När du kör Apache Flink-applikationer på Amazon Managed Service för Apache Flink, har du den unika fördelen att dra fördel av dess serverlösa natur. Detta innebär att kostnadsoptimeringsövningar kan ske när som helst – de behöver inte längre ske i planeringsfasen. Med Managed Service för Apache Flink kan du lägga till och ta bort compute med ett knapptryck.
Apache Flink är ett ramverk för strömbehandling med öppen källkod som används av hundratals företag inom kritiska affärsapplikationer och av tusentals utvecklare som har behov av strömbearbetning för sina arbetsbelastningar. Den är mycket tillgänglig och skalbar och erbjuder hög genomströmning och låg latens för de mest krävande strömbehandlingsapplikationerna. Dessa skalbara egenskaper hos Apache Flink kan vara nyckeln till att optimera dina kostnader i molnet.
Managed Service för Apache Flink är en helt hanterad tjänst som minskar komplexiteten i att bygga och hantera Apache Flink-applikationer. Managed Service för Apache Flink hanterar den underliggande infrastrukturen och Apache Flink-komponenter som ger hållbart applikationstillstånd, mätvärden, loggar och mer.
I det här inlägget kan du lära dig mer om kostnadsmodellen Managed Service för Apache Flink, områden där du kan spara på kostnader i dina Apache Flink-applikationer och överlag få en bättre förståelse för dina databehandlingspipelines. Vi dyker djupt ner i att förstå dina kostnader, förstå om din applikation är överprovisionerad, hur man tänker på skalning automatiskt och sätt att optimera dina Apache Flink-applikationer för att spara kostnader. Slutligen ställer vi viktiga frågor om din arbetsbelastning för att avgöra om Apache Flink är rätt teknik för ditt användningsfall.
Hur kostnader beräknas på Managed Service för Apache Flink
För att optimera för kostnader med avseende på din Managed Service for Apache Flink-applikation kan det hjälpa att ha en god uppfattning om vad som ingår i prissättningen för den hanterade tjänsten.
Managed Service för Apache Flink-applikationer består av Kinesis Processing Units (KPUs), som är beräkningsinstanser som består av 1 virtuell CPU och 4 GB minne. Det totala antalet KPU:er som tilldelats applikationen bestäms genom att multiplicera två parametrar som du styr direkt:
- parallel~~POS=TRUNC – Nivån på parallell bearbetning i Apache Flink-applikationen
- Parallellism per KPU – Antalet resurser som ägnas åt varje parallellitet
Antalet KPU:er bestäms av den enkla formeln: KPU = Parallelism / ParallelismPerKPU, avrundat uppåt till nästa heltal.
En extra KPU per applikation debiteras också för orkestrering och används inte direkt för databehandling.
Det totala antalet KPU:er bestämmer antalet resurser, CPU, minne och programlagring som allokeras till programmet. För varje KPU får applikationen 1 vCPU och 4 GB minne, varav 3 GB tilldelas som standard till den körande applikationen och de återstående 1 GB används för hantering av programtillståndslager. Varje KPU kommer också med 50 GB lagringsutrymme kopplat till applikationen. Apache Flink behåller applikationstillstånd i minnet till en konfigurerbar gräns och spillover till den bifogade lagringen.
Den tredje kostnadskomponenten är hållbara programsäkerhetskopior, eller snapshots. Detta är helt valfritt och dess inverkan på den totala kostnaden är liten, om du inte behåller ett mycket stort antal ögonblicksbilder.
I skrivande stund kostar varje KPU i den amerikanska östra (Ohio) AWS-regionen 0.11 USD per timme och lagring av anslutna program kostar 0.10 USD per GB per månad. Kostnaden för hållbar programsäkerhetskopiering (snapshots) är 0.023 USD per GB och månad. Hänvisa till Amazon Managed Service för Apache Flink-prissättning för uppdaterade priser och olika regioner.
Följande diagram illustrerar de relativa proportionerna av kostnadskomponenter för en applikation som körs på Managed Service för Apache Flink. Du styr antalet KPU:er via parallellitet och parallellitet per KPU-parametrar. Lagring för hållbart program för säkerhetskopiering representeras inte.
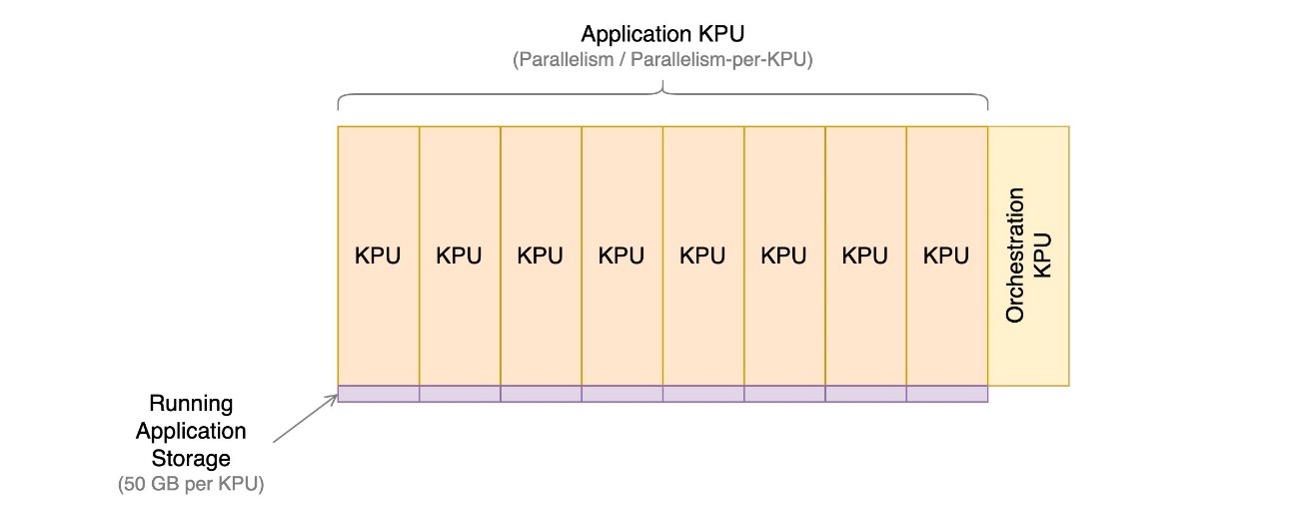
I följande avsnitt undersöker vi hur du övervakar dina kostnader, optimerar användningen av applikationsresurser och hittar det antal KPU:er som krävs för att hantera din genomströmningsprofil.
AWS Cost Explorer och förstå din faktura
För att se vad din nuvarande Managed Service för Apache Flink spenderar kan du använda AWS Cost Explorer.
På Cost Explorer-konsolen kan du filtrera efter datumintervall, användningstyp och tjänst för att isolera dina utgifter för Managed Service för Apache Flink-applikationer. Följande skärmdump visar de senaste 12 månadernas kostnad uppdelad i de priskategorier som beskrivs i föregående avsnitt. Majoriteten av utgifterna under många av dessa månader kom från interaktiva KPU:er från Amazon Managed Service för Apache Flink Studio.
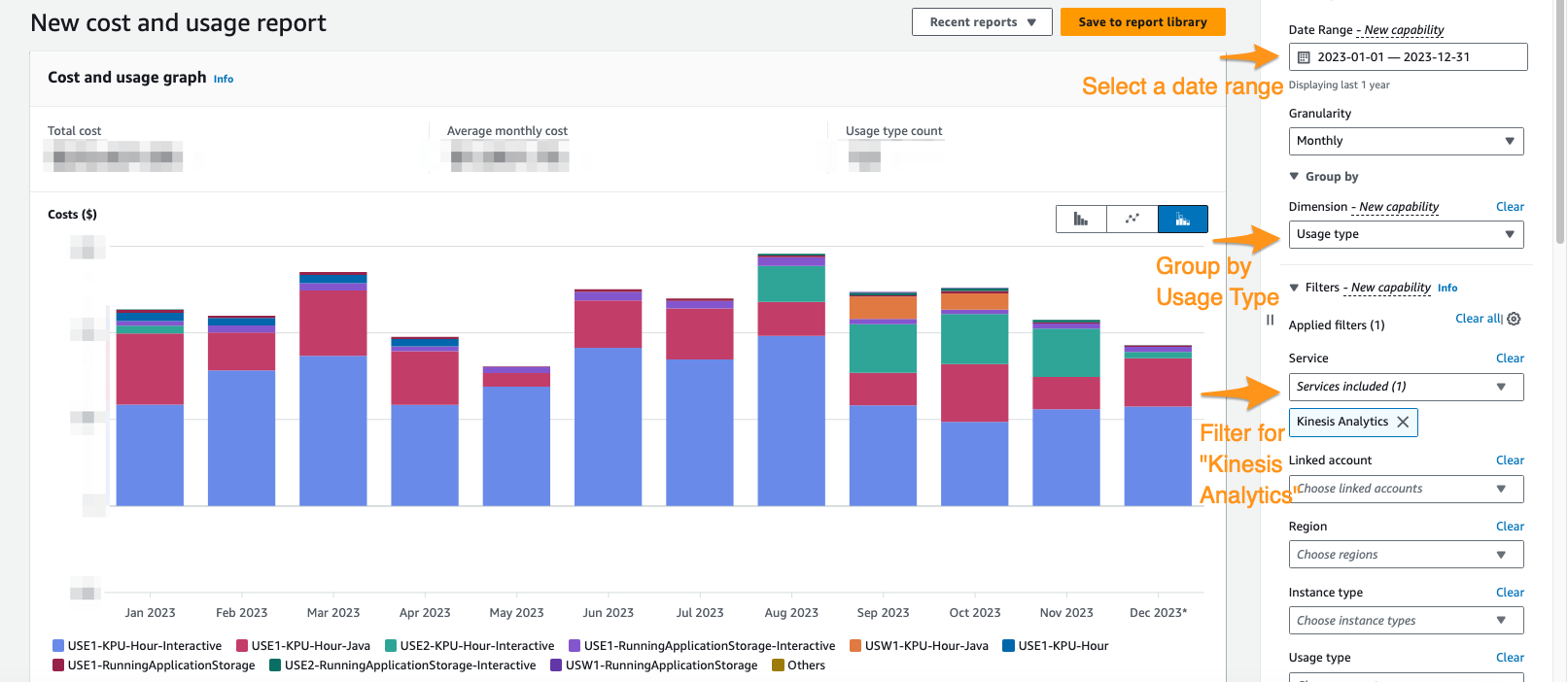
Att använda Cost Explorer kan inte bara hjälpa dig att förstå din faktura, utan hjälpa dig att ytterligare optimera särskilda applikationer som kan ha skalat över förväntan automatiskt eller på grund av genomströmningskrav. Med korrekt applikationsmärkning kan du också dela upp dessa utgifter efter applikation för att se vilka applikationer som står för kostnaden.
Tecken på överprovision eller ineffektiv användning av resurser
För att minimera kostnaderna för Managed Service för Apache Flink-applikationer, innebär ett enkelt tillvägagångssätt att minska antalet KPU:er som dina applikationer använder. Det är dock viktigt att inse att denna minskning kan påverka prestandan negativt om den inte utvärderas och testas noggrant. För att snabbt avgöra om dina applikationer kan vara överprovisionerade, undersök nyckelindikatorer som CPU- och minnesanvändning, applikationsfunktionalitet och datadistribution. Men även om dessa indikatorer kan tyda på potentiell överprovisionering, är det viktigt att utföra prestandatester och validera dina skalningsmönster innan du gör några justeringar av antalet KPU:er.
Metrics
Analysera mätvärden för din ansökan on amazoncloudwatch kan avslöja tydliga signaler om överprovisionering. Om containerCPUUtilization och containerMemoryUtilization mätvärden förblir konsekvent under 20 % under en statistiskt signifikant period för din applikations trafikmönster, kan det vara lönsamt att skala ner och allokera mer data till färre maskiner. I allmänhet anser vi att applikationer har rätt storlek när containerCPUUtilization svävar mellan 50–75 %. Fastän containerMemoryUtilization kan fluktuera under dagen och påverkas av kodoptimering, kan ett konsekvent lågt värde under en avsevärd tid indikera potentiell överprovisionering.
Parallellism per KPU underutnyttjad
Ett annat subtilt tecken på att din applikation är överprovisionerad är om din applikation är rent I/O-bunden, eller bara gör enkla anrop till databaser och icke-CPU-intensiva operationer. Om så är fallet kan du använda parallelliteten per KPU-parameter inom Managed Service för Apache Flink för att ladda fler uppgifter till en enda bearbetningsenhet.
Du kan se parallelliteten per KPU-parameter som ett mått på densiteten av arbetsbelastning per enhet av beräknings- och minnesresurser (KPU). Ökad parallellitet per KPU över standardvärdet 1 gör bearbetningen tätare, och allokerar fler parallella processer på en enda KPU.
Följande diagram illustrerar hur, genom att hålla applikationens parallellitet konstant (till exempel 4) och öka parallelliteten per KPU (till exempel från 1 till 2), använder din applikation färre resurser med samma nivå av parallella körningar.
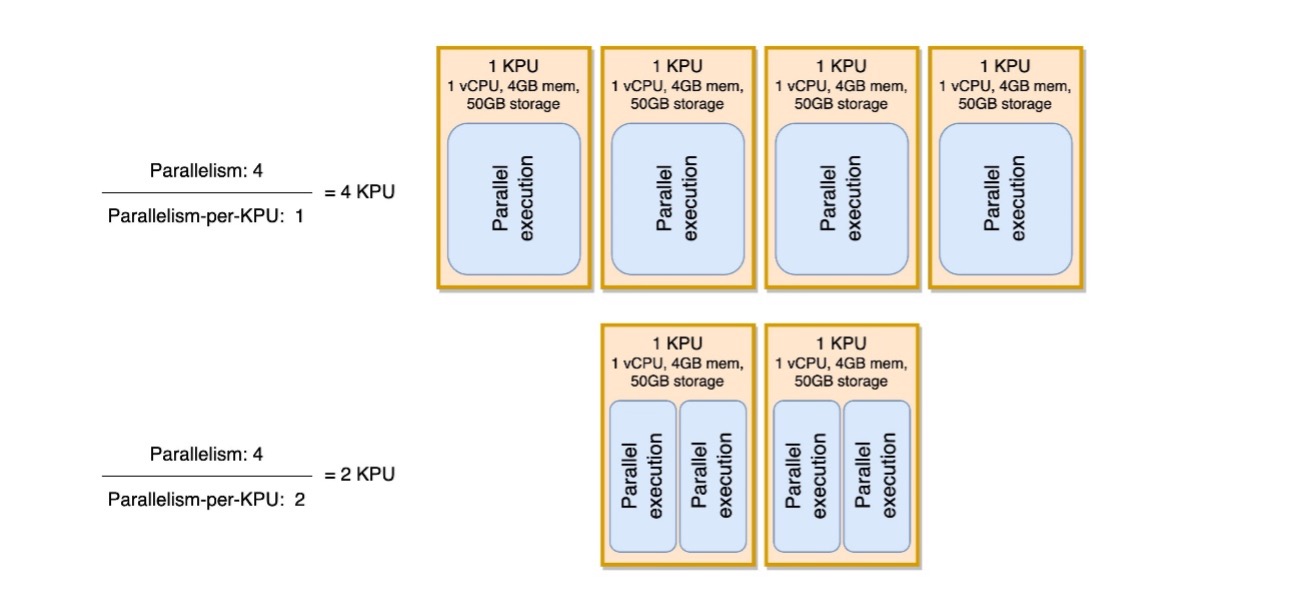
Beslutet att öka parallelliteten per KPU, liksom alla rekommendationer i detta inlägg, bör tas med stor försiktighet. Att öka parallelliteten per KPU-värde kan belasta en enda KPU mer och den måste vara villig att tolerera den belastningen. I/O-bundna operationer kommer inte att öka CPU- eller minnesutnyttjandet på något meningsfullt sätt, men en processfunktion som beräknar många komplexa operationer mot data skulle inte vara en idealisk operation för att samla in på en enda KPU, eftersom den kan överväldiga resurserna. Prestandatesta och utvärdera om detta är ett bra alternativ för dina applikationer.
Hur man närmar sig dimensionering
Innan du startar en Managed Service för Apache Flink-applikation kan det vara svårt att uppskatta antalet KPU:er du bör allokera för din applikation. I allmänhet bör du ha en god känsla för dina trafikmönster innan du gör en uppskattning. Att förstå dina trafikmönster på en megabyte-per-sekund intagshastighet kan hjälpa dig att uppskatta en utgångspunkt.
Som en allmän regel kan du börja med en KPU per 1 MB/s som din ansökan kommer att behandla. Till exempel, om din ansökan behandlar 10 MB/s (i genomsnitt), skulle du tilldela 10 KPU:er som utgångspunkt för din ansökan. Tänk på att detta är en uppskattning på mycket hög nivå som vi har sett effektiv för en allmän uppskattning. Men du måste också prestandatesta och utvärdera om detta är en lämplig storlek på lång sikt baserat på mätvärden (CPU, minne, latens, övergripande jobbprestanda) över en lång tidsperiod.
För att hitta rätt storlek för din applikation måste du skala upp och ner i Apache Flink-applikationen. Som nämnts, i Managed Service för Apache Flink har du två separata kontroller: parallellism och parallellism per KPU. Tillsammans bestämmer dessa parametrar nivån på parallell bearbetning inom applikationen och de övergripande tillgängliga beräknings-, minnes- och lagringsresurserna.
Den rekommenderade testmetoden är att ändra parallellitet eller parallellitet per KPU separat, samtidigt som man experimenterar för att hitta rätt storlek. I allmänhet, ändra endast parallellitet per KPU för att öka antalet parallella I/O-bundna operationer, utan att öka de totala resurserna. För alla andra fall, ändra bara parallellitet – KPU kommer att ändras i följd – för att hitta rätt storlek för din arbetsbelastning.
Du kan också ställa in parallellitet på operatörsnivå för att begränsa källor, sänkor eller någon annan operatör som kan behöva begränsas och oberoende av skalningsmekanismer. Du kan använda detta för en Apache Flink-applikation som läser från ett Apache Kafka-ämne som har 10 partitioner. Med setParallelism() metod, kan du begränsa KafkaSource till 10, men skala Managed Service för Apache Flink-applikationen till en parallellitet högre än 10 utan att skapa lediga uppgifter för Kafka-källan. Det rekommenderas för andra databehandlingsfall att inte statiskt ställa in operatörsparallelliteten till ett statiskt värde, utan snarare en funktion av applikationsparallellen så att den skalas när den övergripande applikationen skalas.
Skalning och automatisk skalning
I Managed Service för Apache Flink är modifiering av parallellitet eller parallellitet per KPU en uppdatering av applikationskonfigurationen. Det gör att applikationen automatiskt tar en ögonblicksbild (om det inte är inaktiverat), stoppa programmet och starta om det med den nya storleken och återställ tillståndet från ögonblicksbilden. Skalningsoperationer orsakar inte dataförlust eller inkonsekvenser, men det pausar databehandlingen under en kort tidsperiod medan infrastruktur läggs till eller tas bort. Detta är något du måste tänka på när du skalar om i en produktionsmiljö.
Under test- och optimeringsprocessen rekommenderar vi att du inaktiverar automatisk skalning och modifiera parallellism och parallellism per KPU för att hitta de optimala värdena. Som nämnts är manuell skalning bara en uppdatering av applikationskonfigurationen och kan köras via AWS Management Console eller API med Uppdatera applikationsåtgärd.
När du har hittat den optimala storleken, om du förväntar dig att din intagna genomströmning kommer att variera avsevärt, kan du välja att aktivera automatisk skalning.
I Managed Service for Apache Flink kan du använda flera typer av automatisk skalning:
- Out-of-the-box automatisk skalning – Du kan aktivera detta för att justera applikationens parallellitet automatiskt baserat på
containerCPUUtilizationmetrisk. Automatisk skalning är aktiverad som standard på nya applikationer. För detaljer om den automatiska skalningsalgoritmen, se Automatisk skalning. - Finkornig, metrisk baserad automatisk skalning – Det här är enkelt att genomföra. Automatiseringen kan baseras på praktiskt taget alla mätvärden, inklusive anpassade mätvärden din ansökan avslöjar.
- Schemalagd skalning – Det här kan vara användbart om du förväntar dig toppar i arbetsbelastningen vid givna tider på dygnet eller veckodagarna.
Out-of-the-box automatisk skalning och finkornig metrisk skalning utesluter varandra. För mer information om finkornig metrisk baserad automatisk skalning och schemalagd skalning, och ett helt fungerande kodexempel, se Aktivera mätvärdesbaserad och schemalagd skalning för Amazon Managed Service för Apache Flink.
Kodoptimeringar
Ett annat sätt att närma sig kostnadsbesparingar för din Managed Service för Apache Flink-applikationer är genom kodoptimering. Ooptimerad kod kommer att kräva fler maskiner för att utföra samma beräkningar. Att optimera koden kan möjliggöra lägre total resursutnyttjande, vilket i sin tur kan möjliggöra nedskalning och kostnadsbesparingar därefter.
Det första steget för att förstå din kodprestanda är genom det inbyggda verktyget i Apache Flink som kallas Flamgrafer.
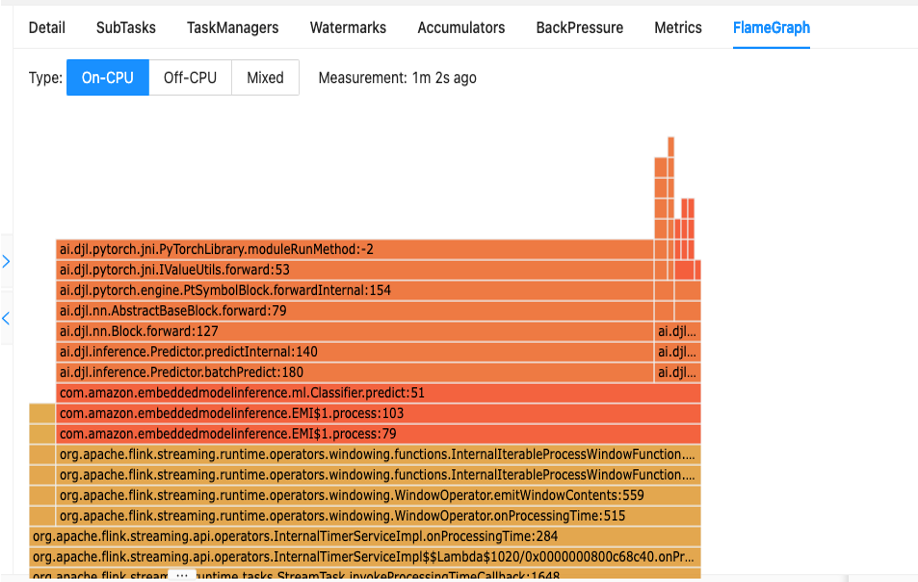
Flame Graphs, som är tillgängliga via Apache Flink-instrumentpanelen, ger dig en visuell representation av din stackspårning. Varje gång en metod anropas blir stapeln som representerar det metodanropet i stackspåret större proportionell mot det totala antalet sampel. Detta innebär att om du har en ineffektiv kodbit med en mycket lång stapel i flamgrafen, kan detta vara anledning att undersöka hur man kan göra denna kod mer effektiv. Dessutom kan du använda Amazon CodeGuru Profiler till övervaka och optimera dina Apache Flink-applikationer som körs på Managed Service för Apache Flink.
När du designar dina applikationer rekommenderas det att använda den högsta nivån API som krävs för en viss operation vid en given tidpunkt. Apache Flink erbjuder fyra nivåer av API-stöd: Flink SQL, Table API, Datastream API och ProcessFunction API:er, med ökande nivåer av komplexitet och ansvar. Om din applikation helt kan skrivas i Flink SQL eller Table API, kan användningen av detta hjälpa till att dra fördel av Apache Flink-ramverket snarare än att hantera tillstånd och beräkningar manuellt.
Data skev
På Apache Flink-instrumentpanelen kan du samla annan användbar information om din Managed Service för Apache Flink-jobb.
På instrumentpanelen kan du inspektera enskilda uppgifter i din jobbansökningsgraf. Varje blå ruta representerar en uppgift, och varje uppgift är sammansatt av deluppgifter, eller distribuerade arbetsenheter för den uppgiften. Du kan identifiera dataskevhet mellan deluppgifter på detta sätt.
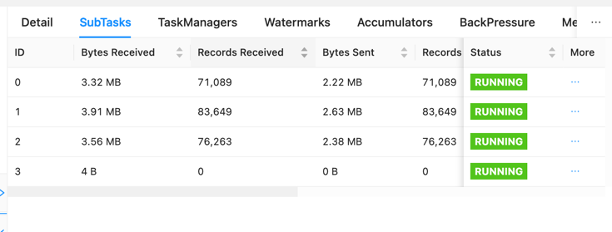
Dataskev är en indikator på att mer data skickas till en deluppgift än en annan, och att en deluppgift som tar emot mer data gör mer arbete än den andra. Om du har sådana symtom på skev data kan du arbeta för att eliminera det genom att identifiera källan. Till exempel, en GroupBy or KeyedStream kan ha en skevhet i nyckeln. Detta skulle innebära att data inte sprids jämnt mellan nycklar, vilket resulterar i en ojämn fördelning av arbetet över Apache Flink-beräkningsinstanser. Föreställ dig ett scenario där du grupperar dig efter userId, men din applikation tar emot data från en användare betydligt mer än resten. Detta kan resultera i skev data. För att eliminera detta kan du välja en annan grupperingsnyckel för att fördela data jämnt över deluppgifter. Tänk på att detta kommer att kräva kodändring för att välja en annan nyckel.
När dataskevningen är eliminerad kan du återgå till containerCPUUtilization och containerMemoryUtilization mätvärden för att minska antalet KPU:er.
Andra områden för kodoptimering inkluderar att se till att du får åtkomst till externa system via Async I/O API eller via en dataström join, eftersom en synkron fråga ut till ett datalager kan skapa nedgångar och problem i checkpointing. Se dessutom till Felsökning Prestanda för problem som du kan uppleva med långsamma kontrollpunkter eller loggning, vilket kan orsaka mottryck i applikationen.
Hur man avgör om Apache Flink är rätt teknik
Om din applikation inte använder någon av de kraftfulla funktionerna bakom Apache Flink-ramverket och Managed Service för Apache Flink, kan du potentiellt spara kostnader genom att använda något enklare.
Apache Flinks slagord är "Stateful Computations over Data Streams." Stateful betyder i detta sammanhang att du använder Apache Flink-tillståndskonstruktionen. State, i Apache Flink, låter dig komma ihåg meddelanden du har sett tidigare under längre perioder, vilket gör saker som strömmande anslutningar, deduplicering, exakt-engångsbehandling, fönster och sen datahantering möjliga. Det gör det genom att använda en minnesbutik. På Managed Service för Apache Flink använder den RocksDB att behålla sitt tillstånd.
Om din ansökan inte omfattar statlig verksamhet kan du överväga alternativ som t.ex AWS Lambda, containeriserade applikationer eller en Amazon Elastic Compute Cloud (Amazon EC2) instans som kör din applikation. Komplexiteten hos Apache Flink kanske inte är nödvändig i sådana fall. Statliga beräkningar, inklusive cachad data eller anrikningsprocedurer som kräver oberoende strömpositionsminne, kan garantera Apache Flinks tillståndskapacitet. Om det finns en potential för din applikation att bli tillståndsgivande i framtiden, oavsett om det är genom långvarig datalagring eller andra tillståndskrav, kan det vara enklare att fortsätta använda Apache Flink. Organisationer som betonar Apache Flink för strömbehandlingsmöjligheter kanske föredrar att hålla fast vid Apache Flink för tillståndsfria och tillståndslösa applikationer så att alla deras applikationer behandlar data på samma sätt. Du bör också ta hänsyn till dess orkestreringsfunktioner som exakt engångsbehandling, fan-out-funktioner och distribuerad beräkning innan du går över från Apache Flink till alternativ.
En annan faktor är dina latenskrav. Eftersom Apache Flink utmärker sig vid databearbetning i realtid, är det inte meningsfullt att använda den för en applikation med ett 6-timmars eller 1-dagars latenskrav. Kostnadsbesparingarna genom att byta till en temporär batchprocess ur Amazon enkel lagringstjänst (Amazon S3), till exempel, skulle vara betydande.
Slutsats
I det här inlägget täckte vi några aspekter att tänka på när du försöker spara kostnadsåtgärder för Managed Service för Apache Flink. Vi diskuterade hur du identifierar dina totala utgifter för den hanterade tjänsten, några användbara mätvärden att övervaka när du skalar ner dina KPU:er, hur du optimerar din kod för nedskalning och hur du avgör om Apache Flink är rätt för ditt användningsfall.
Genom att implementera dessa kostnadsbesparande strategier ökar inte bara din kostnadseffektivitet utan ger också en strömlinjeformad och väloptimerad Apache Flink-distribution. Genom att vara uppmärksam på dina totala utgifter, använda nyckeltal och fatta välgrundade beslut om att minska resurserna kan du uppnå en kostnadseffektiv operation utan att kompromissa med prestanda. När du navigerar i Apache Flink-landskapet blir det avgörande att ständigt utvärdera om det överensstämmer med ditt specifika användningsfall, så att du kan få en skräddarsydd och effektiv lösning för dina databehandlingsbehov.
Om någon av rekommendationerna som diskuteras i det här inlägget överensstämmer med dina arbetsbelastningar rekommenderar vi att du testar dem. Med de angivna måtten och tipsen om hur du förstår dina arbetsbelastningar bättre, bör du nu ha det du behöver för att effektivt optimera dina Apache Flink-arbetsbelastningar på Managed Service för Apache Flink. Följande är några användbara resurser som du kan använda för att komplettera det här inlägget:
Om författarna
 Jeremy Ber har arbetat inom telemetridatautrymmet de senaste 10 åren som mjukvaruingenjör, maskininlärningsingenjör och nu senast som dataingenjör. På AWS är han en Streaming Specialist Solutions Architect som stödjer både Amazon Managed Streaming för Apache Kafka (Amazon MSK) och Amazon Managed Service för Apache Flink.
Jeremy Ber har arbetat inom telemetridatautrymmet de senaste 10 åren som mjukvaruingenjör, maskininlärningsingenjör och nu senast som dataingenjör. På AWS är han en Streaming Specialist Solutions Architect som stödjer både Amazon Managed Streaming för Apache Kafka (Amazon MSK) och Amazon Managed Service för Apache Flink.
 Lorenzo Nicora arbetar som Senior Streaming Solution Architect på AWS och hjälper kunder i hela EMEA. Han har byggt molnbaserade, dataintensiva system i över 25 år och arbetat i finansbranschen både genom konsultföretag och för FinTech-produktföretag. Han har utnyttjat öppen källkodsteknik i stor utsträckning och bidragit till flera projekt, inklusive Apache Flink.
Lorenzo Nicora arbetar som Senior Streaming Solution Architect på AWS och hjälper kunder i hela EMEA. Han har byggt molnbaserade, dataintensiva system i över 25 år och arbetat i finansbranschen både genom konsultföretag och för FinTech-produktföretag. Han har utnyttjat öppen källkodsteknik i stor utsträckning och bidragit till flera projekt, inklusive Apache Flink.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoData.Network Vertical Generative Ai. Styrka dig själv. Tillgång här.
- PlatoAiStream. Web3 Intelligence. Kunskap förstärkt. Tillgång här.
- Platoesg. Kol, CleanTech, Energi, Miljö, Sol, Avfallshantering. Tillgång här.
- PlatoHealth. Biotech och kliniska prövningar Intelligence. Tillgång här.
- Källa: https://aws.amazon.com/blogs/big-data/real-time-cost-savings-for-amazon-managed-service-for-apache-flink/

