โดยทั่วไป โมเดลภาษาขนาดใหญ่ (LLM) จะได้รับการฝึกบนชุดข้อมูลขนาดใหญ่ที่เปิดเผยต่อสาธารณะซึ่งไม่เชื่อเรื่องโดเมน ตัวอย่างเช่น, ลามะของเมต้า โมเดลต่างๆ ได้รับการฝึกฝนเกี่ยวกับชุดข้อมูล เช่น CommonCrawl, C4, วิกิพีเดีย และ อาร์ซีฟ- ชุดข้อมูลเหล่านี้ครอบคลุมหัวข้อและโดเมนที่หลากหลาย แม้ว่าแบบจำลองผลลัพธ์จะให้ผลลัพธ์ที่ดีอย่างน่าอัศจรรย์สำหรับงานทั่วไป เช่น การสร้างข้อความและการจดจำเอนทิตี แต่ก็มีหลักฐานว่าแบบจำลองที่ได้รับการฝึกด้วยชุดข้อมูลเฉพาะโดเมนสามารถปรับปรุงประสิทธิภาพของ LLM ต่อไปได้ เช่น ข้อมูลการฝึกอบรมที่ใช้สำหรับ บลูมเบิร์กจีพีที เป็นเอกสารเฉพาะโดเมน 51% รวมถึงข่าวทางการเงิน เอกสารที่ยื่น และเอกสารทางการเงินอื่นๆ LLM ที่ได้นั้นมีประสิทธิภาพเหนือกว่า LLM ที่ได้รับการฝึกอบรมบนชุดข้อมูลที่ไม่เฉพาะโดเมน เมื่อทดสอบกับงานเฉพาะด้านการเงิน ผู้เขียนของ บลูมเบิร์กจีพีที สรุปว่าโมเดลของพวกเขามีประสิทธิภาพเหนือกว่าโมเดลอื่นๆ ทั้งหมดที่ทดสอบสำหรับงานทางการเงินสี่ในห้างาน แบบจำลองนี้ให้ประสิทธิภาพที่ดียิ่งขึ้นไปอีกเมื่อทดสอบสำหรับงานทางการเงินภายในของ Bloomberg ด้วยอัตรากำไรที่กว้าง ซึ่งดีกว่ามากถึง 60 คะแนน (จากเต็ม 100) แม้ว่าคุณจะสามารถเรียนรู้เพิ่มเติมเกี่ยวกับผลการประเมินที่ครอบคลุมได้ใน กระดาษตัวอย่างต่อไปนี้จับมาจาก บลูมเบิร์กจีพีที เอกสารช่วยให้คุณเห็นประโยชน์ของการฝึกอบรม LLM โดยใช้ข้อมูลเฉพาะโดเมนทางการเงิน ดังที่แสดงในตัวอย่าง โมเดล BloombergGPT ให้คำตอบที่ถูกต้อง ในขณะที่โมเดลที่ไม่เจาะจงโดเมนอื่นๆ ประสบปัญหา:
โพสต์นี้ให้คำแนะนำในการฝึกอบรม LLM สำหรับโดเมนทางการเงินโดยเฉพาะ เราครอบคลุมประเด็นสำคัญดังต่อไปนี้:
- การรวบรวมและจัดทำข้อมูล – คำแนะนำในการจัดหาและดูแลจัดการข้อมูลทางการเงินที่เกี่ยวข้องเพื่อการฝึกโมเดลที่มีประสิทธิภาพ
- การฝึกอบรมล่วงหน้าอย่างต่อเนื่องกับการปรับแต่งอย่างละเอียด – เมื่อใดที่ควรใช้แต่ละเทคนิคเพื่อเพิ่มประสิทธิภาพการทำงานของ LLM ของคุณ
- การฝึกอบรมล่วงหน้าอย่างต่อเนื่องอย่างมีประสิทธิภาพ – กลยุทธ์ในการปรับปรุงกระบวนการก่อนการฝึกอบรมอย่างต่อเนื่อง ประหยัดเวลาและทรัพยากร
โพสต์นี้รวบรวมความเชี่ยวชาญของทีมวิจัยวิทยาศาสตร์ประยุกต์ภายใน Amazon Finance Technology และทีมผู้เชี่ยวชาญ AWS Worldwide สำหรับอุตสาหกรรมการเงินทั่วโลก เนื้อหาบางส่วนอ้างอิงจากบทความ การฝึกอบรมล่วงหน้าอย่างต่อเนื่องอย่างมีประสิทธิภาพสำหรับการสร้างโมเดลภาษาขนาดใหญ่เฉพาะโดเมน.
รวบรวมและจัดทำข้อมูลทางการเงิน
การฝึกอบรมล่วงหน้าอย่างต่อเนื่องของโดเมนจำเป็นต้องมีชุดข้อมูลเฉพาะโดเมนขนาดใหญ่และมีคุณภาพสูง ต่อไปนี้เป็นขั้นตอนหลักสำหรับการดูแลชุดข้อมูลโดเมน:
- ระบุแหล่งข้อมูล – แหล่งข้อมูลที่เป็นไปได้สำหรับคลังข้อมูลโดเมน ได้แก่ เว็บแบบเปิด วิกิพีเดีย หนังสือ โซเชียลมีเดีย และเอกสารภายใน
- ตัวกรองข้อมูลโดเมน – เนื่องจากเป้าหมายสูงสุดคือการดูแลจัดการคลังข้อมูลโดเมน คุณอาจต้องใช้ขั้นตอนเพิ่มเติมเพื่อกรองตัวอย่างที่ไม่เกี่ยวข้องกับโดเมนเป้าหมายออก สิ่งนี้จะช่วยลดคลังข้อมูลที่ไร้ประโยชน์สำหรับการฝึกอบรมล่วงหน้าอย่างต่อเนื่องและลดต้นทุนการฝึกอบรม
- กระบวนการเตรียมการผลิต – คุณอาจพิจารณาชุดขั้นตอนการประมวลผลล่วงหน้าเพื่อปรับปรุงคุณภาพข้อมูลและประสิทธิภาพการฝึกอบรม ตัวอย่างเช่น แหล่งข้อมูลบางแห่งอาจมีโทเค็นที่มีสัญญาณรบกวนในจำนวนที่พอใช้ การขจัดข้อมูลซ้ำซ้อนถือเป็นขั้นตอนที่มีประโยชน์ในการปรับปรุงคุณภาพข้อมูลและลดต้นทุนการฝึกอบรม
ในการพัฒนา LLM ทางการเงิน คุณสามารถใช้แหล่งข้อมูลที่สำคัญสองแหล่ง ได้แก่ News CommonCrawl และ SEC filings การยื่นต่อ SEC คืองบการเงินหรือเอกสารที่เป็นทางการอื่นๆ ที่ยื่นต่อสำนักงานคณะกรรมการกำกับหลักทรัพย์และตลาดหลักทรัพย์ (SEC) ของสหรัฐอเมริกา บริษัทจดทะเบียนจะต้องยื่นเอกสารต่างๆ เป็นประจำ สิ่งนี้ทำให้เกิดเอกสารจำนวนมากในช่วงหลายปีที่ผ่านมา News CommonCrawl เป็นชุดข้อมูลที่เผยแพร่โดย CommonCrawl ในปี 2016 ประกอบด้วยบทความข่าวจากเว็บไซต์ข่าวทั่วโลก
ข่าว CommonCrawl มีอยู่บน บริการจัดเก็บข้อมูลอย่างง่ายของ Amazon (Amazon S3) ใน commoncrawl ถังที่ crawl-data/CC-NEWS/- คุณสามารถรับรายการไฟล์โดยใช้ อินเทอร์เฟซบรรทัดคำสั่ง AWS AWS (AWS CLI) และคำสั่งต่อไปนี้:
In การฝึกอบรมล่วงหน้าอย่างต่อเนื่องอย่างมีประสิทธิภาพสำหรับการสร้างโมเดลภาษาขนาดใหญ่เฉพาะโดเมนผู้เขียนใช้ URL และแนวทางตามคำหลักเพื่อกรองบทความข่าวการเงินจากข่าวทั่วไป โดยเฉพาะอย่างยิ่ง ผู้เขียนเก็บรักษารายชื่อสำนักข่าวทางการเงินที่สำคัญและชุดคำหลักที่เกี่ยวข้องกับข่าวการเงิน เราระบุว่าบทความเป็นข่าวการเงินหากมาจากสำนักข่าวทางการเงินหรือมีคำหลักใดๆ ปรากฏใน URL วิธีการที่เรียบง่ายแต่มีประสิทธิภาพนี้ช่วยให้คุณสามารถระบุข่าวทางการเงินจากสำนักข่าวทางการเงินไม่เพียงเท่านั้น แต่ยังรวมไปถึงส่วนการเงินของสำนักข่าวทั่วไปด้วย
เอกสารที่ยื่นต่อ SEC มีให้บริการทางออนไลน์ผ่านฐานข้อมูล EDGAR (การรวบรวมข้อมูลทางอิเล็กทรอนิกส์ การวิเคราะห์ และการเรียกค้น) ของ SEC ซึ่งให้การเข้าถึงข้อมูลแบบเปิด คุณสามารถขูดไฟล์ที่ยื่นจาก EDGAR ได้โดยตรง หรือใช้ API ใน อเมซอน SageMaker ด้วยโค้ดไม่กี่บรรทัดในช่วงเวลาใดก็ได้และสำหรับตัวแสดงจำนวนมาก (เช่น ตัวระบุที่กำหนดโดย SEC) หากต้องการเรียนรู้เพิ่มเติม โปรดดูที่ ก.ล.ต. การเรียกคืนการยื่นคำร้อง.
ตารางต่อไปนี้สรุปรายละเอียดที่สำคัญของแหล่งข้อมูลทั้งสอง
| . | ข่าว CommonCrawl | ก.ล.ต |
| คุ้มครอง | 2016-2022 | 1993-2022 |
| ขนาด | 25.8 พันล้านคำ | 5.1 พันล้านคำ |
ผู้เขียนจะต้องผ่านขั้นตอนการประมวลผลล่วงหน้าเพิ่มเติมสองสามขั้นตอนก่อนที่ข้อมูลจะถูกป้อนเข้าสู่อัลกอริธึมการฝึกอบรม อันดับแรก เราสังเกตว่าเอกสารที่ยื่นต่อ SEC มีข้อความที่มีเสียงดังเนื่องจากการถอดตารางและรูปภาพออก ดังนั้นผู้เขียนจึงลบประโยคสั้นๆ ที่ถือว่าเป็นป้ายตารางหรือรูปภาพออก ประการที่สอง เราใช้อัลกอริธึมการแฮชที่มีความละเอียดอ่อนในพื้นที่เพื่อขจัดความซ้ำซ้อนของบทความและเอกสารที่ยื่นใหม่ สำหรับการยื่นต่อ SEC เราจะขจัดข้อมูลที่ซ้ำกันในระดับส่วนแทนที่จะเป็นระดับเอกสาร สุดท้ายนี้ เราต่อเอกสารเป็นสตริงยาว สร้างโทเค็น และแบ่งโทเค็นออกเป็นชิ้นส่วนของความยาวอินพุตสูงสุดที่โมเดลรองรับที่จะฝึก ซึ่งจะช่วยปรับปรุงปริมาณงานของการฝึกอบรมล่วงหน้าอย่างต่อเนื่องและลดต้นทุนการฝึกอบรม
การฝึกอบรมล่วงหน้าอย่างต่อเนื่องกับการปรับแต่งอย่างละเอียด
LLM ที่มีอยู่ส่วนใหญ่จะมีวัตถุประสงค์ทั่วไปและไม่มีความสามารถเฉพาะโดเมน Domain LLM แสดงให้เห็นประสิทธิภาพอย่างมากในด้านการแพทย์ การเงิน หรือวิทยาศาสตร์ สำหรับ LLM ที่จะได้รับความรู้เฉพาะโดเมน มีสี่วิธี: การฝึกอบรมตั้งแต่เริ่มต้น การฝึกอบรมล่วงหน้าอย่างต่อเนื่อง การปรับแต่งคำแนะนำในงานในโดเมน และการดึงข้อมูล Augmented Generation (RAG)
ในโมเดลแบบดั้งเดิม การปรับแต่งแบบละเอียดมักจะใช้เพื่อสร้างโมเดลเฉพาะงานสำหรับโดเมน ซึ่งหมายความว่าการรักษาแบบจำลองหลายแบบสำหรับงานหลายอย่าง เช่น การแยกเอนทิตี การจัดประเภทเจตนา การวิเคราะห์ความรู้สึก หรือการตอบคำถาม ด้วยการถือกำเนิดของ LLM ความจำเป็นในการรักษาแบบจำลองที่แยกจากกันจึงล้าสมัยโดยใช้เทคนิคต่างๆ เช่น การเรียนรู้ในบริบทหรือการกระตุ้นเตือน ซึ่งจะช่วยประหยัดความพยายามที่จำเป็นในการรักษาสแต็กของโมเดลสำหรับงานที่เกี่ยวข้องแต่แตกต่างกัน
คุณสามารถฝึกอบรม LLM ตั้งแต่เริ่มต้นด้วยข้อมูลเฉพาะโดเมนได้อย่างง่ายดาย แม้ว่างานส่วนใหญ่ในการสร้างโดเมน LLM จะมุ่งเน้นไปที่การฝึกอบรมตั้งแต่เริ่มต้น แต่ก็มีราคาแพงมาก เช่น ราคารุ่น GPT-4 มากกว่า $ 100 ล้าน เพื่อฝึกฝน โมเดลเหล่านี้ได้รับการฝึกอบรมเกี่ยวกับการผสมผสานระหว่างข้อมูลโดเมนแบบเปิดและข้อมูลโดเมน การฝึกอบรมล่วงหน้าอย่างต่อเนื่องสามารถช่วยให้โมเดลได้รับความรู้เฉพาะโดเมนโดยไม่ต้องเสียค่าใช้จ่ายในการฝึกอบรมล่วงหน้าตั้งแต่เริ่มต้น เนื่องจากคุณฝึกอบรม LLM แบบโอเพ่นโดเมนที่มีอยู่ล่วงหน้าบนข้อมูลโดเมนเท่านั้น
ด้วยการปรับแต่งคำสั่งอย่างละเอียดในงาน คุณไม่สามารถทำให้โมเดลได้รับความรู้เกี่ยวกับโดเมนได้ เนื่องจาก LLM จะได้รับเฉพาะข้อมูลโดเมนที่มีอยู่ในชุดข้อมูลการปรับแต่งคำสั่งอย่างละเอียดเท่านั้น เว้นแต่ว่าจะใช้ชุดข้อมูลขนาดใหญ่มากสำหรับการปรับแต่งคำสั่งอย่างละเอียด การได้รับความรู้เกี่ยวกับโดเมนนั้นไม่เพียงพอ การจัดหาชุดข้อมูลการเรียนการสอนคุณภาพสูงมักเป็นเรื่องที่ท้าทายและเป็นเหตุผลที่ต้องใช้ LLM เป็นอันดับแรก นอกจากนี้ การปรับแต่งคำสั่งอย่างละเอียดในงานหนึ่งอาจส่งผลต่อประสิทธิภาพงานอื่นๆ (ดังที่เห็นใน กระดาษนี้- อย่างไรก็ตาม การปรับคำสั่งอย่างละเอียดจะคุ้มค่ากว่าทางเลือกก่อนการฝึกอบรมอย่างใดอย่างหนึ่ง
รูปต่อไปนี้เปรียบเทียบการปรับแต่งเฉพาะงานแบบดั้งเดิม เทียบกับกระบวนทัศน์การเรียนรู้ในบริบทด้วย LLM
 RAG เป็นวิธีที่มีประสิทธิภาพที่สุดในการแนะนำ LLM เพื่อสร้างคำตอบที่มีพื้นฐานอยู่ในโดเมน แม้ว่าจะสามารถแนะนำแบบจำลองในการสร้างการตอบสนองโดยการให้ข้อเท็จจริงจากโดเมนเป็นข้อมูลเสริม แต่จะไม่ได้รับภาษาเฉพาะโดเมน เนื่องจาก LLM ยังคงใช้รูปแบบภาษาที่ไม่ใช่โดเมนเพื่อสร้างการตอบสนอง
RAG เป็นวิธีที่มีประสิทธิภาพที่สุดในการแนะนำ LLM เพื่อสร้างคำตอบที่มีพื้นฐานอยู่ในโดเมน แม้ว่าจะสามารถแนะนำแบบจำลองในการสร้างการตอบสนองโดยการให้ข้อเท็จจริงจากโดเมนเป็นข้อมูลเสริม แต่จะไม่ได้รับภาษาเฉพาะโดเมน เนื่องจาก LLM ยังคงใช้รูปแบบภาษาที่ไม่ใช่โดเมนเพื่อสร้างการตอบสนอง
การฝึกอบรมล่วงหน้าอย่างต่อเนื่องเป็นจุดกึ่งกลางระหว่างการฝึกอบรมล่วงหน้าและการปรับแต่งการสอนอย่างละเอียดในแง่ของต้นทุน ในขณะเดียวกันก็เป็นทางเลือกที่ดีในการได้รับความรู้และสไตล์เฉพาะโดเมน โดยสามารถให้แบบจำลองทั่วไปซึ่งสามารถดำเนินการปรับคำสั่งเพิ่มเติมอย่างละเอียดเกี่ยวกับข้อมูลคำสั่งที่จำกัดได้ การฝึกอบรมล่วงหน้าอย่างต่อเนื่องอาจเป็นกลยุทธ์ที่คุ้มค่าสำหรับโดเมนเฉพาะทางที่ชุดของงานดาวน์สตรีมมีขนาดใหญ่หรือไม่ทราบข้อมูล และข้อมูลการปรับแต่งคำสั่งที่มีป้ายกำกับมีจำกัด ในสถานการณ์อื่นๆ การปรับแต่งคำสั่งอย่างละเอียดหรือ RAG อาจเหมาะสมกว่า
หากต้องการเรียนรู้เพิ่มเติมเกี่ยวกับการปรับแต่งแบบละเอียด RAG และการฝึกโมเดล โปรดดูที่ ปรับแต่งโมเดลรากฐานอย่างละเอียด, การดึงข้อมูล Augmented Generation (RAG)และ ฝึกโมเดลด้วย Amazon SageMakerตามลำดับ สำหรับโพสต์นี้ เรามุ่งเน้นไปที่การฝึกอบรมล่วงหน้าอย่างต่อเนื่องอย่างมีประสิทธิภาพ
วิธีการฝึกอบรมล่วงหน้าอย่างต่อเนื่องอย่างมีประสิทธิภาพ
การฝึกอบรมล่วงหน้าอย่างต่อเนื่องประกอบด้วยวิธีการดังต่อไปนี้:
- การฝึกอบรมล่วงหน้าอย่างต่อเนื่องแบบปรับเปลี่ยนโดเมน (DACP) – ในกระดาษ การฝึกอบรมล่วงหน้าอย่างต่อเนื่องอย่างมีประสิทธิภาพสำหรับการสร้างโมเดลภาษาขนาดใหญ่เฉพาะโดเมนผู้เขียนจะฝึกอบรมชุดโมเดลภาษา Pythia ล่วงหน้าอย่างต่อเนื่องในคลังข้อมูลทางการเงินเพื่อปรับให้เข้ากับโดเมนทางการเงิน วัตถุประสงค์คือเพื่อสร้าง LLM ทางการเงินโดยการป้อนข้อมูลจากโดเมนทางการเงินทั้งหมดลงในโมเดลโอเพ่นซอร์ส เนื่องจากคลังข้อมูลการฝึกอบรมมีชุดข้อมูลที่ได้รับการดูแลจัดการทั้งหมดในโดเมน โมเดลผลลัพธ์จึงควรได้รับความรู้เฉพาะทางการเงิน ดังนั้นจึงกลายเป็นโมเดลอเนกประสงค์สำหรับงานทางการเงินต่างๆ ผลลัพธ์ที่ได้คือโมเดล FinPythia
- การฝึกอบรมล่วงหน้าอย่างต่อเนื่องแบบปรับเปลี่ยนงานได้ (TACP) – ผู้เขียนจะฝึกอบรมโมเดลล่วงหน้าเพิ่มเติมเกี่ยวกับข้อมูลงานที่ติดป้ายกำกับและที่ไม่มีป้ายกำกับ เพื่อปรับแต่งให้เหมาะกับงานเฉพาะ ในบางสถานการณ์ นักพัฒนาอาจชอบโมเดลที่ให้ประสิทธิภาพที่ดีกว่าในกลุ่มงานในโดเมนมากกว่าโมเดลทั่วไปในโดเมน TACP ได้รับการออกแบบให้เป็นการฝึกอบรมล่วงหน้าอย่างต่อเนื่องโดยมีเป้าหมายเพื่อเพิ่มประสิทธิภาพในงานเป้าหมาย โดยไม่มีข้อกำหนดสำหรับข้อมูลที่ติดป้ายกำกับ โดยเฉพาะอย่างยิ่ง ผู้เขียนจะฝึกอบรมโมเดลโอเพ่นซอร์สล่วงหน้าบนโทเค็นงานอย่างต่อเนื่อง (โดยไม่มีป้ายกำกับ) ข้อจำกัดหลักของ TACP อยู่ที่การสร้าง LLM เฉพาะงาน แทนที่จะเป็น LLM พื้นฐาน เนื่องจากใช้ข้อมูลงานที่ไม่มีป้ายกำกับสำหรับการฝึกอบรมเพียงอย่างเดียว แม้ว่า DACP จะใช้คลังข้อมูลที่ใหญ่กว่ามาก แต่ก็มีราคาแพงมาก เพื่อสร้างความสมดุลให้กับข้อจำกัดเหล่านี้ ผู้เขียนเสนอแนวทางสองแนวทางที่มีจุดมุ่งหมายเพื่อสร้าง LLM พื้นฐานเฉพาะโดเมน ขณะเดียวกันก็รักษาประสิทธิภาพที่เหนือกว่าในงานเป้าหมาย:
- งานที่มีประสิทธิภาพ-DACP ที่คล้ายกัน (ETS-DACP) – ผู้เขียนเสนอให้เลือกชุดย่อยของคลังข้อมูลทางการเงินที่มีความคล้ายคลึงกับข้อมูลงานอย่างมากโดยใช้ความคล้ายคลึงกันแบบฝัง ส่วนย่อยนี้ใช้สำหรับการฝึกล่วงหน้าอย่างต่อเนื่องเพื่อให้มีประสิทธิภาพมากขึ้น โดยเฉพาะอย่างยิ่ง ผู้เขียนได้ฝึกอบรม LLM แบบโอเพ่นซอร์สล่วงหน้าอย่างต่อเนื่องในคลังข้อมูลขนาดเล็กที่ดึงมาจากคลังข้อมูลทางการเงินที่อยู่ใกล้กับงานเป้าหมายในการจัดจำหน่าย สิ่งนี้สามารถช่วยปรับปรุงประสิทธิภาพของงานได้เนื่องจากเราใช้โมเดลนี้ในการกระจายโทเค็นงาน แม้ว่าจะไม่จำเป็นต้องใช้ข้อมูลที่ติดป้ายกำกับก็ตาม
- DACP ที่ไม่เชื่อเรื่องพระเจ้าสำหรับงานที่มีประสิทธิภาพ (ETA-DACP) – ผู้เขียนเสนอให้ใช้หน่วยเมตริก เช่น ความฉงนสนเท่ห์และเอนโทรปีประเภทโทเค็นที่ไม่ต้องใช้ข้อมูลงานในการเลือกตัวอย่างจากคลังข้อมูลทางการเงินเพื่อการฝึกอบรมล่วงหน้าอย่างต่อเนื่องอย่างมีประสิทธิภาพ แนวทางนี้ได้รับการออกแบบมาเพื่อจัดการกับสถานการณ์ที่ไม่มีข้อมูลงานหรือควรใช้โมเดลโดเมนที่หลากหลายมากกว่าสำหรับโดเมนที่กว้างขึ้น ผู้เขียนใช้สองมิติเพื่อเลือกตัวอย่างข้อมูลที่มีความสำคัญสำหรับการได้รับข้อมูลโดเมนจากชุดย่อยของข้อมูลโดเมนก่อนการฝึกอบรม: ความแปลกใหม่และความหลากหลาย ความแปลกใหม่ วัดจากความฉงนสนเท่ห์ที่บันทึกโดยแบบจำลองเป้าหมาย หมายถึงข้อมูลที่ LLM ไม่เคยเห็นมาก่อน ข้อมูลที่มีความแปลกใหม่สูงบ่งบอกถึงความรู้ใหม่สำหรับ LLM และข้อมูลดังกล่าวถูกมองว่ายากต่อการเรียนรู้ สิ่งนี้จะอัปเดต LLM ทั่วไปที่มีความรู้โดเมนที่เข้มข้นในระหว่างการฝึกอบรมล่วงหน้าอย่างต่อเนื่อง ในทางกลับกัน ความหลากหลายจะรวบรวมความหลากหลายของประเภทโทเค็นในคลังโดเมน ซึ่งได้รับการบันทึกไว้ว่าเป็นคุณลักษณะที่มีประโยชน์ในการวิจัยหลักสูตรการเรียนรู้เกี่ยวกับการสร้างแบบจำลองภาษา
รูปต่อไปนี้เปรียบเทียบตัวอย่างของ ETS-DACP (ซ้าย) กับ ETA-DACP (ขวา)

เราใช้แผนการสุ่มตัวอย่างสองแบบเพื่อเลือกจุดข้อมูลจากคลังข้อมูลทางการเงินที่ได้รับการดูแลจัดการ: การสุ่มตัวอย่างแบบฮาร์ดและการสุ่มตัวอย่างแบบนุ่มนวล แบบแรกเสร็จสิ้นโดยการจัดอันดับคลังข้อมูลทางการเงินก่อนด้วยหน่วยวัดที่เกี่ยวข้อง จากนั้นเลือกตัวอย่าง top-k โดยที่ k ถูกกำหนดไว้ล่วงหน้าตามงบประมาณการฝึกอบรม ในส่วนหลัง ผู้เขียนกำหนดน้ำหนักการสุ่มตัวอย่างสำหรับจุดข้อมูลแต่ละจุดตามค่าเมตริก จากนั้นสุ่มสุ่มตัวอย่าง k จุดข้อมูลเพื่อให้ตรงกับงบประมาณการฝึกอบรม
ผลลัพธ์และการวิเคราะห์
ผู้เขียนประเมินผลลัพธ์ LLM ทางการเงินในงานทางการเงินต่างๆ เพื่อตรวจสอบประสิทธิภาพของการฝึกอบรมล่วงหน้าอย่างต่อเนื่อง:
- ธนาคารวลีทางการเงิน – งานจำแนกความเชื่อมั่นในข่าวการเงิน
- FiQA SA – งานการจำแนกประเภทความรู้สึกตามแง่มุมโดยพิจารณาจากข่าวทางการเงินและหัวข้อข่าว
- พาดหัว – งานการจำแนกประเภทไบนารีว่าหัวข้อข่าวในนิติบุคคลทางการเงินมีข้อมูลบางอย่างหรือไม่
- NER – งานการแยกนิติบุคคลที่มีชื่อทางการเงินตามส่วนการประเมินความเสี่ยงด้านเครดิตของรายงานของ SEC คำในงานนี้จะมีคำอธิบายประกอบด้วย PER, LOC, ORG และ MISC
เนื่องจาก LLM ทางการเงินได้รับการปรับแต่งการสอนอย่างละเอียด ผู้เขียนจึงประเมินแบบจำลองในการตั้งค่า 5 ช็อตสำหรับแต่ละงานเพื่อความคงทน โดยเฉลี่ยแล้ว FinPythia 6.9B มีประสิทธิภาพเหนือกว่า Pythia 6.9B ถึง 10% ในงานทั้ง 1 งาน ซึ่งแสดงให้เห็นถึงประสิทธิภาพของการฝึกอบรมล่วงหน้าอย่างต่อเนื่องเฉพาะโดเมน สำหรับรุ่น 2B การปรับปรุงนั้นลึกซึ้งน้อยกว่า แต่ประสิทธิภาพยังคงดีขึ้นโดยเฉลี่ย XNUMX%
รูปต่อไปนี้แสดงให้เห็นถึงความแตกต่างด้านประสิทธิภาพก่อนและหลัง DACP ในทั้งสองรุ่น

รูปต่อไปนี้แสดงตัวอย่างเชิงคุณภาพสองตัวอย่างที่สร้างโดย Pythia 6.9B และ FinPythia 6.9B สำหรับคำถามสองข้อที่เกี่ยวข้องกับการเงินเกี่ยวกับผู้จัดการนักลงทุนและข้อกำหนดทางการเงิน Pythia 6.9B จะไม่เข้าใจคำศัพท์หรือรู้จักชื่อ ในขณะที่ FinPythia 6.9B จะให้คำตอบโดยละเอียดอย่างถูกต้อง ตัวอย่างเชิงคุณภาพแสดงให้เห็นว่าการฝึกอบรมล่วงหน้าอย่างต่อเนื่องช่วยให้ LLM ได้รับความรู้โดเมนในระหว่างกระบวนการ

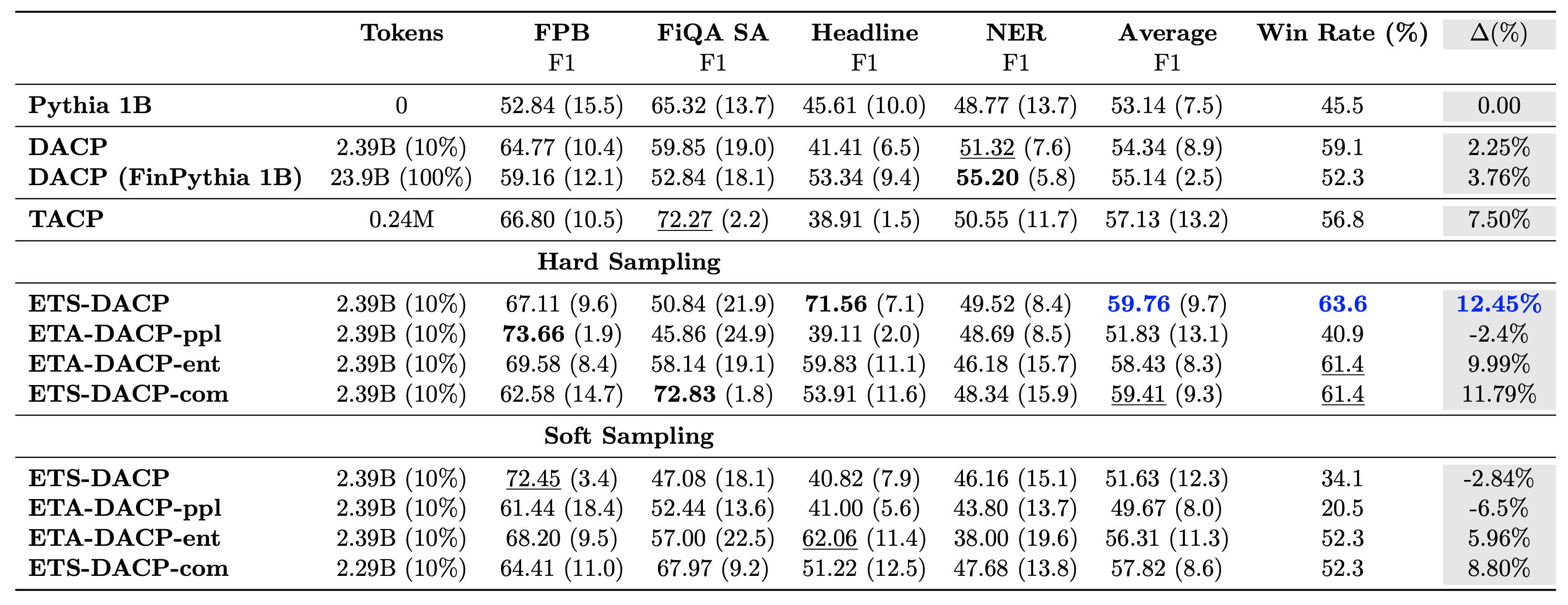
ตารางต่อไปนี้เปรียบเทียบแนวทางการฝึกอบรมล่วงหน้าอย่างต่อเนื่องที่มีประสิทธิภาพต่างๆ ETA-DACP-ppl คือ ETA-DACP ขึ้นอยู่กับความฉงนสนเท่ห์ (ความแปลกใหม่) และ ETA-DACP-ent ขึ้นอยู่กับเอนโทรปี (ความหลากหลาย) ETS-DACP-com มีความคล้ายคลึงกับ DACP โดยมีการเลือกข้อมูลโดยการเฉลี่ยเมตริกทั้งสาม ต่อไปนี้เป็นประเด็นเล็กๆ น้อยๆ จากผลลัพธ์:
- วิธีการเลือกข้อมูลมีประสิทธิภาพ – เหนือกว่าการฝึกอบรมล่วงหน้าต่อเนื่องมาตรฐานด้วยข้อมูลการฝึกอบรมเพียง 10% การฝึกอบรมล่วงหน้าอย่างต่อเนื่องที่มีประสิทธิภาพ รวมถึง Task-Similar DACP (ETS-DACP), Task-Agnostic DACP ที่ยึดตามเอนโทรปี (ESA-DACP-ent) และ Task-Similar DACP ที่ยึดตามตัวชี้วัดทั้งสาม (ETS-DACP-com) มีประสิทธิภาพเหนือกว่า DACP มาตรฐาน โดยเฉลี่ยแล้วแม้ว่าพวกเขาจะได้รับการฝึกอบรมเพียง 10% ของคลังข้อมูลทางการเงินก็ตาม
- การเลือกข้อมูลที่คำนึงถึงงานจะทำงานได้ดีที่สุดตามการวิจัยโมเดลภาษาขนาดเล็ก – ETS-DACP บันทึกประสิทธิภาพเฉลี่ยที่ดีที่สุดในบรรดาวิธีการทั้งหมด และบันทึกประสิทธิภาพงานที่ดีที่สุดเป็นอันดับสองตามตัวชี้วัดทั้งสาม สิ่งนี้ชี้ให้เห็นว่าการใช้ข้อมูลงานที่ไม่มีป้ายกำกับยังคงเป็นแนวทางที่มีประสิทธิภาพในการเพิ่มประสิทธิภาพงานในกรณีของ LLM
- การเลือกข้อมูลที่ไม่เชื่อเรื่องงานนั้นใกล้เคียงกัน – ESA-DACP-ent ติดตามประสิทธิภาพของแนวทางการเลือกข้อมูลที่คำนึงถึงงาน ซึ่งหมายความว่าเรายังคงสามารถเพิ่มประสิทธิภาพงานได้โดยการเลือกตัวอย่างคุณภาพสูงที่ไม่เชื่อมโยงกับงานเฉพาะ นี่เป็นการปูทางไปสู่การสร้าง LLM ทางการเงินสำหรับทั้งโดเมนในขณะที่บรรลุผลการปฏิบัติงานที่เหนือกว่า
คำถามสำคัญประการหนึ่งเกี่ยวกับการฝึกอบรมล่วงหน้าอย่างต่อเนื่องคือ จะส่งผลเสียต่อประสิทธิภาพการทำงานที่ไม่ใช่โดเมนหรือไม่ ผู้เขียนยังประเมินแบบจำลองที่ได้รับการฝึกอบรมล่วงหน้าอย่างต่อเนื่องในงานทั่วไปสี่งานที่ใช้กันอย่างแพร่หลาย ได้แก่ ARC, MMLU, TruthQA และ HellaSwag ซึ่งวัดความสามารถในการตอบคำถาม การใช้เหตุผล และความสมบูรณ์ ผู้เขียนพบว่าการฝึกอบรมล่วงหน้าอย่างต่อเนื่องไม่ส่งผลเสียต่อประสิทธิภาพการทำงานที่ไม่ใช่โดเมน สำหรับรายละเอียดเพิ่มเติม โปรดดูที่ การฝึกอบรมล่วงหน้าอย่างต่อเนื่องอย่างมีประสิทธิภาพสำหรับการสร้างโมเดลภาษาขนาดใหญ่เฉพาะโดเมน.
สรุป
โพสต์นี้นำเสนอข้อมูลเชิงลึกเกี่ยวกับการรวบรวมข้อมูลและกลยุทธ์การฝึกอบรมล่วงหน้าอย่างต่อเนื่องสำหรับการฝึกอบรม LLM สำหรับโดเมนทางการเงิน คุณสามารถเริ่มฝึกอบรม LLM ของคุณเองสำหรับงานทางการเงินได้ การฝึกอบรม Amazon SageMaker or อเมซอน เบดร็อค ในวันนี้
เกี่ยวกับผู้เขียน
 หย่งซี เป็นนักวิทยาศาสตร์ประยุกต์ใน Amazon FinTech เขามุ่งเน้นไปที่การพัฒนาโมเดลภาษาขนาดใหญ่และแอปพลิเคชัน Generative AI สำหรับการเงิน
หย่งซี เป็นนักวิทยาศาสตร์ประยุกต์ใน Amazon FinTech เขามุ่งเน้นไปที่การพัฒนาโมเดลภาษาขนาดใหญ่และแอปพลิเคชัน Generative AI สำหรับการเงิน
 คารัน อัคการ์วาล เป็นนักวิทยาศาสตร์ประยุกต์อาวุโสของ Amazon FinTech โดยมุ่งเน้นที่ Generative AI สำหรับการใช้งานทางการเงิน Karan มีประสบการณ์กว้างขวางในด้านการวิเคราะห์อนุกรมเวลาและ NLP โดยมีความสนใจเป็นพิเศษในการเรียนรู้จากข้อมูลที่มีป้ายกำกับอย่างจำกัด
คารัน อัคการ์วาล เป็นนักวิทยาศาสตร์ประยุกต์อาวุโสของ Amazon FinTech โดยมุ่งเน้นที่ Generative AI สำหรับการใช้งานทางการเงิน Karan มีประสบการณ์กว้างขวางในด้านการวิเคราะห์อนุกรมเวลาและ NLP โดยมีความสนใจเป็นพิเศษในการเรียนรู้จากข้อมูลที่มีป้ายกำกับอย่างจำกัด
 ไอทซาซ อาหมัด เป็นผู้จัดการวิทยาศาสตร์ประยุกต์ที่ Amazon ซึ่งเขาเป็นผู้นำทีมนักวิทยาศาสตร์ที่สร้างแอปพลิเคชันต่างๆ ของ Machine Learning และ Generative AI ในด้านการเงิน งานวิจัยของเขามีความสนใจใน NLP, Generative AI และ LLM Agents เขาได้รับปริญญาเอกสาขาวิศวกรรมไฟฟ้าจากมหาวิทยาลัย Texas A&M
ไอทซาซ อาหมัด เป็นผู้จัดการวิทยาศาสตร์ประยุกต์ที่ Amazon ซึ่งเขาเป็นผู้นำทีมนักวิทยาศาสตร์ที่สร้างแอปพลิเคชันต่างๆ ของ Machine Learning และ Generative AI ในด้านการเงิน งานวิจัยของเขามีความสนใจใน NLP, Generative AI และ LLM Agents เขาได้รับปริญญาเอกสาขาวิศวกรรมไฟฟ้าจากมหาวิทยาลัย Texas A&M
 ชิงเหว่ย ลี่ เป็นผู้เชี่ยวชาญด้าน Machine Learning ที่ Amazon Web Services เขาได้รับปริญญาเอก ในการวิจัยปฏิบัติการหลังจากที่เขาทำลายบัญชีทุนวิจัยของที่ปรึกษาและไม่ได้รับรางวัลโนเบลตามที่เขาสัญญาไว้ ปัจจุบันเขาช่วยลูกค้าในบริการทางการเงินสร้างโซลูชันการเรียนรู้ของเครื่องบน AWS
ชิงเหว่ย ลี่ เป็นผู้เชี่ยวชาญด้าน Machine Learning ที่ Amazon Web Services เขาได้รับปริญญาเอก ในการวิจัยปฏิบัติการหลังจากที่เขาทำลายบัญชีทุนวิจัยของที่ปรึกษาและไม่ได้รับรางวัลโนเบลตามที่เขาสัญญาไว้ ปัจจุบันเขาช่วยลูกค้าในบริการทางการเงินสร้างโซลูชันการเรียนรู้ของเครื่องบน AWS
 ราห์เวนเดอร์ อาร์นี เป็นผู้นำทีม Customer Acceleration (CAT) ภายใน AWS Industries CAT เป็นทีมงานข้ามสายงานระดับโลกซึ่งประกอบด้วยสถาปนิกระบบคลาวด์ วิศวกรซอฟต์แวร์ นักวิทยาศาสตร์ข้อมูล ผู้เชี่ยวชาญด้าน AI/ML และนักออกแบบที่พบปะกับลูกค้า ซึ่งขับเคลื่อนนวัตกรรมผ่านการสร้างต้นแบบขั้นสูง และขับเคลื่อนความเป็นเลิศในการปฏิบัติงานบนระบบคลาวด์ผ่านความเชี่ยวชาญด้านเทคนิคเฉพาะทาง
ราห์เวนเดอร์ อาร์นี เป็นผู้นำทีม Customer Acceleration (CAT) ภายใน AWS Industries CAT เป็นทีมงานข้ามสายงานระดับโลกซึ่งประกอบด้วยสถาปนิกระบบคลาวด์ วิศวกรซอฟต์แวร์ นักวิทยาศาสตร์ข้อมูล ผู้เชี่ยวชาญด้าน AI/ML และนักออกแบบที่พบปะกับลูกค้า ซึ่งขับเคลื่อนนวัตกรรมผ่านการสร้างต้นแบบขั้นสูง และขับเคลื่อนความเป็นเลิศในการปฏิบัติงานบนระบบคลาวด์ผ่านความเชี่ยวชาญด้านเทคนิคเฉพาะทาง
- เนื้อหาที่ขับเคลื่อนด้วย SEO และการเผยแพร่ประชาสัมพันธ์ รับการขยายวันนี้
- PlatoData.Network Vertical Generative Ai เพิ่มพลังให้กับตัวเอง เข้าถึงได้ที่นี่.
- เพลโตไอสตรีม. Web3 อัจฉริยะ ขยายความรู้ เข้าถึงได้ที่นี่.
- เพลโตESG. คาร์บอน, คลีนเทค, พลังงาน, สิ่งแวดล้อม แสงอาทิตย์, การจัดการของเสีย. เข้าถึงได้ที่นี่.
- เพลโตสุขภาพ เทคโนโลยีชีวภาพและข่าวกรองการทดลองทางคลินิก เข้าถึงได้ที่นี่.
- ที่มา: https://aws.amazon.com/blogs/machine-learning/efficient-continual-pre-training-llms-for-financial-domains/

