Bugün NFL, tarafından sağlanan istatistiklerin sayısını artırma yolculuğuna devam ediyor. Yeni Nesil İstatistik Platformu 32 takıma ve taraftara. Makine öğreniminden (ML) türetilen gelişmiş analitikle NFL, futbolu ölçmenin ve taraftarlara futbol hakkındaki bilgilerini artırmaları için gereken araçları sağlamanın yeni yollarını yaratıyor. oyun içi oyunlar futbol 2022 sezonu için NFL, oyuncu izleme verilerinden ve yeni gelişmiş analitik tekniklerinden yararlanmayı amaçladı. özel ekipleri daha iyi anlamak için.
Projenin amacı, geri dönen bir oyuncunun bir degaj veya başlama oyununda kaç yarda kazanacağını tahmin etmekti. Degaj ve başlama vuruşu getirileri için tahmine dayalı modeller oluştururken karşılaşılan zorluklardan biri, bir oyunun dinamiklerinde önemli bir öneme sahip olan çok nadir olayların (örneğin touchdown gibi) mevcudiyetidir. Nadir olayların modellerin genel performansı üzerinde önemli etkiye sahip olduğu gerçek dünya uygulamalarında, uzun kuyruklu bir veri dağılımı yaygındır. Ekstrem olaylara ilişkin dağılımı doğru bir şekilde modellemek için sağlam bir yöntem kullanmak, daha iyi genel performans için çok önemlidir.
Bu gönderide, GluonTS'de uygulanan Spliced Binned-Pareto dağıtımının bu tür şişman kuyruklu dağılımları sağlam bir şekilde modellemek için nasıl kullanılacağını gösteriyoruz.
İlk önce kullanılan veri setini açıklıyoruz. Ardından, veri setine uygulanan veri ön işleme ve diğer dönüştürme yöntemlerini sunuyoruz. Daha sonra makine öğrenimi metodolojisinin ve model eğitim prosedürlerinin ayrıntılarını açıklıyoruz. Son olarak, model performans sonuçlarını sunuyoruz.
Veri kümesi
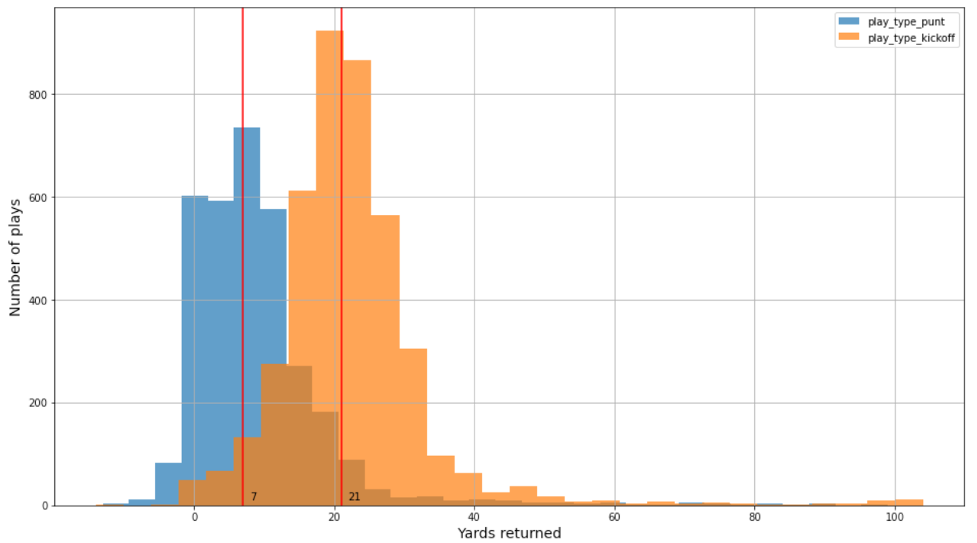
Bu gönderide, degaj ve başlama getirileri için ayrı modeller oluşturmak üzere iki veri kümesi kullandık. Oyuncu izleme verileri, oyuncunun konumunu, yönünü, ivmesini ve daha fazlasını içerir (x,y koordinatlarında). Bahis ve başlama oyunları için dört NFL sezonundan (3,000–4,000) sırasıyla yaklaşık 2018 ve 2021 oyun var. Ek olarak, veri setlerinde çok az bahis ve başlama vuruşuyla ilgili gol var; sırasıyla yalnızca %0.23 ve %0.8. Bahis ve başlama için veri dağılımı farklıdır. Örneğin, başlama vuruşu ve degajlar için gerçek mesafe dağılımı aşağıdaki şekilde gösterildiği gibi benzer ancak kaydırılmıştır.
Veri ön işleme ve özellik mühendisliği
İlk olarak, izleme verileri yalnızca degajlar ve başlama dönüşleriyle ilgili veriler için filtrelendi. Oynatıcı verileri, model geliştirmeye yönelik özellikleri türetmek için kullanıldı:
- X – Sahanın uzun ekseni boyunca oyuncu pozisyonu
- Y – Sahanın kısa ekseni boyunca oyuncu pozisyonu
- S – Yarda/saniye cinsinden hız; daha doğru olması için Dis*10 ile değiştirildi (Dis, son 0.1 saniyedeki mesafedir)
- Dir – Oyuncu hareket açısı (derece)
Önceki verilerden, her oyun 10 hücum oyuncusu (top taşıyıcı hariç), 11 savunma oyuncusu ve 14 türetilmiş özellikle 10X11X14 veriye dönüştürüldü:
- sX – bir oyuncunun x hızı
- sY – bir oyuncunun y hızı
- s – Bir oyuncunun hızı
- aX – bir oyuncunun x ivmesi
- aY – y bir oyuncunun hızlanması
- relX – top taşıyıcıya göre oyuncunun x mesafesi
- güvenmek – oyuncunun top taşıyıcıya göre y mesafesi
- relSx – top taşıyıcıya göre oyuncunun x hızı
- relSy – y top taşıyıcıya göre oyuncunun hızı
- relDist – Oyuncunun top taşıyıcıya göre Öklid mesafesi
- oppX – hücum oyuncusunun savunma oyuncusuna göre x mesafesi
- karşıt – y hücum oyuncusunun savunma oyuncusuna göre mesafesi
- oppSx –x hücum oyuncusunun savunma oyuncusuna göre hızı
- karşıt – y hücum oyuncusunun savunma oyuncusuna göre hızı
Verileri çoğaltmak ve sağ ve sol konumları hesaba katmak için, X ve Y konum değerleri de sağ ve sol alan konumlarını hesaba katmak için yansıtılmıştır. Veri ön işleme ve özellik mühendisliği, kazanandan uyarlanmıştır. NFL Büyük Veri Kasesi Kaggle'daki rekabet.
Makine öğrenimi metodolojisi ve model eğitimi
Bir touchdown olasılığı da dahil olmak üzere oyundaki tüm olası sonuçlarla ilgilendiğimiz için, kazanılan ortalama yardayı bir regresyon problemi olarak basitçe tahmin edemeyiz. Tüm olası saha kazançlarının tam olasılık dağılımını tahmin etmemiz gerekiyor, bu nedenle problemi olasılıksal bir tahmin olarak çerçevelendirdik.
Olasılığa dayalı tahminleri uygulamanın bir yolu, kazanılan yardaları birkaç bölmeye atamak (örneğin, 0'dan az, 0-1, 1-2, ..., 14-15, 15'ten fazla) ve bölmeyi bir sınıflandırma olarak tahmin etmektir. sorun. Bu yaklaşımın dezavantajı, küçük bölmelerin dağılımın yüksek çözünürlüklü bir resmine sahip olmasını istememizdir, ancak küçük bölmeler, bölme başına daha az veri noktası anlamına gelir ve dağılımımız, özellikle de kuyruklar yetersiz tahmin edilebilir ve düzensiz olabilir.
Olasılık tahminlerini uygulamanın başka bir yolu, çıktıyı sınırlı sayıda parametreyle (örneğin, bir Gauss veya Gama dağılımı) sürekli bir olasılık dağılımı olarak modellemek ve parametreleri tahmin etmektir. Bu yaklaşım, dağılımın çok yüksek tanımlı ve düzenli bir resmini verir, ancak kazanılan çok modlu ve ağır kuyruklu yardaların gerçek dağılımına uyması için çok katıdır.
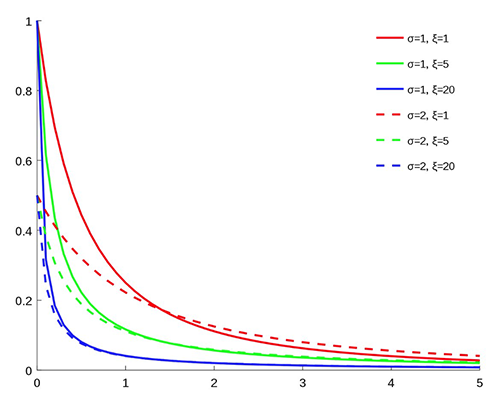
Her iki yöntemden de en iyi şekilde yararlanmak için, Eklenmiş Binned-Pareto dağılımı Çok fazla verinin mevcut olduğu dağıtım merkezi için bölmelere sahip olan (SBP) ve Genelleştirilmiş Pareto dağılımı (GPD), bir touchdown gibi nadir fakat önemli olayların meydana gelebileceği her iki uçta. GPD'nin iki parametresi vardır: aşağıdaki grafikte görüldüğü gibi (kaynak: Wikipedia) biri ölçek ve diğeri kuyruk ağırlığı için.
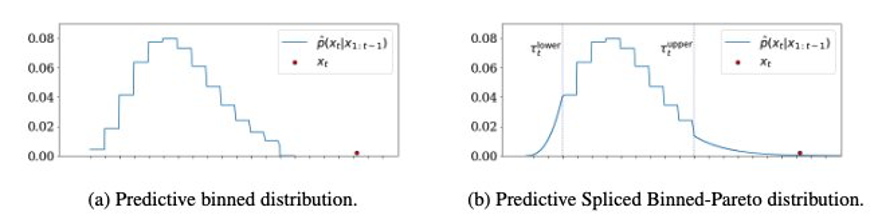
GPD'yi her iki taraftaki ikili dağılımla birleştirerek (aşağıdaki soldaki grafiğe bakın), sağda aşağıdaki SBP'yi elde ederiz. Eklemenin yapıldığı alt ve üst eşikler hiperparametrelerdir.
Temel olarak, kazanan modeli kullandık. NFL Büyük Veri Kasesi Kaggle'daki rekabet. Bu model, hazırlanan verilerden öznitelikleri çıkarmak için CNN katmanlarını kullanır ve sonucu "kutu başına 1 yarda" sınıflandırma problemi olarak tahmin eder. Modelimiz için, taban çizgisinden özellik çıkarma katmanlarını tuttuk ve aşağıdaki şekilde gösterildiği gibi, her bölme için olasılıklar yerine SBP parametrelerini çıkarmak için yalnızca son katmanı değiştirdik (görüntü, gönderiden düzenlendi) 1.lik çözümü Hayvanat Bahçesi).

tarafından sağlanan SBP dağılımını kullandık. Gluon TS. GluonTS, olasılıklı zaman serileri modellemesi için bir Python paketidir, ancak SBP dağılımı zaman serilerine özgü değildir ve onu regresyon için yeniden tasarlayabildik. GluonTS SBP'nin nasıl kullanılacağı hakkında daha fazla bilgi için aşağıdaki demoya bakın defter.
Modeller 2018, 2019 ve 2020 sezonlarında eğitildi ve çapraz doğrulandı ve 2021 sezonunda test edildi. Çapraz doğrulama sırasında sızıntıyı önlemek için aynı oyundaki tüm oyunları aynı pas içinde gruplandırdık.
Değerlendirme için Kaggle yarışmasında kullanılan metriği sakladık. sürekli sıralanmış olasılık puanı (CRPS), aykırı değerlere karşı daha sağlam olan log olasılığına bir alternatif olarak görülebilir. biz de kullandık Pearson korelasyon katsayısı ve RMSE genel ve yorumlanabilir doğruluk ölçümleri olarak. Ayrıca, kalibrasyonu değerlendirmek için konma olasılığına ve olasılık grafiklerine baktık.
Model, kullanılarak CRPS kaybı konusunda eğitildi. Stokastik Ağırlık Ortalaması ve erken durma.
Çıktı dağılımlarının binned kısmındaki düzensizliğin üstesinden gelmek için iki teknik kullandık:
- Ardışık iki bölme arasındaki kare farkıyla orantılı bir düzgünlük cezası
- Çapraz doğrulama sırasında eğitilen birleştirme modelleri
Model performans sonuçları
Her veri kümesi için aşağıdaki seçenekler üzerinden bir ızgara araması yaptık:
- olasılık modelleri
- Taban çizgisi, yarda başına bir olasılıktı
- SBP, merkezde yarda başına bir olasılıktı, kuyruklarda genelleştirilmiş SBP
- Dağıtım yumuşatma
- Düzleştirme yok (düzgünlük cezası = 0)
- Pürüzsüzlük cezası = 5
- Pürüzsüzlük cezası = 10
- Eğitim ve çıkarım prosedürü
- 10 kat çapraz doğrulama ve topluluk çıkarımı (k10)
- 10 dönem veya 20 dönem için tren ve doğrulama verileri üzerine eğitim
Ardından, CRPS'ye göre sıralanan ilk beş modelin metriklerine baktık (düşük iyidir).
Başlama verileri için SBP modeli, CRPS açısından biraz daha yüksek performans gösterir, ancak daha da önemlisi konma olasılığını daha iyi tahmin eder (test setinde gerçek olasılık %0.80'dir). Aşağıdaki tabloda gösterildiği gibi en iyi modellerin 10 katlı birleştirme (k10) kullandığını ve düzgünlük cezası olmadığını görüyoruz.
| Eğitim | Model | Pürüzsüzlük | KBAS | RMSE | DÜZELTME % | P(konma)% |
| k10 | SKB | 0 | 4.071 | 9.641 | 47.15 | 0.78 |
| k10 | Temel | 0 | 4.074 | 9.62 | 47.585 | 0.306 |
| k10 | Temel | 5 | 4.075 | 9.626 | 47.43 | 0.274 |
| k10 | SKB | 5 | 4.079 | 9.656 | 46.977 | 0.682 |
| k10 | Temel | 10 | 4.08 | 9.621 | 47.519 | 0.265 |
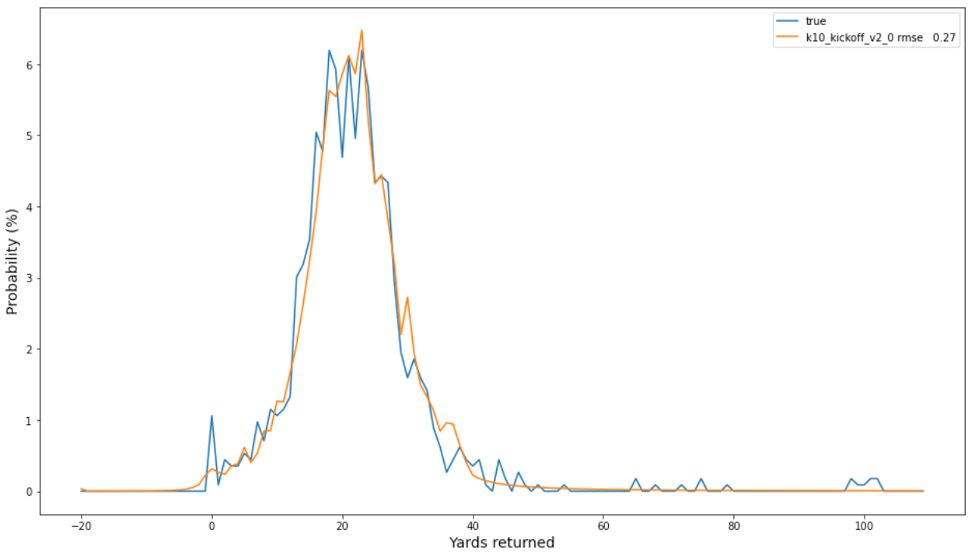
Gözlemlenen frekansların ve tahmin edilen olasılıkların aşağıdaki çizimi, iki dağılım arasında 0.27'lik bir RMSE ile en iyi modelimizin iyi bir kalibrasyonunu gösterir. Gerçek (mavi) ampirik dağılımın kuyruğunda meydana gelen yüksek yarda oluşumlarına (örneğin, 100) dikkat edin, bunların olasılıkları SBP tarafından taban çizgisi yönteminden daha fazla yakalanabilir.
Degaj verileri için, taban çizgisi SBP'den daha iyi performans gösterir, bunun nedeni belki de aşırı mesafe kuyruklarının daha az gerçekleştirmeye sahip olmasıdır. Bu nedenle, modu 0-10 yarda zirveler arasında yakalamak daha iyi bir değiş tokuştur; ve başlangıç verilerinin aksine, en iyi model bir pürüzsüzlük cezası kullanır. Aşağıdaki tablo bulgularımızı özetlemektedir.
| Eğitim | Model | Pürüzsüzlük | KBAS | RMSE | DÜZELTME % | P(konma)% |
| k10 | Temel | 5 | 3.961 | 8.313 | 35.227 | 0.547 |
| k10 | Temel | 0 | 3.972 | 8.346 | 34.227 | 0.579 |
| k10 | Temel | 10 | 3.978 | 8.351 | 34.079 | 0.555 |
| k10 | SKB | 5 | 3.981 | 8.342 | 34.971 | 0.723 |
| k10 | SKB | 0 | 3.991 | 8.378 | 33.437 | 0.677 |
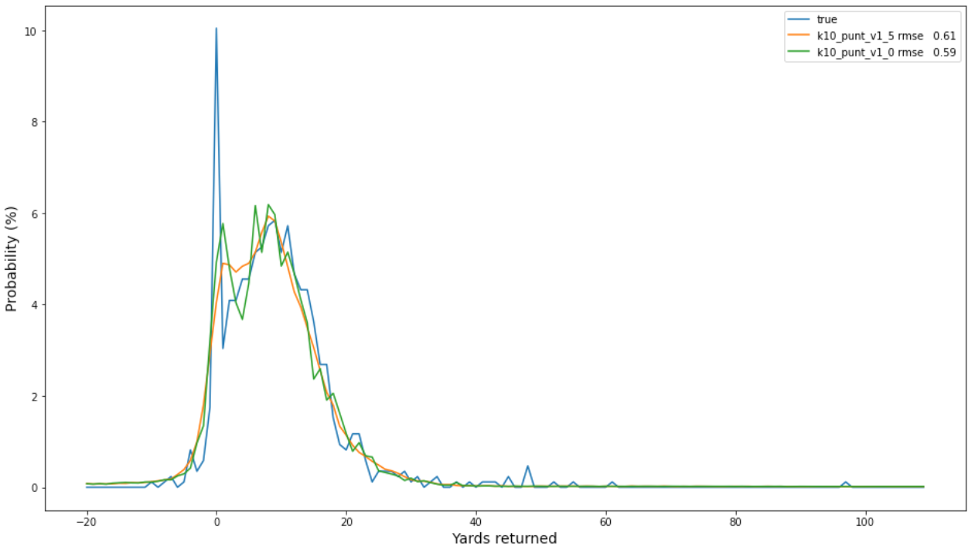
En iyi iki punt modeli için gözlemlenen frekansların (mavi) ve tahmin edilen olasılıkların aşağıdaki çizimi, düzleştirilmemiş modelin (turuncu) düzleştirilmiş modelden (yeşil) biraz daha iyi kalibre edildiğini ve genel olarak daha iyi bir seçim olabileceğini gösterir.
Sonuç
Bu gönderide, ayrıntılı veri dağıtımıyla tahmine dayalı modellerin nasıl oluşturulacağını gösterdik. Bu tür şişman kuyruklu dağılımları sağlam bir şekilde modelleyebilen GluonTS'de uygulanan Spliced Binned-Pareto dağıtımını kullandık. Bahis ve başlangıç getirileri için modeller oluşturmak için bu tekniği kullandık. Bu çözümü, verilerde çok az olayın olduğu ancak bu olayların modellerin genel performansı üzerinde önemli etkisinin olduğu benzer kullanım durumlarına uygulayabiliriz.
Ürün ve hizmetlerinizde makine öğrenimi kullanımını hızlandırma konusunda yardım almak isterseniz lütfen şu adresle iletişime geçin: Amazon ML Çözümleri Laboratuvarı programı.
Yazarlar Hakkında
 Tesfagabir Meharizgi bir Veri Bilimcisidir. Amazon ML Çözümleri Laboratuvarı burada sağlık ve yaşam bilimleri, üretim, otomotiv, spor ve medya gibi çeşitli sektörlerdeki AWS müşterilerine, iş zorluklarını çözmek için makine öğrenimi ve AWS bulut hizmetlerini kullanımlarını hızlandırmalarında yardımcı oluyor.
Tesfagabir Meharizgi bir Veri Bilimcisidir. Amazon ML Çözümleri Laboratuvarı burada sağlık ve yaşam bilimleri, üretim, otomotiv, spor ve medya gibi çeşitli sektörlerdeki AWS müşterilerine, iş zorluklarını çözmek için makine öğrenimi ve AWS bulut hizmetlerini kullanımlarını hızlandırmalarında yardımcı oluyor.
 Marc van Oudheusden Amazon Web Services'de Amazon ML Solutions Lab ekibinde Kıdemli Veri Bilimcisidir. Yapay zeka ve makine öğrenimi ile iş sorunlarını çözmek için AWS müşterileriyle birlikte çalışır. İş dışında onu sahilde, çocuklarıyla oynarken, sörf yaparken veya uçurtma sörfü yaparken bulabilirsiniz.
Marc van Oudheusden Amazon Web Services'de Amazon ML Solutions Lab ekibinde Kıdemli Veri Bilimcisidir. Yapay zeka ve makine öğrenimi ile iş sorunlarını çözmek için AWS müşterileriyle birlikte çalışır. İş dışında onu sahilde, çocuklarıyla oynarken, sörf yaparken veya uçurtma sörfü yaparken bulabilirsiniz.
 Panpan Xu AWS'de Amazon ML Çözümleri Laboratuvarı'nda Kıdemli Uygulamalı Bilim Adamı ve Yöneticidir. Yapay zeka ve bulut benimsemelerini hızlandırmak için çeşitli endüstriyel sektörlerde yüksek etkili müşteri uygulamaları için Makine Öğrenimi algoritmalarının araştırılması ve geliştirilmesi üzerinde çalışıyor. Araştırma ilgi alanları arasında model yorumlanabilirliği, nedensel analiz, döngüde insan yapay zekası ve etkileşimli veri görselleştirme yer almaktadır.
Panpan Xu AWS'de Amazon ML Çözümleri Laboratuvarı'nda Kıdemli Uygulamalı Bilim Adamı ve Yöneticidir. Yapay zeka ve bulut benimsemelerini hızlandırmak için çeşitli endüstriyel sektörlerde yüksek etkili müşteri uygulamaları için Makine Öğrenimi algoritmalarının araştırılması ve geliştirilmesi üzerinde çalışıyor. Araştırma ilgi alanları arasında model yorumlanabilirliği, nedensel analiz, döngüde insan yapay zekası ve etkileşimli veri görselleştirme yer almaktadır.
 Kyeong Hoon (Jonathan) Jung Ulusal Futbol Ligi'nde kıdemli bir yazılım mühendisidir. Son yedi yıldır Next Gen Stats ekibiyle birlikte, ham verilerin akışından, verileri işlemek için mikro hizmetler oluşturmaya ve işlenmiş verileri ortaya çıkaran API'ler oluşturmaya kadar platformun oluşturulmasına yardımcı oluyor. Amazon Machine Learning Solutions Lab ile birlikte çalışacakları temiz veriler sağlamanın yanı sıra verilerin kendisi hakkında alan bilgisi sağlama konusunda işbirliği yaptı. İş dışında Los Angeles'ta bisiklet sürmekten ve Sierras'ta yürüyüş yapmaktan hoşlanıyor.
Kyeong Hoon (Jonathan) Jung Ulusal Futbol Ligi'nde kıdemli bir yazılım mühendisidir. Son yedi yıldır Next Gen Stats ekibiyle birlikte, ham verilerin akışından, verileri işlemek için mikro hizmetler oluşturmaya ve işlenmiş verileri ortaya çıkaran API'ler oluşturmaya kadar platformun oluşturulmasına yardımcı oluyor. Amazon Machine Learning Solutions Lab ile birlikte çalışacakları temiz veriler sağlamanın yanı sıra verilerin kendisi hakkında alan bilgisi sağlama konusunda işbirliği yaptı. İş dışında Los Angeles'ta bisiklet sürmekten ve Sierras'ta yürüyüş yapmaktan hoşlanıyor.
 Michael Ki Ulusal Futbol Ligi'nde Yeni Nesil İstatistikler ve Veri Mühendisliğinden sorumlu Kıdemli Teknoloji Direktörüdür. Urbana Champaign'deki Illinois Üniversitesi'nden Matematik ve Bilgisayar Bilimleri derecesine sahiptir. Michael, NFL'ye ilk olarak 2007'de katıldı ve öncelikle futbol istatistikleri için teknoloji ve platformlara odaklandı. Boş zamanlarında ailesiyle dışarıda vakit geçirmekten hoşlanır.
Michael Ki Ulusal Futbol Ligi'nde Yeni Nesil İstatistikler ve Veri Mühendisliğinden sorumlu Kıdemli Teknoloji Direktörüdür. Urbana Champaign'deki Illinois Üniversitesi'nden Matematik ve Bilgisayar Bilimleri derecesine sahiptir. Michael, NFL'ye ilk olarak 2007'de katıldı ve öncelikle futbol istatistikleri için teknoloji ve platformlara odaklandı. Boş zamanlarında ailesiyle dışarıda vakit geçirmekten hoşlanır.
 Mike Grubu Ulusal Futbol Ligi'nde Yeni Nesil İstatistikler için Kıdemli Araştırma ve Analitik Yöneticisidir. Ekibe 2018'de katıldığından beri taraftarlar, NFL yayın ortakları ve benzer şekilde 32 kulüp için oyuncu izleme verilerinden elde edilen önemli istatistiklerin ve içgörülerin fikirlendirilmesi, geliştirilmesi ve iletilmesinden sorumlu olmuştur. Mike, Chicago Üniversitesi'nden analitik alanında yüksek lisans derecesi, Florida Üniversitesi'nden spor yönetimi lisans derecesi ve hem Minnesota Vikings'in scouting departmanında hem de işe alım departmanında deneyimiyle takıma zengin bir bilgi ve deneyim getiriyor. Florida Gator Futbolu.
Mike Grubu Ulusal Futbol Ligi'nde Yeni Nesil İstatistikler için Kıdemli Araştırma ve Analitik Yöneticisidir. Ekibe 2018'de katıldığından beri taraftarlar, NFL yayın ortakları ve benzer şekilde 32 kulüp için oyuncu izleme verilerinden elde edilen önemli istatistiklerin ve içgörülerin fikirlendirilmesi, geliştirilmesi ve iletilmesinden sorumlu olmuştur. Mike, Chicago Üniversitesi'nden analitik alanında yüksek lisans derecesi, Florida Üniversitesi'nden spor yönetimi lisans derecesi ve hem Minnesota Vikings'in scouting departmanında hem de işe alım departmanında deneyimiyle takıma zengin bir bilgi ve deneyim getiriyor. Florida Gator Futbolu.
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- Plato blok zinciri. Web3 Metaverse Zekası. Bilgi Güçlendirildi. Buradan Erişin.
- Kaynak: https://aws.amazon.com/blogs/machine-learning/predict-football-punt-and-kickoff-return-yards-with-fat-tailed-distribution-using-gluonts/

