Giriş
İnsanlar, alaka düzeyi nedeniyle değil, en üstte oldukları için arama ve önerilerdeki en iyi öğelere daha sık tıklar. Arama sonuçlarınızı bir makine öğrenimi modeliyle sıralarsanız, kendi kendini güçlendiren böylesine olumlu bir geri bildirim döngüsü nedeniyle sonunda kaliteleri düşebilir. Bu sorun nasıl çözülebilir?
Günümüzde, arama sıralaması ve öneri sistemleri, belirli bir sorgu için sonuçları sıralamak amacıyla Learning-to-Rank (LTR) modelleri gibi makine öğrenimi modellerini eğitmek için büyük miktarda veriye güveniyor ve örtülü kullanıcı geri bildirimleri (ör. tıklama verileri) baskın hale geldi. bolluğu ve düşük maliyeti nedeniyle, özellikle büyük İnternet şirketleri için veri toplama kaynağı. Bununla birlikte, bu veri toplama yönteminin bir dezavantajı, verilerin oldukça çarpık olabilmesidir. En belirgin yanlılıklardan biri, kullanıcılar daha üst sıralarda yer alan sonuçlara tıklama eğiliminde olduklarında ortaya çıkan konum yanlılığıdır.
Bu yazıda, aşağıdaki konuları tartışacağız:
- Hangi önyargı türleri mevcuttur ve bunlar nasıl ölçülür?
- Ters Eğilim Ağırlıklandırması ile konum yanlılığının üstesinden gelme ve bu tür bir yaklaşımın dezavantajları.
- Konuma Duyarlı Öğrenme, makine öğrenimi modelinize eğitim sırasında önyargıyı dikkate almayı öğretmenin bir yoludur.
Bu makale, Veri Bilimi Blogathon.
İçindekiler
Sıralamadaki Önyargılar
Bir insana arama sonuçları veya öneriler (veya otomatik tamamlama önerileri ve kişi listeleri) gibi bir şeylerin listesini her sunduğunuzda, listedeki tüm öğeleri neredeyse hiç tarafsız olarak değerlendiremeyiz.
A kademeli tıklama modeli insanların ilgili öğeyi bulmadan önce listedeki tüm öğeleri sırayla değerlendirdiğini varsayar. Ancak bu, en alttaki öğelerin değerlendirilme şansının daha düşük olduğu, dolayısıyla organik olarak daha az tıklama alacağı anlamına gelir:
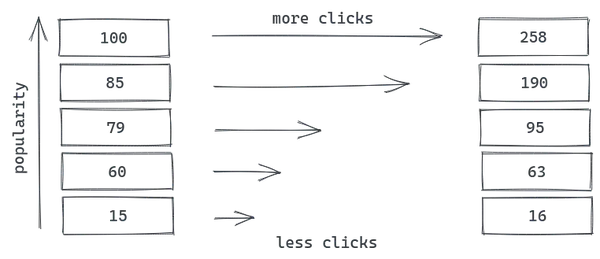
En iyi öğeler, yalnızca konumları nedeniyle daha fazla tıklama alır; bu davranışa konum yanlılığı denir. Ancak, öğe listelerindeki tek önyargı konum yanlılığı değildir, dikkat edilmesi gereken pek çok başka tehlikeli şey vardır:
- Sunum yanlılığı: Örneğin, 3×3 ızgara düzeni nedeniyle, 4. konumdaki bir öğe (üstteki 1 numaralı öğenin hemen altında), köşedeki 3 numaralı öğeden daha fazla tıklama alabilir.
- Model yanlılığı: Bir makine öğrenimi modelini, aynı model tarafından oluşturulan geçmiş veriler üzerinde eğittiğinizde.
- Tıklama tuzağı, süre ve popülerlik gibi bazı daha belirsiz önyargılar - ayrıntılar için bu tür önyargılara ilişkin mükemmel bir genel bakışa bakın.
Uygulamada, konum yanlılığı en güçlüsüdür ve eğitim sırasında bunu kaldırmak, modelinizin güvenilirliğini artırabilir.
Deney: Pozisyon Önyargısını Ölçme
Pozisyon yanlılığı hakkında kitle kaynaklı küçük bir araştırma yürüttük. Birlikte Sıra Mercek veri kümesi, belirli bir filmi bulmak için bir dizi sorgu oluşturmak üzere bir Google Anahtar Kelime Planlayıcı aracı kullandık.
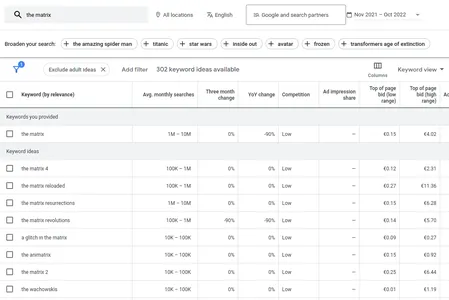
Bir dizi film ve karşılık gelen gerçek sorgularla, mükemmel bir arama değerlendirme veri kümemiz var - tüm öğeler daha geniş bir kitle tarafından iyi biliniyor ve doğru etiketleri önceden biliyoruz.
Amazon Mechanical Turk ve Toloka.ai gibi tüm büyük kitle kaynak platformları, tipik arama değerlendirmesi için kullanıma hazır şablonlara sahiptir:
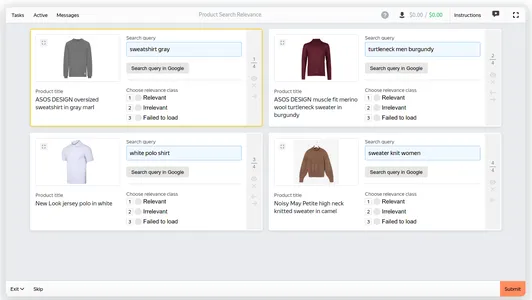
Ancak bu tür şablonlarda, pozisyon önyargısıyla kendinizi ayağınıza vurmanızı engelleyen güzel bir numara var: her öğe bağımsız olarak incelenmelidir. Ekranda birden çok öğe bulunsa bile bunların sıralaması rastgeledir!
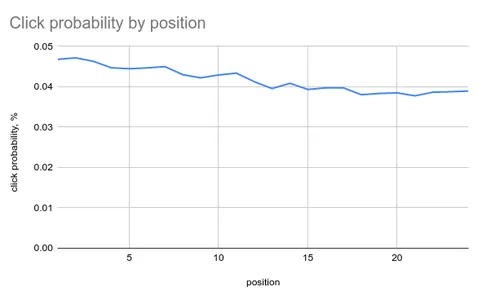
Ancak rastgele öğe sırası, insanların ilk sonuçlara tıklamasını engelliyor mu?
Deney için ham veriler şu adreste mevcuttur: github.com/metarank/msrd, ancak asıl gözlem, insanların rastgele sıralanan öğelerde bile ilk konuma hala daha fazla tıkladıklarıdır!
Ters Eğilim Ağırlıklandırması
Ancak, konumun tıklamalardan aldığınız örtülü geri bildirim üzerindeki etkisini nasıl dengeleyebilirsiniz? Bir öğenin tıklama olasılığını her ölçtüğünüzde, iki bağımsız değişkenin birleşimini gözlemlersiniz:
- Önyargı: Listede belirli bir konuma tıklama olasılığı.
- İlgililik: Maddenin mevcut bağlamdaki önemi (Örneğin BM25 puanı Elasticsearchve önerilerde kosinüs benzerliği)
Önceki paragrafta bahsedilen MSRD veri setinde, pozisyonun etkisini BM25 alaka düzeyinden bağımsız olarak ayırt etmek zordur, çünkü bunları yalnızca bir arada gözlemlersiniz.
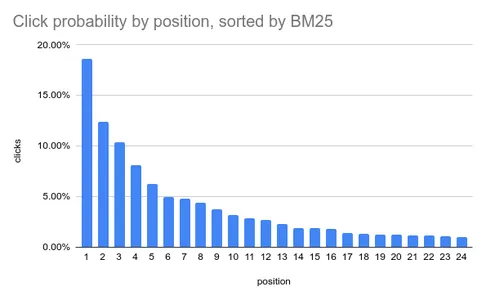
Örneğin, tıklamaların %18'i 1. konumda gerçekleşiyor. Bu sadece orada sunulan en alakalı öğeye sahip olduğumuz için mi oluyor? 20. konumdaki aynı öğe aynı miktarda tıklama alacak mı?
Ters Eğilim Ağırlıklandırma yaklaşımı, bir konumda gözlemlenen tıklama olasılığının yalnızca iki bağımsız değişkenin bir kombinasyonu olduğunu öne sürer:
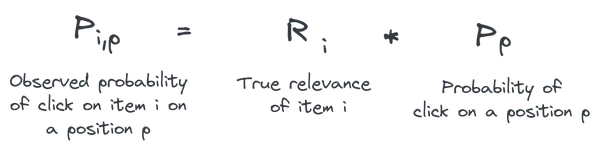
Ardından, her konumdaki tıklama olasılığını (eğilim) tahmin ederseniz, tüm alaka düzeyi etiketlerinizi bununla ağırlıklandırabilir ve gerçek, tarafsız bir alaka düzeyi elde edebilirsiniz:

Ancak pratikte eğilimi nasıl tahmin edebilirsiniz? En yaygın yöntem, aynı bağlamda (örneğin, bir arama sorgusu için) aynı öğelerin farklı konumlarda değerlendirilmesi için sıralamalara küçük bir karıştırma getirmektir.

Ancak fazladan karıştırma eklemek, TO ve Dönüşüm Oranı gibi işletme ölçümlerinizi kesinlikle düşürecektir. Karıştırmayı içermeyen daha az istilacı alternatifler var mı?

Konuma Duyarlı Öğrenme
Sıralamaya yönelik konuma duyarlı bir yaklaşım, makine öğrenimi modeli hem sıralama alaka düzeyini hem de konum etkisini aynı anda optimize etmek için:
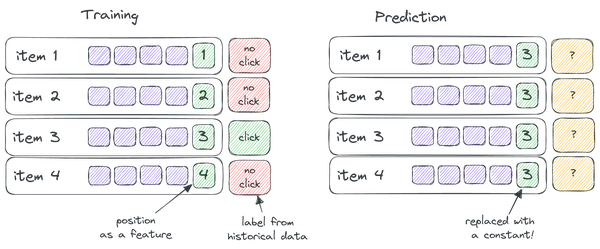
- Eğitim süresinde, öğe konumunu bir giriş özelliği olarak kullanırsınız,
- Tahmin aşamasında, onu sabit bir değerle değiştirirsiniz.
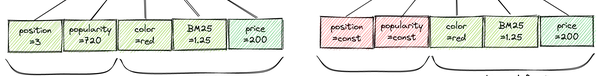
Başka bir deyişle, eğitim sırasında konumun alaka düzeyini nasıl etkilediğini tespit etmesi için sıralama makine öğrenimi modelinizi kandırırsınız, ancak tahmin sırasında bu özelliği sıfırlarsınız: tüm öğeler aynı anda aynı konumda sunulur.
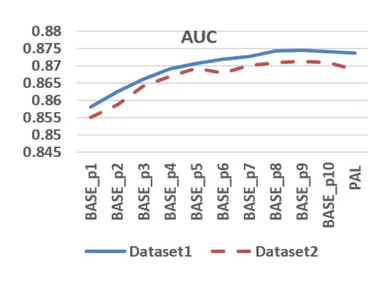
Ancak hangi sabit değeri seçmelisiniz? PAL makalesinin yazarları, en uygun değeri seçmek için birkaç sayısal deney yaptılar - çok fazla gürültü olduğu için çok yüksek konumlar seçmemek temel kuraldır.
Pratik PAL
PAL yaklaşımı, öneriler ve aramalar oluşturmak için halihazırda çok sayıda açık kaynaklı aracın bir parçasıdır:
- ToRecSys, eğitmek için önyargıyı ortadan kaldıran bir yaklaşım olarak PAL'ı uygular tavsiye sistemleri önyargılı veriler üzerinde.
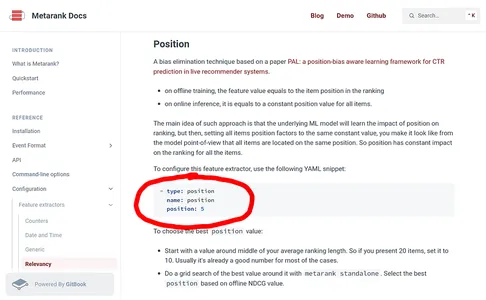
- Metarank, tarafsız bir LambdaMART Learn-to-Rank modelini eğitmek için PAL güdümlü bir özellik kullanabilir.
Pozisyona duyarlı yaklaşım sadece bir hack olduğu için özellik mühendisliği, Metarank'ta sadece başka bir başarı eklemek meselesi
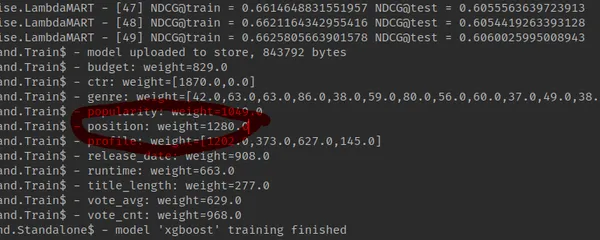
Yukarıda bahsedilen bir MSRD veri setinde, PAL'den ilham alan böyle bir sıralama özelliği, diğer sıralama özelliklerine kıyasla oldukça yüksek bir önem değerine sahiptir:
Sonuç
Pozisyona duyarlı öğrenme yaklaşımı yalnızca saf sıralama görevleri ve pozisyon önyargısını kaldırma ile sınırlı değildir: bu numarayı diğer herhangi bir önyargı türünün üstesinden gelmek için kullanabilirsiniz:
- Izgara düzeninden kaynaklanan sunum yanlılığı için, eğitim sırasında bir öğenin satır ve sütun konumu için bir çift özellik tanıtabilirsiniz. Ancak tahmin sırasında bunları bir sabite değiştirin.
- Model yanlılığı için, sunulan öğeler daha sık olarak daha fazla tıklama aldığında — bir "tıklama sayısı" eğitim özelliği sunabilir ve bunu tahmin süresinde sabit bir değerle değiştirebilirsiniz.
PAL yaklaşımıyla eğitilen makine öğrenimi modeli, tarafsız bir tahmin üretmelidir. PAL yaklaşımının basitliği göz önüne alındığında, önyargılı eğitim verilerinin olağan bir şey olduğu diğer makine öğrenimi alanlarına da uygulanabilir.
Bu araştırmayı yürütürken aşağıdaki temel gözlemleri yaptık:
- Pozisyon yanlılığı, tarafsız veri setlerinde bile mevcut olabilir.
- IPW gibi karıştırmaya dayalı yaklaşımlar, önyargı sorununun üstesinden gelebilir, ancak tahminlerde fazladan sapma sağlamak, TO gibi iş ölçütlerini düşürerek size çok pahalıya mal olabilir.
- Konuma duyarlı öğrenme yaklaşımı, makine öğrenimi modelinizin önyargının etkisini öğrenmesini sağlayarak tahmin kalitesini artırır.
Bu makalede gösterilen medya Analytics Vidhya'ya ait değildir ve Yazarın takdirine bağlı olarak kullanılır.
İlgili bağlantılar
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- Plato blok zinciri. Web3 Metaverse Zekası. Bilgi Güçlendirildi. Buradan Erişin.
- Kaynak: https://www.analyticsvidhya.com/blog/2023/03/how-to-overcome-position-bias-in-recommendation-and-search/

