій зазвичай є складним завданням, і це причина для використання LLMs в першу чергу. Крім того, точне налаштування інструкцій для одного завдання може вплинути на продуктивність інших завдань (як показано в цей папір). Однак точне налаштування інструкцій є більш економічно ефективним, ніж будь-який із варіантів попереднього навчання.
На наступному малюнку порівнюється традиційне тонке налаштування для конкретних завдань. проти парадигми навчання в контексті з LLM.
 RAG — це найефективніший спосіб скерувати LLM для створення відповідей, заснованих на домені. Незважаючи на те, що він може направляти модель для генерування відповідей, надаючи факти з домену як допоміжну інформацію, він не отримує предметно-специфічної мови, оскільки LLM все ще покладається на стиль не доменної мови для генерації відповідей.
RAG — це найефективніший спосіб скерувати LLM для створення відповідей, заснованих на домені. Незважаючи на те, що він може направляти модель для генерування відповідей, надаючи факти з домену як допоміжну інформацію, він не отримує предметно-специфічної мови, оскільки LLM все ще покладається на стиль не доменної мови для генерації відповідей.
Безперервна попередня підготовка є середньою ланкою між попередньою підготовкою та вдосконаленням інструкцій з точки зору вартості, водночас є сильною альтернативою отриманню предметних знань і стилю. Він може надати загальну модель, над якою можна виконати подальше тонке налаштування інструкцій на обмежених даних інструкцій. Постійне попереднє навчання може бути економічно ефективною стратегією для спеціалізованих областей, де набір подальших завдань є великим або невідомим, а дані налаштування інструкцій з мітками обмежені. В інших сценаріях більш підходящим може бути точне налаштування інструкцій або RAG.
Щоб дізнатися більше про точне налаштування, RAG і навчання моделі, див Тонке налаштування базової моделі, Доповнена генерація пошуку (RAG) та Навчайте модель за допомогою Amazon SageMaker, відповідно. Для цієї посади ми зосереджуємось на ефективній постійній попередній підготовці.
Методика ефективного постійного попереднього навчання
Постійне попереднє навчання складається з наступної методики:
- Адаптивне до домену безперервне попереднє навчання (DACP) – У газеті Ефективне безперервне попереднє навчання для побудови предметно-спеціальних моделей великих мов, автори постійно попередньо тренують набір мовних моделей Pythia на фінансовому корпусі, щоб адаптувати його до сфери фінансів. Мета полягає в тому, щоб створити фінансові LLM шляхом передачі даних з усієї фінансової області в модель з відкритим кодом. Оскільки навчальний корпус містить усі підібрані набори даних у домені, результуюча модель повинна отримувати знання про фінанси, таким чином стаючи універсальною моделлю для різних фінансових завдань. Це призводить до моделей FinPythia.
- Безперервне попереднє навчання, адаптоване до завдання (TACP) – Автори попередньо навчають моделі на позначених і не позначених даних завдань, щоб адаптувати їх для конкретних завдань. За певних обставин розробники можуть віддати перевагу моделям, які забезпечують кращу продуктивність для групи завдань у домені, а не загальній моделі домену. TACP розроблено як безперервне попереднє навчання, спрямоване на підвищення ефективності виконання цільових завдань без вимог до позначених даних. Зокрема, автори постійно попередньо тренують моделі з відкритим кодом на маркерах завдань (без міток). Основне обмеження TACP полягає в побудові LLM для конкретного завдання замість базових LLM через використання лише немаркованих даних завдань для навчання. Хоча DACP використовує набагато більший корпус, він непомірно дорогий. Щоб збалансувати ці обмеження, автори пропонують два підходи, спрямовані на створення предметно-спеціальних базових LLM, зберігаючи чудову продуктивність у цільових завданнях:
- Ефективний DACP, аналогічний завданням (ETS-DACP) – Автори пропонують вибрати підмножину фінансового корпусу, яка дуже схожа на дані завдання, використовуючи подібність вбудовування. Цей піднабір використовується для постійного попереднього навчання, щоб зробити його ефективнішим. Зокрема, автори постійно проводять попереднє навчання LLM з відкритим вихідним кодом на невеликому корпусі, отриманому з фінансового корпусу, який близький до цільових завдань у розповсюдженні. Це може допомогти підвищити продуктивність завдань, оскільки ми приймаємо модель розподілу маркерів завдань, незважаючи на те, що позначені дані не потрібні.
- Ефективний DACP, що не залежить від завдань (ETA-DACP) – Автори пропонують використовувати такі показники, як здивування та ентропія типу маркерів, які не вимагають даних про завдання для вибору зразків із фінансового корпусу для ефективного постійного попереднього навчання. Цей підхід призначений для сценаріїв, коли дані про завдання недоступні або перевага віддається більш універсальним моделям домену для ширшого домену. Автори приймають два виміри для вибору зразків даних, які важливі для отримання інформації про домен із підмножини даних домену перед навчанням: новизна та різноманітність. Новизна, виміряна здивуванням, зафіксованим цільовою моделлю, відноситься до інформації, яка раніше не була доступна LLM. Дані з високою новизною вказують на нові знання для LLM, і такі дані вважаються складнішими для вивчення. Це оновлює загальні LLM інтенсивними знаннями предметної області під час постійного попереднього навчання. Різноманітність, з іншого боку, охоплює різноманітність розподілу типів лексем у корпусі предметної області, що було задокументовано як корисну функцію в дослідженні вивчення мовного моделювання за програмою.
На наступному малюнку порівнюється приклад ETS-DACP (ліворуч) і ETA-DACP (праворуч).

Ми застосовуємо дві схеми вибірки для активного відбору точок даних із підібраного фінансового корпусу: жорстку вибірку та м’яку вибірку. Перше виконується шляхом спочатку ранжування фінансового корпусу за відповідними показниками, а потім вибору перших k вибірок, де k попередньо визначено відповідно до бюджету навчання. Для останнього автори призначають ваги вибірки для кожної точки даних відповідно до значень метрики, а потім випадково відбирають k точок даних, щоб відповідати бюджету навчання.
Результат і аналіз
Автори оцінюють отримані фінансові LLM на низці фінансових завдань, щоб дослідити ефективність постійного попереднього навчання:
- Банк фінансової фрази – Завдання на класифікацію настроїв щодо фінансових новин.
- FiQA SA – Завдання класифікації настроїв за аспектами на основі фінансових новин і заголовків.
- Headline – Завдання двійкової класифікації щодо того, чи містить заголовок про фінансову установу певну інформацію.
- NER – Завдання вилучення фінансової іменованої організації на основі розділу оцінки кредитного ризику звітів SEC. Слова в цьому завданні позначені PER, LOC, ORG і MISC.
Оскільки фінансові LLM є детально налаштованими інструкціями, автори оцінюють моделі в 5-кратному режимі для кожного завдання заради надійності. У середньому FinPythia 6.9B перевершує Pythia 6.9B на 10% у чотирьох завданнях, що демонструє ефективність постійного попереднього навчання для конкретної області. Для моделі 1B покращення менш суттєве, але продуктивність все одно підвищується в середньому на 2%.
На наступному малюнку показано різницю в продуктивності до та після DACP на обох моделях.

На наступному малюнку показано два якісні приклади, згенеровані Pythia 6.9B і FinPythia 6.9B. Для двох питань, пов’язаних з фінансами, щодо менеджера інвестора та фінансового терміну, Pythia 6.9B не розуміє термін або не розпізнає назву, тоді як FinPythia 6.9B генерує детальні відповіді правильно. Якісні приклади демонструють, що безперервна попередня підготовка дозволяє магістрам здобувати знання предметної галузі під час процесу.

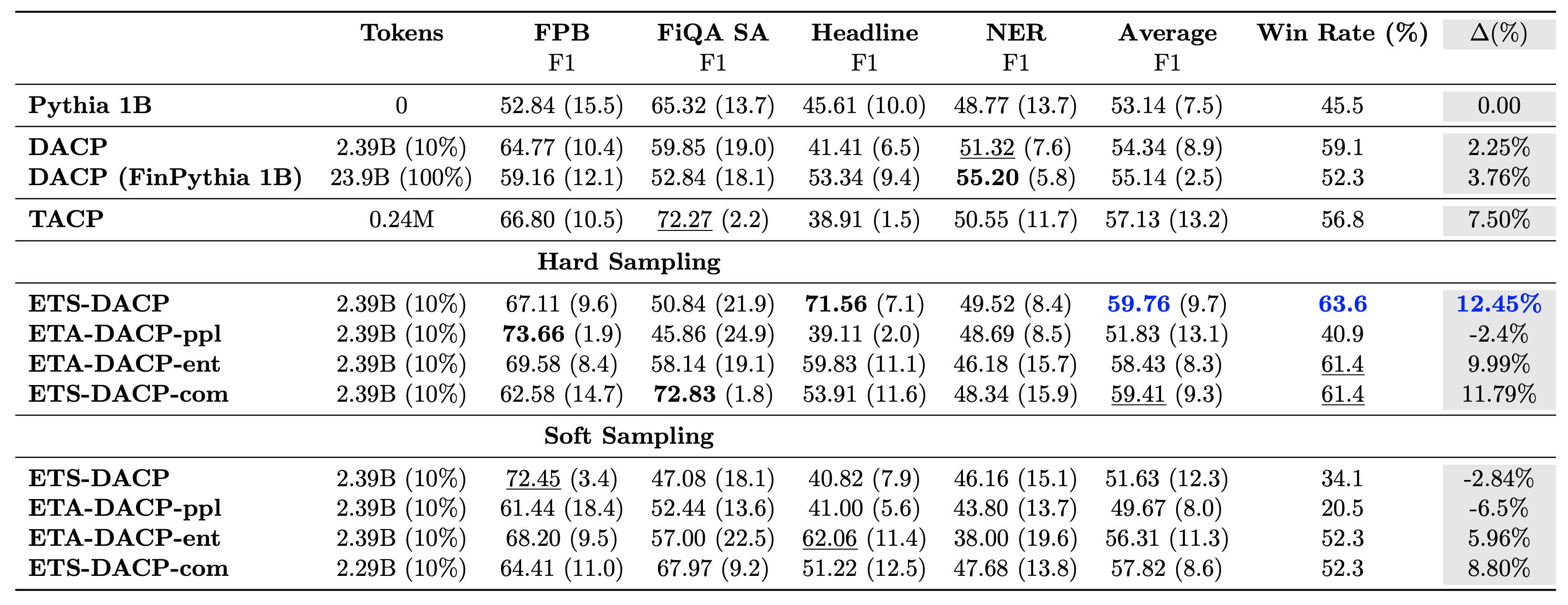
У наведеній нижче таблиці порівнюються різні ефективні підходи до постійного попереднього навчання. ETA-DACP-ppl — це ETA-DACP, заснований на здивуванні (новизна), а ETA-DACP-ent — на ентропії (різноманітність). ETS-DACP-com схожий на DACP з відбором даних шляхом усереднення всіх трьох показників. Нижче наведено кілька висновків із результатів:
- Методи відбору даних ефективні – Вони перевершують стандартне безперервне попереднє навчання лише з 10% тренувальних даних. Ефективне безперервне попереднє навчання, включаючи Task-Similar DACP (ETS-DACP), Task-Agnostic DACP на основі ентропії (ESA-DACP-ent) і Task-Similar DACP на основі всіх трьох показників (ETS-DACP-com), перевершує стандартний DACP в середньому, незважаючи на те, що вони навчаються лише на 10% фінансового корпусу.
- Вибір даних з урахуванням завдань найкраще працює в рамках дослідження малих мовних моделей – ETS-DACP фіксує найкращу середню продуктивність серед усіх методів і, виходячи з усіх трьох показників, фіксує другу найкращу продуктивність завдання. Це свідчить про те, що використання даних завдань без міток все ще є ефективним підходом для підвищення продуктивності завдань у випадку LLM.
- Друге місце займає вибір даних, що не залежить від завдань – ESA-DACP-ent слідує продуктивності підходу відбору даних з урахуванням завдань, маючи на увазі, що ми все ще можемо підвищити продуктивність завдань, активно відбираючи високоякісні зразки, не прив’язані до конкретних завдань. Це відкриває шлях для створення фінансових LLM для всього домену, одночасно досягаючи чудової продуктивності завдань.
Одним із критичних питань щодо постійного попереднього навчання є те, чи воно негативно впливає на продуктивність завдань, що не належать до домену. Автори також оцінюють модель, що постійно тренується, на чотирьох широко використовуваних загальних завданнях: ARC, MMLU, TruthQA та HellaSwag, які вимірюють здатність відповідати на запитання, міркувати та завершувати. Автори виявили, що безперервне попереднє навчання не впливає негативно на продуктивність поза доменом. Для отримання додаткової інформації див Ефективне безперервне попереднє навчання для побудови предметно-спеціальних моделей великих мов.
Висновок
Ця публікація пропонувала розуміння збору даних і стратегій постійного попереднього навчання для навчання магістрів права у фінансовій сфері. Ви можете розпочати навчання своїх власних LLM для фінансових завдань, використовуючи Навчання Amazon SageMaker or Amazon Bedrock сьогодні.
Про авторів
 Юн Се є прикладним науковцем у Amazon FinTech. Він зосереджується на розробці великих мовних моделей і програм Generative AI для фінансів.
Юн Се є прикладним науковцем у Amazon FinTech. Він зосереджується на розробці великих мовних моделей і програм Generative AI для фінансів.
 Каран Агарвал є старшим прикладним науковим співробітником Amazon FinTech і спеціалізується на генеративному штучному інтелекті для фінансових випадків. Каран має великий досвід аналізу часових рядів і НЛП, з особливим інтересом до навчання на обмежених позначених даних
Каран Агарвал є старшим прикладним науковим співробітником Amazon FinTech і спеціалізується на генеративному штучному інтелекті для фінансових випадків. Каран має великий досвід аналізу часових рядів і НЛП, з особливим інтересом до навчання на обмежених позначених даних
 Айцаз Ахмад є менеджером із прикладних наук в Amazon, де він очолює групу вчених, які розробляють різні програми машинного навчання та генеративного штучного інтелекту у фінансах. Його наукові інтереси стосуються НЛП, Generative AI та LLM Agents. Він отримав ступінь доктора філософії з електротехніки в Техаському університеті A&M.
Айцаз Ахмад є менеджером із прикладних наук в Amazon, де він очолює групу вчених, які розробляють різні програми машинного навчання та генеративного штучного інтелекту у фінансах. Його наукові інтереси стосуються НЛП, Generative AI та LLM Agents. Він отримав ступінь доктора філософії з електротехніки в Техаському університеті A&M.
 Цінвей Лі є спеціалістом з машинного навчання в Amazon Web Services. Отримав ступінь доктора філософії. в дослідженні операцій після того, як він зламав грантовий рахунок свого радника і не вручив обіцяну Нобелівську премію. Зараз він допомагає клієнтам у сфері фінансових послуг створювати рішення машинного навчання на AWS.
Цінвей Лі є спеціалістом з машинного навчання в Amazon Web Services. Отримав ступінь доктора філософії. в дослідженні операцій після того, як він зламав грантовий рахунок свого радника і не вручив обіцяну Нобелівську премію. Зараз він допомагає клієнтам у сфері фінансових послуг створювати рішення машинного навчання на AWS.
 Рагвендер Арні очолює групу підтримки клієнтів (CAT) в AWS Industries. CAT — це глобальна міжфункціональна команда хмарних архітекторів, розробників програмного забезпечення, спеціалістів із обробки даних, експертів і дизайнерів зі штучного інтелекту/ML, яка впроваджує інновації за допомогою вдосконаленого прототипування та сприяє досконалості хмарних операцій за допомогою спеціалізованих технічних знань.
Рагвендер Арні очолює групу підтримки клієнтів (CAT) в AWS Industries. CAT — це глобальна міжфункціональна команда хмарних архітекторів, розробників програмного забезпечення, спеціалістів із обробки даних, експертів і дизайнерів зі штучного інтелекту/ML, яка впроваджує інновації за допомогою вдосконаленого прототипування та сприяє досконалості хмарних операцій за допомогою спеціалізованих технічних знань.
- Розповсюдження контенту та PR на основі SEO. Отримайте посилення сьогодні.
- PlatoData.Network Vertical Generative Ai. Додайте собі сили. Доступ тут.
- PlatoAiStream. Web3 Intelligence. Розширення знань. Доступ тут.
- ПлатонЕСГ. вуглець, CleanTech, Енергія, Навколишнє середовище, Сонячна, Поводження з відходами. Доступ тут.
- PlatoHealth. Розвідка про біотехнології та клінічні випробування. Доступ тут.
- джерело: https://aws.amazon.com/blogs/machine-learning/efficient-continual-pre-training-llms-for-financial-domains/

