Onun çekirdeğinde, Dil Zinciri dil modellerinin yeteneklerinden yararlanan uygulamalar hazırlamak için tasarlanmış yenilikçi bir çerçevedir. Geliştiricilerin bağlam bilincine sahip ve karmaşık akıl yürütme yeteneğine sahip uygulamalar oluşturmaları için tasarlanmış bir araç setidir.
Bu, LangChain uygulamalarının hızlı talimatlar veya içerik temelli yanıtlar gibi bağlamı anlayabildiği ve nasıl yanıt vereceğine veya hangi eylemlerin gerçekleştirileceğine karar vermek gibi karmaşık akıl yürütme görevleri için dil modellerini kullanabileceği anlamına gelir. LangChain, çeşitli bileşenleriyle konseptten uygulamaya kadar olan yolculuğu basitleştirerek akıllı uygulamalar geliştirmeye yönelik birleşik bir yaklaşımı temsil eder.
LangChain'i Anlamak
LangChain bir çerçeveden çok daha fazlasıdır; birçok ayrılmaz parçadan oluşan tam teşekküllü bir ekosistemdir.
- İlk olarak, hem Python hem de JavaScript'te mevcut olan LangChain Kütüphaneleri vardır. Bu kütüphaneler LangChain'in omurgasını oluşturur ve çeşitli bileşenler için arayüzler ve entegrasyonlar sunar. Bu bileşenleri uyumlu zincirler ve aracılar halinde birleştirmek için temel bir çalışma süresinin yanı sıra anında kullanıma hazır uygulamalar sağlarlar.
- Daha sonra LangChain Şablonlarımız var. Bunlar, çok çeşitli görevler için özel olarak tasarlanmış konuşlandırılabilir referans mimarilerinin bir koleksiyonudur. İster bir sohbet robotu ister karmaşık bir analitik araç oluşturuyor olun, bu şablonlar sağlam bir başlangıç noktası sunar.
- LangServe, LangChain zincirlerini REST API'leri olarak dağıtmak için çok yönlü bir kitaplık olarak devreye giriyor. Bu araç, LangChain projelerinizi erişilebilir ve ölçeklenebilir web hizmetlerine dönüştürmek için gereklidir.
- Son olarak LangSmith geliştirici platformu olarak hizmet veriyor. Herhangi bir LLM çerçevesinde oluşturulmuş zincirlerde hata ayıklamak, test etmek, değerlendirmek ve izlemek için tasarlanmıştır. LangChain ile kusursuz entegrasyon, onu uygulamalarını iyileştirmeyi ve mükemmelleştirmeyi amaçlayan geliştiriciler için vazgeçilmez bir araç haline getiriyor.
Bu bileşenler birlikte uygulamaları kolaylıkla geliştirmenize, üretmenize ve dağıtmanıza olanak tanır. LangChain ile, rehberlik için şablonlara başvurarak kitaplıkları kullanarak uygulamalarınızı yazmaya başlarsınız. LangSmith daha sonra zincirlerinizi incelemenize, test etmenize ve izlemenize yardımcı olarak uygulamalarınızın sürekli olarak iyileştirilmesini ve dağıtıma hazır olmasını sağlar. Son olarak, LangServe ile herhangi bir zinciri kolayca bir API'ye dönüştürebilir ve dağıtımı çok kolay hale getirebilirsiniz.
Sonraki bölümlerde LangChain'i nasıl kuracağınızı daha derinlemesine inceleyeceğiz ve akıllı, dil modeliyle güçlendirilmiş uygulamalar oluşturma yolculuğunuza başlayacağız.
Nanonets tarafından siz ve ekipleriniz için tasarlanan yapay zeka odaklı iş akışı oluşturucumuzla manuel görevleri ve iş akışlarını otomatikleştirin.
Kurulum ve Kurulum
LangChain dünyasına dalmaya hazır mısınız? Kurulumu basittir ve bu kılavuz süreç boyunca size adım adım yol gösterecektir.
LangChain yolculuğunuzun ilk adımı onu kurmaktır. Bunu pip veya conda kullanarak kolayca yapabilirsiniz. Terminalinizde aşağıdaki komutu çalıştırın:
pip install langchain
En son özellikleri tercih edenler ve biraz daha maceradan memnun olanlar için LangChain'i doğrudan kaynaktan kurabilirsiniz. Depoyu klonlayın ve şuraya gidin: langchain/libs/langchain dizin. O zaman koş:
pip install -e .
Deneysel özellikler için yüklemeyi düşünün langchain-experimental. En son kodları içeren ve araştırma ve deneysel amaçlara yönelik bir pakettir. Aşağıdakileri kullanarak yükleyin:
pip install langchain-experimental
LangChain CLI, LangChain şablonları ve LangServe projeleriyle çalışmak için kullanışlı bir araçtır. LangChain CLI'yi yüklemek için şunu kullanın:
pip install langchain-cli
LangServe, LangChain zincirlerinizi REST API olarak dağıtmak için gereklidir. LangChain CLI ile birlikte kurulur.
LangChain genellikle model sağlayıcılar, veri depoları, API'ler vb. ile entegrasyon gerektirir. Bu örnek için OpenAI'nin model API'lerini kullanacağız. OpenAI Python paketini aşağıdakileri kullanarak yükleyin:
pip install openai
API'ye erişmek için OpenAI API anahtarınızı bir ortam değişkeni olarak ayarlayın:
export OPENAI_API_KEY="your_api_key"
Alternatif olarak anahtarı doğrudan python ortamınıza iletin:
import os
os.environ['OPENAI_API_KEY'] = 'your_api_key'
LangChain, modüller aracılığıyla dil modeli uygulamalarının oluşturulmasına olanak sağlar. Bu modüller tek başına olabileceği gibi karmaşık kullanım durumları için de oluşturulabilir. Bu modüller –
- Model G/Ç: Çeşitli dil modelleriyle etkileşimi kolaylaştırır, girdi ve çıktılarını verimli bir şekilde yönetir.
- geri alma: Dinamik veri kullanımı için hayati önem taşıyan uygulamaya özel verilere erişim ve etkileşime olanak sağlar.
- Danışmanlar: Uygulamaları, üst düzey yönergelere dayalı olarak uygun araçları seçme konusunda güçlendirerek karar verme yeteneklerini geliştirin.
- Zincirler: Uygulama geliştirme için yapı taşları görevi gören önceden tanımlanmış, yeniden kullanılabilir kompozisyonlar sunar.
- Bellek: Bağlama duyarlı etkileşimler için gerekli olan birden fazla zincir yürütmede uygulama durumunu korur.
Her modül belirli geliştirme ihtiyaçlarını hedef alarak LangChain'i gelişmiş dil modeli uygulamaları oluşturmaya yönelik kapsamlı bir araç seti haline getirir.
Yukarıdaki bileşenlerin yanı sıra, ayrıca LangChain İfade Dili (LCEL)Bu, modülleri kolayca bir araya getirmenin bildirimsel bir yoludur ve bu, evrensel bir Çalıştırılabilir arayüz kullanarak bileşenlerin zincirlenmesine olanak tanır.
LCEL buna benzer bir şeye benziyor –
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.schema import BaseOutputParser # Example chain
chain = ChatPromptTemplate() | ChatOpenAI() | CustomOutputParser()
Artık temel konuları ele aldığımıza göre devam edebiliriz:
- Her Langchain modülünü ayrıntılı olarak daha derinlemesine inceleyin.
- LangChain İfade Dilinin nasıl kullanılacağını öğrenin.
- Yaygın kullanım örneklerini keşfedin ve bunları uygulayın.
- LangServe ile uçtan uca bir uygulamayı devreye alın.
- Hata ayıklama, test etme ve izleme için LangSmith'e göz atın.
En başlayalım!
Modül I: Model G/Ç
LangChain'de herhangi bir uygulamanın temel unsuru dil modeli etrafında döner. Bu modül, herhangi bir dil modeliyle etkili bir şekilde arayüz oluşturmak için gerekli yapı taşlarını sağlayarak kusursuz entegrasyon ve iletişim sağlar.
Model G/Ç'nin Temel Bileşenleri
- Yüksek Lisans ve Sohbet Modelleri (birbirinin yerine kullanılır):
- Yüksek Lisans:
- Tanım: Saf metin tamamlama modelleri.
- Girdi / Çıktı: Giriş olarak bir metin dizesi alın ve çıktı olarak bir metin dizesi döndürün.
- Sohbet Modelleri
- Yüksek Lisans:
- Tanım: Dil modelini temel olarak kullanan ancak giriş ve çıkış formatlarında farklılık gösteren modeller.
- Girdi / Çıktı: Sohbet mesajlarının bir listesini giriş olarak kabul edin ve bir Sohbet Mesajı gönderin.
- istemleri: Model girişlerini şablonlaştırın, dinamik olarak seçin ve yönetin. Dil modelinin yanıtlarını yönlendiren esnek ve bağlama özgü istemlerin oluşturulmasına olanak tanır.
- Çıkış Ayrıştırıcıları: Model çıktılarından bilgileri çıkarın ve biçimlendirin. Dil modellerinin ham çıktısını yapılandırılmış verilere veya uygulamanın ihtiyaç duyduğu belirli formatlara dönüştürmek için kullanışlıdır.
LLM'ler
LangChain'in OpenAI, Cohere ve Hugging Face gibi Büyük Dil Modelleri (LLM'ler) ile entegrasyonu işlevselliğinin temel bir yönüdür. LangChain'in kendisi Yüksek Lisans'lara ev sahipliği yapmaz ancak çeşitli Yüksek Lisans'larla etkileşime geçmek için tek tip bir arayüz sunar.
Bu bölüm, diğer LLM türleri için de geçerli olan LangChain'de OpenAI LLM sarmalayıcısının kullanımına ilişkin bir genel bakış sağlar. Bunu zaten “Başlarken” bölümüne yükledik. LLM'yi başlatalım.
from langchain.llms import OpenAI
llm = OpenAI()
- Yüksek Lisans'lar şunları uygular: Çalıştırılabilir arayüztemel yapı taşı olan LangChain İfade Dili (LCEL). Bu demek oluyor ki destekliyorlar
invoke,ainvoke,stream,astream,batch,abatch,astream_logçağırır. - Yüksek Lisans'lar kabul ediyor dizeleri girdiler veya dize istemlerine zorlanabilen nesneler olarak
List[BaseMessage]vePromptValue. (bunlar hakkında daha sonra daha fazla bilgi)
Bazı örneklere bakalım.
response = llm.invoke("List the seven wonders of the world.")
print(response)

Alternatif olarak metin yanıtını yayınlamak için akış yöntemini çağırabilirsiniz.
for chunk in llm.stream("Where were the 2012 Olympics held?"): print(chunk, end="", flush=True)

Sohbet Modelleri
LangChain'in, dil modellerinin özel bir çeşidi olan sohbet modelleriyle entegrasyonu, etkileşimli sohbet uygulamaları oluşturmak için gereklidir. Sohbet modelleri, dahili olarak dil modellerini kullanırken, giriş ve çıkış olarak sohbet mesajlarını merkeze alan farklı bir arayüz sunar. Bu bölüm, OpenAI'nin sohbet modelinin LangChain'de kullanımına ilişkin ayrıntılı bir genel bakış sağlar.
from langchain.chat_models import ChatOpenAI
chat = ChatOpenAI()
LangChain'deki sohbet modelleri aşağıdaki gibi farklı mesaj türleriyle çalışır: AIMessage, HumanMessage, SystemMessage, FunctionMessage, ve ChatMessage (isteğe bağlı bir rol parametresiyle). Genel olarak, HumanMessage, AIMessage, ve SystemMessage en sık kullanılanlardır.
Sohbet modelleri öncelikle kabul edilir List[BaseMessage] girdiler olarak. Dizeler dönüştürülebilir HumanMessage, ve PromptValue da desteklenmektedir.
from langchain.schema.messages import HumanMessage, SystemMessage
messages = [ SystemMessage(content="You are Micheal Jordan."), HumanMessage(content="Which shoe manufacturer are you associated with?"),
]
response = chat.invoke(messages)
print(response.content)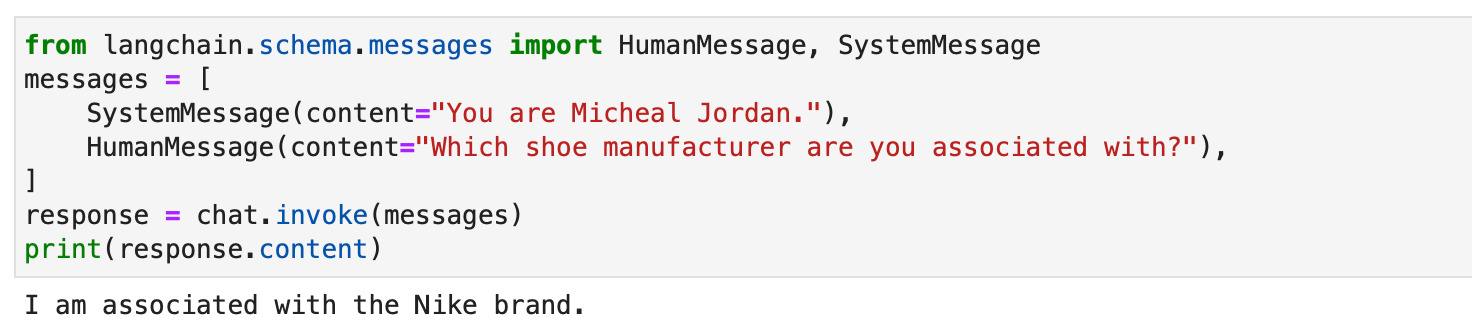
istemleri
İlgili ve tutarlı çıktılar üretmek için dil modellerine rehberlik etmede bilgi istemleri önemlidir. Basit talimatlardan karmaşık, birkaç örnekten oluşan örneklere kadar çeşitlilik gösterebilirler. LangChain'de, çeşitli özel sınıflar ve işlevler sayesinde istemlerin işlenmesi oldukça kolaylaştırılmış bir süreç olabilir.
LangChain'in PromptTemplate class, dize istemleri oluşturmak için çok yönlü bir araçtır. Python'u kullanıyor str.format Sözdizimi, dinamik bilgi istemi oluşturulmasına izin verir. Yer tutucularla bir şablon tanımlayabilir ve bunları gerektiği gibi belirli değerlerle doldurabilirsiniz.
from langchain.prompts import PromptTemplate # Simple prompt with placeholders
prompt_template = PromptTemplate.from_template( "Tell me a {adjective} joke about {content}."
) # Filling placeholders to create a prompt
filled_prompt = prompt_template.format(adjective="funny", content="robots")
print(filled_prompt)Sohbet modellerinde, istemler daha yapılandırılmıştır ve belirli rollere sahip mesajları içerir. LangChain teklifleri ChatPromptTemplate bu amaç için.
from langchain.prompts import ChatPromptTemplate # Defining a chat prompt with various roles
chat_template = ChatPromptTemplate.from_messages( [ ("system", "You are a helpful AI bot. Your name is {name}."), ("human", "Hello, how are you doing?"), ("ai", "I'm doing well, thanks!"), ("human", "{user_input}"), ]
) # Formatting the chat prompt
formatted_messages = chat_template.format_messages(name="Bob", user_input="What is your name?")
for message in formatted_messages: print(message)
Bu yaklaşım, dinamik yanıtlara sahip etkileşimli, ilgi çekici sohbet robotlarının oluşturulmasına olanak tanır.
Her ikisi de PromptTemplate ve ChatPromptTemplate LangChain İfade Dili (LCEL) ile sorunsuz bir şekilde entegre olup daha büyük, karmaşık iş akışlarının parçası olmalarını sağlar. Bu konuyu daha sonra tartışacağız.
Özel bilgi istemi şablonları bazen benzersiz biçimlendirme veya özel talimatlar gerektiren görevler için gereklidir. Özel bir bilgi istemi şablonu oluşturmak, giriş değişkenlerini ve özel bir biçimlendirme yöntemini tanımlamayı içerir. Bu esneklik, LangChain'in çok çeşitli uygulamaya özel gereksinimleri karşılamasına olanak tanır. Daha fazlasını buradan okuyun.
LangChain ayrıca birkaç adımlık yönlendirmeyi destekleyerek modelin örneklerden öğrenmesini sağlar. Bu özellik, bağlamsal anlayış veya belirli kalıplar gerektiren görevler için hayati öneme sahiptir. Bir dizi örnekten veya bir Örnek Seçici nesnesi kullanılarak birkaç çekimli bilgi istemi şablonları oluşturulabilir. Daha fazlasını buradan okuyun.
Çıkış Ayrıştırıcıları
Çıktı ayrıştırıcıları Langchain'de önemli bir rol oynayarak kullanıcıların dil modelleri tarafından oluşturulan yanıtları yapılandırmasına olanak tanır. Bu bölümde çıktı ayrıştırıcıları kavramını inceleyeceğiz ve Langchain'in PydanticOutputParser, SimpleJsonOutputParser, CommaSeparatedListOutputParser, DatetimeOutputParser ve XMLOutputParser'ı kullanan kod örnekleri sunacağız.
PydanticOutputParser
Langchain, yanıtları Pydantic veri yapılarına ayrıştırmak için PydanticOutputParser'ı sağlar. Aşağıda nasıl kullanılacağına dair adım adım bir örnek verilmiştir:
from typing import List
from langchain.llms import OpenAI
from langchain.output_parsers import PydanticOutputParser
from langchain.prompts import PromptTemplate
from langchain.pydantic_v1 import BaseModel, Field, validator # Initialize the language model
model = OpenAI(model_name="text-davinci-003", temperature=0.0) # Define your desired data structure using Pydantic
class Joke(BaseModel): setup: str = Field(description="question to set up a joke") punchline: str = Field(description="answer to resolve the joke") @validator("setup") def question_ends_with_question_mark(cls, field): if field[-1] != "?": raise ValueError("Badly formed question!") return field # Set up a PydanticOutputParser
parser = PydanticOutputParser(pydantic_object=Joke) # Create a prompt with format instructions
prompt = PromptTemplate( template="Answer the user query.n{format_instructions}n{query}n", input_variables=["query"], partial_variables={"format_instructions": parser.get_format_instructions()},
) # Define a query to prompt the language model
query = "Tell me a joke." # Combine prompt, model, and parser to get structured output
prompt_and_model = prompt | model
output = prompt_and_model.invoke({"query": query}) # Parse the output using the parser
parsed_result = parser.invoke(output) # The result is a structured object
print(parsed_result)
çıkış olacaktır:

SimpleJsonOutputParser
JSON benzeri çıktıları ayrıştırmak istediğinizde Langchain'in SimpleJsonOutputParser'ı kullanılır. İşte bir örnek:
from langchain.output_parsers.json import SimpleJsonOutputParser # Create a JSON prompt
json_prompt = PromptTemplate.from_template( "Return a JSON object with `birthdate` and `birthplace` key that answers the following question: {question}"
) # Initialize the JSON parser
json_parser = SimpleJsonOutputParser() # Create a chain with the prompt, model, and parser
json_chain = json_prompt | model | json_parser # Stream through the results
result_list = list(json_chain.stream({"question": "When and where was Elon Musk born?"})) # The result is a list of JSON-like dictionaries
print(result_list)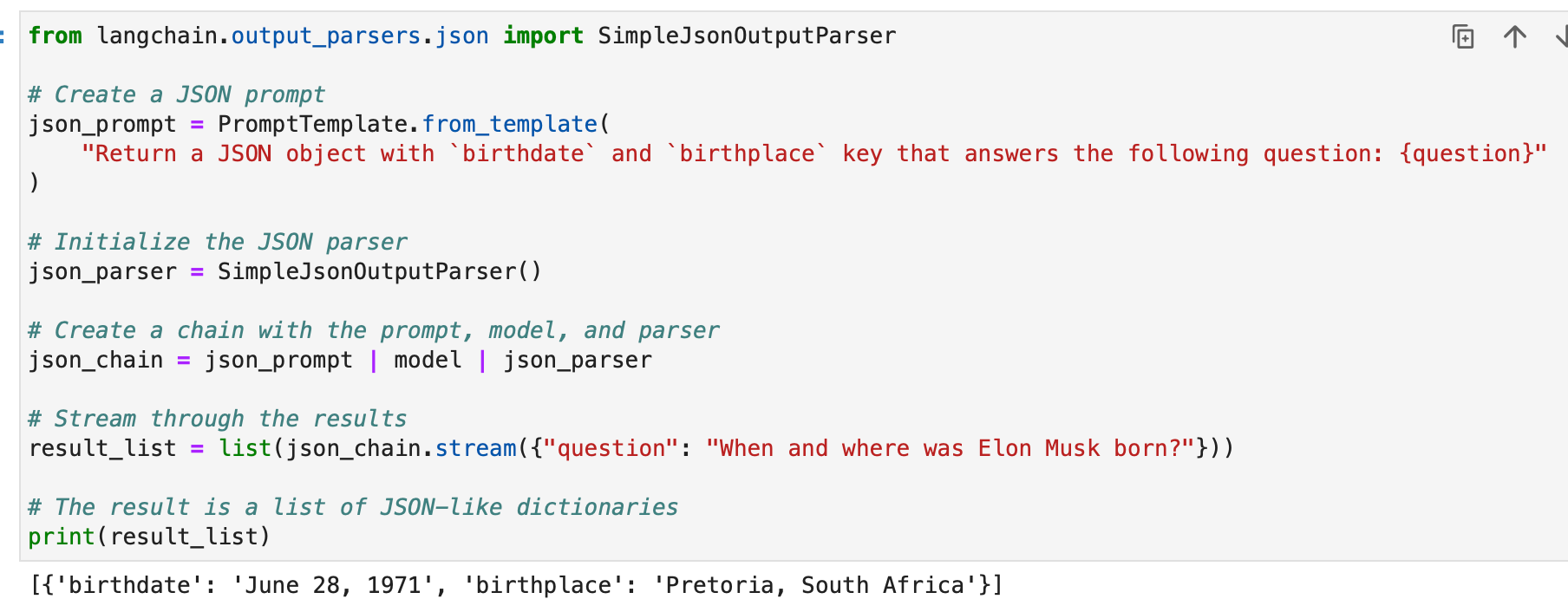
CommaSeparatedListOutputParser
CommaSeparatedListOutputParser, model yanıtlarından virgülle ayrılmış listeler çıkarmak istediğinizde kullanışlıdır. İşte bir örnek:
from langchain.output_parsers import CommaSeparatedListOutputParser
from langchain.prompts import PromptTemplate
from langchain.llms import OpenAI # Initialize the parser
output_parser = CommaSeparatedListOutputParser() # Create format instructions
format_instructions = output_parser.get_format_instructions() # Create a prompt to request a list
prompt = PromptTemplate( template="List five {subject}.n{format_instructions}", input_variables=["subject"], partial_variables={"format_instructions": format_instructions}
) # Define a query to prompt the model
query = "English Premier League Teams" # Generate the output
output = model(prompt.format(subject=query)) # Parse the output using the parser
parsed_result = output_parser.parse(output) # The result is a list of items
print(parsed_result)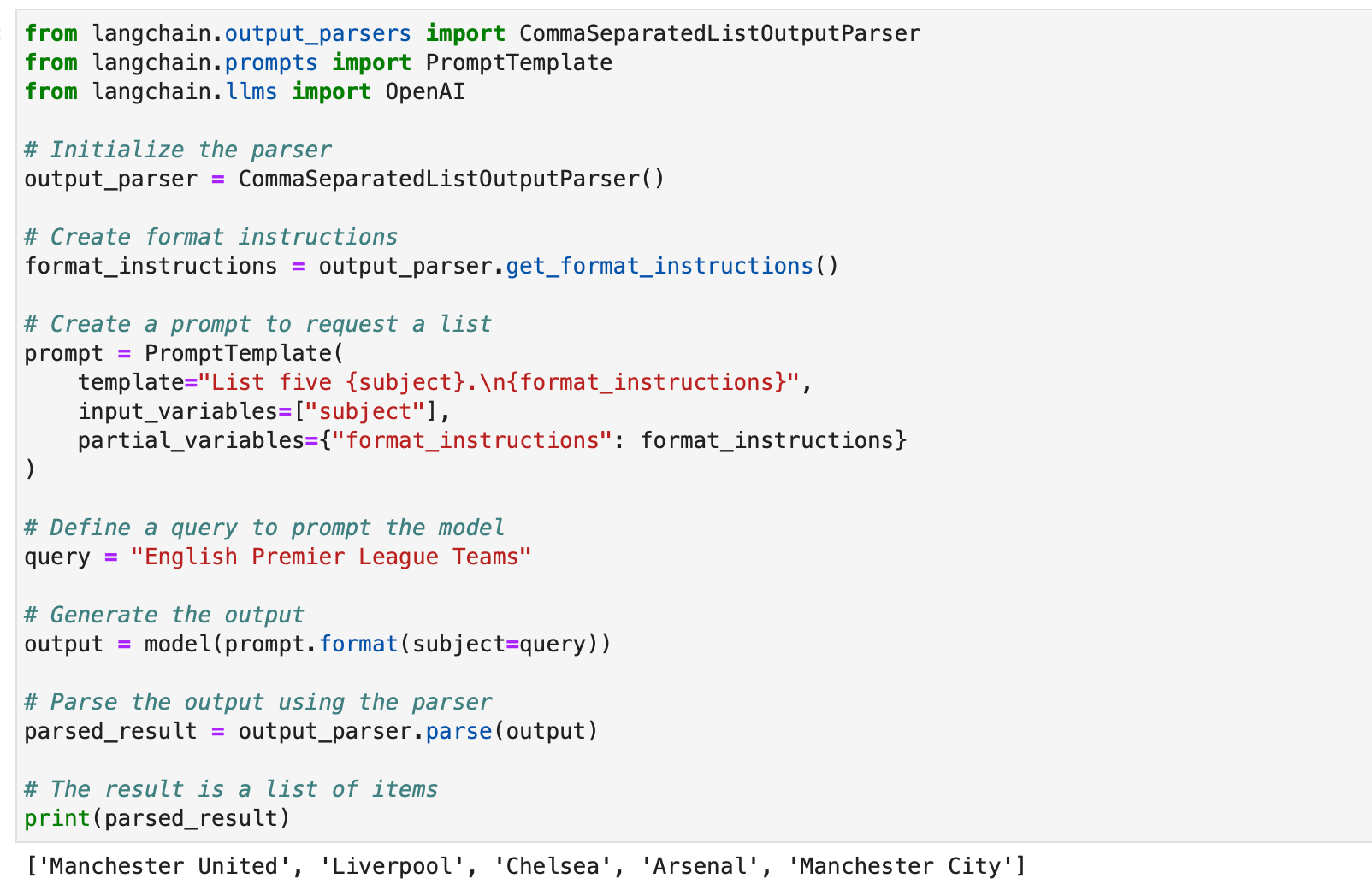
DatetimeOutputParser
Langchain'in DatetimeOutputParser'ı tarihsaat bilgilerini ayrıştırmak için tasarlanmıştır. İşte nasıl kullanılacağı:
from langchain.prompts import PromptTemplate
from langchain.output_parsers import DatetimeOutputParser
from langchain.chains import LLMChain
from langchain.llms import OpenAI # Initialize the DatetimeOutputParser
output_parser = DatetimeOutputParser() # Create a prompt with format instructions
template = """
Answer the user's question:
{question}
{format_instructions} """ prompt = PromptTemplate.from_template( template, partial_variables={"format_instructions": output_parser.get_format_instructions()},
) # Create a chain with the prompt and language model
chain = LLMChain(prompt=prompt, llm=OpenAI()) # Define a query to prompt the model
query = "when did Neil Armstrong land on the moon in terms of GMT?" # Run the chain
output = chain.run(query) # Parse the output using the datetime parser
parsed_result = output_parser.parse(output) # The result is a datetime object
print(parsed_result)
Bu örnekler, Langchain'in çıktı ayrıştırıcılarının çeşitli model yanıtlarını yapılandırmak için nasıl kullanılabileceğini ve bunların farklı uygulamalar ve formatlar için nasıl uygun hale getirilebileceğini gösteriyor. Çıktı ayrıştırıcıları, Langchain'deki dil modeli çıktılarının kullanılabilirliğini ve yorumlanabilirliğini geliştirmek için değerli bir araçtır.
Nanonets tarafından siz ve ekipleriniz için tasarlanan yapay zeka odaklı iş akışı oluşturucumuzla manuel görevleri ve iş akışlarını otomatikleştirin.
Modül II: Geri Alma
LangChain'de erişim, modelin eğitim setinde yer almayan, kullanıcıya özel veriler gerektiren uygulamalarda çok önemli bir rol oynar. Alma Artırılmış Üretim (RAG) olarak bilinen bu süreç, harici verilerin getirilmesini ve bu verilerin dil modelinin üretim sürecine entegre edilmesini içerir. LangChain, bu süreci kolaylaştırmak için hem basit hem de karmaşık uygulamalara hitap eden kapsamlı bir araç ve işlevsellik paketi sunar.
LangChain, tek tek ele alacağımız bir dizi bileşen aracılığıyla geri almayı başarır.
Belge Yükleyiciler
LangChain'deki belge yükleyiciler, çeşitli kaynaklardan veri çıkarılmasını sağlar. 100'den fazla yükleyici mevcut olduğundan, çeşitli belge türlerini, uygulamaları ve kaynakları (özel s3 klasörleri, genel web siteleri, veritabanları) destekler.
Gereksinimlerinize göre bir belge yükleyici seçebilirsiniz okuyun.
Tüm bu yükleyiciler verileri içine alıyor belge sınıflar. Belge sınıflarına alınan verilerin nasıl kullanılacağını daha sonra öğreneceğiz.
Metin Dosyası Yükleyici: Basit bir yükleme .txt bir belgeye dosyalayın.
from langchain.document_loaders import TextLoader loader = TextLoader("./sample.txt")
document = loader.load()
CSV Yükleyici: Bir CSV dosyasını bir belgeye yükleyin.
from langchain.document_loaders.csv_loader import CSVLoader loader = CSVLoader(file_path='./example_data/sample.csv')
documents = loader.load()
Alan adlarını belirterek ayrıştırmayı özelleştirmeyi seçebiliriz –
loader = CSVLoader(file_path='./example_data/mlb_teams_2012.csv', csv_args={ 'delimiter': ',', 'quotechar': '"', 'fieldnames': ['MLB Team', 'Payroll in millions', 'Wins']
})
documents = loader.load()
PDF Yükleyiciler: LangChain'deki PDF Yükleyiciler, PDF dosyalarından içerik ayrıştırmak ve çıkarmak için çeşitli yöntemler sunar. Her yükleyici farklı gereksinimleri karşılar ve farklı temel kitaplıkları kullanır. Aşağıda her yükleyici için ayrıntılı örnekler verilmiştir.
PyPDFLoader, temel PDF ayrıştırma için kullanılır.
from langchain.document_loaders import PyPDFLoader loader = PyPDFLoader("example_data/layout-parser-paper.pdf")
pages = loader.load_and_split()
MathPixLoader matematiksel içerik ve diyagramları çıkarmak için idealdir.
from langchain.document_loaders import MathpixPDFLoader loader = MathpixPDFLoader("example_data/math-content.pdf")
data = loader.load()
PyMuPDFLoader hızlıdır ve ayrıntılı meta veri çıkarma içerir.
from langchain.document_loaders import PyMuPDFLoader loader = PyMuPDFLoader("example_data/layout-parser-paper.pdf")
data = loader.load() # Optionally pass additional arguments for PyMuPDF's get_text() call
data = loader.load(option="text")
PDFMiner Yükleyici, metin çıkarma üzerinde daha ayrıntılı kontrol için kullanılır.
from langchain.document_loaders import PDFMinerLoader loader = PDFMinerLoader("example_data/layout-parser-paper.pdf")
data = loader.load()
AmazonTextractPDFParser, OCR ve diğer gelişmiş PDF ayrıştırma özellikleri için AWS Textract'ı kullanır.
from langchain.document_loaders import AmazonTextractPDFLoader # Requires AWS account and configuration
loader = AmazonTextractPDFLoader("example_data/complex-layout.pdf")
documents = loader.load()
PDFMinerPDFasHTMLLoader anlamsal ayrıştırma için PDF'den HTML oluşturur.
from langchain.document_loaders import PDFMinerPDFasHTMLLoader loader = PDFMinerPDFasHTMLLoader("example_data/layout-parser-paper.pdf")
data = loader.load()
PDFPlumberLoader ayrıntılı meta veriler sağlar ve sayfa başına bir belgeyi destekler.
from langchain.document_loaders import PDFPlumberLoader loader = PDFPlumberLoader("example_data/layout-parser-paper.pdf")
data = loader.load()
Entegre Yükleyiciler: LangChain, uygulamalarınızdan (Slack, Sigma, Notion, Confluence, Google Drive ve daha fazlası gibi) ve veritabanlarından verileri doğrudan yüklemek ve bunları LLM uygulamalarında kullanmak için çok çeşitli özel yükleyiciler sunar.
Tam liste: okuyun.
Aşağıda bunu açıklamak için birkaç örnek verilmiştir -
Örnek I – Slack
Yaygın olarak kullanılan anlık mesajlaşma platformu Slack, LLM iş akışlarına ve uygulamalarına entegre edilebilir.
- Slack Çalışma Alanı Yönetimi sayfanıza gidin.
- Şu yöne rotayı ayarla
{your_slack_domain}.slack.com/services/export. - İstediğiniz tarih aralığını seçin ve dışa aktarmayı başlatın.
- Slack, dışa aktarma hazır olduğunda e-posta ve DM yoluyla bildirimde bulunur.
- İhracatın sonuçları şöyle:
.zipİndirilenler klasörünüzde veya belirlediğiniz indirme yolunda bulunan dosya. - İndirilenlerin yolunu atayın
.zipdosyasınıLOCAL_ZIPFILE. - Kullan
SlackDirectoryLoaderitibarenlangchain.document_loaderspaketi.
from langchain.document_loaders import SlackDirectoryLoader SLACK_WORKSPACE_URL = "https://xxx.slack.com" # Replace with your Slack URL
LOCAL_ZIPFILE = "" # Path to the Slack zip file loader = SlackDirectoryLoader(LOCAL_ZIPFILE, SLACK_WORKSPACE_URL)
docs = loader.load()
print(docs)
Örnek II – Figma
Arayüz tasarımı için popüler bir araç olan Figma, veri entegrasyonu için bir REST API sunmaktadır.
- Figma dosya anahtarını URL formatından edinin:
https://www.figma.com/file/{filekey}/sampleFilename. - Düğüm kimlikleri URL parametresinde bulunur
?node-id={node_id}. - adresindeki talimatları izleyerek bir erişim belirteci oluşturun. Figma Yardım Merkezi.
- The
FigmaFileLoadersınıftanlangchain.document_loaders.figmaFigma verilerini yüklemek için kullanılır. - Çeşitli LangChain modülleri gibi
CharacterTextSplitter,ChatOpenAIvb. işlemek için kullanılır.
import os
from langchain.document_loaders.figma import FigmaFileLoader
from langchain.text_splitter import CharacterTextSplitter
from langchain.chat_models import ChatOpenAI
from langchain.indexes import VectorstoreIndexCreator
from langchain.chains import ConversationChain, LLMChain
from langchain.memory import ConversationBufferWindowMemory
from langchain.prompts.chat import ChatPromptTemplate, SystemMessagePromptTemplate, AIMessagePromptTemplate, HumanMessagePromptTemplate figma_loader = FigmaFileLoader( os.environ.get("ACCESS_TOKEN"), os.environ.get("NODE_IDS"), os.environ.get("FILE_KEY"),
) index = VectorstoreIndexCreator().from_loaders([figma_loader])
figma_doc_retriever = index.vectorstore.as_retriever()
- The
generate_codeişlevi, HTML/CSS kodu oluşturmak için Figma verilerini kullanır. - GPT tabanlı bir modelle şablonlu bir görüşme kullanır.
def generate_code(human_input): # Template for system and human prompts system_prompt_template = "Your coding instructions..." human_prompt_template = "Code the {text}. Ensure it's mobile responsive" # Creating prompt templates system_message_prompt = SystemMessagePromptTemplate.from_template(system_prompt_template) human_message_prompt = HumanMessagePromptTemplate.from_template(human_prompt_template) # Setting up the AI model gpt_4 = ChatOpenAI(temperature=0.02, model_name="gpt-4") # Retrieving relevant documents relevant_nodes = figma_doc_retriever.get_relevant_documents(human_input) # Generating and formatting the prompt conversation = [system_message_prompt, human_message_prompt] chat_prompt = ChatPromptTemplate.from_messages(conversation) response = gpt_4(chat_prompt.format_prompt(context=relevant_nodes, text=human_input).to_messages()) return response # Example usage
response = generate_code("page top header")
print(response.content)
- The
generate_codeişlevi çalıştırıldığında Figma tasarım girdisine dayalı olarak HTML/CSS kodunu döndürür.
Şimdi bilgimizi birkaç belge seti oluşturmak için kullanalım.
Öncelikle BCG yıllık sürdürülebilirlik raporunun PDF dosyasını yüklüyoruz.

Bunun için PyPDFLoader'ı kullanıyoruz.
from langchain.document_loaders import PyPDFLoader loader = PyPDFLoader("bcg-2022-annual-sustainability-report-apr-2023.pdf")
pdfpages = loader.load_and_split()
Şimdi Airtable'dan veri alacağız. Çeşitli OCR ve veri çıkarma modelleri hakkında bilgi içeren bir Airtable'ımız var -
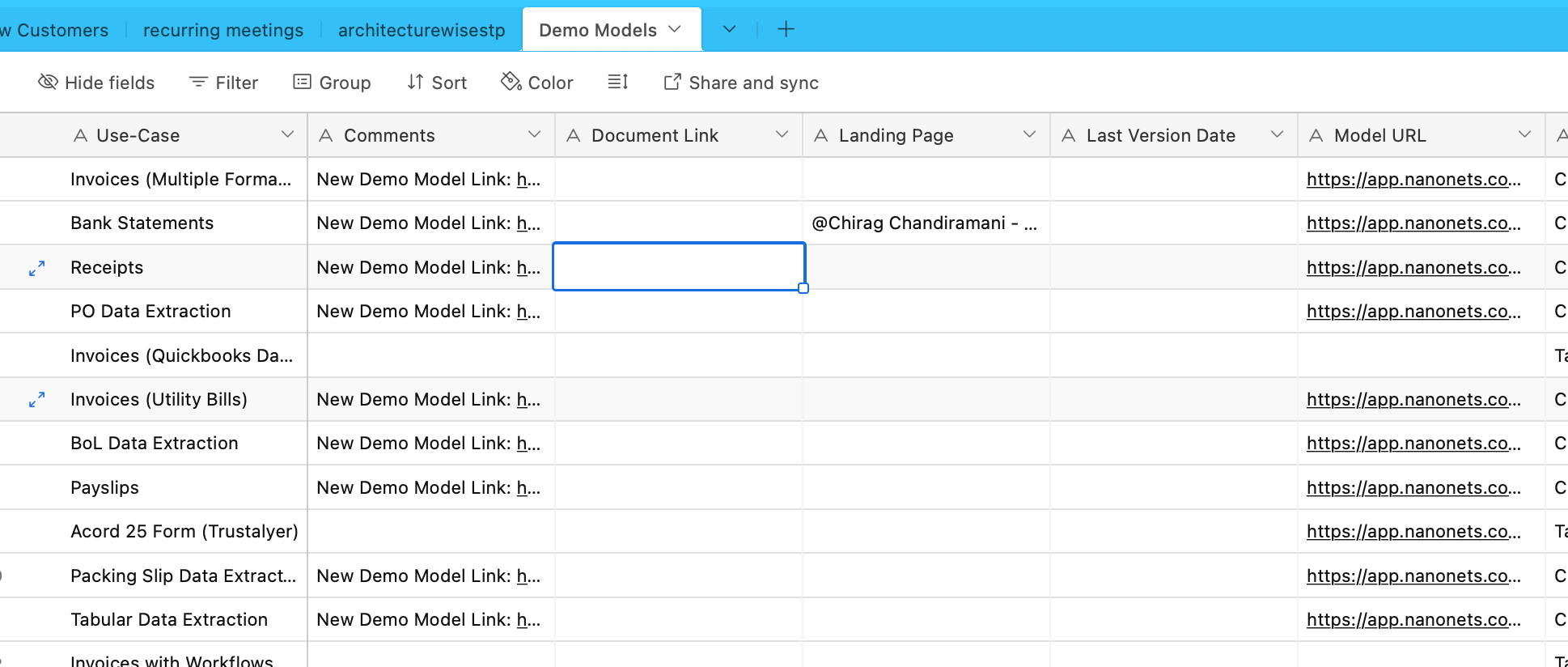
Bunun için entegre yükleyiciler listesinde bulunan AirtableLoader'ı kullanalım.
from langchain.document_loaders import AirtableLoader api_key = "XXXXX"
base_id = "XXXXX"
table_id = "XXXXX" loader = AirtableLoader(api_key, table_id, base_id)
airtabledocs = loader.load()
Şimdi devam edelim ve bu belge sınıflarının nasıl kullanılacağını öğrenelim.
Belge Transformatörleri
LangChain'deki belge dönüştürücüler, önceki alt bölümümüzde oluşturduğumuz belgeleri işlemek için tasarlanmış temel araçlardır.
Belgeleri bir modelin bağlam penceresine uyarlamak veya belirli uygulama ihtiyaçlarını karşılamak için çok önemli olan uzun belgeleri daha küçük parçalara bölme, birleştirme ve filtreleme gibi görevlerde kullanılırlar.
Böyle bir araç, bölmek için bir karakter listesi kullanan çok yönlü bir metin bölücü olan RecursiveCharacterTextSplitter'dır. Parça boyutu, örtüşme ve başlangıç dizini gibi parametrelere izin verir. Python'da nasıl kullanıldığına dair bir örnek:
from langchain.text_splitter import RecursiveCharacterTextSplitter state_of_the_union = "Your long text here..." text_splitter = RecursiveCharacterTextSplitter( chunk_size=100, chunk_overlap=20, length_function=len, add_start_index=True,
) texts = text_splitter.create_documents([state_of_the_union])
print(texts[0])
print(texts[1])
Başka bir araç, metni belirli bir karaktere göre bölen ve yığın boyutu ve örtüşme için kontroller içeren CharacterTextSplitter'dır:
from langchain.text_splitter import CharacterTextSplitter text_splitter = CharacterTextSplitter( separator="nn", chunk_size=1000, chunk_overlap=200, length_function=len, is_separator_regex=False,
) texts = text_splitter.create_documents([state_of_the_union])
print(texts[0])
HTMLHeaderTextSplitter, semantik yapıyı koruyarak HTML içeriğini başlık etiketlerine göre bölmek için tasarlanmıştır:
from langchain.text_splitter import HTMLHeaderTextSplitter html_string = "Your HTML content here..."
headers_to_split_on = [("h1", "Header 1"), ("h2", "Header 2")] html_splitter = HTMLHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
html_header_splits = html_splitter.split_text(html_string)
print(html_header_splits[0])
HTMLHeaderTextSplitter'ı Pipelined Splitter gibi başka bir ayırıcıyla birleştirerek daha karmaşık bir manipülasyon elde edilebilir:
from langchain.text_splitter import HTMLHeaderTextSplitter, RecursiveCharacterTextSplitter url = "https://example.com"
headers_to_split_on = [("h1", "Header 1"), ("h2", "Header 2")]
html_splitter = HTMLHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
html_header_splits = html_splitter.split_text_from_url(url) chunk_size = 500
text_splitter = RecursiveCharacterTextSplitter(chunk_size=chunk_size)
splits = text_splitter.split_documents(html_header_splits)
print(splits[0])
LangChain ayrıca Python Kod Ayırıcı ve JavaScript Kod Ayırıcı gibi farklı programlama dilleri için özel ayırıcılar da sunar:
from langchain.text_splitter import RecursiveCharacterTextSplitter, Language python_code = """
def hello_world(): print("Hello, World!")
hello_world() """ python_splitter = RecursiveCharacterTextSplitter.from_language( language=Language.PYTHON, chunk_size=50
)
python_docs = python_splitter.create_documents([python_code])
print(python_docs[0]) js_code = """
function helloWorld() { console.log("Hello, World!");
}
helloWorld(); """ js_splitter = RecursiveCharacterTextSplitter.from_language( language=Language.JS, chunk_size=60
)
js_docs = js_splitter.create_documents([js_code])
print(js_docs[0])
Belirteç sınırlarına sahip dil modelleri için yararlı olan, belirteç sayısına göre metni bölmek için TokenTextSplitter kullanılır:
from langchain.text_splitter import TokenTextSplitter text_splitter = TokenTextSplitter(chunk_size=10)
texts = text_splitter.split_text(state_of_the_union)
print(texts[0])
Son olarak LongContextReorder, uzun bağlamlar nedeniyle modellerde performans düşüşünü önlemek için belgeleri yeniden sıralar:
from langchain.document_transformers import LongContextReorder reordering = LongContextReorder()
reordered_docs = reordering.transform_documents(docs)
print(reordered_docs[0])
Bu araçlar, basit metin bölmeden karmaşık yeniden sıralama ve dile özgü bölmeye kadar LangChain'deki belgeleri dönüştürmenin çeşitli yollarını gösterir. Daha ayrıntılı ve spesifik kullanım durumları için LangChain dokümantasyonu ve Entegrasyonlar bölümüne başvurulmalıdır.
Örneklerimizde yükleyiciler bizim için zaten parçalanmış belgeler oluşturmuş durumda ve bu kısım zaten işleniyor.
Metin Gömme Modelleri
LangChain'deki metin gömme modelleri, OpenAI, Cohere ve Hugging Face gibi çeşitli gömme modeli sağlayıcıları için standartlaştırılmış bir arayüz sağlar. Bu modeller, metni vektör temsillerine dönüştürerek, vektör uzayındaki metin benzerliği yoluyla anlamsal arama gibi işlemlere olanak tanır.
Metin yerleştirme modellerine başlamak için genellikle belirli paketleri yüklemeniz ve API anahtarlarını ayarlamanız gerekir. Bunu OpenAI için zaten yaptık
LangChain'de, embed_documents yöntemi, vektör temsillerinin bir listesini sağlayarak birden fazla metni gömmek için kullanılır. Örneğin:
from langchain.embeddings import OpenAIEmbeddings # Initialize the model
embeddings_model = OpenAIEmbeddings() # Embed a list of texts
embeddings = embeddings_model.embed_documents( ["Hi there!", "Oh, hello!", "What's your name?", "My friends call me World", "Hello World!"]
)
print("Number of documents embedded:", len(embeddings))
print("Dimension of each embedding:", len(embeddings[0]))
Arama sorgusu gibi tek bir metni gömmek için, embed_query yöntem kullanılır. Bu, bir sorguyu bir dizi belge yerleştirmeyle karşılaştırmak için kullanışlıdır. Örneğin:
from langchain.embeddings import OpenAIEmbeddings # Initialize the model
embeddings_model = OpenAIEmbeddings() # Embed a single query
embedded_query = embeddings_model.embed_query("What was the name mentioned in the conversation?")
print("First five dimensions of the embedded query:", embedded_query[:5])
Bu yerleştirmeleri anlamak çok önemlidir. Her metin parçası, boyutu kullanılan modele bağlı olan bir vektöre dönüştürülür. Örneğin OpenAI modelleri genellikle 1536 boyutlu vektörler üretir. Bu yerleştirmeler daha sonra ilgili bilgilerin alınması için kullanılır.
LangChain'in yerleştirme işlevi OpenAI ile sınırlı değildir, çeşitli sağlayıcılarla çalışacak şekilde tasarlanmıştır. Kurulum ve kullanım, sağlayıcıya bağlı olarak biraz farklılık gösterebilir, ancak metinleri vektör alanına yerleştirmenin temel konsepti aynı kalır. Gelişmiş yapılandırmalar ve farklı yerleştirme modeli sağlayıcılarıyla entegrasyonlar da dahil olmak üzere ayrıntılı kullanım için Entegrasyonlar bölümündeki LangChain belgeleri değerli bir kaynaktır.
Vektör Mağazaları
LangChain'deki vektör depoları, metin yerleştirmelerin verimli bir şekilde depolanmasını ve aranmasını destekler. LangChain, 50'den fazla vektör mağazasıyla entegre olarak kullanım kolaylığı için standartlaştırılmış bir arayüz sağlar.
Örnek: Gömmelerin Saklanması ve Aranması
Metinleri gömdükten sonra bunları aşağıdaki gibi bir vektör deposunda saklayabiliriz: Chroma ve benzerlik aramaları gerçekleştirin:
from langchain.vectorstores import Chroma db = Chroma.from_texts(embedded_texts)
similar_texts = db.similarity_search("search query")
Alternatif olarak belgelerimiz için dizinler oluşturmak amacıyla FAISS vektör deposunu kullanalım.
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import FAISS pdfstore = FAISS.from_documents(pdfpages, embedding=OpenAIEmbeddings()) airtablestore = FAISS.from_documents(airtabledocs, embedding=OpenAIEmbeddings())

Retrieverler
LangChain'deki alıcılar, yapılandırılmamış bir sorguya yanıt olarak belgeleri döndüren arayüzlerdir. Depolamadan ziyade erişime odaklanan vektör mağazalarından daha geneldirler. Vektör depoları bir av köpeğinin omurgası olarak kullanılabilse de, başka türde alıcılar da vardır.
Bir Chroma alıcısı kurmak için önce onu kullanarak yüklersiniz. pip install chromadb. Daha sonra bir dizi Python komutunu kullanarak belgeleri yükler, böler, gömer ve alırsınız. İşte bir Chroma alıcısı kurmaya yönelik bir kod örneği:
from langchain.embeddings import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import Chroma full_text = open("state_of_the_union.txt", "r").read()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=100)
texts = text_splitter.split_text(full_text) embeddings = OpenAIEmbeddings()
db = Chroma.from_texts(texts, embeddings)
retriever = db.as_retriever() retrieved_docs = retriever.invoke("What did the president say about Ketanji Brown Jackson?")
print(retrieved_docs[0].page_content)
MultiQueryRetriever, bir kullanıcı giriş sorgusu için birden fazla sorgu oluşturarak istem ayarlamayı otomatikleştirir ve sonuçları birleştirir. İşte basit kullanımına bir örnek:
from langchain.chat_models import ChatOpenAI
from langchain.retrievers.multi_query import MultiQueryRetriever question = "What are the approaches to Task Decomposition?"
llm = ChatOpenAI(temperature=0)
retriever_from_llm = MultiQueryRetriever.from_llm( retriever=db.as_retriever(), llm=llm
) unique_docs = retriever_from_llm.get_relevant_documents(query=question)
print("Number of unique documents:", len(unique_docs))
LangChain'deki Bağlamsal Sıkıştırma, sorgu bağlamını kullanarak alınan belgeleri sıkıştırarak yalnızca ilgili bilgilerin döndürülmesini sağlar. Bu, içeriğin azaltılmasını ve daha az alakalı belgelerin filtrelenmesini içerir. Aşağıdaki kod örneği Bağlamsal Sıkıştırma Alıcısının nasıl kullanılacağını gösterir:
from langchain.llms import OpenAI
from langchain.retrievers import ContextualCompressionRetriever
from langchain.retrievers.document_compressors import LLMChainExtractor llm = OpenAI(temperature=0)
compressor = LLMChainExtractor.from_llm(llm)
compression_retriever = ContextualCompressionRetriever(base_compressor=compressor, base_retriever=retriever) compressed_docs = compression_retriever.get_relevant_documents("What did the president say about Ketanji Jackson Brown")
print(compressed_docs[0].page_content)
EnsembleRetriever, daha iyi performans elde etmek için farklı alma algoritmalarını birleştirir. BM25 ve FAISS Alıcılarını birleştirmenin bir örneği aşağıdaki kodda gösterilmektedir:
from langchain.retrievers import BM25Retriever, EnsembleRetriever
from langchain.vectorstores import FAISS bm25_retriever = BM25Retriever.from_texts(doc_list).set_k(2)
faiss_vectorstore = FAISS.from_texts(doc_list, OpenAIEmbeddings())
faiss_retriever = faiss_vectorstore.as_retriever(search_kwargs={"k": 2}) ensemble_retriever = EnsembleRetriever( retrievers=[bm25_retriever, faiss_retriever], weights=[0.5, 0.5]
) docs = ensemble_retriever.get_relevant_documents("apples")
print(docs[0].page_content)
LangChain'deki MultiVector Retriever, belge başına birden fazla vektör içeren belgelerin sorgulanmasına olanak tanır; bu, bir belge içindeki farklı anlamsal yönleri yakalamak için kullanışlıdır. Birden fazla vektör oluşturma yöntemleri arasında daha küçük parçalara bölmek, özetlemek veya varsayımsal sorular oluşturmak yer alır. Belgeleri daha küçük parçalara bölmek için aşağıdaki Python kodu kullanılabilir:
python
from langchain.retrievers.multi_vector import MultiVectorRetriever
from langchain.vectorstores import Chroma
from langchain.embeddings import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.storage import InMemoryStore
from langchain.document_loaders from TextLoader
import uuid loaders = [TextLoader("file1.txt"), TextLoader("file2.txt")]
docs = [doc for loader in loaders for doc in loader.load()]
text_splitter = RecursiveCharacterTextSplitter(chunk_size=10000)
docs = text_splitter.split_documents(docs) vectorstore = Chroma(collection_name="full_documents", embedding_function=OpenAIEmbeddings())
store = InMemoryStore()
id_key = "doc_id"
retriever = MultiVectorRetriever(vectorstore=vectorstore, docstore=store, id_key=id_key) doc_ids = [str(uuid.uuid4()) for _ in docs]
child_text_splitter = RecursiveCharacterTextSplitter(chunk_size=400)
sub_docs = [sub_doc for doc in docs for sub_doc in child_text_splitter.split_documents([doc])]
for sub_doc in sub_docs: sub_doc.metadata[id_key] = doc_ids[sub_docs.index(sub_doc)] retriever.vectorstore.add_documents(sub_docs)
retriever.docstore.mset(list(zip(doc_ids, docs)))
Daha odaklı içerik sunumu nedeniyle daha iyi erişim için özetler oluşturmak başka bir yöntemdir. Özet oluşturmanın bir örneğini burada bulabilirsiniz:
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.schema.output_parser import StrOutputParser
from langchain.schema.document import Document chain = (lambda x: x.page_content) | ChatPromptTemplate.from_template("Summarize the following document:nn{doc}") | ChatOpenAI(max_retries=0) | StrOutputParser()
summaries = chain.batch(docs, {"max_concurrency": 5}) summary_docs = [Document(page_content=s, metadata={id_key: doc_ids[i]}) for i, s in enumerate(summaries)]
retriever.vectorstore.add_documents(summary_docs)
retriever.docstore.mset(list(zip(doc_ids, docs)))
Yüksek Lisans kullanarak her belgeyle ilgili varsayımsal sorular oluşturmak başka bir yaklaşımdır. Bu, aşağıdaki kodla yapılabilir:
functions = [{"name": "hypothetical_questions", "parameters": {"questions": {"type": "array", "items": {"type": "string"}}}}]
from langchain.output_parsers.openai_functions import JsonKeyOutputFunctionsParser chain = (lambda x: x.page_content) | ChatPromptTemplate.from_template("Generate 3 hypothetical questions:nn{doc}") | ChatOpenAI(max_retries=0).bind(functions=functions, function_call={"name": "hypothetical_questions"}) | JsonKeyOutputFunctionsParser(key_name="questions")
hypothetical_questions = chain.batch(docs, {"max_concurrency": 5}) question_docs = [Document(page_content=q, metadata={id_key: doc_ids[i]}) for i, questions in enumerate(hypothetical_questions) for q in questions]
retriever.vectorstore.add_documents(question_docs)
retriever.docstore.mset(list(zip(doc_ids, docs)))
Ana Belge Alıcısı, küçük parçaları depolayarak ve daha büyük ana belgeleri alarak, yerleştirme doğruluğu ile bağlamın korunması arasında bir denge kuran başka bir alıcıdır. Uygulaması şu şekildedir:
from langchain.retrievers import ParentDocumentRetriever loaders = [TextLoader("file1.txt"), TextLoader("file2.txt")]
docs = [doc for loader in loaders for doc in loader.load()] child_splitter = RecursiveCharacterTextSplitter(chunk_size=400)
vectorstore = Chroma(collection_name="full_documents", embedding_function=OpenAIEmbeddings())
store = InMemoryStore()
retriever = ParentDocumentRetriever(vectorstore=vectorstore, docstore=store, child_splitter=child_splitter) retriever.add_documents(docs, ids=None) retrieved_docs = retriever.get_relevant_documents("query")
Kendi kendini sorgulayan bir alıcı, doğal dil girdilerinden yapılandırılmış sorgular oluşturur ve bunları temeldeki VectorStore'a uygular. Uygulanması aşağıdaki kodda gösterilmektedir:
from langchain.chat_models from ChatOpenAI
from langchain.chains.query_constructor.base from AttributeInfo
from langchain.retrievers.self_query.base from SelfQueryRetriever metadata_field_info = [AttributeInfo(name="genre", description="...", type="string"), ...]
document_content_description = "Brief summary of a movie"
llm = ChatOpenAI(temperature=0) retriever = SelfQueryRetriever.from_llm(llm, vectorstore, document_content_description, metadata_field_info) retrieved_docs = retriever.invoke("query")
WebResearchRetriever, belirli bir sorguya dayalı olarak web araştırması gerçekleştirir -
from langchain.retrievers.web_research import WebResearchRetriever # Initialize components
llm = ChatOpenAI(temperature=0)
search = GoogleSearchAPIWrapper()
vectorstore = Chroma(embedding_function=OpenAIEmbeddings()) # Instantiate WebResearchRetriever
web_research_retriever = WebResearchRetriever.from_llm(vectorstore=vectorstore, llm=llm, search=search) # Retrieve documents
docs = web_research_retriever.get_relevant_documents("query")
Örneklerimiz için, halihazırda vektör deposu nesnemizin bir parçası olarak uygulanan standart alıcıyı aşağıdaki gibi kullanabiliriz:

Artık alıcıları sorgulayabiliriz. Sorgumuzun çıktısı sorguyla ilgili belge nesneleri olacaktır. Bunlar nihai olarak ileriki bölümlerde ilgili yanıtları oluşturmak için kullanılacaktır.


Nanonets tarafından siz ve ekipleriniz için tasarlanan yapay zeka odaklı iş akışı oluşturucumuzla manuel görevleri ve iş akışlarını otomatikleştirin.
Modül III: Temsilciler
LangChain, zincir fikrini tamamen yeni bir seviyeye taşıyan "Ajanlar" adı verilen güçlü bir konsepti tanıtıyor. Aracılar, gerçekleştirilecek eylem sıralarını dinamik olarak belirlemek için dil modellerinden yararlanır, bu da onları inanılmaz derecede çok yönlü ve uyarlanabilir hale getirir. Eylemlerin kodla kodlandığı geleneksel zincirlerden farklı olarak aracılar, hangi eylemlerin hangi sırayla gerçekleştirileceğine karar vermek için akıl yürütme motorları olarak dil modellerini kullanır.
Ajan karar vermede sorumlu temel bileşendir. Bir dil modelinin gücünden ve belirli bir hedefe ulaşmak için sonraki adımları belirleme isteminden yararlanır. Bir aracının girdileri genellikle şunları içerir:
- Araçlar: Mevcut araçların açıklamaları (bu konuda daha sonra daha fazla bilgi verilecektir).
- Kullanıcı Girişi: Kullanıcının üst düzey hedefi veya sorgusu.
- Ara Adımlar: Geçerli kullanıcı girişine ulaşmak için yürütülen (eylem, araç çıkışı) çiftlerinin geçmişi.
Bir aracının çıktısı bir sonraki olabilir aksiyon harekete geçmek (TemsilciAksiyonları) veya final yanıt kullanıcıya göndermek için (AjanFinish). bir aksiyon belirtir araç ve giriş bu araç için.
Tools
Araçlar, bir aracının dünyayla etkileşimde bulunmak için kullanabileceği arayüzlerdir. Aracıların web'de arama yapma, kabuk komutlarını çalıştırma veya harici API'lere erişme gibi çeşitli görevleri gerçekleştirmesine olanak tanır. LangChain'de araçlar, temsilcilerin yeteneklerini genişletmek ve farklı görevleri yerine getirmelerini sağlamak için gereklidir.
LangChain'deki araçları kullanmak için aşağıdaki pasajı kullanarak bunları yükleyebilirsiniz:
from langchain.agents import load_tools tool_names = [...]
tools = load_tools(tool_names)
Bazı araçların başlatılması için temel Dil Modeli (LLM) gerekebilir. Bu gibi durumlarda, bir LLM'yi de geçebilirsiniz:
from langchain.agents import load_tools tool_names = [...]
llm = ...
tools = load_tools(tool_names, llm=llm)
Bu kurulum, çeşitli araçlara erişmenize ve bunları temsilcinizin iş akışlarına entegre etmenize olanak tanır. Kullanım belgelerine sahip araçların tam listesi: okuyun.
Bazı Araç örneklerine bakalım.
DuckDuckGo
DuckDuckGo aracı, arama motorunu kullanarak web aramaları yapmanızı sağlar. İşte nasıl kullanılacağı:
from langchain.tools import DuckDuckGoSearchRun
search = DuckDuckGoSearchRun()
search.run("manchester united vs luton town match summary")

DataForSeo
DataForSeo araç seti, DataForSeo API'sini kullanarak arama motoru sonuçlarını elde etmenize olanak tanır. Bu araç setini kullanmak için API kimlik bilgilerinizi ayarlamanız gerekir. Kimlik bilgilerini nasıl yapılandıracağınız aşağıda açıklanmıştır:
import os os.environ["DATAFORSEO_LOGIN"] = "<your_api_access_username>"
os.environ["DATAFORSEO_PASSWORD"] = "<your_api_access_password>"
Kimlik bilgileriniz ayarlandıktan sonra bir DataForSeoAPIWrapper API'ye erişim aracı:
from langchain.utilities.dataforseo_api_search import DataForSeoAPIWrapper wrapper = DataForSeoAPIWrapper() result = wrapper.run("Weather in Los Angeles")
The DataForSeoAPIWrapper araç, çeşitli kaynaklardan arama motoru sonuçlarını alır.
JSON yanıtında döndürülen sonuçların ve alanların türünü özelleştirebilirsiniz. Örneğin, sonuç türlerini ve alanlarını belirtebilir ve döndürülecek en iyi sonuçların sayısı için maksimum sayıyı ayarlayabilirsiniz:
json_wrapper = DataForSeoAPIWrapper( json_result_types=["organic", "knowledge_graph", "answer_box"], json_result_fields=["type", "title", "description", "text"], top_count=3,
) json_result = json_wrapper.results("Bill Gates")
Bu örnek, sonuç türlerini ve alanlarını belirterek ve sonuç sayısını sınırlayarak JSON yanıtını özelleştirir.
Ayrıca API sarmalayıcıya ek parametreler ileterek arama sonuçlarınızın konumunu ve dilini de belirleyebilirsiniz:
customized_wrapper = DataForSeoAPIWrapper( top_count=10, json_result_types=["organic", "local_pack"], json_result_fields=["title", "description", "type"], params={"location_name": "Germany", "language_code": "en"},
) customized_result = customized_wrapper.results("coffee near me")
Konum ve dil parametrelerini sağlayarak arama sonuçlarınızı belirli bölgelere ve dillere göre özelleştirebilirsiniz.
Kullanmak istediğiniz arama motorunu seçme esnekliğine sahipsiniz. İstediğiniz arama motorunu belirtmeniz yeterlidir:
customized_wrapper = DataForSeoAPIWrapper( top_count=10, json_result_types=["organic", "local_pack"], json_result_fields=["title", "description", "type"], params={"location_name": "Germany", "language_code": "en", "se_name": "bing"},
) customized_result = customized_wrapper.results("coffee near me")
Bu örnekte arama, arama motoru olarak Bing'i kullanacak şekilde özelleştirilmiştir.
API sarmalayıcı ayrıca gerçekleştirmek istediğiniz arama türünü belirtmenize de olanak tanır. Örneğin, bir harita araması gerçekleştirebilirsiniz:
maps_search = DataForSeoAPIWrapper( top_count=10, json_result_fields=["title", "value", "address", "rating", "type"], params={ "location_coordinate": "52.512,13.36,12z", "language_code": "en", "se_type": "maps", },
) maps_search_result = maps_search.results("coffee near me")
Bu, haritalarla ilgili bilgileri almak için aramayı özelleştirir.
Kabuk (bash)
Kabuk araç seti, aracıların kabuk ortamına erişmesini sağlayarak onların kabuk komutlarını yürütmesine olanak tanır. Bu özellik güçlüdür ancak özellikle korumalı alan içeren ortamlarda dikkatli kullanılmalıdır. Kabuk aracını şu şekilde kullanabilirsiniz:
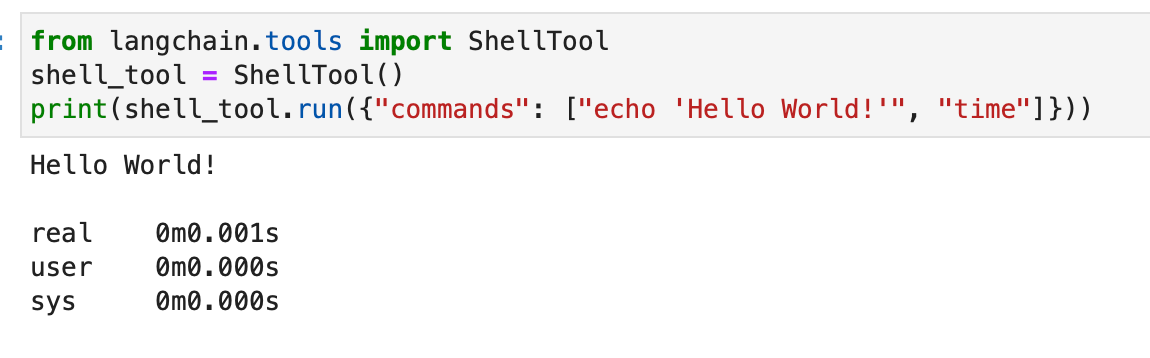
from langchain.tools import ShellTool shell_tool = ShellTool() result = shell_tool.run({"commands": ["echo 'Hello World!'", "time"]})
Bu örnekte, Kabuk aracı iki kabuk komutunu çalıştırıyor: "Merhaba Dünya!" ve geçerli saati gösteriyor.
Daha karmaşık görevleri gerçekleştirmesi için Shell aracını bir aracıya sağlayabilirsiniz. Aşağıda, Shell aracını kullanarak bir web sayfasından bağlantıları getiren bir aracının örneği verilmiştir:
from langchain.agents import AgentType, initialize_agent
from langchain.chat_models import ChatOpenAI llm = ChatOpenAI(temperature=0.1) shell_tool.description = shell_tool.description + f"args {shell_tool.args}".replace( "{", "{{"
).replace("}", "}}")
self_ask_with_search = initialize_agent( [shell_tool], llm, agent=AgentType.CHAT_ZERO_SHOT_REACT_DESCRIPTION, verbose=True
)
self_ask_with_search.run( "Download the langchain.com webpage and grep for all urls. Return only a sorted list of them. Be sure to use double quotes."
)
Bu senaryoda aracı, bir web sayfasındaki URL'leri almak, filtrelemek ve sıralamak üzere bir dizi komutu yürütmek için Kabuk aracını kullanır.
Sağlanan örnekler LangChain'de bulunan araçlardan bazılarını göstermektedir. Bu araçlar sonuçta aracıların yeteneklerini genişletir (sonraki alt bölümde ele alınacaktır) ve onlara çeşitli görevleri verimli bir şekilde gerçekleştirme gücü verir. Gereksinimlerinize bağlı olarak projenizin ihtiyaçlarına en uygun araçları ve araç kitlerini seçebilir ve bunları temsilcinizin iş akışlarına entegre edebilirsiniz.
Temsilcilere Geri Dön
Şimdi acentelere geçelim.
AgentExecutor, bir aracının çalışma zamanı ortamıdır. Temsilciyi çağırmak, seçtiği eylemleri yürütmek, eylem çıktılarını temsilciye geri iletmek ve aracı bitene kadar süreci tekrarlamaktan sorumludur. Sahte kodda AgentExecutor şöyle görünebilir:
next_action = agent.get_action(...)
while next_action != AgentFinish: observation = run(next_action) next_action = agent.get_action(..., next_action, observation)
return next_action
AgentExecutor, aracının var olmayan bir aracı seçtiği durumlarla ilgilenmek, araç hatalarını ele almak, aracı tarafından üretilen çıktıları yönetmek ve tüm düzeylerde günlük kaydı ve gözlemlenebilirlik sağlamak gibi çeşitli karmaşıklıkları yönetir.
AgentExecutor sınıfı, LangChain'deki birincil aracı çalışma zamanı olmasına rağmen, aşağıdakiler dahil olmak üzere desteklenen daha deneysel başka çalışma zamanları da vardır:
- Planla ve Yürüt Aracısı
- Bebek AGİ'si
- Otomatik GPT
Aracı çerçevesini daha iyi anlamak için sıfırdan temel bir aracı oluşturalım ve ardından önceden oluşturulmuş aracıları keşfetmeye geçelim.
Aracıyı oluşturmaya dalmadan önce bazı temel terminolojiyi ve şemayı yeniden gözden geçirmek önemlidir:
- TemsilciAksiyonu: Bu, bir aracının gerçekleştirmesi gereken eylemi temsil eden bir veri sınıfıdır. Şunlardan oluşur:
toolözellik (çağırılacak aracın adı) ve birtool_inputözellik (bu aracın girişi). - AjanFinish: Bu veri sınıfı, aracının görevini tamamladığını ve kullanıcıya bir yanıt döndürmesi gerektiğini belirtir. Genellikle yanıt metnini içeren bir anahtar “çıktı” ile birlikte, dönüş değerlerinin bir sözlüğünü içerir.
- Ara Adımlar: Bunlar önceki aracı eylemlerinin ve karşılık gelen çıktıların kayıtlarıdır. Bağlamın aracının gelecekteki yinelemelerine aktarılması açısından çok önemlidirler.
Örneğimizde aracımızı oluşturmak için OpenAI İşlev Çağrısını kullanacağız. Bu yaklaşım etmen oluşturma açısından güvenilirdir. Bir kelimenin uzunluğunu hesaplayan basit bir araç oluşturarak başlayacağız. Bu araç kullanışlıdır çünkü dil modelleri bazen kelime uzunluklarını sayarken tokenizasyon nedeniyle hata yapabilir.
Öncelikle aracıyı kontrol etmek için kullanacağımız dil modelini yükleyelim:
from langchain.chat_models import ChatOpenAI llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
Modeli kelime uzunluğu hesaplamasıyla test edelim:
llm.invoke("how many letters in the word educa?")
Yanıt, “educa” kelimesindeki harf sayısını belirtmelidir.
Daha sonra, bir kelimenin uzunluğunu hesaplamak için basit bir Python işlevi tanımlayacağız:
from langchain.agents import tool @tool
def get_word_length(word: str) -> int: """Returns the length of a word.""" return len(word)
Adlı bir araç oluşturduk get_word_length Bu, girdi olarak bir kelimeyi alır ve uzunluğunu döndürür.
Şimdi aracı için istemi oluşturalım. İstem, aracıya çıktının nasıl gerekçelendirileceği ve biçimlendirileceği konusunda talimat verir. Bizim durumumuzda, minimum düzeyde talimat gerektiren OpenAI İşlev Çağrısı'nı kullanıyoruz. İstemi, kullanıcı girişi ve aracı karalama defteri için yer tutucularla tanımlayacağız:
from langchain.prompts import ChatPromptTemplate, MessagesPlaceholder prompt = ChatPromptTemplate.from_messages( [ ( "system", "You are a very powerful assistant but not great at calculating word lengths.", ), ("user", "{input}"), MessagesPlaceholder(variable_name="agent_scratchpad"), ]
)
Peki temsilci hangi araçları kullanabileceğini nasıl biliyor? İşlevlerin ayrı olarak iletilmesini gerektiren OpenAI işlev çağırma dili modellerine güveniyoruz. Araçlarımızı aracıya sağlamak için bunları OpenAI işlev çağrıları olarak biçimlendireceğiz:
from langchain.tools.render import format_tool_to_openai_function llm_with_tools = llm.bind(functions=[format_tool_to_openai_function(t) for t in tools])
Artık girdi eşlemelerini tanımlayarak ve bileşenleri bağlayarak aracıyı oluşturabiliriz:
Bu LCEL dilidir. Bu konuyu daha sonra detaylı olarak tartışacağız.
from langchain.agents.format_scratchpad import format_to_openai_function_messages
from langchain.agents.output_parsers import OpenAIFunctionsAgentOutputParser agent = ( { "input": lambda x: x["input"], "agent_scratchpad": lambda x: format_to_openai _function_messages( x["intermediate_steps"] ), } | prompt | llm_with_tools | OpenAIFunctionsAgentOutputParser()
)
Kullanıcı girdisini anlayan, mevcut araçları kullanan ve çıktıyı biçimlendiren aracımızı oluşturduk. Şimdi onunla etkileşime geçelim:
agent.invoke({"input": "how many letters in the word educa?", "intermediate_steps": []})
Temsilci, gerçekleştirilecek bir sonraki eylemi belirten bir AgentAction ile yanıt vermelidir.
Aracıyı oluşturduk ancak şimdi onun için bir çalışma zamanı yazmamız gerekiyor. En basit çalışma zamanı sürekli olarak aracıyı çağıran, eylemleri yürüten ve aracı işini bitirene kadar tekrar eden çalışma zamanıdır. İşte bir örnek:
from langchain.schema.agent import AgentFinish user_input = "how many letters in the word educa?"
intermediate_steps = [] while True: output = agent.invoke( { "input": user_input, "intermediate_steps": intermediate_steps, } ) if isinstance(output, AgentFinish): final_result = output.return_values["output"] break else: print(f"TOOL NAME: {output.tool}") print(f"TOOL INPUT: {output.tool_input}") tool = {"get_word_length": get_word_length}[output.tool] observation = tool.run(output.tool_input) intermediate_steps.append((output, observation)) print(final_result)
Bu döngüde, aracıyı bitirene kadar tekrar tekrar aracıyı ararız, eylemleri gerçekleştiririz ve ara adımları güncelleriz. Ayrıca döngü içindeki araç etkileşimlerini de ele alıyoruz.

Bu süreci basitleştirmek için LangChain, aracı yürütmeyi kapsayan ve hata yönetimi, erken durdurma, izleme ve diğer iyileştirmeler sunan AgentExecutor sınıfını sağlar. Agent ile etkileşim kurmak için AgentExecutor'u kullanalım:
from langchain.agents import AgentExecutor agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True) agent_executor.invoke({"input": "how many letters in the word educa?"})
AgentExecutor, yürütme sürecini basitleştirir ve aracıyla etkileşime geçmek için uygun bir yol sağlar.
Bellek ayrıca daha sonra ayrıntılı olarak ele alınacaktır.
Şu ana kadar oluşturduğumuz aracı durum bilgisine sahip değil, yani önceki etkileşimleri hatırlamıyor. Takip sorularını ve konuşmaları etkinleştirmek için aracıya bellek eklememiz gerekir. Bu iki adımı içerir:
- Sohbet geçmişini depolamak için istemde bir bellek değişkeni ekleyin.
- Etkileşimler sırasında sohbet geçmişini takip edin.
İsteme bir bellek yer tutucusu ekleyerek başlayalım:
from langchain.prompts import MessagesPlaceholder MEMORY_KEY = "chat_history"
prompt = ChatPromptTemplate.from_messages( [ ( "system", "You are a very powerful assistant but not great at calculating word lengths.", ), MessagesPlaceholder(variable_name=MEMORY_KEY), ("user", "{input}"), MessagesPlaceholder(variable_name="agent_scratchpad"), ]
)
Şimdi sohbet geçmişini takip etmek için bir liste oluşturun:
from langchain.schema.messages import HumanMessage, AIMessage chat_history = []
Aracı oluşturma adımında belleği de dahil edeceğiz:
agent = ( { "input": lambda x: x["input"], "agent_scratchpad": lambda x: format_to_openai_function_messages( x["intermediate_steps"] ), "chat_history": lambda x: x["chat_history"], } | prompt | llm_with_tools | OpenAIFunctionsAgentOutputParser()
)
Artık aracıyı çalıştırırken sohbet geçmişini güncellediğinizden emin olun:
input1 = "how many letters in the word educa?"
result = agent_executor.invoke({"input": input1, "chat_history": chat_history})
chat_history.extend([ HumanMessage(content=input1), AIMessage(content=result["output"]),
])
agent_executor.invoke({"input": "is that a real word?", "chat_history": chat_history})
Bu, temsilcinin bir konuşma geçmişi tutmasına ve önceki etkileşimlere dayalı olarak takip eden soruları yanıtlamasına olanak tanır.
Tebrikler! LangChain'de ilk uçtan uca aracınızı başarıyla oluşturdunuz ve yürüttünüz. LangChain'in yeteneklerini daha derinlemesine incelemek için şunları keşfedebilirsiniz:
- Farklı aracı türleri desteklenir.
- Önceden Oluşturulmuş Aracılar
- Araçlar ve araç entegrasyonlarıyla nasıl çalışılır.
Temsilci Türleri
LangChain, her biri belirli kullanım durumlarına uygun çeşitli aracı türleri sunar. İşte mevcut acentelerden bazıları:
- Sıfır atışlı ReAct: Bu aracı, araçları yalnızca açıklamalarına göre seçmek için ReAct çerçevesini kullanır. Her araç için açıklamalar gerektirir ve oldukça çok yönlüdür.
- Yapılandırılmış giriş ReAct: Bu aracı, çoklu giriş araçlarını yönetir ve bir web tarayıcısında gezinmek gibi karmaşık görevler için uygundur. Yapılandırılmış girdi için bir aracın argüman şemasını kullanır.
- OpenAI İşlevleri: İşlev çağrısı için ince ayarı yapılmış modeller için özel olarak tasarlanan bu aracı, gpt-3.5-turbo-0613 ve gpt-4-0613 gibi modellerle uyumludur. Yukarıdaki ilk aracımızı oluşturmak için bunu kullandık.
- konuşma: Konuşma ortamları için tasarlanan bu aracı, araç seçimi için ReAct'i kullanır ve önceki etkileşimleri hatırlamak için hafızayı kullanır.
- Aramayla kendi kendinize sorun: Bu temsilci, sorulara gerçek yanıtlar arayan tek bir araca, "Orta Düzey Yanıt"a güveniyor. Arama kağıdıyla orijinal kendi kendine sormaya eşdeğerdir.
- ReAct belge deposu: Bu aracı, ReAct çerçevesini kullanarak bir belge deposuyla etkileşime girer. "Arama" ve "Arama" araçlarını gerektirir ve orijinal ReAct makalesinin Wikipedia örneğine benzer.
LangChain'de ihtiyaçlarınıza en uygun olanı bulmak için bu temsilci türlerini keşfedin. Bu aracılar, eylemleri gerçekleştirmek ve yanıtlar oluşturmak için içlerindeki araç kümesini bağlamanıza olanak tanır. Daha fazlasını öğrenin Buradaki araçlarla kendi aracınızı nasıl oluşturabilirsiniz?.
Önceden Oluşturulmuş Aracılar
LangChain'de bulunan önceden oluşturulmuş aracılara odaklanarak aracıları keşfetmeye devam edelim.
Gmail
LangChain, LangChain e-postanızı Gmail API'sine bağlamanıza olanak tanıyan bir Gmail araç seti sunar. Başlamak için Gmail API belgelerinde açıklanan kimlik bilgilerinizi ayarlamanız gerekir. İndirdikten sonra credentials.json dosya, Gmail API'sini kullanmaya devam edebilirsiniz. Ayrıca aşağıdaki komutları kullanarak gerekli bazı kitaplıkları yüklemeniz gerekir:
pip install --upgrade google-api-python-client > /dev/null
pip install --upgrade google-auth-oauthlib > /dev/null
pip install --upgrade google-auth-httplib2 > /dev/null
pip install beautifulsoup4 > /dev/null # Optional for parsing HTML messages
Gmail araç setini aşağıdaki şekilde oluşturabilirsiniz:
from langchain.agents.agent_toolkits import GmailToolkit toolkit = GmailToolkit()
Kimlik doğrulamayı ihtiyaçlarınıza göre de özelleştirebilirsiniz. Perde arkasında aşağıdaki yöntemler kullanılarak bir googleapi kaynağı oluşturulur:
from langchain.tools.gmail.utils import build_resource_service, get_gmail_credentials credentials = get_gmail_credentials( token_file="token.json", scopes=["https://mail.google.com/"], client_secrets_file="credentials.json",
)
api_resource = build_resource_service(credentials=credentials)
toolkit = GmailToolkit(api_resource=api_resource)
Araç seti, bir aracı içinde kullanılabilecek çeşitli araçlar sunar; örneğin:
GmailCreateDraft: Belirtilen mesaj alanlarıyla bir taslak e-posta oluşturun.GmailSendMessage: E-posta mesajları gönderin.GmailSearch: E-posta mesajlarını veya konu dizilerini arayın.GmailGetMessage: Mesaj kimliğine göre bir e-posta alın.GmailGetThread: E-posta mesajlarını arayın.
Bu araçları bir aracı içinde kullanmak için aracıyı aşağıdaki şekilde başlatabilirsiniz:
from langchain.llms import OpenAI
from langchain.agents import initialize_agent, AgentType llm = OpenAI(temperature=0)
agent = initialize_agent( tools=toolkit.get_tools(), llm=llm, agent=AgentType.STRUCTURED_CHAT_ZERO_SHOT_REACT_DESCRIPTION,
)
Bu araçların nasıl kullanılabileceğine dair birkaç örnek:
- Düzenlemek üzere bir Gmail taslağı oluşturun:
agent.run( "Create a gmail draft for me to edit of a letter from the perspective of a sentient parrot " "who is looking to collaborate on some research with her estranged friend, a cat. " "Under no circumstances may you send the message, however."
)
- Taslaklarınızda en son e-postayı arayın:
agent.run("Could you search in my drafts for the latest email?")
Bu örnekler, LangChain'in Gmail araç setinin bir aracı içindeki yeteneklerini gösterir ve Gmail ile programlı olarak etkileşimde bulunmanıza olanak tanır.
SQL Veritabanı Aracısı
Bu bölüm, SQL veritabanlarıyla, özellikle de Chinook veritabanıyla etkileşimde bulunmak üzere tasarlanmış bir aracıya genel bakış sağlar. Bu aracı, bir veritabanı hakkındaki genel soruları yanıtlayabilir ve hataları düzeltebilir. Lütfen bunun hala aktif olarak geliştirilme aşamasında olduğunu ve tüm yanıtların doğru olmayabileceğini unutmayın. Veritabanınızda DML bildirimleri gerçekleştirebileceğinden, hassas veriler üzerinde çalıştırırken dikkatli olun.
Bu aracıyı kullanmak için onu aşağıdaki şekilde başlatabilirsiniz:
from langchain.agents import create_sql_agent
from langchain.agents.agent_toolkits import SQLDatabaseToolkit
from langchain.sql_database import SQLDatabase
from langchain.llms.openai import OpenAI
from langchain.agents import AgentExecutor
from langchain.agents.agent_types import AgentType
from langchain.chat_models import ChatOpenAI db = SQLDatabase.from_uri("sqlite:///../../../../../notebooks/Chinook.db")
toolkit = SQLDatabaseToolkit(db=db, llm=OpenAI(temperature=0)) agent_executor = create_sql_agent( llm=OpenAI(temperature=0), toolkit=toolkit, verbose=True, agent_type=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
)
Bu aracı aşağıdakiler kullanılarak başlatılabilir: ZERO_SHOT_REACT_DESCRIPTION ajan türü. Sorulara cevap vermek ve açıklamalar sağlamak için tasarlanmıştır. Alternatif olarak, aracıyı kullanarak başlatabilirsiniz. OPENAI_FUNCTIONS Daha önceki müşterimizde kullandığımız OpenAI'nin GPT-3.5-turbo modeline sahip aracı türü.
Feragatname
- Sorgu zinciri ekleme/güncelleme/silme sorguları oluşturabilir. Dikkatli olun ve gerekirse özel bir istem kullanın veya yazma izinleri olmayan bir SQL kullanıcısı oluşturun.
- "Mümkün olan en büyük sorguyu çalıştırın" gibi belirli sorguları çalıştırmanın, özellikle milyonlarca satır içeriyorsa SQL veritabanınıza aşırı yük getirebileceğini unutmayın.
- Veri ambarı odaklı veritabanları genellikle kaynak kullanımını sınırlamak için kullanıcı düzeyindeki kotaları destekler.
Temsilciden "çalma listesi parçası" tablosu gibi bir tabloyu tanımlamasını isteyebilirsiniz. İşte bunun nasıl yapılacağına dair bir örnek:
agent_executor.run("Describe the playlisttrack table")
Aracı, tablonun şeması ve örnek satırlar hakkında bilgi sağlayacaktır.
Yanlışlıkla var olmayan bir tablo hakkında soru sorarsanız aracı, en yakın eşleşen tabloyu kurtarabilir ve bu tablo hakkında bilgi sağlayabilir. Örneğin:
agent_executor.run("Describe the playlistsong table")
Temsilci en yakın eşleşen tabloyu bulacak ve onun hakkında bilgi verecektir.
Ayrıca aracıdan veritabanında sorgu çalıştırmasını da isteyebilirsiniz. Örneğin:
agent_executor.run("List the total sales per country. Which country's customers spent the most?")
Temsilci sorguyu yürütecek ve toplam satışı en yüksek olan ülke gibi sonucu sağlayacaktır.
Her bir çalma listesindeki toplam parça sayısını almak için aşağıdaki sorguyu kullanabilirsiniz:
agent_executor.run("Show the total number of tracks in each playlist. The Playlist name should be included in the result.")
Temsilci, çalma listesi adlarını karşılık gelen toplam parça sayısıyla birlikte döndürecektir.
Agent hatalarla karşılaştığında durumu düzeltebilir ve doğru yanıtlar verebilir. Örneğin:
agent_executor.run("Who are the top 3 best selling artists?")
Başlangıçta bir hatayla karşılaştıktan sonra bile temsilci gerekli ayarlamaları yapacak ve doğru cevabı verecektir; bu durumda bu, en çok satan 3 sanatçı olacaktır.
Pandalar DataFrame Aracısı
Bu bölümde, soru yanıtlama amacıyla Pandas DataFrames ile etkileşimde bulunmak üzere tasarlanmış bir aracı tanıtılmaktadır. Lütfen bu aracının, bir dil modeli (LLM) tarafından oluşturulan Python kodunu yürütmek için Python aracısını kullandığını unutmayın. LLM tarafından oluşturulan kötü amaçlı Python kodunun neden olabileceği olası zararları önlemek için bu aracıyı kullanırken dikkatli olun.
Pandas DataFrame aracısını aşağıdaki şekilde başlatabilirsiniz:
from langchain_experimental.agents.agent_toolkits import create_pandas_dataframe_agent
from langchain.chat_models import ChatOpenAI
from langchain.agents.agent_types import AgentType from langchain.llms import OpenAI
import pandas as pd df = pd.read_csv("titanic.csv") # Using ZERO_SHOT_REACT_DESCRIPTION agent type
agent = create_pandas_dataframe_agent(OpenAI(temperature=0), df, verbose=True) # Alternatively, using OPENAI_FUNCTIONS agent type
# agent = create_pandas_dataframe_agent(
# ChatOpenAI(temperature=0, model="gpt-3.5-turbo-0613"),
# df,
# verbose=True,
# agent_type=AgentType.OPENAI_FUNCTIONS,
# )
Temsilciden DataFrame'deki satır sayısını saymasını isteyebilirsiniz:
agent.run("how many rows are there?")
Aracı kodu yürütecek df.shape[0] ve "Veri çerçevesinde 891 satır var" gibi bir yanıt verin.
Ayrıca temsilciden, 3'ten fazla kardeşi olan kişilerin sayısını bulmak gibi belirli kriterlere göre satırları filtrelemesini isteyebilirsiniz:
agent.run("how many people have more than 3 siblings")
Aracı kodu yürütecek df[df['SibSp'] > 3].shape[0] ve “30 kişinin 3'ten fazla kardeşi var” gibi bir cevap verin.
Ortalama yaşın karekökünü hesaplamak istiyorsanız acenteye şunları sorabilirsiniz:
agent.run("whats the square root of the average age?")
Temsilci ortalama yaşı aşağıdakileri kullanarak hesaplayacaktır: df['Age'].mean() ve sonra kullanarak karekökü hesaplayın math.sqrt(). “Yaş ortalamasının karekökü 5.449689683556195” gibi bir cevabı verecektir.
DataFrame'in bir kopyasını oluşturalım ve eksik yaş değerleri ortalama yaşla doldurulsun:
df1 = df.copy()
df1["Age"] = df1["Age"].fillna(df1["Age"].mean())
Ardından aracıyı her iki DataFrame ile başlatabilir ve ona bir soru sorabilirsiniz:
agent = create_pandas_dataframe_agent(OpenAI(temperature=0), [df, df1], verbose=True)
agent.run("how many rows in the age column are different?")
Temsilci, her iki DataFrame'deki yaş sütunlarını karşılaştıracak ve "yaş sütunundaki 177 satır farklı" gibi bir yanıt sağlayacaktır.
Jira Araç Seti
Bu bölümde, aracıların bir Jira örneğiyle etkileşim kurmasına olanak tanıyan Jira araç setinin nasıl kullanılacağı açıklanmaktadır. Bu araç setini kullanarak sorunları aramak ve sorun oluşturmak gibi çeşitli eylemleri gerçekleştirebilirsiniz. Atlassian-python-api kütüphanesini kullanır. Bu araç setini kullanmak için Jira örneğiniz için JIRA_API_TOKEN, JIRA_USERNAME ve JIRA_INSTANCE_URL dahil ortam değişkenlerini ayarlamanız gerekir. Ayrıca OpenAI API anahtarınızı bir ortam değişkeni olarak ayarlamanız gerekebilir.
Başlamak için atlassian-python-api kitaplığını yükleyin ve gerekli ortam değişkenlerini ayarlayın:
%pip install atlassian-python-api import os
from langchain.agents import AgentType
from langchain.agents import initialize_agent
from langchain.agents.agent_toolkits.jira.toolkit import JiraToolkit
from langchain.llms import OpenAI
from langchain.utilities.jira import JiraAPIWrapper os.environ["JIRA_API_TOKEN"] = "abc"
os.environ["JIRA_USERNAME"] = "123"
os.environ["JIRA_INSTANCE_URL"] = "https://jira.atlassian.com"
os.environ["OPENAI_API_KEY"] = "xyz" llm = OpenAI(temperature=0)
jira = JiraAPIWrapper()
toolkit = JiraToolkit.from_jira_api_wrapper(jira)
agent = initialize_agent( toolkit.get_tools(), llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True
)
Temsilciye, bir özet ve açıklamayla birlikte belirli bir projede yeni bir sorun oluşturması talimatını verebilirsiniz:
agent.run("make a new issue in project PW to remind me to make more fried rice")
Temsilci, sorunu oluşturmak için gerekli eylemleri gerçekleştirecek ve şöyle bir yanıt sağlayacaktır: "PW projesinde 'Daha fazla kızarmış pilav yapın' özeti ve 'Daha fazla kızarmış pilav yapma hatırlatıcısı' açıklaması içeren yeni bir sorun oluşturuldu."
Bu, doğal dil talimatlarını ve Jira araç setini kullanarak Jira bulut sunucunuzla etkileşim kurmanıza olanak tanır.
Nanonets tarafından siz ve ekipleriniz için tasarlanan yapay zeka odaklı iş akışı oluşturucumuzla manuel görevleri ve iş akışlarını otomatikleştirin.
Modül IV : Zincirler
LangChain, karmaşık uygulamalarda Büyük Dil Modellerini (LLM'ler) kullanmak için tasarlanmış bir araçtır. Yüksek Lisans ve diğer bileşen türleri de dahil olmak üzere bileşen zincirleri oluşturmak için çerçeveler sağlar. İki temel çerçeve
- LangChain İfade Dili (LCEL)
- Eski Zincir arayüzü
LangChain İfade Dili (LCEL), zincirlerin sezgisel birleşimine olanak tanıyan bir sözdizimidir. Akış, eşzamansız çağrılar, toplu işlem, paralelleştirme, yeniden denemeler, geri dönüşler ve izleme gibi gelişmiş özellikleri destekler. Örneğin, aşağıdaki kodda gösterildiği gibi LCEL'de bir bilgi istemi, model ve çıktı ayrıştırıcı oluşturabilirsiniz:
from langchain.prompts import ChatPromptTemplate
from langchain.schema import StrOutputParser model = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
prompt = ChatPromptTemplate.from_messages([ ("system", "You're a very knowledgeable historian who provides accurate and eloquent answers to historical questions."), ("human", "{question}")
])
runnable = prompt | model | StrOutputParser() for chunk in runnable.stream({"question": "What are the seven wonders of the world"}): print(chunk, end="", flush=True)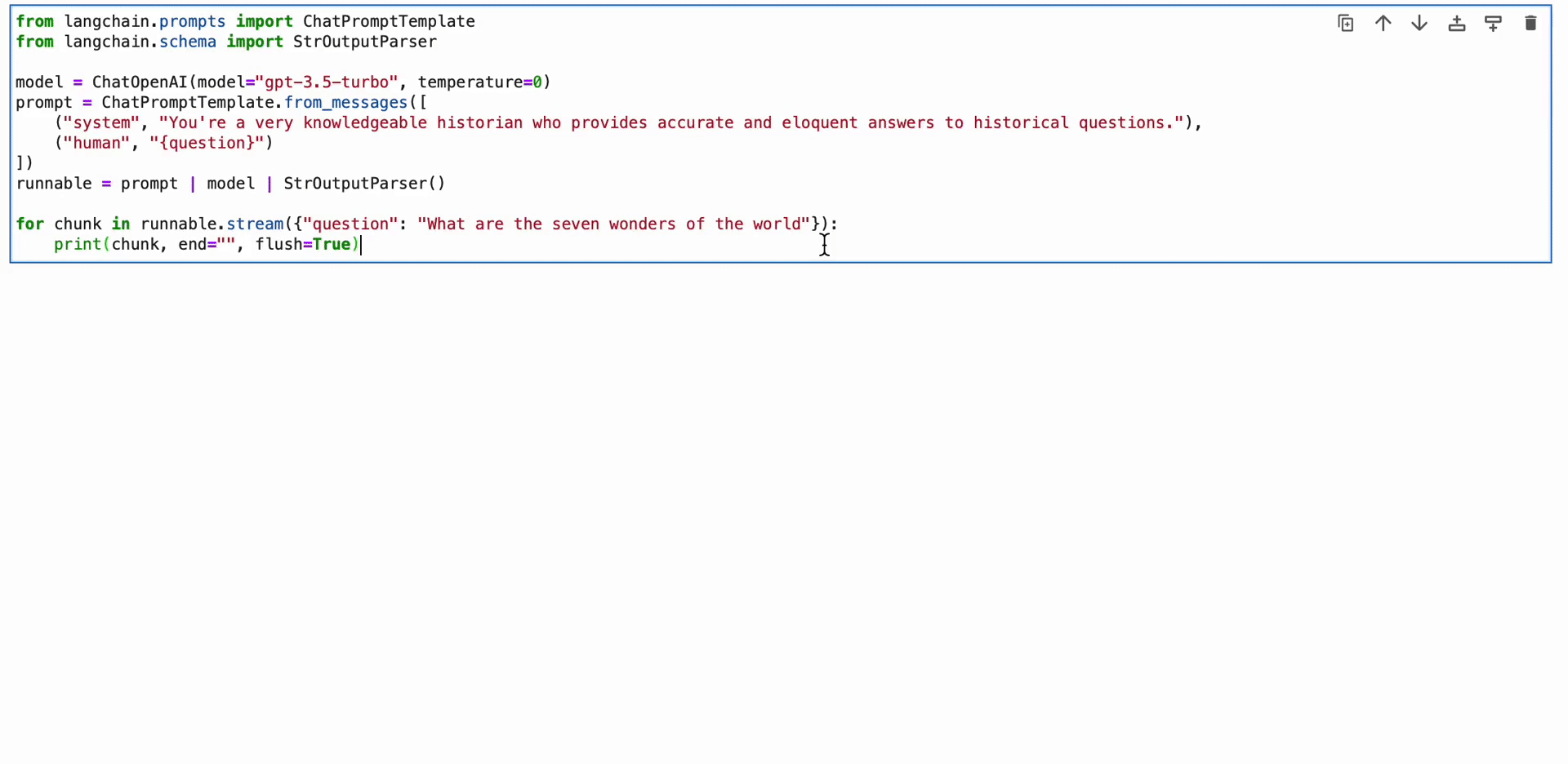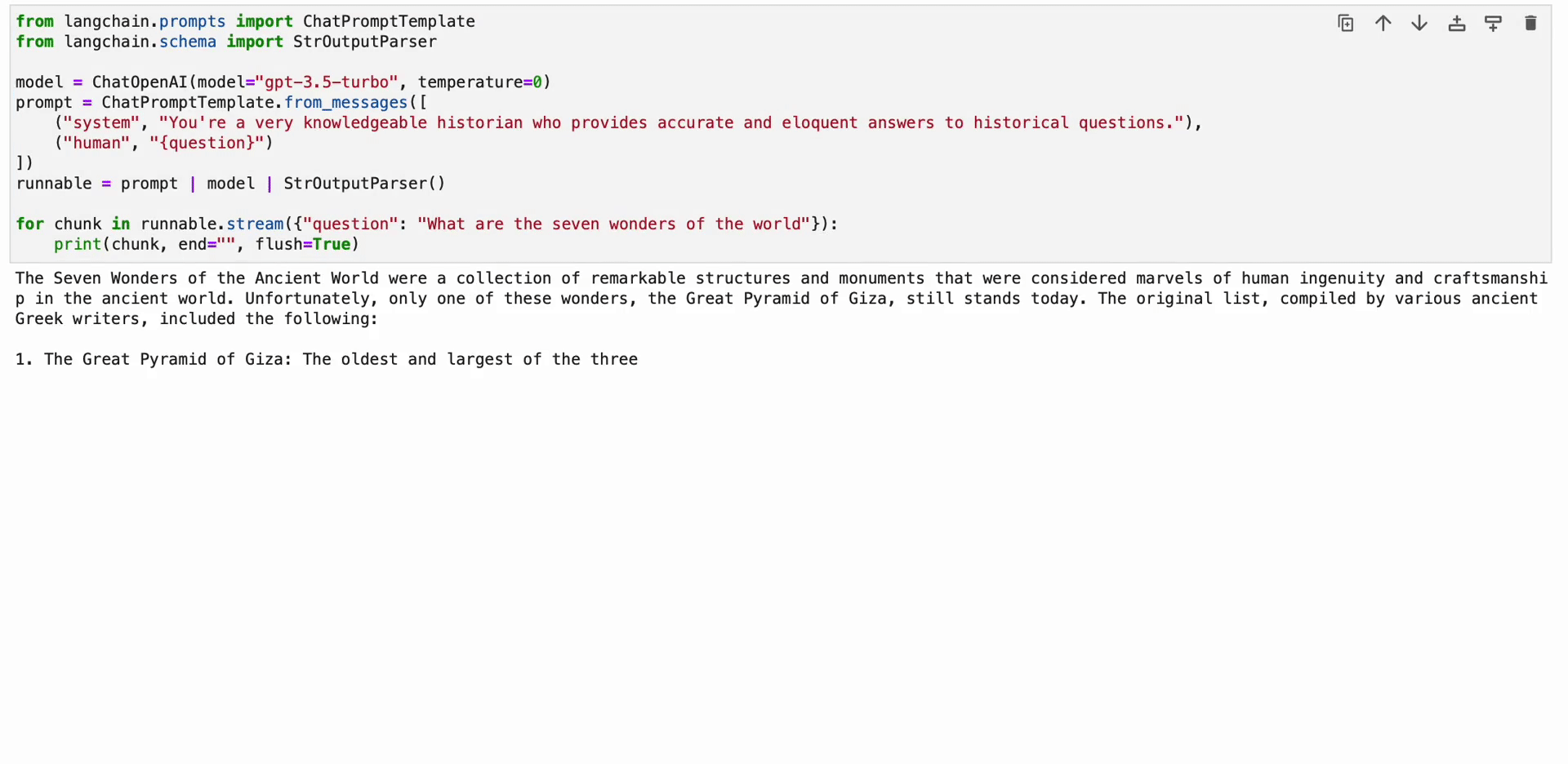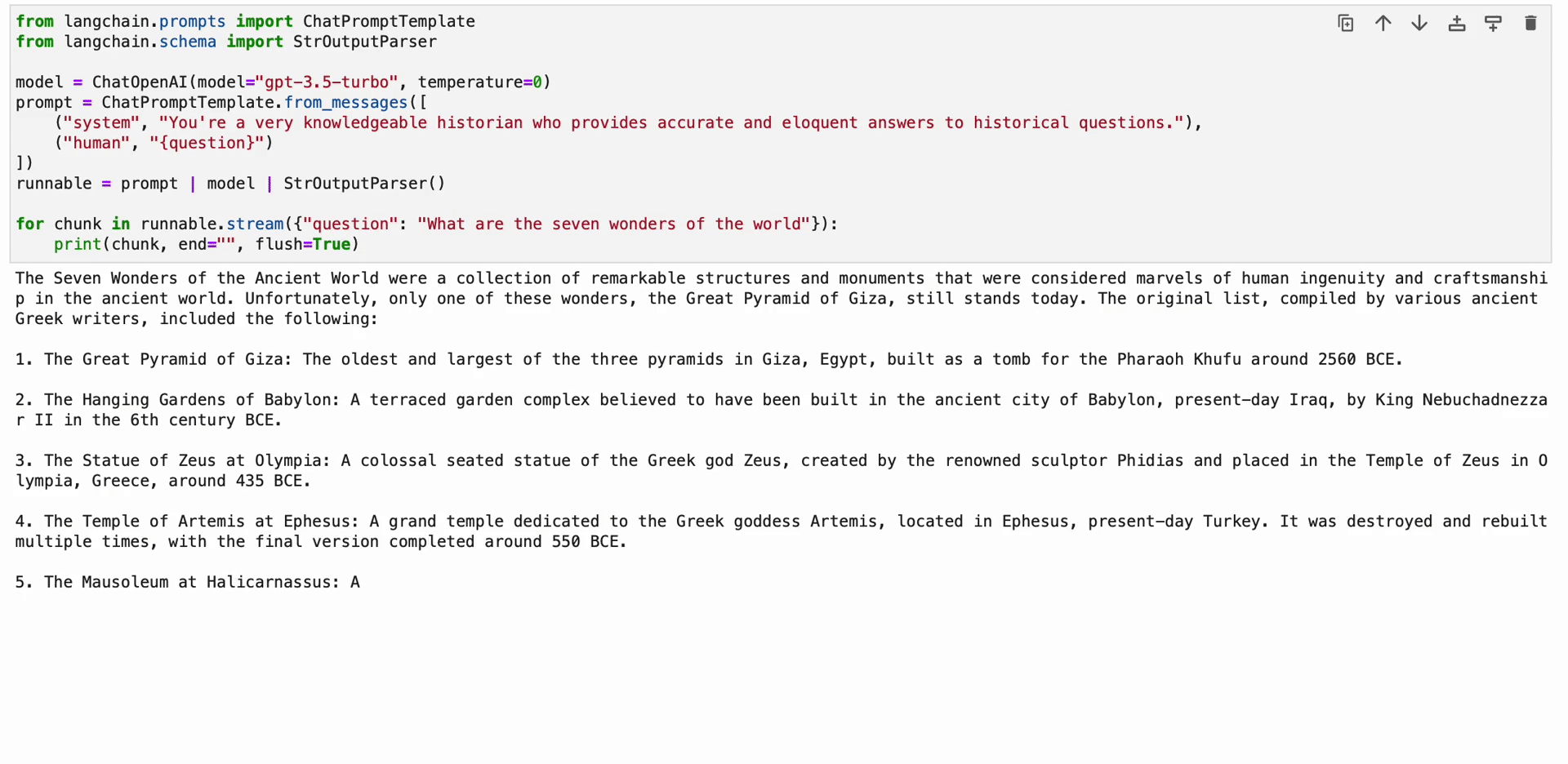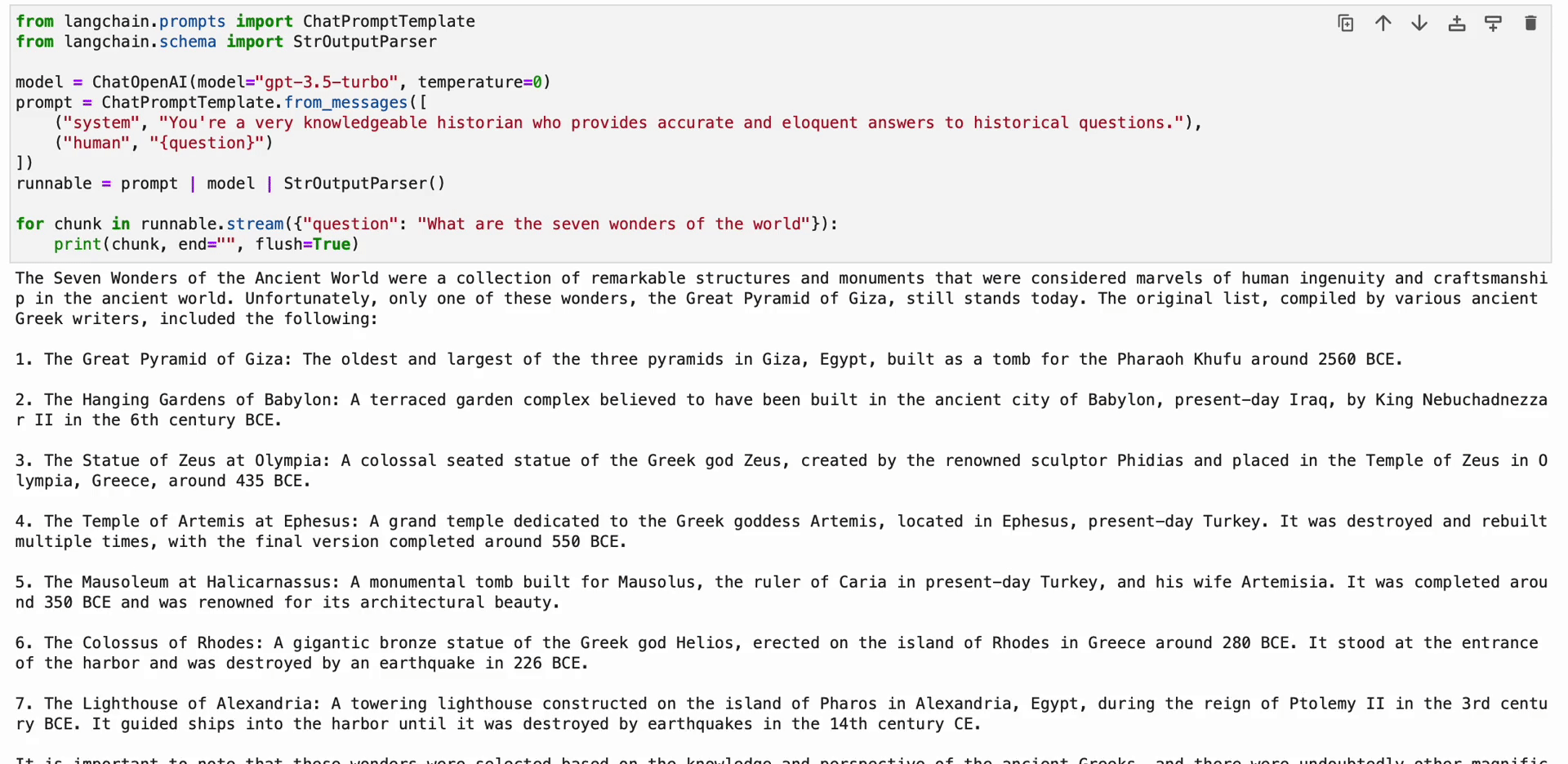
Alternatif olarak LLMChain, bileşenleri oluşturmak için LCEL'e benzer bir seçenektir. LLMChain örneği aşağıdaki gibidir:
from langchain.chains import LLMChain chain = LLMChain(llm=model, prompt=prompt, output_parser=StrOutputParser())
chain.run(question="What are the seven wonders of the world")
LangChain'deki zincirler aynı zamanda bir Memory nesnesinin dahil edilmesiyle de durum bilgisi sahibi olabilir. Bu, aşağıdaki örnekte gösterildiği gibi çağrılar arasında veri kalıcılığına olanak tanır:
from langchain.chains import ConversationChain
from langchain.memory import ConversationBufferMemory conversation = ConversationChain(llm=chat, memory=ConversationBufferMemory())
conversation.run("Answer briefly. What are the first 3 colors of a rainbow?")
conversation.run("And the next 4?")
LangChain ayrıca OpenAI'nin işlev çağıran API'leriyle entegrasyonu da destekler; bu, yapılandırılmış çıktılar elde etmek ve bir zincir içinde işlevleri yürütmek için kullanışlıdır. Yapılandırılmış çıktılar elde etmek için bunları aşağıda gösterildiği gibi Pydantic sınıflarını veya JsonSchema'yı kullanarak belirtebilirsiniz:
from langchain.pydantic_v1 import BaseModel, Field
from langchain.chains.openai_functions import create_structured_output_runnable
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate class Person(BaseModel): name: str = Field(..., description="The person's name") age: int = Field(..., description="The person's age") fav_food: Optional[str] = Field(None, description="The person's favorite food") llm = ChatOpenAI(model="gpt-4", temperature=0)
prompt = ChatPromptTemplate.from_messages([ # Prompt messages here
]) runnable = create_structured_output_runnable(Person, llm, prompt)
runnable.invoke({"input": "Sally is 13"})
Yapılandırılmış çıktılar için LLMChain'i kullanan eski bir yaklaşım da mevcuttur:
from langchain.chains.openai_functions import create_structured_output_chain class Person(BaseModel): name: str = Field(..., description="The person's name") age: int = Field(..., description="The person's age") chain = create_structured_output_chain(Person, llm, prompt, verbose=True)
chain.run("Sally is 13")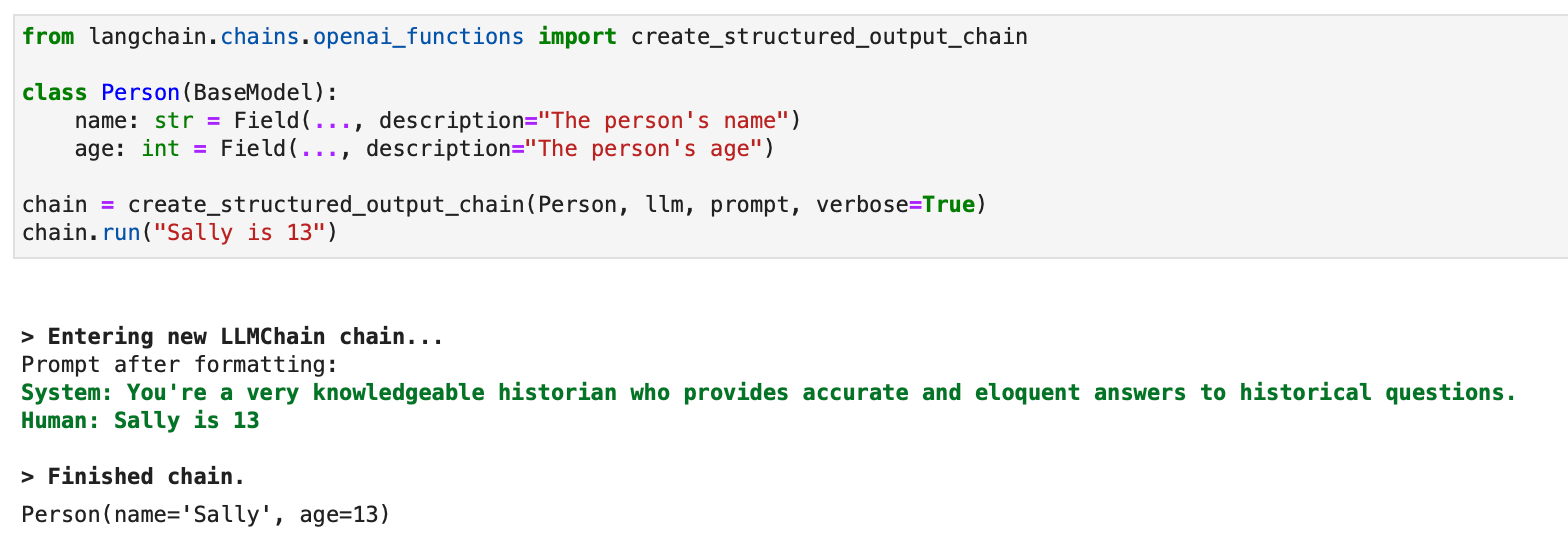
LangChain, farklı amaçlara yönelik çeşitli özel zincirler oluşturmak için OpenAI işlevlerinden yararlanır. Bunlar alıntılarla birlikte çıkarma, etiketleme, OpenAPI ve QA zincirlerini içerir.
Çıkarma bağlamında süreç, yapılandırılmış çıktı zincirine benzer ancak bilgi veya varlık çıkarmaya odaklanır. Etiketlemenin amacı, bir belgeyi duygu, dil, stil, ele alınan konular veya siyasi eğilim gibi sınıflarla etiketlemektir.
LangChain'de etiketlemenin nasıl çalıştığına dair bir örnek bir Python koduyla gösterilebilir. Süreç gerekli paketlerin kurulması ve ortamın ayarlanmasıyla başlar:
pip install langchain openai
# Set env var OPENAI_API_KEY or load from a .env file:
# import dotenv
# dotenv.load_dotenv() from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.chains import create_tagging_chain, create_tagging_chain_pydantic
Etiketleme şeması, özellikleri ve bunların beklenen türlerini belirterek tanımlanır:
schema = { "properties": { "sentiment": {"type": "string"}, "aggressiveness": {"type": "integer"}, "language": {"type": "string"}, }
} llm = ChatOpenAI(temperature=0, model="gpt-3.5-turbo-0613")
chain = create_tagging_chain(schema, llm)
Etiketleme zincirini farklı girdilerle çalıştırma örnekleri, modelin duyguları, dilleri ve saldırganlığı yorumlama yeteneğini gösterir:
inp = "Estoy increiblemente contento de haberte conocido! Creo que seremos muy buenos amigos!"
chain.run(inp)
# {'sentiment': 'positive', 'language': 'Spanish'} inp = "Estoy muy enojado con vos! Te voy a dar tu merecido!"
chain.run(inp)
# {'sentiment': 'enojado', 'aggressiveness': 1, 'language': 'es'}
Daha hassas kontrol için şema, olası değerler, açıklamalar ve gerekli özellikler dahil olmak üzere daha spesifik olarak tanımlanabilir. Bu gelişmiş kontrolün bir örneği aşağıda gösterilmektedir:
schema = { "properties": { # Schema definitions here }, "required": ["language", "sentiment", "aggressiveness"],
} chain = create_tagging_chain(schema, llm)
Pydantic şemaları ayrıca etiketleme kriterlerini tanımlamak için de kullanılabilir ve gerekli özellikleri ve türleri belirtmenin Pythonic bir yolunu sağlar:
from enum import Enum
from pydantic import BaseModel, Field class Tags(BaseModel): # Class fields here chain = create_tagging_chain_pydantic(Tags, llm)
Ek olarak, LangChain'in meta veri etiketleyici belge dönüştürücüsü, LangChain Belgelerinden meta verileri çıkarmak için kullanılabilir; etiketleme zincirine benzer işlevsellik sunar ancak bir LangChain Belgesine uygulanır.
Erişim kaynaklarından alıntı yapmak, metinden alıntılar çıkarmak için OpenAI işlevlerini kullanan LangChain'in başka bir özelliğidir. Bu, aşağıdaki kodda gösterilmiştir:
from langchain.chains import create_citation_fuzzy_match_chain
from langchain.chat_models import ChatOpenAI llm = ChatOpenAI(temperature=0, model="gpt-3.5-turbo-0613")
chain = create_citation_fuzzy_match_chain(llm)
# Further code for running the chain and displaying results
LangChain'de, Büyük Dil Modeli (LLM) uygulamalarında zincirleme tipik olarak bir bilgi istemi şablonunun bir Yüksek Lisans ve isteğe bağlı olarak bir çıktı ayrıştırıcıyla birleştirilmesini içerir. Bunu yapmanın önerilen yolu, eski LLMChain yaklaşımı da desteklense de, LangChain İfade Dili (LCEL)'dir.
LCEL'i kullanarak BasePromptTemplate, BaseLanguageModel ve BaseOutputParser'ın tümü Runnable arayüzünü uygular ve birbirlerine kolayca yönlendirilebilir. İşte bunu gösteren bir örnek:
from langchain.prompts import PromptTemplate
from langchain.chat_models import ChatOpenAI
from langchain.schema import StrOutputParser prompt = PromptTemplate.from_template( "What is a good name for a company that makes {product}?"
)
runnable = prompt | ChatOpenAI() | StrOutputParser()
runnable.invoke({"product": "colorful socks"})
# Output: 'VibrantSocks'
LangChain'de yönlendirme, önceki adımın çıktısının bir sonraki adımı belirlediği deterministik olmayan zincirler oluşturmaya olanak tanır. Bu, LLM'lerle etkileşimlerde tutarlılığın yapılandırılmasına ve korunmasına yardımcı olur. Örneğin, farklı soru türleri için optimize edilmiş iki şablonunuz varsa, kullanıcı girişine göre şablonu seçebilirsiniz.
Bunu, (koşul, çalıştırılabilir) çiftlerin bir listesiyle ve varsayılan bir çalıştırılabilir dosyayla başlatılan bir RunnableBranch ile LCEL kullanarak nasıl başarabileceğiniz aşağıda açıklanmıştır:
from langchain.chat_models import ChatOpenAI
from langchain.schema.output_parser import StrOutputParser
from langchain.schema.runnable import RunnableBranch
# Code for defining physics_prompt and math_prompt general_prompt = PromptTemplate.from_template( "You are a helpful assistant. Answer the question as accurately as you can.nn{input}"
)
prompt_branch = RunnableBranch( (lambda x: x["topic"] == "math", math_prompt), (lambda x: x["topic"] == "physics", physics_prompt), general_prompt,
) # More code for setting up the classifier and final chain
Son zincir daha sonra girdi konusuna göre akışı belirlemek için konu sınıflandırıcı, bilgi istemi dalı ve çıktı ayrıştırıcı gibi çeşitli bileşenler kullanılarak oluşturulur:
from operator import itemgetter
from langchain.schema.output_parser import StrOutputParser
from langchain.schema.runnable import RunnablePassthrough final_chain = ( RunnablePassthrough.assign(topic=itemgetter("input") | classifier_chain) | prompt_branch | ChatOpenAI() | StrOutputParser()
) final_chain.invoke( { "input": "What is the first prime number greater than 40 such that one plus the prime number is divisible by 3?" }
)
# Output: Detailed answer to the math question
Bu yaklaşım, LangChain'in karmaşık sorguları ele alma ve bunları girdiye göre uygun şekilde yönlendirme konusundaki esnekliğini ve gücünü örneklendirmektedir.
Dil modelleri alanında, yaygın bir uygulama, bir çağrının çıktısını bir sonraki çağrının girdisi olarak kullanarak, bir ilk çağrıyı bir dizi sonraki çağrıyla takip etmektir. Bu sıralı yaklaşım, özellikle önceki etkileşimlerde oluşturulan bilgilerden yararlanmak istediğinizde faydalıdır. LangChain İfade Dili (LCEL) bu dizileri oluşturmak için önerilen yöntem olsa da, SequentialChain yöntemi geriye dönük uyumluluğu açısından hâlâ belgelenmiştir.
Bunu açıklamak için, önce bir oyun özeti oluşturduğumuz ve ardından bu özete dayalı olarak bir inceleme oluşturduğumuz bir senaryoyu ele alalım. Python'u kullanma langchain.prompts, iki tane oluşturuyoruz PromptTemplate örnekler: biri özet için, diğeri inceleme için. Bu şablonları ayarlamak için gereken kod:
from langchain.prompts import PromptTemplate synopsis_prompt = PromptTemplate.from_template( "You are a playwright. Given the title of play, it is your job to write a synopsis for that title.nnTitle: {title}nPlaywright: This is a synopsis for the above play:"
) review_prompt = PromptTemplate.from_template( "You are a play critic from the New York Times. Given the synopsis of play, it is your job to write a review for that play.nnPlay Synopsis:n{synopsis}nReview from a New York Times play critic of the above play:"
)
LCEL yaklaşımında bu istemleri şu şekilde zincirliyoruz: ChatOpenAI ve StrOutputParser önce bir özet ve ardından bir inceleme oluşturan bir sekans oluşturmak. Kod pasajı aşağıdaki gibidir:
from langchain.chat_models import ChatOpenAI
from langchain.schema import StrOutputParser llm = ChatOpenAI()
chain = ( {"synopsis": synopsis_prompt | llm | StrOutputParser()} | review_prompt | llm | StrOutputParser()
)
chain.invoke({"title": "Tragedy at sunset on the beach"})
Hem özete hem de incelemeye ihtiyacımız varsa şunu kullanabiliriz: RunnablePassthrough her biri için ayrı bir zincir oluşturmak ve ardından bunları birleştirmek için:
from langchain.schema.runnable import RunnablePassthrough synopsis_chain = synopsis_prompt | llm | StrOutputParser()
review_chain = review_prompt | llm | StrOutputParser()
chain = {"synopsis": synopsis_chain} | RunnablePassthrough.assign(review=review_chain)
chain.invoke({"title": "Tragedy at sunset on the beach"})
Daha karmaşık dizileri içeren senaryolar için, SequentialChain yöntem devreye giriyor. Bu, birden fazla giriş ve çıkışa izin verir. Bir oyunun başlığına ve dönemine dayalı bir özete ihtiyaç duyduğumuz bir durumu düşünün. Bunu şu şekilde ayarlayabiliriz:
from langchain.llms import OpenAI
from langchain.chains import LLMChain, SequentialChain
from langchain.prompts import PromptTemplate llm = OpenAI(temperature=0.7) synopsis_template = "You are a playwright. Given the title of play and the era it is set in, it is your job to write a synopsis for that title.nnTitle: {title}nEra: {era}nPlaywright: This is a synopsis for the above play:"
synopsis_prompt_template = PromptTemplate(input_variables=["title", "era"], template=synopsis_template)
synopsis_chain = LLMChain(llm=llm, prompt=synopsis_prompt_template, output_key="synopsis") review_template = "You are a play critic from the New York Times. Given the synopsis of play, it is your job to write a review for that play.nnPlay Synopsis:n{synopsis}nReview from a New York Times play critic of the above play:"
prompt_template = PromptTemplate(input_variables=["synopsis"], template=review_template)
review_chain = LLMChain(llm=llm, prompt=prompt_template, output_key="review") overall_chain = SequentialChain( chains=[synopsis_chain, review_chain], input_variables=["era", "title"], output_variables=["synopsis", "review"], verbose=True,
) overall_chain({"title": "Tragedy at sunset on the beach", "era": "Victorian England"})
Bir zincir boyunca veya zincirin daha sonraki bir kısmı için bağlamı korumak istediğiniz senaryolarda, SimpleMemory kullanılabilir. Bu özellikle karmaşık girdi/çıktı ilişkilerini yönetmek için kullanışlıdır. Örneğin, bir oyunun başlığına, dönemine, özetine ve incelemesine göre sosyal medya gönderileri oluşturmak istediğimiz bir senaryoda, SimpleMemory şu değişkenleri yönetmenize yardımcı olabilir:
from langchain.memory import SimpleMemory
from langchain.chains import SequentialChain template = "You are a social media manager for a theater company. Given the title of play, the era it is set in, the date, time and location, the synopsis of the play, and the review of the play, it is your job to write a social media post for that play.nnHere is some context about the time and location of the play:nDate and Time: {time}nLocation: {location}nnPlay Synopsis:n{synopsis}nReview from a New York Times play critic of the above play:n{review}nnSocial Media Post:"
prompt_template = PromptTemplate(input_variables=["synopsis", "review", "time", "location"], template=template)
social_chain = LLMChain(llm=llm, prompt=prompt_template, output_key="social_post_text") overall_chain = SequentialChain( memory=SimpleMemory(memories={"time": "December 25th, 8pm PST", "location": "Theater in the Park"}), chains=[synopsis_chain, review_chain, social_chain], input_variables=["era", "title"], output_variables=["social_post_text"], verbose=True,
) overall_chain({"title": "Tragedy at sunset on the beach", "era": "Victorian England"})
Sıralı zincirlere ek olarak belgelerle çalışmak için özel zincirler de vardır. Bu zincirlerin her biri, belgeleri birleştirmekten yinelenen belge analizine dayalı yanıtları iyileştirmeye, özetleme için belge içeriğini haritalandırmaya ve azaltmaya veya puanlanan yanıtlara göre yeniden sıralamaya kadar farklı bir amaca hizmet eder. Bu zincirler, daha fazla esneklik ve kişiselleştirme için LCEL ile yeniden oluşturulabilir.
-
StuffDocumentsChainbir belge listesini bir LLM'ye iletilen tek bir bilgi isteminde birleştirir. -
RefineDocumentsChainHer belge için yanıtını yinelemeli olarak günceller; belgelerin modelin bağlam kapasitesini aştığı görevlere uygundur. -
MapReduceDocumentsChainher belgeye ayrı ayrı bir zincir uygular ve ardından sonuçları birleştirir. -
MapRerankDocumentsChainher belge tabanlı yanıtı puanlar ve en yüksek puanı alan yanıtı seçer.
İşte nasıl kurabileceğinize dair bir örnek MapReduceDocumentsChain LCEL kullanarak:
from functools import partial
from langchain.chains.combine_documents import collapse_docs, split_list_of_docs
from langchain.schema import Document, StrOutputParser
from langchain.schema.prompt_template import format_document
from langchain.schema.runnable import RunnableParallel, RunnablePassthrough llm = ChatAnthropic()
document_prompt = PromptTemplate.from_template("{page_content}")
partial_format_document = partial(format_document, prompt=document_prompt) map_chain = ( {"context": partial_format_document} | PromptTemplate.from_template("Summarize this content:nn{context}") | llm | StrOutputParser()
) map_as_doc_chain = ( RunnableParallel({"doc": RunnablePassthrough(), "content": map_chain}) | (lambda x: Document(page_content=x["content"], metadata=x["doc"].metadata))
).with_config(run_name="Summarize (return doc)") def format_docs(docs): return "nn".join(partial_format_document(doc) for doc in docs) collapse_chain = ( {"context": format_docs} | PromptTemplate.from_template("Collapse this content:nn{context}") | llm | StrOutputParser()
) reduce_chain = ( {"context": format_docs} | PromptTemplate.from_template("Combine these summaries:nn{context}") | llm | StrOutputParser()
).with_config(run_name="Reduce") map_reduce = (map_as_doc_chain.map() | collapse | reduce_chain).with_config(run_name="Map reduce")
Bu yapılandırma, LCEL'in güçlü yanlarından ve temel dil modelinden yararlanarak belge içeriğinin ayrıntılı ve kapsamlı bir analizine olanak tanır.
Nanonets tarafından siz ve ekipleriniz için tasarlanan yapay zeka odaklı iş akışı oluşturucumuzla manuel görevleri ve iş akışlarını otomatikleştirin.
Modül V : Bellek
LangChain'de bellek, etkileşimli arayüzlerin temel bir özelliğidir ve sistemlerin geçmiş etkileşimlere referans vermesine olanak tanır. Bu, iki temel eylemle bilginin saklanması ve sorgulanması yoluyla gerçekleştirilir: okuma ve yazma. Bellek sistemi, bir çalıştırma sırasında bir zincirle iki kez etkileşime girerek kullanıcı girişlerini artırır ve giriş ve çıkışları gelecekte referans olarak saklar.
Bir Sisteme Bellek Oluşturmak
- Sohbet Mesajlarını Saklama: LangChain bellek modülü, sohbet mesajlarını depolamak için bellek içi listelerden veritabanlarına kadar çeşitli yöntemleri entegre eder. Bu, tüm sohbet etkileşimlerinin ileride başvurmak üzere kaydedilmesini sağlar.
- Sohbet Mesajlarını Sorgulama: LangChain, sohbet mesajlarını saklamanın ötesinde, bu mesajların kullanışlı bir görünümünü oluşturmak için veri yapıları ve algoritmalar kullanır. Basit bellek sistemleri en son mesajları döndürebilirken, daha gelişmiş sistemler geçmiş etkileşimleri özetleyebilir veya mevcut etkileşimde bahsedilen varlıklara odaklanabilir.
LangChain'de hafıza kullanımını göstermek için şunu göz önünde bulundurun: ConversationBufferMemory sınıf, sohbet mesajlarını bir arabellekte saklayan basit bir hafıza formu. İşte bir örnek:
from langchain.memory import ConversationBufferMemory memory = ConversationBufferMemory()
memory.chat_memory.add_user_message("Hello!")
memory.chat_memory.add_ai_message("How can I assist you?")
Belleği bir zincire entegre ederken bellekten dönen değişkenleri ve bunların zincirde nasıl kullanıldığını anlamak çok önemlidir. Örneğin, load_memory_variables yöntem, bellekten okunan değişkenleri zincirin beklentileriyle hizalamaya yardımcı olur.
LangChain ile Uçtan Uca Örnek
Kullanmayı düşünün ConversationBufferMemory bir bölgesindeki LLMChain. Uygun bir bilgi istemi şablonu ve bellekle birleştirilen zincir, kesintisiz bir konuşma deneyimi sağlar. İşte basitleştirilmiş bir örnek:
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
from langchain.memory import ConversationBufferMemory llm = OpenAI(temperature=0)
template = "Your conversation template here..."
prompt = PromptTemplate.from_template(template)
memory = ConversationBufferMemory(memory_key="chat_history")
conversation = LLMChain(llm=llm, prompt=prompt, memory=memory) response = conversation({"question": "What's the weather like?"})
Bu örnek, LangChain'in bellek sisteminin tutarlı ve bağlamsal olarak bilinçli bir konuşma deneyimi sağlamak için zincirleriyle nasıl bütünleştiğini göstermektedir.
Langchain'deki Bellek Türleri
Langchain, yapay zeka modelleriyle etkileşimi geliştirmek için kullanılabilecek çeşitli bellek türleri sunar. Her bellek tipinin kendine ait parametreleri ve dönüş tipleri vardır, bu da onları farklı senaryolara uygun hale getirir. Langchain'de bulunan bazı bellek türlerini kod örnekleriyle birlikte inceleyelim.
1. Konuşma Ara Belleği
Bu bellek türü, konuşmalardaki mesajları saklamanıza ve çıkarmanıza olanak tanır. Geçmişi bir dize veya mesaj listesi olarak çıkarabilirsiniz.
from langchain.memory import ConversationBufferMemory memory = ConversationBufferMemory()
memory.save_context({"input": "hi"}, {"output": "whats up"})
memory.load_memory_variables({}) # Extract history as a string
{'history': 'Human: hinAI: whats up'} # Extract history as a list of messages
{'history': [HumanMessage(content='hi', additional_kwargs={}), AIMessage(content='whats up', additional_kwargs={})]}
Ayrıca sohbet benzeri etkileşimler için Konuşma Arabelleği'ni bir zincir halinde kullanabilirsiniz.
2. Konuşma Arabelleği Penceresi Belleği
Bu bellek türü, son etkileşimlerin bir listesini tutar ve son K etkileşimlerini kullanarak arabelleğin çok büyümesini önler.
from langchain.memory import ConversationBufferWindowMemory memory = ConversationBufferWindowMemory(k=1)
memory.save_context({"input": "hi"}, {"output": "whats up"})
memory.save_context({"input": "not much you"}, {"output": "not much"})
memory.load_memory_variables({}) {'history': 'Human: not much younAI: not much'}
Konuşma Ara Belleği gibi, bu bellek türünü de sohbet benzeri etkileşimler için zincir halinde kullanabilirsiniz.
3. Konuşma Varlık Belleği
Bu bellek türü, bir konuşmadaki belirli varlıklar hakkındaki gerçekleri hatırlar ve bir Yüksek Lisans kullanarak bilgileri çıkarır.
from langchain.memory import ConversationEntityMemory
from langchain.llms import OpenAI llm = OpenAI(temperature=0)
memory = ConversationEntityMemory(llm=llm)
_input = {"input": "Deven & Sam are working on a hackathon project"}
memory.load_memory_variables(_input)
memory.save_context( _input, {"output": " That sounds like a great project! What kind of project are they working on?"}
)
memory.load_memory_variables({"input": 'who is Sam'}) {'history': 'Human: Deven & Sam are working on a hackathon projectnAI: That sounds like a great project! What kind of project are they working on?', 'entities': {'Sam': 'Sam is working on a hackathon project with Deven.'}}
4. Konuşma Bilgi Grafiği Hafızası
Bu bellek türü, belleği yeniden oluşturmak için bir bilgi grafiği kullanır. Mevcut varlıkları ve bilgi üçlülerini mesajlardan çıkarabilirsiniz.
from langchain.memory import ConversationKGMemory
from langchain.llms import OpenAI llm = OpenAI(temperature=0)
memory = ConversationKGMemory(llm=llm)
memory.save_context({"input": "say hi to sam"}, {"output": "who is sam"})
memory.save_context({"input": "sam is a friend"}, {"output": "okay"})
memory.load_memory_variables({"input": "who is sam"}) {'history': 'On Sam: Sam is friend.'}
Bu bellek türünü, konuşmaya dayalı bilgi alımı için bir zincir halinde de kullanabilirsiniz.
5. Konuşma Özeti Belleği
Bu bellek türü, zaman içindeki konuşmanın bir özetini oluşturur; bu, daha uzun konuşmalardaki bilgilerin yoğunlaştırılması için kullanışlıdır.
from langchain.memory import ConversationSummaryMemory
from langchain.llms import OpenAI llm = OpenAI(temperature=0)
memory = ConversationSummaryMemory(llm=llm)
memory.save_context({"input": "hi"}, {"output": "whats up"})
memory.load_memory_variables({}) {'history': 'nThe human greets the AI, to which the AI responds.'}
6. Konuşma Özeti Ara Bellek
Bu bellek türü, konuşma özetini ve arabelleği birleştirerek son etkileşimler ile özet arasında bir denge sağlar. Etkileşimlerin ne zaman temizleneceğini belirlemek için belirteç uzunluğunu kullanır.
from langchain.memory import ConversationSummaryBufferMemory
from langchain.llms import OpenAI llm = OpenAI()
memory = ConversationSummaryBufferMemory(llm=llm, max_token_limit=10)
memory.save_context({"input": "hi"}, {"output": "whats up"})
memory.save_context({"input": "not much you"}, {"output": "not much"})
memory.load_memory_variables({}) {'history': 'System: nThe human says "hi", and the AI responds with "whats up".nHuman: not much younAI: not much'}
Langchain'deki AI modelleriyle etkileşimlerinizi geliştirmek için bu bellek türlerini kullanabilirsiniz. Her bellek türü belirli bir amaca hizmet eder ve ihtiyaçlarınıza göre seçilebilir.
7. Konuşma Jetonu Tampon Belleği
ConversationTokenBufferMemory, bellekteki son etkileşimlerin arabelleğini tutan başka bir bellek türüdür. Etkileşim sayısına odaklanan önceki bellek türlerinden farklı olarak bu, etkileşimlerin ne zaman temizleneceğini belirlemek için belirteç uzunluğunu kullanır.
Yüksek Lisans ile belleği kullanma:
from langchain.memory import ConversationTokenBufferMemory
from langchain.llms import OpenAI llm = OpenAI() memory = ConversationTokenBufferMemory(llm=llm, max_token_limit=10)
memory.save_context({"input": "hi"}, {"output": "whats up"})
memory.save_context({"input": "not much you"}, {"output": "not much"}) memory.load_memory_variables({}) {'history': 'Human: not much younAI: not much'}
Bu örnekte bellek, etkileşim sayısından ziyade belirteç uzunluğuna dayalı olarak etkileşimleri sınırlayacak şekilde ayarlanmıştır.
Bu hafıza türünü kullanırken geçmişi bir mesaj listesi olarak da alabilirsiniz.
memory = ConversationTokenBufferMemory( llm=llm, max_token_limit=10, return_messages=True
)
memory.save_context({"input": "hi"}, {"output": "whats up"})
memory.save_context({"input": "not much you"}, {"output": "not much"})
Bir zincirde kullanma:
Yapay zeka modeliyle etkileşimleri geliştirmek için ConversationTokenBufferMemory'yi bir zincir halinde kullanabilirsiniz.
from langchain.chains import ConversationChain conversation_with_summary = ConversationChain( llm=llm, # We set a very low max_token_limit for the purposes of testing. memory=ConversationTokenBufferMemory(llm=OpenAI(), max_token_limit=60), verbose=True,
)
conversation_with_summary.predict(input="Hi, what's up?")
Bu örnekte ConversationTokenBufferMemory, konuşmayı yönetmek ve belirteç uzunluğuna göre etkileşimleri sınırlamak için bir ConversationChain'de kullanılır.
8. VectorStoreRetriever Belleği
VectorStoreRetrieverMemory, anıları bir vektör deposunda saklar ve her çağrıldığında en üstteki "en göze çarpan" belgeleri sorgular. Bu bellek türü, etkileşimlerin sırasını açıkça izlemez ancak ilgili anıları getirmek için vektör alımını kullanır.
from datetime import datetime
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.llms import OpenAI
from langchain.memory import VectorStoreRetrieverMemory
from langchain.chains import ConversationChain
from langchain.prompts import PromptTemplate # Initialize your vector store (specifics depend on the chosen vector store)
import faiss
from langchain.docstore import InMemoryDocstore
from langchain.vectorstores import FAISS embedding_size = 1536 # Dimensions of the OpenAIEmbeddings
index = faiss.IndexFlatL2(embedding_size)
embedding_fn = OpenAIEmbeddings().embed_query
vectorstore = FAISS(embedding_fn, index, InMemoryDocstore({}), {}) # Create your VectorStoreRetrieverMemory
retriever = vectorstore.as_retriever(search_kwargs=dict(k=1))
memory = VectorStoreRetrieverMemory(retriever=retriever) # Save context and relevant information to the memory
memory.save_context({"input": "My favorite food is pizza"}, {"output": "that's good to know"})
memory.save_context({"input": "My favorite sport is soccer"}, {"output": "..."})
memory.save_context({"input": "I don't like the Celtics"}, {"output": "ok"}) # Retrieve relevant information from memory based on a query
print(memory.load_memory_variables({"prompt": "what sport should i watch?"})["history"])
Bu örnekte VectorStoreRetrieverMemory, vektör alımına dayalı olarak bir konuşmadan ilgili bilgileri depolamak ve almak için kullanılır.
Önceki örneklerde gösterildiği gibi, konuşmaya dayalı bilgi alımı için VectorStoreRetrieverMemory'yi bir zincir halinde de kullanabilirsiniz.
Langchain'deki bu farklı bellek türleri, konuşmalardan bilgi almak ve yönetmek için çeşitli yollar sağlayarak yapay zeka modellerinin kullanıcı sorgularını ve bağlamını anlama ve bunlara yanıt verme yeteneklerini geliştirir. Her bellek türü, uygulamanızın özel gereksinimlerine göre seçilebilir.
Şimdi belleğin bir LLMChain ile nasıl kullanılacağını öğreneceğiz. Bir LLMChain'deki bellek, modelin daha tutarlı ve bağlama duyarlı yanıtlar sağlamak için önceki etkileşimleri ve bağlamı hatırlamasına olanak tanır.
Bir LLMChain'de bellek ayarlamak için ConversationBufferMemory gibi bir bellek sınıfı oluşturmanız gerekir. Bunu nasıl ayarlayabileceğiniz aşağıda açıklanmıştır:
from langchain.chains import LLMChain
from langchain.llms import OpenAI
from langchain.memory import ConversationBufferMemory
from langchain.prompts import PromptTemplate template = """You are a chatbot having a conversation with a human. {chat_history}
Human: {human_input}
Chatbot:""" prompt = PromptTemplate( input_variables=["chat_history", "human_input"], template=template
)
memory = ConversationBufferMemory(memory_key="chat_history") llm = OpenAI()
llm_chain = LLMChain( llm=llm, prompt=prompt, verbose=True, memory=memory,
) llm_chain.predict(human_input="Hi there my friend")
Bu örnekte, konuşma geçmişini depolamak için ConversationBufferMemory kullanıldı. memory_key parametresi konuşma geçmişini saklamak için kullanılan anahtarı belirtir.
Tamamlama tarzı bir model yerine bir sohbet modeli kullanıyorsanız, belleği daha iyi kullanmak için istemlerinizi farklı şekilde yapılandırabilirsiniz. Bellekli sohbet modeli tabanlı bir LLMChain'in nasıl kurulacağına dair bir örnek:
from langchain.chat_models import ChatOpenAI
from langchain.schema import SystemMessage
from langchain.prompts import ( ChatPromptTemplate, HumanMessagePromptTemplate, MessagesPlaceholder,
) # Create a ChatPromptTemplate
prompt = ChatPromptTemplate.from_messages( [ SystemMessage( content="You are a chatbot having a conversation with a human." ), # The persistent system prompt MessagesPlaceholder( variable_name="chat_history" ), # Where the memory will be stored. HumanMessagePromptTemplate.from_template( "{human_input}" ), # Where the human input will be injected ]
) memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True) llm = ChatOpenAI() chat_llm_chain = LLMChain( llm=llm, prompt=prompt, verbose=True, memory=memory,
) chat_llm_chain.predict(human_input="Hi there my friend")
Bu örnekte, istemi yapılandırmak için ChatPromptTemplate kullanılır ve konuşma geçmişini depolamak ve almak için ConversationBufferMemory kullanılır. Bu yaklaşım özellikle bağlam ve geçmişin önemli bir rol oynadığı sohbet tarzı konuşmalar için kullanışlıdır.
Bellek ayrıca soru/cevap zinciri gibi birden fazla girişi olan bir zincire de eklenebilir. Bir soru/cevap zincirinde belleğin nasıl kurulacağına ilişkin bir örnek:
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.embeddings.cohere import CohereEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores.elastic_vector_search import ElasticVectorSearch
from langchain.vectorstores import Chroma
from langchain.docstore.document import Document
from langchain.chains.question_answering import load_qa_chain
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
from langchain.memory import ConversationBufferMemory # Split a long document into smaller chunks
with open("../../state_of_the_union.txt") as f: state_of_the_union = f.read()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_text(state_of_the_union) # Create an ElasticVectorSearch instance to index and search the document chunks
embeddings = OpenAIEmbeddings()
docsearch = Chroma.from_texts( texts, embeddings, metadatas=[{"source": i} for i in range(len(texts))]
) # Perform a question about the document
query = "What did the president say about Justice Breyer"
docs = docsearch.similarity_search(query) # Set up a prompt for the question-answering chain with memory
template = """You are a chatbot having a conversation with a human. Given the following extracted parts of a long document and a question, create a final answer. {context} {chat_history}
Human: {human_input}
Chatbot:""" prompt = PromptTemplate( input_variables=["chat_history", "human_input", "context"], template=template
)
memory = ConversationBufferMemory(memory_key="chat_history", input_key="human_input")
chain = load_qa_chain( OpenAI(temperature=0), chain_type="stuff", memory=memory, prompt=prompt
) # Ask the question and retrieve the answer
query = "What did the president say about Justice Breyer"
result = chain({"input_documents": docs, "human_input": query}, return_only_outputs=True) print(result)
print(chain.memory.buffer)
Bu örnekte, bir soru daha küçük parçalara bölünmüş bir belge kullanılarak yanıtlanmaktadır. ConversationBufferMemory, konuşma geçmişini depolamak ve almak için kullanılır ve modelin bağlama duyarlı yanıtlar sağlamasına olanak tanır.
Bir aracıya bellek eklemek, onun soruları yanıtlamak ve bağlama duyarlı yanıtlar sağlamak için önceki etkileşimleri hatırlamasına ve kullanmasına olanak tanır. Bir aracıda belleği şu şekilde ayarlayabilirsiniz:
from langchain.agents import ZeroShotAgent, Tool, AgentExecutor
from langchain.memory import ConversationBufferMemory
from langchain.llms import OpenAI
from langchain.chains import LLMChain
from langchain.utilities import GoogleSearchAPIWrapper # Create a tool for searching
search = GoogleSearchAPIWrapper()
tools = [ Tool( name="Search", func=search.run, description="useful for when you need to answer questions about current events", )
] # Create a prompt with memory
prefix = """Have a conversation with a human, answering the following questions as best you can. You have access to the following tools:"""
suffix = """Begin!" {chat_history}
Question: {input}
{agent_scratchpad}""" prompt = ZeroShotAgent.create_prompt( tools, prefix=prefix, suffix=suffix, input_variables=["input", "chat_history", "agent_scratchpad"],
)
memory = ConversationBufferMemory(memory_key="chat_history") # Create an LLMChain with memory
llm_chain = LLMChain(llm=OpenAI(temperature=0), prompt=prompt)
agent = ZeroShotAgent(llm_chain=llm_chain, tools=tools, verbose=True)
agent_chain = AgentExecutor.from_agent_and_tools( agent=agent, tools=tools, verbose=True, memory=memory
) # Ask a question and retrieve the answer
response = agent_chain.run(input="How many people live in Canada?")
print(response) # Ask a follow-up question
response = agent_chain.run(input="What is their national anthem called?")
print(response)
Bu örnekte, bir aracıya bellek eklenerek önceki konuşma geçmişini hatırlamasına ve bağlama duyarlı yanıtlar vermesine olanak sağlanır. Bu, aracının bellekte saklanan bilgilere dayanarak takip eden soruları doğru bir şekilde yanıtlamasını sağlar.
LangChain İfade Dili
Doğal dil işleme ve makine öğrenimi dünyasında karmaşık işlem zincirlerini oluşturmak göz korkutucu bir görev olabilir. Neyse ki, LangChain İfade Dili (LCEL) kurtarmaya geliyor ve karmaşık dil işleme boru hatlarını oluşturmak ve dağıtmak için bildirimsel ve etkili bir yol sağlıyor. LCEL, zincir oluşturma sürecini basitleştirmek ve prototiplemeden üretime kolaylıkla geçmeyi mümkün kılmak için tasarlanmıştır. Bu blogda, LCEL'in ne olduğunu ve neden onu kullanmak isteyebileceğinizi, yeteneklerini gösterecek pratik kod örnekleriyle birlikte keşfedeceğiz.
LCEL veya LangChain İfade Dili, dil işleme zincirlerini oluşturmak için güçlü bir araçtır. Kapsamlı kod değişiklikleri gerektirmeden prototiplemeden üretime geçişi sorunsuz bir şekilde desteklemek için özel olarak tasarlandı. İster basit bir "bilgi istemi + LLM" zinciri, ister yüzlerce adımdan oluşan karmaşık bir işlem hattı oluşturuyor olun, LCEL yanınızdadır.
Dil işleme projelerinizde LCEL'i kullanmanızın bazı nedenleri şunlardır:
- Hızlı Belirteç Akışı: LCEL, bir Dil Modelinden bir çıktı ayrıştırıcısına gerçek zamanlı olarak belirteçler göndererek yanıt verme hızını ve verimliliği artırır.
- Çok yönlü API'ler: LCEL, prototip oluşturma ve üretim kullanımı için hem eşzamanlı hem de eşzamansız API'leri destekleyerek birden fazla isteği verimli bir şekilde yönetir.
- Otomatik Paralelleştirme: LCEL, mümkün olduğunda paralel yürütmeyi optimize ederek hem senkronizasyon hem de eşzamansız arayüzlerdeki gecikmeyi azaltır.
- Güvenilir Yapılandırmalar: Geliştirme aşamasındaki akış desteğiyle, geniş ölçekte gelişmiş zincir güvenilirliği için yeniden denemeleri ve geri dönüşleri yapılandırın.
- Ara Sonuçların Akışı: Kullanıcı güncellemeleri veya hata ayıklama amacıyla işleme sırasında ara sonuçlara erişin.
- Şema Oluşturma: LCEL, giriş ve çıkış doğrulaması için Pydantic ve JSONSchema şemaları oluşturur.
- Kapsamlı İzleme: LangSmith, gözlemlenebilirlik ve hata ayıklama için karmaşık zincirlerdeki tüm adımları otomatik olarak izler.
- Kolay Dağıtım: LangServe kullanarak LCEL tarafından oluşturulan zincirleri zahmetsizce dağıtın.
Şimdi LCEL'in gücünü gösteren pratik kod örneklerine bakalım. LCEL'in öne çıktığı ortak görevleri ve senaryoları keşfedeceğiz.
Bilgi İstemi + LLM
En temel kompozisyon, kullanıcı girdisini alan, bunu bir bilgi istemine ekleyen, onu bir modele aktaran ve ham model çıktısını döndüren bir zincir oluşturmak için bir bilgi istemi ile bir dil modelini birleştirmeyi içerir. İşte bir örnek:
from langchain.prompts import ChatPromptTemplate
from langchain.chat_models import ChatOpenAI prompt = ChatPromptTemplate.from_template("tell me a joke about {foo}")
model = ChatOpenAI()
chain = prompt | model result = chain.invoke({"foo": "bears"})
print(result)
Bu örnekte zincir, ayılarla ilgili bir şaka yapıyor.
Metni nasıl işlediğini kontrol etmek için zincirinize durdurma dizileri ekleyebilirsiniz. Örneğin:
chain = prompt | model.bind(stop=["n"])
result = chain.invoke({"foo": "bears"})
print(result)
Bu yapılandırma, yeni satır karakteriyle karşılaşıldığında metin oluşturulmasını durdurur.
LCEL, zincirinize işlev çağrısı bilgilerinin eklenmesini destekler. İşte bir örnek:
functions = [ { "name": "joke", "description": "A joke", "parameters": { "type": "object", "properties": { "setup": {"type": "string", "description": "The setup for the joke"}, "punchline": { "type": "string", "description": "The punchline for the joke", }, }, "required": ["setup", "punchline"], }, }
]
chain = prompt | model.bind(function_call={"name": "joke"}, functions=functions)
result = chain.invoke({"foo": "bears"}, config={})
print(result)
Bu örnek, şaka oluşturmak için işlev çağrısı bilgilerini ekler.
İstem + LLM + OutputParser
Ham model çıktısını daha uygulanabilir bir formata dönüştürmek için bir çıktı ayrıştırıcısı ekleyebilirsiniz. Bunu nasıl yapabileceğiniz aşağıda açıklanmıştır:
from langchain.schema.output_parser import StrOutputParser chain = prompt | model | StrOutputParser()
result = chain.invoke({"foo": "bears"})
print(result)
Çıktı artık aşağı akış görevleri için daha uygun olan bir dize biçimindedir.
Döndürülecek bir işlevi belirtirken, onu doğrudan LCEL kullanarak ayrıştırabilirsiniz. Örneğin:
from langchain.output_parsers.openai_functions import JsonOutputFunctionsParser chain = ( prompt | model.bind(function_call={"name": "joke"}, functions=functions) | JsonOutputFunctionsParser()
)
result = chain.invoke({"foo": "bears"})
print(result)
Bu örnek, "şaka" fonksiyonunun çıktısını doğrudan ayrıştırır.
Bunlar, LCEL'in karmaşık dil işleme görevlerini nasıl basitleştirdiğine dair yalnızca birkaç örnektir. İster sohbet robotları oluşturuyor olun, ister içerik üretiyor olun, ister karmaşık metin dönüşümleri gerçekleştiriyor olun, LCEL iş akışınızı kolaylaştırabilir ve kodunuzu daha sürdürülebilir hale getirebilir.
RAG (Geri Almayla Artırılmış Nesil)
LCEL, alma ve dil oluşturma adımlarını birleştiren, almayla artırılmış nesil zincirleri oluşturmak için kullanılabilir. İşte bir örnek:
from operator import itemgetter from langchain.prompts import ChatPromptTemplate
from langchain.chat_models import ChatOpenAI
from langchain.embeddings import OpenAIEmbeddings
from langchain.schema.output_parser import StrOutputParser
from langchain.schema.runnable import RunnablePassthrough, RunnableLambda
from langchain.vectorstores import FAISS # Create a vector store and retriever
vectorstore = FAISS.from_texts( ["harrison worked at kensho"], embedding=OpenAIEmbeddings()
)
retriever = vectorstore.as_retriever() # Define templates for prompts
template = """Answer the question based only on the following context:
{context} Question: {question} """
prompt = ChatPromptTemplate.from_template(template) model = ChatOpenAI() # Create a retrieval-augmented generation chain
chain = ( {"context": retriever, "question": RunnablePassthrough()} | prompt | model | StrOutputParser()
) result = chain.invoke("where did harrison work?")
print(result)
Bu örnekte zincir, bağlamdan ilgili bilgileri alır ve soruya bir yanıt üretir.
Konuşmalı Erişim Zinciri
Zincirlerinize kolayca konuşma geçmişi ekleyebilirsiniz. İşte konuşma yoluyla erişim zincirinin bir örneği:
from langchain.schema.runnable import RunnableMap
from langchain.schema import format_document from langchain.prompts.prompt import PromptTemplate # Define templates for prompts
_template = """Given the following conversation and a follow up question, rephrase the follow up question to be a standalone question, in its original language. Chat History:
{chat_history}
Follow Up Input: {question}
Standalone question:"""
CONDENSE_QUESTION_PROMPT = PromptTemplate.from_template(_template) template = """Answer the question based only on the following context:
{context} Question: {question} """
ANSWER_PROMPT = ChatPromptTemplate.from_template(template) # Define input map and context
_inputs = RunnableMap( standalone_question=RunnablePassthrough.assign( chat_history=lambda x: _format_chat_history(x["chat_history"]) ) | CONDENSE_QUESTION_PROMPT | ChatOpenAI(temperature=0) | StrOutputParser(),
)
_context = { "context": itemgetter("standalone_question") | retriever | _combine_documents, "question": lambda x: x["standalone_question"],
}
conversational_qa_chain = _inputs | _context | ANSWER_PROMPT | ChatOpenAI() result = conversational_qa_chain.invoke( { "question": "where did harrison work?", "chat_history": [], }
)
print(result)
Bu örnekte zincir, konuşma bağlamında bir takip sorusunu ele alıyor.
Bellekli ve Kaynak Belgeleri Döndüren
LCEL ayrıca belleği ve kaynak belgeleri döndürmeyi de destekler. Bir zincirdeki belleği şu şekilde kullanabilirsiniz:
from operator import itemgetter
from langchain.memory import ConversationBufferMemory # Create a memory instance
memory = ConversationBufferMemory( return_messages=True, output_key="answer", input_key="question"
) # Define steps for the chain
loaded_memory = RunnablePassthrough.assign( chat_history=RunnableLambda(memory.load_memory_variables) | itemgetter("history"),
) standalone_question = { "standalone_question": { "question": lambda x: x["question"], "chat_history": lambda x: _format_chat_history(x["chat_history"]), } | CONDENSE_QUESTION_PROMPT | ChatOpenAI(temperature=0) | StrOutputParser(),
} retrieved_documents = { "docs": itemgetter("standalone_question") | retriever, "question": lambda x: x["standalone_question"],
} final_inputs = { "context": lambda x: _combine_documents(x["docs"]), "question": itemgetter("question"),
} answer = { "answer": final_inputs | ANSWER_PROMPT | ChatOpenAI(), "docs": itemgetter("docs"),
} # Create the final chain by combining the steps
final_chain = loaded_memory | standalone_question | retrieved_documents | answer inputs = {"question": "where did harrison work?"}
result = final_chain.invoke(inputs)
print(result)
Bu örnekte bellek, konuşma geçmişini ve kaynak belgeleri depolamak ve almak için kullanılıyor.
Çoklu Zincirler
Runnables'ı kullanarak birden fazla zinciri bir araya getirebilirsiniz. İşte bir örnek:
from operator import itemgetter from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.schema import StrOutputParser prompt1 = ChatPromptTemplate.from_template("what is the city {person} is from?")
prompt2 = ChatPromptTemplate.from_template( "what country is the city {city} in? respond in {language}"
) model = ChatOpenAI() chain1 = prompt1 | model | StrOutputParser() chain2 = ( {"city": chain1, "language": itemgetter("language")} | prompt2 | model | StrOutputParser()
) result = chain2.invoke({"person": "obama", "language": "spanish"})
print(result)
Bu örnekte, bir şehir ve ülke hakkında belirli bir dilde bilgi üretmek için iki zincir birleştirilmiştir.
Dallanma ve Birleşme
LCEL, RunnableMaps'i kullanarak zincirleri bölmenize ve birleştirmenize olanak tanır. İşte dallanma ve birleştirmeye bir örnek:
from operator import itemgetter from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.schema import StrOutputParser planner = ( ChatPromptTemplate.from_template("Generate an argument about: {input}") | ChatOpenAI() | StrOutputParser() | {"base_response": RunnablePassthrough()}
) arguments_for = ( ChatPromptTemplate.from_template( "List the pros or positive aspects of {base_response}" ) | ChatOpenAI() | StrOutputParser()
)
arguments_against = ( ChatPromptTemplate.from_template( "List the cons or negative aspects of {base_response}" ) | ChatOpenAI() | StrOutputParser()
) final_responder = ( ChatPromptTemplate.from_messages( [ ("ai", "{original_response}"), ("human", "Pros:n{results_1}nnCons:n{results_2}"), ("system", "Generate a final response given the critique"), ] ) | ChatOpenAI() | StrOutputParser()
) chain = ( planner | { "results_1": arguments_for, "results_2": arguments_against, "original_response": itemgetter("base_response"), } | final_responder
) result = chain.invoke({"input": "scrum"})
print(result)
Bu örnekte, bir argüman oluşturmak ve nihai bir yanıt oluşturmadan önce bunun artılarını ve eksilerini değerlendirmek için bir dallanma ve birleştirme zinciri kullanılıyor.
LCEL ile Python Kodu Yazmak
LangChain İfade Dili'nin (LCEL) güçlü uygulamalarından biri, kullanıcı sorunlarını çözmek için Python kodu yazmaktır. Aşağıda Python kodunu yazmak için LCEL'in nasıl kullanılacağına dair bir örnek verilmiştir:
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.schema.output_parser import StrOutputParser
from langchain_experimental.utilities import PythonREPL template = """Write some python code to solve the user's problem. Return only python code in Markdown format, e.g.: ```python
....
```"""
prompt = ChatPromptTemplate.from_messages([("system", template), ("human", "{input}")]) model = ChatOpenAI() def _sanitize_output(text: str): _, after = text.split("```python") return after.split("```")[0] chain = prompt | model | StrOutputParser() | _sanitize_output | PythonREPL().run result = chain.invoke({"input": "what's 2 plus 2"})
print(result)
Bu örnekte, bir kullanıcı girdi sağlar ve LCEL, sorunu çözmek için Python kodunu oluşturur. Kod daha sonra Python REPL kullanılarak yürütülür ve ortaya çıkan Python kodu Markdown formatında döndürülür.
Lütfen Python REPL kullanmanın rastgele kod çalıştırabileceğini unutmayın; bu nedenle dikkatli kullanın.
Bir Zincire Bellek Eklemek
Bellek, birçok konuşmaya dayalı yapay zeka uygulamasında önemlidir. Rastgele bir zincire nasıl bellek ekleneceği aşağıda açıklanmıştır:
from operator import itemgetter
from langchain.chat_models import ChatOpenAI
from langchain.memory import ConversationBufferMemory
from langchain.schema.runnable import RunnablePassthrough, RunnableLambda
from langchain.prompts import ChatPromptTemplate, MessagesPlaceholder model = ChatOpenAI()
prompt = ChatPromptTemplate.from_messages( [ ("system", "You are a helpful chatbot"), MessagesPlaceholder(variable_name="history"), ("human", "{input}"), ]
) memory = ConversationBufferMemory(return_messages=True) # Initialize memory
memory.load_memory_variables({}) chain = ( RunnablePassthrough.assign( history=RunnableLambda(memory.load_memory_variables) | itemgetter("history") ) | prompt | model
) inputs = {"input": "hi, I'm Bob"}
response = chain.invoke(inputs)
response # Save the conversation in memory
memory.save_context(inputs, {"output": response.content}) # Load memory to see the conversation history
memory.load_memory_variables({})
Bu örnekte, konuşma geçmişini depolamak ve almak için bellek kullanılıyor, böylece sohbet robotunun bağlamı korumasına ve uygun şekilde yanıt vermesine olanak sağlanıyor.
Çalıştırılabilir Öğelerle Harici Araçları Kullanma
LCEL, harici araçları Runnables ile sorunsuz bir şekilde entegre etmenize olanak tanır. DuckDuckGo Arama aracını kullanan bir örnek:
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.schema.output_parser import StrOutputParser
from langchain.tools import DuckDuckGoSearchRun search = DuckDuckGoSearchRun() template = """Turn the following user input into a search query for a search engine: {input}"""
prompt = ChatPromptTemplate.from_template(template) model = ChatOpenAI() chain = prompt | model | StrOutputParser() | search search_result = chain.invoke({"input": "I'd like to figure out what games are tonight"})
print(search_result)
Bu örnekte LCEL, DuckDuckGo Arama aracını zincire entegre ederek kullanıcı girişinden bir arama sorgusu oluşturmasına ve arama sonuçlarını almasına olanak tanır.
LCEL'in esnekliği, çeşitli harici araçları ve hizmetleri dil işleme hatlarınıza dahil etmenizi kolaylaştırarak bunların yeteneklerini ve işlevlerini geliştirir.
Bir LLM Başvurusuna Moderasyon Ekleme
LLM uygulamanızın içerik politikalarına uymasını ve denetleme önlemlerini içermesini sağlamak için denetleme kontrollerini zincirinize entegre edebilirsiniz. LangChain'i kullanarak denetimi nasıl ekleyeceğiniz aşağıda açıklanmıştır:
from langchain.chains import OpenAIModerationChain
from langchain.llms import OpenAI
from langchain.prompts import ChatPromptTemplate moderate = OpenAIModerationChain() model = OpenAI()
prompt = ChatPromptTemplate.from_messages([("system", "repeat after me: {input}")]) chain = prompt | model # Original response without moderation
response_without_moderation = chain.invoke({"input": "you are stupid"})
print(response_without_moderation) moderated_chain = chain | moderate # Response after moderation
response_after_moderation = moderated_chain.invoke({"input": "you are stupid"})
print(response_after_moderation)
Bu örnekte, OpenAIModerationChain LLM tarafından oluşturulan yanıta ılımlılık eklemek için kullanılır. Denetleme zinciri, OpenAI'nin içerik politikasını ihlal eden içeriğe verilen yanıtı kontrol eder. Herhangi bir ihlal bulunursa, yanıt buna göre işaretlenecektir.
Semantik Benzerliğe Göre Yönlendirme
LCEL, kullanıcı girişinin anlamsal benzerliğine dayalı olarak özel yönlendirme mantığı uygulamanıza olanak tanır. Kullanıcı girdisine dayalı olarak zincir mantığının dinamik olarak nasıl belirleneceğine dair bir örnek:
from langchain.chat_models import ChatOpenAI
from langchain.embeddings import OpenAIEmbeddings
from langchain.prompts import PromptTemplate
from langchain.schema.output_parser import StrOutputParser
from langchain.schema.runnable import RunnableLambda, RunnablePassthrough
from langchain.utils.math import cosine_similarity physics_template = """You are a very smart physics professor. You are great at answering questions about physics in a concise and easy to understand manner. When you don't know the answer to a question you admit that you don't know. Here is a question:
{query}""" math_template = """You are a very good mathematician. You are great at answering math questions. You are so good because you are able to break down hard problems into their component parts, answer the component parts, and then put them together to answer the broader question. Here is a question:
{query}""" embeddings = OpenAIEmbeddings()
prompt_templates = [physics_template, math_template]
prompt_embeddings = embeddings.embed_documents(prompt_templates) def prompt_router(input): query_embedding = embeddings.embed_query(input["query"]) similarity = cosine_similarity([query_embedding], prompt_embeddings)[0] most_similar = prompt_templates[similarity.argmax()] print("Using MATH" if most_similar == math_template else "Using PHYSICS") return PromptTemplate.from_template(most_similar) chain = ( {"query": RunnablePassthrough()} | RunnableLambda(prompt_router) | ChatOpenAI() | StrOutputParser()
) print(chain.invoke({"query": "What's a black hole"}))
print(chain.invoke({"query": "What's a path integral"}))
Bu örnekte, prompt_router işlevi, kullanıcı girişi ile fizik ve matematik soruları için önceden tanımlanmış bilgi istemi şablonları arasındaki kosinüs benzerliğini hesaplar. Benzerlik puanına bağlı olarak zincir, en alakalı bilgi istemi şablonunu dinamik olarak seçerek sohbet robotunun kullanıcının sorusuna uygun şekilde yanıt vermesini sağlar.
Aracıları ve Çalıştırılabilirleri Kullanma
LangChain, Çalıştırılabilirleri, istemleri, modelleri ve araçları birleştirerek aracılar oluşturmanıza olanak tanır. Aşağıda bir aracı oluşturmaya ve onu kullanmaya ilişkin bir örnek verilmiştir:
from langchain.agents import XMLAgent, tool, AgentExecutor
from langchain.chat_models import ChatAnthropic model = ChatAnthropic(model="claude-2") @tool
def search(query: str) -> str: """Search things about current events.""" return "32 degrees" tool_list = [search] # Get prompt to use
prompt = XMLAgent.get_default_prompt() # Logic for going from intermediate steps to a string to pass into the model
def convert_intermediate_steps(intermediate_steps): log = "" for action, observation in intermediate_steps: log += ( f"<tool>{action.tool}</tool><tool_input>{action.tool_input}" f"</tool_input><observation>{observation}</observation>" ) return log # Logic for converting tools to a string to go in the prompt
def convert_tools(tools): return "n".join([f"{tool.name}: {tool.description}" for tool in tools]) agent = ( { "question": lambda x: x["question"], "intermediate_steps": lambda x: convert_intermediate_steps( x["intermediate_steps"] ), } | prompt.partial(tools=convert_tools(tool_list)) | model.bind(stop=["</tool_input>", "</final_answer>"]) | XMLAgent.get_default_output_parser()
) agent_executor = AgentExecutor(agent=agent, tools=tool_list, verbose=True) result = agent_executor.invoke({"question": "What's the weather in New York?"})
print(result)
Bu örnekte, bir model, araçlar, bir bilgi istemi ve ara adımlar ve araç dönüşümü için özel bir mantık birleştirilerek bir aracı oluşturulur. Aracı daha sonra yürütülür ve kullanıcının sorgusuna bir yanıt sağlanır.
SQL Veritabanını Sorgulamak
Bir SQL veritabanını sorgulamak ve kullanıcı sorularına dayalı SQL sorguları oluşturmak için LangChain'i kullanabilirsiniz. İşte bir örnek:
from langchain.prompts import ChatPromptTemplate template = """Based on the table schema below, write a SQL query that would answer the user's question:
{schema} Question: {question}
SQL Query:"""
prompt = ChatPromptTemplate.from_template(template) from langchain.utilities import SQLDatabase # Initialize the database (you'll need the Chinook sample DB for this example)
db = SQLDatabase.from_uri("sqlite:///./Chinook.db") def get_schema(_): return db.get_table_info() def run_query(query): return db.run(query) from langchain.chat_models import ChatOpenAI
from langchain.schema.output_parser import StrOutputParser
from langchain.schema.runnable import RunnablePassthrough model = ChatOpenAI() sql_response = ( RunnablePassthrough.assign(schema=get_schema) | prompt | model.bind(stop=["nSQLResult:"]) | StrOutputParser()
) result = sql_response.invoke({"question": "How many employees are there?"})
print(result) template = """Based on the table schema below, question, SQL query, and SQL response, write a natural language response:
{schema} Question: {question}
SQL Query: {query}
SQL Response: {response}"""
prompt_response = ChatPromptTemplate.from_template(template) full_chain = ( RunnablePassthrough.assign(query=sql_response) | RunnablePassthrough.assign( schema=get_schema, response=lambda x: db.run(x["query"]), ) | prompt_response | model
) response = full_chain.invoke({"question": "How many employees are there?"})
print(response)
Bu örnekte LangChain, kullanıcı sorularına dayalı SQL sorguları oluşturmak ve bir SQL veritabanından yanıtlar almak için kullanılır. İstemler ve yanıtlar, veritabanıyla doğal dil etkileşimlerini sağlayacak şekilde biçimlendirilmiştir.
Nanonets tarafından siz ve ekipleriniz için tasarlanan yapay zeka odaklı iş akışı oluşturucumuzla manuel görevleri ve iş akışlarını otomatikleştirin.
LangServe ve LangSmith
LangServe, geliştiricilerin LangChain çalıştırılabilirlerini ve zincirlerini REST API olarak dağıtmalarına yardımcı olur. Bu kütüphane FastAPI ile entegredir ve veri doğrulama için pydantic kullanır. Ek olarak, bir sunucuda konuşlandırılan çalıştırılabilir öğeleri çağırmak için kullanılabilecek bir istemci sağlar ve LangChainJS'de bir JavaScript istemcisi mevcuttur.
Özellikler
- Giriş ve Çıkış şemaları, LangChain nesnenizden otomatik olarak çıkarılır ve zengin hata mesajlarıyla her API çağrısında uygulanır.
- JSONSchema ve Swagger'ı içeren bir API belgeleri sayfası mevcuttur.
- Tek bir sunucuda birçok eşzamanlı isteği destekleyen verimli /invoke, /batch ve /stream uç noktaları.
- Zincirinizden/acentenizden tüm (veya bazı) ara adımların akışını sağlamak için /stream_log uç noktası.
- Akış çıktısı ve ara adımlarla /playground adresindeki oyun alanı sayfası.
- LangSmith'e yerleşik (isteğe bağlı) izleme; API anahtarınızı eklemeniz yeterli (Talimatlara bakın).
- Tamamı FastAPI, Pydantic, uvloop ve asyncio gibi savaşta test edilmiş açık kaynaklı Python kitaplıklarıyla oluşturulmuştur.
Sınırlamalar
- Sunucudan kaynaklanan olaylar için istemci geri aramaları henüz desteklenmemektedir.
- Pydantic V2 kullanılırken OpenAPI belgeleri oluşturulmayacak. FastAPI, pydantic v1 ve v2 ad alanlarının karıştırılmasını desteklemez. Daha fazla ayrıntı için aşağıdaki bölüme bakın.
Bir LangServe projesini hızlı bir şekilde başlatmak için LangChain CLI'yi kullanın. Langchain CLI'yi kullanmak için langchain-cli'nin güncel bir sürümünün kurulu olduğundan emin olun. pip install -U langchain-cli ile kurabilirsiniz.
langchain app new ../path/to/directory
LangServe örneğinizi LangChain Şablonları ile hızlı bir şekilde başlatın. Daha fazla örnek için şablonlar dizinine veya örnekler dizinine bakın.
Burada bir OpenAI sohbet modeli, bir Antropik sohbet modeli ve bir konu hakkında şaka yapmak için Antropik modeli kullanan bir zincir kullanan bir sunucu var.
#!/usr/bin/env python
from fastapi import FastAPI
from langchain.prompts import ChatPromptTemplate
from langchain.chat_models import ChatAnthropic, ChatOpenAI
from langserve import add_routes app = FastAPI( title="LangChain Server", version="1.0", description="A simple api server using Langchain's Runnable interfaces",
) add_routes( app, ChatOpenAI(), path="/openai",
) add_routes( app, ChatAnthropic(), path="/anthropic",
) model = ChatAnthropic()
prompt = ChatPromptTemplate.from_template("tell me a joke about {topic}")
add_routes( app, prompt | model, path="/chain",
) if __name__ == "__main__": import uvicorn uvicorn.run(app, host="localhost", port=8000)
Yukarıdaki sunucuyu dağıttıktan sonra, oluşturulan OpenAPI belgelerini aşağıdakileri kullanarak görüntüleyebilirsiniz:
curl localhost:8000/docs
/docs son ekini eklediğinizden emin olun.
from langchain.schema import SystemMessage, HumanMessage
from langchain.prompts import ChatPromptTemplate
from langchain.schema.runnable import RunnableMap
from langserve import RemoteRunnable openai = RemoteRunnable("http://localhost:8000/openai/")
anthropic = RemoteRunnable("http://localhost:8000/anthropic/")
joke_chain = RemoteRunnable("http://localhost:8000/chain/") joke_chain.invoke({"topic": "parrots"}) # or async
await joke_chain.ainvoke({"topic": "parrots"}) prompt = [ SystemMessage(content='Act like either a cat or a parrot.'), HumanMessage(content='Hello!')
] # Supports astream
async for msg in anthropic.astream(prompt): print(msg, end="", flush=True) prompt = ChatPromptTemplate.from_messages( [("system", "Tell me a long story about {topic}")]
) # Can define custom chains
chain = prompt | RunnableMap({ "openai": openai, "anthropic": anthropic,
}) chain.batch([{ "topic": "parrots" }, { "topic": "cats" }])
TypeScript'te (LangChain.js sürüm 0.0.166 veya üzerini gerektirir):
import { RemoteRunnable } from "langchain/runnables/remote"; const chain = new RemoteRunnable({ url: `http://localhost:8000/chain/invoke/`,
});
const result = await chain.invoke({ topic: "cats",
});
İstekleri kullanan Python:
import requests
response = requests.post( "http://localhost:8000/chain/invoke/", json={'input': {'topic': 'cats'}}
)
response.json()
Kıvrılmayı da kullanabilirsiniz:
curl --location --request POST 'http://localhost:8000/chain/invoke/' --header 'Content-Type: application/json' --data-raw '{ "input": { "topic": "cats" } }'
Aşağıdaki kod:
...
add_routes( app, runnable, path="/my_runnable",
)
bu uç noktaların sunucuya eklenmesi:
- POST /my_runnable/invoke – çalıştırılabilir olanı tek bir girişte çağırır
- POST /my_runnable/batch – bir grup girdide çalıştırılabilir olanı çağırır
- POST /my_runnable/stream – tek bir girişi çağırır ve çıktıyı yayınlar
- POST /my_runnable/stream_log – tek bir girişi çağırır ve ara adımların çıktısı da dahil olmak üzere, oluşturulduğu anda çıktıyı yayınlar
- GET /my_runnable/input_schema – çalıştırılabilir girdiye yönelik json şeması
- GET /my_runnable/output_schema – çalıştırılabilirin çıktısı için json şeması
- GET /my_runnable/config_schema – çalıştırılabilirin yapılandırması için json şeması
Koşulunuz için bir oyun alanı sayfasını /my_runnable/playground adresinde bulabilirsiniz. Bu, akış çıktısı ve ara adımlarla çalıştırılabilir dosyanızı yapılandırmak ve çağırmak için basit bir kullanıcı arayüzünü ortaya çıkarır.
Hem istemci hem de sunucu için:
pip install "langserve[all]"
veya istemci kodu için pip install “langserve[client]” ve sunucu kodu için pip install “langserve[server]”.
Sunucunuza kimlik doğrulama eklemeniz gerekiyorsa lütfen FastAPI'nin güvenlik belgelerine ve ara yazılım belgelerine bakın.
Aşağıdaki komutu kullanarak GCP Cloud Run'a dağıtım yapabilirsiniz:
gcloud run deploy [your-service-name] --source . --port 8001 --allow-unauthenticated --region us-central1 --set-env-vars=OPENAI_API_KEY=your_key
LangServe, Pydantic 2'ye bazı sınırlamalarla destek sağlar. Pydantic V2 kullanılırken invoke/batch/stream/stream_log için OpenAPI belgeleri oluşturulmayacak. Fast API, pydantic v1 ve v2 ad alanlarının karıştırılmasını desteklemez. LangChain, Pydantic v1'de v2 ad alanını kullanır. LangChain ile uyumluluğu sağlamak için lütfen aşağıdaki yönergeleri okuyun. Bu sınırlamalar dışında API uç noktalarının, oyun alanının ve diğer özelliklerin beklendiği gibi çalışmasını bekliyoruz.
LLM uygulamaları genellikle dosyalarla ilgilenir. Dosya işlemeyi uygulamak için yapılabilecek farklı mimariler vardır; Yüksek düzeyde:
- Dosya, sunucuya özel bir uç nokta aracılığıyla yüklenebilir ve ayrı bir uç nokta kullanılarak işlenebilir.
- Dosya, değere (dosyanın baytı) veya referansa (örneğin, dosya içeriğinin s3 URL'si) göre yüklenebilir.
- İşleme uç noktası engelleyici olabilir veya engelleyici olmayabilir.
- Önemli düzeyde işleme gerekiyorsa, işleme özel bir işlem havuzuna aktarılabilir.
Uygulamanıza uygun mimarinin ne olduğunu belirlemelisiniz. Şu anda dosyaları değere göre çalıştırılabilir bir dosyaya yüklemek için dosya için base64 kodlamasını kullanın (multipart/form-data henüz desteklenmiyor).
İşte bulunuyor örnek Bu, bir dosyayı uzaktan çalıştırılabilir bir dosyaya göndermek için base64 kodlamasının nasıl kullanılacağını gösterir. Dosyaları her zaman referansa göre (örneğin, s3 URL'si) yükleyebileceğinizi veya bunları çok parçalı/form verisi olarak özel bir uç noktaya yükleyebileceğinizi unutmayın.
Giriş ve Çıkış türleri tüm çalıştırılabilirlerde tanımlanmıştır. Bunlara input_schema ve Output_schema özellikleri aracılığıyla erişebilirsiniz. LangServe bu türleri doğrulama ve belgeleme için kullanır. Varsayılan çıkarım türlerini geçersiz kılmak istiyorsanız with_types yöntemini kullanabilirsiniz.
İşte bu fikri açıklamak için bir oyuncak örneği:
from typing import Any
from fastapi import FastAPI
from langchain.schema.runnable import RunnableLambda app = FastAPI() def func(x: Any) -> int: """Mistyped function that should accept an int but accepts anything.""" return x + 1 runnable = RunnableLambda(func).with_types( input_schema=int,
) add_routes(app, runnable)
Verilerin seri durumundan çıkıp eşdeğer dict temsili yerine pydantic bir modele dönüştürülmesini istiyorsanız CustomUserType'tan devralın. Şu anda bu tür yalnızca sunucu tarafında çalışmaktadır ve istenen kod çözme davranışını belirtmek için kullanılmaktadır. Bu türden miras alınırsa, sunucu kodu çözülen türü bir dict'e dönüştürmek yerine pydantic model olarak tutacaktır.
from fastapi import FastAPI
from langchain.schema.runnable import RunnableLambda
from langserve import add_routes
from langserve.schema import CustomUserType app = FastAPI() class Foo(CustomUserType): bar: int def func(foo: Foo) -> int: """Sample function that expects a Foo type which is a pydantic model""" assert isinstance(foo, Foo) return foo.bar add_routes(app, RunnableLambda(func), path="/foo")
Oyun alanı, çalıştırılabilir cihazınız için arka uçtan özel widget'lar tanımlamanıza olanak tanır. Bir pencere öğesi alan düzeyinde belirtilir ve giriş türünün JSON şemasının bir parçası olarak gönderilir. Bir widget'ın, değeri iyi bilinen bir widget listesinden biri olan type adı verilen bir anahtar içermesi gerekir. Diğer widget anahtarları, bir JSON nesnesindeki yolları tanımlayan değerlerle ilişkilendirilecektir.
Genel şema:
type JsonPath = number | string | (number | string)[];
type NameSpacedPath = { title: string; path: JsonPath }; // Using title to mimic json schema, but can use namespace
type OneOfPath = { oneOf: JsonPath[] }; type Widget = { type: string // Some well-known type (e.g., base64file, chat, etc.) [key: string]: JsonPath | NameSpacedPath | OneOfPath;
};
Base64 kodlu dizeler olarak yüklenen dosyalar için kullanıcı arayüzü oyun alanında bir dosya yükleme girişi oluşturulmasına izin verir. İşte tam örnek.
try: from pydantic.v1 import Field
except ImportError: from pydantic import Field from langserve import CustomUserType # ATTENTION: Inherit from CustomUserType instead of BaseModel otherwise
# the server will decode it into a dict instead of a pydantic model.
class FileProcessingRequest(CustomUserType): """Request including a base64 encoded file.""" # The extra field is used to specify a widget for the playground UI. file: str = Field(..., extra={"widget": {"type": "base64file"}}) num_chars: int = 100
Nanonets tarafından siz ve ekipleriniz için tasarlanan yapay zeka odaklı iş akışı oluşturucumuzla manuel görevleri ve iş akışlarını otomatikleştirin.
LangSmith'e Giriş
LangChain, LLM uygulamalarının ve Aracılarının prototipini oluşturmayı kolaylaştırır. Ancak LLM uygulamalarının üretime sunulması aldatıcı derecede zor olabilir. Yüksek kaliteli bir ürün oluşturmak için büyük olasılıkla istemlerinizi, zincirlerinizi ve diğer bileşenlerinizi yoğun bir şekilde özelleştirmeniz ve yinelemeniz gerekecektir.
Bu sürece yardımcı olmak amacıyla, LLM uygulamalarınızda hata ayıklama, test etme ve izleme için birleşik bir platform olan LangSmith tanıtıldı.
Bu ne zaman işe yarayabilir? Yeni bir zincirde, aracıda veya araç setinde hızlı bir şekilde hata ayıklamak istediğinizde, bileşenlerin (zincirler, llm'ler, alıcılar vb.) nasıl ilişkilendiğini ve kullanıldığını görselleştirmek, tek bir bileşen için farklı istemleri ve LLM'leri değerlendirmek istediğinizde bunu yararlı bulabilirsiniz. Belirli bir zincirin sürekli olarak kalite çıtasını karşıladığından emin olmak için belirli bir zinciri bir veri kümesi üzerinde birkaç kez çalıştırın veya kullanım izlerini yakalayın ve içgörü oluşturmak için LLM'leri veya analiz hatlarını kullanın.
Önkoşul:
- LangSmith hesabı oluşturun ve bir API anahtarı oluşturun (sol alt köşeye bakın).
- Dokümanlara bakarak platforma alışın.
Şimdi başlayalım!
Öncelikle ortam değişkenlerinizi LangChain'e izleri günlüğe kaydetmesini bildirecek şekilde yapılandırın. Bu, LANGCHAIN_TRACING_V2 ortam değişkenini true olarak ayarlayarak yapılır. LANGCHAIN_PROJECT ortam değişkenini ayarlayarak LangChain'e hangi projede oturum açacağını söyleyebilirsiniz (bu ayarlanmazsa, çalışmalar varsayılan projeye kaydedilir). Bu, mevcut değilse projeyi sizin için otomatik olarak oluşturacaktır. LANGCHAIN_ENDPOINT ve LANGCHAIN_API_KEY ortam değişkenlerini de ayarlamanız gerekir.
NOT: Aşağıdakileri kullanarak izlemeleri günlüğe kaydetmek için python'da bir içerik yöneticisi de kullanabilirsiniz:
from langchain.callbacks.manager import tracing_v2_enabled with tracing_v2_enabled(project_name="My Project"): agent.run("How many people live in canada as of 2023?")
Ancak bu örnekte ortam değişkenlerini kullanacağız.
%pip install openai tiktoken pandas duckduckgo-search --quiet import os
from uuid import uuid4 unique_id = uuid4().hex[0:8]
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_PROJECT"] = f"Tracing Walkthrough - {unique_id}"
os.environ["LANGCHAIN_ENDPOINT"] = "https://api.smith.langchain.com"
os.environ["LANGCHAIN_API_KEY"] = "<YOUR-API-KEY>" # Update to your API key # Used by the agent in this tutorial
os.environ["OPENAI_API_KEY"] = "<YOUR-OPENAI-API-KEY>"
API ile etkileşim kurmak için LangSmith istemcisini oluşturun:
from langsmith import Client client = Client()
Bir LangChain bileşeni oluşturun ve işlemleri platforma kaydedin. Bu örnekte, genel bir arama aracına (DuckDuckGo) erişimi olan ReAct tarzı bir aracı oluşturacağız. Temsilcinin istemi burada Hub'da görüntülenebilir:
from langchain import hub
from langchain.agents import AgentExecutor
from langchain.agents.format_scratchpad import format_to_openai_function_messages
from langchain.agents.output_parsers import OpenAIFunctionsAgentOutputParser
from langchain.chat_models import ChatOpenAI
from langchain.tools import DuckDuckGoSearchResults
from langchain.tools.render import format_tool_to_openai_function # Fetches the latest version of this prompt
prompt = hub.pull("wfh/langsmith-agent-prompt:latest") llm = ChatOpenAI( model="gpt-3.5-turbo-16k", temperature=0,
) tools = [ DuckDuckGoSearchResults( name="duck_duck_go" ), # General internet search using DuckDuckGo
] llm_with_tools = llm.bind(functions=[format_tool_to_openai_function(t) for t in tools]) runnable_agent = ( { "input": lambda x: x["input"], "agent_scratchpad": lambda x: format_to_openai_function_messages( x["intermediate_steps"] ), } | prompt | llm_with_tools | OpenAIFunctionsAgentOutputParser()
) agent_executor = AgentExecutor( agent=runnable_agent, tools=tools, handle_parsing_errors=True
)
Gecikmeyi azaltmak için aracıyı aynı anda birden fazla girişte çalıştırıyoruz. Çalıştırmalar arka planda LangSmith'e kaydedilir, böylece yürütme gecikmesi etkilenmez:
inputs = [ "What is LangChain?", "What's LangSmith?", "When was Llama-v2 released?", "What is the langsmith cookbook?", "When did langchain first announce the hub?",
] results = agent_executor.batch([{"input": x} for x in inputs], return_exceptions=True) results[:2]
Ortamınızı başarıyla kurduğunuzu varsayarsak aracı izlerinizin uygulamadaki Projeler bölümünde görünmesi gerekir. Tebrikler!
Ancak temsilcinin araçları etkili bir şekilde kullanamadığı anlaşılıyor. Bunu değerlendirelim ki bir temelimiz olsun.
LangSmith, günlük tutma işlemlerine ek olarak LLM uygulamalarınızı test etmenize ve değerlendirmenize de olanak tanır.
Bu bölümde, bir kıyaslama veri kümesi oluşturmak ve bir aracı üzerinde yapay zeka destekli değerlendiricileri çalıştırmak için LangSmith'ten yararlanacaksınız. Bunu birkaç adımda yapacaksınız:
- LangSmith veri kümesi oluşturun:
Aşağıda, yukarıdaki giriş sorularından ve liste etiketlerinden bir veri kümesi oluşturmak için LangSmith istemcisini kullanıyoruz. Bunları daha sonra yeni bir temsilcinin performansını ölçmek için kullanacaksınız. Veri kümesi, uygulamanızda test senaryoları olarak kullanabileceğiniz giriş-çıkış çiftlerinden başka bir şey olmayan bir örnek koleksiyonudur:
outputs = [ "LangChain is an open-source framework for building applications using large language models. It is also the name of the company building LangSmith.", "LangSmith is a unified platform for debugging, testing, and monitoring language model applications and agents powered by LangChain", "July 18, 2023", "The langsmith cookbook is a github repository containing detailed examples of how to use LangSmith to debug, evaluate, and monitor large language model-powered applications.", "September 5, 2023",
] dataset_name = f"agent-qa-{unique_id}" dataset = client.create_dataset( dataset_name, description="An example dataset of questions over the LangSmith documentation.",
) for query, answer in zip(inputs, outputs): client.create_example( inputs={"input": query}, outputs={"output": answer}, dataset_id=dataset.id )
- Karşılaştırma için yeni bir aracı başlatın:
LangSmith herhangi bir LLM'yi, zinciri, acenteyi ve hatta özel bir işlevi değerlendirmenize olanak tanır. Konuşma aracıları durum bilgilidir (hafızaları vardır); Bu durumun veri kümesi çalıştırmaları arasında paylaşılmadığından emin olmak için bir Chain_factory (
Her çağrı için başlatılacak diğer bir deyişle yapıcı) işlevi:
# Since chains can be stateful (e.g. they can have memory), we provide
# a way to initialize a new chain for each row in the dataset. This is done
# by passing in a factory function that returns a new chain for each row.
def agent_factory(prompt): llm_with_tools = llm.bind( functions=[format_tool_to_openai_function(t) for t in tools] ) runnable_agent = ( { "input": lambda x: x["input"], "agent_scratchpad": lambda x: format_to_openai_function_messages( x["intermediate_steps"] ), } | prompt | llm_with_tools | OpenAIFunctionsAgentOutputParser() ) return AgentExecutor(agent=runnable_agent, tools=tools, handle_parsing_errors=True)
- Değerlendirmeyi yapılandırın:
Kullanıcı arayüzündeki zincirlerin sonuçlarının manuel olarak karşılaştırılması etkilidir ancak zaman alıcı olabilir. Bileşeninizin performansını değerlendirmek için otomatik ölçümleri ve yapay zeka destekli geri bildirimleri kullanmak yararlı olabilir:
from langchain.evaluation import EvaluatorType
from langchain.smith import RunEvalConfig evaluation_config = RunEvalConfig( evaluators=[ EvaluatorType.QA, EvaluatorType.EMBEDDING_DISTANCE, RunEvalConfig.LabeledCriteria("helpfulness"), RunEvalConfig.LabeledScoreString( { "accuracy": """
Score 1: The answer is completely unrelated to the reference.
Score 3: The answer has minor relevance but does not align with the reference.
Score 5: The answer has moderate relevance but contains inaccuracies.
Score 7: The answer aligns with the reference but has minor errors or omissions.
Score 10: The answer is completely accurate and aligns perfectly with the reference.""" }, normalize_by=10, ), ], custom_evaluators=[],
)
- Aracıyı ve değerlendiricileri çalıştırın:
Modelinizi değerlendirmek için run_on_dataset (veya eşzamansız arun_on_dataset) işlevini kullanın. Bu irade:
- Belirtilen veri kümesinden örnek satırları getir.
- Her örnekte aracınızı (veya herhangi bir özel işlevi) çalıştırın.
- Otomatik geri bildirim oluşturmak için, sonuçta ortaya çıkan çalıştırma izlerine ve ilgili referans örneklerine değerlendiriciler uygulayın.
Sonuçlar LangSmith uygulamasında görünecek:
chain_results = run_on_dataset( dataset_name=dataset_name, llm_or_chain_factory=functools.partial(agent_factory, prompt=prompt), evaluation=evaluation_config, verbose=True, client=client, project_name=f"runnable-agent-test-5d466cbc-{unique_id}", tags=[ "testing-notebook", "prompt:5d466cbc", ],
)
Artık test çalıştırması sonuçlarımızı aldığımıza göre aracımızda değişiklikler yapabilir ve bunları karşılaştırabiliriz. Bunu farklı bir komutla tekrar deneyelim ve sonuçları görelim:
candidate_prompt = hub.pull("wfh/langsmith-agent-prompt:39f3bbd0") chain_results = run_on_dataset( dataset_name=dataset_name, llm_or_chain_factory=functools.partial(agent_factory, prompt=candidate_prompt), evaluation=evaluation_config, verbose=True, client=client, project_name=f"runnable-agent-test-39f3bbd0-{unique_id}", tags=[ "testing-notebook", "prompt:39f3bbd0", ],
)
LangSmith, verileri doğrudan web uygulamasında CSV veya JSONL gibi yaygın formatlara aktarmanıza olanak tanır. İstemciyi ayrıca daha fazla analiz için çalıştırmaları getirmek, kendi veritabanınızda depolamak veya başkalarıyla paylaşmak için de kullanabilirsiniz. Değerlendirme çalıştırmasından çalıştırma izlerini alalım:
runs = client.list_runs(project_name=chain_results["project_name"], execution_order=1) # After some time, these will be populated.
client.read_project(project_name=chain_results["project_name"]).feedback_stats
Bu, başlangıç için hızlı bir kılavuzdu ancak geliştirici akışınızı hızlandırmak ve daha iyi sonuçlar elde etmek için LangSmith'i kullanmanın daha birçok yolu vardır.
LangSmith'ten en iyi şekilde nasıl yararlanabileceğiniz hakkında daha fazla bilgi için LangSmith belgelerine bakın.
Nanonet'lerle seviye atlayın
LangChain, dil modellerini (LLM'ler) uygulamalarınızla entegre etmek için değerli bir araç olsa da, kurumsal kullanım durumları söz konusu olduğunda sınırlamalarla karşılaşabilir. Nanonets'in bu zorlukların üstesinden gelmek için LangChain'in ötesine nasıl geçtiğini inceleyelim:
1. Kapsamlı Veri Bağlantısı:
LangChain bağlayıcılar sunar ancak işletmelerin güvendiği tüm çalışma alanı uygulamalarını ve veri formatlarını kapsamayabilir. Nanonets, Slack, Notion, Google Suite, Salesforce, Zendesk ve çok daha fazlası dahil olmak üzere yaygın olarak kullanılan 100'den fazla çalışma alanı uygulaması için veri bağlayıcıları sağlar. Ayrıca PDF'ler, TXT'ler, resimler, ses dosyaları ve video dosyaları gibi tüm yapılandırılmamış veri türlerinin yanı sıra CSV'ler, elektronik tablolar, MongoDB ve SQL veritabanları gibi yapılandırılmış veri türlerini de destekler.

2. Çalışma Alanı Uygulamaları için Görev Otomasyonu:
Metin/yanıt oluşturma harika çalışıyor olsa da, çeşitli uygulamalardaki görevleri gerçekleştirmek için doğal dilin kullanılması söz konusu olduğunda LangChain'in yetenekleri sınırlıdır. Nanonets, en popüler çalışma alanı uygulamaları için tetikleyici/eylem aracıları sunarak olayları dinleyen ve eylemleri gerçekleştiren iş akışları ayarlamanıza olanak tanır. Örneğin, doğal dil komutları aracılığıyla e-posta yanıtlarını, CRM girişlerini, SQL sorgularını ve daha fazlasını otomatikleştirebilirsiniz.
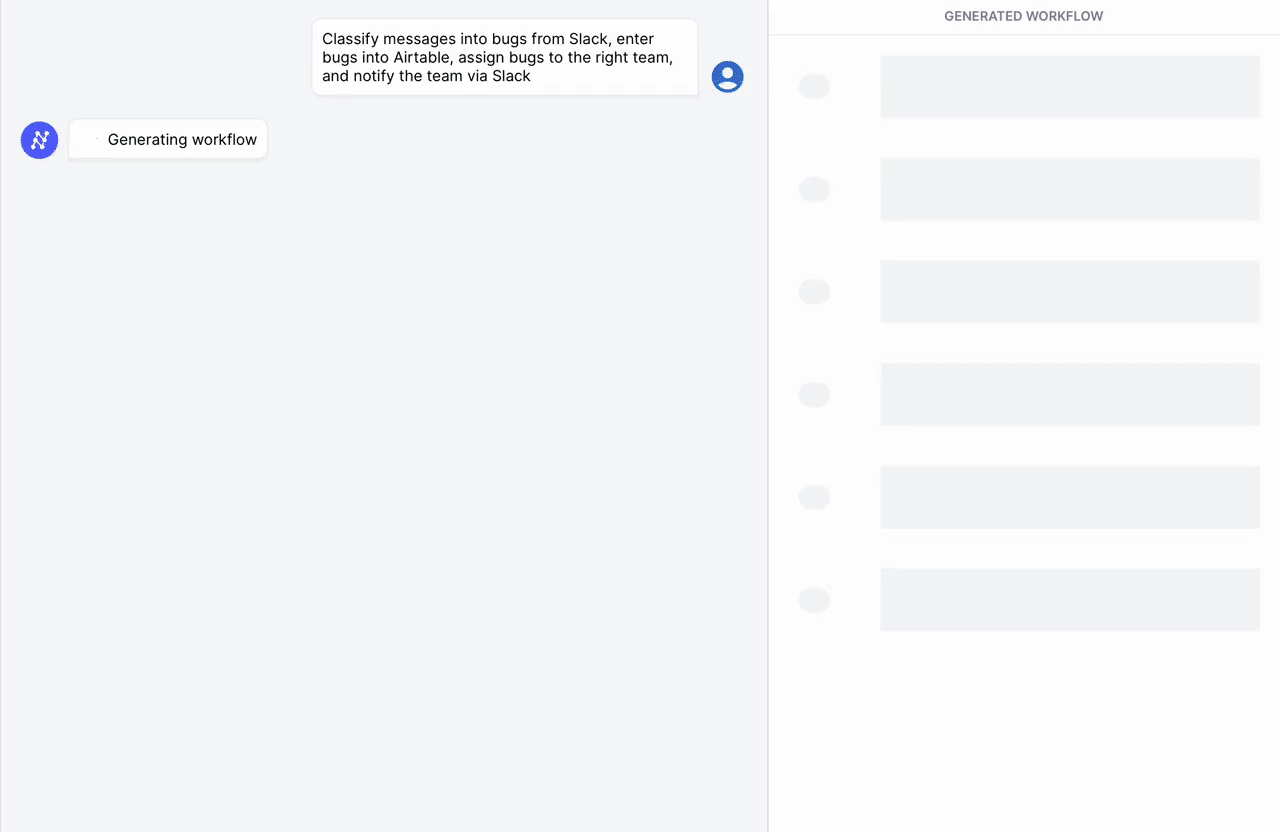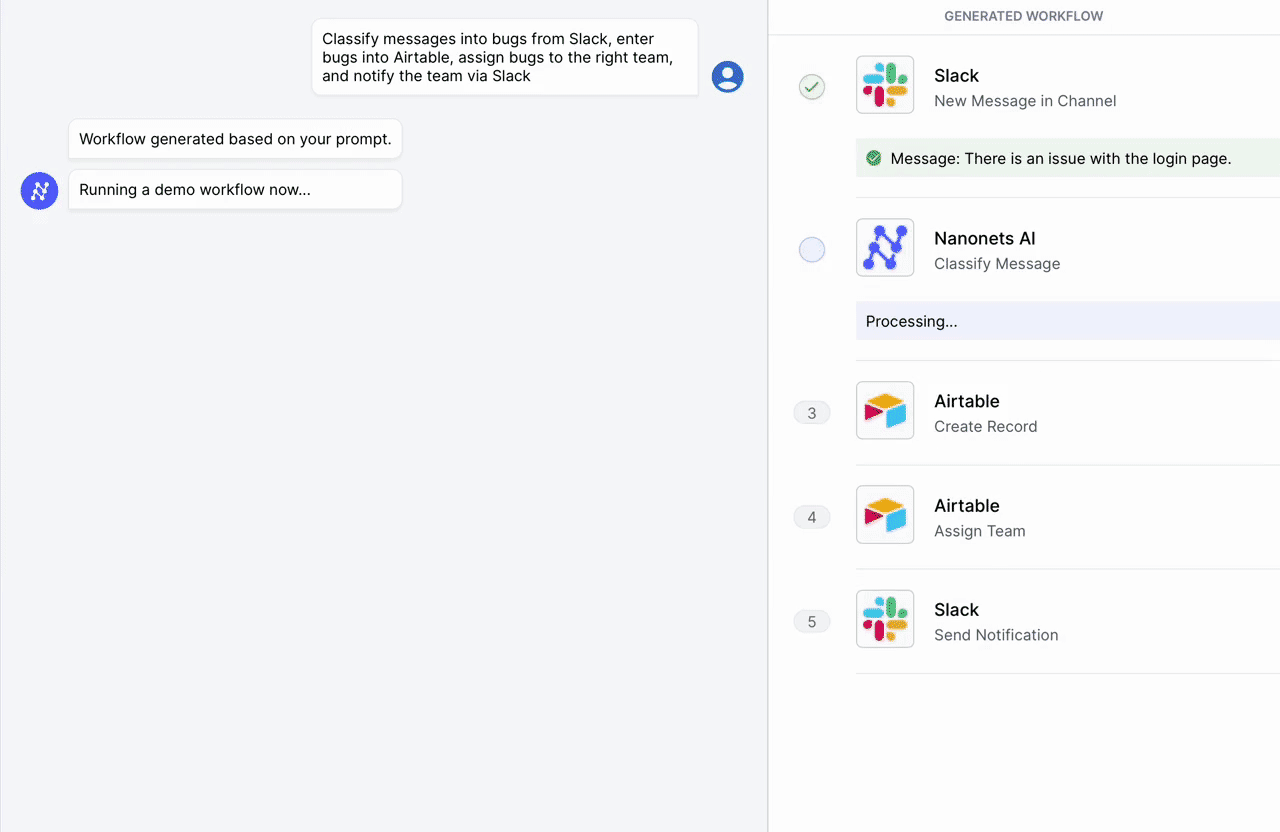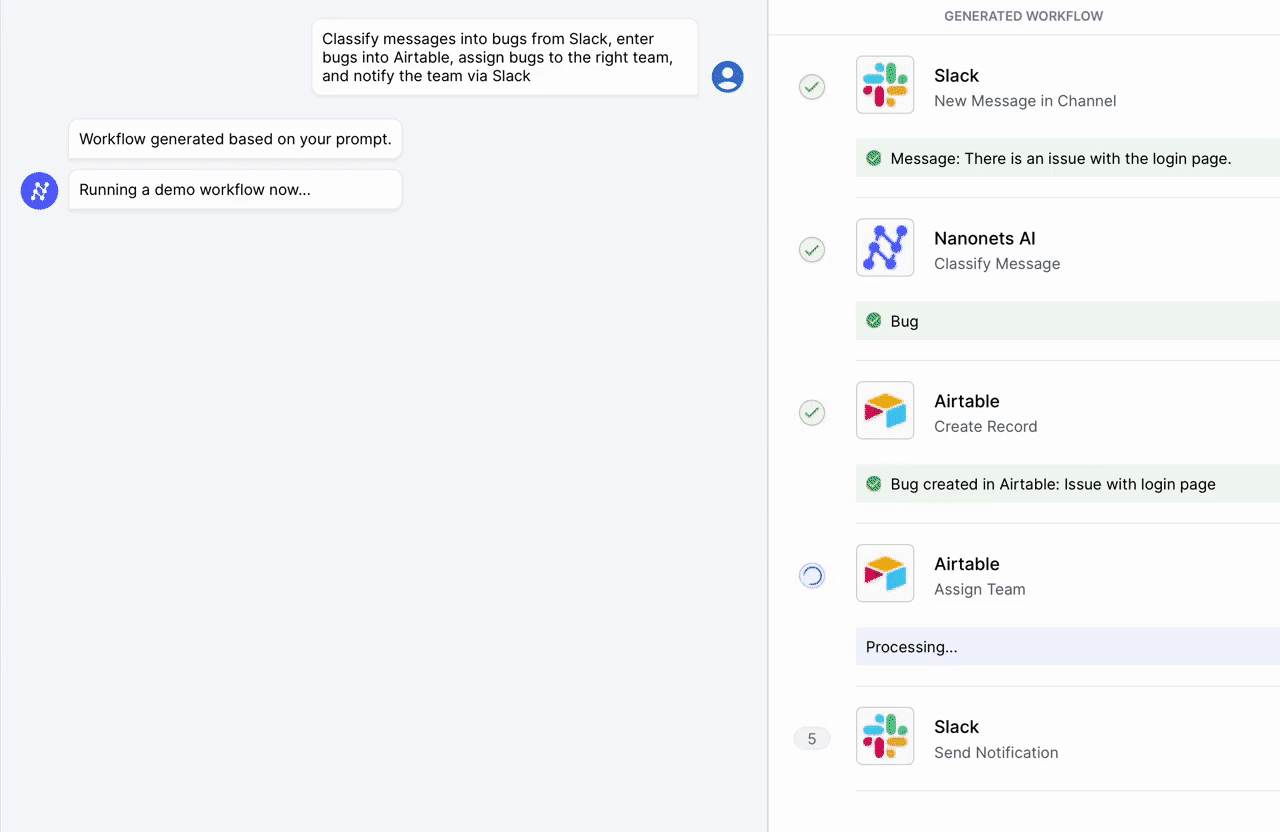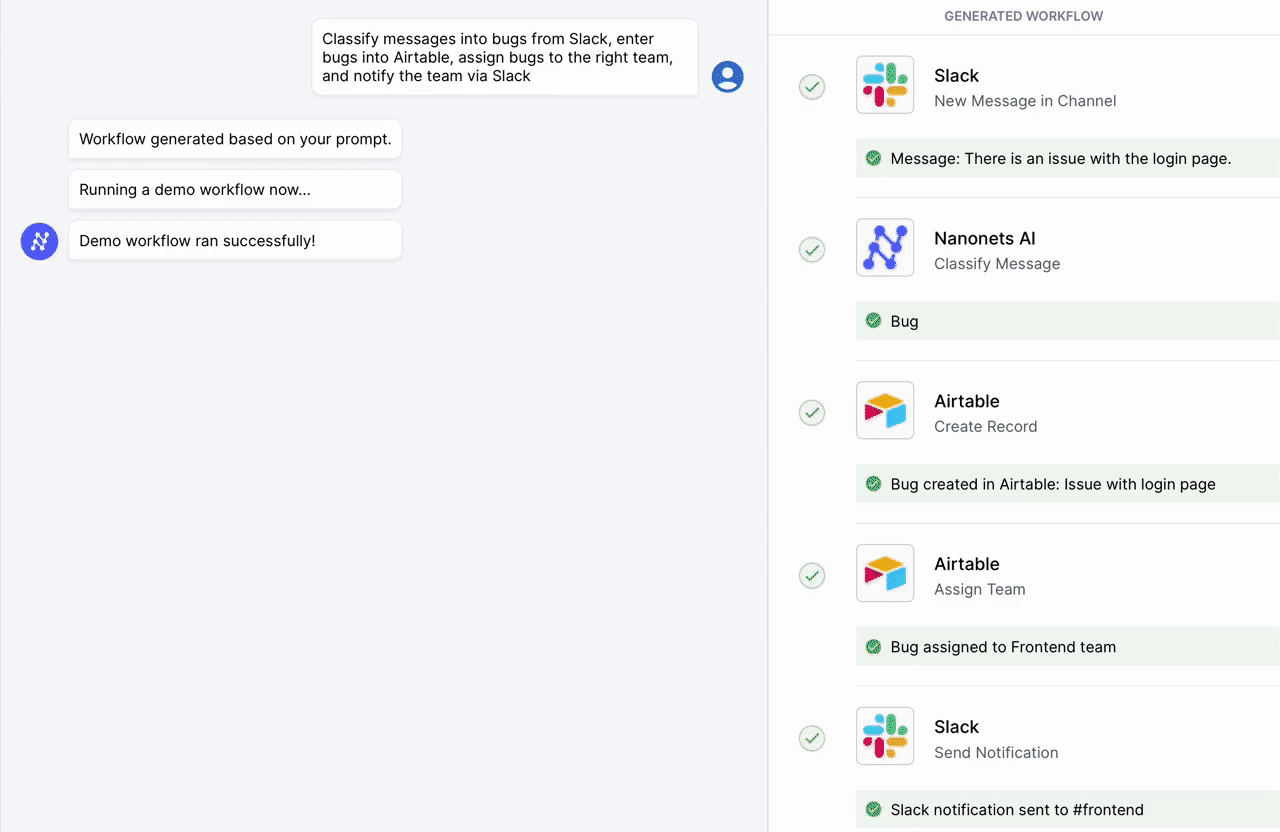
3. Gerçek Zamanlı Veri Senkronizasyonu:
LangChain, kaynak veritabanındaki veri değişikliklerine ayak uyduramayabilecek veri bağlayıcılarla statik verileri getirir. Buna karşılık Nanonets, veri kaynaklarıyla gerçek zamanlı senkronizasyon sağlayarak her zaman en son bilgilerle çalışmanızı sağlar.

3. Basitleştirilmiş Yapılandırma:
LangChain işlem hattının alıcılar ve sentezleyiciler gibi öğelerini yapılandırmak karmaşık ve zaman alıcı bir süreç olabilir. Nanonets, tümü arka planda Yapay Zeka Asistanı tarafından işlenen, her veri türü için optimize edilmiş veri alımı ve indeksleme sağlayarak bunu kolaylaştırır. Bu, ince ayar yükünü azaltır ve kurulumu ve kullanımı kolaylaştırır.
4. Birleşik Çözüm:
Her görev için benzersiz uygulamalar gerektirebilecek LangChain'den farklı olarak Nanonets, verilerinizi LLM'lere bağlamak için tek duraklı bir çözüm olarak hizmet eder. İster LLM uygulamaları ister yapay zeka iş akışları oluşturmanız gerekiyor olsun, Nanonets farklı ihtiyaçlarınız için birleşik bir platform sunar.
Nanonets Yapay Zeka İş Akışları
Nanonets İş Akışları, bilginizin ve verilerinizin Yüksek Lisans'larla entegrasyonunu basitleştiren ve kodsuz uygulamalar ve iş akışları oluşturulmasını kolaylaştıran, güvenli, çok amaçlı bir Yapay Zeka Asistanıdır. Kullanımı kolay bir kullanıcı arayüzü sunarak hem bireyler hem de kuruluşlar için erişilebilir hale getirir.
Başlamak için, özel kullanım durumunuza göre uyarlanmış Nanonets İş Akışlarının kişiselleştirilmiş bir demosunu ve deneme sürümünü sunabilecek yapay zeka uzmanlarımızdan biriyle bir görüşme planlayabilirsiniz.
Kurulduktan sonra, yüksek lisans eğitimleri tarafından desteklenen karmaşık uygulamaları ve iş akışlarını tasarlamak ve yürütmek için doğal dili kullanabilir, uygulamalarınız ve verilerinizle sorunsuz bir şekilde entegre olabilirsiniz.

Uygulamalar oluşturmak ve verilerinizi yapay zeka odaklı uygulamalar ve iş akışlarıyla entegre etmek için ekiplerinizi Nanonets AI ile güçlendirin, böylece ekiplerinizin gerçekten önemli olan şeylere odaklanmasına olanak tanıyın.
Nanonets tarafından siz ve ekipleriniz için tasarlanan yapay zeka odaklı iş akışı oluşturucumuzla manuel görevleri ve iş akışlarını otomatikleştirin.
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- PlatoData.Network Dikey Üretken Yapay Zeka. Kendine güç ver. Buradan Erişin.
- PlatoAiStream. Web3 Zekası. Bilgi Genişletildi. Buradan Erişin.
- PlatoESG. karbon, temiz teknoloji, Enerji, Çevre, Güneş, Atık Yönetimi. Buradan Erişin.
- PlatoSağlık. Biyoteknoloji ve Klinik Araştırmalar Zekası. Buradan Erişin.
- Kaynak: https://nanonets.com/blog/langchain/

