Bild av redaktör | Överför inlärningsflöde från Skyengine.ai
När det gäller att maskininlärning, där aptiten på data är omättlig, har inte alla lyxen att få tillgång till stora datamängder att lära sig av på ett infall – det är där överför lärande kommer till undsättning, särskilt när du har fastnat med begränsad data eller kostnaden för att skaffa mer är alldeles för hög.
Den här artikeln kommer att ta en närmare titt på magin med överföringsinlärning, och visar hur den på ett skickligt sätt använder modeller som redan har lärt sig från massiva datamängder för att ge dina egna maskininlärningsprojekt ett betydande uppsving, även när dina data är på den smala sidan.
Jag kommer att ta itu med hindren som kommer med att arbeta i miljöer med brist på data, titta på vad framtiden kan komma att erbjuda och fira mångsidigheten och effektiviteten av överföringslärande inom alla möjliga olika områden.
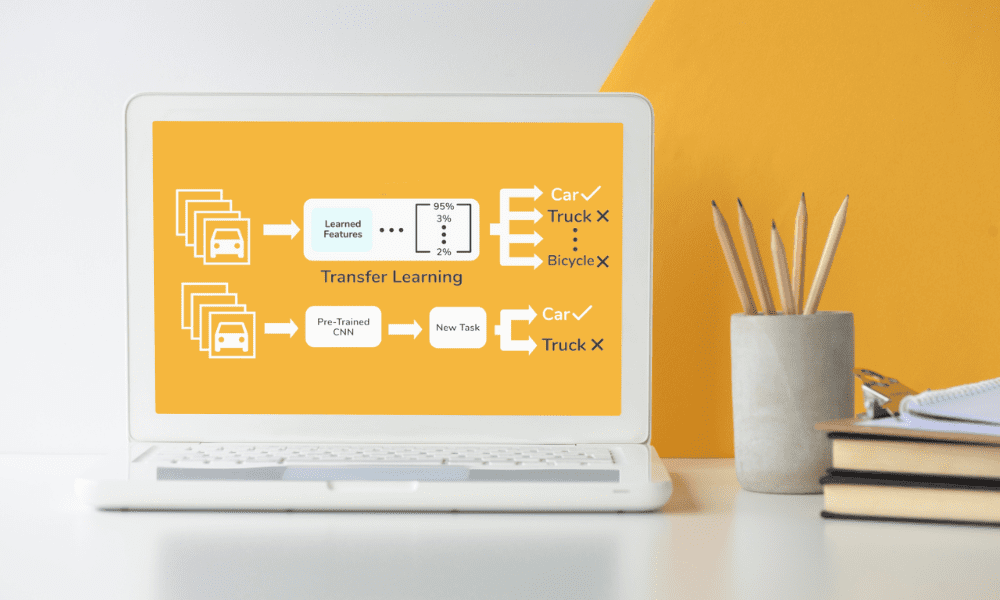
Transfer learning är en teknik som används vid maskininlärning som tar en modell utvecklad för en uppgift och återanvänder den för en andra, relaterad uppgift, och utvecklar den ytterligare.
I grunden bygger detta tillvägagångssätt på tanken att kunskap som förvärvats när man lär sig ett problem kan hjälpa till att lösa ett annat, något liknande problem.
Till exempel en modell tränad att känna igen objekt i bilder kan anpassas för att känna igen specifika typer av djur på foton, utnyttjar sin redan existerande kunskap om former, texturer och mönster.
Det påskyndar aktivt träningsprocessen samtidigt som det också avsevärt minskar mängden data som krävs. I små datascenarier är detta särskilt fördelaktigt, eftersom det kringgår det traditionella behovet av stora datamängder för att uppnå hög modellnoggrannhet.
Genom att använda förutbildade modeller kan utövare kringgå många av de initiala hinder som vanligtvis förknippas med modellutveckling, såsom funktionsval och modellarkitekturdesign.
Förutbildade modeller fungerar som den verkliga grunden för överföringslärande, och dessa modeller, som ofta utvecklas och tränas på storskaliga datauppsättningar av forskningsinstitutioner eller tekniska jättar, görs tillgängliga för allmänheten.
Mångsidigheten hos förutbildade modeller är anmärkningsvärt, med tillämpningar som sträcker sig från bild- och taligenkänning till naturlig språkbehandling. Att använda dessa modeller för nya uppgifter kan drastiskt minska utvecklingstiden och de resurser du behöver.
Till exempel, modeller utbildade i ImageNet-databasen, som innehåller miljontals märkta bilder i tusentals kategorier, ger en omfattande uppsättning funktioner för ett brett utbud av bildigenkänningsuppgifter.
Dessa modellers anpassningsförmåga till nya, mindre datauppsättningar understryker deras värde, vilket möjliggör extrahering av komplexa funktioner utan behov av omfattande beräkningsresurser.
Att arbeta med begränsad data innebär unika utmaningar—det primära problemet är överanpassning, där en modell lär sig träningsdata för väl, inklusive dess brus och extremvärden, vilket leder till dålig prestanda på osynliga data.
Överföringsinlärning minskar denna risk genom att använda modeller som är förutbildade på olika datauppsättningar, vilket förbättrar generaliseringen.
Effektiviteten av överföringslärande beror dock på den förutbildade modellens relevans för den nya uppgiften. Om de inblandade uppgifterna är för olika, kanske fördelarna med överföringslärande inte förverkligas fullt ut.
Dessutom, finjustera en förtränad modell med en liten datauppsättning kräver noggrann justering av parametrar för att undvika att förlora den värdefulla kunskap som modellen redan har förvärvat.
Utöver dessa hinder är ett annat scenario där data kan äventyras under komprimeringsprocessen. Detta gäller även för ganska enkla handlingar, som när du vill komprimera PDF-filer, men tack och lov kan den här typen av händelser förhindras med exakta ändringar.
I samband med maskininlärning, säkerställa fullständigheten och kvaliteten på uppgifterna även när den genomgår komprimering för lagring eller överföring är avgörande för att utveckla en pålitlig modell.
Överföringslärande, med sitt beroende av förutbildade modeller, understryker ytterligare behovet av försiktighet hantering av dataresurser för att förhindra förlust av information, se till att varje bit av data används till sin fulla potential i utbildnings- och tillämpningsfaserna.
Att balansera bibehållandet av inlärda funktioner med anpassningen till nya uppgifter är en känslig process som kräver en djup förståelse av både modellen och data till hands.
Smakämnen horisonten för överföringslärande vidgas ständigt, med forskning som tänjer på gränserna för vad som är möjligt.
En spännande väg här är utvecklingen av mer universella modeller som kan tillämpas på ett bredare utbud av uppgifter med minimala justeringar som behövs.
Ett annat område för utforskning är förbättringen av algoritmer för att överföra kunskap mellan vitt skilda domäner, vilket förbättrar flexibiliteten i överföringsinlärning.
Det finns också ett växande intresse för att automatisera processen att välja och finjustera förtränade modeller för specifika uppgifter, vilket ytterligare kan sänka inträdesbarriären för att använda avancerade maskininlärningstekniker.
Dessa framsteg lovar att göra överföringslärande ännu mer tillgängligt och effektivt, vilket öppnar nya möjligheter för dess tillämpning inom områden där data är knappa eller svåra att samla in.
Det fina med överföringslärande ligger i dess anpassningsförmåga som gäller över alla typer av olika domäner.
Från vården, där den kan hjälpa till att diagnostisera sjukdomar med begränsad patientdata, till robotik, där det påskyndar inlärningen av nya uppgifter utan omfattande utbildning, är de potentiella tillämpningarna enorma.
I området för naturlig språkbehandling, har överföringsinlärning möjliggjort betydande framsteg i språkmodeller med jämförelsevis små datamängder.
Denna anpassningsförmåga visar inte bara upp effektiviteten av överföringsinlärning, den belyser dess potential att demokratisera tillgången till avancerade maskininlärningstekniker för att tillåta mindre organisationer och forskare att genomföra projekt som tidigare låg utanför deras räckhåll på grund av databegränsningar.
Även om det är en Django plattform, kan du utnyttja överföringsinlärning för att förbättra din applikations kapacitet utan att börja om från början om igen.
Transfer learning överskrider gränserna för specifika programmeringsspråk eller ramverk, vilket gör det möjligt att tillämpa avancerade maskininlärningsmodeller på projekt som utvecklats i olika miljöer.
Transfer lärande är inte bara om att övervinna databrist; det är också ett bevis på effektivitet och resursoptimering inom maskininlärning.
Genom att bygga vidare på kunskapen från förutbildade modeller kan forskare och utvecklare uppnå betydande resultat med mindre beräkningskraft och tid.
Denna effektivitet är särskilt viktig i scenarier där resurserna är begränsade, oavsett om det gäller data, beräkningsmöjligheter eller både och.
Eftersom 43% av alla webbplatser använder WordPress som sitt CMS, detta är en bra testplats för ML-modeller som specialiserar sig på, låt oss säga, webbskrapning eller jämföra olika typer av innehåll för kontextuella och språkliga skillnader.
Detta understryker praktiska fördelar med överföringslärande i verkliga scenarier, där tillgången till storskalig, domänspecifik data kan vara begränsad. Överföringslärande uppmuntrar också återanvändning av befintliga modeller, i linje med hållbara metoder genom att minska behovet av energiintensiv utbildning från grunden.
Tillvägagångssättet exemplifierar hur strategisk resursanvändning kan leda till betydande framsteg inom maskininlärning, vilket gör sofistikerade modeller mer tillgängliga och miljövänliga.
När vi avslutar vår utforskning av överföringsinlärning är det uppenbart att denna teknik väsentligt förändrar maskininlärning som vi känner den, särskilt för projekt som brottas med begränsade dataresurser.
Transferinlärning möjliggör effektiv användning av förutbildade modeller, vilket gör det möjligt för både små och storskaliga projekt att uppnå anmärkningsvärda resultat utan behov av omfattande datauppsättningar eller beräkningsresurser.
När man blickar framåt är potentialen för överföringsinlärning enorm och varierande, och möjligheten att göra maskininlärningsprojekt mer genomförbara och mindre resurskrävande är inte bara lovande; det börjar redan bli verklighet.
Denna förändring mot mer tillgängliga och effektiva metoder för maskininlärning har potentialen att stimulera innovation inom många områden, från hälsovård till miljöskydd.
Transfer learning är att demokratisera maskininlärning, vilket gör avancerade tekniker tillgängliga för en mycket bredare publik än någonsin tidigare.
Nahla Davies är en mjukvaruutvecklare och teknikskribent. Innan hon ägnade sitt arbete heltid åt tekniskt skrivande lyckades hon – bland annat spännande – att fungera som ledande programmerare på en Inc. 5,000 XNUMX erfarenhetsbaserad varumärkesorganisation vars kunder inkluderar Samsung, Time Warner, Netflix och Sony.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoData.Network Vertical Generative Ai. Styrka dig själv. Tillgång här.
- PlatoAiStream. Web3 Intelligence. Kunskap förstärkt. Tillgång här.
- Platoesg. Kol, CleanTech, Energi, Miljö, Sol, Avfallshantering. Tillgång här.
- PlatoHealth. Biotech och kliniska prövningar Intelligence. Tillgång här.
- Källa: https://www.kdnuggets.com/exploring-the-potential-of-transfer-learning-in-small-data-scenarios?utm_source=rss&utm_medium=rss&utm_campaign=exploring-the-potential-of-transfer-learning-in-small-data-scenarios

