Amazon Atina açık kaynak çerçeveleri üzerine kurulu, açık tablo dosya formatlarını destekleyen sunucusuz, etkileşimli bir analiz hizmetidir. Athena, petabaytlarca veriyi yaşadığı yerde analiz etmek için basitleştirilmiş ve esnek bir yol sağlar. Verileri analiz edebilir veya uygulamalar oluşturabilirsiniz. Amazon Basit Depolama Hizmeti (Amazon S3) veri gölü ve şirket içi veri kaynakları veya SQL veya Python kullanan diğer bulut sistemleri dahil 30 veri kaynağı. Athena, hiçbir provizyon veya yapılandırma çabası gerektirmeden açık kaynaklı Trino ve Presto motorları ve Apache Spark çerçeveleri üzerine kurulmuştur.
Bugünden itibaren Athena SQL motoru, veritabanında saklanan tablo ve sütun istatistiklerini kullanan yeni bir özellik olan maliyete dayalı optimize ediciyi (CBO) kullanıyor. AWS Tutkal Tablonun meta verilerinin bir parçası olarak Veri Kataloğu. CBO, bu istatistikleri kullanarak sorgu çalıştırma planlarını geliştirir ve Athena'da çalıştırılan sorguların performansını artırır. CBO'nun kullanabileceği spesifik optimizasyonlardan bazıları, birleştirmenin yeniden sıralanması ve her tablo ve sütun için mevcut istatistiklere dayalı olarak toplamaların aşağı itilmesidir.
TPC-DS kıyaslamaları Bu kıyaslamalar, maliyete dayalı optimize edicinin gücünü göstermektedir; sorgular, CBO olmadan aynı TPC-DS sorgularını çalıştırmaya kıyasla CBO etkinken 2 kata kadar daha hızlı çalışır.
TPC-DS kıyaslamalarında performans ve maliyet karşılaştırması
Farklı müşteri kullanım örneklerini temsil etmek için endüstri standardı TPC-DS 3 TB'yi kullandık. Bunlar, belirtilen karşılaştırma boyutunun 10 katı olan iş yüklerini temsil etmektedir. Bu, 3 TB'lık bir karşılaştırma veri kümesinin 30-50 TB veri kümelerindeki müşteri iş yüklerini doğru bir şekilde temsil ettiği anlamına gelir.
Testlerimizde veri kümesi Amazon S3'te sıkıştırılmamış Parquet formatında saklandı ve veritabanları ve tablolara ilişkin meta verileri depolamak için AWS Glue Data Catalog kullanıldı. Bilgi tabloları, birleştirme işlemleri için kullanılan tarih sütununa göre bölümlendi ve her bir bilgi tablosu 2,000 bölümden oluşuyordu. CBO'nun performansını göstermeye yardımcı olmak için çeşitli sorguların davranışını karşılaştırıyoruz ve CBO etkinken ve devre dışıyken çalıştırma arasındaki performans farklarını vurguluyoruz.
Aşağıdaki grafik, CBO'lu ve CBO'suz motordaki sorguların çalışma süresini göstermektedir.

Aşağıdaki grafik, TPC-DS karşılaştırmasında en yüksek performans artışı sağlayan ilk 10 sorguyu göstermektedir.
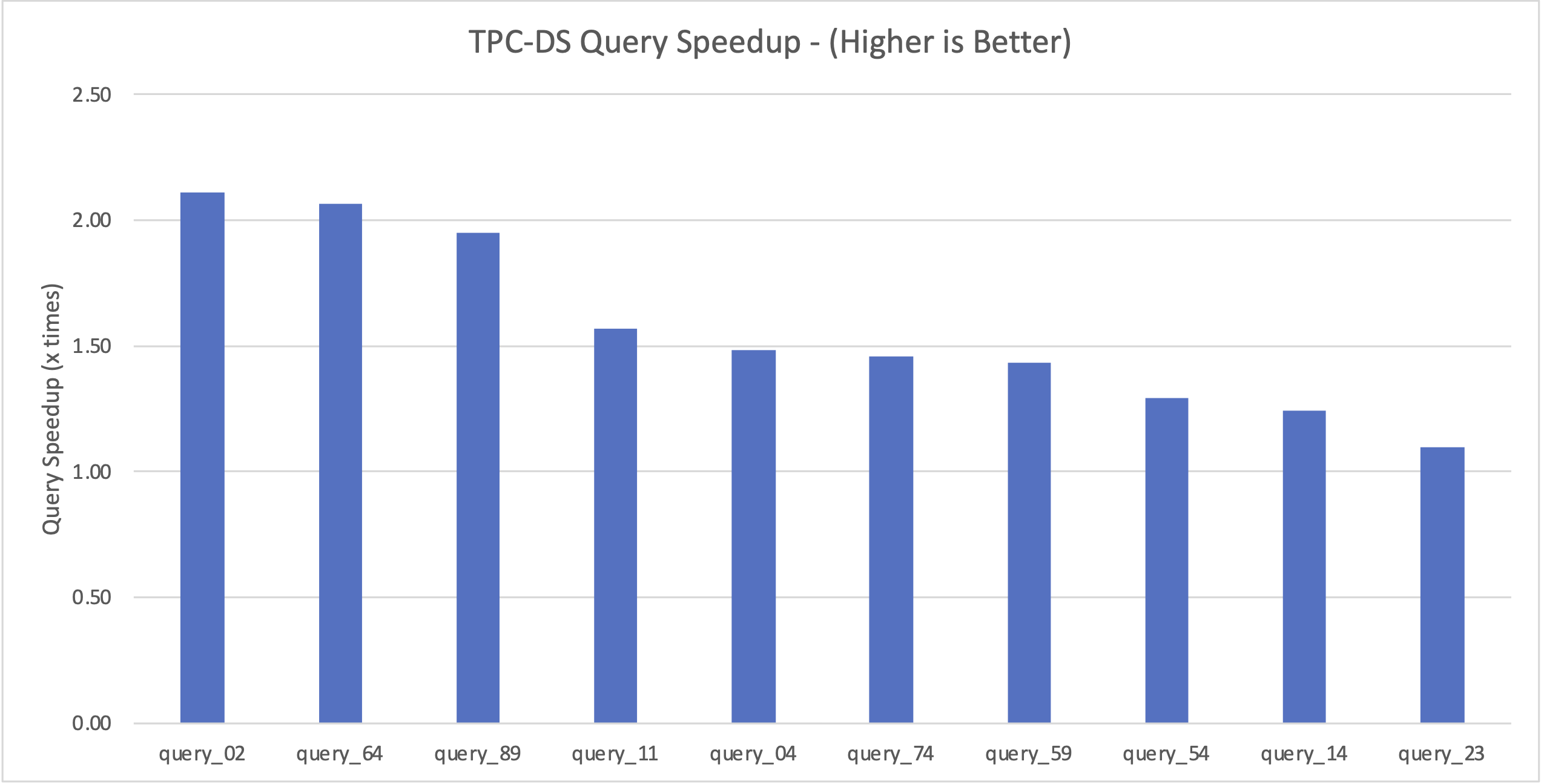
Sorgu performansının iyileştirilmesine katkıda bulunan maliyete dayalı optimizasyon tekniklerinden bazılarını tartışalım.
Maliyete dayalı birleştirme yeniden sıralaması
Maliyet tabanlı SQL iyileştiricileri tarafından kullanılan bir optimizasyon tekniği olan birleştirme yeniden sıralaması, her adımda işlenen ara verileri azaltarak, bellek ve CPU gereksinimlerini azaltarak sorgu çalışma süresini en aza indiren sırayı seçmek için farklı birleştirme dizilerini analiz eder.
TPC-DS 82TB veri setinin 3. sorgusundan bahsedelim. Sorgu dört tabloda iç birleştirmeler gerçekleştirir: item, inventory, date_dim, ve store_sales. store_sales tablonun 8.6 milyar satırı vardır ve tarihe göre bölümlendirilmiştir. inventory Tabloda 1 milyar satır vardır ve ayrıca tarihe göre bölümlendirilmiştir. item tablo 360,000 satır içerir ve date_dim tablo 73,000 satır içerir.
Sorgu 82
CBO olmadan
Motor, CBO kullanmadan, dahili buluşsal yöntemle giriş sorgusunda tanımlanan tabloların sırasına göre birleştirme sırasını belirleyecektir. Giriş sorgusunun FROM yan tümcesi "from item, inventory, date_dim, store_sales" (tüm iç birleşimler). Athena, dahili buluşsal yöntemlerden geçtikten sonra birleştirme sırasını şu şekilde seçti: ((item ⋈ (inventory ⋈ date_dim)) ⋈ store_sales). Aksine store_sales En büyük olgu tablosu olduğundan, FROM yan tümcesinde en son tanımlanır ve bu nedenle en son birleştirilir. Bu plan, ara birleştirme boyutlarını mümkün olduğu kadar erken azaltmayı başaramaz ve bu da sorgu çalışma süresinin artmasına neden olur. Aşağıdaki şemada CBO olmadan birleştirme sırası ve farklı aşamalardan geçen satır sayısı gösterilmektedir.

CBO ile
CBO kullanıldığında, optimizasyon aracı, birleştirme boyutu tahmini, birleştirme yapısı tarafı ve birleştirme türü gibi istatistiklerin yanı sıra çeşitli verileri kullanarak en iyi birleştirme sırasını belirler. Bu örnekte Athena'nın seçilen birleştirme sırası ((store_sales ⋈ item) ⋈ (inventory ⋈ date_dim)). En büyük gerçek tablosu, store_saleskarıştırılmadan ilk önce şununla birleştirilir: item boyut tablosu. Diğer bölümlenmiş tablo, inventory, aynı zamanda ilk olarak yerinde birleştirilir date_dim boyut tablosu. Boyut tablosuyla birleştirme, olgu tablosu üzerinde bir filtre görevi görür ve bu, takip eden birleştirmenin giriş verileri boyutunu önemli ölçüde azaltır. Athena'da bir birleştirme için tablonun hangi tarafta bulunduğunun önemli olduğunu unutmayın, çünkü birleştirme işlemi için belleğe yerleştirilecek olan sağdaki tablodur. Bu nedenle büyük masayı her zaman solda, küçük masayı ise sağda tutmak istiyoruz. CBO, sol tarafın önceden 8.6 milyar olduğu, şimdi ise 13.6 milyon olduğu bir plan seçti.

CBO ile, en uygun birleştirme sırası seçildiğinde sorgu çalışma süresi %25 arttı (15 saniyeden 11 saniyeye düştü).
Şimdi başka bir CBO tekniğini tartışalım.
Maliyete dayalı toplama aşağı itme
Toplama aşağı itme, sorgu iyileştiriciler tarafından performansı artırmak için kullanılan bir optimizasyon tekniğidir. Aynı sorgu semantiğini korurken SUM, COUNT ve AVG gibi toplama işlemlerini sorgu planında daha önceki bir aşamaya aktarmayı içerir. Bu, aşamalar arasında aktarılan veri miktarını azaltır. Toplama aşağı itme, veri işlemeyi en aza indirerek bellek kullanımını, G/Ç maliyetlerini ve ağ trafiğini azaltır.
Ancak toplamayı aşağı itmek her zaman yararlı değildir. Veri dağıtımına bağlıdır. Örneğin, birleştirmelerden önce çok sayıda satıra sahip ancak birkaç farklı değere (cinsiyet gibi) sahip bir sütun üzerinde gruplama yapmak daha iyi sonuç verir. Önce gruplama, çok sayıda kaydın daha az sayıda kayıtta toplanması anlamına gelir (örneğin yalnızca erkek, kadın). Katılmanın ardından gruplama, çok sayıda kaydın toplanmadan önce birleştirmeye katılması gerektiği anlamına gelir. Öte yandan, yüksek kardinaliteli bir sütunda gruplamanın birleştirmelerden sonra yapılması daha iyidir. Bunu daha önce yapmak, gereksiz toplama ek yükü riskini doğurur çünkü her değer muhtemelen benzersizdir ve bu adım, ara aşamalar arasında aktarılan veri miktarında daha erken bir azalmaya yol açmaz.
Bu nedenle, toplamanın azaltılıp azaltılmayacağı maliyete dayalı bir karar olmalıdır. Toplama aşağı itme değerinin veri dağıtımına nasıl bağlı olduğunu gösteren, 2 TB TPC-DS veri kümesinde çalıştırılan sorgu 3 örneğini ele alalım. web_sales Tabloda 2.1 milyar satır var ve catalog_sales Tabloda 4.23 milyar satır var. Her iki tablo da tarih sütununda bölümlendirilmiştir.
Sorgu 2
CBO olmadan
Athena ilk olarak birliğin tüm operasyonları sonucu katılır. web_sales masa ve catalog_sales başka bir masa ile masa. Ancak o zaman birleştirilmiş sonuçlar üzerinde toplama gerçekleştirir. Bu örnekte, birleştirilmesi gereken veri miktarı çok büyüktü ve bu da sorgu çalışma süresinin daha uzun olmasına neden oluyordu.

CBO ile
Athena, toplamayı aşağı itmenin veya bunu yapmamanın maliyet sonuçlarını değerlendirmek için istatistik değerlerinden biri olan farklı değer sayımını kullanır. Bir sütunda çok sayıda satır ancak az sayıda farklı değer bulunduğunda, CBO'nun toplama işlemini aşağı çekme olasılığı daha yüksektir. Bu, nitelikli satırları küçülttü web_sales ve catalog_sales tabloları sırasıyla 2,590 ve 3,590 satıra kadar. Bu birleştirilmiş kayıtlar daha sonra birleştirildi ve tablolarla birleştirmek için kullanıldı. CBO'suz planla karşılaştırıldığında, iki büyük tablodan birleştirmeye katılan kayıtlar 6.33 milyar satırdan (2.1 milyar + 4.23 milyar) yalnızca 6,180 satıra (2,590 + 3,590) düştü. Bu, sorgu çalışma süresini önemli ölçüde azalttı.

CBO ile sorgu çalışma süresi %50 arttı (37 saniyeden 18 saniyeye). Özetle CBO, Athena'nın en uygun toplama aşağı itme planını seçmesine yardımcı oldu ve maliyete dayalı optimizasyon kullanmamaya kıyasla sorgu süresini yarıya indirdi.
Sonuç
Bu yazıda, Athena'nın daha verimli sorgu çalıştırma planları oluşturmak amacıyla tablo istatistiklerini kullanmak için motorunda v3'ünde maliyet tabanlı bir optimize ediciyi (CBO) nasıl kullandığını tartıştık. TPC-DS karşılaştırmasında yapılan testler, CBO kullanıldığında, kullanılmamasına kıyasla genel sorgu performansında %11'lik bir iyileşme gösterdi.
CBO tarafından kullanılan iki temel optimizasyon, birleştirme yeniden sıralaması ve toplu aşağı itmedir. Birleştirme yeniden sıralaması, istatistiklere dayalı olarak tabloları birleştirme sırasını akıllıca seçerek ara verileri azaltır. Toplama aşağı itme, yararlı olduğunda toplamaları planda daha erkene iterek ara verileri azaltır.
Özetle, Athena'nın yeni maliyet tabanlı iyileştiricisi, üstün çalıştırma planları seçerek sorguları önemli ölçüde hızlandırır. CBO, AWS Glue Data Catalog'da depolanan tablo istatistiklerine göre optimizasyon yapar. Bu otomatik optimizasyon, daha duyarlı sorgu performansı sayesinde Athena kullanıcılarının üretkenliğini artırır. CBO'nun optimizasyon tekniklerinden yararlanmak için bkz. sütun istatistikleriyle çalışma AWS Glue Data Catalog'daki tablo ve sütunlara ilişkin istatistikler oluşturmak için.
Yazarlar Hakkında
 Darshit Thakkar AWS'de Teknik Ürün Yöneticisidir ve Boston, Massachusetts merkezli Amazon Athena ekibiyle birlikte çalışmaktadır.
Darshit Thakkar AWS'de Teknik Ürün Yöneticisidir ve Boston, Massachusetts merkezli Amazon Athena ekibiyle birlikte çalışmaktadır.
 Wei Zheng Amazon Athena'da Kıdemli Yazılım Geliştirme Mühendisidir. AWS'ye 2021'de katıldı ve Athena'da birçok performans iyileştirmesi üzerinde çalışıyor.
Wei Zheng Amazon Athena'da Kıdemli Yazılım Geliştirme Mühendisidir. AWS'ye 2021'de katıldı ve Athena'da birçok performans iyileştirmesi üzerinde çalışıyor.
 Chuho Chang Amazon Athena'da Yazılım Geliştirme Mühendisidir. On yılı aşkın bir süredir sorgu iyileştiriciler üzerinde çalışıyor.
Chuho Chang Amazon Athena'da Yazılım Geliştirme Mühendisidir. On yılı aşkın bir süredir sorgu iyileştiriciler üzerinde çalışıyor.
 Pathik Şah Amazon Athena'da Kıdemli Analitik Mimarıdır. AWS'ye 2015 yılında katıldı ve o zamandan bu yana büyük veri analitiği alanına odaklanarak müşterilerin AWS analiz hizmetlerini kullanarak ölçeklenebilir ve sağlam çözümler oluşturmasına yardımcı oluyor.
Pathik Şah Amazon Athena'da Kıdemli Analitik Mimarıdır. AWS'ye 2015 yılında katıldı ve o zamandan bu yana büyük veri analitiği alanına odaklanarak müşterilerin AWS analiz hizmetlerini kullanarak ölçeklenebilir ve sağlam çözümler oluşturmasına yardımcı oluyor.
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- PlatoData.Network Dikey Üretken Yapay Zeka. Kendine güç ver. Buradan Erişin.
- PlatoAiStream. Web3 Zekası. Bilgi Genişletildi. Buradan Erişin.
- PlatoESG. karbon, temiz teknoloji, Enerji, Çevre, Güneş, Atık Yönetimi. Buradan Erişin.
- PlatoSağlık. Biyoteknoloji ve Klinik Araştırmalar Zekası. Buradan Erişin.
- Kaynak: https://aws.amazon.com/blogs/big-data/speed-up-queries-with-cost-based-optimizer-in-amazon-athena/

