Beskrivning
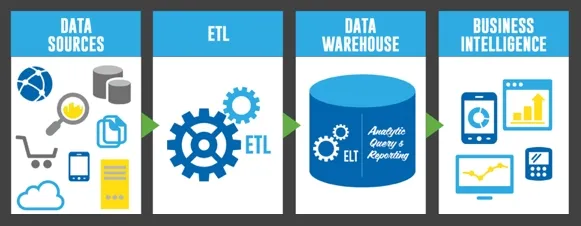
Dataintegrationsteknikerna ETL (Extract, Transform, Load) och ELT pipelines (Extract, Load, Transform) används båda för att överföra data från ett system till ett annat.
Informationen tas från en eller flera datakällor, omvandlas till ett målsystemkompatibelt format och laddas sedan in i målsystemet som en del av ETL-processen. Ett ETL-verktyg eller plattform som organiserar processen gör ofta denna uppgift. För att möta målsystemets behov måste data renas, valideras, integreras och förbättras under transformationsstadiet.
ELT-pipelinen, å andra sidan, innebär att man tar bort data från en eller flera datakällor, för in den i destinationssystemet och sedan ändrar den där. Databashanteringslösningar som kan bearbeta stora mängder data, som SQL eller Apache Spark, kan användas för denna operation. Denna metod är fördelaktig när datakällan behöver hållas i sitt ursprungliga format och målsystemet kan göra de nödvändiga transformationerna.
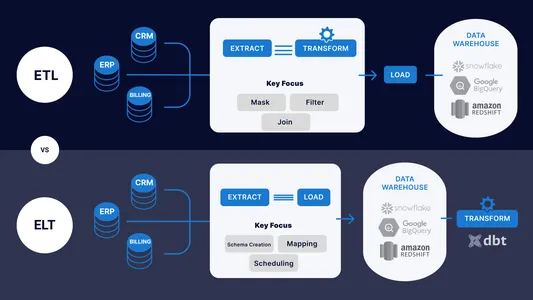
ETL och ELT pipelines integrera data från olika system, inklusive databaser, applikationer och filer, för att skapa en konsekvent och enhetlig bild av data för analys, rapportering och beslutsfattande.
Inlärningsmål
I slutet av den här artikeln kommer du att kunna lära dig skillnaderna mellan ETL och ELT Pipelines, deras för- och nackdelar, och deras tillämpning i olika fall som Data Warehousing, Business Intelligence, Data Integration, etc. Man skulle också lära sig om några metoder för att designa framgångsrika ETL/ELT-pipelines, hur verktyg som Talend, Apache Nifi, Apache Spark, etc kan användas, och vilka strategier för övervakning och felsökning som kan användas för ETL och ELT Pipeline.
Innehållsförteckning
Skillnader mellan ETL och ELT pipelines
| ETL (EXTRACTION, TRANSFORMATION AND LOAD) | ELT (EXTRAKTION, LASTNING OCH TRANSFORMATION) |
| Informationen extraheras först från källsystem, konverteras till ett format som målsystemet kan använda och läggs sedan in i målsystemet. | Informationen laddas först in data i destinationssystemet innan de nödvändiga ändringarna görs i datan där. |
| ETL-pipelines kan vara mer användbara när data behöver omvandlas till ett format som målsystemet inte stöder. Detta leder till en lång konverteringstid och mer hårdvara. | ELT fungerar genom att dela upp arbetet i mindre partier och använda parallell bearbetning, vilket fungerar snabbare. |
| Skalbarheten för ETL kan begränsas eftersom den ändrar data innan den sätts in i ett målsystem. | De är mer skalbara eftersom det innebär att data laddas in i ett målsystem, som sedan omvandlas med hjälp av distribuerade datorverktyg som Hadoop eller Spark. |
| De är vanligtvis lättare att underhålla eftersom det möjliggör större kontroll över datakonsistens och kvalitet, vilket kan hjälpa till att minska risken för fel och göra pipelineunderhållet enklare över tiden. | När du använder ELT-pipelines kan det vara mer utmanande att hjälpa till att hitta problem och underhålla pipeline eftersom data laddas in i målsystemet innan de omvandlas. |
| Den använder mer överkomliga än proprietära ETL-system, såsom Hadoop och Spark, som hjälper till att sänka bearbetningskostnaderna. | De är dyrare när det gäller kostnad eftersom den använder öppen källkodsteknik. |
Sammanfattningsvis är valet mellan ETL- och ELT-pipelines baserat på dataintegrationsprojektets särskilda krav, såsom käll- och målsystemens funktioner, datavolymen och komplexiteten samt kraven på prestanda och skalbarhet.
För- och nackdelar med ETL och ELT Pipelines
I ett enkelt och tydligt språk är fördelarna och nackdelarna med ETL- och ELT-pipelines för olika användningsfall följande:
Fördelar med ETL
- När information behöver konverteras till ett format som målsystemet inte stöder, är ETL till hjälp.
- ETL kan kombinera data från många källor till en enda bild för utvärdering och beslutsfattande.
- ETL-pipelines kan fås att köras mer effektivt genom att använda batch- och parallellbearbetning.
Begränsningar för ETL
- ETL kan vara mödosamt och kräva mycket hårdvaruresurser, särskilt för sofistikerade transformationer och betydande datavolymer.
- För att skapa och tillämpa transformationslogiken kan ETL behöva specialisttalanger.
- Från det att informationen samlas in och den är tillgänglig för analys, kan ETL-processer orsaka förseningar.
Fördelar med ELT
- När målsystemet kan hantera och transformera data i sitt ursprungliga format, kan ELT utföras mer effektivt och snabbare.
- När data måste behållas i sin ursprungliga form och bara ändras för analys och rapportering är ELT till hjälp.
- ELT kan använda flexibiliteten och beräkningskapaciteten hos moderna databashanteringssystem.
Begränsningar för ELT
- Innan du utför transformationer kan ELT behöva mycket lagringsutrymme för att behålla data.
- Att skriva komplicerade SQL-frågor kan kräva detaljerad information för datatransformationer med ELT.
- Målsystemet kan bli mer komplext på grund av ELT, vilket försvårar underhåll och underhåll.
Tillämpning av ETL Pipelines
Applikationer för datalagring och dataanalys används ofta ETL pipelines. I ett enkelt och vanligt språk är följande några användningsfall för ETL-pipelines:
- Datalagring: I ett datalager kombinerar ETL data från flera källor till en enhetlig vy. Data rensas, sätts i ett standardformat och kontrolleras för att garantera kvalitet och konsekvens. ETL laddar ofta in data i datalagret för att hålla data aktuell.
- Business Intelligence: ETL extraherar information från transaktionssystem och laddar in den i ett datalager eller datamart i business intelligence-applikationer. För att möjliggöra rapportering och analys omvandlas och konsolideras informationen. Insamling, bearbetning och inläsning av data i rapporteringssystemet är automatiserad och schemalagd med hjälp av ETL.
- Dataintegration: För att kombinera information från olika källor till ett enda system används ETL. Ett exempel är datafusion från många databaser, kalkylblad och filer. ETL används för att säkerställa att data är korrekta och enhetliga och för att ändra data till ett format som destinationssystemet kan använda.
- Datamigrering: För att överföra information från ett system till ett annat används ETL i datamigreringsprojekt. Det kan handla om dataöverföringar från ett föråldrat system till ett nytt eller att kombinera data från olika system. ETL används under migreringsprocessen för att transformera och kontrollera informationen.
Tillämpning av ELT-rörledningar
ELT-processer (Extract, Load, Transform) används ofta i databehandling och analys för att förbereda stora mängder data för senare användning. Följande är några förenklade användningsfall:
- Datalagring: ELT-pipelines används ofta i datalager för att extrahera data från olika källor, inklusive databaser, molnlagring och online-API:er. Efter att ha transformerats placeras data i ett databassystem för ytterligare analys.
- Big Data Processing: Att analysera enorma mängder data, inklusive sådana dataströmmar eller loggfiler, använder i synnerhet ELT-pipelines. Informationen hämtas först och placeras i en distribuerad databas, såsom Hadoop, innan den parallelliseras med hjälp av Spark eller Hive, bland andra verktyg.
- Maskininlärning: Databearbetning för maskininlärningsapplikationer kan göras via ELT-pipelines. För att göra detta måste data samlas in från olika källor, rensas upp och omvandlas för att vara redo för modellering, och sedan laddas in i ett ramverk för maskininlärning som TensorFlow eller PyTorch.
- Business Intelligence: För att tillhandahålla instrumentpaneler och rapporter för företagsanvändare kan ELT-pipelines samla in och transformera data från olika källor, inklusive kunddata, försäljningsdata och webbanalys.
Tekniker för att designa en effektiv ETL- eller ELT-rörledning
Extraction, Load and Transform, eller ETL, pipelinedesign säkerställer att databearbetningsuppgifter slutförs snabbt och korrekt. Följande är några metoder för att designa framgångsrika ETL/ELT-pipelines:
- Datapartitionering: Datapartitionering delar upp stora datamängder i mer hanterbara delar för parallell bearbetning. Genom att begränsa mängden data som behöver bearbetas på en gång kan partitionering hjälpa till att öka hastigheten och effektiviteten i databehandlingen.
- Datarensning: Datarensning innebär att lokalisera och lösa brister eller inkonsekvenser i data. Tekniker för rengöring av data kan innebära
- Ta bort dubblett eller irrelevant information
- Korrigera stavnings- eller grammatiska problem
- Säkerställa datakonsistens över olika källor
- Datatransformation: Datatransformation är att ändra formatet eller organisationen av data. Att variera datatyper, kombinera eller slå samman databaser och samla in eller utvärdera information är några exempel på datatransformationsprocedurer.
- Inkrementell laddning: Med total laddning bearbetas bara de data som har ändrats eller lagts till sedan föregående bearbetningskörning. Särskilt för stora datamängder kan inkrementell laddning hjälpa till att minska mängden tid och resurser som krävs för databehandling.
- Arbetsschema: Baserat på variabler, inklusive tillgänglig data, handläggningstid och tillgängliga resurser, innebär denna process att skapa en effektiv tidtabell för att utföra ETL/ELT-processer. Ett effektivt program kan förkorta den totala handläggningstiden, vilket garanterar snabb och korrekt databehandling.
Program som kallas ETL- och ELT-verktyg används för dataintegration, bearbetning och transformation. Följande är en förenklad jämförelse av några välkända ETL- och ELT-verktyg:
- Talent: Talend är en plattform för dataintegration och transformation med öppen källkod som erbjuder en mängd olika kopplingar och element för datatransformation. Det ger ett enkelt användargränssnitt och stöder både dra-och-släpp- och programmeringsmetoder. Det ger funktioner som är relevanta för utvecklingen och kvalitetskontroller av information och stödjer batch- och realtidsbearbetning.
- Informatik: En avancerad analytisk integration och transformationsoperation kan stödjas av den kommersiella ETL-produkten Informatica. Det ger en visuell utvecklingsplattform och många kopplingar för olika datakällor. Coherence erbjuder funktioner som datastyrning, datamanipulation och dataintegritet.
- Apache NiFi: Apache NiFi är ett ELT-verktyg med öppen källkod för dataflödeshantering som kallas Apache NiFi. Den innehåller en rad dataintags-, transformations- och routingprocessorer och erbjuder ett webbaserat användargränssnitt. Datahärkomst och härkomstegenskaper tillhandahålls av Apache NiFi, som också erbjuder databehandling i realtid.
- Apache Spark: ETL och ELT kan utföras med Apache Spark, en öppen och distribuerad datorteknik. Det tillåter bulk och faktisk databehandling och erbjuder snabb databehandling. Spark erbjuder maskininlärning, grafanalys och sändningsfunktioner och stöder olika programmeringsspråk.
Rollen för dataintegration och datakvalitet
Att kombinera data från flera källor för att ge en enhetlig bild av datan kallas dataintegration. Data från många källor ansluts med hjälp av ETL (Extract, Transform, Load) och ELT (Extract, Load, Transform) pipelines för att skapa ett datalager eller datasjö.
Kvaliteten på data mäter data noggrannhet, helhet, konsistens och giltighet. Datakvalitet är avgörande för att ställa in ETL- och ELT-pipelines för att garantera att den integrerade datan är säker och praktisk.
För att uttrycka det på ett annat sätt är datakvalitet som att verifiera att pusslets saker passar ihop korrekt och inte är skadade eller saknas. Däremot är dataintegration som att göra delarna av ett pussel tillsammans för att se hela bilden. Processerna som sätter ihop pusselbitarna och säkerställer att de är orienterade och placerade i rätt ordning kallas ETL- och ELT-pipelines.
Strategier för övervakning och felsökning
Det är viktigt att spåra och åtgärda problem med ETL (Extract, Transform, Load) och ELT (Extract, Load, Transform) pipelines för att garantera en effektiv och effektiv drift av dataintegrationsprocessen. Här är några metoder för att hålla koll på saker och felsökning:
- Tidiga varningsproblem: Ställ in varningar och meddelanden för att få aviseringar när en pipeline misslyckas eller stöter på problem. Detta gör att du kan ta itu med problem så snart de uppstår och lösa dem innan de förvärras.
- Övervaka pipelineprestanda: Övervakning av pipelineprestanda innebär att hålla koll på parametrar, inklusive databehandlingstid, dataöverföringshastigheter och resursanvändning. Detta kan hjälpa till med pipeline-optimering och upptäckt av hinder.
- Logga pipelineaktiviteter: Logga pipelineoperationer för att spåra utvecklingen av dataintegration och identifiera problem eller fel. Dessutom kan loggar användas för efterlevnads- och revisionssyften.
- Genomför regelbundna tester: Testa regelbundet för att säkerställa att rörledningen fungerar som den ska. Detta kan hjälpa dig att upptäcka problem innan de blir dyra stillestånd.
- Samarbeta med intressenter: Arbeta tillsammans med intressenter: För att hitta och åtgärda problem, arbeta tillsammans med intressenter som datavetare, ingenjörer och affärsanvändare. Du kan lösa problem och korrekt förstå informationshanteringsprocessen som ett resultat.
Slutsats
Ett projekts särskilda krav och krav kommer att avgöra om ETL eller ETL pipeline ska användas. ETL fungerar bra för småskaliga projekt som kräver manuell anpassning och ingripande i varje arbetsflödessteg. Å andra sidan är en ETL-pipeline bättre lämpad för massiva projekt med enorma mängder data som behöver automatiseras och standardiseras för att säkerställa korrekthet och effektivitet.
Sammanfattningsvis är ETL och ETL pipeline två relaterade men distinkta koncept. En ETL-pipeline är ett automatiserat arbetsflöde som styr hela ETL-processen från början till slut. ETL är en dataintegrationsprocess i tre steg. Projektets storlek, komplexitet och efterfrågan på anpassning och automatisering kommer att avgöra det bästa alternativet.

Key Takeaways
- Inledningsvis har vi sett en översikt över skillnaderna mellan ETL- och ELT-pipelines, inklusive databehandlingsordning och prestandaimplikationer.
- Och sedan förstå för- och nackdelarna med ETL- och ELT-pipelines för olika användningsfall.
- Teknikerna för att designa en effektiv ETL- eller ELT-pipeline inkluderar också datapartitionering, datarensning och datatransformation.
- Jämförelse av populära ETL- och ELT-verktyg, inklusive Talend, Informatica, Apache NiFi och Apache Spark.
- Förstå rollen för dataintegration och datakvalitet i ETL- och ELT-pipelines.
- Strategier för övervakning och felsökning av ETL- och ELT-pipelines och jämförelse av båda.
Relaterad
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- Platoblockchain. Web3 Metaverse Intelligence. Kunskap förstärkt. Tillgång här.
- Källa: https://www.analyticsvidhya.com/blog/2023/03/difference-between-etl-and-elt-pipelines/

