สตูดิโอ Amazon SageMaker มอบโซลูชันที่มีการจัดการเต็มรูปแบบสำหรับนักวิทยาศาสตร์ข้อมูลเพื่อสร้าง ฝึกอบรม และปรับใช้โมเดลการเรียนรู้ของเครื่อง (ML) แบบโต้ตอบ ในกระบวนการทำงานด้าน ML นักวิทยาศาสตร์ข้อมูลมักจะเริ่มขั้นตอนการทำงานโดยการค้นหาแหล่งข้อมูลที่เกี่ยวข้องและเชื่อมต่อกับแหล่งข้อมูลเหล่านั้น จากนั้นพวกเขาใช้ SQL เพื่อสำรวจ วิเคราะห์ แสดงภาพ และบูรณาการข้อมูลจากแหล่งต่างๆ ก่อนที่จะนำไปใช้ในการฝึกอบรมและการอนุมาน ML ก่อนหน้านี้ นักวิทยาศาสตร์ด้านข้อมูลมักพบว่าตัวเองกำลังใช้เครื่องมือหลายอย่างเพื่อรองรับ SQL ในขั้นตอนการทำงาน ซึ่งเป็นอุปสรรคต่อประสิทธิภาพการทำงาน
เรารู้สึกตื่นเต้นที่จะประกาศว่าสมุดบันทึก JupyterLab ใน SageMaker Studio มาพร้อมกับการรองรับ SQL ในตัว นักวิทยาศาสตร์ข้อมูลสามารถ:
- เชื่อมต่อกับบริการข้อมูลยอดนิยมได้แก่ อเมซอน อาเธน่า, อเมซอน Redshift, อเมซอน ดาต้าโซนและ Snowflake โดยตรงภายในสมุดบันทึก
- เรียกดูและค้นหาฐานข้อมูล สคีมา ตาราง และมุมมอง และดูตัวอย่างข้อมูลภายในอินเทอร์เฟซโน้ตบุ๊ก
- ผสมโค้ด SQL และ Python ในสมุดบันทึกเดียวกันเพื่อการสำรวจและการแปลงข้อมูลเพื่อใช้ในโปรเจ็กต์ ML อย่างมีประสิทธิภาพ
- ใช้คุณสมบัติการผลิตของนักพัฒนา เช่น การเติมคำสั่ง SQL ให้สมบูรณ์ ความช่วยเหลือในการจัดรูปแบบโค้ด และการเน้นไวยากรณ์ เพื่อช่วยเร่งการพัฒนาโค้ดและปรับปรุงประสิทธิภาพการทำงานของนักพัฒนาโดยรวม
นอกจากนี้ ผู้ดูแลระบบยังสามารถจัดการการเชื่อมต่อกับบริการข้อมูลเหล่านี้ได้อย่างปลอดภัย ช่วยให้นักวิทยาศาสตร์ข้อมูลสามารถเข้าถึงข้อมูลที่ได้รับอนุญาตโดยไม่จำเป็นต้องจัดการข้อมูลประจำตัวด้วยตนเอง
ในโพสต์นี้ เราจะแนะนำคุณตลอดการตั้งค่าฟีเจอร์นี้ใน SageMaker Studio และแนะนำความสามารถต่างๆ ของฟีเจอร์นี้ให้คุณทราบ จากนั้น เราจะแสดงวิธีที่คุณสามารถปรับปรุงประสบการณ์ SQL ในโน้ตบุ๊กโดยใช้ความสามารถ Text-to-SQL ที่ได้รับจากโมเดลภาษาขนาดใหญ่ขั้นสูง (LLM) เพื่อเขียนคำสั่ง SQL ที่ซับซ้อนโดยใช้ข้อความภาษาธรรมชาติเป็นอินพุต สุดท้าย เพื่อให้ผู้ใช้ในวงกว้างสามารถสร้างแบบสอบถาม SQL จากการป้อนข้อมูลภาษาธรรมชาติในสมุดบันทึกของพวกเขา เราจะแสดงวิธีปรับใช้โมเดล Text-to-SQL เหล่านี้โดยใช้ อเมซอน SageMaker ปลายทาง
ภาพรวมโซลูชัน
ด้วยการผสานรวม SQL ของสมุดบันทึก SageMaker Studio JupyterLab คุณสามารถเชื่อมต่อกับแหล่งข้อมูลยอดนิยม เช่น Snowflake, Athena, Amazon Redshift และ Amazon DataZone ได้แล้ว คุณสมบัติใหม่นี้ช่วยให้คุณสามารถทำหน้าที่ต่างๆ ได้
ตัวอย่างเช่น คุณสามารถสำรวจแหล่งข้อมูล เช่น ฐานข้อมูล ตาราง และสคีมาได้โดยตรงจากระบบนิเวศ JupyterLab ของคุณ หากสภาพแวดล้อมโน้ตบุ๊กของคุณทำงานบน SageMaker Distribution 1.6 หรือสูงกว่า ให้มองหาวิดเจ็ตใหม่ทางด้านซ้ายของอินเทอร์เฟซ JupyterLab การเพิ่มนี้ช่วยเพิ่มการเข้าถึงข้อมูลและการจัดการภายในสภาพแวดล้อมการพัฒนาของคุณ
หากคุณไม่ได้อยู่ใน SageMaker Distribution ที่แนะนำ (1.5 หรือต่ำกว่า) หรือในสภาพแวดล้อมที่กำหนดเอง โปรดดูข้อมูลเพิ่มเติมในภาคผนวก
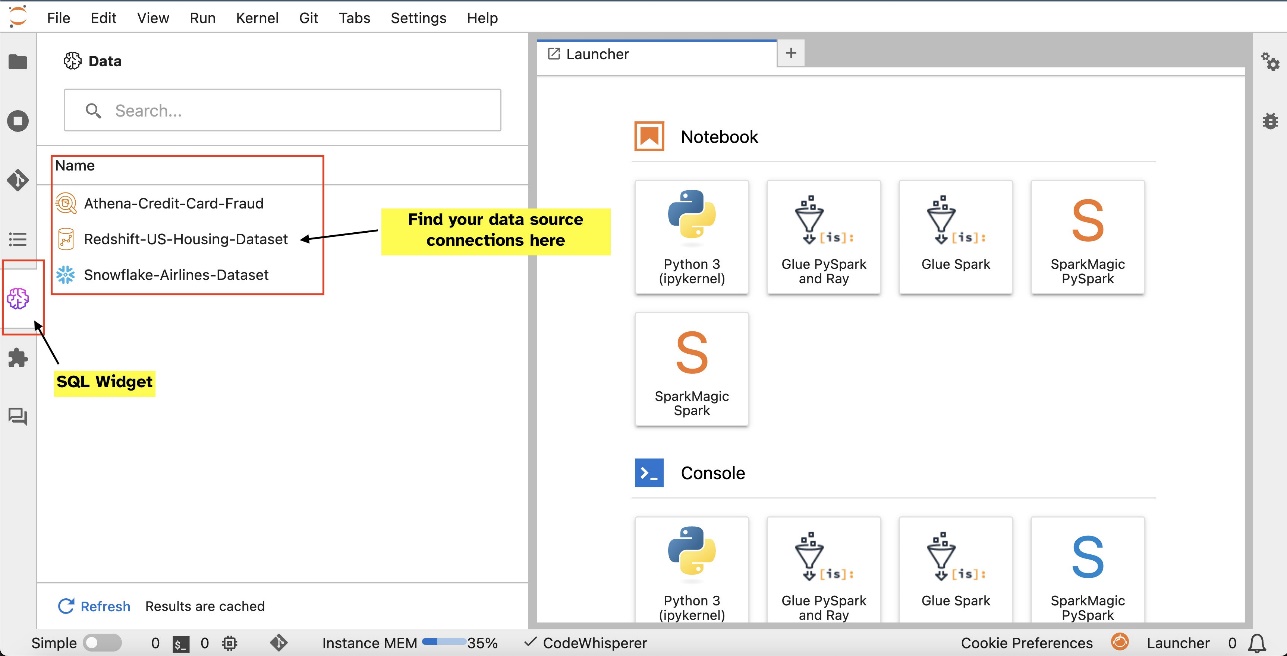
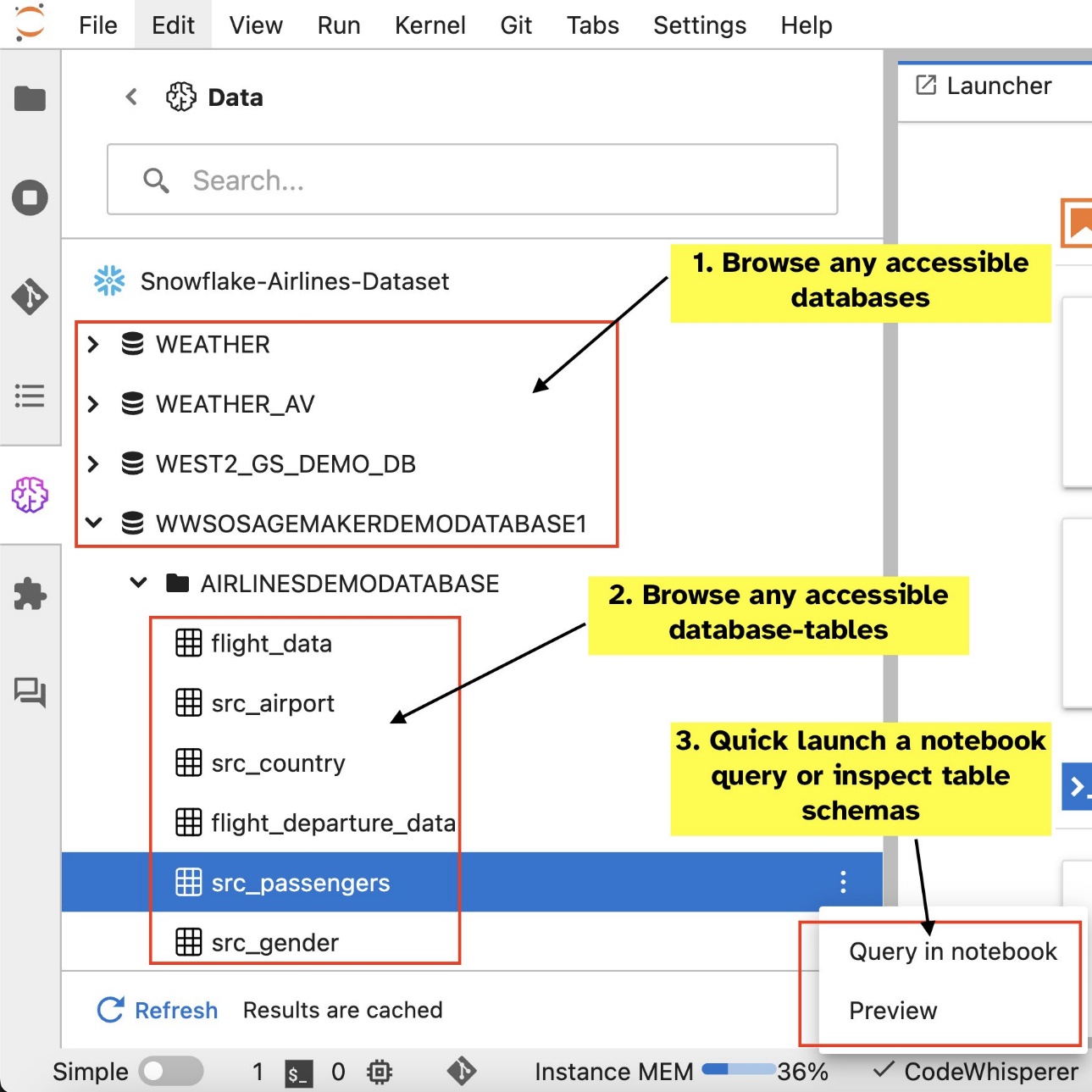
หลังจากที่คุณตั้งค่าการเชื่อมต่อแล้ว (ดังภาพประกอบในส่วนถัดไป) คุณสามารถแสดงรายการการเชื่อมต่อข้อมูล เรียกดูฐานข้อมูลและตาราง และตรวจสอบสคีมาได้
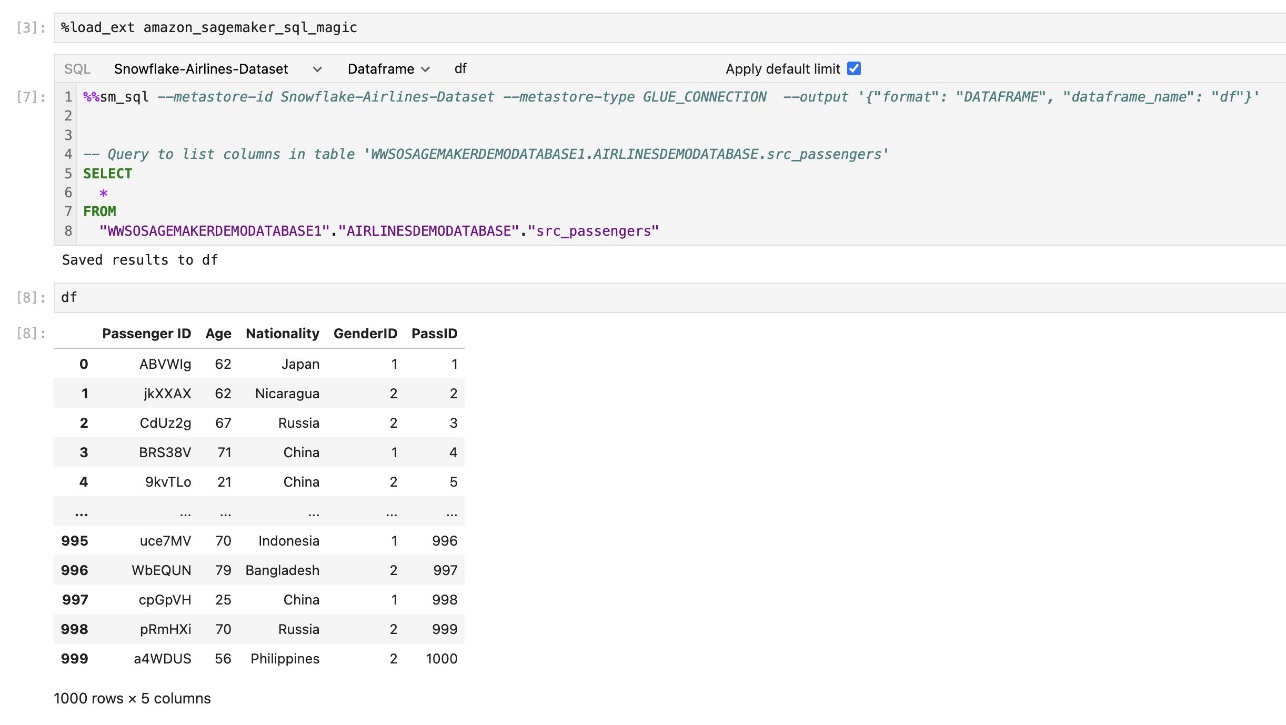
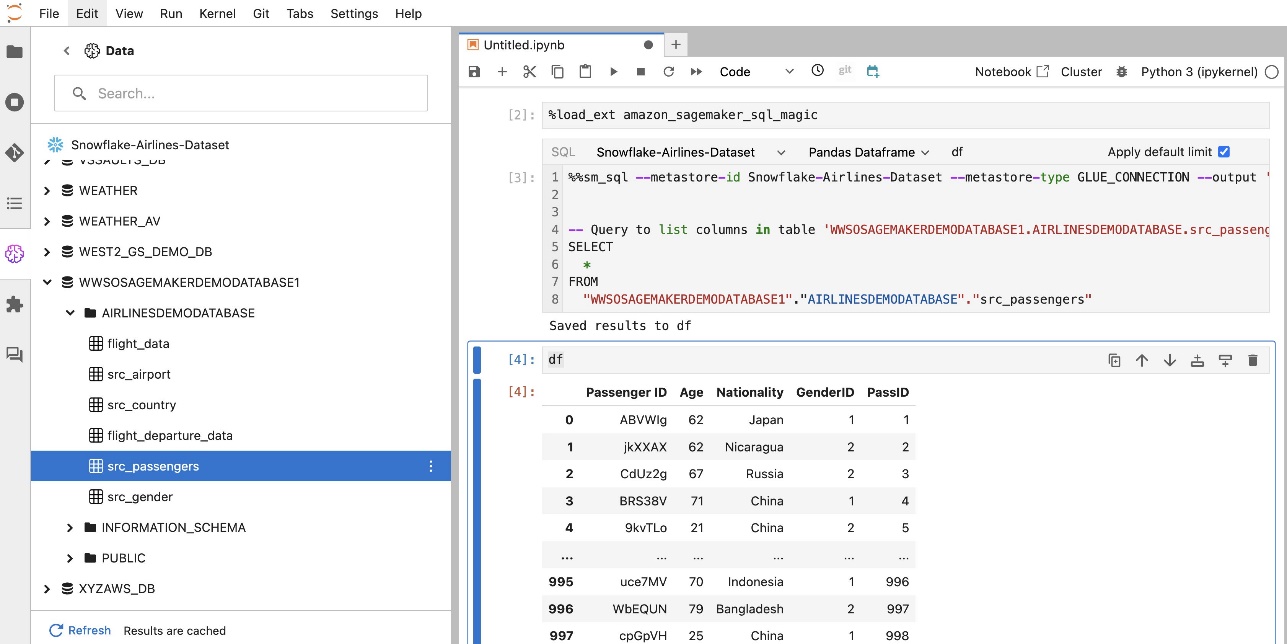
ส่วนขยาย SQL ในตัวของ SageMaker Studio JupyterLab ยังช่วยให้คุณสามารถเรียกใช้คำสั่ง SQL ได้โดยตรงจากโน้ตบุ๊ก สมุดบันทึก Jupyter สามารถแยกความแตกต่างระหว่างโค้ด SQL และ Python ได้โดยใช้ %%sm_sql คำสั่งเวทย์มนตร์ซึ่งจะต้องวางไว้ที่ด้านบนของเซลล์ใด ๆ ที่มีโค้ด SQL คำสั่งนี้จะส่งสัญญาณไปยัง JupyterLab ว่าคำแนะนำต่อไปนี้เป็นคำสั่ง SQL แทนที่จะเป็นรหัส Python ผลลัพธ์ของการสืบค้นสามารถแสดงผลได้โดยตรงภายในสมุดบันทึก ช่วยให้สามารถรวมเวิร์กโฟลว์ SQL และ Python ในการวิเคราะห์ข้อมูลของคุณได้อย่างราบรื่น
ผลลัพธ์ของแบบสอบถามสามารถแสดงเป็นภาพเป็นตาราง HTML ดังที่แสดงในภาพหน้าจอต่อไปนี้

นอกจากนี้ยังสามารถเขียนถึงก DataFrame ของแพนด้า.
เบื้องต้น
ตรวจสอบให้แน่ใจว่าคุณได้ปฏิบัติตามข้อกำหนดเบื้องต้นต่อไปนี้เพื่อใช้ประสบการณ์ SQL ของสมุดบันทึก SageMaker Studio:
- SageMaker สตูดิโอ V2 – ตรวจสอบให้แน่ใจว่าคุณใช้เวอร์ชันล่าสุดของคุณ โดเมน SageMaker Studio และโปรไฟล์ผู้ใช้- หากคุณใช้ SageMaker Studio Classic อยู่ โปรดดูที่ การย้ายข้อมูลจาก Amazon SageMaker Studio Classic.
- บทบาท IAM – SageMaker จำเป็นต้องมี AWS Identity และการจัดการการเข้าถึง บทบาท (IAM) ที่จะกำหนดให้กับโดเมน SageMaker Studio หรือโปรไฟล์ผู้ใช้เพื่อจัดการสิทธิ์อย่างมีประสิทธิภาพ อาจจำเป็นต้องมีการอัปเดตบทบาทการดำเนินการเพื่อนำเข้าการเรียกดูข้อมูลและคุณสมบัติการรัน SQL นโยบายตัวอย่างต่อไปนี้ช่วยให้ผู้ใช้สามารถอนุญาต แสดงรายการ และเรียกใช้ได้ AWS กาว, เอเธน่า, บริการจัดเก็บข้อมูลอย่างง่ายของ Amazon (อเมซอน เอส3) ผู้จัดการความลับของ AWSและทรัพยากรของ Amazon RedShift:
- จูปิเตอร์แล็บ สเปซ – คุณต้องเข้าถึง SageMaker Studio และ JupyterLab Space ที่อัปเดตด้วย การกระจาย SageMaker เวอร์ชันอิมเมจเวอร์ชัน v1.6 หรือใหม่กว่า หากคุณใช้อิมเมจที่กำหนดเองสำหรับ JupyterLab Spaces หรือ SageMaker Distribution เวอร์ชันเก่า (v1.5 หรือต่ำกว่า) โปรดดูภาคผนวกเพื่อดูคำแนะนำในการติดตั้งแพ็คเกจและโมดูลที่จำเป็นเพื่อเปิดใช้งานคุณสมบัตินี้ในสภาพแวดล้อมของคุณ หากต้องการเรียนรู้เพิ่มเติมเกี่ยวกับ SageMaker Studio JupyterLab Spaces โปรดดูที่ เพิ่มประสิทธิภาพการทำงานบน Amazon SageMaker Studio: ขอแนะนำ JupyterLab Spaces และเครื่องมือ AI เชิงสร้างสรรค์.
- ข้อมูลรับรองการเข้าถึงแหล่งข้อมูล – คุณสมบัติสมุดบันทึก SageMaker Studio นี้ต้องการชื่อผู้ใช้และรหัสผ่านในการเข้าถึงแหล่งข้อมูล เช่น Snowflake และ Amazon Redshift สร้างชื่อผู้ใช้และการเข้าถึงตามรหัสผ่านสำหรับแหล่งข้อมูลเหล่านี้ หากคุณยังไม่มี การเข้าถึง Snowflake โดยใช้ OAuth ไม่ได้รับการสนับสนุนในขณะที่เขียนบทความนี้
- โหลดเวทมนตร์ SQL – ก่อนที่คุณจะเรียกใช้การสืบค้น SQL จากเซลล์สมุดบันทึก Jupyter จำเป็นต้องโหลดส่วนขยาย SQL magics ใช้คำสั่ง
%load_ext amazon_sagemaker_sql_magicเพื่อเปิดใช้งานคุณสมบัตินี้ นอกจากนี้ คุณยังสามารถเรียกใช้ไฟล์%sm_sql?คำสั่งเพื่อดูรายการตัวเลือกที่รองรับสำหรับการสืบค้นจากเซลล์ SQL ตัวเลือกเหล่านี้รวมถึงการตั้งค่าขีดจำกัดการสืบค้นเริ่มต้นที่ 1,000 การเรียกใช้การแยกข้อมูลแบบเต็ม และการแทรกพารามิเตอร์การสืบค้น และอื่นๆ การตั้งค่านี้ช่วยให้สามารถจัดการข้อมูล SQL ที่ยืดหยุ่นและมีประสิทธิภาพได้โดยตรงภายในสภาพแวดล้อมโน้ตบุ๊กของคุณ
สร้างการเชื่อมต่อฐานข้อมูล
ความสามารถในการเรียกดูและดำเนินการ SQL ในตัวของ SageMaker Studio ได้รับการปรับปรุงโดยการเชื่อมต่อ AWS Glue การเชื่อมต่อ AWS Glue คือออบเจ็กต์ AWS Glue Data Catalog ที่จัดเก็บข้อมูลที่จำเป็น เช่น ข้อมูลรับรองการเข้าสู่ระบบ สตริง URI และข้อมูล Virtual Private Cloud (VPC) สำหรับการจัดเก็บข้อมูลเฉพาะ การเชื่อมต่อเหล่านี้ถูกใช้โดยโปรแกรมรวบรวมข้อมูล AWS Glue งาน และตำแหน่งข้อมูลการพัฒนาเพื่อเข้าถึงที่เก็บข้อมูลประเภทต่างๆ คุณสามารถใช้การเชื่อมต่อเหล่านี้สำหรับทั้งข้อมูลต้นทางและเป้าหมาย และแม้แต่ใช้การเชื่อมต่อเดียวกันซ้ำกับโปรแกรมรวบรวมข้อมูลหลายตัวหรืองานแยก แปลง และโหลด (ETL)
หากต้องการสำรวจแหล่งข้อมูล SQL ในบานหน้าต่างด้านซ้ายของ SageMaker Studio คุณต้องสร้างอ็อบเจ็กต์การเชื่อมต่อ AWS Glue ก่อน การเชื่อมต่อเหล่านี้อำนวยความสะดวกในการเข้าถึงแหล่งข้อมูลต่างๆ และช่วยให้คุณสามารถสำรวจองค์ประกอบข้อมูลแผนผังได้
ในส่วนต่อไปนี้ เราจะอธิบายขั้นตอนการสร้างตัวเชื่อมต่อ AWS Glue เฉพาะ SQL สิ่งนี้จะช่วยให้คุณเข้าถึง ดู และสำรวจชุดข้อมูลในที่เก็บข้อมูลที่หลากหลาย สำหรับข้อมูลโดยละเอียดเพิ่มเติมเกี่ยวกับการเชื่อมต่อ AWS Glue โปรดดูที่ การเชื่อมต่อกับข้อมูล.
สร้างการเชื่อมต่อ AWS Glue
วิธีเดียวที่จะนำแหล่งข้อมูลมาสู่ SageMaker Studio คือใช้การเชื่อมต่อ AWS Glue คุณต้องสร้างการเชื่อมต่อ AWS Glue ด้วยประเภทการเชื่อมต่อเฉพาะ ในขณะที่เขียนบทความนี้ กลไกเดียวที่ได้รับการสนับสนุนในการสร้างการเชื่อมต่อเหล่านี้คือการใช้ อินเทอร์เฟซบรรทัดคำสั่ง AWS AWS (AWS CLI)
ไฟล์ JSON คำจำกัดความของการเชื่อมต่อ
เมื่อเชื่อมต่อกับแหล่งข้อมูลที่แตกต่างกันใน AWS Glue คุณต้องสร้างไฟล์ JSON ที่กำหนดคุณสมบัติการเชื่อมต่อก่อน ซึ่งเรียกว่า ไฟล์คำจำกัดความการเชื่อมต่อ- ไฟล์นี้มีความสำคัญอย่างยิ่งต่อการสร้างการเชื่อมต่อ AWS Glue และควรมีรายละเอียดการกำหนดค่าที่จำเป็นทั้งหมดสำหรับการเข้าถึงแหล่งข้อมูล สำหรับแนวทางปฏิบัติที่ดีที่สุดด้านความปลอดภัย ขอแนะนำให้ใช้ Secrets Manager เพื่อจัดเก็บข้อมูลที่ละเอียดอ่อน เช่น รหัสผ่าน ไว้อย่างปลอดภัย ในขณะเดียวกัน คุณสมบัติการเชื่อมต่ออื่นๆ สามารถจัดการได้โดยตรงผ่านการเชื่อมต่อ AWS Glue วิธีการนี้ช่วยให้แน่ใจว่าข้อมูลประจำตัวที่ละเอียดอ่อนได้รับการปกป้อง ในขณะที่ยังคงทำให้การกำหนดค่าการเชื่อมต่อสามารถเข้าถึงและจัดการได้
ต่อไปนี้เป็นตัวอย่างของคำจำกัดความการเชื่อมต่อ JSON:
เมื่อตั้งค่าการเชื่อมต่อ AWS Glue สำหรับแหล่งข้อมูลของคุณ มีหลักเกณฑ์สำคัญบางประการที่ต้องปฏิบัติตามเพื่อให้ทั้งฟังก์ชันการทำงานและความปลอดภัย:
- การทำให้คุณสมบัติเป็นสตริง - ภายใน
PythonPropertiesสำคัญ ตรวจสอบให้แน่ใจว่าคุณสมบัติทั้งหมดเป็น คู่คีย์-ค่าแบบสตริง- จำเป็นอย่างยิ่งที่จะต้องหลีกเลี่ยงเครื่องหมายคำพูดคู่อย่างถูกต้องโดยใช้อักขระแบ็กสแลช () เมื่อจำเป็น ซึ่งจะช่วยรักษารูปแบบที่ถูกต้องและหลีกเลี่ยงข้อผิดพลาดทางไวยากรณ์ใน JSON ของคุณ - การจัดการข้อมูลที่ละเอียดอ่อน – แม้ว่าจะสามารถรวมคุณสมบัติการเชื่อมต่อทั้งหมดไว้ภายในได้
PythonPropertiesไม่แนะนำให้รวมรายละเอียดที่ละเอียดอ่อน เช่น รหัสผ่าน ไว้ในคุณสมบัติเหล่านี้โดยตรง ให้ใช้ Secrets Manager เพื่อจัดการข้อมูลที่ละเอียดอ่อนแทน วิธีการนี้จะรักษาความปลอดภัยข้อมูลที่ละเอียดอ่อนของคุณโดยจัดเก็บไว้ในสภาพแวดล้อมที่มีการควบคุมและเข้ารหัส ห่างจากไฟล์การกำหนดค่าหลัก
สร้างการเชื่อมต่อ AWS Glue โดยใช้ AWS CLI
หลังจากที่คุณรวมฟิลด์ที่จำเป็นทั้งหมดในไฟล์ JSON ข้อกำหนดการเชื่อมต่อของคุณแล้ว คุณก็พร้อมที่จะสร้างการเชื่อมต่อ AWS Glue สำหรับแหล่งข้อมูลของคุณโดยใช้ AWS CLI และคำสั่งต่อไปนี้:
คำสั่งนี้เริ่มต้นการเชื่อมต่อ AWS Glue ใหม่ตามข้อกำหนดรายละเอียดในไฟล์ JSON ของคุณ ต่อไปนี้เป็นการแจกแจงส่วนประกอบคำสั่งโดยย่อ:
- -ภูมิภาค – นี่เป็นการระบุภูมิภาค AWS ที่จะสร้างการเชื่อมต่อ AWS Glue ของคุณ การเลือกภูมิภาคที่มีแหล่งข้อมูลและบริการอื่น ๆ ของคุณตั้งอยู่เป็นสิ่งสำคัญอย่างยิ่ง เพื่อลดเวลาแฝงและปฏิบัติตามข้อกำหนดด้านถิ่นที่อยู่ของข้อมูล
- –ไฟล์ cli-input-json:///path/to/file/connection/definition/file.json – พารามิเตอร์นี้สั่งให้ AWS CLI อ่านการกำหนดค่าอินพุตจากไฟล์ในเครื่องที่มีข้อกำหนดการเชื่อมต่อของคุณในรูปแบบ JSON
คุณควรจะสามารถสร้างการเชื่อมต่อ AWS Glue ด้วยคำสั่ง AWS CLI ก่อนหน้าจากเทอร์มินัล Studio JupyterLab ของคุณ บน เนื้อไม่มีมัน เมนูให้เลือก ใหม่ และ สถานีปลายทาง.

ถ้า create-connection คำสั่งทำงานได้สำเร็จ คุณควรเห็นแหล่งข้อมูลของคุณแสดงอยู่ในบานหน้าต่างเบราว์เซอร์ SQL หากคุณไม่เห็นแหล่งข้อมูลของคุณในรายการ ให้เลือก รีเฟรช เพื่ออัพเดตแคช

สร้างการเชื่อมต่อเกล็ดหิมะ
ในส่วนนี้ เรามุ่งเน้นไปที่การรวมแหล่งข้อมูล Snowflake เข้ากับ SageMaker Studio การสร้างบัญชี Snowflake ฐานข้อมูล และคลังสินค้าอยู่นอกเหนือขอบเขตของโพสต์นี้ หากต้องการเริ่มต้นใช้งาน Snowflake โปรดดูที่ คู่มือผู้ใช้สโนว์เฟลก- ในโพสต์นี้ เรามุ่งเน้นที่การสร้างไฟล์ JSON ที่กำหนด Snowflake และสร้างการเชื่อมต่อแหล่งข้อมูล Snowflake โดยใช้ AWS Glue
สร้างข้อมูลลับของ Secrets Manager
คุณสามารถเชื่อมต่อกับบัญชี Snowflake ของคุณได้โดยใช้ ID ผู้ใช้และรหัสผ่านหรือใช้คีย์ส่วนตัว หากต้องการเชื่อมต่อกับ ID ผู้ใช้และรหัสผ่าน คุณต้องจัดเก็บข้อมูลประจำตัวของคุณอย่างปลอดภัยในตัวจัดการความลับ ตามที่กล่าวไว้ก่อนหน้านี้ แม้ว่าจะสามารถฝังข้อมูลนี้ภายใต้ PythonProperties ได้ แต่ไม่แนะนำให้จัดเก็บข้อมูลที่ละเอียดอ่อนในรูปแบบข้อความธรรมดา ตรวจสอบให้แน่ใจว่าข้อมูลที่ละเอียดอ่อนได้รับการจัดการอย่างปลอดภัยเสมอเพื่อหลีกเลี่ยงความเสี่ยงด้านความปลอดภัยที่อาจเกิดขึ้น
หากต้องการเก็บข้อมูลใน Secrets Manager ให้ทำตามขั้นตอนต่อไปนี้:
- บนคอนโซล Secrets Manager ให้เลือก เก็บความลับใหม่.
- สำหรับ ประเภทลับเลือก ความลับอีกประเภทหนึ่ง.
- สำหรับคู่คีย์-ค่า ให้เลือก ข้อความธรรมดา และป้อนข้อมูลต่อไปนี้:
- ป้อนชื่อความลับของคุณ เช่น
sm-sql-snowflake-secret. - ปล่อยการตั้งค่าอื่นๆ ไว้เป็นค่าเริ่มต้นหรือปรับแต่งหากจำเป็น
- สร้างความลับ
สร้างการเชื่อมต่อ AWS Glue สำหรับ Snowflake
ตามที่กล่าวไว้ข้างต้น การเชื่อมต่อ AWS Glue จำเป็นสำหรับการเข้าถึงการเชื่อมต่อใดๆ จาก SageMaker Studio คุณสามารถค้นหารายการของ คุณสมบัติการเชื่อมต่อที่รองรับทั้งหมดสำหรับ Snowflake- ต่อไปนี้คือตัวอย่างคำจำกัดความการเชื่อมต่อ JSON สำหรับ Snowflake แทนที่ค่าตัวยึดตำแหน่งด้วยค่าที่เหมาะสมก่อนที่จะบันทึกลงดิสก์:
หากต้องการสร้างออบเจ็กต์การเชื่อมต่อ AWS Glue สำหรับแหล่งข้อมูล Snowflake ให้ใช้คำสั่งต่อไปนี้:
คำสั่งนี้จะสร้างการเชื่อมต่อแหล่งข้อมูล Snowflake ใหม่ในบานหน้าต่างเบราว์เซอร์ SQL ของคุณที่สามารถเรียกดูได้ และคุณสามารถเรียกใช้คำสั่ง SQL กับการเชื่อมต่อนั้นได้จากเซลล์สมุดบันทึก JupyterLab ของคุณ
สร้างการเชื่อมต่อ Amazon Redshift
Amazon Redshift เป็นบริการคลังข้อมูลขนาดเพตะไบต์ที่มีการจัดการเต็มรูปแบบ ซึ่งช่วยลดความยุ่งยากและลดต้นทุนในการวิเคราะห์ข้อมูลทั้งหมดของคุณโดยใช้ SQL มาตรฐาน ขั้นตอนการสร้างการเชื่อมต่อ Amazon RedShift จะสะท้อนขั้นตอนดังกล่าวสำหรับการเชื่อมต่อ Snowflake อย่างใกล้ชิด
สร้างข้อมูลลับของ Secrets Manager
เช่นเดียวกับการตั้งค่า Snowflake ในการเชื่อมต่อกับ Amazon RedShift โดยใช้ ID ผู้ใช้และรหัสผ่าน คุณจะต้องจัดเก็บข้อมูลความลับไว้ใน Secrets Manager อย่างปลอดภัย ทำตามขั้นตอนต่อไปนี้:
- บนคอนโซล Secrets Manager ให้เลือก เก็บความลับใหม่.
- สำหรับ ประเภทลับเลือก ข้อมูลประจำตัวสำหรับคลัสเตอร์ Amazon RedShift.
- ป้อนข้อมูลประจำตัวที่ใช้ในการเข้าสู่ระบบเพื่อเข้าถึง Amazon RedShift เป็นแหล่งข้อมูล
- เลือกคลัสเตอร์ RedShift ที่เชื่อมโยงกับข้อมูลลับ
- ป้อนชื่อสำหรับข้อมูลลับ เช่น
sm-sql-redshift-secret. - ปล่อยการตั้งค่าอื่นๆ ไว้เป็นค่าเริ่มต้นหรือปรับแต่งหากจำเป็น
- สร้างความลับ
เมื่อทำตามขั้นตอนเหล่านี้ คุณจะมั่นใจได้ว่าข้อมูลรับรองการเชื่อมต่อของคุณได้รับการจัดการอย่างปลอดภัย โดยใช้คุณสมบัติความปลอดภัยที่แข็งแกร่งของ AWS เพื่อจัดการข้อมูลที่ละเอียดอ่อนอย่างมีประสิทธิภาพ
สร้างการเชื่อมต่อ AWS Glue สำหรับ Amazon RedShift
หากต้องการตั้งค่าการเชื่อมต่อกับ Amazon RedShift โดยใช้คำจำกัดความ JSON ให้กรอกข้อมูลในช่องที่จำเป็นและบันทึกการกำหนดค่า JSON ต่อไปนี้ลงในดิสก์:
หากต้องการสร้างออบเจ็กต์การเชื่อมต่อ AWS Glue สำหรับแหล่งข้อมูล Redshift ให้ใช้คำสั่ง AWS CLI ต่อไปนี้:
คำสั่งนี้สร้างการเชื่อมต่อใน AWS Glue ที่เชื่อมโยงกับแหล่งข้อมูล Redshift ของคุณ หากคำสั่งรันสำเร็จ คุณจะสามารถเห็นแหล่งข้อมูล Redshift ของคุณภายในสมุดบันทึก SageMaker Studio JupyterLab ซึ่งพร้อมสำหรับการเรียกใช้คำสั่ง SQL และดำเนินการวิเคราะห์ข้อมูล

สร้างการเชื่อมต่อ Athena
Athena เป็นบริการสืบค้น SQL ที่มีการจัดการเต็มรูปแบบจาก AWS ซึ่งช่วยให้สามารถวิเคราะห์ข้อมูลที่จัดเก็บไว้ใน Amazon S3 โดยใช้ SQL มาตรฐาน หากต้องการตั้งค่าการเชื่อมต่อ Athena เป็นแหล่งข้อมูลในเบราว์เซอร์ SQL ของสมุดบันทึก JupyterLab คุณต้องสร้าง JSON ข้อกำหนดการเชื่อมต่อตัวอย่าง Athena โครงสร้าง JSON ต่อไปนี้กำหนดค่ารายละเอียดที่จำเป็นเพื่อเชื่อมต่อกับ Athena โดยระบุแค็ตตาล็อกข้อมูล ไดเร็กทอรีการแสดง S3 และภูมิภาค:
หากต้องการสร้างออบเจ็กต์การเชื่อมต่อ AWS Glue สำหรับแหล่งข้อมูล Athena ให้ใช้คำสั่ง AWS CLI ต่อไปนี้:
หากคำสั่งสำเร็จ คุณจะสามารถเข้าถึงแค็ตตาล็อกข้อมูลและตาราง Athena ได้โดยตรงจากเบราว์เซอร์ SQL ภายในสมุดบันทึก SageMaker Studio JupyterLab ของคุณ
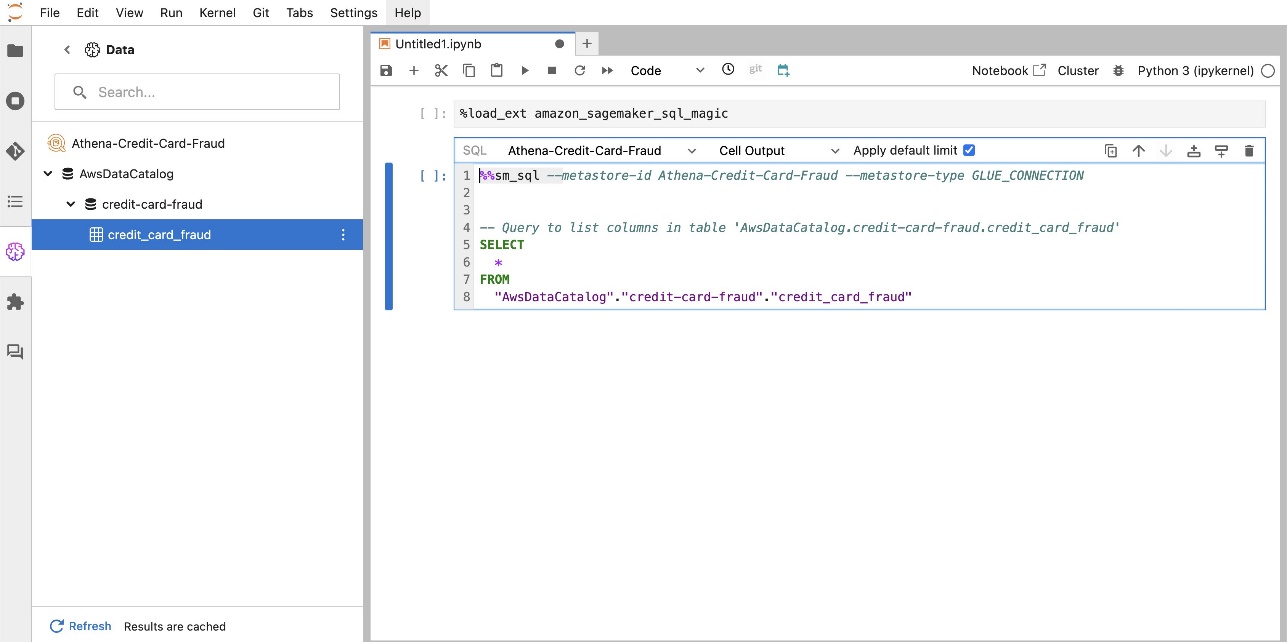
สืบค้นข้อมูลจากหลายแหล่ง
หากคุณมีแหล่งข้อมูลหลายแหล่งที่รวมอยู่ใน SageMaker Studio ผ่านเบราว์เซอร์ SQL ในตัวและคุณสมบัติ SQL ของสมุดบันทึก คุณสามารถดำเนินการสืบค้นได้อย่างรวดเร็วและสลับระหว่างแบ็กเอนด์แหล่งข้อมูลในเซลล์ถัดไปภายในสมุดบันทึกได้อย่างง่ายดาย ความสามารถนี้ช่วยให้สามารถเปลี่ยนแปลงระหว่างฐานข้อมูลหรือแหล่งข้อมูลต่างๆ ได้อย่างราบรื่นในระหว่างขั้นตอนการวิเคราะห์ของคุณ
คุณสามารถเรียกใช้การสืบค้นกับคอลเลกชันแบ็กเอนด์แหล่งข้อมูลที่หลากหลาย และนำผลลัพธ์มาสู่พื้นที่ Python โดยตรงเพื่อการวิเคราะห์หรือการแสดงภาพเพิ่มเติม โดยมีการอำนวยความสะดวกโดย %%sm_sql คำสั่งเวทย์มนตร์มีอยู่ในสมุดบันทึก SageMaker Studio หากต้องการส่งออกผลลัพธ์ของการสืบค้น SQL ของคุณไปยัง pandas DataFrame มีสองตัวเลือก:
- จากแถบเครื่องมือเซลล์สมุดบันทึกของคุณ ให้เลือกประเภทเอาต์พุต ดาต้าเฟรม และตั้งชื่อตัวแปร DataFrame ของคุณ
- ผนวกพารามิเตอร์ต่อไปนี้เข้ากับของคุณ
%%sm_sqlคำสั่ง:
แผนภาพต่อไปนี้แสดงขั้นตอนการทำงานนี้และแสดงวิธีที่คุณสามารถเรียกใช้การสืบค้นจากแหล่งต่างๆ ในเซลล์สมุดบันทึกต่อๆ ไปได้อย่างง่ายดาย ตลอดจนฝึกโมเดล SageMaker โดยใช้งานการฝึกอบรมหรือภายในสมุดบันทึกโดยตรงโดยใช้การประมวลผลในเครื่อง นอกจากนี้ แผนภาพยังเน้นย้ำว่าการรวม SQL ในตัวของ SageMaker Studio ช่วยลดความยุ่งยากในกระบวนการแยกและสร้างโดยตรงภายในสภาพแวดล้อมที่คุ้นเคยของเซลล์สมุดบันทึก JupyterLab ได้อย่างไร
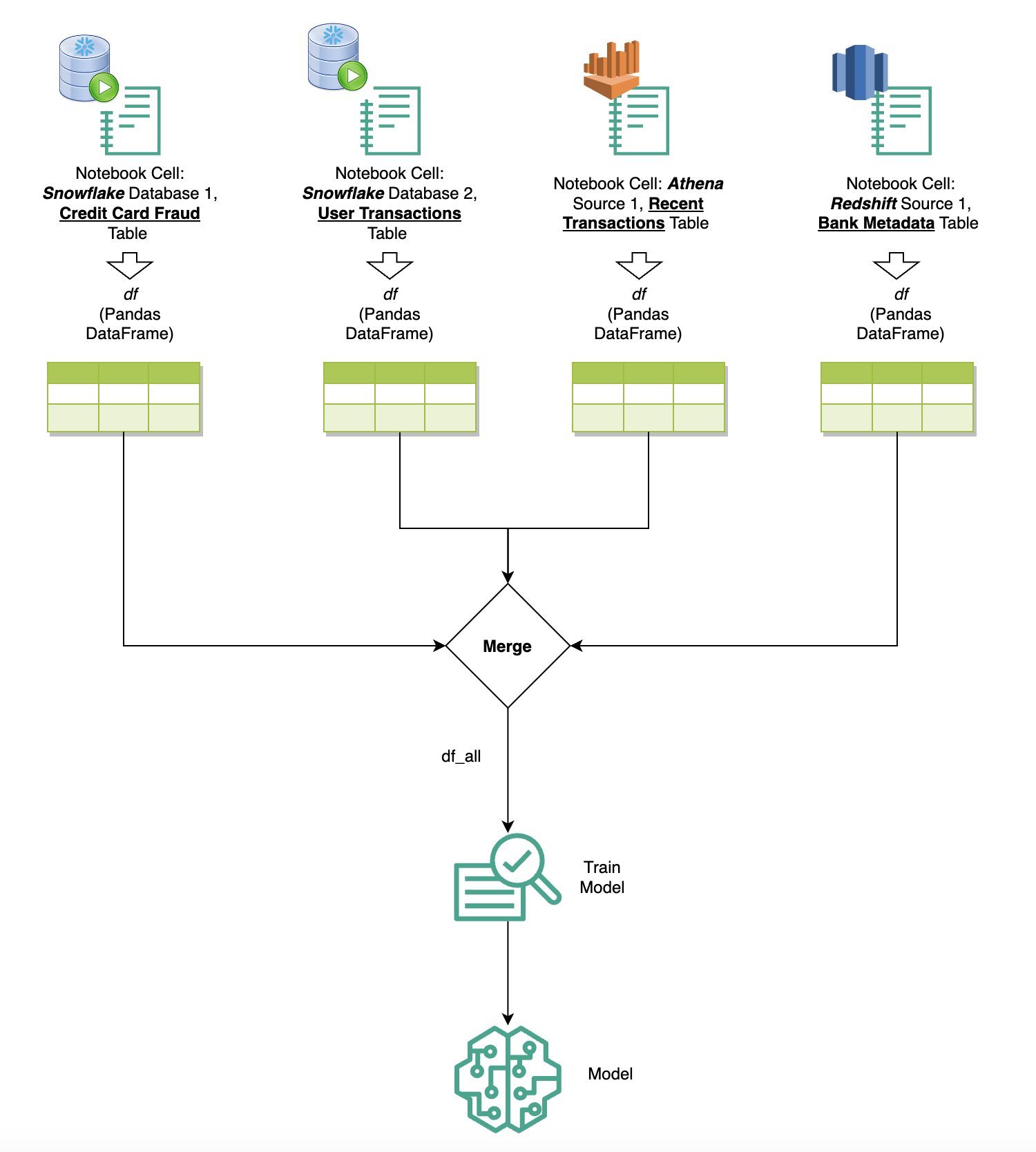
ข้อความเป็น SQL: การใช้ภาษาธรรมชาติเพื่อปรับปรุงการเขียนแบบสอบถาม
SQL เป็นภาษาที่ซับซ้อนซึ่งต้องมีความเข้าใจในฐานข้อมูล ตาราง ไวยากรณ์ และข้อมูลเมตา ปัจจุบัน ปัญญาประดิษฐ์เชิงสร้างสรรค์ (AI) สามารถช่วยให้คุณเขียนคำสั่ง SQL ที่ซับซ้อนได้โดยไม่ต้องมีประสบการณ์ SQL ในเชิงลึก ความก้าวหน้าของ LLM ส่งผลกระทบอย่างมีนัยสำคัญต่อการสร้าง SQL ที่ใช้การประมวลผลภาษาธรรมชาติ (NLP) ทำให้สามารถสร้างคำสั่ง SQL ที่แม่นยำจากคำอธิบายภาษาธรรมชาติ ซึ่งเป็นเทคนิคที่เรียกว่า Text-to-SQL อย่างไรก็ตาม จำเป็นต้องรับทราบถึงความแตกต่างโดยธรรมชาติระหว่างภาษามนุษย์และ SQL ภาษาของมนุษย์บางครั้งอาจไม่ชัดเจนหรือไม่ชัดเจน ในขณะที่ SQL มีโครงสร้าง ชัดเจน และไม่คลุมเครือ การเชื่อมช่องว่างนี้และการแปลงภาษาธรรมชาติเป็นการสืบค้น SQL อย่างถูกต้องสามารถนำเสนอความท้าทายที่น่ากลัว เมื่อได้รับพร้อมท์ที่เหมาะสม LLM สามารถช่วยเชื่อมช่องว่างนี้โดยการทำความเข้าใจจุดประสงค์ที่อยู่เบื้องหลังภาษาของมนุษย์ และสร้างคำสั่ง SQL ที่แม่นยำตามนั้น
ด้วยการเปิดตัวคุณสมบัติการสืบค้น SQL ในโน้ตบุ๊กของ SageMaker Studio SageMaker Studio ทำให้การตรวจสอบฐานข้อมูลและสคีมา รวมถึงการเขียน เรียกใช้ และดีบักการสืบค้น SQL เป็นเรื่องง่ายโดยไม่ต้องออกจาก IDE โน้ตบุ๊ก Jupyter ส่วนนี้จะสำรวจว่าความสามารถ Text-to-SQL ของ LLM ขั้นสูงสามารถอำนวยความสะดวกในการสร้างคำสั่ง SQL โดยใช้ภาษาธรรมชาติภายในสมุดบันทึก Jupyter ได้อย่างไร เราใช้โมเดล Text-to-SQL ที่ล้ำสมัย defog/sqlcoder-7b-2 ร่วมกับ Jupyter AI ซึ่งเป็นผู้ช่วย AI เจนเนอเรชั่นที่ออกแบบมาโดยเฉพาะสำหรับโน้ตบุ๊ก Jupyter เพื่อสร้างคำสั่ง SQL ที่ซับซ้อนจากภาษาธรรมชาติ ด้วยการใช้โมเดลขั้นสูงนี้ เราสามารถสร้างการสืบค้น SQL ที่ซับซ้อนได้อย่างง่ายดายและมีประสิทธิภาพโดยใช้ภาษาธรรมชาติ ซึ่งจะช่วยปรับปรุงประสบการณ์ SQL ของเราภายในสมุดบันทึก
การสร้างต้นแบบโน้ตบุ๊กโดยใช้ Hugging Face Hub
ในการเริ่มสร้างต้นแบบ คุณต้องมีสิ่งต่อไปนี้:
- รหัส GitHub – รหัสที่นำเสนอในส่วนนี้มีดังต่อไปนี้ repo GitHub และโดยการอ้างอิงถึง ตัวอย่างโน๊ตบุ๊ค.
- จูปิเตอร์แล็บ สเปซ – การเข้าถึง SageMaker Studio JupyterLab Space ที่ได้รับการสนับสนุนจากอินสแตนซ์ที่ใช้ GPU ถือเป็นสิ่งสำคัญ สำหรับ
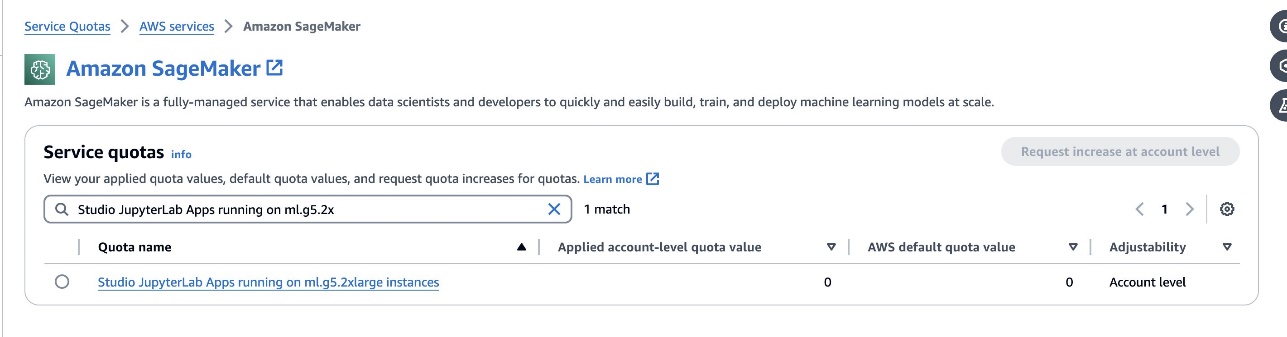
defog/sqlcoder-7b-2แนะนำให้ใช้โมเดลพารามิเตอร์ 7B โดยใช้อินสแตนซ์ ml.g5.2xlarge ทางเลือกอื่นเช่นdefog/sqlcoder-70b-alpha หรือdefog/sqlcoder-34b-alphaยังสามารถใช้งานได้กับการแปลงภาษาธรรมชาติไปเป็น SQL อีกด้วย แต่อาจต้องใช้ประเภทอินสแตนซ์ที่ใหญ่กว่าสำหรับการสร้างต้นแบบ ตรวจสอบให้แน่ใจว่าคุณมีโควต้าในการเปิดใช้อินสแตนซ์ที่สนับสนุน GPU โดยไปที่คอนโซลโควต้าบริการ ค้นหา SageMaker และค้นหาStudio JupyterLab Apps running on <instance type>.
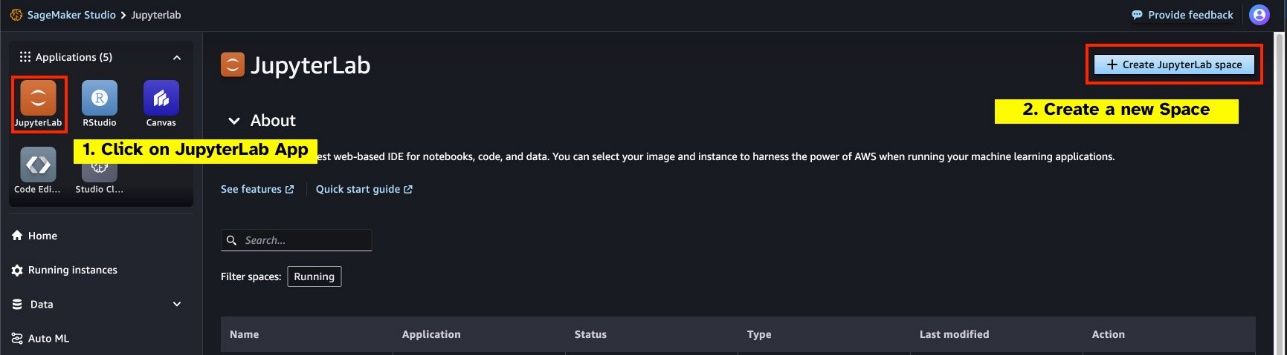
เปิดตัว JupyterLab Space ที่สนับสนุน GPU ใหม่จาก SageMaker Studio ของคุณ ขอแนะนำให้สร้าง JupyterLab Space ใหม่โดยมีขนาดอย่างน้อย 75 GB ร้านค้า Amazon Elastic Block พื้นที่จัดเก็บข้อมูล (Amazon EBS) สำหรับโมเดลพารามิเตอร์ 7B

- กอดใบหน้าฮับ – หากโดเมน SageMaker Studio ของคุณมีสิทธิ์เข้าถึงโมเดลการดาวน์โหลดจาก กอดใบหน้าฮับคุณสามารถใช้
AutoModelForCausalLMชั้นเรียนจาก กอดหน้า/หม้อแปลง เพื่อดาวน์โหลดโมเดลโดยอัตโนมัติและปักหมุดโมเดลเหล่านั้นไว้ที่ GPU ในเครื่องของคุณ น้ำหนักโมเดลจะถูกจัดเก็บไว้ในแคชของเครื่องภายในเครื่องของคุณ ดูรหัสต่อไปนี้:
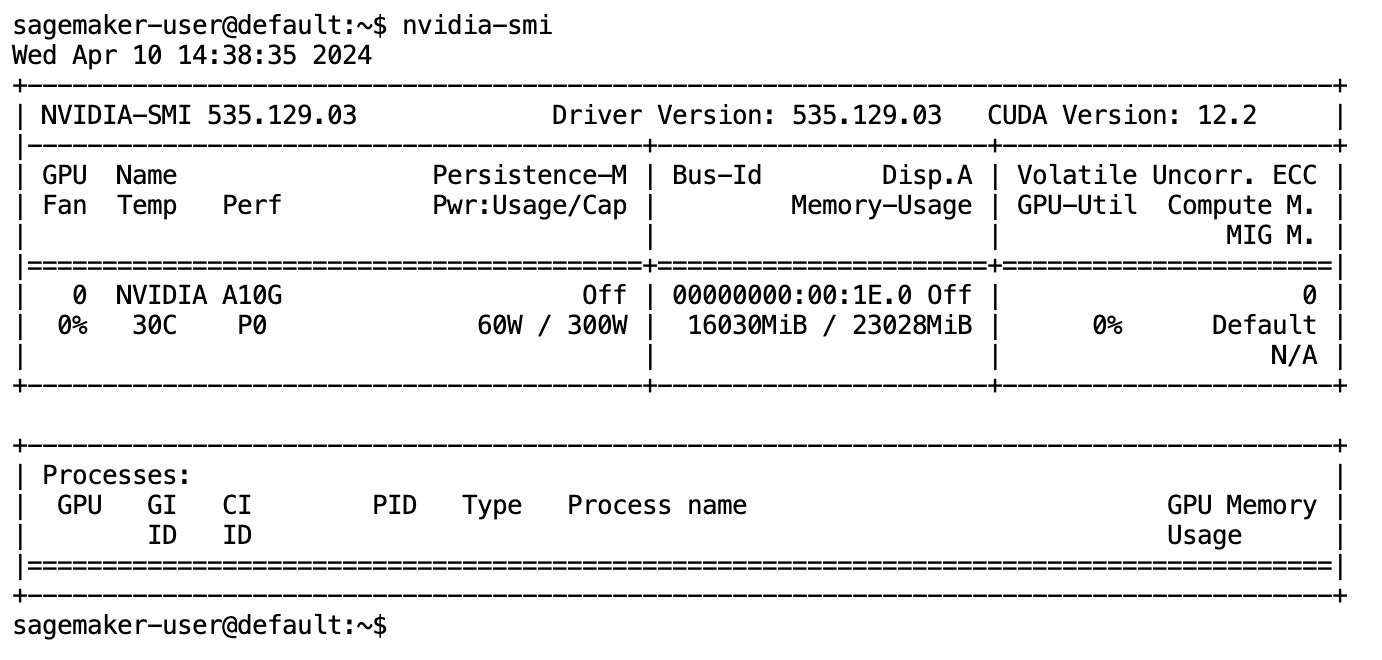
หลังจากดาวน์โหลดโมเดลและโหลดลงในหน่วยความจำเรียบร้อยแล้ว คุณควรสังเกตเห็นการใช้งาน GPU เพิ่มขึ้นในเครื่องของคุณ สิ่งนี้บ่งชี้ว่าโมเดลกำลังใช้ทรัพยากร GPU สำหรับงานคำนวณอยู่ คุณสามารถตรวจสอบสิ่งนี้ได้ในพื้นที่ JupyterLab ของคุณเองโดยการเรียกใช้ nvidia-smi (สำหรับการแสดงครั้งเดียว) หรือ nvidia-smi —loop=1 (เพื่อทำซ้ำทุกวินาที) จากเทอร์มินัล JupyterLab ของคุณ
โมเดลข้อความเป็น SQL เก่งในการทำความเข้าใจจุดประสงค์และบริบทของคำขอของผู้ใช้ แม้ว่าภาษาที่ใช้จะเป็นการสนทนาหรือคลุมเครือก็ตาม กระบวนการนี้เกี่ยวข้องกับการแปลอินพุตภาษาธรรมชาติให้เป็นองค์ประกอบสคีมาฐานข้อมูลที่ถูกต้อง เช่น ชื่อตาราง ชื่อคอลัมน์ และเงื่อนไข อย่างไรก็ตาม โมเดล Text-to-SQL ที่มีจำหน่ายทั่วไปจะไม่ทราบโครงสร้างของคลังข้อมูลของคุณ สกีมาฐานข้อมูลเฉพาะ หรือไม่สามารถตีความเนื้อหาของตารางตามชื่อคอลัมน์เพียงอย่างเดียวได้อย่างแม่นยำ หากต้องการใช้โมเดลเหล่านี้อย่างมีประสิทธิภาพเพื่อสร้างการสืบค้น SQL ที่ใช้งานได้จริงและมีประสิทธิภาพจากภาษาธรรมชาติ จำเป็นต้องปรับโมเดลการสร้างข้อความ SQL ให้เข้ากับสคีมาฐานข้อมูลคลังสินค้าเฉพาะของคุณ การปรับตัวนี้อำนวยความสะดวกโดยการใช้ LLM แจ้ง- ต่อไปนี้เป็นเทมเพลตพร้อมต์ที่แนะนำสำหรับโมเดล defog/sqlcoder-7b-2 Text-to-SQL ซึ่งแบ่งออกเป็นสี่ส่วน:
- งาน – ส่วนนี้ควรระบุงานระดับสูงที่แบบจำลองจะต้องทำให้สำเร็จ ควรมีประเภทของแบ็กเอนด์ฐานข้อมูล (เช่น Amazon RDS, PostgreSQL หรือ Amazon Redshift) เพื่อให้โมเดลทราบถึงความแตกต่างทางไวยากรณ์ที่เหมาะสมเล็กๆ น้อยๆ ที่อาจส่งผลต่อการสร้างการสืบค้น SQL สุดท้าย
- คำแนะนำ – ส่วนนี้ควรกำหนดขอบเขตของงานและการรับรู้โดเมนสำหรับโมเดล และอาจรวมถึงตัวอย่างสั้นๆ เพื่อเป็นแนวทางให้กับโมเดลในการสร้างคำสั่ง SQL ที่ปรับแต่งอย่างละเอียด
- สคีมาฐานข้อมูล – ส่วนนี้ควรให้รายละเอียดเกี่ยวกับสกีมาฐานข้อมูลคลังสินค้าของคุณ โดยสรุปความสัมพันธ์ระหว่างตารางและคอลัมน์เพื่อช่วยแบบจำลองในการทำความเข้าใจโครงสร้างฐานข้อมูล
- คำตอบ – ส่วนนี้สงวนไว้สำหรับโมเดลในการส่งออกการตอบกลับแบบสอบถาม SQL ไปยังอินพุตภาษาธรรมชาติ
ตัวอย่างของสคีมาฐานข้อมูลและพร้อมท์ที่ใช้ในส่วนนี้มีอยู่ใน ที่เก็บ GitHub.
วิศวกรรมพร้อมท์ไม่ได้เป็นเพียงการสร้างคำถามหรือข้อความเท่านั้น เป็นศาสตร์และศิลป์ที่ละเอียดอ่อนซึ่งส่งผลกระทบอย่างมากต่อคุณภาพของการโต้ตอบกับโมเดล AI วิธีที่คุณสร้างการแจ้งเตือนสามารถมีอิทธิพลอย่างมากต่อธรรมชาติและประโยชน์ของการตอบสนองของ AI ทักษะนี้เป็นหัวใจสำคัญในการเพิ่มศักยภาพของการโต้ตอบของ AI โดยเฉพาะอย่างยิ่งในงานที่ซับซ้อนซึ่งต้องใช้ความเข้าใจเฉพาะทางและการตอบสนองโดยละเอียด
สิ่งสำคัญคือต้องมีตัวเลือกในการสร้างและทดสอบการตอบสนองของโมเดลอย่างรวดเร็วสำหรับพร้อมท์ที่กำหนด และปรับพร้อมท์ให้เหมาะสมตามการตอบสนอง โน้ตบุ๊ก JupyterLab มอบความสามารถในการรับคำติชมโมเดลทันทีจากโมเดลที่ทำงานบนการประมวลผลในเครื่อง และเพิ่มประสิทธิภาพการแจ้งเตือนและปรับแต่งการตอบสนองของโมเดลเพิ่มเติมหรือเปลี่ยนโมเดลทั้งหมด ในโพสต์นี้ เราใช้สมุดบันทึก SageMaker Studio JupyterLab ที่ได้รับการสนับสนุนจาก GPU NVIDIA A5.2G 10 GB ของ ml.g24xlarge เพื่อเรียกใช้การอนุมานโมเดล Text-to-SQL บนโน้ตบุ๊ก และสร้างพรอมต์โมเดลของเราเชิงโต้ตอบจนกว่าการตอบสนองของโมเดลจะได้รับการปรับแต่งอย่างเพียงพอเพื่อให้ การตอบสนองที่สามารถเรียกใช้งานได้โดยตรงในเซลล์ SQL ของ JupyterLab ในการรันการอนุมานโมเดลและสตรีมการตอบสนองของโมเดลไปพร้อมๆ กัน เราใช้การผสมผสานของ model.generate และ TextIteratorStreamer ตามที่กำหนดไว้ในรหัสต่อไปนี้:
ผลลัพธ์ของโมเดลสามารถตกแต่งได้ด้วยเวทย์มนตร์ SageMaker SQL %%sm_sql ...ซึ่งช่วยให้สมุดบันทึก JupyterLab สามารถระบุเซลล์เป็นเซลล์ SQL ได้
โฮสต์โมเดล Text-to-SQL เป็นจุดสิ้นสุดของ SageMaker
ในตอนท้ายของขั้นตอนการสร้างต้นแบบ เราได้เลือก Text-to-SQL LLM ที่เราต้องการ รูปแบบพร้อมท์ที่มีประสิทธิภาพ และประเภทอินสแตนซ์ที่เหมาะสมสำหรับการโฮสต์โมเดล (GPU เดี่ยวหรือหลาย GPU) SageMaker อำนวยความสะดวกในการโฮสต์โมเดลแบบกำหนดเองที่ปรับขนาดได้ผ่านการใช้ตำแหน่งข้อมูล SageMaker ตำแหน่งข้อมูลเหล่านี้สามารถกำหนดได้ตามเกณฑ์เฉพาะ ช่วยให้สามารถปรับใช้ LLM เป็นจุดสิ้นสุดได้ ความสามารถนี้ช่วยให้คุณสามารถปรับขนาดโซลูชันให้ครอบคลุมผู้ชมได้กว้างขึ้น โดยช่วยให้ผู้ใช้สามารถสร้างการสืบค้น SQL จากการป้อนข้อมูลภาษาธรรมชาติโดยใช้ LLM ที่โฮสต์แบบกำหนดเอง แผนภาพต่อไปนี้แสดงให้เห็นถึงสถาปัตยกรรมนี้

หากต้องการโฮสต์ LLM ของคุณเป็นตำแหน่งข้อมูล SageMaker คุณจะต้องสร้างอาร์ติแฟกต์หลายรายการ
สิ่งประดิษฐ์ชิ้นแรกคือตุ้มน้ำหนักแบบจำลอง การให้บริการ SageMaker Deep Java Library (DJL) คอนเทนเนอร์ช่วยให้คุณสามารถตั้งค่าการกำหนดค่าผ่านเมตาดาต้าได้ ให้บริการคุณสมบัติ ซึ่งช่วยให้คุณกำหนดวิธีการแหล่งที่มาของโมเดลได้โดยตรงจาก Hugging Face Hub หรือโดยการดาวน์โหลดอาร์ติแฟกต์ของโมเดลจาก Amazon S3 หากคุณระบุ model_id=defog/sqlcoder-7b-2DJL Serving จะพยายามดาวน์โหลดโมเดลนี้โดยตรงจาก Hugging Face Hub อย่างไรก็ตาม คุณอาจต้องเสียค่าบริการเครือข่ายขาเข้า/ขาออกทุกครั้งที่มีการปรับใช้ตำแหน่งข้อมูลหรือปรับขนาดแบบยืดหยุ่น เพื่อหลีกเลี่ยงค่าใช้จ่ายเหล่านี้และอาจเพิ่มความเร็วในการดาวน์โหลดอาร์ติแฟกต์โมเดล ขอแนะนำให้ข้ามการใช้ model_id in serving.properties และบันทึกน้ำหนักโมเดลเป็นอาร์ติแฟกต์ S3 และระบุด้วยเท่านั้น s3url=s3://path/to/model/bin.
การบันทึกโมเดล (ด้วยโทเค็นเซอร์) ลงดิสก์และอัปโหลดไปยัง Amazon S3 สามารถทำได้โดยใช้โค้ดเพียงไม่กี่บรรทัด:
คุณยังใช้ไฟล์พร้อมท์ฐานข้อมูล ในการตั้งค่านี้ พรอมต์ฐานข้อมูลจะประกอบด้วย Task, Instructions, Database Schemaและ Answer sections- สำหรับสถาปัตยกรรมปัจจุบัน เราจัดสรรไฟล์พร้อมท์แยกต่างหากสำหรับแต่ละสคีมาฐานข้อมูล อย่างไรก็ตาม มีความยืดหยุ่นในการขยายการตั้งค่านี้ให้รวมหลายฐานข้อมูลต่อไฟล์พร้อมท์ ซึ่งช่วยให้โมเดลสามารถเรียกใช้การรวมแบบคอมโพสิตระหว่างฐานข้อมูลบนเซิร์ฟเวอร์เดียวกัน ในระหว่างขั้นตอนการสร้างต้นแบบ เราจะบันทึกพรอมต์ฐานข้อมูลเป็นไฟล์ข้อความชื่อ <Database-Glue-Connection-Name>.promptที่นี่มี Database-Glue-Connection-Name สอดคล้องกับชื่อการเชื่อมต่อที่ปรากฏในสภาพแวดล้อม JupyterLab ของคุณ ตัวอย่างเช่น โพสต์นี้อ้างถึงการเชื่อมต่อ Snowflake ที่ตั้งชื่อไว้ Airlines_Datasetดังนั้นจึงตั้งชื่อไฟล์พรอมต์ฐานข้อมูล Airlines_Dataset.prompt- จากนั้นไฟล์นี้จะถูกจัดเก็บไว้ใน Amazon S3 และอ่านและแคชในภายหลังโดยตรรกะการให้บริการโมเดลของเรา
นอกจากนี้ สถาปัตยกรรมนี้ยังอนุญาตให้ผู้ใช้ที่ได้รับอนุญาตของตำแหน่งข้อมูลนี้กำหนด จัดเก็บ และสร้างภาษาธรรมชาติสำหรับการสืบค้น SQL โดยไม่จำเป็นต้องปรับใช้โมเดลหลายครั้ง เราใช้สิ่งต่อไปนี้ ตัวอย่างการแจ้งฐานข้อมูล เพื่อสาธิตการทำงานของ Text-to-SQL
ถัดไป คุณสร้างตรรกะการบริการโมเดลแบบกำหนดเอง ในส่วนนี้ คุณจะร่างโครงร่างตรรกะการอนุมานแบบกำหนดเองที่มีชื่อว่า model.py- สคริปต์นี้ออกแบบมาเพื่อเพิ่มประสิทธิภาพการทำงานและการผสานรวมบริการ Text-to-SQL ของเรา:
- กำหนดตรรกะการแคชไฟล์พร้อมท์ฐานข้อมูล – เพื่อลดเวลาแฝงให้เหลือน้อยที่สุด เราใช้ตรรกะแบบกำหนดเองสำหรับการดาวน์โหลดและแคชไฟล์พร้อมท์ฐานข้อมูล กลไกนี้ทำให้แน่ใจว่าพร้อมท์พร้อมใช้งาน ซึ่งช่วยลดค่าใช้จ่ายที่เกี่ยวข้องกับการดาวน์โหลดบ่อยครั้ง
- กำหนดตรรกะการอนุมานแบบจำลองแบบกำหนดเอง – เพื่อเพิ่มความเร็วในการอนุมาน โมเดลข้อความเป็น SQL ของเราจะถูกโหลดในรูปแบบความแม่นยำ float16 แล้วแปลงเป็นโมเดล DeepSpeed ขั้นตอนนี้ช่วยให้การคำนวณมีประสิทธิภาพมากขึ้น นอกจากนี้ ภายในตรรกะนี้ คุณยังระบุพารามิเตอร์ที่ผู้ใช้สามารถปรับได้ระหว่างการโทรอนุมาน เพื่อปรับแต่งฟังก์ชันการทำงานตามความต้องการของพวกเขา
- กำหนดตรรกะอินพุตและเอาต์พุตแบบกำหนดเอง – การสร้างรูปแบบอินพุต/เอาท์พุตที่ชัดเจนและปรับแต่งเองถือเป็นสิ่งสำคัญสำหรับการรวมเข้ากับแอปพลิเคชันดาวน์สตรีมได้อย่างราบรื่น แอปพลิเคชันหนึ่งคือ JupyterAI ซึ่งเราจะกล่าวถึงในหัวข้อถัดไป
นอกจากนี้ เรายังรวมถึงก serving.properties ซึ่งทำหน้าที่เป็นไฟล์กำหนดค่าส่วนกลางสำหรับโมเดลที่โฮสต์โดยใช้การให้บริการ DJL สำหรับข้อมูลเพิ่มเติม โปรดดูที่ การกำหนดค่าและการตั้งค่า.
สุดท้ายนี้ คุณยังสามารถรวมก requirements.txt เพื่อกำหนดโมดูลเพิ่มเติมที่จำเป็นสำหรับการอนุมานและรวมทุกอย่างไว้ใน tarball เพื่อนำไปใช้งาน
ดูรหัสต่อไปนี้:
ผสานรวมตำแหน่งข้อมูลของคุณเข้ากับผู้ช่วย SageMaker Studio Jupyter AI
จูปิเตอร์ เอไอ เป็นเครื่องมือโอเพ่นซอร์สที่นำ AI เชิงสร้างสรรค์มาสู่โน้ตบุ๊ก Jupyter โดยนำเสนอแพลตฟอร์มที่แข็งแกร่งและใช้งานง่ายสำหรับการสำรวจโมเดล AI เชิงสร้างสรรค์ ช่วยเพิ่มประสิทธิภาพการทำงานในโน้ตบุ๊ก JupyterLab และ Jupyter ด้วยการมอบฟีเจอร์ต่างๆ เช่น %%ai magic สำหรับการสร้างสนามเด็กเล่น AI ภายในโน้ตบุ๊ก, UI การแชทแบบเนทีฟใน JupyterLab สำหรับการโต้ตอบกับ AI ในฐานะผู้ช่วยสนทนา และรองรับ LLM ที่หลากหลายจาก ผู้ให้บริการชอบ อเมซอนไททัน, AI21, Anthropic, Cohere และ Hugging Face หรือบริการที่ได้รับการจัดการ เช่น อเมซอน เบดร็อค และตำแหน่งข้อมูล SageMaker สำหรับโพสต์นี้ เราใช้การบูรณาการแบบทันทีของ Jupyter AI กับตำแหน่งข้อมูล SageMaker เพื่อนำความสามารถ Text-to-SQL มาสู่สมุดบันทึก JupyterLab เครื่องมือ Jupyter AI ติดตั้งไว้ล่วงหน้าใน SageMaker Studio JupyterLab Spaces ทั้งหมดที่ได้รับการสนับสนุนจาก รูปภาพการเผยแพร่ SageMaker- ผู้ใช้ไม่จำเป็นต้องทำการกำหนดค่าเพิ่มเติมใดๆ เพื่อเริ่มใช้ส่วนขยาย Jupyter AI เพื่อผสานรวมกับอุปกรณ์ปลายทางที่โฮสต์โดย SageMaker ในส่วนนี้ เราจะพูดถึงสองวิธีในการใช้เครื่องมือ Jupyter AI ที่ผสานรวม
Jupyter AI ภายในสมุดบันทึกโดยใช้เวทมนตร์
จูปิเตอร์ เอไอ %%ai คำสั่งเวทย์มนตร์ช่วยให้คุณแปลงสมุดบันทึก SageMaker Studio JupyterLab ของคุณให้เป็นสภาพแวดล้อม AI ที่สร้างซ้ำได้ หากต้องการเริ่มใช้ AI magics ตรวจสอบให้แน่ใจว่าคุณได้โหลดส่วนขยาย jupyter_ai_magics ที่จะใช้ %%ai เวทย์มนตร์และโหลดเพิ่มเติม amazon_sagemaker_sql_magic ใช้ %%sm_sql มายากล:
หากต้องการเรียกใช้การเรียกไปยังตำแหน่งข้อมูล SageMaker จากสมุดบันทึกของคุณโดยใช้ %%ai คำสั่ง magic จัดเตรียมพารามิเตอร์ต่อไปนี้และจัดโครงสร้างคำสั่งดังต่อไปนี้:
- –ชื่อภูมิภาค – ระบุภูมิภาคที่จุดสิ้นสุดของคุณถูกปรับใช้ เพื่อให้แน่ใจว่าคำขอถูกส่งไปยังที่ตั้งทางภูมิศาสตร์ที่ถูกต้อง
- –คำขอสคีมา – รวมสคีมาของข้อมูลอินพุต สคีมานี้จะสรุปรูปแบบและประเภทของข้อมูลอินพุตที่คาดหวังซึ่งโมเดลของคุณจำเป็นต้องใช้ในการประมวลผลคำขอ
- –เส้นทางการตอบสนอง – กำหนดเส้นทางภายในวัตถุตอบสนองซึ่งมีเอาต์พุตของโมเดลของคุณอยู่ เส้นทางนี้ใช้เพื่อแยกข้อมูลที่เกี่ยวข้องจากการตอบสนองที่ส่งคืนโดยโมเดลของคุณ
- -f (ไม่จำเป็น) - นี่คือ ฟอร์แมตเอาท์พุต ธงที่ระบุประเภทของเอาต์พุตที่ส่งคืนโดยโมเดล ในบริบทของสมุดบันทึก Jupyter หากเอาต์พุตเป็นโค้ด ควรตั้งค่าแฟล็กนี้ให้สอดคล้องเพื่อจัดรูปแบบเอาต์พุตเป็นโค้ดที่ปฏิบัติการได้ที่ด้านบนของเซลล์สมุดบันทึก Jupyter ตามด้วยพื้นที่ป้อนข้อความอิสระสำหรับการโต้ตอบของผู้ใช้
ตัวอย่างเช่น คำสั่งในเซลล์สมุดบันทึก Jupyter อาจมีลักษณะเหมือนโค้ดต่อไปนี้:
หน้าต่างแชท Jupyter AI
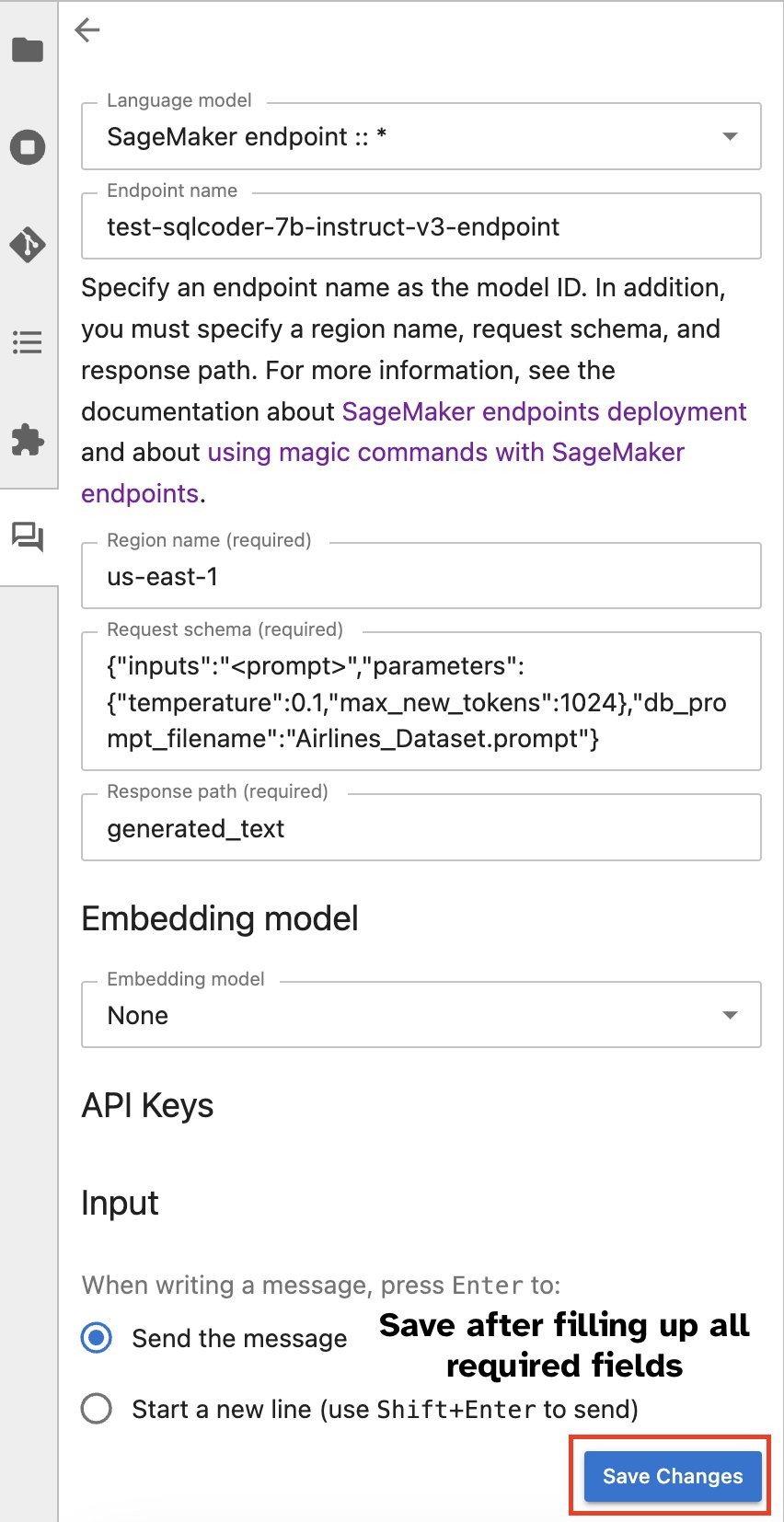
หรือคุณสามารถโต้ตอบกับตำแหน่งข้อมูล SageMaker ผ่านอินเทอร์เฟซผู้ใช้ในตัว ซึ่งทำให้กระบวนการสร้างแบบสอบถามหรือมีส่วนร่วมในการสนทนาง่ายขึ้น ก่อนที่จะเริ่มแชทกับตำแหน่งข้อมูล SageMaker ของคุณ ให้กำหนดการตั้งค่าที่เกี่ยวข้องใน Jupyter AI สำหรับตำแหน่งข้อมูล SageMaker ดังที่แสดงในภาพหน้าจอต่อไปนี้
 |
 |
สรุป
ตอนนี้ SageMaker Studio ลดความซับซ้อนและเพิ่มประสิทธิภาพเวิร์กโฟลว์นักวิทยาศาสตร์ข้อมูลโดยการผสานรวมการสนับสนุน SQL เข้ากับสมุดบันทึก JupyterLab ช่วยให้นักวิทยาศาสตร์ข้อมูลมุ่งความสนใจไปที่งานของตนได้โดยไม่จำเป็นต้องจัดการเครื่องมือหลายอย่าง นอกจากนี้ การรวม SQL ในตัวใหม่ใน SageMaker Studio ช่วยให้บุคคลข้อมูลสามารถสร้างการสืบค้น SQL ได้อย่างง่ายดายโดยใช้ข้อความภาษาธรรมชาติเป็นอินพุต จึงช่วยเร่งเวิร์กโฟลว์ของพวกเขา
เราขอแนะนำให้คุณสำรวจคุณสมบัติเหล่านี้ใน SageMaker Studio สำหรับข้อมูลเพิ่มเติม โปรดดูที่ เตรียมข้อมูลด้วย SQL ใน Studio.
ภาคผนวก
เปิดใช้งานเบราว์เซอร์ SQL และเซลล์ SQL สมุดบันทึกในสภาพแวดล้อมที่กำหนดเอง
หากคุณไม่ได้ใช้อิมเมจการแจกจ่าย SageMaker หรือใช้อิมเมจการแจกจ่าย 1.5 หรือต่ำกว่า ให้รันคำสั่งต่อไปนี้เพื่อเปิดใช้งานคุณสมบัติการเรียกดู SQL ภายในสภาพแวดล้อม JupyterLab ของคุณ:
ย้ายวิดเจ็ตเบราว์เซอร์ SQL
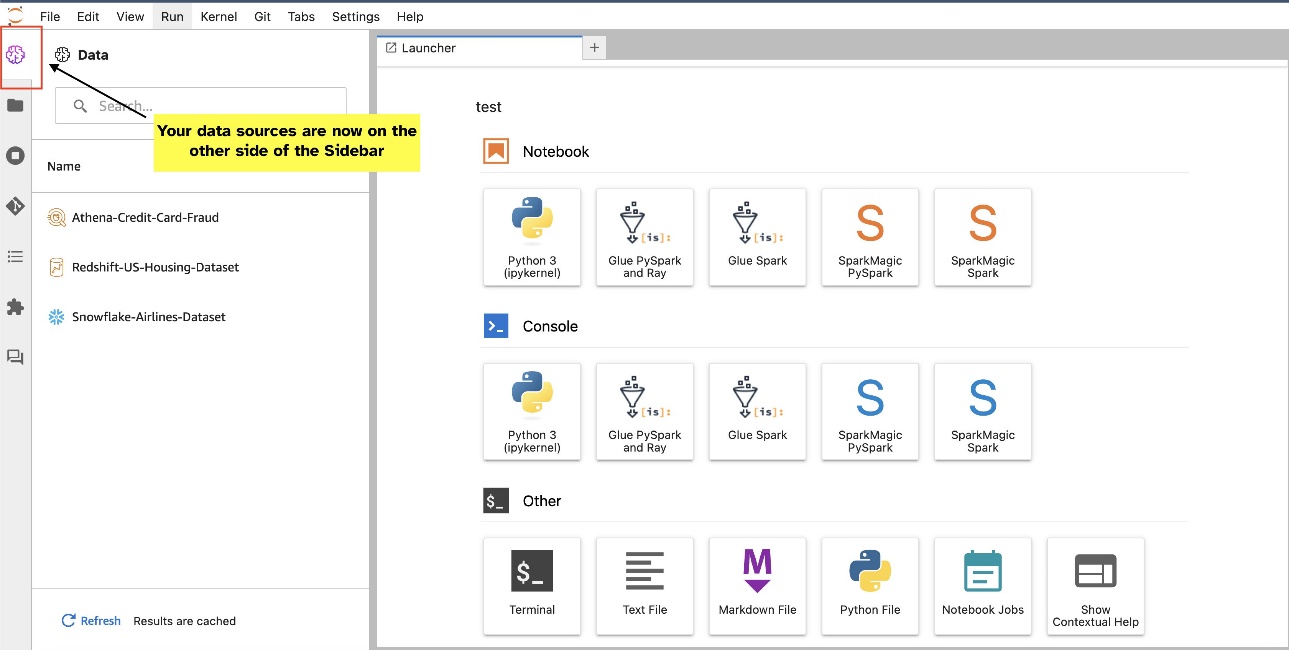
วิดเจ็ต JupyterLab อนุญาตให้มีการย้ายตำแหน่ง คุณสามารถย้ายวิดเจ็ตไปที่ด้านใดด้านหนึ่งของบานหน้าต่างวิดเจ็ต JupyterLab ได้ ทั้งนี้ขึ้นอยู่กับความต้องการของคุณ หากคุณต้องการ คุณสามารถย้ายทิศทางของวิดเจ็ต SQL ไปยังฝั่งตรงข้าม (จากขวาไปซ้าย) ของแถบด้านข้างได้ด้วยการคลิกขวาที่ไอคอนวิดเจ็ตแล้วเลือก สลับแถบด้านข้าง.
 |
 |
เกี่ยวกับผู้แต่ง
 ปรานาฟ เมอร์ธี เป็นสถาปนิกโซลูชันผู้เชี่ยวชาญ AI/ML ที่ AWS เขามุ่งเน้นที่การช่วยเหลือลูกค้าในการสร้าง ฝึกอบรม ปรับใช้ และโยกย้ายปริมาณงานการเรียนรู้ของเครื่อง (ML) ไปยัง SageMaker ก่อนหน้านี้เขาเคยทำงานในอุตสาหกรรมเซมิคอนดักเตอร์ที่พัฒนาโมเดลคอมพิวเตอร์วิทัศน์ขนาดใหญ่ (CV) และการประมวลผลภาษาธรรมชาติ (NLP) เพื่อปรับปรุงกระบวนการเซมิคอนดักเตอร์โดยใช้เทคนิค ML อันล้ำสมัย ในเวลาว่าง เขาชอบเล่นหมากรุกและท่องเที่ยว คุณสามารถค้นหาปรานาฟได้ LinkedIn.
ปรานาฟ เมอร์ธี เป็นสถาปนิกโซลูชันผู้เชี่ยวชาญ AI/ML ที่ AWS เขามุ่งเน้นที่การช่วยเหลือลูกค้าในการสร้าง ฝึกอบรม ปรับใช้ และโยกย้ายปริมาณงานการเรียนรู้ของเครื่อง (ML) ไปยัง SageMaker ก่อนหน้านี้เขาเคยทำงานในอุตสาหกรรมเซมิคอนดักเตอร์ที่พัฒนาโมเดลคอมพิวเตอร์วิทัศน์ขนาดใหญ่ (CV) และการประมวลผลภาษาธรรมชาติ (NLP) เพื่อปรับปรุงกระบวนการเซมิคอนดักเตอร์โดยใช้เทคนิค ML อันล้ำสมัย ในเวลาว่าง เขาชอบเล่นหมากรุกและท่องเที่ยว คุณสามารถค้นหาปรานาฟได้ LinkedIn.
 วรุณ ชาห์ เป็นวิศวกรซอฟต์แวร์ที่ทำงานบน Amazon SageMaker Studio ที่ Amazon Web Services เขามุ่งเน้นไปที่การสร้างโซลูชัน ML แบบโต้ตอบ ซึ่งทำให้การประมวลผลข้อมูลและการเตรียมข้อมูลง่ายขึ้น ในเวลาว่าง วรุณจะสนุกกับกิจกรรมกลางแจ้งต่างๆ เช่น เดินป่าและเล่นสกี และพร้อมสำหรับการค้นพบสถานที่ใหม่ๆ ที่น่าตื่นเต้นอยู่เสมอ
วรุณ ชาห์ เป็นวิศวกรซอฟต์แวร์ที่ทำงานบน Amazon SageMaker Studio ที่ Amazon Web Services เขามุ่งเน้นไปที่การสร้างโซลูชัน ML แบบโต้ตอบ ซึ่งทำให้การประมวลผลข้อมูลและการเตรียมข้อมูลง่ายขึ้น ในเวลาว่าง วรุณจะสนุกกับกิจกรรมกลางแจ้งต่างๆ เช่น เดินป่าและเล่นสกี และพร้อมสำหรับการค้นพบสถานที่ใหม่ๆ ที่น่าตื่นเต้นอยู่เสมอ
 สุเมธา สวามี เป็นผู้จัดการผลิตภัณฑ์หลักที่ Amazon Web Services ซึ่งเขาเป็นผู้นำทีม SageMaker Studio ในภารกิจในการพัฒนา IDE ทางเลือกสำหรับวิทยาศาสตร์ข้อมูลและการเรียนรู้ของเครื่อง เขาได้ทุ่มเทตลอด 15 ปีที่ผ่านมาในการสร้างผลิตภัณฑ์สำหรับผู้บริโภคและองค์กรที่ใช้ Machine Learning
สุเมธา สวามี เป็นผู้จัดการผลิตภัณฑ์หลักที่ Amazon Web Services ซึ่งเขาเป็นผู้นำทีม SageMaker Studio ในภารกิจในการพัฒนา IDE ทางเลือกสำหรับวิทยาศาสตร์ข้อมูลและการเรียนรู้ของเครื่อง เขาได้ทุ่มเทตลอด 15 ปีที่ผ่านมาในการสร้างผลิตภัณฑ์สำหรับผู้บริโภคและองค์กรที่ใช้ Machine Learning
 บอสโก อัลบูเคอร์กี เป็น Sr. Partner Solutions Architect ที่ AWS และมีประสบการณ์มากกว่า 20 ปีในการทำงานกับฐานข้อมูลและผลิตภัณฑ์การวิเคราะห์จากผู้จำหน่ายฐานข้อมูลระดับองค์กรและผู้ให้บริการระบบคลาวด์ เขาช่วยบริษัทด้านเทคโนโลยีในการออกแบบและนำโซลูชันและผลิตภัณฑ์การวิเคราะห์ข้อมูลไปใช้
บอสโก อัลบูเคอร์กี เป็น Sr. Partner Solutions Architect ที่ AWS และมีประสบการณ์มากกว่า 20 ปีในการทำงานกับฐานข้อมูลและผลิตภัณฑ์การวิเคราะห์จากผู้จำหน่ายฐานข้อมูลระดับองค์กรและผู้ให้บริการระบบคลาวด์ เขาช่วยบริษัทด้านเทคโนโลยีในการออกแบบและนำโซลูชันและผลิตภัณฑ์การวิเคราะห์ข้อมูลไปใช้
- เนื้อหาที่ขับเคลื่อนด้วย SEO และการเผยแพร่ประชาสัมพันธ์ รับการขยายวันนี้
- PlatoData.Network Vertical Generative Ai เพิ่มพลังให้กับตัวเอง เข้าถึงได้ที่นี่.
- เพลโตไอสตรีม. Web3 อัจฉริยะ ขยายความรู้ เข้าถึงได้ที่นี่.
- เพลโตESG. คาร์บอน, คลีนเทค, พลังงาน, สิ่งแวดล้อม แสงอาทิตย์, การจัดการของเสีย. เข้าถึงได้ที่นี่.
- เพลโตสุขภาพ เทคโนโลยีชีวภาพและข่าวกรองการทดลองทางคลินิก เข้าถึงได้ที่นี่.
- ที่มา: https://aws.amazon.com/blogs/machine-learning/explore-data-with-ease-using-sql-and-text-to-sql-in-amazon-sagemaker-studio-jupyterlab-notebooks/

