
Yazara göre resim
Dünyanın önde gelen yapay zeka araştırma şirketlerinden biri olan Mistral AI, yakın zamanda temel modeli yayınladı. Mistral 7B v0.2.
Bu açık kaynaklı dil modeli, şirketin 23 Mart 2024'teki hackathon etkinliği sırasında tanıtıldı.
Mistral 7B modelleri 7.3 milyar parametreye sahiptir ve bu da onları son derece güçlü kılmaktadır. Neredeyse tüm kıyaslamalarda Llama 2 13B ve Llama 1 34B'den daha iyi performans gösteriyorlar. En yeni V0.2 modeli, diğer gelişmelerin yanı sıra 32k'lik bir bağlam penceresi sunarak metin işleme ve oluşturma yeteneğini geliştiriyor.
Ayrıca yakın zamanda duyurulan sürüm, geçen yılın başlarında piyasaya sürülen "Mistral-7B-Instruct-V0.2" adlı talimat ayarlı varyantın temel modelidir.
Bu eğitimde size Hugging Face'te bu dil modeline nasıl erişeceğinizi ve ince ayar yapacağınızı göstereceğim.
Hugging Face'in AutoTrain işlevini kullanarak Mistral 7B-v0.2 temel modeline ince ayar yapacağız.
Sarılma Yüz makine öğrenimi modellerine erişimi demokratikleştirmesi ve sıradan kullanıcıların gelişmiş yapay zeka çözümleri geliştirmesine olanak sağlamasıyla ünlüdür.
Hugging Face'in bir özelliği olan AutoTrain, model eğitimi sürecini otomatikleştirerek onu erişilebilir ve verimli hale getirir.
Aksi takdirde göz korkutucu ve zaman alıcı olabilecek bir görev olan modellerde ince ayar yaparken kullanıcıların en iyi parametreleri ve eğitim tekniklerini seçmelerine yardımcı olur.
Mistral-5B modelinize ince ayar yapmak için 7 adım:
1. Ortamın ayarlanması
Öncelikle Hugging Face ile bir hesap oluşturmalı, ardından bir model deposu oluşturmalısınız.
Bunu başarmak için bu kılavuzda verilen adımları uygulamanız yeterlidir. Link ve bu eğitime geri dönün.
Modeli Python'da eğiteceğiz. Eğitim için bir dizüstü bilgisayar ortamı seçmeye gelince şunları kullanabilirsiniz: Kaggle Defterleri or Google İşbirliğiher ikisi de GPU'lara ücretsiz erişim sağlar.
Eğitim süreci çok uzun sürüyorsa AWS Sagemaker veya Azure ML gibi bir bulut platformuna geçmek isteyebilirsiniz.
Son olarak, bu eğitimde kodlamaya başlamadan önce aşağıdaki pip kurulumlarını gerçekleştirin:
!pip install -U autotrain-advanced
!pip install datasets transformers2. Veri kümenizi hazırlamak
Bu derste kullanacağımız Alpaka veri kümesi Hugging Face'te şuna benziyor:
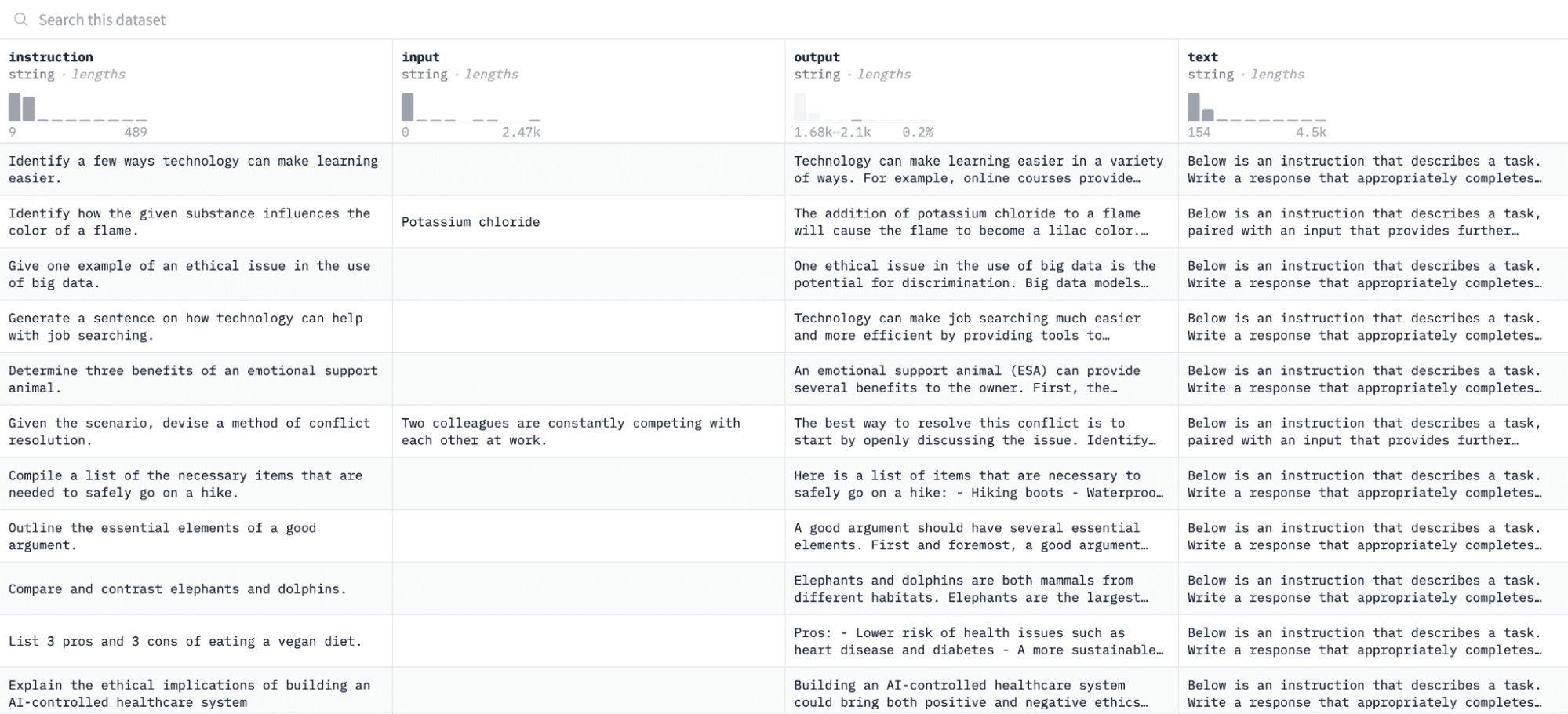
Modele talimat ve çıktı çiftleri üzerinde ince ayar yapacağız ve değerlendirme sürecinde verilen talimata yanıt verme yeteneğini değerlendireceğiz.
Bu veri kümesine erişmek ve hazırlamak için aşağıdaki kod satırlarını çalıştırın:
import pandas as pd
from datasets import load_dataset
# Load and preprocess dataset
def preprocess_dataset(dataset_name, split_ratio='train[:10%]', input_col='input', output_col='output'):
dataset = load_dataset(dataset_name, split=split_ratio)
df = pd.DataFrame(dataset)
chat_df = df[df[input_col] == ''].reset_index(drop=True)
return chat_df
# Formatting according to AutoTrain requirements
def format_interaction(row):
formatted_text = f"[Begin] {row['instruction']} [End] {row['output']} [Close]"
return formatted_text
# Process and save the dataset
if __name__ == "__main__":
dataset_name = "tatsu-lab/alpaca"
processed_data = preprocess_dataset(dataset_name)
processed_data['formatted_text'] = processed_data.apply(format_interaction, axis=1)
save_path = 'formatted_data/training_dataset'
os.makedirs(save_path, exist_ok=True)
file_path = os.path.join(save_path, 'formatted_train.csv')
processed_data[['formatted_text']].to_csv(file_path, index=False)
print("Dataset formatted and saved.")İlk işlev, "veri kümeleri" kitaplığını kullanarak Alpaka veri kümesini yükleyecek ve herhangi bir boş talimat eklemediğimizden emin olmak için onu temizleyecektir. İkinci işlev, verilerinizi AutoTrain'in anlayabileceği bir biçimde yapılandırır.
Yukarıdaki kodu çalıştırdıktan sonra veri kümesi yüklenecek, biçimlendirilecek ve belirtilen yola kaydedilecektir. Biçimlendirilmiş veri kümenizi açtığınızda "biçimlendirilmiş_metin" etiketli tek bir sütun görmelisiniz.
3. Eğitim ortamınızı ayarlama
Artık veri kümesini başarıyla hazırladığınıza göre model eğitim ortamınızı kurmaya devam edelim.
Bunu yapmak için aşağıdaki parametreleri tanımlamanız gerekir:
project_name = 'mistralai'
model_name = 'alpindale/Mistral-7B-v0.2-hf'
push_to_hub = True
hf_token = 'your_token_here'
repo_id = 'your_repo_here.'Yukarıdaki spesifikasyonların bir dökümü aşağıda verilmiştir:
- Herhangi birini belirtebilirsiniz proje Adı. Burası tüm proje ve eğitim dosyalarınızın saklanacağı yerdir.
- The model adı parametre, ince ayar yapmak istediğiniz modeldir. Bu durumda, bir yol belirledim. Mistral-7B v0.2 temel modeli Sarılma Yüzünde.
- The hf_token değişkeni, şuraya giderek elde edebileceğiniz Hugging Face jetonunuza ayarlanmalıdır. Bu bağlantıyı.
- repo_id bu eğitimin ilk adımında oluşturduğunuz Hugging Face model deposuna ayarlanmalıdır. Örneğin, depo kimliğim NatasshaS/Model2.
4. Model parametrelerini yapılandırma
Modelimize ince ayar yapmadan önce, model davranışının eğitim süresi ve düzenleme gibi yönlerini kontrol eden eğitim parametrelerini tanımlamalıyız.
Bu parametreler, modelin ne kadar süre eğitim aldığı, verilerden nasıl öğrendiği ve aşırı uyumdan nasıl kaçındığı gibi temel hususları etkiler.
Modeliniz için aşağıdaki parametreleri ayarlayabilirsiniz:
use_fp16 = True
use_peft = True
use_int4 = True
learning_rate = 1e-4
num_epochs = 3
batch_size = 4
block_size = 512
warmup_ratio = 0.05
weight_decay = 0.005
lora_r = 8
lora_alpha = 16
lora_dropout = 0.015. Ortam değişkenlerini ayarlama
Şimdi bazı ortam değişkenlerini ayarlayarak eğitim ortamımızı hazırlayalım.
Bu adım, AutoTrain özelliğinin modele ince ayar yapmak için proje adımız ve eğitim tercihlerimiz gibi istenen ayarları kullanmasını sağlar:
os.environ["PROJECT_NAME"] = project_name
os.environ["MODEL_NAME"] = model_name
os.environ["LEARNING_RATE"] = str(learning_rate)
os.environ["NUM_EPOCHS"] = str(num_epochs)
os.environ["BATCH_SIZE"] = str(batch_size)
os.environ["BLOCK_SIZE"] = str(block_size)
os.environ["WARMUP_RATIO"] = str(warmup_ratio)
os.environ["WEIGHT_DECAY"] = str(weight_decay)
os.environ["USE_FP16"] = str(use_fp16)
os.environ["LORA_R"] = str(lora_r)
os.environ["LORA_ALPHA"] = str(lora_alpha)
os.environ["LORA_DROPOUT"] = str(lora_dropout)6. Model eğitimini başlatın
Son olarak modeli kullanarak eğitime başlayalım. otomatik tren emretmek. Bu adım, aşağıda gösterildiği gibi modelinizi, veri kümenizi ve eğitim yapılandırmalarınızı belirtmeyi içerir:
!autotrain llm
--train
--model "${MODEL_NAME}"
--project-name "${PROJECT_NAME}"
--data-path "formatted_data/training_dataset/"
--text-column "formatted_text"
--lr "${LEARNING_RATE}"
--batch-size "${BATCH_SIZE}"
--epochs "${NUM_EPOCHS}"
--block-size "${BLOCK_SIZE}"
--warmup-ratio "${WARMUP_RATIO}"
--lora-r "${LORA_R}"
--lora-alpha "${LORA_ALPHA}"
--lora-dropout "${LORA_DROPOUT}"
--weight-decay "${WEIGHT_DECAY}"
$( [[ "$USE_FP16" == "True" ]] && echo "--mixed-precision fp16" )
$( [[ "$USE_PEFT" == "True" ]] && echo "--use-peft" )
$( [[ "$USE_INT4" == "True" ]] && echo "--quantization int4" )
$( [[ "$PUSH_TO_HUB" == "True" ]] && echo "--push-to-hub --token ${HF_TOKEN} --repo-id ${REPO_ID}" )Değiştirdiğinizden emin olun. veri yolu eğitim veri kümenizin bulunduğu yere.
7. Modelin değerlendirilmesi
Modelinizin eğitimi bittiğinde dizininizde proje adınızla aynı adı taşıyan bir klasörün göründüğünü görmelisiniz.
Benim durumumda bu klasörün başlığı “mistralai” aşağıdaki resimde görüldüğü gibi:
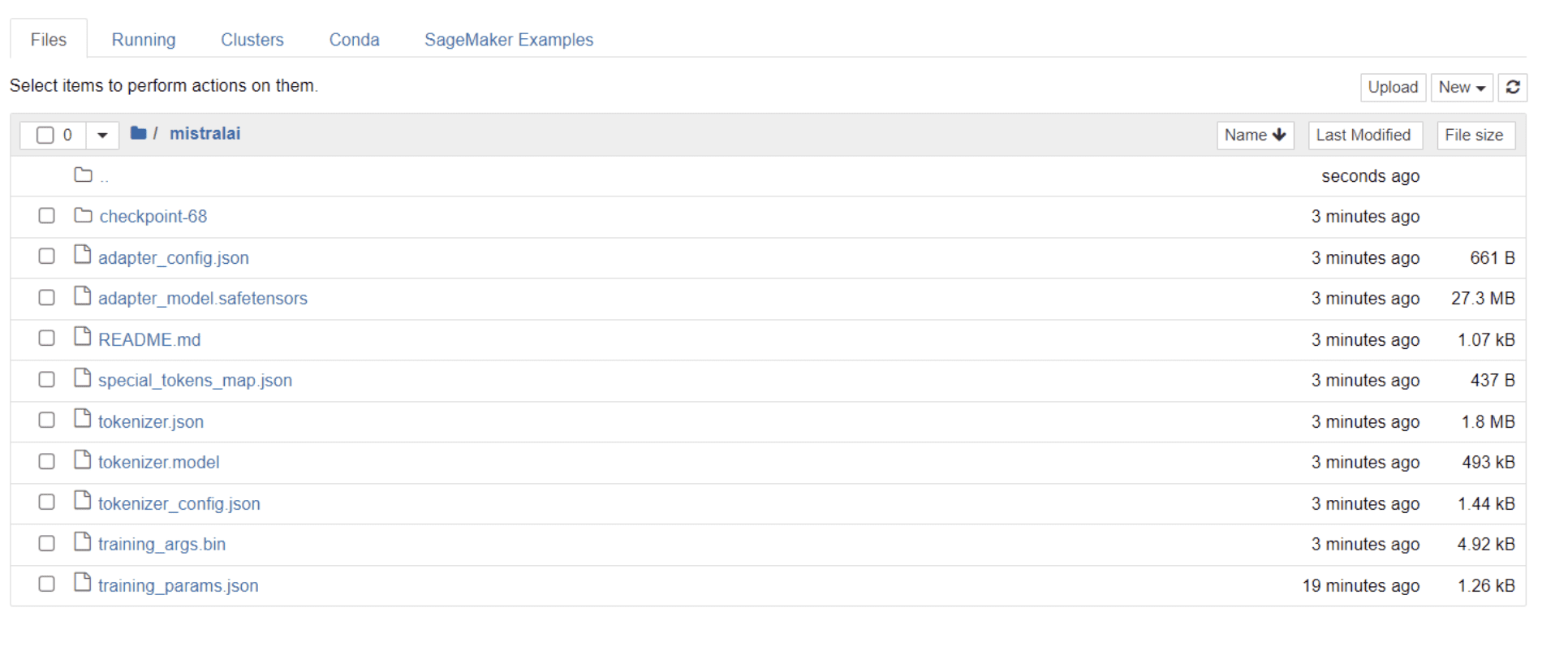
Bu klasörde model ağırlıklarınızı, hiperparametrelerinizi ve mimari ayrıntılarınızı içeren dosyaları bulabilirsiniz.
Şimdi bu ince ayarlı modelin veri setimizdeki bir soruya doğru yanıt verip vermediğini kontrol edelim. Bunu başarmak için öncelikle veri kümemizden 5 örnek giriş ve çıkış oluşturmak üzere aşağıdaki kod satırlarını çalıştırmamız gerekir:
# Print out 5 sample inputs and outputs from our dataset
for i, example in enumerate(dataset):
if i >= 5:
break
print(f"Instruction: {example['instruction']}")
print(f"Output: {example['output']}n---")5 örnek veri noktasını gösteren şuna benzer bir yanıt görmelisiniz:
Instruction: Give three tips for staying healthy.
Output: 1.Eat a balanced diet and make sure to include plenty of fruits and vegetables.
2. Exercise regularly to keep your body active and strong.
3. Get enough sleep and maintain a consistent sleep schedule.
---
Instruction: What are the three primary colors?
Output: The three primary colors are red, blue, and yellow.
---
Instruction: Describe the structure of an atom.
Output: An atom is made up of a nucleus, which contains protons and neutrons, surrounded by electrons that travel in orbits around the nucleus. The protons and neutrons have a positive charge, while the electrons have a negative charge, resulting in an overall neutral atom. The number of each particle determines the atomic number and the type of atom.
---
Instruction: How can we reduce air pollution?
Output: There are a number of ways to reduce air pollution, such as shifting to renewable energy sources, encouraging the use of public transportation, prohibiting the burning of fossil fuels, implementing policies to reduce emissions from industrial sources, and implementing vehicle emissions standards. Additionally, individuals can do their part to reduce air pollution by reducing car use, avoiding burning materials such as wood, and changing to energy efficient appliances.
---
Instruction: Describe a time when you had to make a difficult decision.
Output: I had to make a difficult decision when I was working as a project manager at a construction company. I was in charge of a project that needed to be completed by a certain date in order to meet the client's expectations. However, due to unexpected delays, we were not able to meet the deadline and so I had to make a difficult decision. I decided to extend the deadline, but I had to stretch the team's resources even further and increase the budget. Although it was a risky decision, I ultimately decided to go ahead with it to ensure that the project was completed on time and that the client's expectations were met. The project was eventually successfully completed and this was seen as a testament to my leadership and decision-making abilities.Yukarıdaki talimatlardan birini modele yazacağız ve doğru çıktı üretip üretmediğini kontrol edeceğiz. Modele bir talimat sağlayan ve ondan yanıt alan bir fonksiyon:
# Function to provide an instruction
def ask(model, tokenizer, question, max_length=128):
inputs = tokenizer.encode(question, return_tensors='pt')
outputs = model.generate(inputs, max_length=max_length, num_return_sequences=1)
answer = tokenizer.decode(outputs[0], skip_special_tokens=True)
return answerSon olarak, bu fonksiyona aşağıda gösterildiği gibi bir soru girin:
question = "Describe a time when you had to make a difficult decision."
answer = ask(model, tokenizer, question)
print(answer)Modeliniz, aşağıda gösterildiği gibi, eğitim veri kümesindeki karşılık gelen çıktısıyla aynı olan bir yanıt oluşturmalıdır:
Describe a time when you had to make a difficult decision.
What did you do? How did it turn out?
[/INST] I remember a time when I had to make a difficult decision about
my career. I had been working in the same job for several years and had
grown tired of it. I knew that I needed to make a change, but I was unsure of what to do. I weighed my options carefully and eventually decided to take a leap of faith and start my own business. It was a risky move, but it paid off in the end. I am now the owner of a successful business andBelirttiğimiz belirteçlerin sayısı nedeniyle yanıtın eksik veya kesik görünebileceğini lütfen unutmayın. Daha kapsamlı bir yanıta izin vermek için "max_length" değerini ayarlamaktan çekinmeyin.
Buraya kadar geldiyseniz tebrikler!
Hugging Face'in yeteneklerinin yanı sıra Mistral 7B v-0.2'nin gücünden de yararlanarak son teknoloji ürünü bir dil modeline başarıyla ince ayar yaptınız.
Ancak yolculuk burada bitmiyor.
Bir sonraki adım olarak, model performansını optimize etmek için farklı veri kümeleriyle denemeler yapmanızı veya belirli eğitim parametrelerinde ince ayarlamalar yapmanızı öneririm. Modellere daha büyük ölçekte ince ayar yapmak, faydalarını artıracaktır; bu nedenle, daha büyük veri kümeleriyle veya PDF'ler ve metin dosyaları gibi farklı formatlarla denemeler yapmayı deneyin.
Bu tür deneyimler, organizasyonlarda genellikle karmaşık ve yapılandırılmamış olan gerçek dünya verileriyle çalışırken çok değerli hale gelir.
Nataşa Selvaraj yazma tutkusu olan, kendi kendini yetiştirmiş bir veri bilimcidir. Natassha, veri bilimiyle ilgili her şey hakkında yazıyor ve tüm veri konularının gerçek ustası. Onunla bağlantı kurabilirsin LinkedIn veya ona bak YouTube kanalı.
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- PlatoData.Network Dikey Üretken Yapay Zeka. Kendine güç ver. Buradan Erişin.
- PlatoAiStream. Web3 Zekası. Bilgi Genişletildi. Buradan Erişin.
- PlatoESG. karbon, temiz teknoloji, Enerji, Çevre, Güneş, Atık Yönetimi. Buradan Erişin.
- PlatoSağlık. Biyoteknoloji ve Klinik Araştırmalar Zekası. Buradan Erişin.
- Kaynak: https://www.kdnuggets.com/mistral-7b-v02-fine-tuning-mistral-new-open-source-llm-with-hugging-face?utm_source=rss&utm_medium=rss&utm_campaign=mistral-7b-v0-2-fine-tuning-mistrals-new-open-source-llm-with-hugging-face

