Grundmodeller (FM) är modeller för stora maskininlärning (ML) som tränas på ett brett spektrum av omärkta och generaliserade datauppsättningar. FMs, som namnet antyder, utgör grunden för att bygga mer specialiserade nedströmsapplikationer och är unika i sin anpassningsförmåga. De kan utföra en mängd olika uppgifter, som naturlig språkbehandling, klassificering av bilder, förutsäga trender, analysera känslor och svara på frågor. Denna skala och allmänna anpassningsförmåga är det som skiljer FM:s från traditionella ML-modeller. FM är multimodala; de arbetar med olika datatyper som text, video, ljud och bilder. Stora språkmodeller (LLM) är en typ av FM och är förtränade på stora mängder textdata och har vanligtvis applikationsanvändningar som textgenerering, intelligenta chatbots eller sammanfattningar.
Streaming av data underlättar det konstanta flödet av mångsidig och uppdaterad information, vilket förbättrar modellernas förmåga att anpassa och generera mer exakta, kontextuellt relevanta utdata. Denna dynamiska integration av strömmande data möjliggör generativ AI applikationer för att reagera snabbt på förändrade förhållanden, förbättra deras anpassningsförmåga och övergripande prestanda i olika uppgifter.
För att bättre förstå detta, föreställ dig en chatbot som hjälper resenärer att boka sina resor. I det här scenariot behöver chatboten realtidsåtkomst till flygbolagens inventering, flygstatus, hotellinventering, senaste prisändringar och mer. Dessa data kommer vanligtvis från tredje part, och utvecklare måste hitta ett sätt att få in denna data och bearbeta dataändringarna när de inträffar.
Batchbearbetning passar inte bäst i detta scenario. När data ändras snabbt kan bearbetning av dem i en batch resultera i att inaktuella data används av chatboten, vilket ger felaktig information till kunden, vilket påverkar den övergripande kundupplevelsen. Strömbehandling kan dock göra det möjligt för chatboten att få tillgång till realtidsdata och anpassa sig till förändringar i tillgänglighet och pris, vilket ger den bästa vägledningen till kunden och förbättrar kundupplevelsen.
Ett annat exempel är en AI-driven observerbarhets- och övervakningslösning där FM:er övervakar interna mätvärden i realtid för ett system och producerar varningar. När modellen hittar en anomali eller ett onormalt metriskt värde bör den omedelbart ge en varning och meddela operatören. Men värdet av sådana viktiga data minskar avsevärt med tiden. Dessa meddelanden bör helst tas emot inom några sekunder eller till och med medan det händer. Om operatörer får dessa meddelanden minuter eller timmar efter att de inträffade är en sådan insikt inte åtgärdbar och har potentiellt förlorat sitt värde. Du kan hitta liknande användningsfall i andra branscher som detaljhandel, biltillverkning, energi och finansbranschen.
I det här inlägget diskuterar vi varför dataströmning är en avgörande komponent i generativa AI-applikationer på grund av dess natur i realtid. Vi diskuterar värdet av AWS dataströmningstjänster som t.ex Amazon Managed Streaming för Apache Kafka (Amazon MSK), Amazon Kinesis dataströmmar, Amazon Managed Service för Apache Flinkoch Amazon Kinesis Data Firehose i att bygga generativa AI-applikationer.
Inlärning i sammanhang
LLM:er tränas med punkt-i-tid-data och har ingen inneboende förmåga att komma åt färska data vid slutledningstidpunkten. När ny data dyker upp måste du kontinuerligt finjustera eller vidareutbilda modellen. Detta är inte bara en dyr operation, utan också mycket begränsande i praktiken eftersom hastigheten för ny datagenerering vida ersätter hastigheten för finjustering. Dessutom saknar LLMs kontextuell förståelse och förlitar sig enbart på sina träningsdata, och är därför benägna att hallucinera. Detta innebär att de kan generera ett flytande, sammanhängande och syntaktiskt ljud men faktiskt felaktigt svar. De saknar också relevans, personalisering och sammanhang.
LLM:er har dock kapacitet att lära sig av de data de får från sammanhanget för att svara mer exakt utan att modifiera modellvikterna. Det här kallas inlärning i sammanhang, och kan användas för att producera personliga svar eller ge ett korrekt svar i samband med organisationens policyer.
Till exempel, i en chatbot, kan datahändelser hänföra sig till en inventering av flyg och hotell eller prisändringar som ständigt matas in till en strömningslagringsmotor. Dessutom filtreras, berikas och omvandlas datahändelser till ett förbrukningsformat med hjälp av en strömprocessor. Resultatet görs tillgängligt för applikationen genom att fråga efter den senaste ögonblicksbilden. Ögonblicksbilden uppdateras ständigt genom strömbehandling; därför tillhandahålls den uppdaterade informationen i samband med en användarprompt till modellen. Detta gör att modellen kan anpassa sig till de senaste förändringarna i pris och tillgänglighet. Följande diagram illustrerar ett grundläggande arbetsflöde för inlärning i sammanhanget.
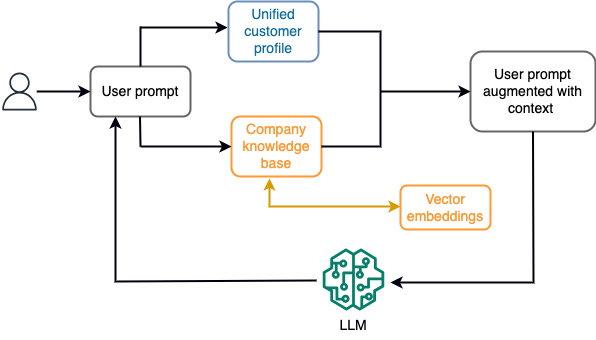
En vanlig metod för inlärning i sammanhang är att använda en teknik som kallas Retrieval Augmented Generation (RAG). I RAG tillhandahåller du relevant information såsom de mest relevanta policyerna och kundregister tillsammans med användarfrågan till prompten. På detta sätt genererar LLM ett svar på användarfrågan med hjälp av ytterligare information som tillhandahålls som sammanhang. För att lära dig mer om RAG, se Frågesvar med hjälp av Retrieval Augmented Generation med grundmodeller i Amazon SageMaker JumpStart.
En RAG-baserad generativ AI-applikation kan bara producera generiska svar baserat på dess träningsdata och relevanta dokument i kunskapsbasen. Denna lösning misslyckas när ett personligt svar i nästan realtid förväntas från applikationen. Till exempel förväntas en resechatbot ta hänsyn till användarens aktuella bokningar, tillgängliga hotell- och flyginventarier med mera. Dessutom, de relevanta kunduppgifterna (allmänt känd som enhetlig kundprofil) kan vanligtvis ändras. Om en batchprocess används för att uppdatera den generativa AI:s användarprofildatabas kan kunden få missnöjda svar baserat på gamla data.
I det här inlägget diskuterar vi tillämpningen av strömbehandling för att förbättra en RAG-lösning som används för att bygga frågesvarsagenter med sammanhang från realtidsåtkomst till enhetliga kundprofiler och organisatorisk kunskapsbas.
Kundprofiluppdateringar nästan i realtid
Kundposter är vanligtvis distribuerade över datalager inom en organisation. För att din generativa AI-applikation ska ge en relevant, korrekt och uppdaterad kundprofil är det viktigt att bygga strömmande datapipelines som kan utföra identitetsupplösning och profilaggregering över de distribuerade datalagren. Strömmande jobb tar ständigt in ny data för att synkronisera mellan system och kan utföra anrikning, transformationer, sammanfogningar och aggregering över tidsperioder mer effektivt. Change data capture (CDC)-händelser innehåller information om källposten, uppdateringar och metadata som tid, källa, klassificering (infoga, uppdatera eller ta bort) och initiativtagaren till ändringen.
Följande diagram illustrerar ett exempel på ett arbetsflöde för CDC-streamingintag och bearbetning för enhetliga kundprofiler.

I det här avsnittet diskuterar vi huvudkomponenterna i ett CDC-strömningsmönster som krävs för att stödja RAG-baserade generativa AI-applikationer.
CDC-strömningsintag
En CDC-replikator är en process som samlar in dataändringar från ett källsystem (vanligtvis genom att läsa transaktionsloggar eller binlogs) och skriver CDC-händelser i exakt samma ordning som de inträffade i en strömmande dataström eller ett ämne. Detta innebär en loggbaserad infångning med verktyg som t.ex AWS Database Migration Service (AWS DMS) eller open source-kontakter som Debezium for Apache Kafka connect. Apache Kafka Connect är en del av Apache Kafka-miljön, vilket gör att data kan tas in från olika källor och levereras till olika destinationer. Du kan köra din Apache Kafka-kontakt på Amazon MSK Connect inom några minuter utan att oroa dig för konfiguration, installation och drift av ett Apache Kafka-kluster. Du behöver bara ladda upp din connectors kompilerade kod till Amazon enkel lagringstjänst (Amazon S3) och ställ in din kontakt med din arbetsbelastnings specifika konfiguration.
Det finns även andra metoder för att fånga dataändringar. Till exempel, Amazon DynamoDB tillhandahåller en funktion för att streama CDC-data till Amazon DynamoDB-strömmar eller Kinesis Dataströmmar. Amazon S3 tillhandahåller en trigger för att anropa en AWS Lambda funktion när ett nytt dokument lagras.
Strömmande lagring
Streaminglagring fungerar som en mellanbuffert för att lagra CDC-händelser innan de bearbetas. Strömmande lagring ger tillförlitlig lagring för strömmande data. Genom sin design är den mycket tillgänglig och motståndskraftig mot hårdvaru- eller nodfel och upprätthåller ordningen på händelserna när de skrivs. Streaminglagring kan lagra datahändelser antingen permanent eller under en viss tidsperiod. Detta gör att strömprocessorer kan läsa från en del av strömmen om det finns ett fel eller behov av ombearbetning. Kinesis Data Streams är en serverlös strömningsdatatjänst som gör det enkelt att fånga, bearbeta och lagra dataströmmar i stor skala. Amazon MSK är en fullt hanterad, högtillgänglig och säker tjänst som tillhandahålls av AWS för att köra Apache Kafka.
Strömbehandling
Strömbehandlingssystem bör utformas för parallellitet för att hantera hög datagenomströmning. De bör partitionera indataströmmen mellan flera uppgifter som körs på flera beräkningsnoder. Uppgifter ska kunna skicka resultatet av en operation till nästa över nätverket, vilket gör det möjligt att bearbeta data parallellt samtidigt som man utför operationer som kopplingar, filtrering, anrikning och aggregering. Strömbehandlingsapplikationer bör kunna bearbeta händelser med avseende på händelsetiden för användningsfall där händelser kan komma försent eller korrekt beräkning förlitar sig på den tid som händelser inträffar snarare än systemtiden. För mer information, se Tidsbegrepp: Händelsetid och bearbetningstid.
Strömprocesser producerar kontinuerligt resultat i form av datahändelser som måste matas ut till ett målsystem. Ett målsystem kan vara vilket system som helst som kan integreras direkt med processen eller via strömmande lagring som mellanhand. Beroende på vilket ramverk du väljer för strömbearbetning kommer du att ha olika alternativ för målsystem beroende på tillgängliga sänkanslutningar. Om du bestämmer dig för att skriva resultaten till en mellanliggande strömningslagring, kan du bygga en separat process som läser händelser och tillämpar ändringar på målsystemet, till exempel att köra en Apache Kafka-sänkanslutning. Oavsett vilket alternativ du väljer behöver CDC-data extra hantering på grund av sin natur. Eftersom CDC-händelser innehåller information om uppdateringar eller borttagningar är det viktigt att de slås samman i målsystemet i rätt ordning. Om ändringarna tillämpas i fel ordning kommer målsystemet att vara osynkroniserat med sin källa.
Apache Flash är ett kraftfullt ramverk för strömbearbetning känt för sin låga latens och höga genomströmningskapacitet. Den stöder bearbetning av händelsetid, semantik för exakt-engångsbehandling och hög feltolerans. Dessutom ger det inbyggt stöd för CDC-data via en speciell struktur som kallas dynamiska tabeller. Dynamiska tabeller efterliknar källdatabastabellerna och ger en kolumnär representation av strömmande data. Data i dynamiska tabeller ändras med varje händelse som bearbetas. Nya poster kan läggas till, uppdateras eller raderas när som helst. Dynamiska tabeller tar bort den extra logik du behöver implementera för varje postoperation (infoga, uppdatera, ta bort) separat. För mer information, se Dynamiska tabeller.
Med Amazon Managed Service för Apache Flink, kan du köra Apache Flink-jobb och integrera med andra AWS-tjänster. Det finns inga servrar och kluster att hantera, och det finns ingen dator- och lagringsinfrastruktur att installera.
AWS-lim är en helt hanterad ETL-tjänst (extrahering, transform and load), vilket innebär att AWS hanterar infrastrukturförsörjning, skalning och underhåll åt dig. Även om det främst är känt för sina ETL-funktioner, kan AWS Glue också användas för Spark-streamingapplikationer. AWS Glue kan interagera med strömmande datatjänster som Kinesis Data Streams och Amazon MSK för att bearbeta och transformera CDC-data. AWS Glue kan också sömlöst integreras med andra AWS-tjänster som Lambda, AWS stegfunktioner, och DynamoDB, vilket ger dig ett omfattande ekosystem för att bygga och hantera pipelines för databehandling.
Enad kundprofil
För att övervinna föreningen av kundprofilen över en mängd olika källsystem krävs utveckling av robusta datapipelines. Du behöver datapipelines som kan föra och synkronisera alla poster till ett datalager. Detta datalager förser din organisation med den holistiska kundregistreringsvy som behövs för operativ effektivitet av RAG-baserade generativa AI-applikationer. För att bygga ett sådant datalager skulle ett ostrukturerat datalager vara bäst.
En identitetsgraf är en användbar struktur för att skapa en enhetlig kundprofil eftersom den konsoliderar och integrerar kunddata från olika källor, säkerställer datanoggrannhet och deduplicering, erbjuder uppdateringar i realtid, kopplar samman insikter mellan olika system, möjliggör personalisering, förbättrar kundupplevelsen och stöder regelefterlevnad. Denna enhetliga kundprofil ger den generativa AI-applikationen möjlighet att förstå och engagera sig med kunder på ett effektivt sätt och följa reglerna för datasekretess, vilket i slutändan förbättrar kundupplevelsen och driver affärstillväxt. Du kan bygga din identitetsgraflösning med hjälp av Amazon Neptunus, en snabb, pålitlig, fullt hanterad grafdatabastjänst.
AWS tillhandahåller några andra hanterade och serverlösa NoSQL-lagringstjänster för ostrukturerade nyckel-värdeobjekt. Amazon DocumentDB (med MongoDB-kompatibilitet) är ett snabbt, skalbart, mycket tillgängligt och fullt hanterat företag dokumentdatabas tjänst som stöder inbyggda JSON-arbetsbelastningar. DynamoDB är en fullständigt hanterad NoSQL-databastjänst som ger snabb och förutsägbar prestanda med sömlös skalbarhet.
Uppdateringar av organisationens kunskapsbas nästan i realtid
I likhet med kundregister, är interna kunskapsarkiv som företagspolicyer och organisationsdokument förvarade över lagringssystem. Detta är vanligtvis ostrukturerad data och uppdateras på ett icke-inkrementellt sätt. Användningen av ostrukturerad data för AI-applikationer är effektiv med hjälp av vektorinbäddningar, vilket är en teknik för att representera högdimensionella data som textfiler, bilder och ljudfiler som flerdimensionella numeriska.
AWS tillhandahåller flera vektormotortjänster, Såsom Amazon OpenSearch Serverlös, Amazon Kendraoch Amazon Aurora PostgreSQL-kompatibel utgåva med tillägget pgvector för att lagra vektorinbäddningar. Generativa AI-applikationer kan förbättra användarupplevelsen genom att omvandla användarprompten till en vektor och använda den för att fråga vektormotorn för att hämta kontextuellt relevant information. Både prompten och vektordata som hämtas skickas sedan till LLM för att få ett mer exakt och personligt svar.
Följande diagram illustrerar ett exempel på strömbearbetningsarbetsflöde för vektorinbäddningar.
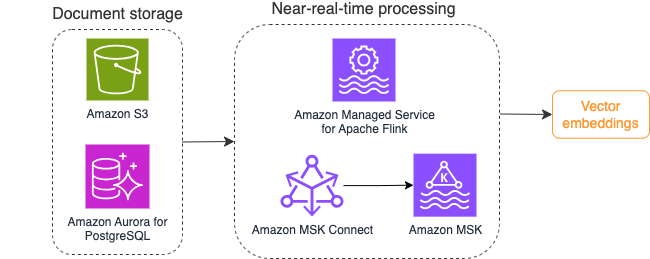
Kunskapsbasinnehåll måste konverteras till vektorinbäddningar innan det skrivs till vektordatalagret. Amazonas berggrund or Amazon SageMaker kan hjälpa dig att komma åt den modell du väljer och exponera en privat slutpunkt för denna konvertering. Dessutom kan du använda bibliotek som LangChain för att integrera med dessa slutpunkter. Att bygga en batchprocess kan hjälpa dig att konvertera ditt kunskapsbasinnehåll till vektordata och lagra det i en vektordatabas initialt. Du måste dock lita på ett intervall för att bearbeta dokumenten för att synkronisera din vektordatabas med ändringar i din kunskapsbasinnehåll. Med ett stort antal dokument kan denna process vara ineffektiv. Mellan dessa intervall kommer dina generativa AI-applikationsanvändare att få svar enligt det gamla innehållet, eller kommer att få ett felaktigt svar eftersom det nya innehållet inte har vektoriserats ännu.
Strömbehandling är en idealisk lösning för dessa utmaningar. Den producerar händelser enligt befintliga dokument initialt och övervakar vidare källsystemet och skapar en dokumentändringshändelse så snart de inträffar. Dessa händelser kan lagras i strömmande lagring och vänta på att bearbetas av ett strömmande jobb. Ett strömmande jobb läser dessa händelser, läser in innehållet i dokumentet och omvandlar innehållet till en rad relaterade symboler av ord. Varje token omvandlas vidare till vektordata via ett API-anrop till en inbäddad FM. Resultat skickas för lagring till vektorlagringen via en sänkoperator.
Om du använder Amazon S3 för att lagra dina dokument kan du bygga en händelsekälla-arkitektur baserad på S3-objektändringsutlösare för Lambda. En Lambda-funktion kan skapa en händelse i önskat format och skriva det till din streaminglagring.
Du kan också använda Apache Flink för att köra som ett strömmande jobb. Apache Flink tillhandahåller den inbyggda FileSystem-källkopplingen, som kan upptäcka befintliga filer och läsa deras innehåll initialt. Efter det kan den kontinuerligt övervaka ditt filsystem efter nya filer och fånga deras innehåll. Kontakten stöder läsning av en uppsättning filer från distribuerade filsystem som Amazon S3 eller HDFS med ett format av vanlig text, Avro, CSV, Parkett och mer, och producerar en strömmande rekord. Som en helt hanterad tjänst tar Managed Service för Apache Flink bort de operativa omkostnaderna för att distribuera och underhålla Flink-jobb, vilket gör att du kan fokusera på att bygga och skala dina streamingapplikationer. Med sömlös integrering i AWS-streamingtjänsterna som Amazon MSK eller Kinesis Data Streams, tillhandahåller den funktioner som automatisk skalning, säkerhet och motståndskraft, vilket ger pålitliga och effektiva Flink-applikationer för hantering av realtidsströmningsdata.
Baserat på dina DevOps-preferenser kan du välja mellan Kinesis Data Streams eller Amazon MSK för att lagra streamingposterna. Kinesis Data Streams förenklar komplexiteten i att bygga och hantera anpassade strömmande dataapplikationer, vilket gör att du kan fokusera på att få insikter från dina data snarare än underhåll av infrastruktur. Kunder som använder Apache Kafka väljer ofta Amazon MSK på grund av dess enkelhet, skalbarhet och pålitlighet när det gäller att övervaka Apache Kafka-kluster inom AWS-miljön. Som en helt hanterad tjänst tar Amazon MSK på sig den operativa komplexiteten som är förknippad med att distribuera och underhålla Apache Kafka-kluster, vilket gör att du kan koncentrera dig på att konstruera och utöka dina streamingapplikationer.
Eftersom en RESTful API-integration passar denna processs natur behöver du ett ramverk som stöder ett tillståndsbestämt anrikningsmönster via RESTful API-anrop för att spåra fel och försöka igen för den misslyckade begäran. Apache Flink är återigen ett ramverk som kan utföra stateful operationer i minneshastighet. För att förstå de bästa sätten att göra API-anrop via Apache Flink, se Vanliga mönster för anrikning av strömmande data i Amazon Kinesis Data Analytics för Apache Flink.
Apache Flink tillhandahåller inbyggda sink-kontakter för att skriva data till vektordatalager som Amazon Aurora för PostgreSQL med pgvector eller Amazon OpenSearch Service med VectorDB. Alternativt kan du iscensätta Flink-jobbets utdata (vektoriserade data) i ett MSK-ämne eller en Kinesis-dataström. OpenSearch Service tillhandahåller stöd för inbyggt intag från Kinesis-dataströmmar eller MSK-ämnen. För mer information, se Vi introducerar Amazon MSK som en källa för Amazon OpenSearch Ingestion och Laddar strömmande data från Amazon Kinesis Data Streams.
Feedbackanalys och finjustering
Det är viktigt för datadriftshanterare och AI/ML-utvecklare att få insikt om prestandan för den generativa AI-applikationen och de FM som används. För att uppnå det måste du bygga datapipelines som beräknar viktiga nyckelprestandaindikatorer (KPI) baserat på användarfeedback och olika programloggar och mätvärden. Den här informationen är användbar för intressenter för att få insikt i realtid om prestandan för FM, applikationen och övergripande användartillfredsställelse om kvaliteten på supporten de får från din applikation. Du måste också samla in och lagra konversationshistoriken för att ytterligare finjustera dina FM:er för att förbättra deras förmåga att utföra domänspecifika uppgifter.
Detta användningsfall passar väldigt bra i strömningsanalysdomänen. Din applikation bör lagra varje konversation i strömmande lagring. Din applikation kan fråga användarna om deras betyg på varje svars exakthet och deras övergripande tillfredsställelse. Dessa data kan vara i ett format av ett binärt val eller en text i fri form. Dessa data kan lagras i en Kinesis-dataström eller MSK-ämne och bearbetas för att generera KPI:er i realtid. Du kan sätta FM:er i arbete för användarnas sentimentanalys. FM:er kan analysera varje svar och tilldela en kategori av användarnöjdhet.
Apache Flinks arkitektur möjliggör komplex dataaggregering över tidsfönster. Det ger också stöd för SQL-förfrågningar över datahändelser. Genom att använda Apache Flink kan du därför snabbt analysera råa användarindata och generera KPI:er i realtid genom att skriva välbekanta SQL-frågor. För mer information, se Tabell API & SQL.
Med Amazon Managed Service för Apache Flink Studio, kan du bygga och köra Apache Flink-strömbehandlingsprogram med standard SQL, Python och Scala i en interaktiv anteckningsbok. Studio bärbara datorer drivs av Apache Zeppelin och använder Apache Flink som strömbehandlingsmotor. Studio-anteckningsböcker kombinerar sömlöst dessa tekniker för att göra avancerad analys av dataströmmar tillgänglig för utvecklare av alla färdigheter. Med stöd för användardefinierade funktioner (UDF) tillåter Apache Flink att bygga anpassade operatörer för att integrera med externa resurser som FM:er för att utföra komplexa uppgifter som sentimentanalys. Du kan använda UDF:er för att beräkna olika mätvärden eller berika rådata från användarfeedback med ytterligare insikter som användarsentiment. För att lära dig mer om detta mönster, se Proaktivt ta itu med kundproblem i realtid med GenAI, Flink, Apache Kafka och Kinesis.
Med Managed Service för Apache Flink Studio kan du distribuera din Studio-anteckningsbok som ett streamingjobb med ett klick. Du kan använda inbyggda handfatanslutningar från Apache Flink för att skicka utdata till din lagring eller placera den i en Kinesis-dataström eller MSK-ämne. Amazon RedShift och OpenSearch Service är båda idealiska för att lagra analytisk data. Båda motorerna tillhandahåller inbyggt intagsstöd från Kinesis Data Streams och Amazon MSK via en separat strömmande pipeline till en datasjö eller datalager för analys.
Amazon Redshift använder SQL för att analysera strukturerad och semi-strukturerad data över datalager och datasjöar, med hjälp av AWS-designad hårdvara och maskininlärning för att leverera bästa pris-prestanda i skala. OpenSearch Service erbjuder visualiseringsfunktioner som drivs av OpenSearch Dashboards och Kibana (1.5 till 7.10 versioner).
Du kan använda resultatet av en sådan analys i kombination med användarpromptdata för att finjustera FM när det behövs. SageMaker är det enklaste sättet att finjustera dina FM-apparater. Att använda Amazon S3 med SageMaker ger en kraftfull och sömlös integration för att finjustera dina modeller. Amazon S3 fungerar som en skalbar och hållbar objektlagringslösning, som möjliggör enkel lagring och hämtning av stora datamängder, träningsdata och modellartefakter. SageMaker är en fullt hanterad ML-tjänst som förenklar hela ML-livscykeln. Genom att använda Amazon S3 som lagringsbackend för SageMaker kan du dra nytta av skalbarheten, tillförlitligheten och kostnadseffektiviteten hos Amazon S3, samtidigt som du sömlöst integrerar den med SageMakers utbildnings- och distributionsmöjligheter. Denna kombination möjliggör effektiv datahantering, underlättar utveckling av samarbetsmodeller och ser till att ML-arbetsflöden är strömlinjeformade och skalbara, vilket i slutändan förbättrar ML-processens övergripande smidighet och prestanda. För mer information, se Finjustera Falcon 7B och andra LLM på Amazon SageMaker med @remote decorator.
Med en filsystemssänkanslutning kan Apache Flink-jobb leverera data till Amazon S3 i öppet format (som JSON, Avro, Parquet och fler) filer som dataobjekt. Om du föredrar att hantera din datasjö med hjälp av ett transaktionsdatasjöramverk (som Apache Hudi, Apache Iceberg eller Delta Lake), tillhandahåller alla dessa ramverk en anpassad anslutning för Apache Flink. För mer information, se Skapa en pipeline med låg latens käll-till-datasjö med hjälp av Amazon MSK Connect, Apache Flink och Apache Hudi.
Sammanfattning
För en generativ AI-applikation baserad på en RAG-modell måste du överväga att bygga två datalagringssystem, och du måste bygga dataoperationer som håller dem uppdaterade med alla källsystem. Traditionella batchjobb räcker inte för att bearbeta storleken och mångfalden av de data du behöver för att integrera med din generativa AI-applikation. Förseningar i bearbetningen av ändringarna i källsystem resulterar i ett felaktigt svar och minskar effektiviteten i din generativa AI-applikation. Dataströmning gör att du kan mata in data från en mängd olika databaser över olika system. Det låter dig också transformera, berika, sammanfoga och samla data över många källor effektivt i nästan realtid. Dataströmning ger en förenklad dataarkitektur för att samla in och omvandla användares reaktioner i realtid eller kommentarer på applikationssvaren, vilket hjälper dig att leverera och lagra resultaten i en datasjö för modellfinjustering. Dataströmning hjälper dig också att optimera datapipelines genom att endast bearbeta förändringshändelser, vilket gör att du kan svara på dataändringar snabbare och mer effektivt.
Läs mer om AWS dataströmningstjänster och börja bygga din egen dataströmningslösning.
Om författarna
 Ali Alemi är en Streaming Specialist Solutions Architect på AWS. Ali ger AWS-kunder råd med arkitektoniska bästa praxis och hjälper dem att designa realtidsanalysdatasystem som är pålitliga, säkra, effektiva och kostnadseffektiva. Han arbetar baklänges från kundernas användningsfall och designar datalösningar för att lösa deras affärsproblem. Innan han började på AWS, stöttade Ali flera offentliga kunder och AWS-konsultpartner i deras applikationsmoderniseringsresa och migrering till molnet.
Ali Alemi är en Streaming Specialist Solutions Architect på AWS. Ali ger AWS-kunder råd med arkitektoniska bästa praxis och hjälper dem att designa realtidsanalysdatasystem som är pålitliga, säkra, effektiva och kostnadseffektiva. Han arbetar baklänges från kundernas användningsfall och designar datalösningar för att lösa deras affärsproblem. Innan han började på AWS, stöttade Ali flera offentliga kunder och AWS-konsultpartner i deras applikationsmoderniseringsresa och migrering till molnet.
 Say Imtiaz (Taz). är världsomspännande teknisk ledare för Analytics på AWS. Han tycker om att engagera sig i samhället i allt som rör data och analyser. Han kan nås via LinkedIn.
Say Imtiaz (Taz). är världsomspännande teknisk ledare för Analytics på AWS. Han tycker om att engagera sig i samhället i allt som rör data och analyser. Han kan nås via LinkedIn.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoData.Network Vertical Generative Ai. Styrka dig själv. Tillgång här.
- PlatoAiStream. Web3 Intelligence. Kunskap förstärkt. Tillgång här.
- Platoesg. Kol, CleanTech, Energi, Miljö, Sol, Avfallshantering. Tillgång här.
- PlatoHealth. Biotech och kliniska prövningar Intelligence. Tillgång här.
- Källa: https://aws.amazon.com/blogs/big-data/exploring-real-time-streaming-for-generative-ai-applications/

