Derin Öğrenme Öneri Modelleri (DLRM): Derin Bir İnceleme
21. yüzyılda para birimi artık sadece veri değil. İnsanların ilgisi. Bu derinlemesine inceleme makalesi, Mart 2019'da Facebook tarafından açık kaynaklı olan derin öğrenme öneri modeli DLRM ile yaşanan mimari ve dağıtım sorunlarını sunar.
By Nishant Kumar, Veri Bilimi Uzmanı.
Öneri sistemleri, özellikle çok sayıda seçenek mevcut olduğunda, kullanıcıların neleri beğenebileceğini tahmin etmek için oluşturulmuştur.
DLRM algoritması, 31 Mart 2019'da Facebook tarafından açık kaynaklı olup, popüler MLPerf Benchmark'ın bir parçasıdır.

Derin Öğrenme Öneri Modeli Mimarisi (DLRM)
Neden DLRM kullanmayı düşünmelisiniz?
Bu makale, öneri sistemlerindeki mimari değişiklikleri yönlendiren 2 önemli kavramı birleştirmeye çalışmaktadır:
- Öneri Sistemleri açısından başlangıçta kullanıcıları tercihlerine göre ürünlerle eşleştiren içerik filtreleme sistemleri kullanıldı. Bu daha sonra, tavsiyelerin geçmiş kullanıcı davranışlarına dayalı olduğu işbirliğine dayalı filtrelemeyi kullanmak için gelişti.
- Tahmine Dayalı Analitik bakış açısından, verilen verilere dayalı olarak olayların olasılığını sınıflandırmak veya tahmin etmek için istatistiksel modellere dayanır. Bu modeller, doğrusal ve lojistik regresyon gibi basit modellerden derin ağları içeren modellere geçti.
Bu yazıda, yazarlar bu 2 perspektifi DLRM Modelinde birleştirmeyi başardıklarını iddia ediyorlar.
Birkaç önemli özellik:
- Gömme Tablolarının kapsamlı kullanımı: Gömme, kullanıcıların verilerinin zengin ve anlamlı bir sunumunu sağlar.
- Çok Katmanlı Algılayıcıyı (MLP) kullanır: MLP, bir Derin Öğrenme çeşidi sunar. İstatistiksel yöntemlerin sunduğu sınırlamaları iyi bir şekilde ele alabilirler.
- Model Paralelliği: Bellek üzerinde daha az yük oluşturur ve bunu hızlandırır.
- Gömmeler arasındaki etkileşim: Özellik etkileşimleri arasındaki gizli faktörleri (yani gizli faktörler) yorumlamak için kullanılır. Komedi ve korku filmlerini seven bir kullanıcının bir korku-komedi filmini beğenme olasılığı buna bir örnek olabilir. Bu tür etkileşimler, öneri sistemlerinin çalışmasında önemli bir rol oynar.

HADİ BAŞLAYALIM
Model İş Akışı:
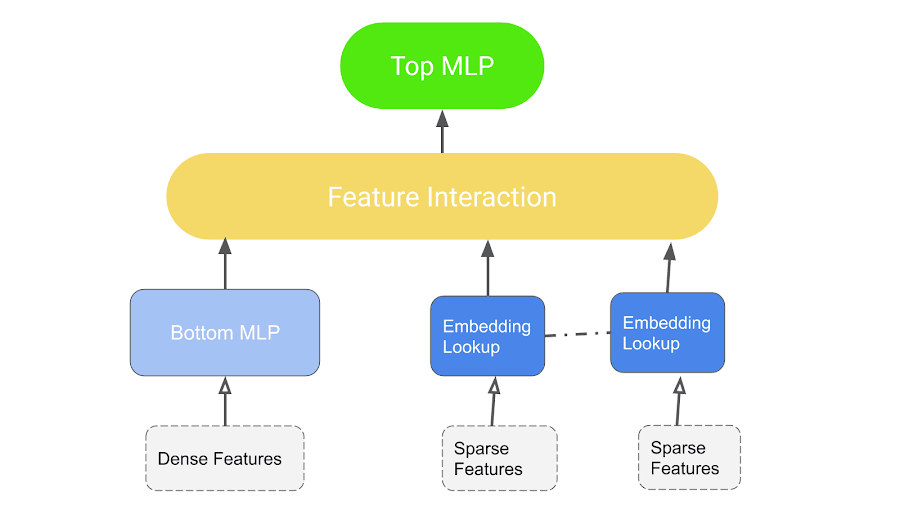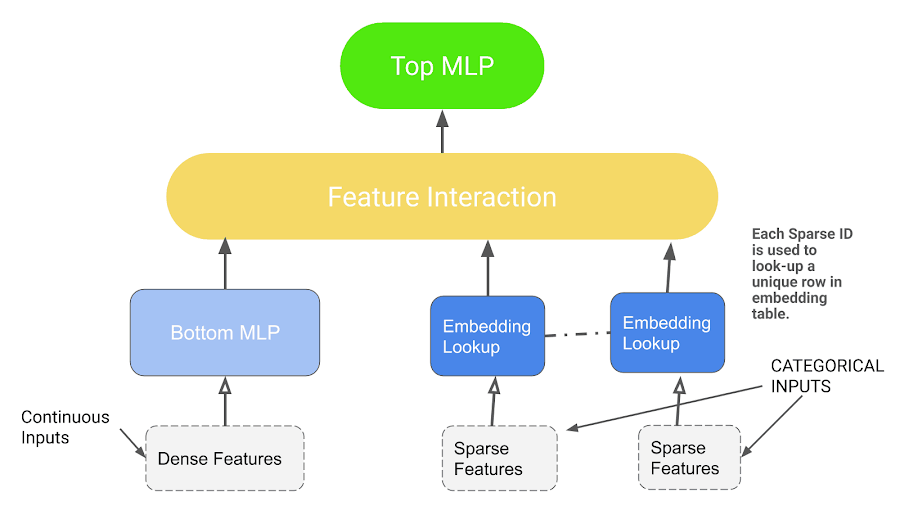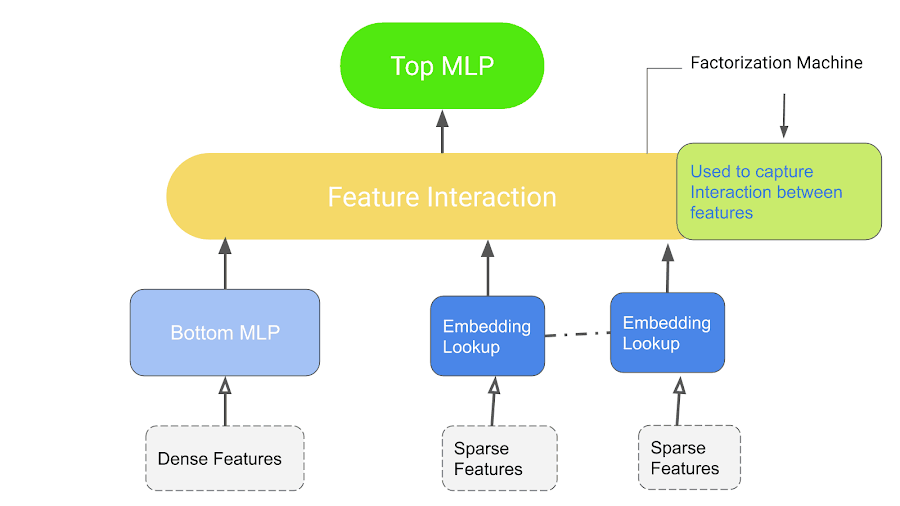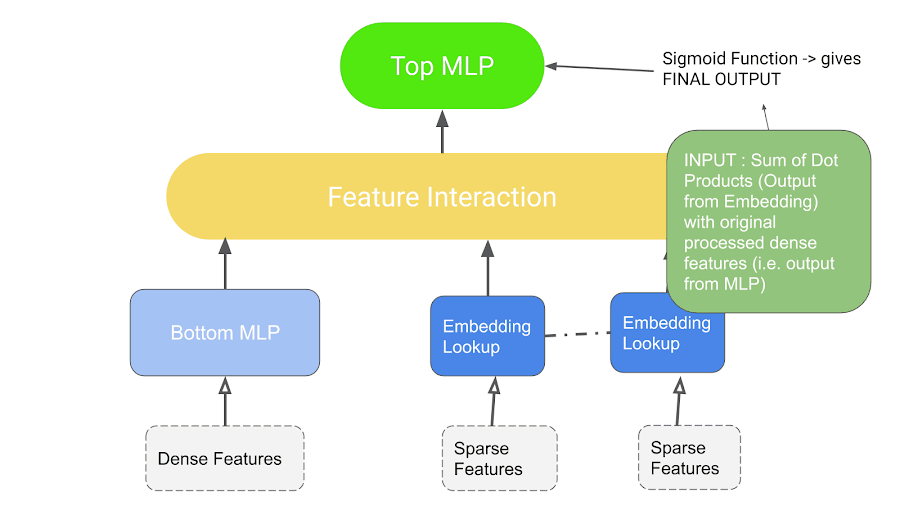
DLRM İş Akışı.
- Model, kategorik verileri temsil eden seyrek özellikleri işlemek için gömme ve yoğun özellikleri işlemek için Çok Katmanlı Algılayıcı (MLP) kullanır,
- Önerilen istatistiksel teknikleri kullanarak bu özellikleri açıkça etkileşime sokar.
- Son olarak, başka bir MLP ile etkileşimleri sonradan işleyerek olay olasılığını bulur.
MİMARİ:
- kalıplamaların
- Matris Ayrıştırması
- Faktorizasyon Makinesi
- Çok katmanlı Perceptron (MLP)
Onları biraz detaylı tartışalım.
1. Gömme
Kavramların, nesnelerin veya öğelerin bir vektör uzayına eşlenmesine Gömme adı verilir
örneğin,
Sinir ağları bağlamında, yerleştirmeler düşük boyutludur, kesikli değişkenlerin öğrenilmiş sürekli vektör temsilidir.
Seyrek öğe listeleri gibi diğer seçenekler yerine neden Gömme kullanmalıyız?
- Kategorik değişkenlerin boyutsallığını azaltır ve soyut alanda kategorileri anlamlı bir şekilde temsil eder.
- Düğünler arasındaki mesafeyi daha anlamlı bir şekilde ölçebiliriz.
- Gömme öğeleri, eldeki modelle ilgili bazı soyut boşluklardaki seyrek özellikleri temsil ederken, tam sayılar giriş verilerinin bir sırasını temsil eder.
- Vektörleri gömme projesi n boyutlu öğe alanı içine d boyutlu gömme vektörleri nerede n >> d.
2. Matris Ayrıştırması
Bu teknik, Öneri Sistemlerinde kullanılan İşbirlikçi filtreleme algoritmaları sınıfına aittir.
Matris Çarpanlarına ayırma algoritmaları, kullanıcı-öğe etkileşim matrisini daha düşük boyutlu 2 dikdörtgen matrisin ürününe ayrıştırarak çalışır.
Bakın https://developers.google.com/machine-learning/recommendation/collaborative/matrix daha fazla ayrıntı için.
3. Faktorizasyon Makineleri (FM)
Yüksek boyutlu seyrek veri kümeleriyle ilgilenen görevler için iyi bir seçim.
FM, MF'nin geliştirilmiş bir versiyonudur. Yüksek boyutlu seyrek veri kümelerindeki özellikler arasındaki etkileşimleri ekonomik olarak yakalamak için tasarlanmıştır.

Çarpanlara Ayırma Matrisi (FM) Denklemi.

Faktorizasyon Makinalarının Özellikleri:
- Seyrek ortamlarda etkileşimleri tahmin edebilir, çünkü etkileşimin bağımsızlığını parametrelerle çarpanlarına ayırarak kırarlar.
- Formun bir modelini tanımlayarak ikinci dereceden etkileşimleri kategorik verilerle doğrusal bir modelde birleştirir,
![]()
FM'ler, seyrek verileri daha etkin bir şekilde işleyen matris çarpanlarına ayırmada olduğu gibi, ikinci dereceden etkileşim matrisini gizli faktörlerine (veya gömme vektörlerine) çarpanlara ayırır.
 Etkileşim matrislerinin farklı dereceleri.
Etkileşim matrislerinin farklı dereceleri.
Yalnızca farklı gömme vektörlerinin çiftleri arasındaki etkileşimleri yakalayarak ikinci dereceden etkileşimlerin karmaşıklığını önemli ölçüde azaltır ve doğrusal hesaplama karmaşıklığı sağlar.
Bakın https://docs.aws.amazon.com/sagemaker/latest/dg/fact-machines.html.
4. Çok Katmanlı Perceptron
Son olarak, biraz Derin Öğrenmenin tadı.
Çok Katmanlı Perceptron (MLP), İleri Beslemeli Yapay Sinir Ağı sınıfıdır.
Bir MLP, en az 3 düğüm katmanından oluşur:
- Giriş katmanı
- Gizli katman
- Çıktı katmanı
Giriş düğümleri dışında, her düğüm doğrusal olmayan bir aktivasyon işlevi kullanan bir nörondur.

MLP, eğitim için Backpropagation adı verilen denetimli öğrenmeyi kullanır.

Bu yöntemler, daha karmaşık etkileşimleri yakalamak için kullanılmıştır.
Yeterli derinlik ve genişliğe sahip MLP'ler, verileri keyfi bir hassasiyete sığdırabilir.
MLPerf Benchmark'ın bir parçası olarak kullanılan Neural Collaborative Filtering (NCF) adlı özel bir durum, Matrix Factorization'daki yerleştirmeler arasındaki etkileşimleri hesaplamak için nokta ürün yerine bir MLP kullanır.
Çerçeveye Göre DLRM Operatörleri

Açık kaynak öneri modeli sisteminin genel mimarisini aşağıda bulabilirsiniz. Yapılandırılabilir tüm parametreler mavi renkle özetlenmiştir. Ve kullanılan operatörler yeşil renkte gösterilmiştir.

Kaynak: https://arxiv.org/pdf/1906.03109.pdf.
Facebook'tan 3 test edilmiş modelimiz var (Kaynak: Facebook'un DNN Tabanlı Kişiselleştirilmiş Önerisinin Mimari Etkisi)

Model Mimarisi parametreleri, kullanılan 3 öneri modeli örneği için üretim ölçeği öneri iş yüklerinin temsilcisidir ve gömme tablosu ve FC boyutları açısından çeşitliliklerini vurgular. Her parametre (sütun), 3 konfigürasyonun tamamında en küçük örneğe normalleştirilir.
KONULAR

- Bellek Kapasitesi Hakimdir (Ağdan Giriş)
- Bellek Bant Genişliğine Hakim (Unsurların İşlenmesi: Gömme Arama ve MLP)
- İletişim Tabanlı (Özellikler Arası Etkileşim)
- Hesaplamaya Hakim Olan (Hesaplama / Çalışma Zamanı Darboğazı)
1. Bellek Kapasitesi Hakimdir
(Ağdan Giriş)

Kaynak: https://arxiv.org/pdf/1906.00091.pdf.
ÇÖZÜM: paralellik
Temel ve en önemli adımlardan biri
- Gömmeler, her biri birden çok GB'den fazla bellek gerektiren birkaç tabloyla parametrelerin çoğuna katkıda bulunur. Bu, modellerin birden çok cihaza dağıtımını gerektirir.
- MLP parametreleri bellekte daha küçüktür, ancak büyük miktarda hesaplamaya dönüştürülür
Veri Paralelliği MLP'ler için tercih edilir çünkü bu, numunelerin farklı cihazlarda eşzamanlı olarak işlenmesini sağlar ve yalnızca güncellemeleri toplarken iletişim gerektirir.
Kişiselleştirme:
KURMAK: En iyi MLP ve etkileşim operatörü, alt MLP'den ve tüm yerleştirmelerden mini partinin bir kısmına erişim gerektirir. Model paralelliği, yerleştirmeleri cihazlar arasında dağıtmak için kullanıldığından, bu, bir kişiselleştirilmiş hepsi bir arada iletişim.

Herkese Özel (Kişiselleştirilmiş) İletişim için Kelebek Karıştırma. Kaynak: https://arxiv.org/pdf/1906.00091.pdf.
Dilimler (yani 1,2,3), kişiselleştirme için hedef cihazlara aktarılması beklenen gömme vektörleridir.
Şu anda, aktarımlar yalnızca açık kopyadır.
2. Bellek Bant Genişliğine Hakimdir
(Özelliklerin İşlenmesi: Arama ve MLP Gömme)

Kaynak: https://arxiv.org/pdf/1909.02107.pdf, https://arxiv.org/pdf/1901.02103.pdf.
- MLP parametreleri bellekte daha küçüktür, ancak büyük miktarda hesaplamaya çevrilir (bu nedenle sorun, işlem sırasında ortaya çıkacaktır).
- Aramaları katıştırmak bellek kısıtlamalarına neden olabilir.
ÇÖZÜM: Tamamlayıcı Bölmeleri Kullanan Kompozisyonel Gömmeler
N öğenin d boyutlu vektör uzayında temsili genel olarak 2 kategoriye ayrılabilir:

Bileşik Gömmeler oluşturmak için kategori kümesinin Tamamlayıcı Bölümlerini kullanarak her kategorik özellik için benzersiz gömme oluşturmak için bir yaklaşım önerilmiştir.
Bellek Bant Genişliği Tüketimi sorununa yaklaşılıyor:
- Hashing Hilesi
- Bölüm-Kalan Trick
KARIŞTIRMA HİKÂYESİ:
Basit bir karma işlevi kullanarak gömme tablosunu azaltmaya yönelik naif bir yaklaşım.

Hash hilesi.
Gömme matrisinin boyutunu O (| S | D) 'den O (mD)' ye önemli ölçüde azaltır çünkü m << | S |.
Dezavantajları -
- Bir vermez Benzersiz Gömme için her Kategori.
- Birden çok kategoriyi aynı gömme vektörüne saf bir şekilde eşler.
- Sonuçları Bilgi kaybı,dolayısıyla, model kalitesinin hızlı bozulması.
QUOTIENT-HATIRLATICI TRICK:
2 tamamlayıcı işlevi, yani tamsayı bölümü ve kalan işlevleri kullanarak: 2 ayrı gömme tablosu oluşturabilir ve bunları her kategori için benzersiz bir gömme sağlayacak şekilde birleştirebiliriz.
Hafıza karmaşıklığı O (D * | S | / m + mD) ile sonuçlanır, karma hile ile karşılaştırıldığında hafızada hafif bir artış,
- Ancak benzersiz bir sunum oluşturmanın ek bir yararı var.
Bölüm-Kalan Trick.
Tamamlayıcı Bölümler
Bölüm-Kalan numarasında, her işlem bir kategori kümesini "Birden Çok Bölüm" e böler, böylece aynı "kova" daki her dizin aynı vektöre eşlenir.
Hem bölümden hem de kalandan gelen gömmeleri bir araya getirerek, her indeks için ayrı bir vektör oluşturulabilir.
NOT: Tamamlayıcı Bölümler: Verilerin tekrarlanmasını veya tabloların bölümlere yerleştirilmesini önler (tamamlayıcı olduğu için, ha !!)
Yapıya Göre Tipler:
- Naif Tamamlayıcı Bölüm
- Bölüm - Kalan Tamamlayıcı Bölümler
- Genelleştirilmiş Bölüm-Kalan Tamamlayıcı Bölümler
- Çince Kalan Bölümler
İşleve Göre Türler:
İşleve göre Tamamlayıcı Bölüm Türleri.
Operasyona Dayalı Kompozisyonel Gömmeler:
Her gömme tablosundaki vektörlerin farklı olduğunu varsayın. Eğer birbirine bağlama işlem kullanılırsa, herhangi bir kategorinin bileşimsel düğünleri benzersizdir.
Bu yaklaşım, tüm gömme tablosu O (| S | D) 'den O (| P1 | D1 + | P2 | D2 +… | Pk | Dk)' ye kadar hafızanın karmaşıklığını azaltır.
Operasyon bazlı yerleştirmeler, uygulanan operasyonlar nedeniyle daha karmaşıktır.
Yola Dayalı Kompozisyonel Gömmeler:
Bir kompozisyondaki her işlev, her bölümden alınan benzersiz bir eşdeğerlik sınıfları kümesine göre belirlenir, benzersiz bir dönüşüm 'yolu' sağlar.
Yola Dayalı Kompozisyonel Gömmelerin daha düşük model karmaşıklığı avantajıyla daha iyi sonuçlar vermesi beklenir.
DEĞİŞ TOKUŞ -
Bir yakalama var.
- Daha büyük bir gömme tablosu, daha iyi model kalitesi sağlar, ancak bu, artan bellek gereksinimleri pahasına.
- Daha agresif bir sürüm kullanmak, daha küçük modeller üretecek, ancak model kalitesinde bir azalmaya yol açacaktır.
- Çoğu model, bir dizi parametre ile performansında katlanarak azalır.
- Her iki tür bileşimsel yerleştirme, bazılarını örtük olarak zorlayarak parametre sayısını azaltır. tarafından tanımlanan yapıtamamlayıcı bölümler her kategorinin yerleştirilmesinin oluşturulmasında.
- Modelin kalitesi, seçilen bölümlerin kategori kümesinin iç özelliklerini ve ilgili yerleştirmelerini ne kadar yakından yansıttığına bağlı olmalıdır.
3. İletişim Temelli
(Özellikler arasındaki etkileşim)
Kaynak: https://github.com/thumbe3/Distributed_Training_of_DLRM/blob/master/CS744_group10.pdf.
DLRM kullanır model paralelliği her GPU cihazına tüm gömme tabloları setini kopyalamaktan kaçınmak ve veri paralellik FC katmanlarındaki numunelerin eşzamanlı işlenmesini sağlamak için.
MLP parametreleri, GPU cihazları arasında çoğaltılır ve karıştırılmaz.
Sorun nedir?
Bir kümedeki düğümler arasında gömme tablolarını aktarmak pahalı hale gelir ve Darboğaz olabilir.
Çözüm:
Çünkü önemli olan, kendilerini yerleştirmenin mutlak değerleri değil, öğrenilmiş yerleştirme vektörleri çiftleri arasındaki etkileşimdir.
İyi bir model elde etmek için farklı düğümlerdeki yerleştirmeleri bağımsız olarak öğrenebileceğimizi varsayıyoruz.
Yalnızca MLP parametrelerini senkronize ederek ve her bir sunucu düğümüne bağımsız olarak tablo yerleştirmeyi öğrenerek Ağ Bant Genişliğinden tasarruf sağlar.
Eğitimi hızlandırmak için, Kırma işlemi giriş veri kümesinin küme düğümleri arasında her iki düğümün de yapabileceği şekilde uygulanmıştır. farklı veri parçalarını eşzamanlı olarak işler ve bu nedenle tek bir düğümden daha fazla ilerleme sağlar.
Dağıtılmış DLRM.
Ana düğüm, MLP parametrelerinin gradyanlarını toplar köle düğümünden ve kendisinden. MLP parametreleri senkronize edildi bazı deneyler için değerlerini izleyerek.
Tabloları katıştırma her iki düğümde de öğrenilenler farklıdır çünkü bunlar senkronize değildir ve düğümler giriş veri kümesinin farklı parçaları üzerinde çalışır.
DLRM, Gömme Etkileşimini kullandığından kendilerini gömmek yerine iyi modeller elde edilebilirdi gömmeler düğümler arasında senkronize edilmemiş olsa bile.
4. Hesaplamaya Hakim Olun
(Hesaplama / Çalışma Zamanı Darboğazı)
Kaynak: https://github.com/pytorch/FBGEMM/wiki/Recent-feature-additions-and-improvements-in-FBGEMM, https://engineering.fb.com/ml-applications/fbgemm/
Yukarıda tartışıldığı gibi,
- MLP ayrıca Hesaplamanın Aşırı Yüklenmesine neden olur
- Ortak yerleşim, üretim ölçeğinde öneri modellerini çalıştırırken daha düşük kaynak kullanımına yol açan performans darboğazları yaratır
Ortak yerleşim, Seyrek Uzunluk Toplamı daha az önbellek yeniden kullanımı sergileyen daha yüksek düzensiz bellek erişimi nedeniyle.
ÇÖZÜM: FBGEMM (Facebook + Genel Matris Çarpımı)
Modelimizin iş gücüyle tanışın
Bu, sunucularda nicelleştirilmiş çıkarım için PyTorch'un kesin arka ucudur.
- Bilimsel hesaplamada kullanılan (FP32 veya FP64 hassasiyeti ile çalışan) geleneksel doğrusal cebir kitaplıklarının aksine, özellikle düşük hassasiyetli veriler için optimize edilmiştir.
- Küçük parti boyutları için verimli düşük hassasiyetli genel matris-matris çarpımı (GEMM) sağlar ve satır bazında niceleme ve aykırı değer farkında niceleme gibi doğruluk kaybı en aza indiren teknikler için destek sağlar.
- Ayrıca, bant genişliğine bağlı GEMM öncesi ve sonrası işlemlerle daha düşük hassasiyette matris çarpımının benzersiz zorluklarının üstesinden gelmek için füzyon fırsatlarından yararlanır.
Mevcut özelliklerde bir dizi iyileştirmenin yanı sıra yeni özellikler eklendi. Ocak 2020 sürümü.
Bunlar Gömme Çekirdeklerini içerir (bizim için çok önemli) Gizlilik Korumalı Makine Öğrenimi Modelleri için JIT'lenmiş seyrek çekirdekler ve int64 GEMM.
Birkaç uygulama istatistiği:
- Öneri Sistemlerinde DRAM bant genişliği kullanımını% 40 azaltır
- Karakter algılamayı 2.4 kat hızlandırır Rosetta(Görüntüler ve Videolar'daki metni algılamak için ML Algo)
64-bit Matris Çarpma İşlemlerinde hesaplamalar gerçekleşirGizlilik Koruma alanında yaygın olarak kullanılan, Makine Öğrenimi Modellerini Koruyan Gizliliği temelde hızlandırmak.
Şu anda, mevcut CPU nesli üzerinde 64-bit GEMM'lerin iyi bir yüksek performanslı uygulaması yoktur.
Bu nedenle FBGEMM'e 64 bit GEMM'ler eklenmiştir. Turbo kapalıyken Intel Xeon Gold 10.5 işlemcide 6138 GOP / sn'ye ulaşır. Saniyede 3.5 GOps hızında çalışan mevcut uygulamadan 3 kat daha hızlıdır. Bu, 64 bit GEMM uygulamasının ilk yinelemesidir.
REFERANSLAR
- James Le tarafından yazılan öneri dizisi: Öneri Sistemleri hakkında temel bilgiler oluşturmak için gerçekten çok iyi. https://jameskle.com/writes/rec-sys-part-1
- Kişiselleştirme ve Öneri Sistemleri için Derin Öğrenme Öneri Modeli https://arxiv.org/pdf/1906.00091.pdf
- Bellek Açısından Verimli Öneri Sistemleri İçin Tamamlayıcı Bölümler Kullanan Kompozisyonel Gömmeler https://arxiv.org/pdf/1909.02107.pdf
- Seyrek Özellikler ve Veriler için Gömme Boyutları Hakkında https://arxiv.org/pdf/1901.02103.pdf
- Facebook'un DNN tabanlı Kişiselleştirilmiş Önerisinin Mimari Etkileri https://arxiv.org/pdf/1906.03109.pdf
- https://github.com/pytorch/FBGEMM/wiki/Recent-feature-additions-and-improvements-in-FBGEMM
- Son teknoloji ürünü sunucu tarafı çıkarımı için açık kaynaklı FBGEMM https://engineering.fb.com/ml-applications/fbgemm/
orijinal. İzinle yeniden yayınlandı.
Bio: Nishant Kumar Bilgisayar Bilimleri alanında Lisans Derecesine sahiptir. Makine Öğrenimi, NLP, Öneri Sistemleri dahil olmak üzere Veri Bilimi ile ilgili çeşitli alanlarda 4 yıldan fazla BT endüstrisi deneyimine sahiptir. Verilerle oynamadığı zamanlarda bisiklete binmek ve yemek pişirmek için zaman harcıyor. Veri Biliminin teknik yönleri ve NLP'de ilginç Araştırmalar üzerine teknik makaleler yazmayı seviyor. Şu konulardaki makalelere göz atabilirsiniz: Orta.
İlgili:
30 Gün İçindeki En Çok Okunan Haberler
|
|
Coinsmart. Europa İçindeki En İyi Bitcoin-Börse
Kaynak: https://www.kdnuggets.com/2021/04/deep-learning-recommendation-models-dlrm-deep-dive.html

