ทุกวันนี้ ลูกค้าของทุกอุตสาหกรรม ไม่ว่าจะเป็นบริการทางการเงิน การดูแลสุขภาพและวิทยาศาสตร์ชีวภาพ การท่องเที่ยวและการบริการ สื่อและความบันเทิง โทรคมนาคม ซอฟต์แวร์ในฐานะบริการ (SaaS) และแม้แต่ผู้ให้บริการโมเดลที่เป็นกรรมสิทธิ์ ต่างก็ใช้โมเดลภาษาขนาดใหญ่ (LLM) เพื่อ สร้างแอปพลิเคชัน เช่น แชทบอทคำถามและคำตอบ (QnA) เครื่องมือค้นหา และฐานความรู้ เหล่านี้ AI กำเนิด แอปพลิเคชันไม่เพียงแต่ใช้เพื่อทำให้กระบวนการทางธุรกิจที่มีอยู่เป็นแบบอัตโนมัติเท่านั้น แต่ยังมีความสามารถในการเปลี่ยนแปลงประสบการณ์สำหรับลูกค้าที่ใช้แอปพลิเคชันเหล่านี้อีกด้วย ด้วยความก้าวหน้าที่เกิดขึ้นกับ LLM เช่น คำแนะนำ Mixtral-8x7Bอนุพันธ์ของสถาปัตยกรรมเช่น ส่วนผสมของผู้เชี่ยวชาญ (MoE)ลูกค้ามองหาวิธีปรับปรุงประสิทธิภาพและความแม่นยำของแอปพลิเคชัน AI เจนเนอเรชั่นอย่างต่อเนื่อง ขณะเดียวกันก็ช่วยให้พวกเขาใช้โมเดลโอเพ่นซอร์สและปิดที่หลากหลายได้อย่างมีประสิทธิภาพ
โดยทั่วไปจะใช้เทคนิคจำนวนหนึ่งเพื่อปรับปรุงความแม่นยำและประสิทธิภาพของเอาท์พุตของ LLM เช่น การปรับแต่งอย่างละเอียดด้วย การปรับพารามิเตอร์อย่างมีประสิทธิภาพ (PEFT), การเรียนรู้การเสริมแรงจากคำติชมของมนุษย์ (RLHF)และการแสดง การกลั่นความรู้- อย่างไรก็ตาม เมื่อสร้างแอปพลิเคชัน AI เชิงสร้างสรรค์ คุณสามารถใช้โซลูชันทางเลือกที่ช่วยให้สามารถรวบรวมความรู้ภายนอกแบบไดนามิก และช่วยให้คุณควบคุมข้อมูลที่ใช้ในการสร้างโดยไม่จำเป็นต้องปรับแต่งโมเดลพื้นฐานที่มีอยู่ของคุณอย่างละเอียด นี่คือจุดที่การดึงข้อมูล Augmented Generation (RAG) เข้ามามีบทบาท โดยเฉพาะสำหรับแอปพลิเคชัน AI เชิงสร้างสรรค์ ซึ่งต่างจากทางเลือกการปรับแต่งแบบละเอียดที่มีราคาแพงกว่าและแข็งแกร่งกว่าที่เราได้พูดคุยกัน หากคุณกำลังใช้แอปพลิเคชัน RAG ที่ซับซ้อนในงานประจำวันของคุณ คุณอาจเผชิญกับความท้าทายทั่วไปกับระบบ RAG ของคุณ เช่น การดึงข้อมูลไม่ถูกต้อง การเพิ่มขนาดและความซับซ้อนของเอกสาร และบริบทที่ล้นหลาม ซึ่งอาจส่งผลกระทบอย่างมากต่อคุณภาพและความน่าเชื่อถือของคำตอบที่สร้างขึ้น .
โพสต์นี้กล่าวถึงรูปแบบ RAG เพื่อปรับปรุงความแม่นยำในการตอบสนองโดยใช้ LangChain และเครื่องมือ เช่น ตัวเรียกเอกสารหลัก นอกเหนือจากเทคนิค เช่น การบีบอัดบริบท เพื่อให้นักพัฒนาสามารถปรับปรุงแอปพลิเคชัน AI ทั่วไปที่มีอยู่ได้
ภาพรวมโซลูชัน
ในโพสต์นี้ เราสาธิตการใช้การสร้างข้อความคำสั่ง Mixtral-8x7B รวมกับโมเดลการฝัง BGE Large En เพื่อสร้างระบบ RAG QnA บนสมุดบันทึก Amazon SageMaker อย่างมีประสิทธิภาพ โดยใช้เครื่องมือดึงเอกสารหลักและเทคนิคการบีบอัดตามบริบท แผนภาพต่อไปนี้แสดงสถาปัตยกรรมของโซลูชันนี้
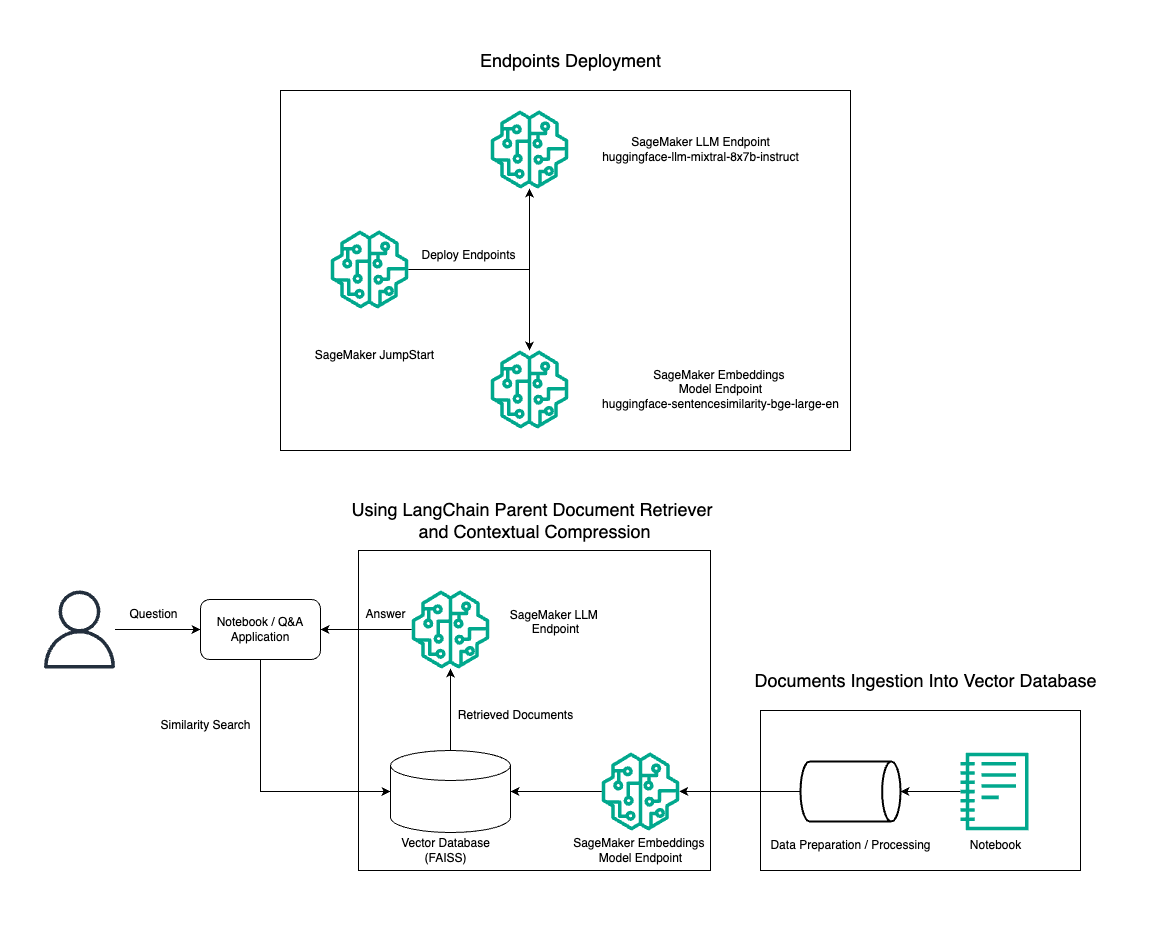
คุณสามารถปรับใช้โซลูชันนี้ได้ด้วยการคลิกเพียงไม่กี่ครั้ง Amazon SageMaker JumpStartซึ่งเป็นแพลตฟอร์มที่มีการจัดการเต็มรูปแบบที่นำเสนอโมเดลพื้นฐานที่ล้ำสมัยสำหรับกรณีการใช้งานต่างๆ เช่น การเขียนเนื้อหา การสร้างโค้ด การตอบคำถาม การเขียนคำโฆษณา การสรุป การจำแนกประเภท และการดึงข้อมูล โดยประกอบด้วยคอลเลกชันโมเดลที่ได้รับการฝึกอบรมล่วงหน้าซึ่งคุณสามารถปรับใช้ได้อย่างรวดเร็วและง่ายดาย ช่วยเร่งการพัฒนาและการปรับใช้แอปพลิเคชัน Machine Learning (ML) องค์ประกอบหลักอย่างหนึ่งของ SageMaker JumpStart คือ Model Hub ซึ่งมีแค็ตตาล็อกโมเดลที่ผ่านการฝึกอบรมมากมาย เช่น Mixtral-8x7B สำหรับงานที่หลากหลาย
Mixtral-8x7B ใช้สถาปัตยกรรม MoE สถาปัตยกรรมนี้ช่วยให้ส่วนต่างๆ ของโครงข่ายประสาทเทียมมีความเชี่ยวชาญในงานที่แตกต่างกัน โดยแบ่งภาระงานให้กับผู้เชี่ยวชาญหลายคนได้อย่างมีประสิทธิภาพ แนวทางนี้ช่วยให้สามารถฝึกอบรมและปรับใช้โมเดลขนาดใหญ่ได้อย่างมีประสิทธิภาพเมื่อเปรียบเทียบกับสถาปัตยกรรมแบบดั้งเดิม
ข้อดีหลักประการหนึ่งของสถาปัตยกรรม MoE คือความสามารถในการปรับขนาดได้ ด้วยการกระจายภาระงานไปยังผู้เชี่ยวชาญหลายราย โมเดล MoE จึงสามารถฝึกอบรมบนชุดข้อมูลขนาดใหญ่ และมีประสิทธิภาพที่ดีกว่าโมเดลดั้งเดิมที่มีขนาดเท่ากัน นอกจากนี้ แบบจำลอง MoE ยังมีประสิทธิภาพมากขึ้นในระหว่างการอนุมาน เนื่องจากจำเป็นต้องเปิดใช้งานผู้เชี่ยวชาญเพียงบางส่วนเท่านั้นสำหรับอินพุตที่กำหนด
สำหรับข้อมูลเพิ่มเติมเกี่ยวกับคำสั่ง Mixtral-8x7B บน AWS โปรดดูที่ Mixtral-8x7B พร้อมใช้งานแล้วใน Amazon SageMaker JumpStart- รุ่น Mixtral-8x7B จัดทำขึ้นภายใต้ลิขสิทธิ์ Apache 2.0 ที่ได้รับอนุญาต เพื่อการใช้งานโดยไม่มีข้อจำกัด
ในโพสต์นี้ เราจะหารือเกี่ยวกับวิธีการใช้งานของคุณ หลังเชน เพื่อสร้างแอปพลิเคชัน RAG ที่มีประสิทธิภาพและมีประสิทธิภาพมากขึ้น LangChain เป็นไลบรารี Python แบบโอเพ่นซอร์สที่ออกแบบมาเพื่อสร้างแอปพลิเคชันด้วย LLM โดยมีเฟรมเวิร์กแบบแยกส่วนและยืดหยุ่นสำหรับการรวม LLM เข้ากับส่วนประกอบอื่นๆ เช่น ฐานความรู้ ระบบการดึงข้อมูล และเครื่องมือ AI อื่นๆ เพื่อสร้างแอปพลิเคชันที่ทรงพลังและปรับแต่งได้
เราอธิบายเกี่ยวกับการสร้างไปป์ไลน์ RAG บน SageMaker ด้วย Mixtral-8x7B เราใช้โมเดลการสร้างข้อความคำสั่ง Mixtral-8x7B กับโมเดลการฝัง BGE Large En เพื่อสร้างระบบ QnA ที่มีประสิทธิภาพโดยใช้ RAG บนโน้ตบุ๊ก SageMaker เราใช้อินสแตนซ์ ml.t3.medium เพื่อสาธิตการปรับใช้ LLM ผ่าน SageMaker JumpStart ซึ่งสามารถเข้าถึงได้ผ่านตำแหน่งข้อมูล API ที่ SageMaker สร้างขึ้น การตั้งค่านี้ช่วยให้สามารถสำรวจ ทดลอง และเพิ่มประสิทธิภาพเทคนิค RAG ขั้นสูงด้วย LangChain นอกจากนี้เรายังแสดงให้เห็นการรวมร้านค้า FAISS Embedding เข้ากับเวิร์กโฟลว์ RAG โดยเน้นบทบาทในการจัดเก็บและเรียกข้อมูลการฝังเพื่อปรับปรุงประสิทธิภาพของระบบ
เราดำเนินการคำแนะนำสั้นๆ เกี่ยวกับสมุดบันทึก SageMaker สำหรับคำแนะนำโดยละเอียดและทีละขั้นตอน โปรดดูที่ รูปแบบ RAG ขั้นสูงพร้อม Mixtral บน SageMaker Jumpstart GitHub repo.
ความต้องการรูปแบบ RAG ขั้นสูง
รูปแบบ RAG ขั้นสูงถือเป็นสิ่งสำคัญในการปรับปรุงความสามารถในปัจจุบันของ LLM ในการประมวลผล การทำความเข้าใจ และสร้างข้อความที่เหมือนมนุษย์ เมื่อขนาดและความซับซ้อนของเอกสารเพิ่มขึ้น การแสดงหลายแง่มุมของเอกสารในการฝังเพียงครั้งเดียวอาจทำให้สูญเสียความเฉพาะเจาะจงได้ แม้ว่าการระบุสาระสำคัญโดยทั่วไปของเอกสารจะเป็นสิ่งสำคัญ แต่การรับรู้และนำเสนอบริบทย่อยต่างๆ ภายในก็มีความสำคัญไม่แพ้กัน นี่เป็นความท้าทายที่คุณมักเผชิญเมื่อทำงานกับเอกสารขนาดใหญ่ ความท้าทายอีกประการหนึ่งของ RAG ก็คือในการดึงข้อมูล คุณจะไม่ทราบถึงคำถามเฉพาะเจาะจงที่ระบบจัดเก็บเอกสารของคุณจะต้องจัดการเมื่อนำเข้า ซึ่งอาจส่งผลให้ข้อมูลที่เกี่ยวข้องกับข้อความค้นหาถูกฝังอยู่ใต้ข้อความมากที่สุด (บริบทล้น) เพื่อลดความล้มเหลวและปรับปรุงสถาปัตยกรรม RAG ที่มีอยู่ คุณสามารถใช้รูปแบบ RAG ขั้นสูง (การเรียกเอกสารหลักและการบีบอัดบริบท) เพื่อลดข้อผิดพลาดในการเรียกข้อมูล ปรับปรุงคุณภาพคำตอบ และเปิดใช้งานการจัดการคำถามที่ซับซ้อน
ด้วยเทคนิคที่กล่าวถึงในโพสต์นี้ คุณสามารถจัดการกับความท้าทายหลักที่เกี่ยวข้องกับการดึงข้อมูลและการบูรณาการความรู้จากภายนอก ทำให้แอปพลิเคชันของคุณสามารถส่งมอบการตอบสนองที่แม่นยำและรับรู้ตามบริบทมากขึ้น
ในส่วนต่อไปนี้ เราจะสำรวจวิธีการ การดึงเอกสารหลัก และ การบีบอัดตามบริบท สามารถช่วยคุณจัดการกับปัญหาบางอย่างที่เราได้พูดคุยไปแล้ว
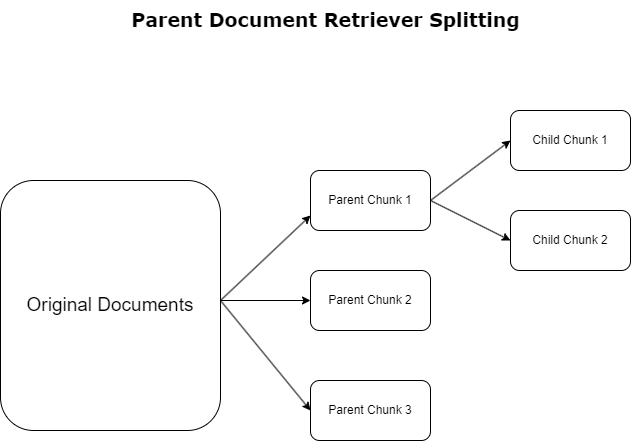
ตัวเรียกเอกสารหลัก
ในส่วนก่อนหน้านี้ เราได้เน้นย้ำถึงความท้าทายที่แอปพลิเคชัน RAG เผชิญเมื่อต้องจัดการกับเอกสารจำนวนมาก เพื่อจัดการกับความท้าทายเหล่านี้ การดึงเอกสารหลัก จัดหมวดหมู่และกำหนดเอกสารขาเข้าเป็น เอกสารผู้ปกครอง- เอกสารเหล่านี้ได้รับการยอมรับว่ามีลักษณะครอบคลุมแต่ไม่ได้นำไปใช้โดยตรงในรูปแบบดั้งเดิมสำหรับการฝัง แทนที่จะบีบอัดเอกสารทั้งหมดเป็นการฝังตัวเดียว ตัวเรียกเอกสารหลักจะแยกเอกสารหลักเหล่านี้ออกเป็น เอกสารเด็ก- เอกสารย่อยแต่ละฉบับจะรวบรวมแง่มุมหรือหัวข้อที่แตกต่างกันจากเอกสารหลักที่กว้างขึ้น หลังจากการระบุกลุ่มย่อยเหล่านี้แล้ว การฝังแต่ละรายการจะถูกมอบหมายให้กับแต่ละกลุ่ม โดยจับแก่นแท้เฉพาะของส่วนย่อยเหล่านั้น (ดูแผนภาพต่อไปนี้) ในระหว่างการเรียกข้อมูล เอกสารหลักจะถูกเรียกใช้ เทคนิคนี้ให้ความสามารถในการค้นหาที่ตรงเป้าหมายแต่หลากหลาย ทำให้ LLM มีมุมมองที่กว้างขึ้น การดึงเอกสารหลักช่วยให้ LLM มีข้อได้เปรียบสองเท่า: ความเฉพาะเจาะจงของการฝังเอกสารลูกเพื่อการเรียกค้นข้อมูลที่แม่นยำและเกี่ยวข้อง ควบคู่ไปกับการเรียกใช้เอกสารหลักสำหรับการสร้างการตอบสนอง ซึ่งจะทำให้ผลลัพธ์ของ LLM สมบูรณ์ด้วยบริบทแบบเลเยอร์และละเอียดถี่ถ้วน
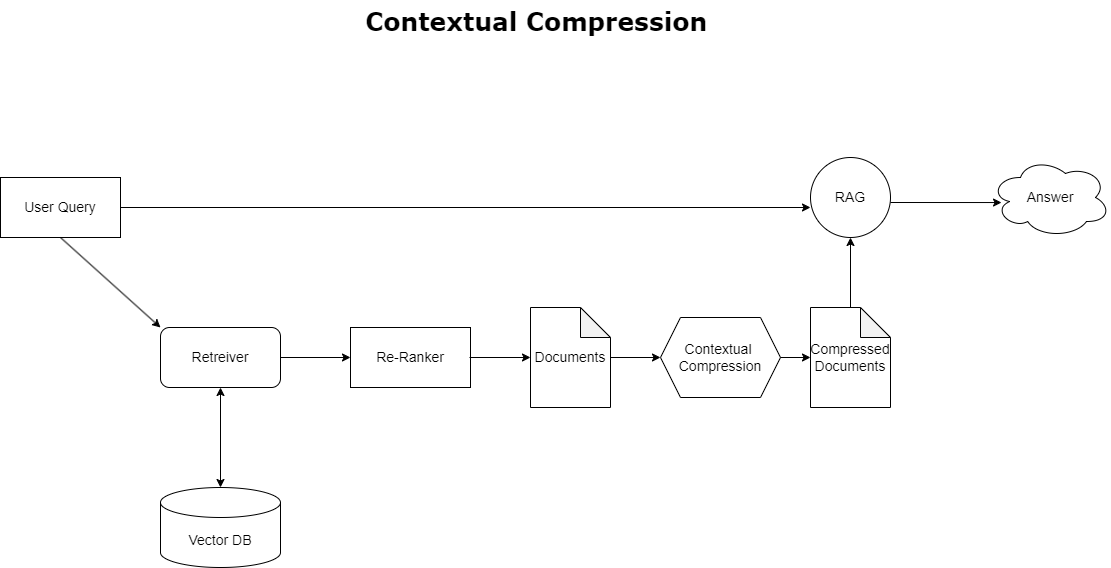
การบีบอัดตามบริบท
คุณสามารถใช้เพื่อแก้ไขปัญหาบริบทล้นที่กล่าวถึงก่อนหน้านี้ การบีบอัดตามบริบท เพื่อบีบอัดและกรองเอกสารที่ดึงมาให้สอดคล้องกับบริบทของการสืบค้น ดังนั้นจะเก็บและประมวลผลเฉพาะข้อมูลที่เกี่ยวข้องเท่านั้น ซึ่งสามารถทำได้โดยการผสมผสานระหว่างตัวดึงข้อมูลพื้นฐานสำหรับการดึงเอกสารเริ่มต้น และตัวบีบอัดเอกสารสำหรับการปรับแต่งเอกสารเหล่านี้ โดยการแยกเนื้อหาออกหรือแยกออกทั้งหมดตามความเกี่ยวข้อง ดังที่แสดงในแผนภาพต่อไปนี้ แนวทางที่ได้รับการปรับปรุงให้ดีขึ้นนี้ ซึ่งอำนวยความสะดวกโดยตัวดึงข้อมูลการบีบอัดตามบริบท ช่วยเพิ่มประสิทธิภาพการใช้งาน RAG ได้อย่างมาก ด้วยการจัดเตรียมวิธีการแยกและใช้เฉพาะสิ่งที่จำเป็นจากข้อมูลจำนวนมาก โดยจะจัดการกับปัญหาข้อมูลล้นเกินและการประมวลผลข้อมูลที่ไม่เกี่ยวข้องโดยตรง ซึ่งนำไปสู่คุณภาพการตอบสนองที่ดีขึ้น การดำเนินงาน LLM ที่คุ้มต้นทุนมากขึ้น และกระบวนการดึงข้อมูลโดยรวมที่ราบรื่นยิ่งขึ้น โดยพื้นฐานแล้ว มันเป็นตัวกรองที่ปรับแต่งข้อมูลให้เหมาะกับการสืบค้นที่มีอยู่ ทำให้เป็นเครื่องมือที่มีความจำเป็นมากสำหรับนักพัฒนาที่ต้องการเพิ่มประสิทธิภาพแอปพลิเคชัน RAG เพื่อประสิทธิภาพที่ดีขึ้นและความพึงพอใจของผู้ใช้
เบื้องต้น
หากคุณยังใหม่กับ SageMaker โปรดดูที่ คู่มือการพัฒนา Amazon SageMaker.
ก่อนที่คุณจะเริ่มใช้โซลูชัน สร้างบัญชี AWS- เมื่อคุณสร้างบัญชี AWS คุณจะได้รับข้อมูลระบุตัวตนการลงชื่อเพียงครั้งเดียว (SSO) ที่สามารถเข้าถึงบริการและทรัพยากรของ AWS ทั้งหมดในบัญชีได้อย่างสมบูรณ์ ข้อมูลประจำตัวนี้เรียกว่าบัญชี AWS ผู้ใช้ root.
ลงชื่อเข้าใช้ คอนโซลการจัดการ AWS การใช้ที่อยู่อีเมลและรหัสผ่านที่คุณใช้สร้างบัญชีจะทำให้คุณสามารถเข้าถึงทรัพยากร AWS ทั้งหมดในบัญชีของคุณได้อย่างสมบูรณ์ เราขอแนะนำอย่างยิ่งให้คุณอย่าใช้ผู้ใช้รูทสำหรับงานประจำวัน แม้แต่งานด้านการดูแลระบบก็ตาม
แทนที่จะยึดถือ. แนวทางปฏิบัติที่ดีที่สุดด้านความปลอดภัย in AWS Identity และการจัดการการเข้าถึง (ไอเอเอ็ม) และ สร้างผู้ใช้และกลุ่มผู้ดูแลระบบ- จากนั้นล็อคข้อมูลรับรองผู้ใช้รูทอย่างปลอดภัย และใช้ข้อมูลเหล่านี้เพื่อดำเนินการบัญชีและบริการการจัดการเพียงไม่กี่อย่างเท่านั้น
โมเดล Mixtral-8x7b ต้องใช้อินสแตนซ์ ml.g5.48xlarge SageMaker JumpStart มอบวิธีที่ง่ายขึ้นในการเข้าถึงและปรับใช้โมเดลพื้นฐานโอเพ่นซอร์สและบุคคลที่สามที่แตกต่างกันมากกว่า 100 แบบ เพื่อที่จะ เปิดใช้ตำแหน่งข้อมูลเพื่อโฮสต์ Mixtral-8x7B จาก SageMaker JumpStartคุณอาจต้องขอเพิ่มโควต้าบริการเพื่อเข้าถึงอินสแตนซ์ ml.g5.48xlarge สำหรับการใช้งานตำแหน่งข้อมูล คุณสามารถ ขอโควต้าบริการเพิ่มขึ้น ผ่านคอนโซล อินเทอร์เฟซบรรทัดคำสั่ง AWS AWS (AWS CLI) หรือ API เพื่ออนุญาตการเข้าถึงทรัพยากรเพิ่มเติมเหล่านั้น
ตั้งค่าอินสแตนซ์โน้ตบุ๊ก SageMaker และติดตั้งการขึ้นต่อกัน
ในการเริ่มต้น ให้สร้างอินสแตนซ์โน้ตบุ๊ก SageMaker และติดตั้งการขึ้นต่อกันที่จำเป็น อ้างถึง repo GitHub เพื่อให้แน่ใจว่าการตั้งค่าจะสำเร็จ หลังจากที่คุณตั้งค่าอินสแตนซ์โน้ตบุ๊กแล้ว คุณสามารถปรับใช้โมเดลได้
คุณยังสามารถเรียกใช้โน้ตบุ๊กแบบโลคัลบนสภาพแวดล้อมการพัฒนาแบบรวม (IDE) ที่คุณต้องการได้ ตรวจสอบให้แน่ใจว่าคุณได้ติดตั้งแล็บโน้ตบุ๊ก Jupyter แล้ว
ปรับใช้โมเดล
ปรับใช้โมเดล Mixtral-8X7B Instruct LLM บน SageMaker JumpStart:
ปรับใช้โมเดลการฝัง BGE Large En บน SageMaker JumpStart:
ตั้งค่า LangChain
หลังจากนำเข้าไลบรารีที่จำเป็นทั้งหมดและปรับใช้โมเดล Mixtral-8x7B และโมเดลการฝัง BGE Large En แล้ว ตอนนี้คุณสามารถตั้งค่า LangChain ได้แล้ว สำหรับคำแนะนำทีละขั้นตอน โปรดดูที่ repo GitHub.
การเตรียมข้อมูล
ในโพสต์นี้ เราใช้จดหมายถึงผู้ถือหุ้นของ Amazon หลายปีถึงผู้ถือหุ้นเป็นคลังข้อความในการดำเนินการ QnA สำหรับขั้นตอนโดยละเอียดเพิ่มเติมในการเตรียมข้อมูล โปรดดูที่ repo GitHub.
ตอบคำถาม
เมื่อเตรียมข้อมูลแล้ว คุณสามารถใช้ wrapper ที่ LangChain เตรียมไว้ให้ ซึ่งจะพันรอบ vector store และรับอินพุตสำหรับ LLM Wrapper นี้ดำเนินการตามขั้นตอนต่อไปนี้:
- ตอบคำถามอินพุต
- สร้างการฝังคำถาม
- ดึงเอกสารที่เกี่ยวข้อง
- รวมเอกสารและคำถามไว้ในพร้อมท์
- เรียกใช้โมเดลพร้อมท์และสร้างคำตอบในลักษณะที่อ่านง่าย
ขณะนี้มีร้านค้าเวกเตอร์แล้ว คุณสามารถเริ่มถามคำถามได้:
ห่วงโซ่รีทรีฟเวอร์แบบปกติ
ในสถานการณ์ก่อนหน้านี้ เราได้สำรวจวิธีที่รวดเร็วและตรงไปตรงมาในการรับคำตอบตามบริบทสำหรับคำถามของคุณ ตอนนี้เรามาดูตัวเลือกที่ปรับแต่งได้มากขึ้นด้วยความช่วยเหลือของ RetrievalQA ซึ่งคุณสามารถปรับแต่งวิธีการเพิ่มเอกสารที่ดึงมาในพร้อมต์ได้โดยใช้พารามิเตอร์ chain_type นอกจากนี้ เพื่อควบคุมจำนวนเอกสารที่เกี่ยวข้องที่ควรดึงข้อมูล คุณสามารถเปลี่ยนพารามิเตอร์ k ในโค้ดต่อไปนี้เพื่อดูผลลัพธ์ที่แตกต่างกัน ในหลายสถานการณ์ คุณอาจต้องการทราบว่า LLM ใช้เอกสารต้นฉบับใดในการสร้างคำตอบ คุณสามารถรับเอกสารเหล่านั้นในผลลัพธ์โดยใช้ return_source_documentsซึ่งส่งคืนเอกสารที่เพิ่มในบริบทของพรอมต์ LLM RestorealQA ยังช่วยให้คุณสามารถจัดเตรียมเทมเพลตพร้อมท์แบบกำหนดเองที่สามารถเฉพาะเจาะจงกับโมเดลได้
ลองถามคำถาม:
ห่วงโซ่การดึงเอกสารหลัก
ลองดูตัวเลือก RAG ขั้นสูงเพิ่มเติมด้วยความช่วยเหลือ ParentDocumentRetriever- เมื่อทำงานกับการดึงเอกสาร คุณอาจพบกับข้อเสียระหว่างการจัดเก็บเอกสารชิ้นเล็กๆ เพื่อการฝังที่แม่นยำ และเอกสารขนาดใหญ่เพื่อรักษาบริบทมากขึ้น โปรแกรมเรียกเอกสารหลักสร้างความสมดุลด้วยการแยกและจัดเก็บข้อมูลชิ้นเล็กๆ
เราใช้ a parent_splitter เพื่อแบ่งเอกสารต้นฉบับออกเป็นชิ้นใหญ่เรียกว่าเอกสารหลักและก child_splitter เพื่อสร้างเอกสารลูกที่มีขนาดเล็กลงจากเอกสารต้นฉบับ:
จากนั้นเอกสารย่อยจะถูกจัดทำดัชนีในร้านค้าเวกเตอร์โดยใช้การฝัง ช่วยให้สามารถดึงเอกสารย่อยที่เกี่ยวข้องได้อย่างมีประสิทธิภาพโดยยึดตามความคล้ายคลึงกัน ในการดึงข้อมูลที่เกี่ยวข้อง ตัวเรียกเอกสารหลักจะดึงเอกสารลูกจากร้านค้าเวกเตอร์ก่อน จากนั้นจะค้นหารหัสพาเรนต์สำหรับเอกสารย่อยเหล่านั้น และส่งกลับเอกสารพาเรนต์ที่มีขนาดใหญ่กว่าที่เกี่ยวข้อง
ลองถามคำถาม:
ห่วงโซ่การบีบอัดตามบริบท
ลองดูตัวเลือก RAG ขั้นสูงอื่นที่เรียกว่า การบีบอัดตามบริบท- ความท้าทายประการหนึ่งในการเรียกค้นคือ โดยปกติแล้วเราจะไม่ทราบคำถามเฉพาะเจาะจงที่ระบบจัดเก็บเอกสารของคุณจะต้องเผชิญเมื่อคุณนำเข้าข้อมูลเข้าสู่ระบบ ซึ่งหมายความว่าข้อมูลที่เกี่ยวข้องกับแบบสอบถามมากที่สุดอาจถูกฝังอยู่ในเอกสารที่มีข้อความที่ไม่เกี่ยวข้องจำนวนมาก การส่งเอกสารฉบับเต็มผ่านใบสมัครของคุณอาจทำให้การโทร LLM มีราคาแพงขึ้นและการตอบกลับที่แย่ลง
ตัวดึงข้อมูลการบีบอัดตามบริบทจัดการกับความท้าทายในการดึงข้อมูลที่เกี่ยวข้องจากระบบจัดเก็บเอกสาร ซึ่งข้อมูลที่เกี่ยวข้องอาจถูกฝังอยู่ในเอกสารที่มีข้อความจำนวนมาก โดยการบีบอัดและกรองเอกสารที่ดึงมาตามบริบทการสืบค้นที่กำหนด ระบบจะส่งกลับเฉพาะข้อมูลที่เกี่ยวข้องมากที่สุดเท่านั้น
หากต้องการใช้ตัวดึงข้อมูลการบีบอัดตามบริบท คุณจะต้องมี:
- รีทรีฟเวอร์แบบฐาน – นี่คือรีทรีฟเวอร์เริ่มต้นที่ดึงเอกสารจากระบบจัดเก็บข้อมูลตามแบบสอบถาม
- เครื่องอัดเอกสาร – ส่วนประกอบนี้จะนำเอกสารที่ดึงมาในตอนแรกมาและทำให้สั้นลงโดยการลดเนื้อหาของเอกสารแต่ละฉบับหรือทิ้งเอกสารที่ไม่เกี่ยวข้องออกไปทั้งหมด โดยใช้บริบทแบบสอบถามเพื่อกำหนดความเกี่ยวข้อง
การเพิ่มการบีบอัดตามบริบทด้วยตัวแยกลูกโซ่ LLM
ขั้นแรก ให้พันเบสรีทรีฟเวอร์ของคุณด้วย ContextualCompressionRetriever- คุณจะเพิ่ม LLMChainExtractorซึ่งจะวนซ้ำเอกสารที่ส่งคืนในตอนแรก และแยกเฉพาะเนื้อหาที่เกี่ยวข้องกับแบบสอบถามออกจากแต่ละเอกสารเท่านั้น
เริ่มต้นห่วงโซ่โดยใช้ ContextualCompressionRetriever ด้วย LLMChainExtractor และส่งข้อความแจ้งผ่านทาง chain_type_kwargs ข้อโต้แย้ง.
ลองถามคำถาม:
กรองเอกสารด้วยตัวกรองลูกโซ่ LLM
พื้นที่ LLMChainFilter เป็นคอมเพรสเซอร์ที่เรียบง่ายกว่าเล็กน้อยแต่แข็งแกร่งกว่าซึ่งใช้สายโซ่ LLM เพื่อตัดสินใจว่าเอกสารใดที่ดึงมาในตอนแรกที่จะกรองออก และเอกสารใดที่จะส่งคืน โดยไม่ต้องจัดการเนื้อหาของเอกสาร:
เริ่มต้นห่วงโซ่โดยใช้ ContextualCompressionRetriever ด้วย LLMChainFilter และส่งข้อความแจ้งผ่านทาง chain_type_kwargs ข้อโต้แย้ง.
ลองถามคำถาม:
เปรียบเทียบผลลัพธ์
ตารางต่อไปนี้เปรียบเทียบผลลัพธ์จากการสืบค้นที่แตกต่างกันตามเทคนิค
| เทคนิค | แบบสอบถาม 1 | แบบสอบถาม 2 | การเปรียบเทียบ |
| AWS พัฒนาไปอย่างไร? | ทำไม Amazon ถึงประสบความสำเร็จ? | ||
| เอาท์พุตโซ่รีทรีฟเวอร์แบบปกติ | AWS (Amazon Web Services) พัฒนาจากการลงทุนที่ไม่ทำกำไรในตอนแรก มาเป็นธุรกิจที่มีอัตราการสร้างรายได้ต่อปีที่ 85 พันล้านดอลลาร์พร้อมความสามารถในการทำกำไรที่แข็งแกร่ง โดยนำเสนอบริการและคุณสมบัติที่หลากหลาย และกลายเป็นส่วนสำคัญของพอร์ตโฟลิโอของ Amazon แม้จะเผชิญกับความกังขาและอุปสรรคในระยะสั้น แต่ AWS ยังคงสร้างสรรค์สิ่งใหม่ๆ ดึงดูดลูกค้าใหม่ๆ และย้ายลูกค้าที่ใช้งานอยู่ โดยนำเสนอคุณประโยชน์ต่างๆ เช่น ความคล่องตัว นวัตกรรม ความคุ้มทุน และความปลอดภัย AWS ยังขยายการลงทุนระยะยาว รวมถึงการพัฒนาชิป เพื่อมอบความสามารถใหม่ๆ และเปลี่ยนแปลงสิ่งที่เป็นไปได้สำหรับลูกค้า | Amazon ประสบความสำเร็จเนื่องจากนวัตกรรมอย่างต่อเนื่องและการขยายไปสู่พื้นที่ใหม่ๆ เช่น บริการโครงสร้างพื้นฐานด้านเทคโนโลยี อุปกรณ์การอ่านดิจิทัล ผู้ช่วยส่วนตัวที่ขับเคลื่อนด้วยเสียง และโมเดลธุรกิจใหม่ เช่น ตลาดบุคคลที่สาม ความสามารถในการปรับขนาดการดำเนินงานได้อย่างรวดเร็ว ดังที่เห็นได้จากการขยายตัวอย่างรวดเร็วของเครือข่ายคลังสินค้าและการขนส่ง ก็มีส่วนช่วยให้ประสบความสำเร็จเช่นกัน นอกจากนี้ การมุ่งเน้นของ Amazon ในเรื่องการปรับให้เหมาะสมและการเพิ่มประสิทธิภาพในกระบวนการส่งผลให้มีการปรับปรุงประสิทธิภาพการผลิตและลดต้นทุน ตัวอย่างของ Amazon Business เน้นย้ำถึงความสามารถของบริษัทในการใช้ประโยชน์จากจุดแข็งด้านอีคอมเมิร์ซและโลจิสติกส์ในภาคส่วนต่างๆ | จากการตอบกลับจากสายการดึงข้อมูลปกติ เราสังเกตเห็นว่าถึงแม้จะให้คำตอบที่ยาว แต่ก็ประสบปัญหาบริบทล้นและไม่ได้กล่าวถึงรายละเอียดที่สำคัญใดๆ จากคลังข้อมูลเกี่ยวกับการตอบสนองต่อคำค้นหาที่ให้ไว้ ห่วงโซ่การดึงข้อมูลตามปกติไม่สามารถจับความแตกต่างด้วยข้อมูลเชิงลึกหรือข้อมูลเชิงลึกตามบริบท ซึ่งอาจขาดประเด็นสำคัญในเอกสาร |
| เอาต์พุตตัวดึงเอกสารหลัก | AWS (Amazon Web Services) เริ่มต้นด้วยการเปิดตัวบริการ Elastic Compute Cloud (EC2) ครั้งแรกที่มีฟีเจอร์ไม่ดีในปี 2006 โดยมีขนาดอินสแตนซ์เพียงขนาดเดียวในศูนย์ข้อมูลเดียว ในภูมิภาคหนึ่งของโลก โดยมีอินสแตนซ์ระบบปฏิบัติการ Linux เท่านั้น และไม่มีฟีเจอร์หลักๆ มากมาย เช่น การตรวจสอบ โหลดบาลานซ์ การปรับขนาดอัตโนมัติ หรือการจัดเก็บข้อมูลถาวร อย่างไรก็ตาม ความสำเร็จของ AWS ช่วยให้พวกเขาสามารถทำซ้ำได้อย่างรวดเร็วและเพิ่มความสามารถที่ขาดหายไป ในที่สุดก็ขยายออกไปเพื่อนำเสนอรสชาติ ขนาด และการเพิ่มประสิทธิภาพการประมวลผล พื้นที่จัดเก็บ และเครือข่ายที่หลากหลาย รวมถึงการพัฒนาชิปของตัวเอง (Graviton) เพื่อผลักดันราคาและประสิทธิภาพให้ก้าวไกลยิ่งขึ้น . กระบวนการสร้างสรรค์นวัตกรรมแบบวนซ้ำของ AWS จำเป็นต้องมีการลงทุนจำนวนมากในด้านการเงินและทรัพยากรบุคคลในช่วง 20 ปี ซึ่งมักจะล่วงหน้าก่อนว่าจะจ่ายเมื่อใด เพื่อตอบสนองความต้องการของลูกค้าและปรับปรุงประสบการณ์ลูกค้า ความภักดี และผลตอบแทนในระยะยาวของลูกค้า | Amazon ประสบความสำเร็จเนื่องจากความสามารถในการสร้างสรรค์สิ่งใหม่ๆ อย่างต่อเนื่อง ปรับตัวให้เข้ากับสภาวะตลาดที่เปลี่ยนแปลง และตอบสนองความต้องการของลูกค้าในตลาดกลุ่มต่างๆ สิ่งนี้เห็นได้ชัดในความสำเร็จของ Amazon Business ซึ่งเติบโตขึ้นจนสามารถผลักดันยอดขายรวมต่อปีได้ประมาณ 35 พันล้านเหรียญสหรัฐ โดยการส่งมอบตัวเลือก มูลค่า และความสะดวกสบายให้กับลูกค้าธุรกิจ การลงทุนของ Amazon ในด้านความสามารถด้านอีคอมเมิร์ซและลอจิสติกส์ยังทำให้เกิดการสร้างบริการต่างๆ เช่น Buy with Prime ซึ่งช่วยให้ผู้ค้าที่มีเว็บไซต์ที่เข้าถึงผู้บริโภคโดยตรงขับเคลื่อนการเปลี่ยนแปลงจากการดูไปสู่การซื้อ | โปรแกรมดึงเอกสารหลักจะเจาะลึกลงไปในกลยุทธ์การเติบโตของ AWS โดยเฉพาะ รวมถึงกระบวนการทำซ้ำในการเพิ่มคุณสมบัติใหม่ตามความคิดเห็นของลูกค้า และการเดินทางโดยละเอียดตั้งแต่การเปิดตัวครั้งแรกที่มีฟีเจอร์ไม่ดีไปจนถึงตำแหน่งทางการตลาดที่โดดเด่น ขณะเดียวกันก็ให้การตอบสนองที่มีบริบทมากมาย . คำตอบครอบคลุมหลากหลายแง่มุม ตั้งแต่นวัตกรรมทางเทคนิคและกลยุทธ์การตลาดไปจนถึงประสิทธิภาพขององค์กรและการมุ่งเน้นที่ลูกค้า โดยให้มุมมองแบบองค์รวมของปัจจัยที่มีส่วนทำให้เกิดความสำเร็จพร้อมทั้งตัวอย่าง สาเหตุนี้สามารถนำมาประกอบกับความสามารถในการค้นหาที่กำหนดเป้าหมายแต่เป็นวงกว้างของตัวเรียกเอกสารหลัก |
| LLM Chain Extractor: เอาต์พุตการบีบอัดตามบริบท | AWS พัฒนาโดยการเริ่มต้นเป็นโครงการขนาดเล็กภายใน Amazon ซึ่งต้องใช้เงินลงทุนจำนวนมากและเผชิญกับความกังขาจากทั้งภายในและภายนอกบริษัท อย่างไรก็ตาม AWS มีข้อได้เปรียบเหนือคู่แข่งที่มีศักยภาพและเชื่อมั่นในคุณค่าที่ AWS สามารถนำมาสู่ลูกค้าและ Amazon ได้ AWS ให้คำมั่นสัญญาระยะยาวที่จะลงทุนต่อไป ส่งผลให้มีฟีเจอร์และบริการใหม่ๆ มากกว่า 3,300 รายการที่เปิดตัวในปี 2022 AWS ได้เปลี่ยนแปลงวิธีที่ลูกค้าจัดการโครงสร้างพื้นฐานด้านเทคโนโลยีของตน และกลายเป็นธุรกิจที่มีอัตราการสร้างรายได้ต่อปีที่ 85 พันล้านดอลลาร์พร้อมความสามารถในการทำกำไรที่แข็งแกร่ง AWS ยังได้ปรับปรุงข้อเสนออย่างต่อเนื่อง เช่น การปรับปรุง EC2 ด้วยคุณสมบัติและบริการเพิ่มเติมหลังจากเปิดตัวครั้งแรก | จากบริบทที่ให้มา ความสำเร็จของ Amazon สามารถนำมาประกอบกับการขยายเชิงกลยุทธ์จากแพลตฟอร์มการขายหนังสือไปสู่ตลาดโลกที่มีระบบนิเวศผู้ขายบุคคลที่สามที่มีชีวิตชีวา การลงทุนในช่วงต้นใน AWS นวัตกรรมในการแนะนำ Kindle และ Alexa และการเติบโตที่สำคัญ ในรายได้ต่อปีตั้งแต่ปี 2019 ถึง 2022 การเติบโตนี้นำไปสู่การขยายขอบเขตของศูนย์ปฏิบัติตาม การสร้างเครือข่ายการขนส่งระยะทางสุดท้าย และการสร้างเครือข่ายศูนย์คัดแยกใหม่ ซึ่งได้รับการปรับให้เหมาะสมเพื่อประสิทธิภาพการผลิตและการลดต้นทุน | เครื่องสกัดโซ่ LLM รักษาสมดุลระหว่างการครอบคลุมประเด็นสำคัญอย่างครอบคลุมและการหลีกเลี่ยงความลึกที่ไม่จำเป็น โดยจะปรับตามบริบทของการสืบค้นแบบไดนามิก ดังนั้นผลลัพธ์จึงมีความเกี่ยวข้องและครอบคลุมโดยตรง |
| ตัวกรองลูกโซ่ LLM: เอาต์พุตการบีบอัดตามบริบท | AWS (Amazon Web Services) พัฒนาขึ้นโดยการเปิดตัวฟีเจอร์ที่ไม่ดีในตอนแรก แต่ทำซ้ำอย่างรวดเร็วตามความคิดเห็นของลูกค้าเพื่อเพิ่มความสามารถที่จำเป็น แนวทางนี้ทำให้ AWS เปิดตัว EC2 ในปี 2006 ด้วยคุณสมบัติที่จำกัด จากนั้นจึงเพิ่มฟังก์ชันการทำงานใหม่ๆ อย่างต่อเนื่อง เช่น ขนาดอินสแตนซ์เพิ่มเติม ศูนย์ข้อมูล ภูมิภาค ตัวเลือกระบบปฏิบัติการ เครื่องมือตรวจสอบ โหลดบาลานซ์ การปรับขนาดอัตโนมัติ และพื้นที่จัดเก็บข้อมูลถาวร เมื่อเวลาผ่านไป AWS เปลี่ยนจากบริการที่มีฟีเจอร์ต่ำไปเป็นธุรกิจที่มีมูลค่าหลายพันล้านดอลลาร์โดยมุ่งเน้นไปที่ความต้องการของลูกค้า ความคล่องตัว นวัตกรรม ความคุ้มทุน และความปลอดภัย ปัจจุบัน AWS มีอัตราการสร้างรายได้ต่อปีที่ 85 พันล้านดอลลาร์ และนำเสนอฟีเจอร์และบริการใหม่มากกว่า 3,300 รายการในแต่ละปี เพื่อรองรับลูกค้าที่หลากหลายตั้งแต่บริษัทสตาร์ทอัพไปจนถึงบริษัทข้ามชาติและองค์กรภาครัฐ | Amazon ประสบความสำเร็จด้วยโมเดลธุรกิจที่เป็นนวัตกรรม ความก้าวหน้าทางเทคโนโลยีอย่างต่อเนื่อง และการเปลี่ยนแปลงเชิงกลยุทธ์ขององค์กร บริษัทได้เปลี่ยนแปลงอุตสาหกรรมแบบดั้งเดิมอย่างต่อเนื่องด้วยการนำเสนอแนวคิดใหม่ๆ เช่น แพลตฟอร์มอีคอมเมิร์ซสำหรับผลิตภัณฑ์และบริการต่างๆ ตลาดบุคคลที่สาม บริการโครงสร้างพื้นฐานคลาวด์ (AWS) Kindle e-reader และผู้ช่วยส่วนตัวที่ขับเคลื่อนด้วยเสียงของ Alexa . นอกจากนี้ Amazon ได้ทำการเปลี่ยนแปลงเชิงโครงสร้างเพื่อปรับปรุงประสิทธิภาพ เช่น การจัดโครงสร้างเครือข่ายการปฏิบัติตามคำสั่งซื้อในสหรัฐฯ ใหม่เพื่อลดต้นทุนและเวลาจัดส่ง ซึ่งมีส่วนช่วยให้ประสบความสำเร็จมากยิ่งขึ้น | เช่นเดียวกับเครื่องแยกสายโซ่ LLM ตัวกรองสายโซ่ LLM ทำให้แน่ใจว่าถึงแม้จะครอบคลุมประเด็นสำคัญต่างๆ แต่ผลลัพธ์ก็มีประสิทธิภาพสำหรับลูกค้าที่กำลังมองหาคำตอบที่กระชับและมีบริบท |
เมื่อเปรียบเทียบเทคนิคต่างๆ เหล่านี้ เราจะเห็นว่าในบริบทต่างๆ เช่น การให้รายละเอียดเกี่ยวกับการเปลี่ยนแปลงของ AWS จากบริการแบบธรรมดาไปเป็นเอนทิตีที่ซับซ้อนที่มีมูลค่าหลายพันล้านดอลลาร์ หรือการอธิบายความสำเร็จเชิงกลยุทธ์ของ Amazon สายการดึงข้อมูลแบบปกติขาดความแม่นยำตามที่เทคนิคที่ซับซ้อนมากขึ้นนำเสนอ ส่งผลให้ข้อมูลตรงเป้าหมายน้อยลง แม้ว่าจะมองเห็นความแตกต่างได้น้อยมากระหว่างเทคนิคขั้นสูงที่กล่าวถึง แต่ก็มีข้อมูลมากกว่าสายโซ่ดึงข้อมูลทั่วไป
สำหรับลูกค้าในอุตสาหกรรมต่างๆ เช่น การดูแลสุขภาพ โทรคมนาคม และบริการทางการเงินที่ต้องการนำ RAG ไปใช้งานในแอปพลิเคชันของตน ข้อจำกัดของสายโซ่ดึงข้อมูลทั่วไปในการให้ความแม่นยำ การหลีกเลี่ยงความซ้ำซ้อน และการบีบอัดข้อมูลอย่างมีประสิทธิภาพ ทำให้ไม่เหมาะสมในการตอบสนองความต้องการเหล่านี้เมื่อเปรียบเทียบกับ ไปจนถึงการดึงเอกสารพาเรนต์ขั้นสูงและเทคนิคการบีบอัดตามบริบท เทคนิคเหล่านี้สามารถกลั่นกรองข้อมูลจำนวนมหาศาลไปยังข้อมูลเชิงลึกที่เข้มข้นและมีประสิทธิภาพที่คุณต้องการ ขณะเดียวกันก็ช่วยปรับปรุงประสิทธิภาพด้านราคา
ทำความสะอาด
เมื่อคุณใช้งานสมุดบันทึกเสร็จแล้ว ให้ลบทรัพยากรที่คุณสร้างขึ้นเพื่อหลีกเลี่ยงการสะสมค่าใช้จ่ายสำหรับทรัพยากรที่ใช้งานอยู่:
สรุป
ในโพสต์นี้ เราได้นำเสนอโซลูชันที่ช่วยให้คุณสามารถใช้โปรแกรมดึงเอกสารหลักและเทคนิคลูกโซ่การบีบอัดตามบริบท เพื่อเพิ่มความสามารถของ LLM ในการประมวลผลและสร้างข้อมูล เราได้ทดสอบเทคนิค RAG ขั้นสูงเหล่านี้ด้วยคำสั่ง Mixtral-8x7B และรุ่น BGE Large En ที่ใช้ได้กับ SageMaker JumpStart นอกจากนี้เรายังสำรวจการใช้พื้นที่จัดเก็บข้อมูลถาวรสำหรับการฝังและชิ้นเอกสาร และการผสานรวมกับที่เก็บข้อมูลขององค์กร
เทคนิคที่เราทำไม่เพียงแต่ปรับแต่งวิธีที่โมเดล LLM เข้าถึงและรวมความรู้จากภายนอกเท่านั้น แต่ยังปรับปรุงคุณภาพ ความเกี่ยวข้อง และประสิทธิภาพของผลลัพธ์อย่างมีนัยสำคัญอีกด้วย ด้วยการรวมการดึงข้อมูลจากคลังข้อความขนาดใหญ่เข้ากับความสามารถในการสร้างภาษา เทคนิค RAG ขั้นสูงเหล่านี้ช่วยให้ LLM สามารถสร้างคำตอบที่เป็นข้อเท็จจริง สอดคล้องกัน และเหมาะสมกับบริบทมากขึ้น เพิ่มประสิทธิภาพการทำงานในงานประมวลผลภาษาธรรมชาติต่างๆ
SageMaker JumpStart เป็นศูนย์กลางของโซลูชันนี้ ด้วย SageMaker JumpStart คุณจะสามารถเข้าถึงโมเดลโอเพ่นซอร์สและแบบปิดที่หลากหลาย ปรับปรุงกระบวนการเริ่มต้นใช้งาน ML และทำให้สามารถทดลองและปรับใช้ได้อย่างรวดเร็ว หากต้องการเริ่มต้นใช้งานโซลูชันนี้ ให้ไปที่โน้ตบุ๊กใน repo GitHub.
เกี่ยวกับผู้เขียน
 นิธิน วิเจียศวรัน เป็นสถาปนิกโซลูชันที่ AWS สิ่งที่เขามุ่งเน้นคือ generative AI และ AWS AI Accelerators เขาสำเร็จการศึกษาระดับปริญญาตรีสาขาวิทยาการคอมพิวเตอร์และชีวสารสนเทศศาสตร์ Niithiyn ทำงานอย่างใกล้ชิดกับทีม Generative AI GTM เพื่อเปิดใช้งานลูกค้า AWS ในหลายๆ ด้าน และเร่งการนำ AI ทั่วไปไปใช้ เขาเป็นแฟนตัวยงของทีม Dallas Mavericks และชอบสะสมรองเท้าผ้าใบ
นิธิน วิเจียศวรัน เป็นสถาปนิกโซลูชันที่ AWS สิ่งที่เขามุ่งเน้นคือ generative AI และ AWS AI Accelerators เขาสำเร็จการศึกษาระดับปริญญาตรีสาขาวิทยาการคอมพิวเตอร์และชีวสารสนเทศศาสตร์ Niithiyn ทำงานอย่างใกล้ชิดกับทีม Generative AI GTM เพื่อเปิดใช้งานลูกค้า AWS ในหลายๆ ด้าน และเร่งการนำ AI ทั่วไปไปใช้ เขาเป็นแฟนตัวยงของทีม Dallas Mavericks และชอบสะสมรองเท้าผ้าใบ
 เซบาสเตียน บุสติลโล เป็นสถาปนิกโซลูชันที่ AWS เขามุ่งเน้นไปที่เทคโนโลยี AI/ML ด้วยความหลงใหลอย่างลึกซึ้งต่อ generative AI และตัวเร่งการประมวลผล ที่ AWS เขาช่วยให้ลูกค้าปลดล็อกมูลค่าทางธุรกิจผ่าน AI เชิงสร้างสรรค์ เมื่อเขาไม่ได้ทำงาน เขาจะสนุกกับการชงกาแฟชนิดพิเศษสักแก้วและสำรวจโลกร่วมกับภรรยาของเขา
เซบาสเตียน บุสติลโล เป็นสถาปนิกโซลูชันที่ AWS เขามุ่งเน้นไปที่เทคโนโลยี AI/ML ด้วยความหลงใหลอย่างลึกซึ้งต่อ generative AI และตัวเร่งการประมวลผล ที่ AWS เขาช่วยให้ลูกค้าปลดล็อกมูลค่าทางธุรกิจผ่าน AI เชิงสร้างสรรค์ เมื่อเขาไม่ได้ทำงาน เขาจะสนุกกับการชงกาแฟชนิดพิเศษสักแก้วและสำรวจโลกร่วมกับภรรยาของเขา
 อาร์มันโด ดิแอซ เป็นสถาปนิกโซลูชันที่ AWS เขามุ่งเน้นไปที่การสร้าง AI, AI/ML และการวิเคราะห์ข้อมูล ที่ AWS Armando ช่วยให้ลูกค้าผสานรวมความสามารถ AI เชิงสร้างสรรค์ที่ล้ำสมัยเข้ากับระบบของพวกเขา ส่งเสริมนวัตกรรมและความได้เปรียบทางการแข่งขัน เมื่อเขาไม่ได้ทำงาน เขาสนุกกับการใช้เวลากับภรรยาและครอบครัว เดินป่า และท่องเที่ยวรอบโลก
อาร์มันโด ดิแอซ เป็นสถาปนิกโซลูชันที่ AWS เขามุ่งเน้นไปที่การสร้าง AI, AI/ML และการวิเคราะห์ข้อมูล ที่ AWS Armando ช่วยให้ลูกค้าผสานรวมความสามารถ AI เชิงสร้างสรรค์ที่ล้ำสมัยเข้ากับระบบของพวกเขา ส่งเสริมนวัตกรรมและความได้เปรียบทางการแข่งขัน เมื่อเขาไม่ได้ทำงาน เขาสนุกกับการใช้เวลากับภรรยาและครอบครัว เดินป่า และท่องเที่ยวรอบโลก
 ดร.ฟารุค ซาบีร์ เป็นสถาปนิกอาวุโสด้านปัญญาประดิษฐ์และผู้เชี่ยวชาญด้านการเรียนรู้ของเครื่องที่ AWS เขาสำเร็จการศึกษาระดับปริญญาเอกและปริญญาโทสาขาวิศวกรรมไฟฟ้าจากมหาวิทยาลัยเทกซัสออสติน และปริญญาโทสาขาวิทยาการคอมพิวเตอร์จากสถาบันเทคโนโลยีจอร์เจีย เขามีประสบการณ์การทำงานมากกว่า 15 ปี และยังชอบสอนและให้คำปรึกษาแก่นักศึกษาอีกด้วย ที่ AWS เขาช่วยลูกค้ากำหนดและแก้ปัญหาทางธุรกิจในด้านวิทยาศาสตร์ข้อมูล การเรียนรู้ของเครื่อง คอมพิวเตอร์วิทัศน์ ปัญญาประดิษฐ์ การเพิ่มประสิทธิภาพเชิงตัวเลข และโดเมนที่เกี่ยวข้อง เขาและครอบครัวอาศัยอยู่ในเมืองดัลลัส รัฐเท็กซัส รักการเดินทางและเดินทางไกล
ดร.ฟารุค ซาบีร์ เป็นสถาปนิกอาวุโสด้านปัญญาประดิษฐ์และผู้เชี่ยวชาญด้านการเรียนรู้ของเครื่องที่ AWS เขาสำเร็จการศึกษาระดับปริญญาเอกและปริญญาโทสาขาวิศวกรรมไฟฟ้าจากมหาวิทยาลัยเทกซัสออสติน และปริญญาโทสาขาวิทยาการคอมพิวเตอร์จากสถาบันเทคโนโลยีจอร์เจีย เขามีประสบการณ์การทำงานมากกว่า 15 ปี และยังชอบสอนและให้คำปรึกษาแก่นักศึกษาอีกด้วย ที่ AWS เขาช่วยลูกค้ากำหนดและแก้ปัญหาทางธุรกิจในด้านวิทยาศาสตร์ข้อมูล การเรียนรู้ของเครื่อง คอมพิวเตอร์วิทัศน์ ปัญญาประดิษฐ์ การเพิ่มประสิทธิภาพเชิงตัวเลข และโดเมนที่เกี่ยวข้อง เขาและครอบครัวอาศัยอยู่ในเมืองดัลลัส รัฐเท็กซัส รักการเดินทางและเดินทางไกล
 มาร์โก ปูนิโอ เป็นสถาปนิกโซลูชันที่มุ่งเน้นกลยุทธ์ AI เชิงสร้างสรรค์ ประยุกต์โซลูชัน AI และดำเนินการวิจัยเพื่อช่วยให้ลูกค้าขยายขนาดมากบน AWS Marco เป็นที่ปรึกษาดิจิทัลเนทีฟคลาวด์ที่มีประสบการณ์ใน FinTech, การดูแลสุขภาพและวิทยาศาสตร์ชีวภาพ, ซอฟต์แวร์ในรูปแบบบริการ และล่าสุดในอุตสาหกรรมโทรคมนาคม เขาเป็นนักเทคโนโลยีที่มีคุณสมบัติและมีความหลงใหลในแมชชีนเลิร์นนิง ปัญญาประดิษฐ์ และการควบรวมกิจการ Marco ประจำอยู่ในซีแอตเทิล รัฐวอชิงตัน และชอบเขียน อ่านหนังสือ ออกกำลังกาย และสร้างแอปพลิเคชันในเวลาว่าง
มาร์โก ปูนิโอ เป็นสถาปนิกโซลูชันที่มุ่งเน้นกลยุทธ์ AI เชิงสร้างสรรค์ ประยุกต์โซลูชัน AI และดำเนินการวิจัยเพื่อช่วยให้ลูกค้าขยายขนาดมากบน AWS Marco เป็นที่ปรึกษาดิจิทัลเนทีฟคลาวด์ที่มีประสบการณ์ใน FinTech, การดูแลสุขภาพและวิทยาศาสตร์ชีวภาพ, ซอฟต์แวร์ในรูปแบบบริการ และล่าสุดในอุตสาหกรรมโทรคมนาคม เขาเป็นนักเทคโนโลยีที่มีคุณสมบัติและมีความหลงใหลในแมชชีนเลิร์นนิง ปัญญาประดิษฐ์ และการควบรวมกิจการ Marco ประจำอยู่ในซีแอตเทิล รัฐวอชิงตัน และชอบเขียน อ่านหนังสือ ออกกำลังกาย และสร้างแอปพลิเคชันในเวลาว่าง
 เอเจ ดิมิเน เป็นสถาปนิกโซลูชันที่ AWS เขาเชี่ยวชาญด้าน generative AI, การประมวลผลแบบไร้เซิร์ฟเวอร์ และการวิเคราะห์ข้อมูล เขาเป็นสมาชิก/ที่ปรึกษาที่แข็งขันในชุมชนภาคสนามด้านเทคนิคการเรียนรู้ของเครื่อง และได้ตีพิมพ์บทความทางวิทยาศาสตร์หลายฉบับในหัวข้อ AI/ML ต่างๆ เขาทำงานร่วมกับลูกค้าตั้งแต่บริษัทสตาร์ทอัพไปจนถึงองค์กรต่างๆ เพื่อพัฒนาโซลูชัน AWSome generative AI เขามีความหลงใหลเป็นพิเศษในการใช้ประโยชน์จากโมเดลภาษาขนาดใหญ่สำหรับการวิเคราะห์ข้อมูลขั้นสูง และการสำรวจการใช้งานจริงที่จัดการกับความท้าทายในโลกแห่งความเป็นจริง นอกเหนือจากงาน AJ ยังชื่นชอบการเดินทาง และปัจจุบันอยู่ใน 53 ประเทศโดยมีเป้าหมายที่จะไปเยือนทุกประเทศในโลก
เอเจ ดิมิเน เป็นสถาปนิกโซลูชันที่ AWS เขาเชี่ยวชาญด้าน generative AI, การประมวลผลแบบไร้เซิร์ฟเวอร์ และการวิเคราะห์ข้อมูล เขาเป็นสมาชิก/ที่ปรึกษาที่แข็งขันในชุมชนภาคสนามด้านเทคนิคการเรียนรู้ของเครื่อง และได้ตีพิมพ์บทความทางวิทยาศาสตร์หลายฉบับในหัวข้อ AI/ML ต่างๆ เขาทำงานร่วมกับลูกค้าตั้งแต่บริษัทสตาร์ทอัพไปจนถึงองค์กรต่างๆ เพื่อพัฒนาโซลูชัน AWSome generative AI เขามีความหลงใหลเป็นพิเศษในการใช้ประโยชน์จากโมเดลภาษาขนาดใหญ่สำหรับการวิเคราะห์ข้อมูลขั้นสูง และการสำรวจการใช้งานจริงที่จัดการกับความท้าทายในโลกแห่งความเป็นจริง นอกเหนือจากงาน AJ ยังชื่นชอบการเดินทาง และปัจจุบันอยู่ใน 53 ประเทศโดยมีเป้าหมายที่จะไปเยือนทุกประเทศในโลก
- เนื้อหาที่ขับเคลื่อนด้วย SEO และการเผยแพร่ประชาสัมพันธ์ รับการขยายวันนี้
- PlatoData.Network Vertical Generative Ai เพิ่มพลังให้กับตัวเอง เข้าถึงได้ที่นี่.
- เพลโตไอสตรีม. Web3 อัจฉริยะ ขยายความรู้ เข้าถึงได้ที่นี่.
- เพลโตESG. คาร์บอน, คลีนเทค, พลังงาน, สิ่งแวดล้อม แสงอาทิตย์, การจัดการของเสีย. เข้าถึงได้ที่นี่.
- เพลโตสุขภาพ เทคโนโลยีชีวภาพและข่าวกรองการทดลองทางคลินิก เข้าถึงได้ที่นี่.
- ที่มา: https://aws.amazon.com/blogs/machine-learning/advanced-rag-patterns-on-amazon-sagemaker/

