Det här inlägget är en fortsättning på en serie i två delar. I den första delen, grävde vi i Apache Flashs interna mekanismer för kontrollpunkter, databuffring under flygning och hantering av mottryck. Vi täckte dessa begrepp för att förstå hur buffertavblåsning och ojusterade kontrollpunkter tillåter oss att förbättra prestandan för specifika förhållanden i Apache Flink-applikationer.
In del 1, introducerade och undersökte vi hur man använder buffertavblåsning för att förbättra databearbetning under flygning. I det här inlägget fokuserar vi på oriktade checkpoints. Den här funktionen har varit tillgänglig sedan Apache Flink 1.11 och har fått många förbättringar sedan dess. Ojusterade kontrollpunkter hjälper, under specifika förhållanden, att minska kontrolltiden för applikationer som lider av tillfälligt mottryck, och kan nu aktiveras in Amazon Managed Service för Apache Flink applikationer som kör Apache Flink 1.15.2 till en biljettsupport.
Även om den här funktionen kan förbättra prestandan för dina kontrollpunkter, kan du behöva en djupare analys och omdesign av din applikation om din applikation ständigt misslyckas på grund av att checkpoints tar slut, eller lider av konstant mottryck.
Justerade kontrollpunkter
Som diskuteras i del 1, Apache Flink checkpointing tillåter applikationer att registrera tillstånd i händelse av fel. Vi har redan diskuterat hur kontrollpunkter, när de utlöses av jobbansvarig, signalerar alla källoperatörer att ögonblicksbilda deras tillstånd, som sedan sänds som en speciell post som kallas en checkpoint barriär. Denna process uppnår exakt engångskonsistens för tillstånd i en distribuerad streamingapplikation genom anpassningen av dessa barriärer.
Låt oss gå igenom processen med justerade kontrollpunkter i en standard Apache Flink-applikation. Kom ihåg att Apache Flink fördelar arbetsbelastningen horisontellt: var och en Operatören (en nod i det logiska flödet av din applikation, inklusive källor och sänkor) är uppdelad i flera deluppgifter baserat på dess parallellitet.
Barriärinriktning
Justeringen av kontrollpunktsbarriärer är avgörande för att uppnå exakt engångskonsistens i Apache Flink-applikationer under checkpointkörningar. För att sammanfatta, när en jobbansvarig utlöser en kontrollpunkt, får alla deluppgifter för källoperatörer en signal för att initiera kontrollpunktsprocessen. Varje deluppgift tar självständigt ögonblicksbilder av sitt tillstånd till statens backend och sänder en speciell post känd som en kontrollpunktsbarriär till alla utgående strömmar.
När en applikation arbetar med en parallellitet högre än 1, flera instanser av varje uppgift – kallad deluppgifter— möjliggör parallell konsumtion och bearbetning av meddelanden. En deluppgift kan ta emot distinkta partitioner av samma ström från olika uppströmsunderuppgifter, till exempel efter en ompartitionering av en ström med keyBy or rebalance operationer. För att bibehålla exakt engångskonsistens måste alla deluppgifter vänta på ankomsten av alla checkpointbarriärer innan de tar en ögonblicksbild av staten. Följande diagram illustrerar flödet av checkpointbarriärer.
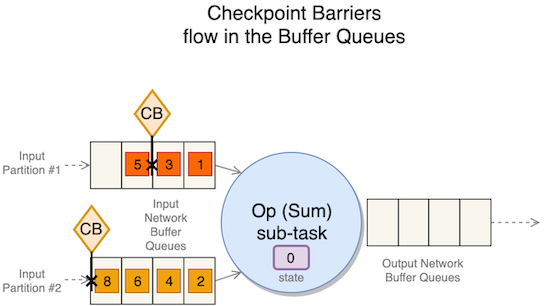
Denna fas kallas kontrollpunktens inriktning. Under justeringen slutar underuppgiften att bearbeta poster från de partitioner som den redan har tagit emot barriärer från, som visas i följande figur.
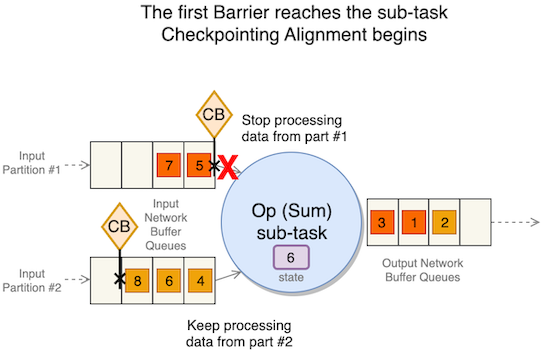
Den fortsätter dock att bearbeta partitioner som ligger bakom barriären.
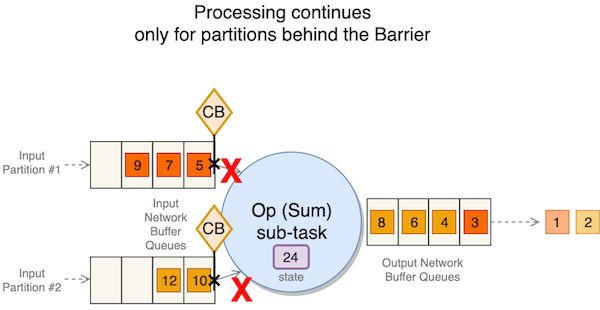
När barriärer från alla uppströmspartitioner har anlänt, tar deluppgiften en ögonblicksbild av dess tillstånd.

Sedan sänder den barriären nedströms.

Tiden som en deluppgift tillbringar i väntan på att alla barriärer ska anlända mäts med mätvärdet för kontrollpunkten Alignment Duration, som kan observeras i Apache Flink-gränssnittet.
Om applikationen upplever mottryck, kan en ökning av detta mått leda till längre kontrollpunkter och till och med kontrollpunktsfel på grund av timeout. Det är här ojusterade kontrollpunkter blir ett gångbart alternativ för att potentiellt förbättra kontrollpunktsprestanda.
Ojusterade kontrollpunkter
Ojusterade checkpoints adresserar situationer där mottrycket inte bara är en tillfällig topp, utan resulterar i timeouts för justerade checkpoints, på grund av barriärköer i strömmen. Som diskuterats i del 1 kan checkpoint-barriärer inte passera vanliga register. Därför kan betydande mottryck bromsa rörelsen av barriärer över applikationen, vilket potentiellt kan orsaka tidsgränser för kontrollpunkter.
Syftet med oriktade kontrollpunkter är att möjliggöra omkörning av barriärer, vilket gör att barriärer kan flyttas snabbt från källa till sjunka även när dataflödet är långsammare än förväntat.
Med utgångspunkt i vad vi såg i del 1 om checkpoints och vad inriktade checkpoints är, låt oss utforska hur ojusterade checkpoints modifierar kontrollmekanismen.
Vid emission injiceras varje källas kontrollpunktsbarriär i strömmen som flödar över deluppgifter. Den går från källutgångsnätverksbuffertkön till ingångsnätverksbuffertkön för den efterföljande operatören.
Vid ankomsten av den första barriären i inmatningsnätverkets buffertkö väntar operatören initialt på barriärinriktning. Om den angivna tidsgränsen för inriktning löper ut eftersom inte alla barriärer har nått slutet av inmatningsnätverkets buffertkö, växlar operatören till ojusterat kontrollpunktsläge.
Justeringstidsgränsen kan ställas in programmatiskt av env.getCheckpointConfig().setAlignedCheckpointTimeout(Duration.ofSeconds(30)), men att ändra standarden rekommenderas inte i Apache Flink 1.15.
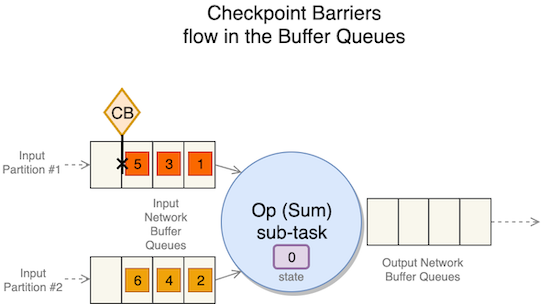
Operatören väntar tills alla kontrollpunktsbarriärer finns i ingångsnätverkets buffertkö innan kontrollpunkten utlöses. Till skillnad från justerade checkpoints behöver operatören inte vänta på att alla barriärer når köns slut, vilket gör att operatören kan ha data under flygning från bufferten som inte har bearbetats innan checkpoint initieras.

Efter att alla barriärer har anlänt till ingångsnätverksbuffertkön, flyttar operatören fram barriären till slutet av utmatningsnätverksbuffertkön. Detta förbättrar kontrollpunktshastigheten eftersom barriären smidigt kan passera applikationen från källa till sjunka, oberoende av applikationens slut-till-ände latens.

Efter att ha vidarebefordrat barriären till utmatningsnätverkets buffertkö, initierar operatören ögonblicksbilden av flygdata mellan barriärerna i ingångs- och utmatningsnätverksbuffertköerna, tillsammans med ögonblicksbilden av tillståndet.
Även om bearbetningen tillfälligt pausas under denna process, sker den faktiska skrivningen till fjärrlagringen för beständigt tillstånd asynkront, vilket förhindrar potentiella flaskhalsar.

Den lokala ögonblicksbilden, som omfattar meddelanden under flygning och tillstånd, sparas asynkront i det fjärranslutna permanenta tillståndsarkivet, medan barriären fortsätter sin resa genom applikationen.

När ska man använda oriktade kontrollpunkter
Kom ihåg att barriärinriktning endast sker mellan partitioner som kommer från olika deluppgifter för samma operatör. Därför, om en operatör upplever tillfälligt mottryck, kan det vara fördelaktigt att aktivera oriktade kontrollpunkter. På så sätt behöver applikationen inte vänta på att alla barriärer når operatören innan den gör en ögonblicksbild av tillståndet eller flyttar barriären framåt.
Tillfälligt mottryck kan uppstå av följande:
- En ökning av dataintag
- Återfyllning eller komma ikapp med historiska data
- Ökad meddelandebehandlingstid på grund av försenade externa system
Ett annat scenario där oriktade kontrollpunkter visar sig vara fördelaktiga är när man arbetar med sänkor med exakt en gång. Genom att använda den tvåfasiga commit-sänkfunktionen för sänkningar med exakt en gång, kan ojusterade checkpoints påskynda checkpointkörningar, och därigenom minska fördröjningen från slut till ände.
När man inte ska använda oriktade kontrollpunkter
Ojusterade kontrollpunkter kommer inte att minska tiden som krävs räddningspunkter (kallad snapshots i Amazon Managed Service för Apache Flink-implementering) eftersom räddningspunkter uteslutande använder justerade kontrollpunkter. Dessutom, eftersom Apache Flink inte tillåter samtidiga ojusterade kontrollpunkter, kommer inte räddningspunkter att inträffa samtidigt med ojusterade kontrollpunkter, vilket potentiellt förlänger räddningspunktens varaktighet.
Ojusterade kontrollpunkter kommer inte att lösa några underliggande problem i din applikationsdesign. Om din applikation lider av ihållande mottryck eller konstanta tidsgränser för kontrollpunkter, kan detta indikera skevhet eller underprovisionering, vilket kan kräva att applikationen förbättras och justeras.
Använder ojusterade kontrollpunkter med buffertavblåsning
Ett alternativ för att minska riskerna förknippade med en ökad tillståndsstorlek är att kombinera oriktade checkpoints med buffertavblåsning. Detta tillvägagångssätt resulterar i att det finns mindre data under flygningen att ögonblicksbilda och lagra i tillståndet, tillsammans med mindre data som ska användas för återställning i händelse av fel. Denna synergi underlättar förbättrad prestanda och effektiva checkpointkörningar, vilket leder till mindre checkpointstorlekar och snabbare återställningstider. När du testar användningen av ojusterade kontrollpunkter rekommenderar vi att du gör det med buffertavblåsning för att förhindra att statens storlek ökar.
Begränsningar
Ojusterade kontrollpunkter är föremål för följande begränsningar:
- De ger ingen fördel för operatörer med en parallellitet på 1.
- De förbättrar bara prestandan för operatörer där barriärinriktning skulle ha skett. Denna justering sker endast om poster kommer från olika deluppgifter från samma operatör, till exempel genom ompartitionering eller
keyByoperationer. - Operatörer som får input från flera källor eller deltar i anslutningar kanske inte upplever förbättringar, eftersom operatören skulle ta emot data från olika operatörer i dessa fall.
- Även om kontrollpunktsbarriärer kan överträffa poster i nätverkets buffertkö, kommer detta inte att inträffa om underuppgiften för närvarande bearbetar ett meddelande. Om bearbetningen av ett meddelande tar för lång tid (t.ex. en platt kartoperation som sänder ut många poster för varje indatapost), kommer barriärhanteringen att försenas.
- Som vi har sett använder räddningspunkter alltid justerade kontrollpunkter. Om räddningspunkterna för dina applikationer är långsamma på grund av barriärinriktning, kommer ojusterade kontrollpunkter inte att hjälpa.
- Ytterligare begränsningar påverkar vattenstämplar, meddelandeordning och sändningstillstånd vid återställning. För mer information, se Begränsningar.
Överväganden
Överväganden för att implementera ojusterade kontrollpunkter:
- Ojusterade kontrollpunkter introducerar ytterligare I/O till kontrollpunktslagring
- Kontrollpunkter omfattar inte bara operatörstillstånd utan även data under flygning i nätverksbuffertköer, vilket leder till ökad tillståndsstorlek
Rekommendationer
Vi erbjuder följande rekommendationer:
- Överväg att endast aktivera ojusterade kontrollpunkter om båda följande villkor är uppfyllda:
- Kontrollpunkter håller på att ta slut.
- Den genomsnittliga asynkroniseringstiden för kontrollpunkten för en operatör är mer än 50 % av den totala kontrollpunktslängden för operatören (summan av synkroniseringsvaraktighet + asynkroniseringsvaraktighet).
- Överväg att aktivera buffertavblåsning först och utvärdera om det löser problemet med tidsgräns för kontrollpunkter.
- Om buffertavblåsning inte hjälper, överväg att aktivera ojusterade kontrollpunkter tillsammans med buffertavblåsning. Buffertavblåsning minskar nackdelarna med oriktade kontrollpunkter, vilket minskar mängden data under flygning.
- Om ojusterade kontrollpunkter och buffertavblåsning tillsammans inte förbättrar kontrollpunktens inriktningslängd, överväg att testa enbart ojusterade kontrollpunkter.
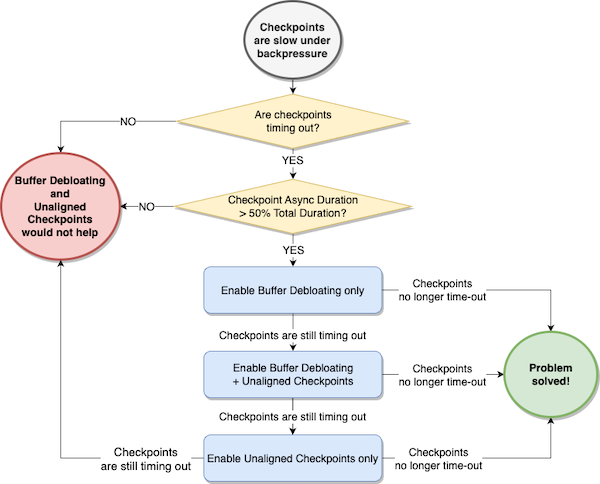
Slutligen, men viktigast av allt, testa alltid ojusterade kontrollpunkter i en icke-produktionsmiljö först, kör några jämförande prestandatester med en realistisk arbetsbelastning och verifiera att ojusterade kontrollpunkter faktiskt minskar kontrollpunktens varaktighet.
Slutsats
Denna tvådelade serie utforskade avancerade strategier för att optimera kontrollpunkter inom din Amazon Managed Service för Apache Flink-applikationer. Genom att dra nytta av potentialen med buffertavblåsning och icke-justerade kontrollpunkter kan du låsa upp betydande prestandaförbättringar och effektivisera kontrollpunktsprocesser. Det är dock viktigt att förstå när dessa tekniker kommer att ge förbättringar och när de inte kommer att göra det. Om du tror att din applikation kan dra nytta av förbättring av kontrollpunktens prestanda kan du det aktivera dessa funktioner i din Amazon Managed Service For Apache Flink version 1.15 applikationer. Vi rekommenderar att först aktivera buffertavblåsning och testa applikationen. Om du fortfarande inte ser det förväntade resultatet, aktivera buffertavblåsning med ojusterade kontrollpunkter. På så sätt kan du omedelbart minska tillståndsstorleken och den extra I/O till tillståndsbackends. Slutligen kan du prova att använda oriktade kontrollpunkter i sig själv, med tanke på de överväganden vi har nämnt.
Med en djupare förståelse för dessa tekniker och deras tillämpbarhet är du bättre rustad att maximera effektiviteten hos kontrollpunkter och mildra effekten av mottryck i din Apache Flink-applikation.
Om författarna
 Lorenzo Nicora arbetar som Senior Streaming Solution Architect och hjälper kunder i hela EMEA. Han har byggt molnbaserade, dataintensiva system i över 25 år och arbetat i finansbranschen både genom konsultföretag och för FinTech-produktföretag. Han har utnyttjat öppen källkodsteknik i stor utsträckning och bidragit till flera projekt, inklusive Apache Flink.
Lorenzo Nicora arbetar som Senior Streaming Solution Architect och hjälper kunder i hela EMEA. Han har byggt molnbaserade, dataintensiva system i över 25 år och arbetat i finansbranschen både genom konsultföretag och för FinTech-produktföretag. Han har utnyttjat öppen källkodsteknik i stor utsträckning och bidragit till flera projekt, inklusive Apache Flink.
 Francisco Morillo är en Streaming Solutions Architect på AWS. Francisco arbetar med AWS-kunder och hjälper dem att designa realtidsanalysarkitekturer med hjälp av AWS-tjänster, stöder Amazon Managed Streaming för Apache Kafka (Amazon MSK) och AWS:s hanterade erbjudande för Apache Flink.
Francisco Morillo är en Streaming Solutions Architect på AWS. Francisco arbetar med AWS-kunder och hjälper dem att designa realtidsanalysarkitekturer med hjälp av AWS-tjänster, stöder Amazon Managed Streaming för Apache Kafka (Amazon MSK) och AWS:s hanterade erbjudande för Apache Flink.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoData.Network Vertical Generative Ai. Styrka dig själv. Tillgång här.
- PlatoAiStream. Web3 Intelligence. Kunskap förstärkt. Tillgång här.
- Platoesg. Fordon / elbilar, Kol, CleanTech, Energi, Miljö, Sol, Avfallshantering. Tillgång här.
- PlatoHealth. Biotech och kliniska prövningar Intelligence. Tillgång här.
- ChartPrime. Höj ditt handelsspel med ChartPrime. Tillgång här.
- BlockOffsets. Modernisera miljökompensation ägande. Tillgång här.
- Källa: https://aws.amazon.com/blogs/big-data/optimize-checkpointing-in-your-amazon-managed-service-for-apache-flink-applications-with-buffer-debloating-and-unaligned-checkpoints-part-2/

