
Bruce Warrington via Unsplash
Anledningen till att maskininlärningsmodeller i allmänhet blir smartare beror på deras beroende av att använda märkt data för att hjälpa dem att skilja mellan två liknande objekt.
Men utan dessa märkta datamängder kommer du att stöta på stora hinder när du skapar den mest effektiva och pålitliga maskininlärningsmodellen. Märkta datamängder under utbildningsfasen av en modell är viktiga.
Deep learning har använts i stor utsträckning för att lösa uppgifter som datorseende med hjälp av övervakat lärande. Men som med många saker i livet kommer det med begränsningar. Övervakad klassificering kräver en hög kvantitet och kvalitet av märkt träningsdata för att kunna producera en robust modell. Detta innebär att klassificeringsmodellen inte kan hantera osedda klasser.
Och vi vet alla hur mycket beräkningskraft, omträning, tid och pengar som krävs för att träna en modell för djupinlärning.
Men kan en modell ändå kunna skilja mellan två objekt utan att ha använt träningsdata? Ja, det kallas nollskottslärning. Zero-shot learning är en modells förmåga att kunna utföra en uppgift utan att ha fått eller använt några träningsexempel.
Människor är naturligtvis kapabla till noll-shot-inlärning utan att behöva lägga ner mycket ansträngning på. Våra hjärnor lagrar redan ordböcker och tillåter oss att skilja objekt genom att titta på deras fysiska egenskaper på grund av vår nuvarande kunskapsbas. Vi kan använda denna kunskapsbas för att se likheter och skillnader mellan objekt och hitta kopplingen mellan dem.
Låt oss till exempel säga att vi försöker bygga en klassificeringsmodell på djurarter. Enligt OurWorldInData, det fanns 2.13 miljoner arter beräknade år 2021. Om vi vill skapa den mest effektiva klassificeringsmodellen för djurarter skulle vi därför behöva 2.13 miljoner olika klasser. Det behövs också mycket data. Data med hög kvantitet och kvalitet är svåra att komma över.
Så hur löser zero-shot learning detta problem?
Eftersom noll-shot-inlärning inte kräver att modellen har lärt sig träningsdata och hur man klassificerar klasser, gör det att vi kan lita mindre på modellens behov av märkt data.
Följande är vad din data kommer att behöva bestå av för att fortsätta med noll-shot-inlärning.
sett klasser
Detta består av de dataklasser som tidigare har använts för att träna en modell.
Osynliga klasser
Detta består av de dataklasser som INTE har använts för att träna en modell och den nya nollskottsmodellen kommer att generaliseras.
Hjälpinformation
Eftersom data i de osynliga klasserna inte är märkta, kommer noll-shot-inlärning att kräva extra information för att lära sig och hitta korrelationer, länkar och egenskaper. Detta kan vara i form av ordinbäddningar, beskrivningar och semantisk information.
Zero-shot inlärningsmetoder
Zero-shot learning används vanligtvis i:
- Klassificerare-baserade metoder
- Instansbaserade metoder
praktik
Zero-shot learning används för att bygga modeller för klasser som inte tränar med hjälp av märkta data, därför kräver det dessa två steg:
1. Träning
Utbildningsstadiet är processen för inlärningsmetoden som försöker fånga så mycket kunskap som möjligt om datans kvaliteter. Vi kan se detta som inlärningsfasen.
2. Slutledning
Under slutledningsstadiet tillämpas och utnyttjas all inlärd kunskap från utbildningsstadiet för att klassificera exempel i en ny uppsättning klasser. Vi kan se detta som fasen för att göra förutsägelser.
Hur fungerar det?
Kunskapen från de sedda klasserna kommer att överföras till de osynliga klasserna i ett högdimensionellt vektorrum; detta kallas semantiskt utrymme. Till exempel, i bildklassificering kommer det semantiska utrymmet tillsammans med bilden att genomgå två steg:
1. Gemensamt inbäddningsutrymme
Det är hit de semantiska vektorerna och vektorerna för den visuella egenskapen projiceras till.
2. Största likheten
Det är här funktionerna matchas mot de i en osynlig klass.
För att hjälpa dig förstå processen med de två stegen (träning och slutledning), låt oss tillämpa dem i användningen av bildklassificering.
Utbildning

Jari Hytönen via Unsplash
Om du som människa skulle läsa texten till höger i bilden ovan skulle du genast anta att det finns 4 kattungar i en brun korg. Men låt oss säga att du inte har någon aning om vad en "kattunge" är. Du kommer att anta att det finns en brun korg med 4 saker inuti, som kallas "kattungar". När du väl stöter på fler bilder som innehåller något som ser ut som en "kattunge", kommer du att kunna skilja en "kattunge" från andra djur.
Detta är vad som händer när du använder Kontrastiv språk-bild förträning (CLIP) av OpenAI för zero-shot-inlärning i bildklassificering. Det är känt som hjälpinformation.
Du kanske tänker, "det är bara märkt data". Jag förstår varför du skulle tro det, men det är de inte. Hjälpinformation är inte etiketter för data, de är en form av övervakning för att hjälpa modellen att lära sig under utbildningsstadiet.
När en noll-shot-inlärningsmodell ser en tillräcklig mängd bild-text-parningar, kommer den att kunna särskilja och förstå fraser och hur de korrelerar med vissa mönster i bilderna. Genom att använda CLIP-tekniken 'kontrastiv inlärning' har nollskotts-inlärningsmodellen kunnat ackumulera en bra kunskapsbas för att kunna göra förutsägelser om klassificeringsuppgifter.
Detta är en sammanfattning av CLIP-metoden där de tränar en bildkodare och en textkodare tillsammans för att förutsäga de korrekta parningarna av en grupp av (bild, text) träningsexempel. Se bilden nedan:
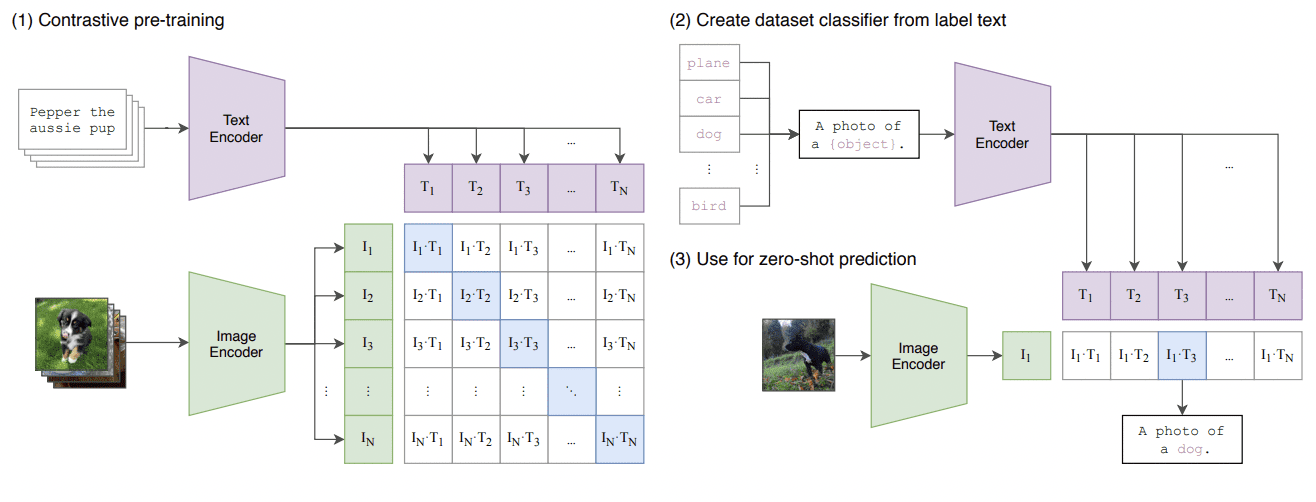
Lär dig överförbara visuella modeller från övervakning av naturligt språk
Slutledning
När modellen har gått igenom utbildningsstadiet har den en bra kunskapsbas om bild-text-parning och kan nu användas för att göra förutsägelser. Men innan vi kan börja göra förutsägelser, måste vi ställa in klassificeringsuppgiften genom att skapa en lista över alla möjliga etiketter som modellen kan mata ut.
Om vi till exempel håller oss till uppgiften om bildklassificering av djurarter, kommer vi att behöva en lista över alla djurarter. Var och en av dessa etiketter kommer att kodas, T? till T? med hjälp av den förtränade textkodaren som inträffade under träningsstadiet.
När etiketterna har kodats kan vi mata in bilder genom den förtränade bildkodaren. Vi kommer att använda den avståndsmetriska cosinuslikheten för att beräkna likheterna mellan bildkodningen och varje textetikettkodning.
Klassificeringen av bilden görs utifrån etiketten med störst likhet med bilden. Och det är så noll-shot-inlärning uppnås, särskilt i bildklassificering.
Brist på data
Som nämnts tidigare är data med hög kvantitet och kvalitet svåra att få tag på. Till skillnad från människor som redan har noll-shot-inlärningsförmågan, kräver maskiner ingångsmärkta data för att lära sig och sedan kunna anpassa sig till varianser som kan uppstå naturligt.
Om vi tittar på djurartexemplet så var det så många. Och eftersom antalet kategorier fortsätter att växa inom olika domäner kommer det att krävas mycket arbete för att hålla jämna steg med att samla in kommenterad data.
På grund av detta har zero-shot learning blivit mer värdefullt för oss. Fler och fler forskare är intresserade av automatisk attributigenkänning för att kompensera för bristen på tillgänglig data.
Datamärkning
En annan fördel med zero-shot-inlärning är dess datamärkningsegenskaper. Datamärkning kan vara arbetskrävande och mycket tråkigt, och på grund av detta kan det leda till fel under processen. Datamärkning kräver experter, till exempel medicinsk personal som arbetar med en biomedicinsk datauppsättning, vilket är mycket dyrt och tidskrävande.
Zero-shot learning blir mer populärt på grund av ovanstående begränsningar av data. Det finns några artiklar jag skulle rekommendera dig att läsa om du är intresserad av dess förmågor:
Nisha Arya är datavetare och frilansande teknisk skribent. Hon är särskilt intresserad av att ge Data Science karriärråd eller handledning och teoribaserad kunskap kring Data Science. Hon vill också utforska de olika sätten artificiell intelligens är/kan gynna människans livslängd. En angelägen lärande, som vill bredda sina tekniska kunskaper och skrivförmåga, samtidigt som hon hjälper andra att vägleda.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- Platoblockchain. Web3 Metaverse Intelligence. Kunskap förstärkt. Tillgång här.
- Källa: https://www.kdnuggets.com/2022/12/zeroshot-learning-explained.html?utm_source=rss&utm_medium=rss&utm_campaign=zero-shot-learning-explained

