Detta är gemensamt inlägg skrivet av Science Applications International Corporation och AWS. Leidos är en FORTUNE 500-ledare inom vetenskap och teknik som arbetar för att ta itu med några av världens tuffaste utmaningar inom försvars-, underrättelse-, hemvärns-, civil- och hälsovårdsmarknaderna.
Leidos har samarbetat med AWS för att utveckla en metod för integritetsbevarande, konfidentiell maskininlärning (ML)-modellering där du bygger molnaktiverade, krypterade pipelines.
Homomorf kryptering är ett nytt tillvägagångssätt för kryptering som gör att beräkningar och analytiska funktioner kan köras på krypterad data, utan att först behöva dekryptera den, för att bevara integriteten i de fall du har en policy som säger att data aldrig ska dekrypteras. Fullständig homomorf kryptering (FHE) är den starkaste uppfattningen av denna typ av tillvägagångssätt, och den låter dig låsa upp värdet av din data där nollförtroende är nyckeln. Kärnkravet är att data måste kunna representeras med siffror genom en kodningsteknik, som kan tillämpas på numeriska, textuella och bildbaserade datamängder. Data som använder FHE är större i storlek, så testning måste göras för applikationer som behöver slutsatsen utföras i nästan realtid eller med storleksbegränsningar. Det är också viktigt att formulera alla beräkningar som linjära ekvationer.
I det här inlägget visar vi hur man aktiverar sekretessbevarande ML-förutsägelser för de mest reglerade miljöerna. Förutsägelserna (inferensen) använder krypterad data och resultaten dekrypteras endast av slutkonsumenten (klientsidan).
För att visa detta visar vi ett exempel på att anpassa en Amazon SageMaker Scikit-learn, öppen källkod, djupinlärningsbehållare för att möjliggöra för en utplacerad slutpunkt att acceptera krypterade slutledningsbegäranden på klientsidan. Även om det här exemplet visar hur du utför detta för slutledningsoperationer, kan du utöka lösningen till träning och andra ML-steg.
Endpoints distribueras med ett par klick eller rader kod med SageMaker, vilket förenklar processen för utvecklare och ML-experter att bygga och träna ML- och djupinlärningsmodeller i molnet. Modeller byggda med SageMaker kan sedan distribueras som slutpunkter i realtid, vilket är avgörande för slutledningsarbetsbelastningar där du har krav på realtid, steady state och låg latens. Applikationer och tjänster kan anropa den distribuerade slutpunkten direkt eller via en distribuerad serverlös Amazon API Gateway arkitektur. För att lära dig mer om bästa praxis för slutpunktsarkitektur i realtid, se Skapa en maskininlärningsdriven REST API med Amazon API Gateway-mappmallar och Amazon SageMaker. Följande bild visar båda versionerna av dessa mönster.
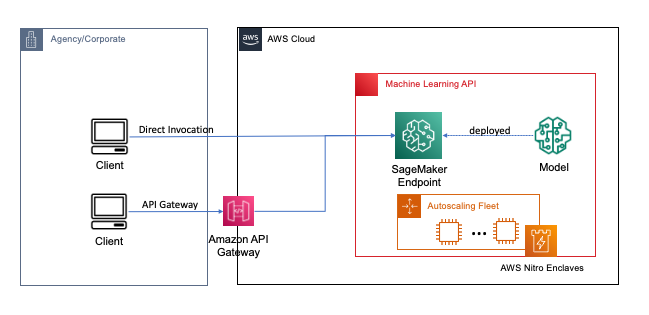
I båda dessa mönster ger kryptering under överföring konfidentialitet när data strömmar genom tjänsterna för att utföra slutledningsoperationen. När den tas emot av SageMaker-slutpunkten dekrypteras data i allmänhet för att utföra slutledningsoperationen vid körning och är oåtkomlig för extern kod och processer. För att uppnå ytterligare skyddsnivåer möjliggör FHE slutledningsoperationen att generera krypterade resultat för vilka resultaten kan dekrypteras av en pålitlig applikation eller klient.
Mer om helt homomorf kryptering
FHE gör det möjligt för system att utföra beräkningar på krypterad data. De resulterande beräkningarna, när de dekrypteras, är kontrollerbart nära de som produceras utan krypteringsprocessen. FHE kan resultera i en liten matematisk oprecision, liknande ett flyttalsfel, på grund av brus som injiceras i beräkningen. Det styrs genom att välja lämpliga FHE-krypteringsparametrar, vilket är en problemspecifik, avstämd parameter. För mer information, kolla in videon Hur skulle du förklara homomorf kryptering?
Följande diagram ger ett exempel på implementering av ett FHE-system.
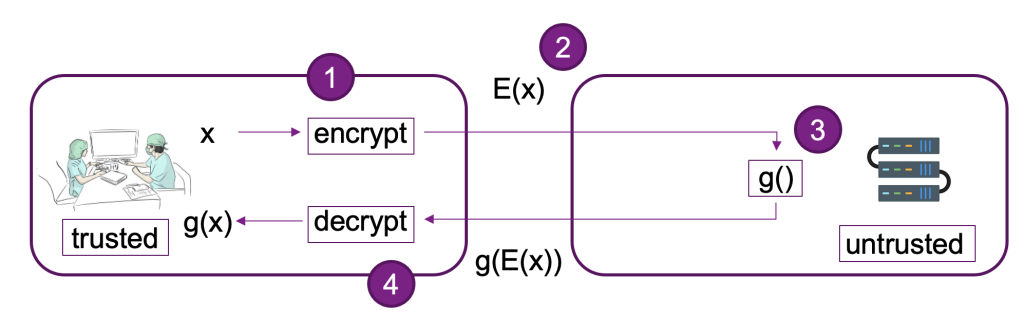
I det här systemet kan du eller din betrodda klient göra följande:
- Kryptera data med ett FHE-schema med offentlig nyckel. Det finns ett par olika acceptabla system; i det här exemplet använder vi CKKS-schemat. För att lära dig mer om FHEs offentliga nyckelkrypteringsprocess som vi valde, se CKKS förklarade.
- Skicka krypterad data på klientsidan till en leverantör eller server för bearbetning.
- Utför modellinferens på krypterad data; med FHE krävs ingen dekryptering.
- Krypterade resultat returneras till den som ringer och dekrypteras sedan för att avslöja ditt resultat med hjälp av en privat nyckel som bara är tillgänglig för dig eller dina betrodda användare inom klienten.
Vi har använt den föregående arkitekturen för att skapa ett exempel med SageMaker-slutpunkter, Pyfhel som ett FHE API-omslag som förenklar integrationen med ML-applikationer, och SEAL som vår underliggande FHE-krypteringsverktygssats.
Lösningsöversikt
Vi har byggt ut ett exempel på en skalbar FHE-pipeline i AWS med hjälp av en SKLär dig logistisk regression djupinlärningsbehållare med Iris -datauppsättning. Vi utför datautforskning och funktionsutveckling med hjälp av en SageMaker-anteckningsbok, och utför sedan modellträning med en SageMaker utbildningsjobb. Den resulterande modellen är utplacerade till en SageMaker realtidsslutpunkt för användning av klienttjänster, som visas i följande diagram.
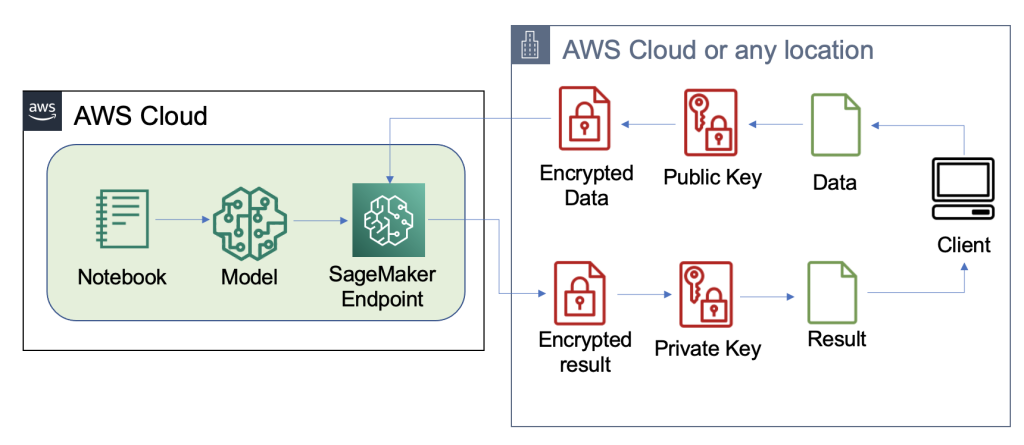
I den här arkitekturen är det bara klientapplikationen som ser okrypterad data. Data som behandlas genom modellen för slutledning förblir krypterad under hela dess livscykel, även vid körning i processorn i den isolerade AWS Nitro Enklav. I följande avsnitt går vi igenom koden för att bygga denna pipeline.
Förutsättningar
För att följa med antar vi att du har lanserat en SageMaker anteckningsbok med en AWS identitets- och åtkomsthantering (IAM) roll med AmazonSageMakerFullAccess hanterad politik.
Träna modellen
Följande diagram illustrerar arbetsflödet för modellträning.
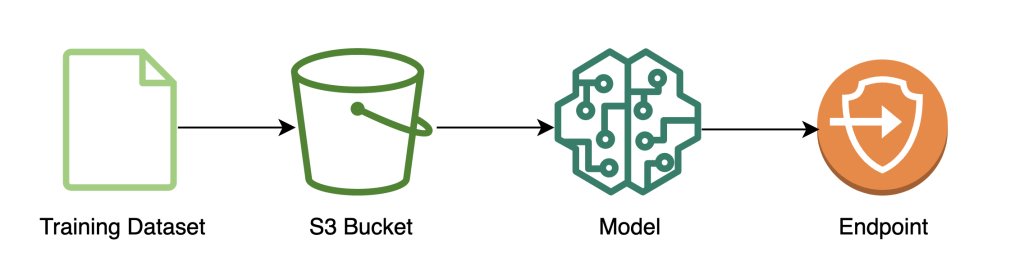
Följande kod visar hur vi först förbereder data för träning med SageMaker-anteckningsböcker genom att dra in vår träningsdatauppsättning, utföra nödvändiga rengöringsåtgärder och sedan ladda upp data till en Amazon enkel lagringstjänst (Amazon S3) hink. I det här skedet kan du också behöva göra ytterligare funktionsutveckling av din datauppsättning eller integrera med olika offlinefunktionsbutiker.
I det här exemplet använder vi skript-läge på ett inbyggt ramverk inom SageMaker (scikit lära), där vi instansierar vår standard SageMaker SKLearn-uppskattare med ett anpassat träningsskript för att hantera krypterad data under slutledning. För att se mer information om inbyggt stödda ramverk och skriptläge, se Använd Framställningar för maskininlärning, Python och R med Amazon SageMaker.
Slutligen tränar vi vår modell på datamängden och distribuerar vår tränade modell till den instanstyp vi väljer.
Vid det här laget har vi tränat en anpassad SKLearn FHE-modell och distribuerat den till en SageMaker slutpunkt i realtid som är redo att acceptera krypterad data.
Kryptera och skicka klientdata
Följande diagram illustrerar arbetsflödet för att kryptera och skicka klientdata till modellen.
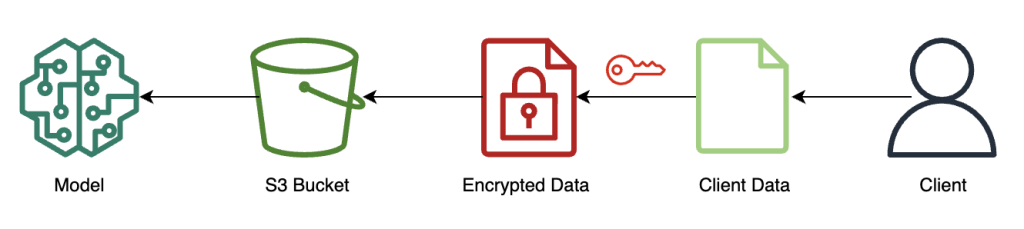
I de flesta fall innehåller nyttolasten för anropet till slutpunkten för slutpunkten den krypterade data snarare än att lagra den i Amazon S3 först. Vi gör detta i det här exemplet eftersom vi har slagit ihop ett stort antal poster till slutledningssamtalet. I praktiken kommer denna batchstorlek att vara mindre eller så kommer batchtransformation att användas istället. Att använda Amazon S3 som mellanhand krävs inte för FHE.
Nu när slutpunkten har ställts in kan vi börja skicka data över. Vi använder normalt olika test- och träningsdatauppsättningar, men för det här exemplet använder vi samma träningsdatauppsättning.
Först laddar vi Iris-datauppsättningen på klientsidan. Därefter ställer vi in FHE-kontexten med Pyfhel. Vi valde Pyfhel för den här processen eftersom den är enkel att installera och arbeta med, inkluderar populära FHE-scheman och förlitar sig på pålitlig underliggande krypteringsimplementering med öppen källkod SEAL. I det här exemplet skickar vi den krypterade datan, tillsammans med information om offentliga nycklar för detta FHE-schema, till servern, vilket gör det möjligt för slutpunkten att kryptera resultatet för att skicka på sin sida med de nödvändiga FHE-parametrarna, men som inte ger den förmåga att dekryptera inkommande data. Den privata nyckeln förblir endast hos klienten, som har förmågan att dekryptera resultaten.
Efter att vi krypterat vår data sammanställer vi en komplett dataordbok – inklusive relevanta nycklar och krypterad data – som ska lagras på Amazon S3. Efteråt gör modellen sina förutsägelser över krypterad data från klienten, som visas i följande kod. Observera att vi inte överför den privata nyckeln, så modellvärden kan inte dekryptera data. I det här exemplet skickar vi data igenom som ett S3-objekt; alternativt kan denna data skickas direkt till Sagemaker-slutpunkten. Som en slutpunkt i realtid innehåller nyttolasten dataparametern i förfrågan, som nämns i SageMaker-dokumentation.
Följande skärmdump visar den centrala förutsägelsen inom fhe_train.py (bilagan visar hela träningsmanuset).
Vi beräknar resultaten av vår krypterade logistiska regression. Denna kod beräknar en krypterad skalär produkt för varje möjlig klass och returnerar resultaten till klienten. Resultaten är de förutspådda logiterna för varje klass i alla exempel.
Klienten returnerar dekrypterade resultat
Följande diagram illustrerar arbetsflödet för klienten som hämtar sitt krypterade resultat och dekrypterar det (med den privata nyckeln som bara de har tillgång till) för att avslöja slutledningsresultatet.
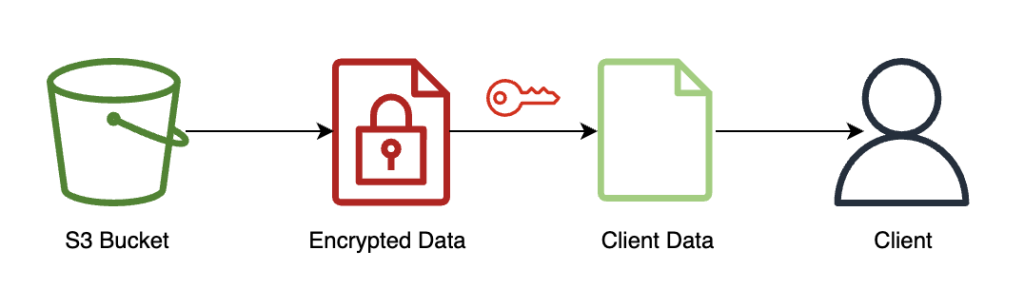
I det här exemplet lagras resultaten på Amazon S3, men i allmänhet skulle detta returneras via nyttolasten för realtidsslutpunkten. Att använda Amazon S3 som mellanhand krävs inte för FHE.
Slutledningsresultatet kommer att vara kontrollerbart nära resultaten som om de hade beräknat det själva, utan att använda FHE.
Städa upp
Vi avslutar denna process genom att ta bort slutpunkten vi skapade, för att säkerställa att det inte finns någon oanvänd dator efter denna process.
Resultat och överväganden
En av de vanligaste nackdelarna med att använda FHE ovanpå modeller är att det lägger till beräkningsoverhead, vilket – i praktiken – gör den resulterande modellen för långsam för interaktiva användningsfall. Men i fall där informationen är mycket känslig kan det vara värt att acceptera denna fördröjning. Men för vår enkla logistiska regression kan vi behandla 140 indataprover inom 60 sekunder och se linjär prestanda. Följande diagram inkluderar den totala tiden från slut till slut, inklusive den tid som utförs av klienten för att kryptera inmatningen och dekryptera resultaten. Den använder också Amazon S3, som lägger till latens och inte krävs för dessa fall.

Vi ser linjär skalning när vi ökar antalet exempel från 1 till 150. Detta förväntas eftersom varje exempel är krypterat oberoende av varandra, så vi förväntar oss en linjär ökning av beräkningen, med en fast installationskostnad.
Detta innebär också att du kan skala din inferensflotta horisontellt för större förfrågningskapacitet bakom din SageMaker-slutpunkt. Du kan använda Amazon SageMaker Inference Recommender att kostnadsoptimera din flotta beroende på dina affärsbehov.
Slutsats
Och där har du det: helt homomorf kryptering ML för en SKLearn logistisk regressionsmodell som du kan ställa in med några rader kod. Med viss anpassning kan du implementera samma krypteringsprocess för olika modelltyper och ramverk, oberoende av träningsdata.
Om du vill lära dig mer om att bygga en ML-lösning som använder homomorf kryptering, kontakta ditt AWS-kontoteam eller partner, Leidos, för att lära dig mer. Du kan också hänvisa till följande resurser för fler exempel:
Innehållet och åsikterna i det här inlägget innehåller de från tredje parts författare och AWS ansvarar inte för innehållet eller riktigheten i detta inlägg.
Appendix
Det fullständiga träningsskriptet är som följer:
Om författarna
Liv d'Aliberti är forskare inom Leidos AI/ML Accelerator under Office of Technology. Deras forskning fokuserar på maskininlärning som bevarar integritet.
Manbir Gulati är forskare inom Leidos AI/ML Accelerator under Office of Technology. Hans forskning fokuserar på skärningspunkten mellan cybersäkerhet och framväxande AI-hot.
Joe Kovba är en Cloud Center of Excellence Practice Lead inom Leidos Digital Modernization Accelerator under Office of Technology. På fritiden tycker han om att döma fotbollsmatcher och spela softboll.
Ben Snively är en specialistlösningsarkitekt inom den offentliga sektorn. Han arbetar med statliga, ideella och utbildningskunder i big data och analytiska projekt, och hjälper dem att bygga lösningar med hjälp av AWS. På fritiden lägger han till IoT-sensorer i hela sitt hus och kör analyser på dem.
Sami Hoda är Senior Solutions Architect i Partners Consulting-divisionen som täcker den globala offentliga sektorn. Sami brinner för projekt där lika delar designtänkande, innovation och emotionell intelligens kan användas för att lösa problem för och påverka människor i nöd.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- Platoblockchain. Web3 Metaverse Intelligence. Kunskap förstärkt. Tillgång här.
- Källa: https://aws.amazon.com/blogs/machine-learning/enable-fully-homomorphic-encryption-with-amazon-sagemaker-endpoints-for-secure-real-time-inferencing/

