İçindekiler
Bu yazıda, nasıl yapılacağını öğreneceğiz OpenCV kullanarak yüzleri gerçek zamanlı olarak tespit edin. Web kamerası akışından yüzü tespit ettikten sonra yüzün bulunduğu kareleri kaydedeceğiz. Daha sonra bu kareleri (görüntüleri) kişinin maske takıp takmadığını anlamak için maske dedektörü sınıflandırıcımıza ileteceğiz.
Ayrıca kullanarak özel bir maske dedektörünün nasıl yapıldığını da göreceğiz. Tensorflow ve Keras ancak aşağıda indirip kullanabileceğiniz eğitimli model dosyasını ekleyeceğim için bunu atlayabilirsiniz. Ele alacağımız alt konuların listesi:
- Yüz Algılama nedir?
- Yüz Algılama Yöntemleri
- Yüz algılama algoritması
- Yüz tanıma
- Python kullanarak Yüz Algılama
- OpenCV kullanarak Yüz Algılama
- Maske takan yüzleri tanımak için bir model oluşturun (İsteğe bağlı)
- Gerçek Zamanlı Maske tespiti nasıl yapılır?
Ne algılama nedir?
Yüz algılamanın amacı, görüntüde veya videoda herhangi bir yüz olup olmadığını belirlemektir. Birden çok yüz varsa, her yüz bir sınırlayıcı kutuyla çevrelenir ve bu nedenle yüzlerin konumunu biliriz.
Yüz algılama algoritmalarının birincil amacı, bir görüntü veya videodaki yüzlerin varlığını ve konumunu doğru ve verimli bir şekilde belirlemektir. Algoritmalar, yüz özelliklerine karşılık gelen kalıpları ve özellikleri arayarak verilerin görsel içeriğini analiz eder. Yüz algılama algoritmaları, makine öğrenimi, görüntü işleme ve örüntü tanıma gibi çeşitli teknikleri kullanarak, görsel verilerdeki yüzleri diğer nesnelerden veya arka plan öğelerinden ayırmayı amaçlar.
Yüz ifadesi, oryantasyon, aydınlatma koşulları ve güneş gözlüğü, atkı, maske vb. gibi kısmi oklüzyonlar gibi değişebilen birçok değişken olduğundan insan yüzlerini modellemek zordur. örneğin yüzün orta kısmını kaplayan bir dikdörtgen, göz merkezleri veya gözler, burun ve ağız köşeleri, kaşlar, burun delikleri vb.
Yüz Algılama Yöntemleri
Yüz Algılama için iki ana yaklaşım vardır:
- Özellik Tabanlı Yaklaşım
- Görüntü Tabanlı Yaklaşım
Özellik Tabanlı Yaklaşım
Nesneler genellikle benzersiz özellikleriyle tanınır. Bir insan yüzünde, bir yüz ve diğer birçok nesne arasında tanınabilen birçok özellik vardır. Göz, burun, ağız vb. yapısal özellikleri çıkararak yüzleri bulur ve ardından bunları bir yüzü algılamak için kullanır. Tipik olarak, bir tür istatistiksel sınıflandırıcı nitelikli ve daha sonra yüz ve yüz olmayan bölgeleri ayırmaya yardımcı olur. Ek olarak, insan yüzleri, bir yüzü diğer nesneler arasında ayırt etmek için kullanılabilecek özel dokulara sahiptir. Ayrıca, kenarların özellikleri yüzden nesneleri algılamaya yardımcı olabilir. Gelecek bölümde, kullanarak özellik tabanlı bir yaklaşım uygulayacağız. OpenCV eğitimi.
Görüntü Tabanlı Yaklaşım
Genel olarak, Görüntü tabanlı yöntemler, yüz ve yüz olmayan görüntülerin ilgili özelliklerini bulmak için istatistiksel analiz ve makine öğreniminden elde edilen tekniklere dayanır. Öğrenilen özellikler, sonuç olarak yüz algılama için kullanılan dağılım modelleri veya ayırt edici işlevler biçimindedir. Bu yöntemde sinir ağları, HMM gibi farklı algoritmalar kullanıyoruz. SVM, AdaBoost öğrenimi. Gelecek bölümde MTCNN veya Multi-Task Cascaded Convolutional ile yüzleri nasıl tespit edebileceğimizi göreceğiz. Sinir ağıYüz algılamaya yönelik Görüntü tabanlı bir yaklaşım olan
Yüz algılama algoritması
Özellik tabanlı bir yaklaşım kullanan popüler algoritmalardan biri, Viola-Jones algoritması ve burada kısaca tartışacağım. Bunu ayrıntılı olarak öğrenmek istiyorsanız, Viola Jones Algoritmasını Kullanarak Yüz Algılama adlı bu makaleyi incelemenizi öneririm.
Viola-Jones Algoritma, adını 2001 yılında yöntemi öneren iki bilgisayarlı görü araştırmacısından almıştır, Paul. menekşe ve Michael Jones "Artırılmış Basit Özellikler Kaskadını Kullanarak Hızlı Nesne Tespiti" başlıklı makalelerinde. Eski bir çerçeve olmasına rağmen, Viola-Jones oldukça güçlüdür ve uygulamasının gerçek zamanlı yüz algılamada olağanüstü derecede dikkate değer olduğu kanıtlanmıştır. Bu algoritmanın eğitilmesi son derece yavaştır, ancak etkileyici bir hızla gerçek zamanlı olarak yüzleri algılayabilir.
Bir görüntü verildiğinde (bu algoritma gri tonlamalı görüntüler üzerinde çalışır), algoritma birçok küçük alt bölgeye bakar ve her bir alt bölgedeki belirli özellikleri arayarak bir yüz bulmaya çalışır. Bir görüntü çeşitli boyutlarda birçok yüz içerebileceğinden, birçok farklı konumu ve ölçeği kontrol etmesi gerekir. Viola ve Jones, bu algoritmada yüzleri algılamak için Haar benzeri özellikler kullandı.
yüz Tanıma
Yüz algılama ve Yüz Tanıma genellikle birbirinin yerine kullanılır, ancak bunlar oldukça farklıdır. Aslında, Yüz algılama, Yüz Tanıma'nın sadece bir parçasıdır.
Yüz tanıma, bir kişinin yüzünü kullanarak kimliğini belirleme veya doğrulama yöntemidir. Yüz tanıma yapabilen çeşitli algoritmalar vardır ancak doğrulukları değişebilir. Burada derin öğrenmeyi kullanarak yüz tanımayı nasıl yaptığımızı anlatacağım.
Aslında burada, Yüz Tanıma'nın nasıl uygulanacağını gösteren Yüz Tanıma Python adlı bir makale bulunmaktadır.
Python kullanarak Yüz Algılama
Daha önce de belirtildiği gibi, burada Görüntü tabanlı bir yaklaşım kullanarak yüzleri nasıl tespit edebileceğimizi göreceğiz. MTCNN veya Multi-Task Cascaded Convolutional Neural Network, tartışmasız bu prensipte çalışan en popüler ve en doğru yüz algılama araçlarından biridir. Bu itibarla, bir esasa dayanmaktadır. derin öğrenme mimarisi, özellikle bir kademeli olarak bağlı 3 sinir ağından (P-Net, R-Net ve O-Net) oluşur.
Öyleyse, yüzleri gerçek zamanlı olarak algılamak için bu algoritmayı Python'da nasıl kullanabileceğimize bakalım. Öncelikle, yüzleri algılayabilen eğitimli bir model içeren MTCNN kitaplığını kurmanız gerekir.
pip install mtcnnŞimdi MTCNN'nin nasıl kullanılacağına bakalım:
from mtcnn import MTCNN
import cv2
detector = MTCNN()
#Load a videopip TensorFlow
video_capture = cv2.VideoCapture(0) while (True): ret, frame = video_capture.read() frame = cv2.resize(frame, (600, 400)) boxes = detector.detect_faces(frame) if boxes: box = boxes[0]['box'] conf = boxes[0]['confidence'] x, y, w, h = box[0], box[1], box[2], box[3] if conf > 0.5: cv2.rectangle(frame, (x, y), (x + w, y + h), (255, 255, 255), 1) cv2.imshow("Frame", frame) if cv2.waitKey(25) & 0xFF == ord('q'): break video_capture.release()
cv2.destroyAllWindows()
OpenCV kullanarak Yüz Algılama
Bu bölümde gerçek zamanlı olarak gerçekleştireceğiz. OpenCV kullanarak yüz algılama web kameramız üzerinden canlı yayından.
Bildiğiniz gibi videolar temel olarak durağan görüntülerden oluşan çerçevelerden oluşur. Bir videodaki her kare için yüz algılama gerçekleştiriyoruz. Dolayısıyla, hareketsiz bir görüntüde yüz algılama ile gerçek zamanlı bir video akışında yüz algılama söz konusu olduğunda, aralarında pek bir fark yoktur.
Yüzleri algılamak için Voila-Jones algoritması olarak da bilinen Haar Cascade algoritmasını kullanacağız. Temel olarak, bir görüntü veya videodaki nesneleri tanımlamak için kullanılan bir makine öğrenimi nesne algılama algoritmasıdır. OpenCV'de, XML dosyaları olarak kaydedilen birkaç eğitimli Haar Cascade modelimiz var. Modeli sıfırdan oluşturmak ve eğitmek yerine bu dosyayı kullanıyoruz. Bu projede “haarcascade_frontalface_alt2.xml” dosyasını kullanacağız. Şimdi bunu kodlamaya başlayalım
İlk adım, "haarcascade_frontalface_alt2.xml" dosyasının yolunu bulmaktır. Bunu Python dilinin os modülünü kullanarak yapıyoruz.
import os
cascPath = os.path.dirname( cv2.__file__) + "/data/haarcascade_frontalface_alt2.xml"Bir sonraki adım, sınıflandırıcımızı yüklemektir. Yukarıdaki XML dosyasının yolu, OpenCV'nin CascadeClassifier() yöntemine argüman olarak gider.
faceCascade = cv2.CascadeClassifier(cascPath)Sınıflandırıcıyı yükledikten sonra, bu basit OpenCV tek satırlık kodunu kullanarak web kamerasını açalım.
video_capture = cv2.VideoCapture(0)Ardından, web kamerası akışından kareleri almamız gerekiyor, bunu read() işlevini kullanarak yapıyoruz. Akışı kapatmak istediğimiz zamana kadar tüm kareleri almak için sonsuz döngüde kullanırız.
while True: # Capture frame-by-frame ret, frame = video_capture.read()read() işlevi şunu döndürür:
- Okunan gerçek video karesi (her döngüde bir kare)
- Bir dönüş kodu
Dönüş kodu, bir dosyadan okuyorsak olacak olan çerçevelerin bitip bitmediğini bize söyler. Sonsuza kadar kayıt yapabileceğimiz için web kamerasından okurken bunun önemi yok, bu yüzden bunu görmezden geleceğiz.
Bu özel sınıflandırıcının çalışması için çerçeveyi gri tonlamaya dönüştürmemiz gerekiyor.
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)faceCascade nesnesi, argüman olarak bir çerçeve(görüntü) alan ve görüntü üzerinde sınıflandırıcı basamaklamasını çalıştıran bir DetectMultiScale() yöntemine sahiptir. MultiScale terimi, algoritmanın farklı boyutlardaki yüzleri algılamak için görüntünün alt bölgelerine birden çok ölçekte baktığını belirtir.
faces = faceCascade.detectMultiScale(gray, scaleFactor=1.1, minNeighbors=5, minSize=(60, 60), flags=cv2.CASCADE_SCALE_IMAGE)Bu işlevin bu argümanlarını inceleyelim:
- scaleFactor – Her görüntü ölçeğinde görüntü boyutunun ne kadar küçültüleceğini belirten parametre. Girdi görüntüsünü yeniden ölçekleyerek, daha büyük bir yüzü daha küçük bir yüze yeniden boyutlandırabilir ve algoritma tarafından algılanabilir hale getirebilirsiniz. 1.05 bunun için iyi bir olası değerdir, yani yeniden boyutlandırma için küçük bir adım kullanırsınız, yani boyutu %5 oranında küçültürsünüz, tespit için bulunan model ile eşleşen bir boyut şansınızı artırırsınız.
- minNeighbors – Her aday dikdörtgenin onu tutması için kaç komşu olması gerektiğini belirten parametre. Bu parametre, algılanan yüzlerin kalitesini etkileyecektir. Daha yüksek değer, daha az algılamayla ancak daha yüksek kalitede sonuçlanır. 3~6 bunun için iyi bir değerdir.
- bayraklar –Çalışma modu
- minSize – Minimum olası nesne boyutu. Bundan daha küçük nesneler yoksayılır.
Değişken yüzler artık hedef görüntü için tüm algılamaları içerir. Tespitler piksel koordinatları olarak kaydedilir. Her algılama, sol üst köşe koordinatları ve algılanan yüzü çevreleyen dikdörtgenin genişliği ve yüksekliği ile tanımlanır.
Algılanan yüzü göstermek için üzerine bir dikdörtgen çizeceğiz. OpenCV'nin dikdörtgen() işlevi görüntülerin üzerine dikdörtgenler çiziyor ve sol üst ve sağ alt köşelerin piksel koordinatlarını bilmesi gerekiyor. Koordinatlar, görüntüdeki piksellerin satırını ve sütununu gösterir. Bu koordinatları değişken yüzden kolayca alabiliriz.
for (x,y,w,h) in faces: cv2.rectangle(frame, (x, y), (x + w, y + h),(0,255,0), 2)dikdörtgen() aşağıdaki bağımsız değişkenleri kabul eder:
- Orijinal görüntü
- Algılamanın sol üst noktasının koordinatları
- Algılamanın sağ alt noktasının koordinatları
- Dikdörtgenin rengi (kırmızı, yeşil ve mavinin (0-255) miktarını tanımlayan bir tuple). Bizim durumumuzda, yeşil bileşeni 255 olarak ve kalanını sıfır olarak tutarak yeşil olarak ayarladık.
- Dikdörtgen çizgilerin kalınlığı
Sonra, sadece ortaya çıkan kareyi gösteriyoruz ve ayrıca bu sonsuz döngüden çıkmak ve video beslemesini kapatmak için bir yol belirliyoruz. 'q' tuşuna basarak komut dosyasından buradan çıkabiliriz.
cv2.imshow('Video', frame) if cv2.waitKey(1) & 0xFF == ord('q'): breakSonraki iki satır sadece resmi temizlemek ve serbest bırakmak içindir.
video_capture.release()
cv2.destroyAllWindows()İşte tam kod ve çıktı.
import cv2
import os
cascPath = os.path.dirname( cv2.__file__) + "/data/haarcascade_frontalface_alt2.xml"
faceCascade = cv2.CascadeClassifier(cascPath)
video_capture = cv2.VideoCapture(0)
while True: # Capture frame-by-frame ret, frame = video_capture.read() gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) faces = faceCascade.detectMultiScale(gray, scaleFactor=1.1, minNeighbors=5, minSize=(60, 60), flags=cv2.CASCADE_SCALE_IMAGE) for (x,y,w,h) in faces: cv2.rectangle(frame, (x, y), (x + w, y + h),(0,255,0), 2) # Display the resulting frame cv2.imshow('Video', frame) if cv2.waitKey(1) & 0xFF == ord('q'): break
video_capture.release()
cv2.destroyAllWindows()
Çıktı:
Maske takan yüzleri tanımak için bir model oluşturun
Bu bölümde, yüzleri maskeli ve maskesiz olarak ayırt edebilen bir sınıflandırıcı yapacağız. Bu kısmı atlamak isterseniz, işte bir Link önceden eğitilmiş modeli indirmek için. Onu kaydedin ve OpenCV kullanarak maskeleri algılamak için nasıl kullanılacağını öğrenmek için bir sonraki bölüme geçin. koleksiyonumuza göz atın OpenCV kursları becerilerinizi geliştirmenize ve daha iyi anlamanıza yardımcı olmak için.
Dolayısıyla, bu sınıflandırıcıyı oluşturmak için Görüntüler biçimindeki verilere ihtiyacımız var. Neyse ki maskeli ve maskesiz yüz resimleri içeren bir veri setimiz var. Bu görüntülerin sayısı çok az olduğu için bir sinir ağını sıfırdan eğitemeyiz. Bunun yerine, Imagenet veri kümesi üzerinde eğitilmiş MobileNetV2 adlı önceden eğitilmiş bir ağın ince ayarını yapıyoruz.
Önce ihtiyacımız olacak tüm gerekli kütüphaneleri içe aktaralım.
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.applications import MobileNetV2
from tensorflow.keras.layers import AveragePooling2D
from tensorflow.keras.layers import Dropout
from tensorflow.keras.layers import Flatten
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import Input
from tensorflow.keras.models import Model
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.applications.mobilenet_v2 import preprocess_input
from tensorflow.keras.preprocessing.image import img_to_array
from tensorflow.keras.preprocessing.image import load_img
from tensorflow.keras.utils import to_categorical
from sklearn.preprocessing import LabelBinarizer
from sklearn.model_selection import train_test_split
from imutils import paths
import matplotlib.pyplot as plt
import numpy as np
import osBir sonraki adım, tüm görüntüleri okumak ve onları bir listeye atamaktır. Burada, bu görüntülerle ilişkili tüm yolları alıyoruz ve ardından bunları buna göre etiketliyoruz. Veri setimizin maskeli ve maskesiz olmak üzere iki klasörde bulunduğunu unutmayın. Böylece klasör adını yoldan çıkararak etiketleri kolayca alabiliriz. Ayrıca görüntüyü önceden işliyoruz ve 224x 224 boyutlarında yeniden boyutlandırıyoruz.
imagePaths = list(paths.list_images('/content/drive/My Drive/dataset'))
data = []
labels = []
# loop over the image paths
for imagePath in imagePaths: # extract the class label from the filename label = imagePath.split(os.path.sep)[-2] # load the input image (224x224) and preprocess it image = load_img(imagePath, target_size=(224, 224)) image = img_to_array(image) image = preprocess_input(image) # update the data and labels lists, respectively data.append(image) labels.append(label)
# convert the data and labels to NumPy arrays
data = np.array(data, dtype="float32")
labels = np.array(labels)Bir sonraki adım, önceden eğitilmiş modeli yüklemek ve problemimize göre özelleştirmek. Bu yüzden, bu önceden eğitilmiş modelin üst katmanlarını kaldırıyoruz ve kendimize ait birkaç katman ekliyoruz. Gördüğünüz gibi son katmanda iki düğüm var, çünkü sadece iki çıkışımız var. Buna transfer öğrenme denir.
baseModel = MobileNetV2(weights="imagenet", include_top=False, input_shape=(224, 224, 3))
# construct the head of the model that will be placed on top of the
# the base model
headModel = baseModel.output
headModel = AveragePooling2D(pool_size=(7, 7))(headModel)
headModel = Flatten(name="flatten")(headModel)
headModel = Dense(128, activation="relu")(headModel)
headModel = Dropout(0.5)(headModel)
headModel = Dense(2, activation="softmax")(headModel) # place the head FC model on top of the base model (this will become
# the actual model we will train)
model = Model(inputs=baseModel.input, outputs=headModel)
# loop over all layers in the base model and freeze them so they will
# *not* be updated during the first training process
for layer in baseModel.layers: layer.trainable = FalseŞimdi etiketleri one-hot kodlamaya dönüştürmemiz gerekiyor. Bundan sonra, verileri değerlendirmek için eğitim ve test kümelerine ayırıyoruz. Ayrıca bir sonraki adım, fiilen yeni veri toplamadan eğitim modelleri için mevcut veri çeşitliliğini önemli ölçüde artıran veri artırmadır. Kırpma, döndürme, kesme ve yatay çevirme gibi veri artırma teknikleri, büyük sinir ağlarını eğitmek için yaygın olarak kullanılır.
lb = LabelBinarizer()
labels = lb.fit_transform(labels)
labels = to_categorical(labels)
# partition the data into training and testing splits using 80% of
# the data for training and the remaining 20% for testing
(trainX, testX, trainY, testY) = train_test_split(data, labels, test_size=0.20, stratify=labels, random_state=42)
# construct the training image generator for data augmentation
aug = ImageDataGenerator( rotation_range=20, zoom_range=0.15, width_shift_range=0.2, height_shift_range=0.2, shear_range=0.15, horizontal_flip=True, fill_mode="nearest")Bir sonraki adım, modeli derlemek ve artırılmış veriler üzerinde eğitmektir.
INIT_LR = 1e-4
EPOCHS = 20
BS = 32
print("[INFO] compiling model...")
opt = Adam(lr=INIT_LR, decay=INIT_LR / EPOCHS)
model.compile(loss="binary_crossentropy", optimizer=opt, metrics=["accuracy"])
# train the head of the network
print("[INFO] training head...")
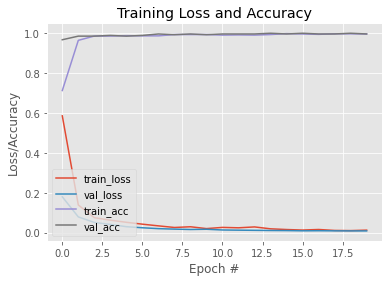
H = model.fit( aug.flow(trainX, trainY, batch_size=BS), steps_per_epoch=len(trainX) // BS, validation_data=(testX, testY), validation_steps=len(testX) // BS, epochs=EPOCHS)Artık modelimiz eğitildiğine göre, öğrenme eğrisini görmek için bir grafik çizelim. Ayrıca, modeli daha sonra kullanmak üzere kaydediyoruz. Burada bir Link bu eğitimli modele.
N = EPOCHS
plt.style.use("ggplot")
plt.figure()
plt.plot(np.arange(0, N), H.history["loss"], label="train_loss")
plt.plot(np.arange(0, N), H.history["val_loss"], label="val_loss")
plt.plot(np.arange(0, N), H.history["accuracy"], label="train_acc")
plt.plot(np.arange(0, N), H.history["val_accuracy"], label="val_acc")
plt.title("Training Loss and Accuracy")
plt.xlabel("Epoch #")
plt.ylabel("Loss/Accuracy")
plt.legend(loc="lower left")Çıktı:
#To save the trained model
model.save('mask_recog_ver2.h5')Gerçek Zamanlı Maske tespiti nasıl yapılır?
Bir sonraki bölüme geçmeden önce yukarıdaki modeli buradan indirdiğinizden emin olun. Link ve aşağıdaki kodu yazacağınız python betiği ile aynı klasöre yerleştirin.
Artık modelimiz eğitildiğine göre, ilk bölümdeki kodu değiştirerek yüzleri algılayabilir ve ayrıca kişinin maske takıp takmadığını bize söyleyebilir.
Maske dedektörü modelimizin çalışabilmesi için yüz görüntülerine ihtiyacı vardır. Bunun için yüzleri olan çerçeveleri ilk bölümde gösterdiğimiz yöntemlerle tespit edip önişlemlerden geçirdikten sonra modelimize aktaracağız. Öyleyse önce ihtiyacımız olan tüm kütüphaneleri içe aktaralım.
import cv2
import os
from tensorflow.keras.preprocessing.image import img_to_array
from tensorflow.keras.models import load_model
from tensorflow.keras.applications.mobilenet_v2 import preprocess_input
import numpy as npİlk birkaç satır, ilk bölümle tamamen aynı. Farklı olan tek şey, önceden eğitilmiş maske dedektörü modelimizi değişken modele atamış olmamızdır.
ascPath = os.path.dirname( cv2.__file__) + "/data/haarcascade_frontalface_alt2.xml"
faceCascade = cv2.CascadeClassifier(cascPath)
model = load_model("mask_recog1.h5") video_capture = cv2.VideoCapture(0)
while True: # Capture frame-by-frame ret, frame = video_capture.read() gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) faces = faceCascade.detectMultiScale(gray, scaleFactor=1.1, minNeighbors=5, minSize=(60, 60), flags=cv2.CASCADE_SCALE_IMAGE)Ardından, bazı listeler tanımlıyoruz. faces_list, faceCascade modeli tarafından algılanan tüm yüzleri içerir ve pres listesi, maske detektörü modeli tarafından yapılan tahminleri depolamak için kullanılır.
faces_list=[]
preds=[]Ayrıca yüzler değişkeni, yüzleri çevreleyen dikdörtgenin sol üst köşe koordinatlarını, yüksekliğini ve genişliğini içerdiğinden, bunu yüzün bir çerçevesini elde etmek için kullanabilir ve ardından bu çerçeveyi tahmin için modele beslenebilmesi için önceden işleyebiliriz. . Ön işleme adımları, ikinci bölümde model eğitilirken izlenen adımlarla aynıdır. Örneğin, model RGB görüntüleri üzerinde eğitildiğinden burada görüntüyü RGB'ye dönüştürüyoruz.
for (x, y, w, h) in faces: face_frame = frame[y:y+h,x:x+w] face_frame = cv2.cvtColor(face_frame, cv2.COLOR_BGR2RGB) face_frame = cv2.resize(face_frame, (224, 224)) face_frame = img_to_array(face_frame) face_frame = np.expand_dims(face_frame, axis=0) face_frame = preprocess_input(face_frame) faces_list.append(face_frame) if len(faces_list)>0: preds = model.predict(faces_list) for pred in preds: #mask contain probabily of wearing a mask and vice versa (mask, withoutMask) = pred Tahminleri aldıktan sonra yüze bir dikdörtgen çizip tahminlere göre etiket koyuyoruz.
label = "Mask" if mask > withoutMask else "No Mask" color = (0, 255, 0) if label == "Mask" else (0, 0, 255) label = "{}: {:.2f}%".format(label, max(mask, withoutMask) * 100) cv2.putText(frame, label, (x, y- 10), cv2.FONT_HERSHEY_SIMPLEX, 0.45, color, 2) cv2.rectangle(frame, (x, y), (x + w, y + h),color, 2)Adımların geri kalanı ilk bölümle aynıdır.
cv2.imshow('Video', frame) if cv2.waitKey(1) & 0xFF == ord('q'): break
video_capture.release()
cv2.destroyAllWindows()İşte tam kod ve çıktı:
import cv2
import os
from tensorflow.keras.preprocessing.image import img_to_array
from tensorflow.keras.models import load_model
from tensorflow.keras.applications.mobilenet_v2 import preprocess_input
import numpy as np cascPath = os.path.dirname( cv2.__file__) + "/data/haarcascade_frontalface_alt2.xml"
faceCascade = cv2.CascadeClassifier(cascPath)
model = load_model("mask_recog1.h5") video_capture = cv2.VideoCapture(0)
while True: # Capture frame-by-frame ret, frame = video_capture.read() gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) faces = faceCascade.detectMultiScale(gray, scaleFactor=1.1, minNeighbors=5, minSize=(60, 60), flags=cv2.CASCADE_SCALE_IMAGE) faces_list=[] preds=[] for (x, y, w, h) in faces: face_frame = frame[y:y+h,x:x+w] face_frame = cv2.cvtColor(face_frame, cv2.COLOR_BGR2RGB) face_frame = cv2.resize(face_frame, (224, 224)) face_frame = img_to_array(face_frame) face_frame = np.expand_dims(face_frame, axis=0) face_frame = preprocess_input(face_frame) faces_list.append(face_frame) if len(faces_list)>0: preds = model.predict(faces_list) for pred in preds: (mask, withoutMask) = pred label = "Mask" if mask > withoutMask else "No Mask" color = (0, 255, 0) if label == "Mask" else (0, 0, 255) label = "{}: {:.2f}%".format(label, max(mask, withoutMask) * 100) cv2.putText(frame, label, (x, y- 10), cv2.FONT_HERSHEY_SIMPLEX, 0.45, color, 2) cv2.rectangle(frame, (x, y), (x + w, y + h),color, 2) # Display the resulting frame cv2.imshow('Video', frame) if cv2.waitKey(1) & 0xFF == ord('q'): break
video_capture.release()
cv2.destroyAllWindows()
Çıktı:
Bu da bizi yüzleri gerçek zamanlı olarak nasıl algılayacağımızı öğrendiğimiz ve ayrıca maskelerle yüzleri algılayabilen bir model tasarladığımız bu makalenin sonuna getiriyor. Bu modeli kullanarak yüz dedektörünü maske dedektörüne değiştirebildik.
Güncelleme: Görüntüleri maske takmak, maske takmamak ve uygun şekilde maske takmamak şeklinde sınıflandırabilen başka bir model eğittim. İşte bir bağlantı Kaggle dizüstü bilgisayar bu modelin Üzerinde değişiklik yapabilir ve ayrıca buradan modeli indirebilir ve bu yazıda eğittiğimiz model yerine kullanabilirsiniz. Bu model burada eğittiğimiz model kadar verimli olmasa da fazladan düzgün takılmamış maskeleri tespit etme özelliği var.
Bu modeli kullanıyorsanız, kodda bazı küçük değişiklikler yapmanız gerekir. Önceki satırları bu satırlarla değiştirin.
#Here are some minor changes in opencv code
for (box, pred) in zip(locs, preds): # unpack the bounding box and predictions (startX, startY, endX, endY) = box (mask, withoutMask,notproper) = pred # determine the class label and color we'll use to draw # the bounding box and text if (mask > withoutMask and mask>notproper): label = "Without Mask" elif ( withoutMask > notproper and withoutMask > mask): label = "Mask" else: label = "Wear Mask Properly" if label == "Mask": color = (0, 255, 0) elif label=="Without Mask": color = (0, 0, 255) else: color = (255, 140, 0) # include the probability in the label label = "{}: {:.2f}%".format(label, max(mask, withoutMask, notproper) * 100) # display the label and bounding box rectangle on the output # frame cv2.putText(frame, label, (startX, startY - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.45, color, 2) cv2.rectangle(frame, (startX, startY), (endX, endY), color, 2)Great Learning'lerle de becerilerinizi geliştirebilirsiniz. PGP Yapay Zeka ve Makine Öğrenimi Kursu. Kurs, endüstri liderlerinden mentorluk sunar ve ayrıca sektörle ilgili gerçek zamanlı projeler üzerinde çalışma fırsatına sahip olursunuz.
Daha fazla Okuma
- TensorFlow Kullanarak Gerçek Zamanlı Nesne Algılama
- OpenCV kullanarak YOLO nesne algılama
- Pytorch'ta Nesne Algılama | Nesne Algılama nedir?
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- EVM Finans. Merkezi Olmayan Finans için Birleşik Arayüz. Buradan Erişin.
- Kuantum Medya Grubu. IR/PR Güçlendirilmiş. Buradan Erişin.
- PlatoAiStream. Web3 Veri Zekası. Bilgi Genişletildi. Buradan Erişin.
- Kaynak: https://www.mygreatlearning.com/blog/real-time-face-detection/

