Giriş
Yapay zeka alanında Büyük Dil Modelleri (LLM'ler) ve OpenAI'nin GPT-4'ü, Anthropic'in Claude 2'si, Meta'nın Llama'sı, Falcon, Google'ın Palm'ı vb. Üretken Yapay Zeka modelleri, sorunları çözme şeklimizde devrim yarattı. Yüksek Lisans'lar doğal dil işleme görevlerini gerçekleştirmek için derin öğrenme tekniklerini kullanır. Bu makale size bir vektör veritabanı kullanarak Yüksek Lisans Uygulamaları oluşturmayı öğretecektir. Amazon müşteri hizmetleri veya Flipkart Decision Assistant gibi bir sohbet robotuyla etkileşime girmiş olabilirsiniz. İnsan benzeri metinler oluştururlar ve gerçek hayattaki konuşmalardan neredeyse ayırt edilemeyecek etkileşimli bir kullanıcı deneyimi sağlarlar. Bununla birlikte, bu yüksek lisans programlarının, belirli kullanım durumları için gerçekten yararlı olacak, son derece ilgili ve spesifik sonuçlar üretecek şekilde optimize edilmesi gerekir.

Örneğin “Android uygulamasında dilimi nasıl değiştiririm?” diye sorarsanız. Amazon müşteri hizmetleri uygulamasına, tam olarak bu metinle ilgili eğitim verilmemiş olabilir ve bu nedenle yanıt veremeyebilir. Burası bir vektör veritabanının kurtarmaya geldiği yerdir. Bir vektör veritabanı, alan adı metinlerini (bu durumda yardım dokümanları) ve sipariş geçmişi vb. dahil olmak üzere tüm kullanıcılar tarafından yapılan geçmiş sorguları sayısal yerleştirmeler olarak saklar ve benzer vektörlerin gerçek zamanlı olarak aranmasını sağlar. Bu durumda, bu sorguyu sayısal bir vektöre kodlar ve bunu, vektör veritabanında benzerlik araması yapmak ve en yakın komşularını bulmak için kullanır. Bu yardım sayesinde chatbot, kullanıcıyı Amazon uygulamasındaki “Dil tercihinizi değiştirin” bölümüne doğru bir şekilde yönlendirebilir.
Öğrenme hedefleri
- Yüksek Lisans'lar nasıl çalışır, sınırlamaları nelerdir ve neden vektör veritabanlarına ihtiyaç duyarlar?
- Gömme modellerine giriş ve bunların kodlanıp uygulamalarda nasıl kullanılacağı.
- Vektör veritabanının ne olduğunu ve LLM uygulama mimarisinin nasıl bir parçası olduğunu öğrenin.
- Vektör veritabanlarını ve tensor akışını kullanarak Yüksek Lisans/Generatif Yapay Zeka uygulamalarını nasıl kodlayacağınızı öğrenin.
Bu makale, Veri Bilimi Blogatonu.
İçindekiler
LLM nedir?
Büyük Dil Modelleri (LLM'ler), doğal dili işlemek ve anlamak için derin öğrenme algoritmaları kullanan temel makine öğrenimi modelleridir. Bu modeller, dildeki kalıpları ve varlık ilişkilerini öğrenmek için büyük miktarda metin verisi üzerinde eğitilir. LLM'ler, dilleri çevirme, duyguları analiz etme, chatbot konuşmaları ve daha fazlası gibi birçok türde dil görevi gerçekleştirebilir. Karmaşık metin verilerini anlayabilir, varlıkları ve aralarındaki ilişkileri tanımlayabilir ve tutarlı ve gramer açısından doğru yeni metinler oluşturabilirler.
Yüksek Lisans hakkında daha fazlasını okuyun okuyun.
Yüksek Lisans'lar nasıl çalışır?
LLM'ler, milyarlarca veya trilyonlarca parametre içeren, genellikle terabaytlar, hatta petabaytlarca büyük miktarda veri kullanılarak eğitilir ve bu da onların kullanıcının istemlerine veya sorgularına göre ilgili yanıtları tahmin etmelerine ve oluşturmalarına olanak tanır. Anlamlı metinler oluşturmak için girdi verilerini kelime yerleştirmeler, öz-dikkat katmanları ve ileri besleme ağları aracılığıyla işlerler. Yüksek Lisans mimarileri hakkında daha fazla bilgi edinebilirsiniz okuyun.
Yüksek Lisans'ın Sınırlamaları
Yüksek Lisans'lar oldukça yüksek doğrulukla yanıtlar üretiyor gibi görünse de, daha iyi birçok standartlaştırılmış durumda insanlardan daha testleri, bu modellerin hâlâ sınırlamaları vardır. İlk olarak, muhakemelerini oluşturmak için yalnızca eğitim verilerine güvenirler ve dolayısıyla verilerdeki belirli veya güncel bilgilerden yoksun olabilirler. Bu, modelin yanlış veya olağandışı yanıtlar, yani "halüsinasyonlar" üretmesine yol açar. Devam eden bir durum var çaba bunu hafifletmek için. İkinci olarak model, kullanıcının beklentilerine uygun şekilde davranmayabilir veya yanıt vermeyebilir.
Bu sorunu çözmek için vektör veritabanları ve yerleştirme modelleri, kullanıcının bilgi aradığı benzer yöntemlere (metin, resim, video vb.) ek aramalar sağlayarak Yüksek Lisans/Üretici Yapay Zeka bilgisini geliştirir. İşte LLM'lerin kullanıcının istediği yanıtı vermediği ve bunun yerine bu bilgiyi bulmak için bir vektör veritabanına güvendiği bir örnek.

Yüksek Lisans ve Vektör Veritabanları
Büyük Dil Modelleri (LLM'ler) e-ticaret, seyahat, arama, içerik oluşturma ve finans gibi endüstrinin birçok bölümünde kullanılıyor veya entegre ediliyor. Bu modeller, metin, resim, video ve diğer verilerin sayısal temsilini yerleştirme adı verilen ikili bir temsilde saklayan, vektör veritabanı olarak bilinen nispeten daha yeni bir veritabanı türüne dayanır. Bu bölümde vektör veritabanları ve yerleştirmelerin temelleri vurgulanmakta ve daha da önemlisi bunların LLM uygulamalarıyla entegrasyon için nasıl kullanılacağına odaklanılmaktadır.
Vektör veritabanı, yüksek boyutlu alanı kullanarak yerleştirmeleri depolayan ve arayan bir veritabanıdır. Bu vektörler bir verinin özelliklerinin veya niteliklerinin sayısal temsilleridir. Yüksek boyutlu bir uzaydaki vektörler arasındaki mesafeyi veya benzerliği hesaplayan algoritmalar kullanan vektör veritabanları, benzer verileri hızlı ve verimli bir şekilde alabilir. Verileri satırlar veya sütunlar halinde depolayan ve tam eşleştirme veya anahtar kelimeye dayalı arama yöntemlerini kullanan geleneksel skaler tabanlı veritabanlarının aksine, vektör veritabanları farklı şekilde çalışır. Yaklaşık En Yakın Komşular (ANN) gibi teknikleri kullanarak çok kısa bir sürede (milisaniye düzeyinde) geniş bir vektör koleksiyonunu aramak ve karşılaştırmak için vektör veritabanlarını kullanırlar.
Gömmeler Hakkında Hızlı Bir Eğitim
Yapay zeka modelleri, metin, video, görseller gibi ham verileri aşağıdaki gibi bir vektör yerleştirme kitaplığına girerek yerleştirmeler oluşturur. kelime2vec Yapay zeka ve makine öğrenimi bağlamında bu özellikler, kalıp ilişkilerini ve temel yapıları anlamak için gerekli olan verilerin farklı boyutlarını temsil eder.
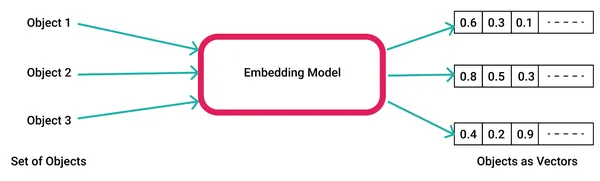
İşte word2vec kullanarak sözcük yerleştirmelerin nasıl oluşturulacağına ilişkin bir örnek.
1. Özel veri topluluğunuzu kullanarak modeli oluşturun veya önceden oluşturulmuş örnek bir modeli kullanın. Google veya FastText'i seçin. Kendiniz oluşturursanız, bunu dosya sisteminize “word2vec.model” dosyası olarak kaydedebilirsiniz.
import gensim # Create a word2vec model
model = gensim.models.Word2Vec(corpus) # Save the model file
model.save('word2vec.model')2. Modeli yükleyin, bir giriş sözcüğü için bir vektör yerleştirme oluşturun ve bunu, vektör yerleştirme uzayında benzer sözcükler elde etmek için kullanın.
import gensim
import numpy as np # Load the word2vec model
model = gensim.models.Word2Vec.load('word2vec.model') # Get the vector for the word "king"
king_vector = model['king'] # Get the most similar vectors to the king vector
similar_vectors = model.similar_by_vector(king_vector, topn=5) # Print the most similar vectors
for vector in similar_vectors: print(vector[0], vector[1]) 3. İşte giriş kelimesine yakın ilk 5 kelime.
Output: man 0.85
prince 0.78
queen 0.75
lord 0.74
emperor 0.72Vektör Veritabanlarını Kullanan Yüksek Lisans Uygulama Mimarisi
Yüksek düzeyde, vektör veritabanları, yerleştirmelerin hem oluşturulmasını hem de sorgulanmasını yönetmek için gömme modellerine dayanır. Besleme yolunda, derlem içeriği gömme modeli kullanılarak vektörlere kodlanır ve Pinecone, ChromaDB, Weaviate vb. gibi vektör veritabanlarında depolanır. Okuma yolunda uygulama cümleleri veya kelimeleri kullanarak bir sorgu yapar ve tekrar kodlanır modelin bir vektöre yerleştirilmesiyle, bu daha sonra sonuçları almak için vektör db'de sorgulanır.
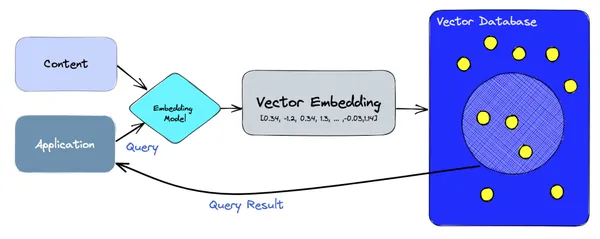
Vektör Veritabanlarını Kullanan Yüksek Lisans Başvuruları
LLM, dil görevlerine yardımcı olur ve aşağıdakiler gibi daha geniş bir model sınıfına yerleştirilmiştir: üretken yapay zeka Bu, yalnızca metnin yanı sıra görüntüler ve videolar da oluşturabiliyor. Bu bölümde vektör veritabanlarını kullanarak pratik Yüksek Lisans/Üretici Yapay Zeka uygulamalarının nasıl oluşturulacağını öğreneceğiz. Dil modelleri için transformatörler ve meşale kitaplıkları kullandım ve çam kozalağı bir vektör veritabanı olarak. LLM/gömmeler için herhangi bir dil modelini ve depolama ve arama için herhangi bir vektör veritabanını seçebilirsiniz.
Chatbot Uygulaması
Vektör veritabanını kullanarak bir chatbot oluşturmak için şu adımları takip edebilirsiniz:
- Pinecone, Chroma, Weaviate, AWS Kendra vb. gibi bir vektör veritabanı seçin.
- Chatbot'unuz için bir vektör dizini oluşturun.
- Seçtiğiniz geniş bir metin kümesini kullanarak bir dil modeli eğitin. Örneğin bir haber sohbet robotu için haber verilerini besleyebilirsiniz.
- Vektör veritabanını ve dil modelini entegre edin.
Aşağıda bir vektör veritabanı ve bir dil modeli kullanan bir chatbot uygulamasının basit bir örneği verilmiştir:
import pinecone
import transformers # Create an API client for the vector database
client = pinecone.Client(api_key="YOUR_API_KEY") # Load the language model
model = transformers.AutoModelForCausalLM.from_pretrained("google/bigbird-roberta-base") # Define a function to generate text
def generate_text(prompt): inputs = model.prepare_inputs_for_generation(prompt, return_tensors="pt") outputs = model.generate(inputs, max_length=100) return outputs[0].decode("utf-8") # Define a function to retrieve the most similar vectors to the user's query vector
def retrieve_similar_vectors(query_vector): results = client.search("my_index", query_vector) return results # Define a function to generate a response to the user's query
def generate_response(query): # Retrieve the most similar vectors to the user's query vector similar_vectors = retrieve_similar_vectors(query) # Generate text based on the retrieved vectors response = generate_text(similar_vectors[0]) return response # Start the chatbot
while True: # Get the user's query query = input("What is your question? ") # Generate a response to the user's query response = generate_response(query) # Print the response print(response)Bu chatbot uygulaması, kullanıcının sorgu vektörüne en benzer vektörleri vektör veritabanından alacak ve ardından alınan vektörlere dayalı dil modelini kullanarak metin üretecektir.
ChatBot > What is your question?
User_A> How tall is the Eiffel Tower?
ChatBot>The height of the Eiffel Tower measures 324 meters (1,063 feet) from its base to the top of its antenna. Görüntü Oluşturucu Uygulaması
Her ikisini de kullanan bir Image Generator uygulamasının nasıl oluşturulacağını keşfedelim üretken yapay zeka ve LLM kütüphaneleri.
- Görüntü vektörlerinizi depolamak için bir vektör veritabanı oluşturun.
- Egzersiz verilerinizden görüntü vektörlerini çıkarın.
- Görüntü vektörlerini vektör veritabanına ekleyin.
- Üretken bir rakip ağı (GAN) eğitin. Okumak okuyun GAN'a giriş yapmaya ihtiyacınız varsa.
- Vektör veritabanını ve GAN'ı entegre edin.
Görüntüler oluşturmak için bir vektör veritabanını ve bir GAN'ı birleştiren bir programın basit bir örneği:
import pinecone
import torch
from torchvision import transforms # Create an API client for the vector database
client = pinecone.Client(api_key="YOUR_API_KEY") # Load the GAN
generator = torch.load("generator.pt") # Define a function to generate an image from a vector
def generate_image(vector): # Convert the vector to a tensor tensor = torch.from_numpy(vector).float() # Generate the image image = generator(tensor) # Transform the image to a PIL image image = transforms.ToPILImage()(image) return image # Start the image generator
while True: # Get the user's query query = input("What kind of image would you like to generate? ") # Retrieve the most similar vector to the user's query vector similar_vectors = client.search("my_index", query) # Generate an image from the retrieved vector image = generate_image(similar_vectors[0]) # Display the image image.show()Bu program, kullanıcının sorgu vektörüne en benzer vektörü vektör veritabanından alacak ve ardından alınan vektöre dayalı olarak GAN'ı kullanarak bir görüntü oluşturacaktır.
ImageBot>What kind of image would you like to generate?
Me>An idyllic image of a mountain with a flowing river.
ImageBot> Wait a minute! Here you go...
Bu programı özel ihtiyaçlarınızı karşılayacak şekilde özelleştirebilirsiniz. Örneğin, portreler veya manzaralar gibi belirli bir görüntü türünü oluşturma konusunda uzmanlaşmış bir GAN'ı eğitebilirsiniz.
Film Tavsiye Uygulaması
Bir film külliyatından nasıl film önerisi uygulaması oluşturulacağını keşfedelim. Ürünler veya diğer varlıklar için bir öneri sistemi oluşturmak için benzer bir fikri kullanabilirsiniz.
- Film vektörlerinizi depolamak için bir vektör veritabanı oluşturun.
- Film meta verilerinizden film vektörlerini çıkarın.
- Film vektörlerini vektör veritabanına ekleyin.
- Kullanıcılara film önerin.
Kullanıcılara film önermek için Pinecone API'sinin nasıl kullanılacağına ilişkin bir örneği burada bulabilirsiniz:
import pinecone # Create an API client
client = pinecone.Client(api_key="YOUR_API_KEY") # Get the user's vector
user_vector = client.get_vector("user_index", user_id) # Recommend movies to the user
results = client.search("movie_index", user_vector) # Print the results
for result in results: print(result["title"])İşte bir kullanıcı için örnek bir öneri
The Shawshank Redemption
The Dark Knight
Inception
The Godfather
Pulp FictionVektör Arama/Veritabanı Kullanarak Yüksek Lisans'ların Gerçek Dünya Kullanım Durumları
- Microsoft ve TikTok, uzun süreli bellek ve daha hızlı aramalar için Pinecone gibi vektör veritabanlarını kullanıyor. Bu, LLM'lerin bir vektör veritabanı olmadan tek başına yapamayacağı bir şeydir. Kullanıcıların geçmiş sorularını/cevaplarını kaydetmelerine ve oturumlarına devam etmelerine yardımcı oluyor. Örneğin kullanıcılar, "Geçen hafta tartıştığımız makarna tarifi hakkında bana daha fazla bilgi verin" diye sorabilir. Okumak okuyun.

- Flipkart'ın Karar Asistanı, öncelikle sorguyu vektör yerleştirme olarak kodlayarak ve ilgili ürünleri yüksek boyutlu uzayda depolayan vektörlere göre arama yaparak kullanıcılara ürünler önerir. Örneğin, "Wrangler deri ceket kahverengi erkek orta boy" araması yaparsanız, vektör benzerlik aramasını kullanarak kullanıcıya alakalı ürünleri önerir. Aksi takdirde, hiçbir ürün kataloğu bu tür başlıkları veya ürün ayrıntılarını içermeyeceğinden LLM'nin herhangi bir tavsiyesi olmayacaktır. Okuyabilirsin okuyun.
- Afrika'da faaliyet gösteren bir fintech şirketi olan Chipper Cash, dolandırıcılık amaçlı kullanıcı kayıtlarını 10 kat azaltmak için bir vektör veritabanı kullanıyor. Bunu, önceki kullanıcı kayıtlarının tüm görsellerini vektör yerleştirmeleri olarak depolayarak yapar. Daha sonra yeni bir kullanıcı kaydolduğunda bunu bir vektör olarak kodluyor ve sahtekarlığı tespit etmek için mevcut kullanıcılarla karşılaştırıyor. Okuyabilirsin okuyun.

- Facebook, vektör arama kütüphanesini kullanıyor FAİS (blog) herhangi bir multimedyada hızlı bir arama yapmak ve kullanıcıya daha iyi öneriler gösterilmek üzere benzer adaylar bulmak için Instagram Reels ve Facebook Stories dahil olmak üzere dahili olarak birçok üründe bulunur.
Sonuç
Vektör veritabanları, görüntü oluşturma, film veya ürün önerileri ve sohbet robotları gibi çeşitli Yüksek Lisans uygulamaları oluşturmak için kullanışlıdır. Yüksek Lisans'lara Yüksek Lisans'ların eğitim almadığı ek veya benzer bilgileri sağlarlar. Vektör yerleştirmelerini yüksek boyutlu bir alanda verimli bir şekilde saklarlar ve benzer yerleştirmeleri yüksek doğrulukla bulmak için en yakın komşu aramasını kullanırlar.
Önemli Noktalar
Bu makaleden elde edilen önemli çıkarımlar, vektör veritabanlarının LLM uygulamaları için son derece uygun olduğu ve kullanıcıların entegre olabileceği aşağıdaki önemli özellikleri sunduğudur:
- Performans: Vektör veritabanları, yüksek performanslı LLM uygulamaları geliştirmek için önemli olan vektör verilerini verimli bir şekilde depolamak ve almak için özel olarak tasarlanmıştır.
- Hassas: Vektör veritabanları, küçük farklılıklar gösterseler bile benzer vektörleri doğru bir şekilde eşleştirebilir. Benzer vektörleri hesaplamak için en yakın komşu algoritmalarını kullanırlar.
- Çok Modlu: Vektör veritabanları metin, resim ve ses dahil olmak üzere çeşitli çok modlu verileri barındırabilir. Bu çok yönlülük, onları çeşitli veri türleriyle çalışmayı gerektiren Yüksek Lisans/Üretken Yapay Zeka uygulamaları için ideal bir seçim haline getiriyor.
- Geliştirici dostu: Vektör veritabanları, makine öğrenimi teknikleri konusunda kapsamlı bilgiye sahip olmayan geliştiriciler için bile nispeten kullanıcı dostudur.
Ek olarak, birçok mevcut SQL/NoSQL çözümünün zaten vektör gömme depolama, indeksleme ve daha hızlı benzerlik arama özellikleri eklediğini vurgulamak isterim; PostgreSQL ve Redis. Bu hızla gelişen bir alandır, dolayısıyla uygulama geliştiricileri yakın gelecekte yenilikçi uygulamalar geliştirmek için birçok seçeneğe sahip olacak.
Sık Sorulan Sorular
A. Büyük Dil Modelleri veya LLM'ler, bağlamla birlikte insan benzeri yanıtları taklit etmek için sinir ağlarını kullanan geniş bir metin verisi topluluğu üzerinde eğitilmiş gelişmiş Yapay Zeka (AI) programlarıdır. Eğitim aldıkları alanda metinsel verileri tahmin edebilir, yanıtlayabilir ve üretebilirler.
A. Gömmeler metin, resim, video veya diğer veri formatlarının sayısal temsilleridir. Yüksek boyutlu bir alanda anlamsal olarak benzer nesnelerin bir arada bulunmasını ve bulunmasını kolaylaştırırlar.
A. Bir veritabanı, yerelliğe duyarlı karma oluşturma gibi en yakın komşu algoritmalarını kullanarak benzer vektörleri bulmak için yüksek boyutlu vektör yerleştirmelerini saklar ve sorgular. Yüksek Lisans/Generatif Yapay Zeka, Yüksek Lisans'ta ince ayar yapmak yerine benzer vektörler için ek aramalar sağlamalarına yardımcı olmalarına ihtiyaç duyuyor.
A. Vektör veritabanları, vektör yerleştirmelerini indekslemeye ve aramaya yardımcı olan niş veritabanlarıdır. Açık kaynak topluluğunda oldukça popülerdirler ve birçok kuruluş/uygulama onlarla entegre olmaktadır. Ancak mevcut birçok SQL/NoSQL veri tabanı benzer yetenekler ekliyor, böylece geliştirici topluluğu yakın gelecekte birçok seçeneğe sahip olacak.
Bu makalede gösterilen medya Analytics Vidhya'ya ait değildir ve Yazarın takdirine bağlı olarak kullanılır.
İlgili bağlantılar
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- PlatoData.Network Dikey Üretken Yapay Zeka. Kendine güç ver. Buradan Erişin.
- PlatoAiStream. Web3 Zekası. Bilgi Genişletildi. Buradan Erişin.
- PlatoESG. karbon, temiz teknoloji, Enerji, Çevre, Güneş, Atık Yönetimi. Buradan Erişin.
- PlatoSağlık. Biyoteknoloji ve Klinik Araştırmalar Zekası. Buradan Erişin.
- Kaynak: https://www.analyticsvidhya.com/blog/2023/10/how-to-build-llm-apps-using-vector-database/

