Bu, GoDaddy'den Brandon Abear, Dinesh Sharma, John Bush ve Ozcan IIikhan ile birlikte yazılan bir misafir yazısıdır.
GoDaddy Çevrimiçi başarıya ulaşmaları için tüm yardım ve araçları sağlayarak sıradan girişimcilere güç verir. Dünya çapında 20 milyondan fazla müşterisiyle GoDaddy, insanların fikirlerini dile getirmek, profesyonel bir web sitesi oluşturmak, müşteri çekmek ve işlerini yönetmek için geldikleri yerdir.
GoDaddy olarak veri odaklı bir şirket olmaktan gurur duyuyoruz. Verilerden değerli içgörüler elde etmeye yönelik aralıksız arayışımız, iş kararlarımızı güçlendirir ve müşteri memnuniyetini sağlar. Verimliliğe olan bağlılığımız değişmez ve toplu işleme işlerimizi optimize etmek için heyecan verici bir girişimde bulunduk. Bu yolculukta, iyileştirme fırsatlarının yedi katmanı olarak adlandırdığımız yapılandırılmış bir yaklaşım belirledik. Bu metodoloji verimlilik arayışımızda rehberimiz haline geldi.
Bu yazıda operasyonel verimliliği nasıl artırdığımızı tartışıyoruz. Amazon EMR Sunucusuz. Kıyaslama sonuçlarımızı ve metodolojimizi ve EMR Sunucusuz ve sabit kapasitenin maliyet etkinliğine ilişkin içgörülerimizi paylaşıyoruz EC2'de Amazon EMR kullanılarak düzenlenen veri iş akışlarımızdaki geçici kümeler Apache Airflow için Amazon Tarafından Yönetilen İş Akışları (Amazon MWAA). EMR Serverless'ın üstün olduğu alanlarda benimsenmesine yönelik stratejimizi paylaşıyoruz. Bulgularımız, %60'ın üzerinde maliyet azalması, %50 daha hızlı Spark iş yükleri, geliştirme ve test hızında beş kat kayda değer bir iyileşme ve karbon ayak izimizde önemli bir azalma dahil olmak üzere önemli faydaları ortaya koyuyor.
Olayın Arka Planı
2020'nin sonlarında GoDaddy'nin veri platformu, 800 PB veri içeren 2.5 düğümlü Hadoop kümesini veri merkezinden EC2'deki EMR'ye taşıyarak AWS Bulut yolculuğunu başlattı. Bu kaldır ve kaydır yaklaşımı, şirket içi ve bulut ortamları arasında doğrudan karşılaştırmayı kolaylaştırarak AWS ardışık düzenlerine sorunsuz bir geçiş sağlayarak veri doğrulama sorunlarını ve geçiş gecikmelerini en aza indirdi.
2022'nin başlarında büyük veri iş yüklerimizi başarıyla EC2'deki EMR'ye taşıdık. AWS FinHack programından öğrenilen en iyi uygulamaları kullanarak, kaynak yoğun işlerde ince ayar yaptık, Pig ve Hive işlerini Spark'a dönüştürdük ve 22.75'de toplu iş yükü harcamamızı %2022 oranında azalttık. Ancak işlerin çokluğu nedeniyle ölçeklenebilirlik zorlukları ortaya çıktı. . Bu, GoDaddy'yi daha sürdürülebilir ve verimli büyük veri işleme için temel oluşturarak sistematik bir optimizasyon yolculuğuna çıkmaya teşvik etti.
Yedi katman iyileştirme fırsatı
Operasyonel verimlilik arayışımızda, aşağıdaki şekilde gösterildiği gibi toplu işleme işlerimizde optimizasyon için yedi farklı fırsat katmanı belirledik. Bu katmanlar, hassas kod düzeyindeki iyileştirmelerden daha kapsamlı platform iyileştirmelerine kadar uzanır. Bu çok katmanlı yaklaşım, daha iyi performans ve daha yüksek verimlilik arayışımızda stratejik planımız haline geldi.

Katmanlar aşağıdaki gibidir:
- Kod optimizasyonu – Kod mantığını iyileştirmeye ve daha iyi performans için nasıl optimize edilebileceğine odaklanır. Bu, seçici önbelleğe alma, bölümleme ve projeksiyon budama, birleştirme optimizasyonları ve diğer işe özgü ayarlamalar yoluyla performans iyileştirmelerini içerir. Yapay zeka kodlama çözümlerinin kullanılması da bu sürecin ayrılmaz bir parçasıdır.
- Yazılım güncellemeleri - Yeni özelliklerden ve iyileştirmelerden yararlanmak için açık kaynaklı yazılımın (OSS) en son sürümlerine güncelleme. Örneğin Spark 3'teki Uyarlanabilir Sorgu Yürütme, önemli performans ve maliyet iyileştirmeleri sağlar.
- Özel Spark yapılandırmaları - Kaynak kullanımını, belleği ve paralelliği en üst düzeye çıkarmak için özel Spark yapılandırmalarının ayarlanması. Görevleri doğru boyutlandırarak önemli iyileştirmeler elde edebiliriz.
spark.sql.shuffle.partitions,spark.sql.files.maxPartitionBytes,spark.executor.cores, vespark.executor.memory. Ancak bu özel yapılandırmalar, belirli Spark sürümüyle uyumlu olmadıkları takdirde verimsiz olabilir. - Kaynak sağlama süresi - Geçici EMR kümeleri gibi kaynakların başlatılması için gereken süre Amazon Elastik Bilgi İşlem Bulutu (Amazon EC2). Bu süreyi etkileyen bazı faktörler mühendisin kontrolü dışında olmasına rağmen, optimize edilebilecek faktörlerin belirlenmesi ve ele alınması, genel tedarik süresinin azaltılmasına yardımcı olabilir.
- Görev düzeyinde ince taneli ölçeklendirme - Bir görev içindeki her aşamanın ihtiyaçlarına göre CPU, bellek, disk ve ağ bant genişliği gibi kaynakları dinamik olarak ayarlama. Buradaki amaç, kaynak israfına yol açabilecek sabit küme boyutlarından kaçınmaktır.
- Bir iş akışındaki birden çok görev arasında ayrıntılı ölçeklendirme - Her görevin benzersiz kaynak gereksinimleri olduğu göz önüne alındığında, sabit bir kaynak boyutunun korunması, aynı iş akışı içindeki belirli görevler için gereğinden az veya fazla kaynak sağlanmasına neden olabilir. Geleneksel olarak en büyük görevin boyutu, çok görevli bir iş akışı için küme boyutunu belirler. Bununla birlikte, bir iş akışındaki birden fazla görev ve adımdaki kaynakların dinamik olarak ayarlanması, daha uygun maliyetli bir uygulamayla sonuçlanır.
- Platform düzeyinde geliştirmeler – Önceki katmanlardaki geliştirmeler yalnızca belirli bir işi veya iş akışını optimize edebilir. Platform iyileştirmesi, şirket düzeyinde verimliliğe ulaşmayı amaçlamaktadır. Bunu, temel altyapıyı güncelleme veya yükseltme, yeni çerçeveler sunma, her iş profili için uygun kaynakları ayırma, hizmet kullanımını dengeleme, Tasarruf Planları ve Spot Bulut Sunucularının kullanımını optimize etme veya performansı artırmak için diğer kapsamlı değişiklikleri uygulama gibi çeşitli yollarla başarabiliriz. tüm görevler ve iş akışlarında verimlilik.
Katman 1-3: Önceki maliyet düşüşleri
Şirket içinden AWS Cloud'a geçiş yaptıktan sonra maliyet optimizasyonu çalışmalarımızı öncelikle şemada gösterilen ilk üç katmana odakladık. En maliyetli eski Pig ve Hive işlem hatlarımızı Spark'a geçirerek ve Spark yapılandırmalarını Amazon EMR için optimize ederek önemli ölçüde maliyet tasarrufu sağladık.
Örneğin, eski bir Pig işinin tamamlanması 10 saat sürdü ve en pahalı 10 EMR işi arasında yer aldı. TEZ günlüklerini ve küme metriklerini inceledikten sonra, işlenen veri hacmi için kümenin büyük ölçüde aşırı provizyonlandığını ve çalışma zamanının çoğunda yetersiz kullanıldığını keşfettik. Pig'den Spark'a geçiş daha verimli oldu. Dönüşüm için hiçbir otomatik araç mevcut olmasa da aşağıdakiler dahil olmak üzere manuel optimizasyonlar yapıldı:
- Gereksiz disk yazma işlemlerinin azaltılması, serileştirme ve seri durumdan çıkarma süresinden tasarruf (Katman 1)
- Airflow DAG'yi (Katman 1) basitleştirerek Airflow görevi paralelleştirmesi Spark ile değiştirildi
- Gereksiz Spark dönüşümleri ortadan kaldırıldı (Katman 1)
- Uyarlanabilir Sorgu Yürütme (Katman 2) kullanılarak Spark 3'den 2'e yükseltildi
- Eğik birleştirmeler ele alındı ve daha küçük boyut tabloları optimize edildi (Katman 3)
Bunun sonucunda iş maliyeti %95 oranında azaldı ve işin tamamlanma süresi 1 saate düştü. Ancak bu yaklaşım emek yoğundu ve çok sayıda iş için ölçeklenebilir değildi.
Katman 4-6: Doğru bilgi işlem çözümünü bulun ve benimseyin
2022'nin sonlarında, optimizasyonda önceki seviyelerde elde ettiğimiz önemli başarıların ardından dikkatimiz kalan katmanları geliştirmeye yöneldi.
Toplu işleme sürecimizin durumunu anlama
Buluttaki veri iş akışlarımızı uygun ölçekte düzenlemek için Amazon MWAA'yı kullanıyoruz. Apache Hava Akışı olarak adlandırılan süreç ve görev dizilerini programlı olarak yazmak, planlamak ve izlemek için kullanılan açık kaynaklı bir araçtır. iş akışları. Bu yazıda şartlar iş akışı ve iş Amazon MWAA tarafından düzenlenen görevlerden oluşan Yönlendirilmiş Döngüsel Grafiklere (DAG'ler) atıfta bulunarak birbirinin yerine kullanılır. Her iş akışı için sıralı veya paralel görevlerimiz ve hatta DAG'da her ikisinin bir kombinasyonu var. create_emr ve terminate_emr iş akışı boyunca sabit işlem kapasitesine sahip geçici bir EMR kümesinde çalışan görevler. İş yükümüzün bir kısmını optimize ettikten sonra bile, aşağıdaki şekilde gösterildiği gibi, iş akışındaki en yoğun kaynak gerektiren göreve dayalı olarak bilgi işlem kaynaklarının aşırı sağlanması nedeniyle yeterince kullanılmayan çok sayıda optimize edilmemiş iş akışımız vardı.
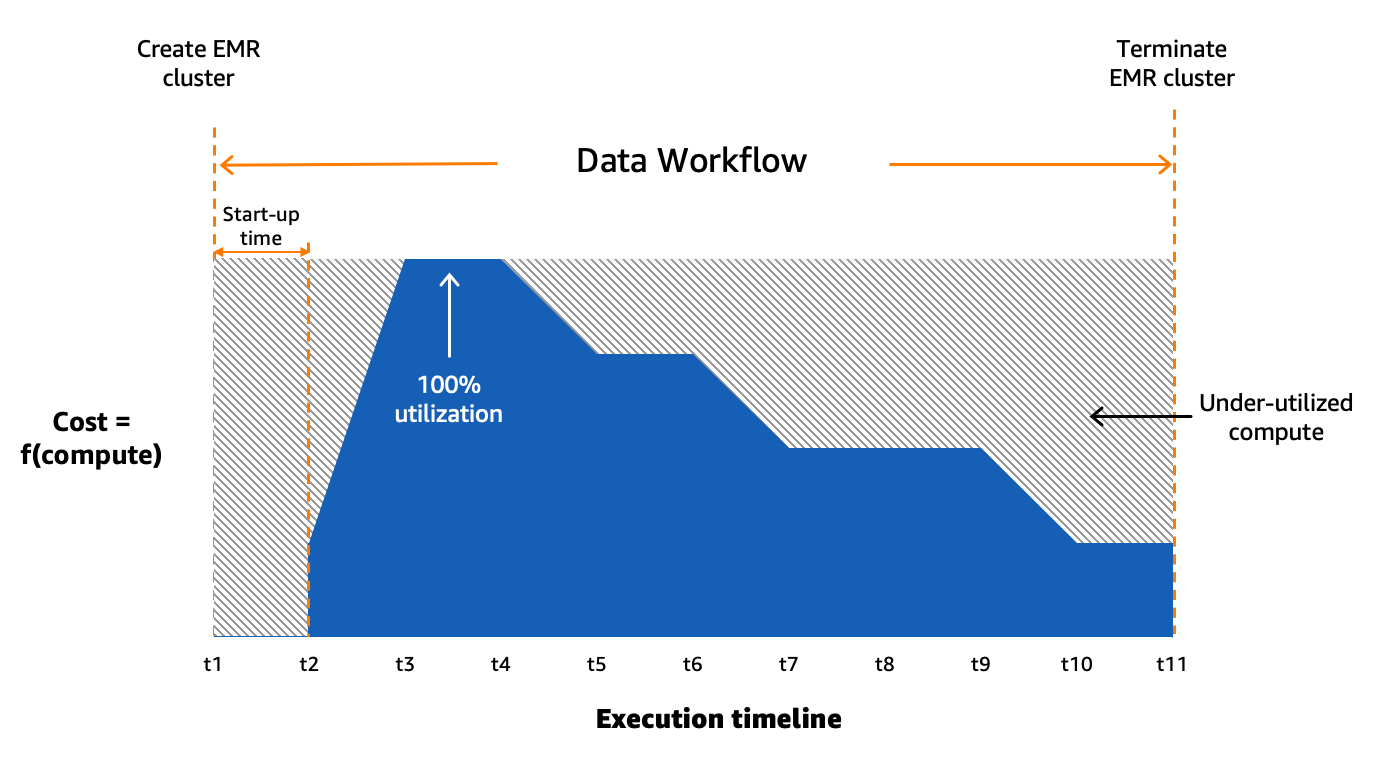
Bu, statik kaynak tahsisinin pratik olmadığını vurguladı ve dinamik bir kaynak tahsisi (DRA) sisteminin gerekliliğini anlamamıza yol açtı. Bir çözüm önermeden önce toplu işleme sürecimizi iyice anlamak için kapsamlı veriler topladık. Tedarik ve boşta kalma süresi hariç küme adım süresinin analiz edilmesi, önemli öngörüler ortaya çıkardı: iş akışlarının yarısından fazlasının 20 dakika veya daha kısa sürede tamamlandığı ve yalnızca %10'unun 60 dakikadan fazla sürdüğü sağa çarpık bir dağılım. Bu dağıtım, hızlı provizyon sağlayan bilgi işlem çözümü seçimimize rehberlik ederek iş akışı çalışma sürelerini önemli ölçüde azalttı. Aşağıdaki şema, toplu işleme hesaplarımızdan birindeki EC2 geçici kümelerindeki EMR'nin adım sürelerini (temel hazırlık ve boşta kalma süresi hariç) göstermektedir.
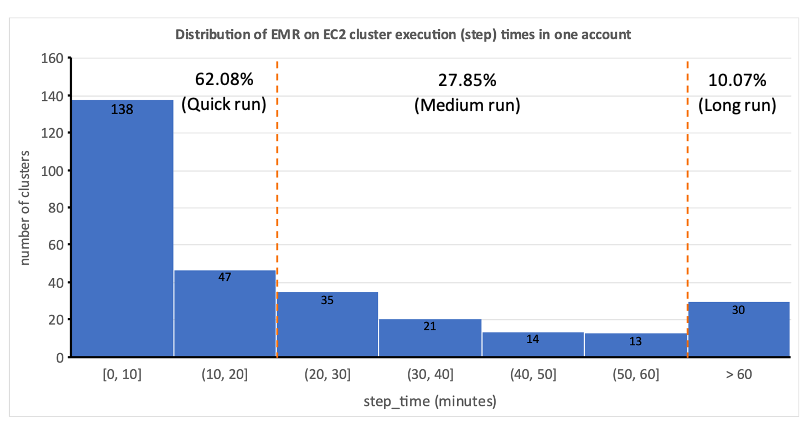
Ayrıca iş akışlarının adım süresi (temel hazırlık ve boşta kalma süresi hariç) dağılımına göre iş akışlarımızı üç gruba ayırdık:
- Hızlı koş – 20 dakika veya daha az süren
- Orta koşu – 20–60 dakika arası süren
- Uzun koşu – 60 dakikayı aşan, genellikle birkaç saat veya daha uzun süren
Göz önünde bulundurmamız gereken diğer bir faktör de güvenlik, iş ve maliyet izolasyonu ve amaca yönelik oluşturulmuş kümeler gibi nedenlerle geçici kümelerin yaygın kullanımıydı. Ayrıca, kaynak ihtiyaçlarında yoğun saatler ile düşük kullanım dönemleri arasında önemli bir farklılık vardı.
Sabit boyutlu kümeler yerine, bazı maliyet avantajları elde etmek için EC2'de EMR'de yönetilen ölçeklendirmeyi potansiyel olarak kullanabiliriz. Ancak EMR Sunucusuz'a geçiş, veri platformumuz için daha stratejik bir yön gibi görünüyor. EMR Sunucusuz, olası maliyet avantajlarının yanı sıra, en yeni Amazon EMR sürümlerine tek tıklamayla yükseltme, basitleştirilmiş operasyonel ve hata ayıklama deneyimi ve kullanıma sunulduktan sonra en yeni nesillere otomatik yükseltme gibi ek avantajlar sunar. Bu özellikler toplu olarak bir platformun daha büyük ölçekte çalıştırılma sürecini basitleştirir.
EMR Sunucusuz Değerlendirmesi: GoDaddy'de bir örnek olay çalışması
EMR Sunucusuz, Amazon EMR'de Apache Spark ve Apache Hive gibi büyük veri çerçevelerini çalıştırırken kümeleri yapılandırma, yönetme ve ölçeklendirmenin karmaşıklığını ortadan kaldıran sunucusuz bir seçenektir. İşletmeler, EMR Serverless ile maliyet etkinliği, daha hızlı kaynak sağlama, basitleştirilmiş geliştirici deneyimi ve Erişilebilirlik Alanı arızalarına karşı gelişmiş dayanıklılık gibi çok sayıda avantajdan yararlanabilir.
EMR Serverless'ın potansiyelinin farkında olarak, gerçek üretim iş akışlarını kullanarak derinlemesine bir karşılaştırma çalışması gerçekleştirdik. Çalışma, EMR Sunucusuz performansını ve verimliliğini değerlendirmeyi ve aynı zamanda büyük ölçekli uygulama için bir benimseme planı oluşturmayı amaçladı. Bulgular son derece cesaret vericiydi; EMR Serverless'ın iş yüklerimizi etkili bir şekilde işleyebildiğini gösteriyordu.
Kıyaslama metodolojisi
Veri iş akışlarımızı toplam adım süresine (temel hazırlık ve boşta kalma süresi hariç) dayalı olarak üç kategoriye ayırdık: hızlı çalıştırma (0-20 dakika), orta çalıştırma (20-60 dakika) ve uzun çalıştırma (60 dakikanın üzerinde). EMR dağıtım türünün (Amazon EC2 ile EMR Sunucusuz karşılaştırması) iki temel ölçüm üzerindeki etkisini analiz ettik: genel değerlendirme kriterlerimiz olarak hizmet eden maliyet verimliliği ve toplam çalışma süresi hızlandırması. Kullanım kolaylığını ve dayanıklılığı resmi olarak ölçmemiş olsak da, değerlendirme süreci boyunca bu faktörler dikkate alındı.
Çevreyi değerlendirmeye yönelik üst düzey adımlar aşağıdaki gibidir:
- Verileri ve ortamı hazırlayın:
- Her iş kategorisinden üç ila beş rastgele üretim işi seçin.
- Üretime müdahaleyi önlemek için gerekli ayarlamaları uygulayın.
- Testleri çalıştırın:
- Kesin ve tutarlı veri noktaları toplamak için komut dosyalarını birkaç gün boyunca veya birden çok yinelemeyle çalıştırın.
- EC2 ve EMR Sunucusuz'da EMR'yi kullanarak testler gerçekleştirin.
- Verileri ve test çalıştırmalarını doğrulayın:
- Aynı veri işlemeyi sağlamak için giriş ve çıkış veri kümelerini, bölümleri ve satır sayılarını doğrulayın.
- Metrikleri toplayın ve sonuçları analiz edin:
- Testlerden ilgili ölçümleri toplayın.
- İçgörü ve sonuçlar çıkarmak için sonuçları analiz edin.
Karşılaştırma sonuçları
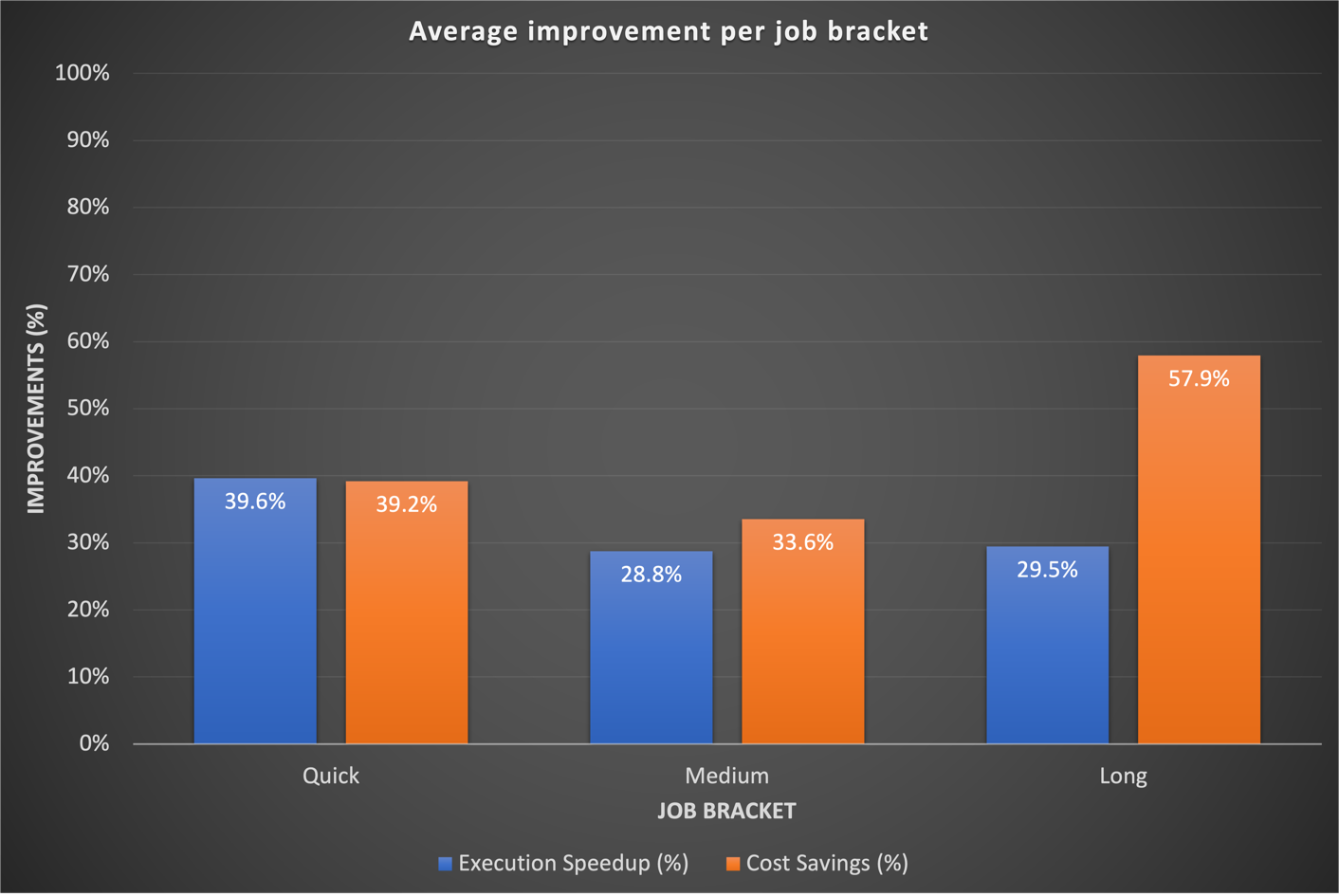
Karşılaştırma sonuçlarımız, hem çalışma süresi hızlandırması hem de maliyet verimliliği açısından üç iş kategorisinin tamamında önemli iyileştirmeler gösterdi. İyileştirmeler en çok hızlı işler için belirgindi ve doğrudan daha hızlı başlatma sürelerinden kaynaklanıyordu. Örneğin, EC20 geçici sabit bilgi işlem kapasitesi kümesindeki bir EMR üzerinde çalışan 2 dakikalık (küme sağlama ve kapatma dahil) veri iş akışı, EMR Sunucusuz'da 10 dakikada tamamlanır ve maliyet avantajlarıyla birlikte daha kısa bir çalışma süresi sağlar. Genel olarak, EMR Sunucusuz'a geçiş, aşağıdaki şekilde görüldüğü gibi iş grupları genelinde önemli performans iyileştirmeleri ve maliyet düşüşleri sağladı.
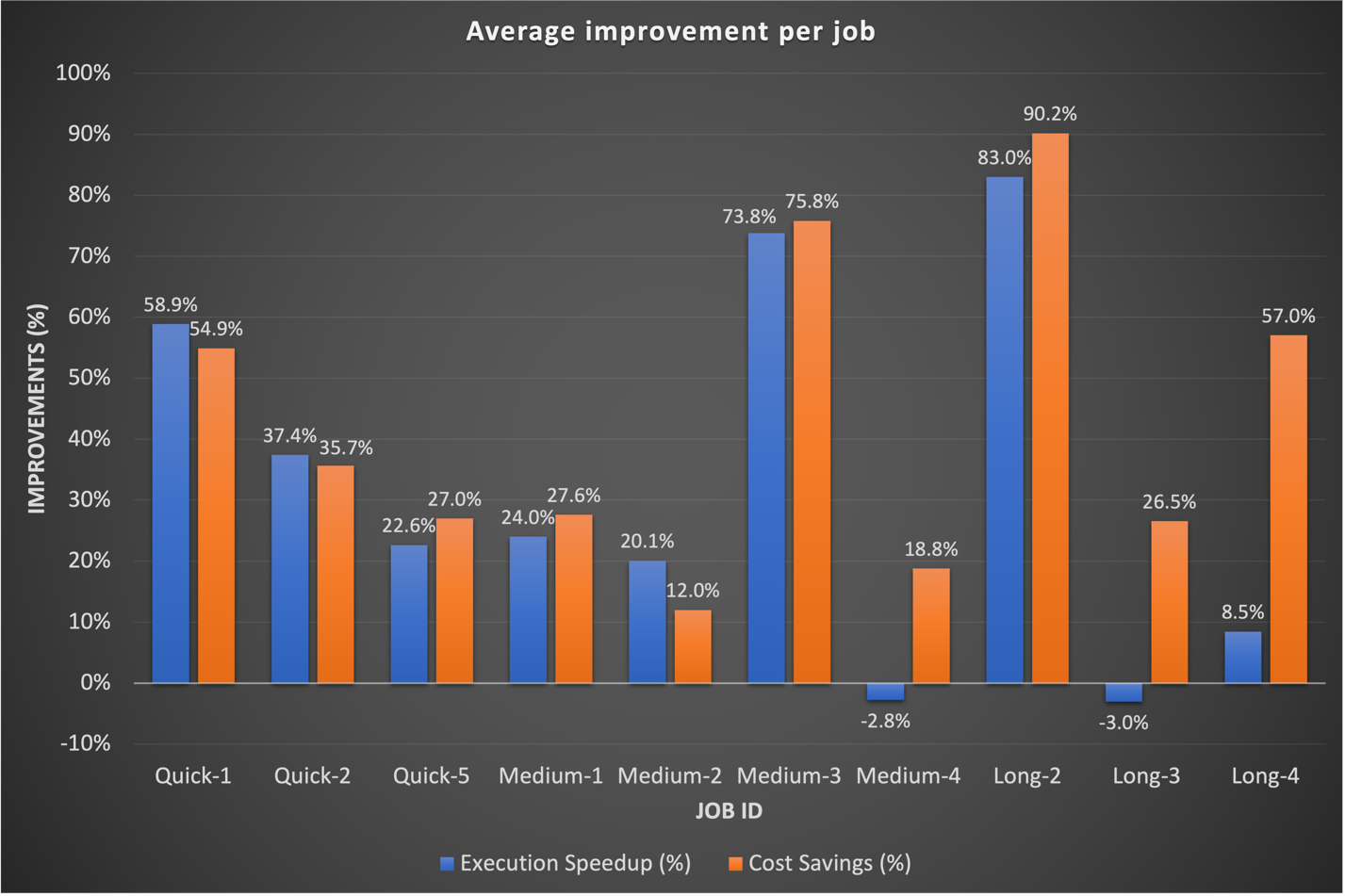
Geçmişte, uzun vadeli iş akışlarımızı ayarlamaya daha fazla zaman ayırıyorduk. İlginç bir şekilde, bu işler için mevcut özel Spark yapılandırmalarının EMR Sunucusuz'a her zaman iyi şekilde tercüme edilmediğini keşfettik. Sonuçların önemsiz olduğu durumlarda yaygın yaklaşım, yürütücü çekirdeklerle ilgili önceki Spark yapılandırmalarının atılmasıydı. EMR Serverless'ın bu Spark yapılandırmalarını özerk bir şekilde yönetmesine izin vererek çoğu zaman daha iyi sonuçlar elde ettiğimizi gözlemledik. Aşağıdaki grafik, EMR Serverless'ı EC2'deki EMR ile karşılaştırırken iş başına ortalama çalışma süresini ve maliyet iyileşmesini göstermektedir.
Aşağıdaki tabloda, Amazon EMR'nin farklı dağıtım seçeneklerinde (EC2'de EMR ve EMR Sunucusuz) çalışan aynı iş akışına ilişkin sonuçların örnek bir karşılaştırması gösterilmektedir.
| metrik | EC2'de EMR (Ortalama) |
EMR Sunucusuz (Ortalama) |
EC2'de EMR vs EMR Sunucusuz |
| Toplam Çalıştırma Maliyeti ($) | 5.82 ABD doları | 2.60 ABD doları | %55 |
| Toplam Çalışma Süresi (Dakika) | 53.40 | 39.40 | %26 |
| Hazırlama Süresi (Dakika) | 10.20 | 0.05 | . |
| Tedarik Maliyeti ($) | $1.19 | . | . |
| Adım Süresi (Dakika) | 38.20 | 39.16 | -3% |
| Adım Maliyeti ($) | $4.30 | . | . |
| Boşta Kalma Süresi (Dakika) | 4.80 | . | . |
| EMR Sürüm Etiketi | emr-6.9.0 | . | |
| Hadoop Dağıtımı | Amazon 3.3.3 | . | |
| Kıvılcım Sürümü | Spark 3.3.0 | . | |
| Hive/HCatalog Sürümü | Kovan 3.1.3, HKatalog 3.1.3 | . | |
| İş Türü | Kıvılcım | . | |
EMR Sunucusuz performans değerlendirmesinde AWS Graviton2
EMR Serverless'ın iş yüklerimiz için ilgi çekici sonuçlarını gördükten sonra, performansı daha ayrıntılı bir şekilde analiz etmeye karar verdik. AWS Graviton2 EMR Sunucusuz içindeki (arm64) mimarisi. AWS'nin vardı Benchmarking TPC-DS 2 TB ölçeğini kullanarak Graviton3 EMR Sunucusuz üzerinde iş yüklerini artırın ve genel olarak %27'lik bir fiyat-performans artışı gösterin.
Entegrasyonun avantajlarını daha iyi anlamak için GoDaddy'nin üretim iş yüklerini günlük programda kullanarak kendi çalışmamızı yürüttük ve Graviton23.8'yi kullanırken çeşitli işlerde %2'lik etkileyici bir fiyat-performans artışı gözlemledik. Bu çalışma hakkında daha fazla ayrıntı için bkz. GoDaddy karşılaştırması, Amazon EMR Serverless'ta AWS Graviton24 ile Spark iş yükleri için %2'e kadar daha iyi fiyat-performans oranı sağlıyor.
EMR Sunucusuz için benimseme stratejisi
Sistematik entegrasyona olanak tanıyan dağıtım halkaları aracılığıyla EMR Sunucusuz'un aşamalı olarak kullanıma sunulmasını stratejik olarak uyguladık. Bu aşamalı yaklaşım, iyileştirmeleri doğrulamamıza ve gerekirse EMR Sunucusuz'un daha fazla benimsenmesini durdurmamıza olanak tanıyor. Hem sorunları erken tespit etmek için bir güvenlik ağı hem de altyapımızı iyileştirmenin bir yolu olarak hizmet etti. Süreç, Veri Mühendisliği ve DevOps ekiplerimizin ekip uzmanlığını oluştururken, sorunsuz operasyonlar yoluyla değişimin etkisini azalttı. Ek olarak sıkı geri bildirim döngülerini destekleyerek hızlı ayarlamalara olanak sağladı ve verimli EMR Sunucusuz entegrasyon sağladı.
Aşağıdaki resimde gösterildiği gibi iş akışlarımızı üç ana benimseme grubuna ayırdık:
- Kanaryalar - Bu grup, olası sorunların dağıtım aşamasında erken tespit edilmesine ve çözülmesine yardımcı olur.
- Erken benimseyenler - Bu, ilk sorunlar Kanaryalar grubu tarafından belirlenip düzeltildikten sonra yeni bilgi işlem çözümünü benimseyen ikinci iş akışları grubudur.
- Geniş dağıtım halkaları - En büyük halka grubu olan bu grup, çözümün geniş ölçekli dağıtımını temsil eder. Bunlar önceki iki grupta başarılı test ve uygulama sonrasında devreye alınır.
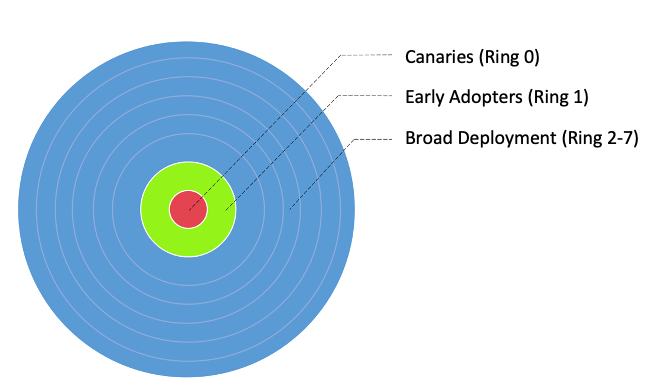
Aşağıdaki tabloda gösterildiği gibi, EMR Sunucusuz'u benimsemek için bu iş akışlarını ayrıntılı dağıtım halkalarına ayırdık.
| Yüzük # | Name | - Detaylar |
| 0 halkası | Kanarya | Maliyet tasarrufu sağlayan faydalar sağlaması beklenen düşük benimsenme riskli işler. |
| 1 halkası | Erken benimseyenler | Yüksek kazanç sağlamayı bekleyen, düşük riskli Hızlı çalıştırılan Spark işleri. |
| 2 halkası | Hızlı koş | Hızlı çalıştırmanın geri kalanı (step_time <= 20 dk) Kıvılcım işleri |
| 3 halkası | LargerJobs_EZ | Yüksek potansiyel kazanç, kolay taşınma, orta ve uzun vadeli Spark işleri |
| 4 halkası | Daha Büyük İşler | Orta vadeli ve uzun vadeli Spark işlerinin geri kalanı potansiyel kazanımlar sunuyor |
| 5 halkası | kovan | Potansiyel olarak daha yüksek maliyet tasarrufu sağlayan kovan işleri |
| 6 halkası | Kırmızıya kayma_EZ | Kolay geçiş EMR Serverless'a uygun Redshift işleri |
| 7 halkası | Glue_EZ | Kolay geçiş EMR Serverless'a uygun tutkal işleri |
Üretim benimseme sonuçlarının özeti
Cesaret verici kıyaslama ve kanarya benimseme sonuçları, GoDaddy'de EMR Sunucusuz'un daha geniş çapta benimsenmesine büyük ilgi uyandırdı. Şu ana kadar EMR Sunucusuz kullanıma sunma süreci devam ediyor. Şu ana kadar maliyetleri %62.5 oranında azalttı ve toplam toplu iş akışının tamamlanmasını %50.4 oranında hızlandırdı.
Ön değerlendirmelere dayanarak ekibimiz hızlı işler için önemli kazanımlar bekliyordu. Bizi şaşırtan bir şekilde, gerçek üretim dağıtımları tahminleri aştı; tahmin edilenin %64.4'sine kıyasla ortalama %42 daha hızlı ve tahmin edilenin %71.8'ına kıyasla %40 daha ucuz oldu.
Dikkat çekici bir şekilde, uzun süredir devam eden işlerde, EMR Sunucusuz'un hızlı tedariği ve dinamik kaynak tahsisinin mümkün kıldığı agresif ölçeklendirme sayesinde önemli performans iyileşmeleri görüldü. Yüksek kaynak segmentleri sırasında önemli paralellik gözlemledik, bu da geleneksel yaklaşımlara kıyasla %40.5 daha hızlı toplam çalışma süresi sağladı. Aşağıdaki grafik iş kategorisine göre ortalama iyileştirmeleri göstermektedir.
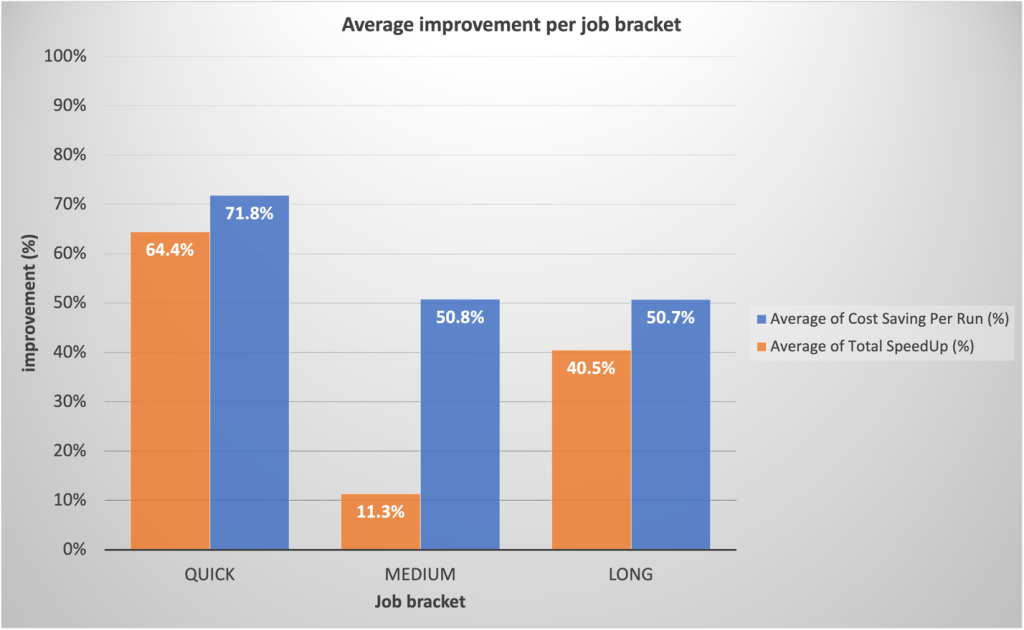
Ek olarak, aşağıdaki kutu-bıyık grafiğinde gösterildiği gibi, uzun vadeli iş kategorisinde hız iyileştirmeleri için en yüksek dağılım derecesini gözlemledik.
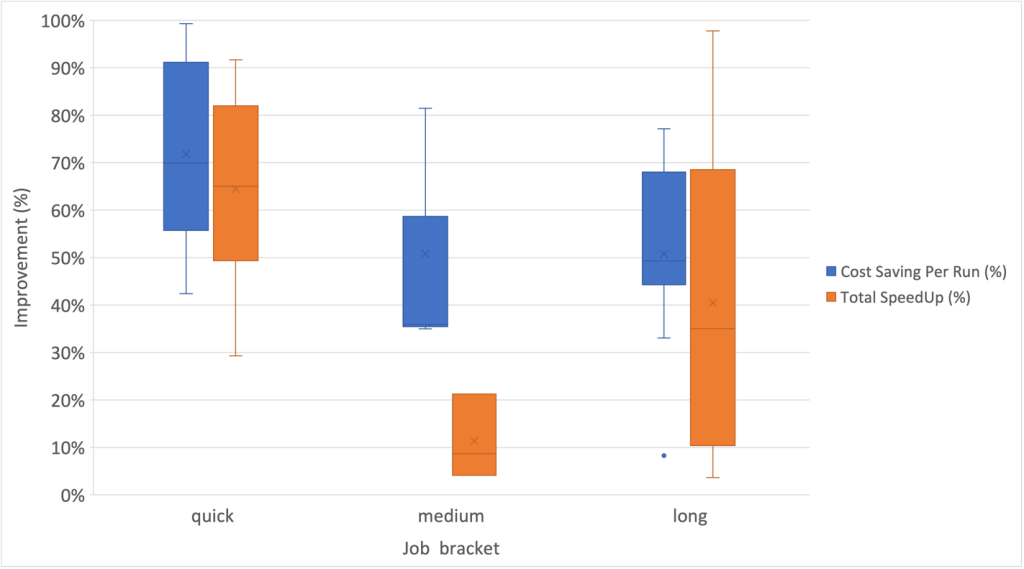
EMR Sunucusuz benimsenen örnek iş akışları
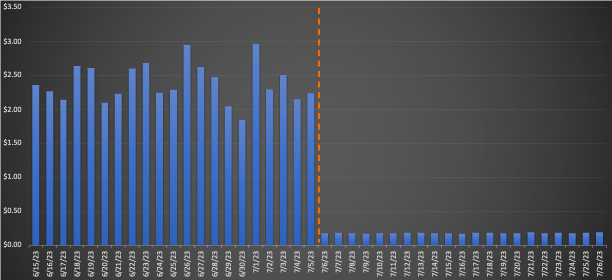
EMR Sunucusuz'a taşınan büyük bir iş akışı için, geçiş öncesi ve sonrası 3 haftalık ortalamalar karşılaştırıldığında etkileyici maliyet tasarrufları ortaya çıktı; perakende fiyatlandırmasına göre %75.30'luk bir düşüş ve toplam çalışma süresinde %10'luk bir iyileşme, operasyonel verimliliği artırdı. Aşağıdaki grafik maliyet eğilimini göstermektedir.
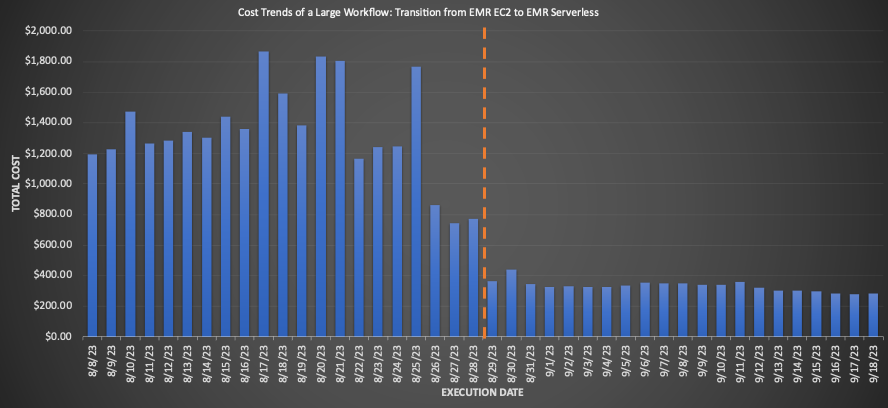
Hızlı çalıştırılan işler dolar başına minimum maliyet düşüşü sağlasa da, en önemli yüzde maliyet tasarrufunu sağladılar. Bu iş akışlarının binlercesinin her gün çalıştırılmasıyla, birikmiş tasarruflar ciddi boyutlara ulaşıyor. Aşağıdaki grafik, EC2'deki EMR'den EMR Sunucusuz'a geçirilen küçük bir iş yükünün maliyet eğilimini göstermektedir. Geçiş öncesi ve sonrası 3 haftalık ortalamalar karşılaştırıldığında, perakende isteğe bağlı fiyatlandırmada %92.43 oranında kayda değer bir maliyet tasarrufunun yanı sıra toplam çalışma süresinde %80.6'lık bir hızlanma ortaya çıktı.
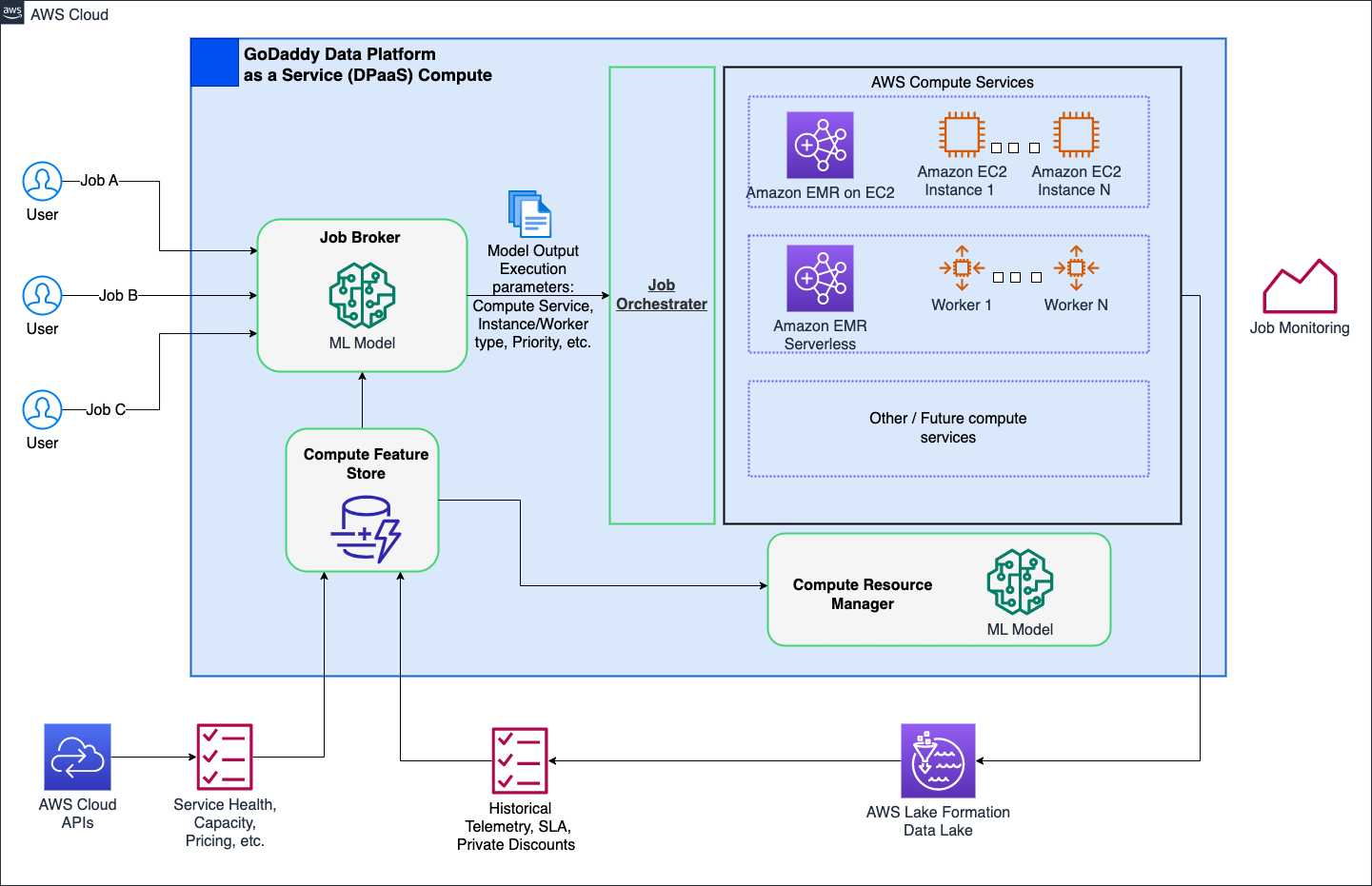
Katman 7: Platform çapında iyileştirmeler
Akıllı Bilgi İşlem Platformumuzla tüm kullanıcılara basitleştirilmiş ancak güçlü çözümler sunarak GoDaddy'de bilgi işlem operasyonlarında devrim yaratmayı hedefliyoruz. EC2'de EMR Serverless ve EMR gibi AWS bilgi işlem çözümleriyle, veri işleme ve makine öğrenimi (ML) iş yüklerinin optimize edilmiş çalıştırmalarını sağladı. ML destekli bir iş aracısı, çeşitli parametrelere göre işlerin ne zaman ve nasıl çalıştırılacağını akıllı bir şekilde belirlerken, uzman kullanıcıların özelleştirmesine de olanak tanır. Ek olarak, makine öğrenimi destekli bir bilgi işlem kaynağı yöneticisi, yük ve geçmiş verilere dayalı olarak kaynakları önceden hazırlayarak optimum maliyetle verimli, hızlı kaynak sağlama sağlar. Akıllı bilgi işlem, kullanıcılara kullanıma hazır optimizasyonla güç verir ve uzman kullanıcılardan ödün vermeden farklı kişilere hitap eder.
Aşağıdaki şemada akıllı bilgi işlem mimarisinin üst düzey bir örneği gösterilmektedir.
Analizler ve önerilen en iyi uygulamalar
Aşağıdaki bölümde, topladığımız bilgiler ve ön ve daha geniş benimseme aşamalarımız sırasında geliştirdiğimiz önerilen en iyi uygulamalar anlatılmaktadır.
Altyapı hazırlığı
EMR Serverless, EMR dahilindeki bir dağıtım yöntemi olmasına rağmen potansiyelini optimize etmek için bazı altyapı hazırlığı gerektirir. Uygulamaya ilişkin aşağıdaki gereklilikleri ve pratik rehberliği göz önünde bulundurun:
- Birden çok Erişilebilirlik Alanında büyük alt ağlar kullanın – VPC'nizde EMR Sunucusuz iş yüklerini çalıştırırken, alt ağların birden fazla Erişilebilirlik Alanına yayıldığından ve IP adresleriyle sınırlandırılmadığından emin olun. Bakınız VPC erişimini yapılandırma ve Alt ağ planlaması için en iyi uygulamalar Ayrıntılar için.
- Maksimum eşzamanlı vCPU kotasını değiştirin - Kapsamlı bilgi işlem gereksinimleri için, kapasitenizi artırmanız önerilir. hesap başına maksimum eşzamanlı vCPU sayısı hizmet kotası.
- Amazon MWAA sürüm uyumluluğu - GoDaddy'nin veri hattı orkestrasyonu için merkezi olmayan Amazon MWAA ekosistemi, EMR Serverless'ı benimserken, farklı AWS Sağlayıcıları sürümlerinde uyumluluk sorunları yarattı. Amazon MWAA'yı doğrudan yükseltmek, çok sayıda DAG'yi güncellemekten daha verimliydi. Amazon MWAA bulut sunucularını kendimiz yükselterek, sorunları belgeleyerek ve doğru yükseltme planlaması için bulguları ve çaba tahminlerini paylaşarak benimsemeyi kolaylaştırdık.
- GoDaddy EMR operatörü - Çok sayıda Airflow DAG'nin EC2'deki EMR'den EMR Sunucusuz'a geçişini kolaylaştırmak için mevcut arayüzleri uyarlayan özel operatörler geliştirdik. Bu, tanıdık ayarlama seçeneklerini korurken kesintisiz geçişlere olanak sağladı. Veri mühendisleri, basit bul-değiştir içe aktarma işlemleriyle işlem hatlarını kolaylıkla taşıyabilir ve EMR Sunucusuz'u hemen kullanabilir.
Beklenmeyen davranış azaltma
Karşılaştığımız beklenmedik davranışlar ve bunları hafifletmek için yaptıklarımız şunlardır:
- Spark DRA agresif ölçeklendirme - Bazı işler için (başlangıçtaki karşılaştırmaların %8.33'ü, üretimin %13.6'sı), EMR Sunucusuz'a geçişten sonra maliyet arttı. Bunun nedeni Spark DRA'nın yeni çalışanları aşırı derecede kısa süreliğine görevlendirmesi ve maliyetten ziyade performansa öncelik vermesiydi. Bunu ortadan kaldırmak için maksimum yürütücü eşiklerini ayarlayarak belirliyoruz.
spark.dynamicAllocation.maxExecutorEMR Sunucusuz ölçeklendirme saldırganlığını etkili bir şekilde sınırlıyor. EC2'de EMR'den geçiş yaparken, EMR Sunucusuz'da benzer işlem sınırlarını çoğaltmak için Spark Geçmişi Kullanıcı Arayüzündeki maksimum çekirdek sayısını gözlemlemenizi öneririz;--conf spark.executor.coresve--conf spark.dynamicAllocation.maxExecutors. - Büyük ölçekli işler için disk alanını yönetme - Büyük miktarda veri işleyen, önemli miktarda veri karıştıran ve önemli disk gereksinimleri olan işleri EMR Sunucusuz'a geçirirken, aşağıdaki yapılandırmayı yapmanızı öneririz:
spark.emr-serverless.executor.diskmevcut Spark iş ölçümlerine atıfta bulunarak. Ayrıca, aşağıdaki gibi konfigürasyonlarspark.executor.coresile birliktespark.emr-serverless.executor.diskvespark.dynamicAllocation.maxExecutorsAvantajlı olduğunda temel çalışan büyüklüğü ve toplam bağlı depolama üzerinde kontrole izin verin. Örneğin, nispeten düşük disk kullanımına sahip, karıştırma ağırlıklı bir iş, yerel karıştırma getirme olasılığını artırmak için daha büyük bir çalışanın kullanılmasından faydalanabilir.
Sonuç
Bu yazıda tartışıldığı gibi, arm64'te EMR Serverless'ı benimseme konusundaki deneyimlerimiz son derece olumluydu. Maliyette %60 azalma, toplu Spark iş yüklerinin %50 daha hızlı çalıştırılması ve geliştirme ve test hızında beş kat şaşırtıcı bir iyileşme dahil olmak üzere elde ettiğimiz etkileyici sonuçlar, bu teknolojinin potansiyeli hakkında çok şey ifade ediyor. Ayrıca mevcut sonuçlarımız, EMR Serverless'ta Graviton2'yi geniş çapta benimseyerek, toplu işlememiz için karbon ayak izini potansiyel olarak %60'a kadar azaltabileceğimizi gösteriyor.
Ancak bu sonuçların herkese uyacak tek bir senaryo olmadığını anlamak çok önemlidir. Bekleyebileceğiniz iyileştirmeler, iş akışlarınızın özel yapısı, küme yapılandırmaları, kaynak kullanım düzeyleri ve hesaplama kapasitesindeki dalgalanmalar dahil ancak bunlarla sınırlı olmamak üzere faktörlere tabidir. Bu nedenle, EMR Sunucusuz'un entegrasyonunu değerlendirirken, faydalarını sonuna kadar optimize etmeye yardımcı olabilecek, veri odaklı, halka tabanlı bir dağıtım stratejisini şiddetle savunuyoruz.
Özel teşekkür etmek mukul sharma ve Boris Berlin Benchmarking'e katkılarından dolayı. Çok teşekkürler Travis Muhlestein (CDO), Abhijit Kundu (Başkan Yardımcısı Müh), Vincent Yung (Kıdemli Müdür Müh.) ve Wai Kin Lau (Kıdemli Direktör Veri Müh.)'ye sürekli destekleri için teşekkür ederiz.
Yazarlar Hakkında
 Brandon Abear GoDaddy'nin Veri ve Analitik (DnA) organizasyonunda Baş Veri Mühendisidir. Büyük veriyle ilgili her şeyden hoşlanıyor. Boş zamanlarında seyahat etmekten, film izlemekten ve ritim oyunları oynamaktan hoşlanıyor.
Brandon Abear GoDaddy'nin Veri ve Analitik (DnA) organizasyonunda Baş Veri Mühendisidir. Büyük veriyle ilgili her şeyden hoşlanıyor. Boş zamanlarında seyahat etmekten, film izlemekten ve ritim oyunları oynamaktan hoşlanıyor.
 Dinesh Sharma GoDaddy'nin Veri ve Analitik (DnA) organizasyonunda Baş Veri Mühendisidir. Kullanıcı deneyimi ve geliştirici üretkenliği konusunda tutkuludur ve her zaman mühendislik süreçlerini optimize etmenin ve maliyetten tasarruf etmenin yollarını arar. Boş zamanlarında okumayı seviyor ve sıkı bir manga hayranı.
Dinesh Sharma GoDaddy'nin Veri ve Analitik (DnA) organizasyonunda Baş Veri Mühendisidir. Kullanıcı deneyimi ve geliştirici üretkenliği konusunda tutkuludur ve her zaman mühendislik süreçlerini optimize etmenin ve maliyetten tasarruf etmenin yollarını arar. Boş zamanlarında okumayı seviyor ve sıkı bir manga hayranı.
 John Bush GoDaddy'nin Veri ve Analitik (DnA) organizasyonunda Baş Yazılım Mühendisidir. Kuruluşların verileri yönetmesini ve işletmelerini ileriye taşımak için kullanmasını kolaylaştırma konusunda tutkulu. Boş zamanlarında yürüyüş yapmayı, kamp yapmayı ve e-bisiklete binmeyi seviyor.
John Bush GoDaddy'nin Veri ve Analitik (DnA) organizasyonunda Baş Yazılım Mühendisidir. Kuruluşların verileri yönetmesini ve işletmelerini ileriye taşımak için kullanmasını kolaylaştırma konusunda tutkulu. Boş zamanlarında yürüyüş yapmayı, kamp yapmayı ve e-bisiklete binmeyi seviyor.
 Özcan Ilıkhan GoDaddy'de Veri ve ML Platformu Mühendislik Direktörüdür. Startup'lardan küresel girişimlere uzanan yirmi yılı aşkın çok disiplinli liderlik deneyimine sahiptir. Müşterileri memnun eden, onları daha fazlasını başarmaya teşvik eden ve operasyonel verimliliği artıran çözümler oluşturmak için verilerden ve yapay zekadan yararlanma tutkusuna sahiptir. Profesyonel yaşamının dışında kitap okumaktan, yürüyüş yapmaktan, bahçecilik yapmaktan, gönüllülük yapmaktan ve Kendin Yap projelerine girişmekten hoşlanıyor.
Özcan Ilıkhan GoDaddy'de Veri ve ML Platformu Mühendislik Direktörüdür. Startup'lardan küresel girişimlere uzanan yirmi yılı aşkın çok disiplinli liderlik deneyimine sahiptir. Müşterileri memnun eden, onları daha fazlasını başarmaya teşvik eden ve operasyonel verimliliği artıran çözümler oluşturmak için verilerden ve yapay zekadan yararlanma tutkusuna sahiptir. Profesyonel yaşamının dışında kitap okumaktan, yürüyüş yapmaktan, bahçecilik yapmaktan, gönüllülük yapmaktan ve Kendin Yap projelerine girişmekten hoşlanıyor.
 Sert Vardhan büyük veri ve analiz konusunda uzmanlaşmış bir AWS Çözüm Mimarıdır. Büyük veri ve veri bilimi alanında 8 yılı aşkın deneyime sahiptir. Müşterilerin en iyi uygulamaları benimsemelerine ve verilerinden içgörüler keşfetmelerine yardımcı olma konusunda tutkulu.
Sert Vardhan büyük veri ve analiz konusunda uzmanlaşmış bir AWS Çözüm Mimarıdır. Büyük veri ve veri bilimi alanında 8 yılı aşkın deneyime sahiptir. Müşterilerin en iyi uygulamaları benimsemelerine ve verilerinden içgörüler keşfetmelerine yardımcı olma konusunda tutkulu.
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- PlatoData.Network Dikey Üretken Yapay Zeka. Kendine güç ver. Buradan Erişin.
- PlatoAiStream. Web3 Zekası. Bilgi Genişletildi. Buradan Erişin.
- PlatoESG. karbon, temiz teknoloji, Enerji, Çevre, Güneş, Atık Yönetimi. Buradan Erişin.
- PlatoSağlık. Biyoteknoloji ve Klinik Araştırmalar Zekası. Buradan Erişin.
- Kaynak: https://aws.amazon.com/blogs/big-data/how-the-godaddy-data-platform-achieved-over-60-cost-reduction-and-50-performance-boost-by-adopting-amazon-emr-serverless/

