
"Bir ons önleme, bir kilo tedaviye bedeldir" diyen eski bir deyiş, bize bir şeyin olmasını ilk etapta durdurmanın, meydana gelen hasarı onarmaktan daha kolay olduğunu hatırlatır.
Yapay zeka (AI) çağında bu atasözü, düzenlileştirme gibi teknikler yoluyla aşırı uyum gibi potansiyel tuzaklardan kaçınmanın önemini vurguluyor.
Bu yazımızda, Sci-kit Learn(Makine Öğrenimi) ve Tensorflow(Derin Öğrenme) kullanarak uygulamasına temel ilkelerinden başlayarak düzenlileştirmeyi keşfedecek ve bu sonuçları karşılaştırarak gerçek dünya veri kümeleriyle dönüştürücü gücüne tanık olacağız. Hadi başlayalım!
Düzenlileştirme, makine öğrenimi ve derin öğrenmede modellerin gereğinden fazla takılmasını önlemeyi amaçlayan kritik bir kavramdır.
Aşırı uyum, bir model eğitim verilerini çok iyi öğrendiğinde meydana gelir. Durum, modelinizin gerçek olamayacak kadar iyi olduğunu gösteriyor.
Aşırı uyumun neye benzediğini görelim.
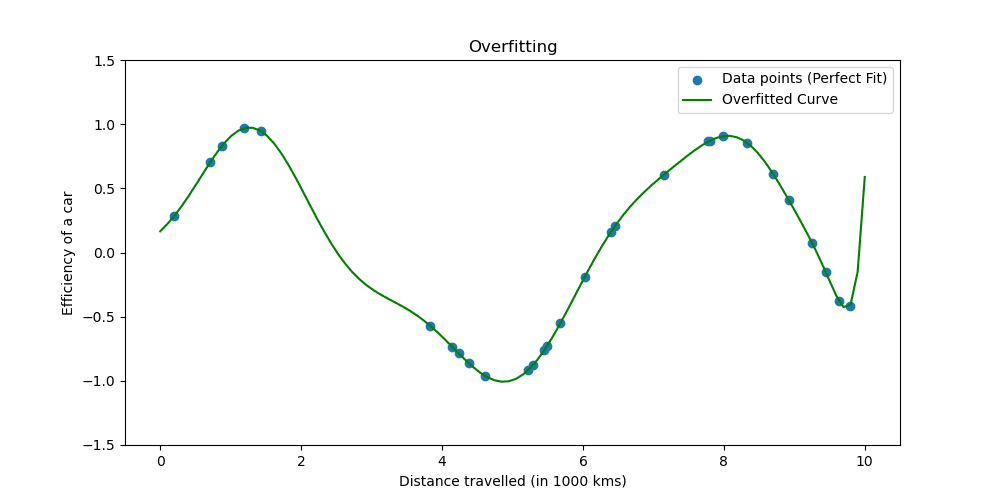
Düzenlileştirme teknikleri, modeli basitleştirecek şekilde öğrenme sürecini ayarlar, eğitim verileri üzerinde iyi performans göstermesini ve yeni verilere iyi bir şekilde genellenmesini sağlar. Bunu yapmanın iki iyi bilinen yolunu inceleyeceğiz.
Makine öğreniminde düzenlileştirme genellikle doğrusal ve lojistik regresyon gibi doğrusal modellere uygulanır. Bu bağlamda en yaygın düzenleme biçimleri şunlardır:
- L1 düzenlemesi (Kement regresyonu)
- L2 düzenlemesi (Ridge regresyonu)
Kement Düzenleme Bazı katsayı değerlerinin tam olarak sıfır olmasına izin vererek modeli yalnızca en temel özellikleri kullanmaya teşvik eder; bu, özellik seçimi için özellikle yararlı olabilir.


Öte yandan, Sırt düzenlemesi değerlerinin karesini cezalandırarak önemli katsayıları ortadan kaldırır.

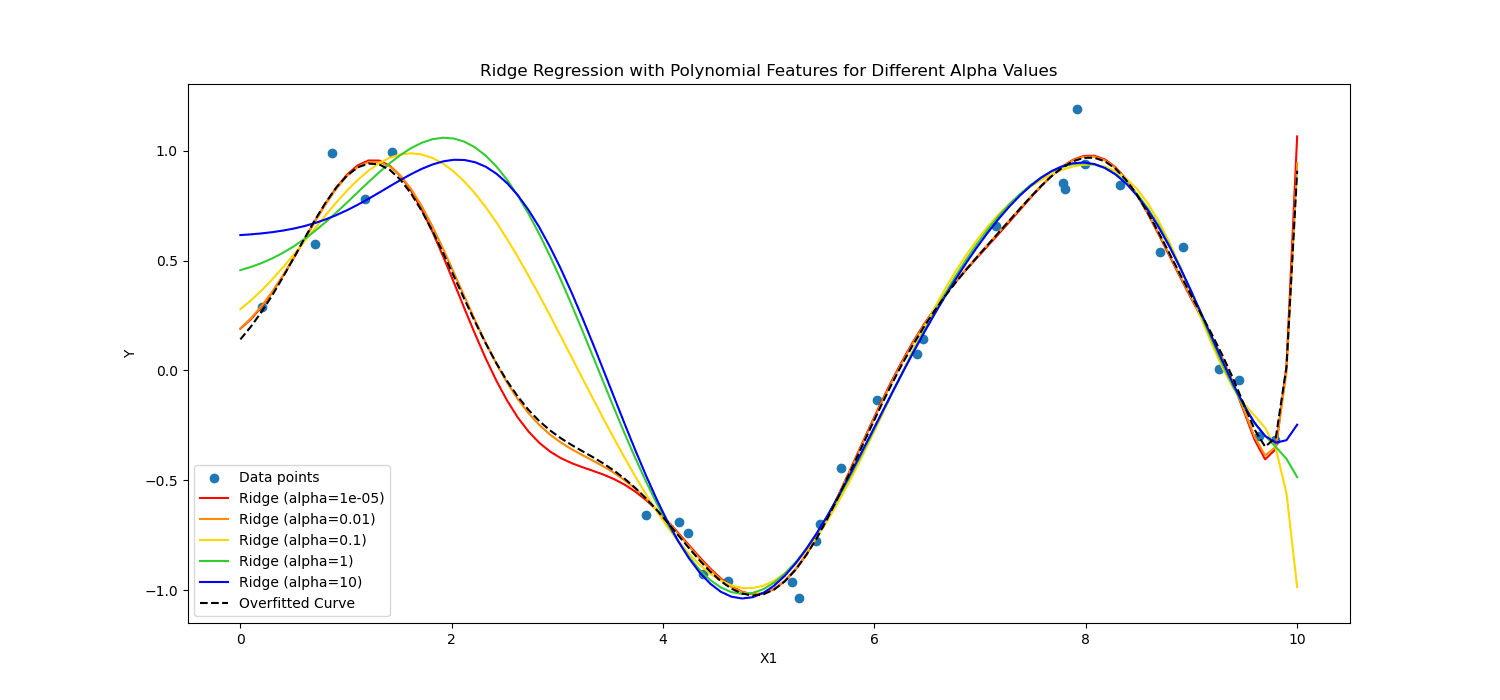
Kısacası farklı hesapladılar.
Derin öğrenme ve makine öğrenimindeki gücünü görmek için bunları kalp hastası verilerine uygulayalım.
Şimdi düzenlileştirmenin gücünü görmek amacıyla kalp hastası verilerini analiz etmek için düzenlemeyi uygulayacağız. Veri setine şuradan ulaşabilirsiniz: okuyun.
Makine öğrenimini uygulamak için Scikit-learn'i kullanacağız; Derin öğrenmeyi uygulamak için TensorFlow'u kullanacağız. Hadi başlayalım!
Makine Öğreniminde Düzenleme
Scikit-learn en popülerlerden biridir Python kitaplıkları basit ve etkili veri analizi ve modelleme araçları sağlayan makine öğrenimi için.
Özellikle doğrusal modeller için çeşitli düzenleme tekniklerinin uygulamalarını içerir.
Burada L1 (Kement) ve L2 (Ridge) düzenlemesinin nasıl uygulanacağını keşfedeceğiz.
Aşağıdaki kodda, Ridge(L2) ve Lasso düzenlileştirme (L1) tekniklerini kullanarak lojistik regresyonu eğiteceğiz. Sonunda ayrıntılı raporu göreceğiz. Kodu görelim.
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, classification_report
# Assuming heart_data is already loaded
X = heart_data.drop('target', axis=1)
y = heart_data['target']
# Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Standardize the features
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# Define regularization values to explore
regularization_values = [0.001, 0.01, 0.1]
# Placeholder for storing performance metrics
performance_metrics = []
# Iterate over regularization values for L1 and L2
for C_value in regularization_values:
# Train and evaluate L1 model
log_reg_l1 = LogisticRegression(penalty='l1', C=C_value, solver='liblinear')
log_reg_l1.fit(X_train_scaled, y_train)
y_pred_l1 = log_reg_l1.predict(X_test_scaled)
accuracy_l1 = accuracy_score(y_test, y_pred_l1)
report_l1 = classification_report(y_test, y_pred_l1)
performance_metrics.append(('L1', C_value, accuracy_l1))
# Train and evaluate L2 model
log_reg_l2 = LogisticRegression(penalty='l2', C=C_value, solver='liblinear')
log_reg_l2.fit(X_train_scaled, y_train)
y_pred_l2 = log_reg_l2.predict(X_test_scaled)
accuracy_l2 = accuracy_score(y_test, y_pred_l2)
report_l2 = classification_report(y_test, y_pred_l2)
performance_metrics.append(('L2', C_value, accuracy_l2))
# Print the performance metrics for all models
print("Model Performance Evaluation:")
print("--------------------------------")
for metric in performance_metrics:
reg_type, C_value, accuracy = metric
print(f"Regularization: {reg_type}, C: {C_value}, Accuracy: {accuracy:.2f}")
İşte çıktı.
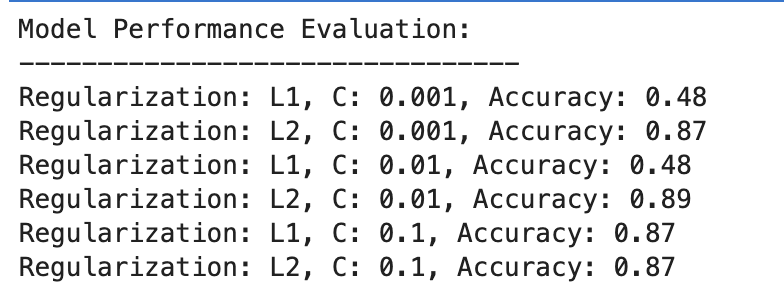
Sonucu değerlendirelim.
L1 Düzenlemesi
- C=0.001'de doğruluk oldukça düşüktür (%48). Bu da modelin yetersiz olduğunu gösteriyor. Çok fazla düzenlilik gösteriyor.
- C 0.01'e yükseldikçe L1 için doğruluk değişmeden kalır, bu da modelde hala yetersiz uyum sorunu olduğunu veya düzenlileştirmenin çok güçlü olduğunu gösterir.
- C=0.1'de doğruluk önemli ölçüde %87'ye yükselir; bu da düzenlileştirme gücünün azaltılmasının modelin verilerden daha iyi öğrenmesine olanak sağladığını gösterir.
L2 Düzenlemesi
Genel olarak, L2 düzenlemesi, C=87 için %0.001'lik doğrulukla ve C=89 için %0.01'da biraz daha yüksek doğrulukla, ardından C=87 için %0.1'de sabitlenerek tutarlı biçimde iyi bir performans sergiliyor.
Bu, L2 düzenlemesinin, potansiyel olarak doğası gereği, lojistik regresyon modellerinde bu veri kümesi için genellikle daha bağışlayıcı ve etkili olduğunu göstermektedir.
Derin Öğrenmede Düzenleme
Derin öğrenmede L1 (Kement) ve L2 (Ridge) düzenlemesi, bırakma ve erken durdurma dahil olmak üzere çeşitli düzenleme teknikleri kullanılır.
Bu örnekte, daha önce makine öğrenimi örneğinde yaptığımızı tekrarlamak için L1 ve L2 düzenlemesini uygulayacağız. Bu sefer L1 ve L2 düzenleme değerlerinin bir listesini tanımlayalım.
Daha sonra tüm bu değerler için derin öğrenme modelimizi eğitip değerlendireceğiz ve sonunda sonuçları değerlendireceğiz.
Kodu görelim.
from tensorflow.keras.regularizers import l1_l2
import numpy as np
# Define a list/grid of L1 and L2 regularization values
l1_values = [0.001, 0.01, 0.1]
l2_values = [0.001, 0.01, 0.1]
# Placeholder for storing performance metrics
performance_metrics = []
# Iterate over all combinations of L1 and L2 values
for l1_val in l1_values:
for l2_val in l2_values:
# Define model with the current combination of L1 and L2
model = Sequential([
Dense(128, activation='relu', input_shape=(X_train_scaled.shape[1],), kernel_regularizer=l1_l2(l1=l1_val, l2=l2_val)),
Dropout(0.5),
Dense(64, activation='relu', kernel_regularizer=l1_l2(l1=l1_val, l2=l2_val)),
Dropout(0.5),
Dense(1, activation='sigmoid')
])
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# Train the model
history = model.fit(X_train_scaled, y_train, validation_split=0.2, epochs=100, batch_size=10, verbose=0)
# Evaluate the model
loss, accuracy = model.evaluate(X_test_scaled, y_test, verbose=0)
# Store the performance along with the regularization values
performance_metrics.append((l1_val, l2_val, accuracy))
# Find the best performing model
best_performance = max(performance_metrics, key=lambda x: x[2])
best_l1, best_l2, best_accuracy = best_performance
# After the loop, to print all performance metrics
print("All Model Performances:")
print("L1 Value | L2 Value | Accuracy")
for metrics in performance_metrics:
print(f"{metrics[0]:8} | {metrics[1]:8} | {metrics[2]:.3f}")
# After finding the best performance, to print the best model details
print("nBest Model Performance:")
print("----------------------------")
print(f"Best L1 value: {best_l1}")
print(f"Best L2 value: {best_l2}")
print(f"Best accuracy: {best_accuracy:.3f}")
İşte çıktı.
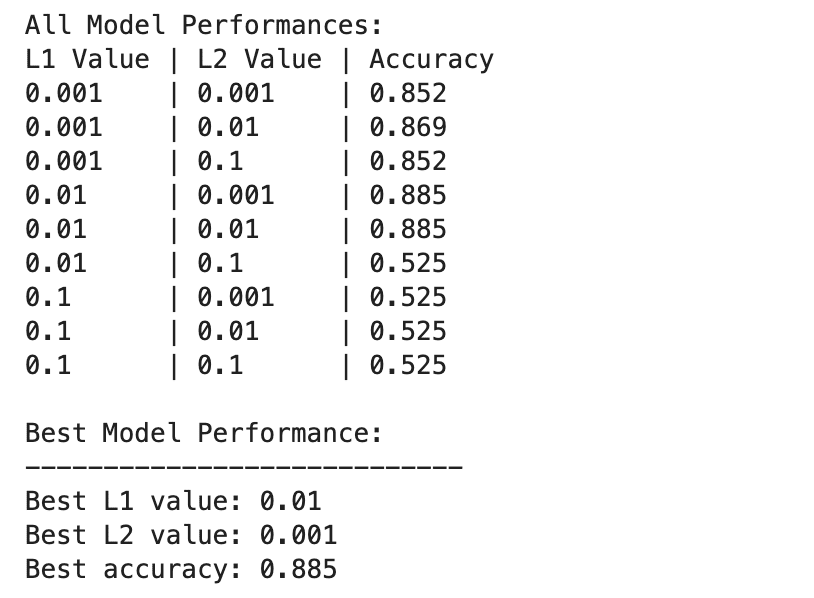
Derin öğrenme modeli performansları, L1 ve L2 düzenlileştirme değerlerinin farklı kombinasyonlarına göre daha geniş ölçüde farklılık gösterir.
En iyi performans, %1'lik bir doğrulukla L0.01=2 ve L0.001=88.5'de gözlemlenir; bu, modelin verilerdeki temel kalıpları yakalamasına izin verirken aşırı uyumu önleyen dengeli bir düzenlemeyi gösterir.
Özellikle L1=0.1 veya L2=0.1'de daha yüksek düzenleme değerleri, model doğruluğunu büyük ölçüde %52.5'e düşürür; bu da çok fazla düzenlemenin modelin öğrenme kapasitesini ciddi şekilde sınırladığını gösterir.
Düzenlileştirmede Makine Öğrenimi ve Derin Öğrenme
Makine Öğrenimi ile Derin Öğrenme arasındaki sonuçları karşılaştıralım.
Düzenlemenin Etkinliği: Hem makine öğrenimi hem de derin öğrenme bağlamlarında, uygun düzenleme aşırı uyumun azaltılmasına yardımcı olur, ancak aşırı düzenleme yetersiz uyumun oluşmasına neden olur. Optimum düzenleme gücü, daha karmaşık olmaları nedeniyle potansiyel olarak daha incelikli bir denge gerektiren derin öğrenme modelleriyle birlikte değişiklik gösterir.
performans: En iyi performansa sahip makine öğrenimi modeli (L2 ile C=0.01, %89 doğruluk) ve en iyi performansa sahip derin öğrenme modeli (L1=0.01, L2=0.001, %88.5 doğruluk) karşılaştırılabilir doğruluklar elde ederek her iki yaklaşımın da etkili olabileceğini gösterir. Bu veri kümesinde yüksek performans elde etmek için düzenli hale getirildi.
Düzenleme Stratejisi: L2 düzenlileştirmesi, lojistik regresyon modellerinde C seçimine daha etkili ve daha az duyarlı gibi görünürken, L1 ve L2 düzenlileştirmesinin bir kombinasyonu, özellik seçimi ile ağırlık cezası arasında bir denge sunarak derin öğrenmede en iyi sonucu sağlar.
Düzenlemenin seçimi ve gücü, öğrenme karmaşıklığını aşırı uyum veya yetersiz uyum riskiyle dengelemek için dikkatli bir şekilde ayarlanmalıdır.
Bu araştırma boyunca, düzenlileştirmenin gizemini açığa çıkardık, aşırı uyumu önlemedeki rolünü gösterdik ve modellerimizin görünmeyen verilere iyi bir şekilde genelleştirilmesini sağladık.
Düzenlileştirme tekniklerini uygulamak, sizi makine öğrenimi ve derin öğrenmede uzmanlığa yaklaştıracak ve veri bilimci araç setinizi güçlendirecektir.
Veri projelerine gidin ve verilerinizi aşağıdaki gibi farklı senaryolarda düzenlemeyi deneyin: Teslimat Süresi Tahmini. Bu veri projemizde hem Makine Öğrenimi hem de Derin Öğrenme modellerini kullandık. Ancak sonuçta iyileştirmeye yer olabileceğinden de bahsettik. Öyleyse neden orada düzenlileştirmeyi denemiyorsunuz ve faydası olup olmadığına bakmıyorsunuz?
Nate Rosidi bir veri bilimcisi ve ürün stratejisidir. Aynı zamanda analitik öğreten bir yardımcı profesördür ve kurucusudur. StrataScratch, veri bilimcilerinin en iyi şirketlerden gelen gerçek röportaj sorularıyla röportajlarına hazırlanmalarına yardımcı olan bir platform. onunla bağlantı kurun Twitter: StrataScratch or LinkedIn.
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- PlatoData.Network Dikey Üretken Yapay Zeka. Kendine güç ver. Buradan Erişin.
- PlatoAiStream. Web3 Zekası. Bilgi Genişletildi. Buradan Erişin.
- PlatoESG. karbon, temiz teknoloji, Enerji, Çevre, Güneş, Atık Yönetimi. Buradan Erişin.
- PlatoSağlık. Biyoteknoloji ve Klinik Araştırmalar Zekası. Buradan Erişin.
- Kaynak: https://www.kdnuggets.com/wtf-is-regularization-and-what-is-it-for?utm_source=rss&utm_medium=rss&utm_campaign=wtf-is-regularization-and-what-is-it-for

