När företag expanderar överstiger efterfrågan på IP-adresser inom företagsnätverket ofta utbudet. En organisations nätverk är ofta utformat med viss förväntan på framtida krav, men i takt med att företagen utvecklas överträffar deras behov av informationsteknologi (IT) det tidigare designade nätverket. Företag kan bli utmanade att hantera den begränsade poolen av IP-adresser.
För datateknik arbetsbelastningar när AWS-lim används i en sådan begränsad nätverkskonfiguration, kan ditt team ibland möta hinder att köra många jobb samtidigt. Detta beror på att du kanske inte har tillräckligt med IP-adresser för att stödja de nödvändiga anslutningarna till databaser. För att övervinna denna brist kan teamet få fler IP-adresser från företagets nätverkspool. Dessa erhållna IP-adresser kan vara unika (icke-överlappande) eller överlappande när IP-adresserna återanvänds i ditt företagsnätverk.
När du använder överlappande IP-adresser behöver du en extra nätverkshantering för att upprätta anslutning. Nätverkslösningar kan innehålla alternativ som privata NAT-gateways (Network Address Translation)., AWS PrivateLink, eller självhanterade NAT-enheter för att översätta IP-adresser.
I det här inlägget kommer vi att diskutera två strategier för att skala AWS limjobb:
- Optimera IP-adressförbrukningen genom att anpassa databehandlingsenheter (DPU) i rätt storlek, använda funktionen Auto Scaling i AWS Glue och finjustera jobben.
- Utöka nätverkskapaciteten med ytterligare icke-routbar Classless Inter-Domain Routing (CIDR)-intervall med en privat NAT-gateway.
Innan vi dyker djupt in i dessa lösningar, låt oss förstå hur AWS Glue använder Elastiskt nätverksgränssnitt (ENI) för att upprätta anslutning. För att möjliggöra åtkomst till datalager inuti en VPC måste du skapa en AWS Glue-anslutning som är kopplad till din VPC. När ett AWS Glue-jobb körs i din VPC, skapar jobbet en ENI inuti den konfigurerade VPC:n för varje dataanslutning, och den ENI använder en IP-adress i den angivna VPC:n. Dessa ENI är kortlivade och aktiva tills jobbet är klart.
Låt oss nu titta på den första lösningen som förklarar optimering av AWS Glue IP-adressförbrukning.
Strategier för effektiv IP-adressförbrukning
I AWS Glue avgör antalet arbetare som ett jobb använder antalet IP-adresser som används från ditt VPC-undernät. Detta beror på att varje arbetare kräver en IP-adress som mappas till en ENI. När du inte har tillräckligt med CIDR-intervall tilldelat AWS Glue-undernätet kan du upptäcka fel på IP-adresser. Följande är några bästa metoder för att optimera AWS Glue IP-adressförbrukning:
- Rätt storlek på jobbets DPU:er – AWS Glue är en distribuerad processmotor. Det fungerar effektivt när det kan köra uppgifter parallellt. Om ett jobb har fler än de nödvändiga DPU:erna går det inte alltid snabbare. Så att hitta rätt antal DPU:er kommer att se till att du använder IP-adresser optimalt. Genom att bygga upp observerbarhet i systemet och analysera jobbets prestanda kan du få insikter i ENI-konsumtionstrender och sedan konfigurera lämplig kapacitet på jobbet för rätt storlek. För mer information, se Övervakning för DPU-kapacitetsplanering. Spark UI är ett användbart verktyg för att övervaka AWS Glue-jobbs arbetaranvändning. För mer information, se Övervaka jobb med Apache Sparks webbgränssnitt.
- AWS Glue Auto Scaling – Det är ofta svårt att förutsäga ett jobbs kapacitetskrav i förväg. Aktivering av funktionen för automatisk skalning av AWS Glue kommer att överföra en del av detta ansvar till AWS. Under körning, baserat på arbetsbelastningskraven, skalar jobbet automatiskt arbetarnoder upp till den definierade maximala konfigurationen. Om det inte finns något ytterligare behov kommer AWS Glue inte att överprovisionera arbetare, vilket sparar resurser och minskar kostnaderna. Funktionen för automatisk skalning är tillgänglig i AWS Glue 3.0 och senare. För mer information, se Vi introducerar AWS Glue Auto Scaling: Ändra automatiskt storlek på serverlösa datorresurser för lägre kostnad med optimerad Apache Spark.
- Optimering på jobbnivå – Identifiera optimeringar på jobbnivå genom att använda AWS limjobbsmått och tillämpa bästa praxis från Bästa metoder för prestandajustering av AWS Glue för Apache Spark-jobb.
Låt oss sedan titta på den andra lösningen som utvecklar nätverkskapacitetsutbyggnad.
Lösningar för expansion av nätverksstorlek (IP-adress).
I det här avsnittet kommer vi att diskutera två möjliga lösningar för att utöka nätverksstorleken mer i detalj.
Utöka VPC CIDR-intervall med routbara adresser
En lösning är att lägga till fler privata IPv4 CIDR-intervall från RFC 1918 till din VPC. Teoretiskt sett kan varje AWS-konto tilldelas några eller alla dessa IP-adress-CIDR:er. Ditt IP-adresshanteringsteam (IPAM) hanterar ofta allokeringen av IP-adresser som varje affärsenhet kan använda från RFC1918 för att undvika överlappande IP-adresser över flera AWS-konton eller affärsenheter. Om din nuvarande ruttbara IP-adresskvot som tilldelats av IPAM-teamet inte är tillräcklig, kan du begära mer.
Om ditt IPAM-team ger dig ett ytterligare icke-överlappande CIDR-intervall, kan du antingen lägga till det som en sekundär CIDR till din befintliga VPC eller skapa en ny VPC med den. Om du planerar att skapa en ny VPC kan du koppla ihop VPC:erna via VPC-peering or AWS Transit Gateway.
Om denna extra kapacitet räcker för att driva alla dina jobb inom den definierade tidsramen är det en enkel och kostnadseffektiv lösning. Annars kan du överväga att använda överlappande IP-adresser med en privat NAT-gateway, som beskrivs i följande avsnitt. Med följande lösning måste du använda Transit Gateway för att ansluta VPC:er eftersom VPC-peering inte är möjlig när det finns överlappande CIDR-intervall i dessa två VPC:er.
Konfigurera icke-routbar CIDR med en privat NAT-gateway
Som beskrivs i AWS whitepaper Bygga en skalbar och säker multi-VPC AWS-nätverksinfrastruktur, kan du utöka din nätverkskapacitet genom att skapa ett undernät för icke-routbar IP-adress och använda en privat NAT-gateway som finns i ett dirigerbart IP-adressutrymme (icke överlappande) för att dirigera trafik. En privat NAT-gateway översätter och dirigerar trafik mellan icke-dirigerbara IP-adresser och dirigerbara IP-adresser. Följande diagram visar lösningen med hänvisning till AWS Glue.
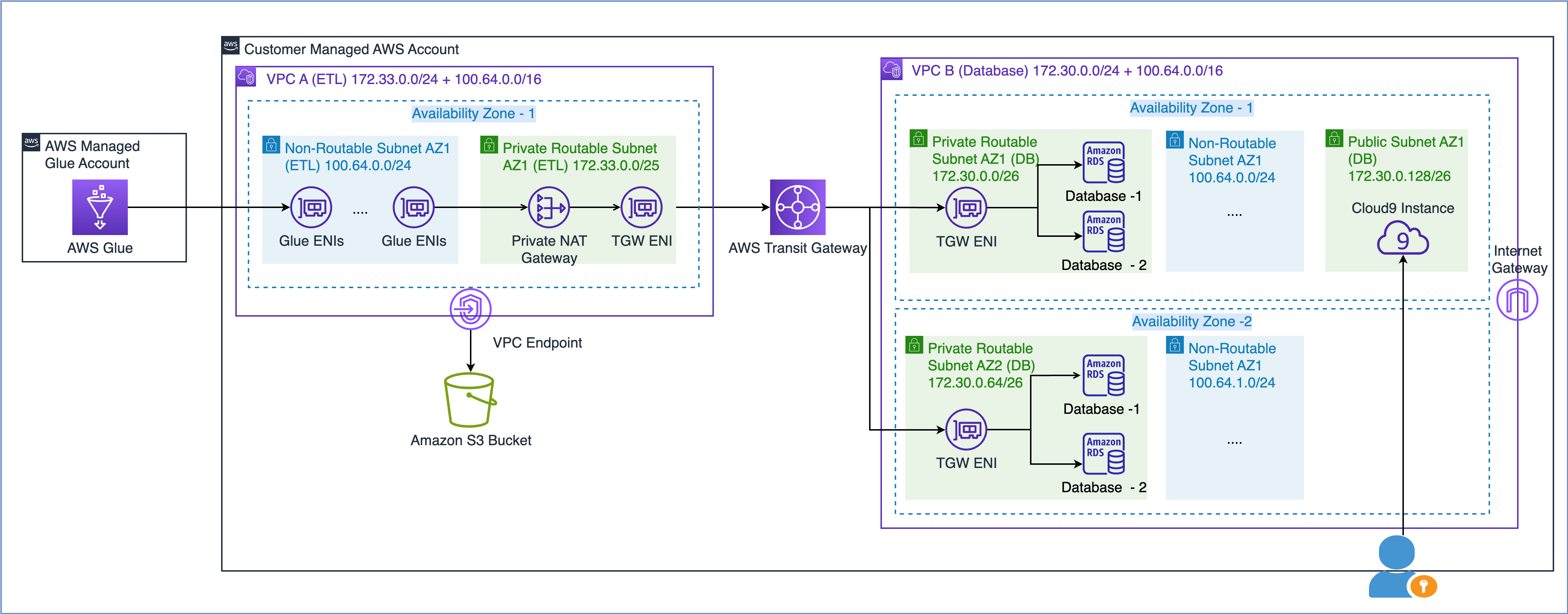
Som du kan se i diagrammet ovan har VPC A (ETL) två CIDR-intervall kopplade. Det mindre CIDR-intervallet 172.33.0.0/24 är routbart eftersom det inte återanvänds någonstans, medan det större CIDR-intervallet 100.64.0.0/16 inte är routbart eftersom det återanvänds i databasen VPC.
I VPC B (Databas) har vi varit värd för två databaser i routbara delnät 172.30.0.0/26 och 172.30.0.64/26. Dessa två undernät finns i två separata tillgänglighetszoner för hög tillgänglighet. Vi har också ytterligare två oanvända subnät 100.64.0.0/24 och 100.64.1.0/24 för att simulera en icke-rutbar installation.
Du kan välja storleken på det icke-routbara CIDR-sortimentet baserat på dina kapacitetskrav. Eftersom du kan återanvända IP-adresser kan du skapa ett mycket stort subnät efter behov. Till exempel skulle en CIDR-mask på /16 ge dig cirka 65,000 4 IPvXNUMX-adresser. Du kan arbeta med ditt nätverksteknikteam och göra storlek på undernäten.
Kort sagt, du kan konfigurera AWS Glue-jobb för att använda både routbara och icke routbara subnät i din VPC för att maximera den tillgängliga IP-adresspoolen.
Låt oss nu förstå hur Glue ENIs som finns i ett icke-routbart subnät kommunicerar med datakällor i en annan VPC.
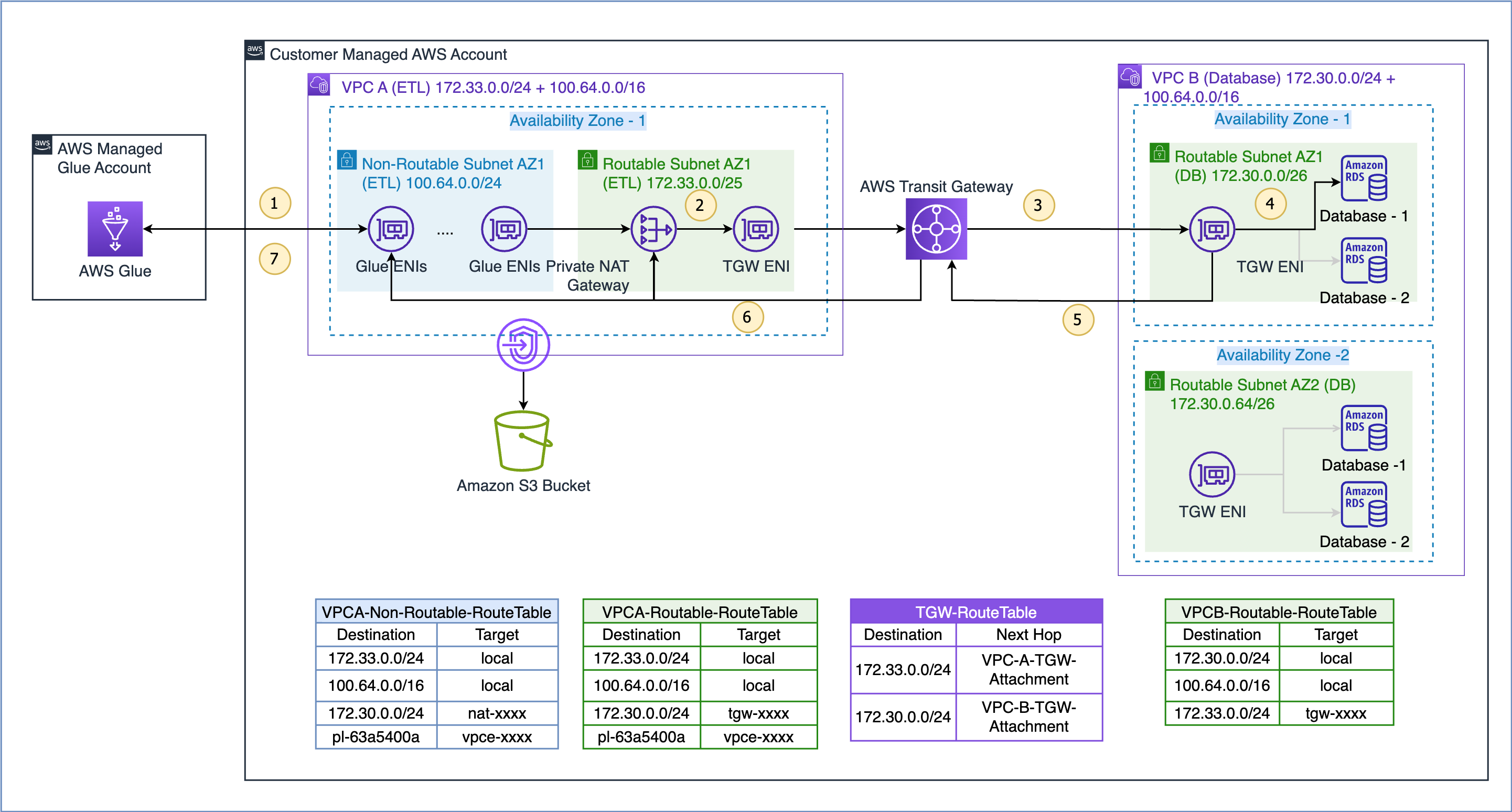
Dataflödet för användningsfallet som visas här är som följer (med hänvisning till de numrerade stegen i figuren ovan):
- När ett AWS Glue-jobb behöver komma åt en datakälla, använder det först AWS Glue-anslutningen på jobbet och skapar ENI i det icke-routbara subnätet 100.64.0.0/24 i VPC A. Senare använder AWS Glue databasanslutningskonfigurationen och försöker ansluta till databasen i VPC B 172.30.0.0/24.
- Enligt rutttabellen
VPCA-Non-Routable-RouteTabledestinationen 172.30.0.0/24 är konfigurerad för en privat NAT-gateway. Begäran skickas till NAT-gatewayen, som sedan översätter käll-IP-adressen från en icke-routbar IP-adress till en routbar IP-adress. Trafik skickas sedan till transitgatewaybilagan i VPC A eftersom den är associerad medVPCA-Routable-RouteTablerutttabell i VPC A. - Transit Gateway använder rutten 172.30.0.0/24 och skickar trafiken till VPC B transitgateway-bilaga.
- Transitporten ENI i VPC B använder VPC B:s lokala rutt för att ansluta till databasens slutpunkt och fråga efter data.
- När frågan är klar skickas svaret tillbaka till VPC A. Svarstrafiken dirigeras till transitgatewaybilagan i VPC B, sedan använder Transit Gateway rutten 172.33.0.0/24 och skickar trafik till VPC A transitgatewaybilagan .
- Transitgatewayen ENI i VPC A använder den lokala vägen för att vidarebefordra trafiken till den privata NAT-gatewayen, som översätter destinations-IP-adressen till den för ENI i icke-routbara subnät.
- Slutligen tar AWS Glue-jobbet emot data och fortsätter bearbetningen.
Den privata NAT-gatewaylösningen är ett alternativ om du behöver extra IP-adresser när du inte kan få dem från ett routbart nätverk i din organisation. Ibland uppstår en extra kostnad för varje tilläggstjänst, och denna avvägning är nödvändig för att nå dina mål. Se prissektionen för NAT Gateway på Prissida för Amazon VPC för mer information.
Förutsättningar
För att slutföra genomgången av den privata NAT-gatewaylösningen behöver du följande:
Distribuera lösningen
Följ följande steg för att implementera lösningen:
- Logga in på din AWS-hanteringskonsol.
- Distribuera lösningen genom att klicka
 . Denna stack har som standard
. Denna stack har som standard us-east-1, kan du välja önskad region. - Klicka Nästa och ange sedan stackdetaljerna. Du kan behålla inmatningsparametrarna till de förinställda standardvärdena eller ändra dem efter behov.
- För
DatabaseUserPassword, ange ett valfritt alfanumeriskt lösenord och se till att anteckna det för vidare användning. - För
S3BucketName, ange en unik Amazon enkel lagringstjänst (Amazon S3) hinknamn. Den här hinken lagrar AWS Glue-jobbskriptet som kommer att kopieras från ett AWS offentliga kodlager.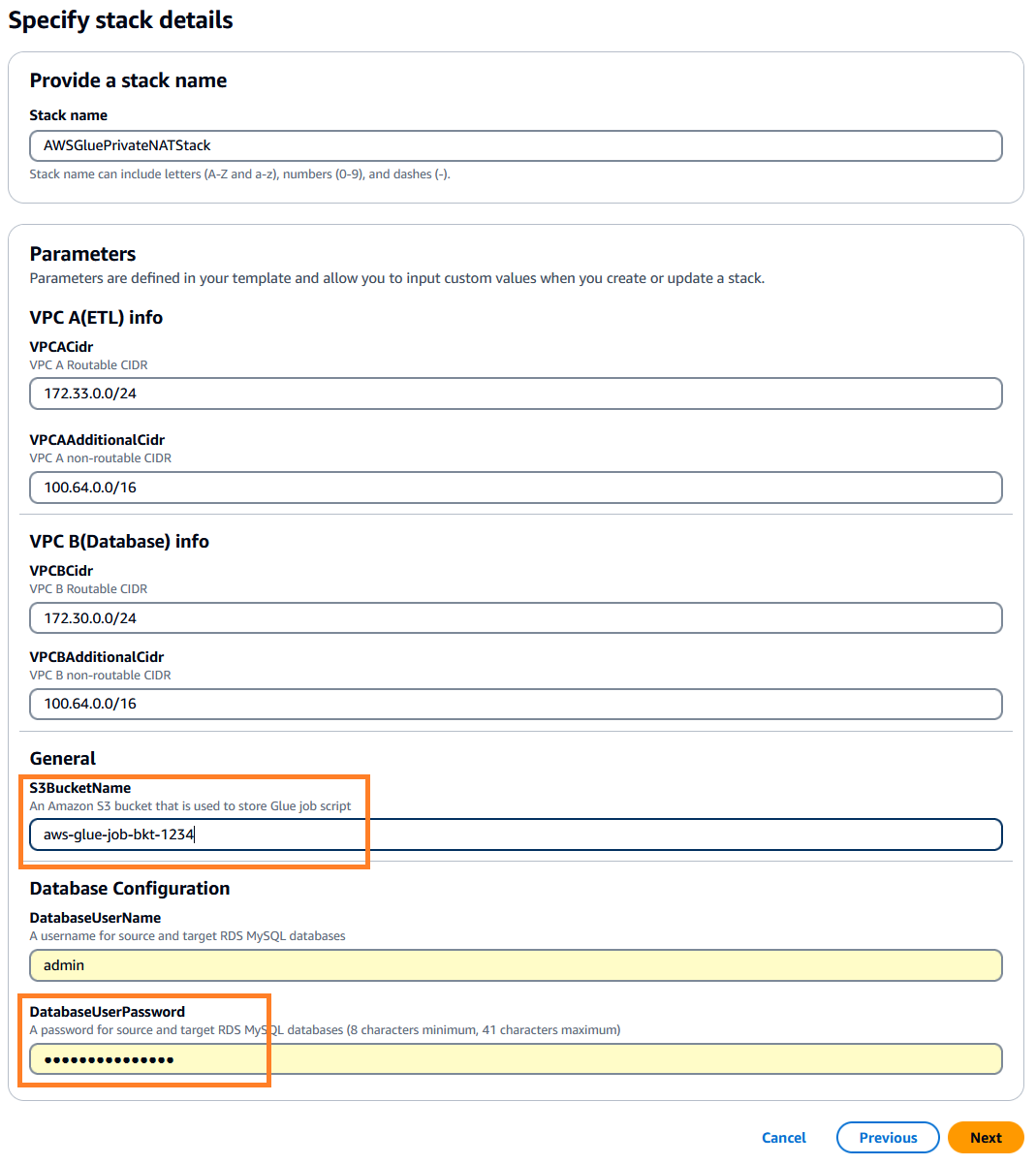
- Klicka Nästa.
- Lämna standardvärdena och klicka Nästa igen.
- Granska detaljerna, bekräfta skapandet av IAM-resurser och klicka skicka för att starta distributionen.
Du kan övervaka händelserna för att se resurser som skapas på AWS CloudFormation-konsolen. Det kan ta cirka 20 minuter för stackresurserna att skapas.
När stacken är klar, gå till fliken Utgångar på AWS CloudFormation-konsolen och notera följande värden för senare användning:
DBSourceDBTargetSourceCrawlerTargetCrawler
Anslut till en AWS Cloud9-instans
Därefter måste vi förbereda källan och rikta Amazon RDS för MySQL-tabeller med hjälp av en AWS Cloud9 exempel. Slutför följande steg:
- På AWS Cloud9-konsolsidan letar du reda på
aws-glue-cloud9miljö. - Klicka på i kolumnen Cloud9 IDE Öppen för att starta din AWS Cloud9-instans i en ny webbläsare.
Förbered MySQL-källtabellen
Utför följande steg för att förbereda din källtabell:
- Från AWS Cloud9-terminalen installerar du MySQL-klienten med följande kommando:
sudo yum update -y && sudo yum install -y mysql - Anslut till källdatabasen med följande kommando. Ersätt källvärdnamnet med DBSource-värdet som du fångade tidigare. När du blir ombedd anger du databaslösenordet som du angav när du skapade stacken.
mysql -h <Source Hostname> -P 3306 -u admin -p - Kör följande skript för att skapa källan
emptabell och ladda testdata:-- connect to source database USE srcdb; -- Drop emp table if it exists DROP TABLE IF EXISTS emp; -- Create the emp table CREATE TABLE emp (empid INT AUTO_INCREMENT, ename VARCHAR(100) NOT NULL, edept VARCHAR(100) NOT NULL, PRIMARY KEY (empid)); -- Create a stored procedure to load sample records into emp table DELIMITER $$ CREATE PROCEDURE sp_load_emp_source_data() BEGIN DECLARE empid INT; DECLARE ename VARCHAR(100); DECLARE edept VARCHAR(50); DECLARE cnt INT DEFAULT 1; -- Initialize counter to 1 to auto-increment the PK DECLARE rec_count INT DEFAULT 1000; -- Initialize sample records counter TRUNCATE TABLE emp; -- Truncate the emp table WHILE cnt <= rec_count DO -- Loop and load the required number of sample records SET ename = CONCAT('Employee_', FLOOR(RAND() * 100) + 1); -- Generate random employee name SET edept = CONCAT('Dept_', FLOOR(RAND() * 100) + 1); -- Generate random employee department -- Insert record with auto-incrementing empid INSERT INTO emp (ename, edept) VALUES (ename, edept); -- Increment counter for next record SET cnt = cnt + 1; END WHILE; COMMIT; END$$ DELIMITER ; -- Call the above stored procedure to load sample records into emp table CALL sp_load_emp_source_data(); - Kontrollera källan
emptabellens antal med hjälp av SQL-frågan nedan (du behöver detta i ett senare steg för verifiering).select count(*) from emp; - Kör följande kommando för att avsluta MySQL-klientverktyget och återgå till AWS Cloud9-instansens terminal:
quit;
Förbered måltabellen för MySQL
Utför följande steg för att förbereda måltabellen:
- Anslut till måldatabasen med följande kommando. Ersätt målvärdnamnet med DBTarget-värdet som du fångade tidigare. När du uppmanas att ange databaslösenordet som du angav när stacken skapades.
mysql -h <Target Hostname> -P 3306 -u admin -p - Kör följande skript för att skapa målet
emptabell. Denna tabell kommer att laddas av AWS Glue-jobbet i det efterföljande steget.-- connect to the target database USE targetdb; -- Drop emp table if it exists DROP TABLE IF EXISTS emp; -- Create the emp table CREATE TABLE emp (empid INT AUTO_INCREMENT, ename VARCHAR(100) NOT NULL, edept VARCHAR(100) NOT NULL, PRIMARY KEY (empid) );
Verifiera nätverksinställningarna (valfritt)
Följande steg är användbara för att förstå NAT-gateway, rutttabeller och transitgateway-konfigurationerna för privat NAT-gatewaylösning. Dessa komponenter skapades när CloudFormation-stacken skapades.
- På Amazon VPC-konsolsidan, navigera till Virtual Private Cloud-sektionen och leta reda på NAT-gateways.
- Sök efter NAT Gateway med namn
Glue-OverlappingCIDR-NATGWoch utforska det vidare. Som du kan se i följande skärmdump skapades NAT-gatewayen i VPC A (ETL) på det routbara subnätet.
- I den vänstra navigeringsrutan navigerar du till rutttabeller under avsnittet virtuellt privat moln.
- Sök efter
VPCA-Non-Routable-RouteTableoch utforska det vidare. Du kan se att rutttabellen är konfigurerad för att översätta trafik från överlappande CIDR med hjälp av NAT-gatewayen.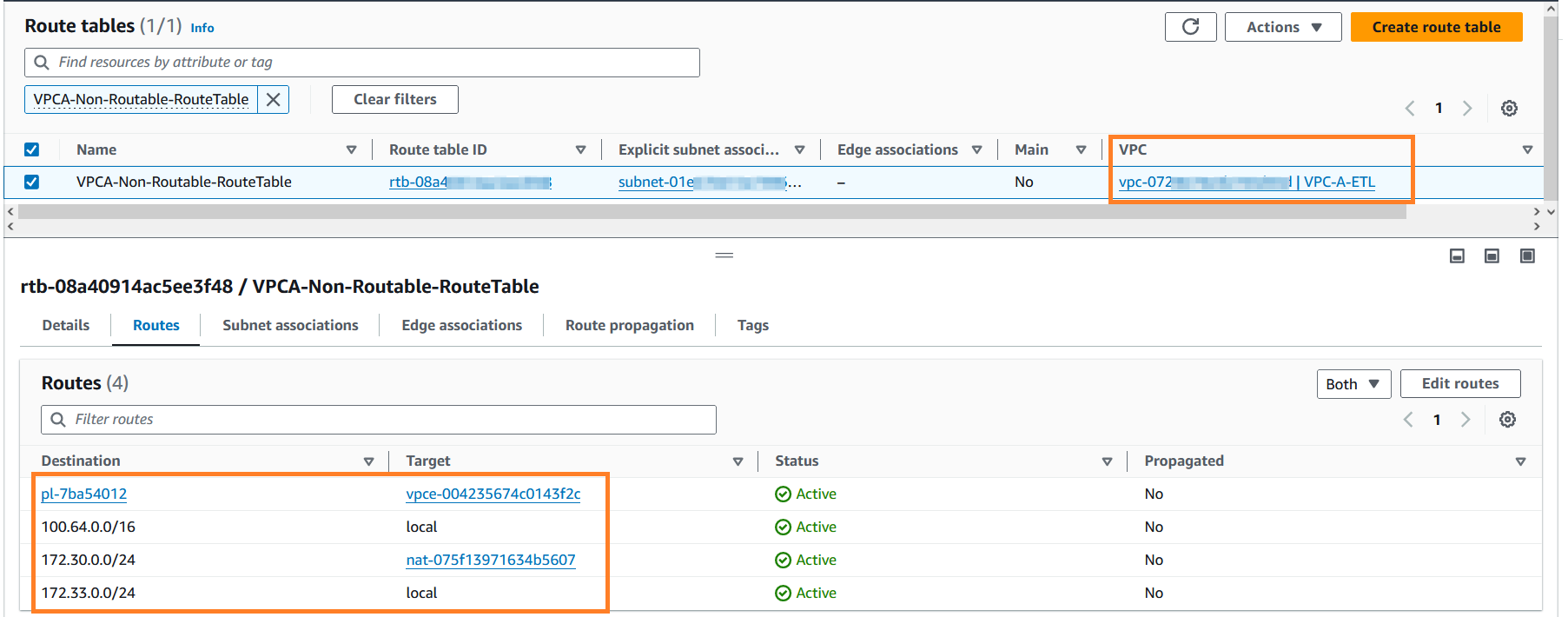
- I den vänstra navigeringsrutan, navigera till avsnittet Transit gateways och klicka på Transit gateway bilagor. Stiga på
VPC-i sökrutan och leta reda på de två nyskapade transitgateway-bilagorna. - Du kan utforska dessa bilagor ytterligare för att lära dig deras konfigurationer.
Kör AWS Glue crawlers
Slutför följande steg för att köra AWS Glue-sökrobotarna som krävs för att katalogisera källan och målet emp tabeller. Detta är ett förutsättningssteg för att köra AWS Glue-jobbet.
- På sidan AWS Glue Console, under avsnittet Datakatalog i navigeringsfönstret, klicka på crawlers.
- Leta reda på käll- och målsökrobotarna som du noterade tidigare.
- Välj dessa sökrobotar och klicka Körning för att skapa respektive AWS Glue Data Catalog-tabeller.
- Du kan övervaka AWS Glue-sökrobotarna för framgångsrikt slutförande. Det kan ta cirka 3–4 minuter för båda sökrobotarna att slutföra. När de är klara ändras den senaste körningsstatusen för jobbet till Lyckad, och du kan också se att det finns två AWS Glue-katalogtabeller skapade från denna körning.

Kör AWS Glue ETL-jobbet
När du har ställt in tabellerna och slutfört de nödvändiga stegen är du nu redo att köra AWS Glue-jobbet som du skapade med CloudFormation-mallen. Det här jobbet ansluter till källdatabasen RDS för MySQL, extraherar data och laddar data till RDS-måldatabasen för MySQL. Det här jobbet läser data från en käll-MySQL-tabell och laddar den till mål-MySQL-tabellen med hjälp av privat NAT-gateway-lösning. Utför följande steg för att köra AWS Glue-jobbet:
- På AWS Glue-konsolen klickar du på ETL jobb i navigeringsfönstret.
- Klicka på jobbet
glue-private-nat-job. - Klicka Körning att starta det.
Följande är PySpark-skriptet för detta ETL-jobb:
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
args = getResolvedOptions(sys.argv, ["JOB_NAME"])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args["JOB_NAME"], args)
# Script generated for node AWS Glue Data Catalog
AWSGlueDataCatalog_node = glueContext.create_dynamic_frame.from_catalog(
database="glue_cat_db_source",
table_name="srcdb_emp",
transformation_ctx="AWSGlueDataCatalog_node",
)
# Script generated for node Change Schema
ChangeSchema_node = ApplyMapping.apply(
frame=AWSGlueDataCatalog_node,
mappings=[
("empid", "int", "empid", "int"),
("ename", "string", "ename", "string"),
("edept", "string", "edept", "string"),
],
transformation_ctx="ChangeSchema_node",
)
# Script generated for node AWS Glue Data Catalog
AWSGlueDataCatalog_node = glueContext.write_dynamic_frame.from_catalog(
frame=ChangeSchema_node,
database="glue_cat_db_target",
table_name="targetdb_emp",
transformation_ctx="AWSGlueDataCatalog_node",
)
job.commit()
Baserat på jobbets DPU-konfiguration skapar AWS Glue en uppsättning ENI:er i det icke-routbara subnätet som är konfigurerat på AWS Glue-anslutningen. Du kan övervaka dessa ENI på sidan Nätverksgränssnitt på Amazon Elastic Compute Cloud (Amazon EC2) konsol.
Skärmbilden nedan visar de 10 ENI:er som skapades för jobbkörningen för att matcha det begärda antalet arbetare som konfigurerats på jobbparametrarna. Som förväntat skapades ENI:erna i det icke-routbara subnätet av VPC A, vilket möjliggör skalbarhet för IP-adresser. När jobbet är klart kommer dessa ENI:er att släppas automatiskt av AWS Glue.
När AWS Glue-jobbet körs kan du övervaka dess status. Efter framgångsrikt slutförande ändras jobbets status till Lyckades.
Verifiera resultaten
När AWS Glue-jobbet är klart, anslut till måldatabasen MySQL. Kontrollera om antalet målposter stämmer överens med källan. Du kan använda SQL-frågan nedan i AWS Cloud9-terminalen.
USE targetdb;
SELECT count(*) from emp;Slutligen, avsluta MySQL-klientverktyget med följande kommando och återgå till AWS Cloud9-terminalen: quit;
Du kan nu bekräfta att AWS Glue har slutfört ett jobb för att ladda data till en måldatabas med hjälp av IP-adresserna från ett icke-routbart subnät. Detta avslutar end-to-end-testningen av den privata NAT-gatewaylösningen.
Städa upp
För att undvika framtida avgifter, ta bort resursen som skapats via CloudFormation-stacken genom att utföra följande steg:
- På AWS CloudFormation-konsolen klickar du på Stacks i navigeringsfönstret.
- Välj stacken
AWSGluePrivateNATStack. - Klicka på Ta bort för att ta bort stacken. När du uppmanas att bekräfta raderingen av stack.
Slutsats
I det här inlägget demonstrerade vi hur du kan skala AWS Glue-jobb genom att optimera IP-adressförbrukningen och utöka din nätverkskapacitet genom att använda en privat NAT-gatewaylösning. Detta tvåfaldiga tillvägagångssätt hjälper dig att bli avblockerad i en miljö som har IP-adresskapacitetsbegränsningar. Alternativen som diskuteras i avsnittet AWS Glue IP-adressoptimering är komplement till lösningarna för IP-adressexpansion, och du kan iterativt bygga för att mogna din dataplattform.
Lär dig mer om AWS limjobboptimeringstekniker från Övervaka och optimera kostnaden för AWS Glue for Apache Spark och Bästa metoder för att skala Apache Spark-jobb och partitioneringsdata med AWS Glue.
Om författarna
 Sushanth Kothapally är en lösningsarkitekt på Amazon Web Services som stödjer fordons- och tillverkningskunder. Han brinner för att designa tekniska lösningar för att möta affärsmål och har stort intresse för serverlösa och händelsedrivna arkitekturer.
Sushanth Kothapally är en lösningsarkitekt på Amazon Web Services som stödjer fordons- och tillverkningskunder. Han brinner för att designa tekniska lösningar för att möta affärsmål och har stort intresse för serverlösa och händelsedrivna arkitekturer.
 Senthil Kamala Rathinam är en lösningsarkitekt på Amazon Web Services specialiserad på data och analys. Han brinner för att hjälpa kunder att designa och bygga moderna dataplattformar. På fritiden älskar Senthil att umgås med sin familj och spela badminton.
Senthil Kamala Rathinam är en lösningsarkitekt på Amazon Web Services specialiserad på data och analys. Han brinner för att hjälpa kunder att designa och bygga moderna dataplattformar. På fritiden älskar Senthil att umgås med sin familj och spela badminton.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoData.Network Vertical Generative Ai. Styrka dig själv. Tillgång här.
- PlatoAiStream. Web3 Intelligence. Kunskap förstärkt. Tillgång här.
- Platoesg. Kol, CleanTech, Energi, Miljö, Sol, Avfallshantering. Tillgång här.
- PlatoHealth. Biotech och kliniska prövningar Intelligence. Tillgång här.
- Källa: https://aws.amazon.com/blogs/big-data/scale-aws-glue-jobs-by-optimizing-ip-address-consumption-and-expanding-network-capacity-using-a-private-nat-gateway/

