Yazara göre resim
Scikit-learn işlem hatlarını kullanmak, ön işleme ve modelleme adımlarınızı basitleştirebilir, kod karmaşıklığını azaltabilir, veri ön işlemede tutarlılık sağlayabilir, hiper parametre ayarlamasına yardımcı olabilir ve iş akışınızı daha organize ve bakımı kolay hale getirebilir. Pipelines, birden fazla dönüşümü ve son modeli tek bir varlıkta birleştirerek tekrarlanabilirliği artırır ve her şeyi daha verimli hale getirir.
Bu eğitimde aşağıdakilerle çalışacağız: Banka Kaybı Rastgele Orman Sınıflandırıcısını eğitmek için Kaggle'dan veri kümesi. Geleneksel veri ön işleme ve model eğitim yaklaşımını, Scikit-learn işlem hatları ve ColumnTransformers'ı kullanarak daha verimli bir yöntemle karşılaştıracağız.
Veri işleme hattında hem kategorik hem de sayısal sütunları ayrı ayrı nasıl dönüştüreceğimizi öğreneceğiz. Geleneksel kod stiliyle başlayacağız ve ardından benzer işlemleri gerçekleştirmenin daha iyi bir yolunu göstereceğiz.
Verileri zip dosyasından çıkardıktan sonra, indeks sütunu olarak “id” içeren `train.csv` dosyasını yükleyin. Gereksiz sütunları bırakın ve veri kümesini karıştırın.
import pandas as pd
bank_df = pd.read_csv("train.csv", index_col="id")
bank_df = bank_df.drop(['CustomerId', 'Surname'], axis=1)
bank_df = bank_df.sample(frac=1)
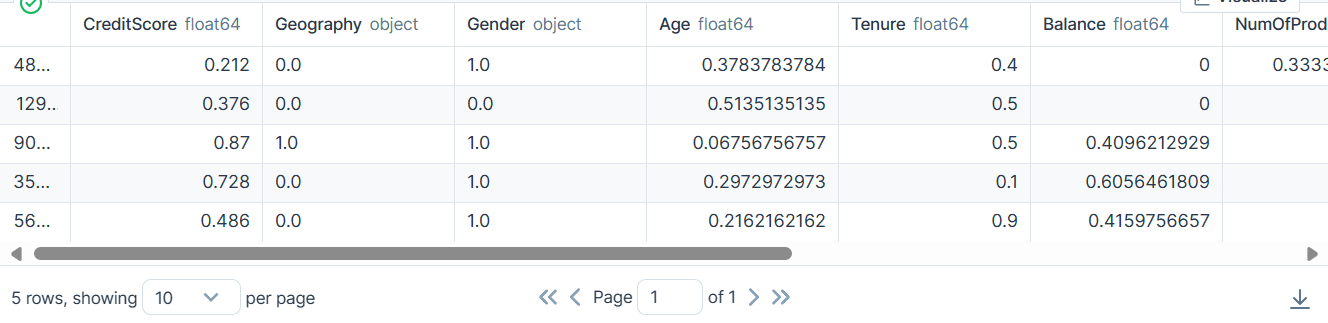
bank_df.head()
Kategorik, tamsayı ve kayan sütunlarımız var. Veri kümesi oldukça temiz görünüyor.

Basit Scikit-öğrenme Kodu
Bir veri bilimci olarak bu kodu defalarca yazdım. Amacımız hem kategorik hem de sayısal özellikler için eksik değerleri doldurmaktır. Bunu başarmak için her özellik türü için farklı stratejilere sahip bir 'SimpleImputer' kullanacağız.
Eksik değerler doldurulduktan sonra kategorik özellikleri tamsayılara dönüştürüp sayısal özellikler üzerinde min-maks ölçeklendirme uygulayacağız.
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import OrdinalEncoder, MinMaxScaler
cat_col = [1,2]
num_col = [0,3,4,5,6,7,8,9]
# Filling missing categorical values
cat_impute = SimpleImputer(strategy="most_frequent")
bank_df.iloc[:,cat_col] = cat_impute.fit_transform(bank_df.iloc[:,cat_col])
# Filling missing numerical values
num_impute = SimpleImputer(strategy="median")
bank_df.iloc[:,num_col] = num_impute.fit_transform(bank_df.iloc[:,num_col])
# Encode categorical features as an integer array.
cat_encode = OrdinalEncoder()
bank_df.iloc[:,cat_col] = cat_encode.fit_transform(bank_df.iloc[:,cat_col])
# Scaling numerical values.
scaler = MinMaxScaler()
bank_df.iloc[:,num_col] = scaler.fit_transform(bank_df.iloc[:,num_col])
bank_df.head()
Sonuç olarak temiz ve yalnızca tamsayı veya kayan değer değerleriyle dönüştürülmüş bir veri kümesi elde ettik.
Scikit-learn Boru Hatları Kodu
Yukarıdaki kodu `Pipeline` ve `ColumnTransformer`ı kullanarak dönüştürelim. Ön işleme tekniğini uygulamak yerine iki boru hattı oluşturacağız. Biri sayısal sütunlar içindir, diğeri ise kategorik sütunlar içindir.
- Sayısal boru hattında, "ortalama" stratejisiyle basit bir değer kullandık ve normalleştirme için bir min-maks ölçekleyici uyguladık.
- Kategorik ardışık düzende, kategorileri sayısal değerlere dönüştürmek için "most_frequent" stratejisine sahip basit imputer'ı ve orijinal kodlayıcıyı kullandık.
ColumnTransformer'ı kullanarak iki boru hattını birleştirdik ve her birine sütun indeksini sağladık. Bu boru hatlarını belirli sütunlara uygulamanıza yardımcı olacaktır. Örneğin, kategorik bir transformatör boru hattı yalnızca 1 ve 2 numaralı sütunlara uygulanacaktır.
Not: the rest=”passthrough” işlenmemiş sütunların en sona ekleneceği anlamına gelir. Bizim durumumuzda bu hedef sütundur.
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import OrdinalEncoder, MinMaxScaler
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
# Identify numerical and categorical columns
cat_col = [1,2]
num_col = [0,3,4,5,6,7,8,9]
# Transformers for numerical data
numerical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='mean')),
('scaler', MinMaxScaler())
])
# Transformers for categorical data
categorical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='most_frequent')),
('encoder', OrdinalEncoder())
])
# Combine transformers into a ColumnTransformer
preproc_pipe = ColumnTransformer(
transformers=[
('num', numerical_transformer, num_col),
('cat', categorical_transformer, cat_col)
],
remainder="passthrough"
)
# Apply the preprocessing pipeline
bank_df = preproc_pipe.fit_transform(bank_df)
bank_df[0]
Dönüşümden sonra ortaya çıkan dizi, sütun transformatöründeki boru hatlarının sırasına göre başlangıçta sayısal dönüşüm değerini ve sonunda kategorik dönüşüm değerini içerir.
array([0.712 , 0.24324324, 0.6 , 0. , 0.33333333,
1. , 1. , 0.76443485, 2. , 0. ,
0. ])
Boru hattını görselleştirmek için Jupyter Notebook'ta boru hattı nesnesini çalıştırabilirsiniz. Scikit-learn'in en son sürümüne sahip olduğunuzdan emin olun.
preproc_pipe

Modelimizi eğitmek ve değerlendirmek için veri kümemizi iki alt kümeye ayırmamız gerekir: eğitim ve test.
Bunu yapmak için öncelikle bağımlı ve bağımsız değişkenler oluşturup bunları NumPy dizilerine dönüştüreceğiz. Daha sonra veri setini iki alt kümeye bölmek için 'train_test_split' fonksiyonunu kullanacağız.
from sklearn.model_selection import train_test_split
X = bank_df.drop("Exited", axis=1).values
y = bank_df.Exited.values
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=125
)Basit Scikit-öğrenme Kodu
Eğitim kodu yazmanın geleneksel yolu, önce 'SelectKBest'i kullanarak özellik seçimini gerçekleştirmek ve ardından yeni özelliği Rastgele Orman Sınıflandırıcı modelimize sağlamaktır.
Öncelikle eğitim setini kullanarak modeli eğiteceğiz ve sonuçları test veri setini kullanarak değerlendireceğiz.
from sklearn.feature_selection import SelectKBest, chi2
from sklearn.ensemble import RandomForestClassifier
KBest = SelectKBest(chi2, k="all")
X_train = KBest.fit_transform(X_train, y_train)
X_test = KBest.transform(X_test)
model = RandomForestClassifier(n_estimators=100, random_state=125)
model.fit(X_train,y_train)
model.score(X_test, y_test)
Oldukça iyi bir doğruluk puanı elde ettik.
0.8613035487063481Scikit-learn Boru Hatları Kodu
Her iki eğitim adımını bir ardışık düzende birleştirmek için 'Pipeline' işlevini kullanalım. Daha sonra modeli eğitim setine yerleştirebilir ve test setinde değerlendirebiliriz.
KBest = SelectKBest(chi2, k="all")
model = RandomForestClassifier(n_estimators=100, random_state=125)
train_pipe = Pipeline(
steps=[
("KBest", KBest),
("RFmodel", model),
]
)
train_pipe.fit(X_train,y_train)
train_pipe.score(X_test, y_test)
Benzer sonuçlar elde ettik ancak kod daha verimli ve anlaşılır görünüyor. Eğitim hattına yeni adımlar eklemek veya çıkarmak oldukça kolaydır.
0.8613035487063481
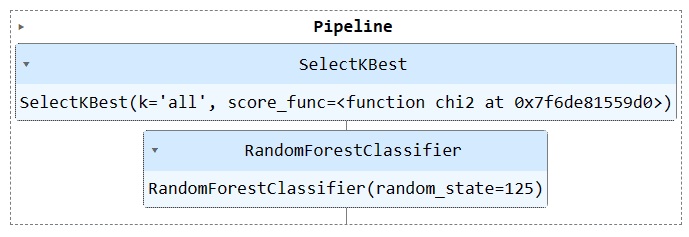
İşlem hattını görselleştirmek için boru hattı nesnesini çalıştırın.
train_pipe
Şimdi, başka bir işlem hattı oluşturup her iki işlem hattını ekleyerek hem ön işleme hem de eğitim işlem hattını birleştireceğiz.
İşte kodun tamamı:
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import OrdinalEncoder, MinMaxScaler
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.feature_selection import SelectKBest, chi2
from sklearn.ensemble import RandomForestClassifier
#loading the data
bank_df = pd.read_csv("train.csv", index_col="id")
bank_df = bank_df.drop(['CustomerId', 'Surname'], axis=1)
bank_df = bank_df.sample(frac=1)
# Splitting data into training and testing sets
X = bank_df.drop(["Exited"],axis=1)
y = bank_df.Exited
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=125
)
# Identify numerical and categorical columns
cat_col = [1,2]
num_col = [0,3,4,5,6,7,8,9]
# Transformers for numerical data
numerical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='mean')),
('scaler', MinMaxScaler())
])
# Transformers for categorical data
categorical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='most_frequent')),
('encoder', OrdinalEncoder())
])
# Combine pipelines using ColumnTransformer
preproc_pipe = ColumnTransformer(
transformers=[
('num', numerical_transformer, num_col),
('cat', categorical_transformer, cat_col)
],
remainder="passthrough"
)
# Selecting the best features
KBest = SelectKBest(chi2, k="all")
# Random Forest Classifier
model = RandomForestClassifier(n_estimators=100, random_state=125)
# KBest and model pipeline
train_pipe = Pipeline(
steps=[
("KBest", KBest),
("RFmodel", model),
]
)
# Combining the preprocessing and training pipelines
complete_pipe = Pipeline(
steps=[
("preprocessor", preproc_pipe),
("train", train_pipe),
]
)
# running the complete pipeline
complete_pipe.fit(X_train,y_train)
# model accuracy
complete_pipe.score(X_test, y_test)
Çıktı:
0.8592837955201874
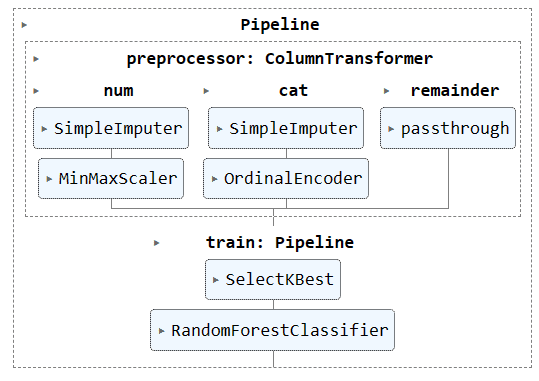
Boru hattının tamamının görselleştirilmesi.
complete_pipe

İşlem hatlarını kullanmanın en büyük avantajlarından biri, işlem hattını modelle birlikte kaydedebilmenizdir. Çıkarım sırasında yalnızca ham verileri işlemeye ve size doğru tahminler sağlamaya hazır olacak boru hattı nesnesini yüklemeniz gerekir. Kutudan çıktığı gibi çalışacağı için uygulama dosyasındaki işleme ve dönüştürme işlevlerini yeniden yazmanıza gerek yoktur. Bu, makine öğrenimi iş akışını daha verimli hale getirir ve zamandan tasarruf sağlar.
İlk önce boru hattını kullanarak kaydedelim. skops-dev/skops kütüphane.
import skops.io as sio
sio.dump(complete_pipe, "bank_pipeline.skops")
Ardından kaydedilen işlem hattını yükleyin ve işlem hattını görüntüleyin.
new_pipe = sio.load("bank_pipeline.skops", trusted=True)
new_pipe
Gördüğünüz gibi boru hattını başarıyla yükledik.
Yüklenen boru hattımızı değerlendirmek için test seti üzerinde tahminler yapacağız ve ardından doğruluğu ve F1 puanlarını hesaplayacağız.
from sklearn.metrics import accuracy_score, f1_score
predictions = new_pipe.predict(X_test)
accuracy = accuracy_score(y_test, predictions)
f1 = f1_score(y_test, predictions, average="macro")
print("Accuracy:", str(round(accuracy, 2) * 100) + "%", "F1:", round(f1, 2))
F1 puanımızı yükseltmek için azınlık sınıflarına odaklanmamız gerektiği ortaya çıktı.
Accuracy: 86.0% F1: 0.76
Proje dosyaları ve kodu şu adreste mevcuttur: Derin Not Çalışma Alanı. Çalışma alanında iki Not Defteri vardır: Biri Scikit-learn işlem hattına sahip, diğeri ise bu olmayan.
Bu eğitimde, Scikit-learn işlem hatlarının, veri dönüşümleri ve modelleri dizilerini birbirine zincirleyerek makine öğrenimi iş akışlarını kolaylaştırmaya nasıl yardımcı olabileceğini öğrendik. Ön işleme ve model eğitimini tek bir Pipeline nesnesinde birleştirerek kodu basitleştirebilir, tutarlı veri dönüşümleri sağlayabilir ve iş akışlarımızı daha organize ve tekrarlanabilir hale getirebiliriz.
Abid Ali Avan (@1abidaliwan), makine öğrenimi modelleri oluşturmayı seven sertifikalı bir veri bilimcisi uzmanıdır. Şu anda, makine öğrenimi ve veri bilimi teknolojileri üzerine içerik oluşturmaya ve teknik bloglar yazmaya odaklanıyor. Abid, Teknoloji Yönetimi alanında yüksek lisans ve Telekomünikasyon Mühendisliği alanında lisans derecesine sahiptir. Vizyonu, akıl hastalığı ile mücadele eden öğrenciler için bir grafik sinir ağı kullanarak bir AI ürünü oluşturmaktır.
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- PlatoData.Network Dikey Üretken Yapay Zeka. Kendine güç ver. Buradan Erişin.
- PlatoAiStream. Web3 Zekası. Bilgi Genişletildi. Buradan Erişin.
- PlatoESG. karbon, temiz teknoloji, Enerji, Çevre, Güneş, Atık Yönetimi. Buradan Erişin.
- PlatoSağlık. Biyoteknoloji ve Klinik Araştırmalar Zekası. Buradan Erişin.
- Kaynak: https://www.kdnuggets.com/streamline-your-machine-learning-workflow-with-scikit-learn-pipelines?utm_source=rss&utm_medium=rss&utm_campaign=streamline-your-machine-learning-workflow-with-scikit-learn-pipelines

