Under de senaste åren har datasjöar blivit en vanlig arkitektur, och datakvalitetsvalidering är en kritisk faktor för att förbättra återanvändbarheten och konsistensen av datan. AWS limdatakvalitet minskar ansträngningen som krävs för att validera data från dagar till timmar, och ger datorrekommendationer, statistik och insikter om de resurser som krävs för att köra datavalidering.
AWS Glue Data Quality bygger på DeeQu, ett verktyg med öppen källkod som utvecklats och används på Amazon för att beräkna datakvalitetsmått och verifiera datakvalitetsbegränsningar och förändringar i datadistributionen så att du kan fokusera på att beskriva hur data ska se ut istället för att implementera algoritmer.
I det här inlägget tillhandahåller vi benchmarkresultat för att köra allt mer komplexa datakvalitetsregeluppsättningar över en fördefinierad testdatauppsättning. Som en del av resultaten visar vi hur AWS Glue Data Quality ger information om körtiden för extrahera, transformera och ladda (ETL) jobb, resurserna som mäts i termer av databehandlingsenheter (DPU) och hur du kan spåra kostnaden att köra AWS Glue Data Quality för ETL-pipelines genom att definiera anpassad kostnadsrapportering i AWS Cost Explorer.
Lösningsöversikt
Vi börjar med att definiera vår testdatauppsättning för att utforska hur AWS Glue Data Quality automatiskt skalas beroende på indatauppsättningar.
Dataset detaljer
Testdataset innehåller 104 kolumner och 1 miljon rader lagrade i parkettformat. Du kan ladda ner datamängden eller återskapa det lokalt med Python-skriptet som finns i Repository. Om du väljer att köra generatorskriptet måste du installera pandas och mimesis paket i din Python-miljö:
Datauppsättningsschemat är en kombination av numeriska, kategoriska och strängvariabler för att ha tillräckligt med attribut för att använda en kombination av inbyggd AWS Glue Data Quality regeltyper. Schemat replikerar några av de vanligaste attributen som finns i finansmarknadsdata, såsom instrumentticker, omsatta volymer och prisprognoser.
Regler för datakvalitet
Vi kategoriserar några av de inbyggda AWS Glue Data Quality regeltyperna för att definiera benchmarkstrukturen. Kategorierna överväger om reglerna utför kolumnkontroller som inte kräver inspektion på radnivå (enkla regler), rad-för-rad-analys (mediumregler) eller kontroller av datatyp, och så småningom jämför radvärden med andra datakällor (komplexa regler). ). Följande tabell sammanfattar dessa regler.
| Enkla regler | Medium regler | Komplexa regler |
| Kolumnräkning | DistinctValuesCount | Kolumnvärden |
| ColumnDataType | Är komplett | Fullständighet |
| KolumnExist | Sum | Referensintegritet |
| ColumnNamesMatchPattern | Standardavvikelse | KolumnKorrelation |
| RowCount | Betyda | RowCountMatch |
| Kolumnlängd | . | . |
Vi definierar åtta olika AWS Glue ETL-jobb där vi kör datakvalitetsreglerna. Varje jobb har ett olika antal datakvalitetsregler kopplade till sig. Varje jobb har också en tillhörande användardefinierad kostnadsfördelningstagg som vi använder för att skapa en kostnadsrapport för datakvalitet i AWS Cost Explorer senare.
Vi tillhandahåller klartextdefinitionen för varje regeluppsättning i följande tabell.
| Jobb namn | Enkla regler | Medium regler | Komplexa regler | Antal regler | tagg | Definition |
| regeluppsättning-0 | 0 | 0 | 0 | 0 | dqjob:rs0 | - |
| regeluppsättning-1 | 0 | 0 | 1 | 1 | dqjob:rs1 | Länk |
| regeluppsättning-5 | 3 | 1 | 1 | 5 | dqjob:rs5 | Länk |
| regeluppsättning-10 | 6 | 2 | 2 | 10 | dqjob:rs10 | Länk |
| regeluppsättning-50 | 30 | 10 | 10 | 50 | dqjob:rs50 | Länk |
| regeluppsättning-100 | 50 | 30 | 20 | 100 | dqjob:rs100 | Länk |
| regeluppsättning-200 | 100 | 60 | 40 | 200 | dqjob:rs200 | Länk |
| regeluppsättning-400 | 200 | 120 | 80 | 400 | dqjob:rs400 | Länk |
Skapa AWS Glue ETL-jobb som innehåller datakvalitetsreglerna
Vi laddar upp testdatauppsättning till Amazon enkel lagringstjänst (Amazon S3) och även två ytterligare CSV-filer som vi kommer att använda för att utvärdera referensintegritetsregler i AWS Glue Data Quality (isokoder.csv och exchanges.csv) efter att de har lagts till i AWS Glue Data Catalog. Slutför följande steg:
- På Amazon S3-konsolen skapar du en ny S3-bucket på ditt konto och laddar upp testdatauppsättning.
- Skapa en mapp i S3-hinken som heter
isocodesoch ladda upp isokoder.csv fil. - Skapa en annan mapp i S3-bucketen som heter utbyte och ladda upp exchanges.csv fil.
- På AWS Glue-konsolen, kör två AWS Glue-sökrobotar, en för varje mapp för att registrera CSV-innehållet i AWS Glue Data Catalog (
data_quality_catalog). För instruktioner, se Lägga till en AWS Glue Crawler.
AWS Glue-sökrobotar genererar två tabeller (exchanges och isocodes) som en del av AWS Glue Data Catalog.

Nu ska vi skapa AWS identitets- och åtkomsthantering (JAG ÄR) roll som kommer att antas av ETL-jobben vid körning:
- På IAM-konsolen skapar du en ny IAM-roll som heter
AWSGlueDataQualityPerformanceRole - För Typ av betrodd enhet, Välj AWS-tjänst.
- För Service eller användningsfallväljer Lim.
- Välja Nästa.

- För Tillståndspolicyer, stiga på
AWSGlueServiceRole - Välja Nästa.

- Skapa och bifoga en ny inline-policy (
AWSGlueDataQualityBucketPolicy) med följande innehåll. Byt ut platshållaren med S3-skopnamnet som du skapade tidigare:
Därefter skapar vi ett av AWS Glue ETL-jobben, ruleset-5.
- På AWS Lim-konsolen, under ETL jobb välj i navigeringsfönstret Visuell ETL.
- I Skapa jobb avsnitt väljer Visuell ETL.x

- Lägg till en i Visual Editor Datakälla – S3 Bucket källnod:
- För S3 URL, ange S3-mappen som innehåller testdatauppsättningen.
- För Dataformatväljer Parkett.

- Skapa en ny åtgärdsnod, Transform: Evaluate-Data-Catalog:
- För Nodföräldrar, välj den nod du skapade.
- Lägg till regeluppsättning-5 definition under Regeluppsättningsredigerare.

- Bläddra till slutet och under Prestandakonfiguration, Gör det möjligt Cache-data.

- Enligt Jobb detaljer, För IAM-rollväljer
AWSGlueDataQualityPerformanceRole.
- I Tags avsnitt, definiera dqjob tagga som rs5.
Denna tagg kommer att vara olika för vart och ett av datakvalitets-ETL-jobben; vi använder dem i AWS Cost Explorer för att granska kostnaden för ETL-jobb.

- Välja Save.
- Upprepa dessa steg med resten av regeluppsättningarna för att definiera alla ETL-jobb.

Kör AWS Glue ETL-jobben
Utför följande steg för att köra ETL-jobben:
- Välj på AWS Lim-konsolen Visuell ETL under ETL jobb i navigeringsfönstret.
- Välj ETL-jobbet och välj Kör jobb.
- Upprepa för alla ETL-jobb.

När ETL-jobben är klara, Jobbkörningsövervakning sidan kommer att visa jobbdetaljerna. Som visas i följande skärmdump, a DPU timmar kolumn finns för varje ETL-jobb.

Granska prestanda
Följande tabell sammanfattar varaktigheten, DPU-timmar och uppskattade kostnader för att köra de åtta olika datakvalitetsregeluppsättningarna över samma testdatauppsättning. Observera att alla regeluppsättningar har körts med hela testdatasetet som beskrivits tidigare (104 kolumner, 1 miljon rader).
| ETL jobbnamn | Antal regler | tagg | Varaktighet (sek) | Antal DPU-timmar | Antal DPU:er | Kostnad ($) |
| regeluppsättning-400 | 400 | dqjob:rs400 | 445.7 | 1.24 | 10 | $0.54 |
| regeluppsättning-200 | 200 | dqjob:rs200 | 235.7 | 0.65 | 10 | $0.29 |
| regeluppsättning-100 | 100 | dqjob:rs100 | 186.5 | 0.52 | 10 | $0.23 |
| regeluppsättning-50 | 50 | dqjob:rs50 | 155.2 | 0.43 | 10 | $0.19 |
| regeluppsättning-10 | 10 | dqjob:rs10 | 152.2 | 0.42 | 10 | $0.18 |
| regeluppsättning-5 | 5 | dqjob:rs5 | 150.3 | 0.42 | 10 | $0.18 |
| regeluppsättning-1 | 1 | dqjob:rs1 | 150.1 | 0.42 | 10 | $0.18 |
| regeluppsättning-0 | 0 | dqjob:rs0 | 53.2 | 0.15 | 10 | $0.06 |
Kostnaden för att utvärdera en tom regeluppsättning är nära noll, men den har inkluderats eftersom den kan användas som ett snabbtest för att validera IAM-rollerna som är kopplade till AWS Glue Data Quality-jobb och läsbehörigheter till testdataset i Amazon S3. Kostnaden för datakvalitetsjobb börjar bara öka efter att ha utvärderat regeluppsättningar med mer än 100 regler, som förblir konstant under det antalet.
Vi kan observera att kostnaden för att köra datakvalitet för den största regeluppsättningen i riktmärket (400 regler) fortfarande ligger något över $0.50.
Datakvalitetskostnadsanalys i AWS Cost Explorer
För att se ETL-jobbtaggarna för datakvalitet i AWS Cost Explorer måste du aktivera de användardefinierade kostnadsfördelningstaggarna först.
När du har skapat och tillämpat användardefinierade taggar på dina resurser kan det ta upp till 24 timmar innan taggnycklarna visas på sidan för kostnadsfördelningstaggar för aktivering. Det kan sedan ta upp till 24 timmar för taggnycklarna att aktiveras.
- På AWS Kostnadsutforskare konsol, välj Kostnadsutforskare sparade rapporter i navigeringsfönstret.
- Välja Skapa ny rapport.

- Välja Kostnad och användning som rapporttyp.
- Välja Skapa rapport.
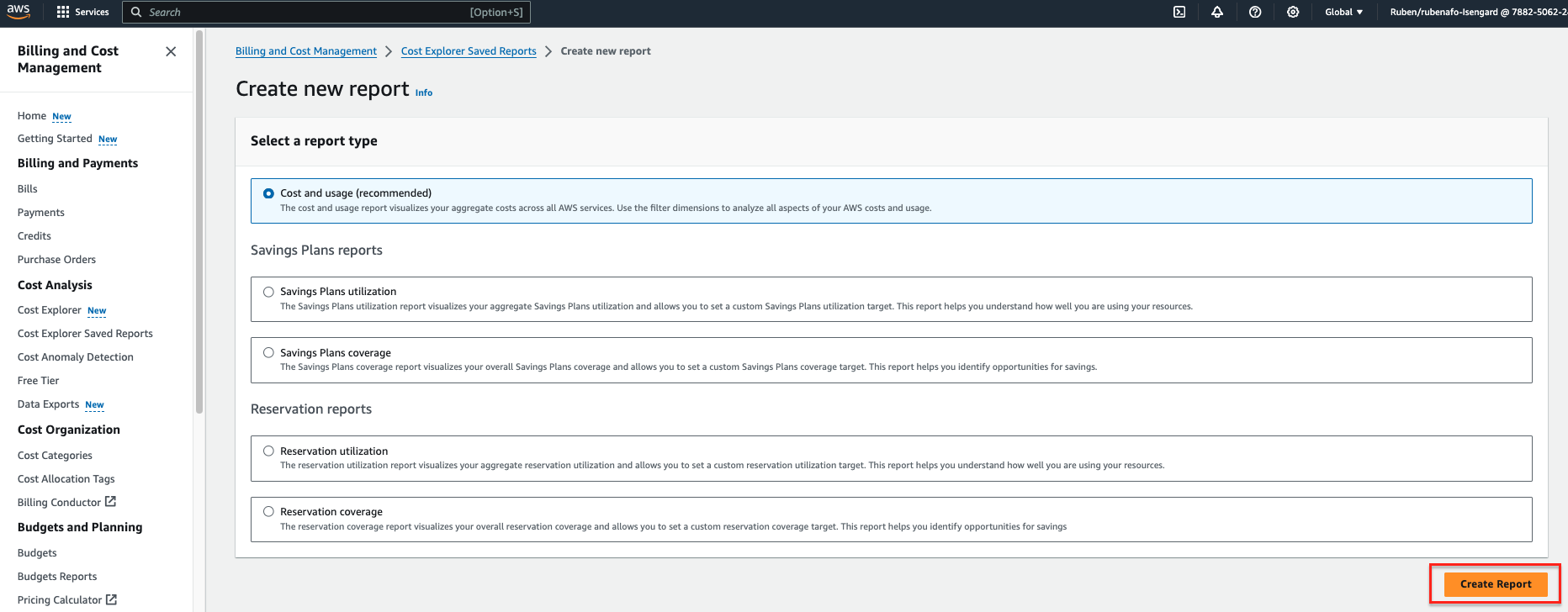
- För Datumintervall, ange ett datumintervall.
- För kornighet¸ välja Dagligen.
- För Dimensioneraväljer tagg, välj sedan
dqjobmärka.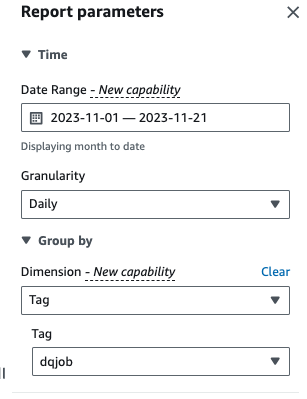
- Enligt Tillämpade filter, Välj den
dqjobtaggen och de åtta taggarna som används i datakvalitetsregeluppsättningarna (rs0, rs1, rs5, rs10, rs50, rs100, rs200 och rs400).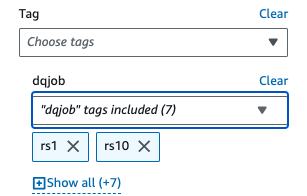
- Välja Ansök.
Kostnads- och användningsrapporten kommer att uppdateras. X-axeln visar regeluppsättningstaggarna för datakvalitet som kategorier. De Kostnad och användning grafen i AWS Cost Explorer kommer att uppdateras och visa den totala månadskostnaden för de senaste körda ETL-jobben med datakvalitet, aggregerade efter ETL-jobb.

Städa upp
För att rensa upp infrastrukturen och undvika extra avgifter, slutför följande steg:
- Töm S3-hinken som ursprungligen skapades för att lagra testdatauppsättningen.
- Ta bort ETL-jobben du skapade i AWS Glue.
- Radera
AWSGlueDataQualityPerformanceRoleIAM roll. - Ta bort den anpassade rapporten som skapats i AWS Cost Explorer.
Slutsats
AWS Glue Data Quality tillhandahåller ett effektivt sätt att införliva datakvalitetsvalidering som en del av ETL-pipelines och skalas automatiskt för att ta emot ökande datamängder. De inbyggda datakvalitetsregeltyperna erbjuder ett brett utbud av alternativ för att anpassa datakvalitetskontrollerna och fokusera på hur din data ska se ut istället för att implementera odifferentierad logik.
I den här benchmarkanalysen visade vi hur regeluppsättningar för AWS Glue Data Quality i vanliga storlekar har liten eller ingen overhead, medan kostnaden i komplexa fall ökar linjärt. Vi har också granskat hur du kan tagga AWS Glue Data Quality-jobb för att göra kostnadsinformation tillgänglig i AWS Cost Explorer för snabb rapportering.
AWS Glue Data Quality är allmänt tillgänglig i alla AWS-regioner där AWS Glue är tillgängligt. Läs mer om AWS Glue Data Quality och AWS Glue Data Catalogue i Komma igång med AWS Glue Data Quality från AWS Glue Data Catalog.
Om författarna
 Reuben Afonso är en Global Financial Services Solutions Architect med AWS. Han tycker om att arbeta med analyser och AI/ML-utmaningar, med en passion för automatisering och optimering. När han inte är på jobbet tycker han om att hitta gömda platser utanför den upptrampade stigen runt Barcelona.
Reuben Afonso är en Global Financial Services Solutions Architect med AWS. Han tycker om att arbeta med analyser och AI/ML-utmaningar, med en passion för automatisering och optimering. När han inte är på jobbet tycker han om att hitta gömda platser utanför den upptrampade stigen runt Barcelona.
 Kalyan Kumar Neelampudi (KK) är en Specialist Partner Solutions Architect (Data Analytics & Generative AI) på AWS. Han fungerar som teknisk rådgivare och samarbetar med olika AWS-partners för att designa, implementera och bygga praxis kring dataanalys och AI/ML-arbetsbelastningar. Utanför jobbet är han en badmintonentusiast och kulinarisk äventyrare, utforskar lokala rätter och reser med sin partner för att upptäcka nya smaker och upplevelser.
Kalyan Kumar Neelampudi (KK) är en Specialist Partner Solutions Architect (Data Analytics & Generative AI) på AWS. Han fungerar som teknisk rådgivare och samarbetar med olika AWS-partners för att designa, implementera och bygga praxis kring dataanalys och AI/ML-arbetsbelastningar. Utanför jobbet är han en badmintonentusiast och kulinarisk äventyrare, utforskar lokala rätter och reser med sin partner för att upptäcka nya smaker och upplevelser.

Gonzalo herreros är Senior Big Data Architect på AWS Glue-teamet.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoData.Network Vertical Generative Ai. Styrka dig själv. Tillgång här.
- PlatoAiStream. Web3 Intelligence. Kunskap förstärkt. Tillgång här.
- Platoesg. Kol, CleanTech, Energi, Miljö, Sol, Avfallshantering. Tillgång här.
- PlatoHealth. Biotech och kliniska prövningar Intelligence. Tillgång här.
- Källa: https://aws.amazon.com/blogs/big-data/measure-performance-of-aws-glue-data-quality-for-etl-pipelines/

