Beskrivning
Inom datorseende finns olika tekniker för detektering av levande objekt, inklusive Faster R-CNN, SSDoch YOLO. Varje teknik har sina begränsningar och fördelar. Faster R-CNN kan utmärka sig i noggrannhet, men det kanske inte fungerar lika bra i realtidsscenarier, vilket leder till en förändring mot YOLO algoritm.
Objektdetektering är grundläggande i datorseende, vilket gör det möjligt för maskiner att identifiera och lokalisera objekt inom en ram eller skärm. Under årens lopp har olika objektdetekteringsalgoritmer utvecklats, där YOLO framstår som en av de mest framgångsrika. Nyligen har YOLOv8 introducerats, vilket ytterligare förbättrar algoritmens möjligheter.
I den här omfattande guiden utforskar vi tre framträdande objektdetekteringsalgoritmer: Faster R-CNN, SSD (Single Shot MultiBox Detector) och YOLOv8. Vi diskuterar de praktiska aspekterna av att implementera dessa algoritmer, inklusive att sätta upp en virtuell miljö och utveckla en Streamlit-applikation.
Lärande mål
- Förstå Faster R-CNN, SSD och YOLO och analysera skillnaderna mellan dem.
- Få praktisk erfarenhet av att implementera live-objektdetektionssystem med OpenCV, Supervision och YOLOv8.
- Förstå bildsegmenteringsmodellen med hjälp av Roboflow-kommentaren.
- Skapa en Streamlit-applikation för ett enkelt användargränssnitt.
Låt oss utforska hur man gör bildsegmentering med YOLOv8!
Innehållsförteckning
Denna artikel publicerades som en del av Data Science Blogathon.
Snabbare R-CNN
Faster R-CNN (Faster Region-based Convolutional Neural Network) är en djupinlärningsbaserad objektdetekteringsalgoritm. Det utvärderas med R-CNN och Fast R-CNN ramverk och kan betraktas som en förlängning av Fast R-CNN.
Denna algoritm introducerar Region Proposal Network (RPN) för att generera regionförslag, och ersätter den selektiva sökningen som används i R-CNN. RPN delar faltningslager med detektionsnätverket, vilket möjliggör effektiv träning från början till slut.
De genererade regionförslagen matas sedan in i ett Fast R-CNN-nätverk för begränsningsboxförfining och objektklassificering.
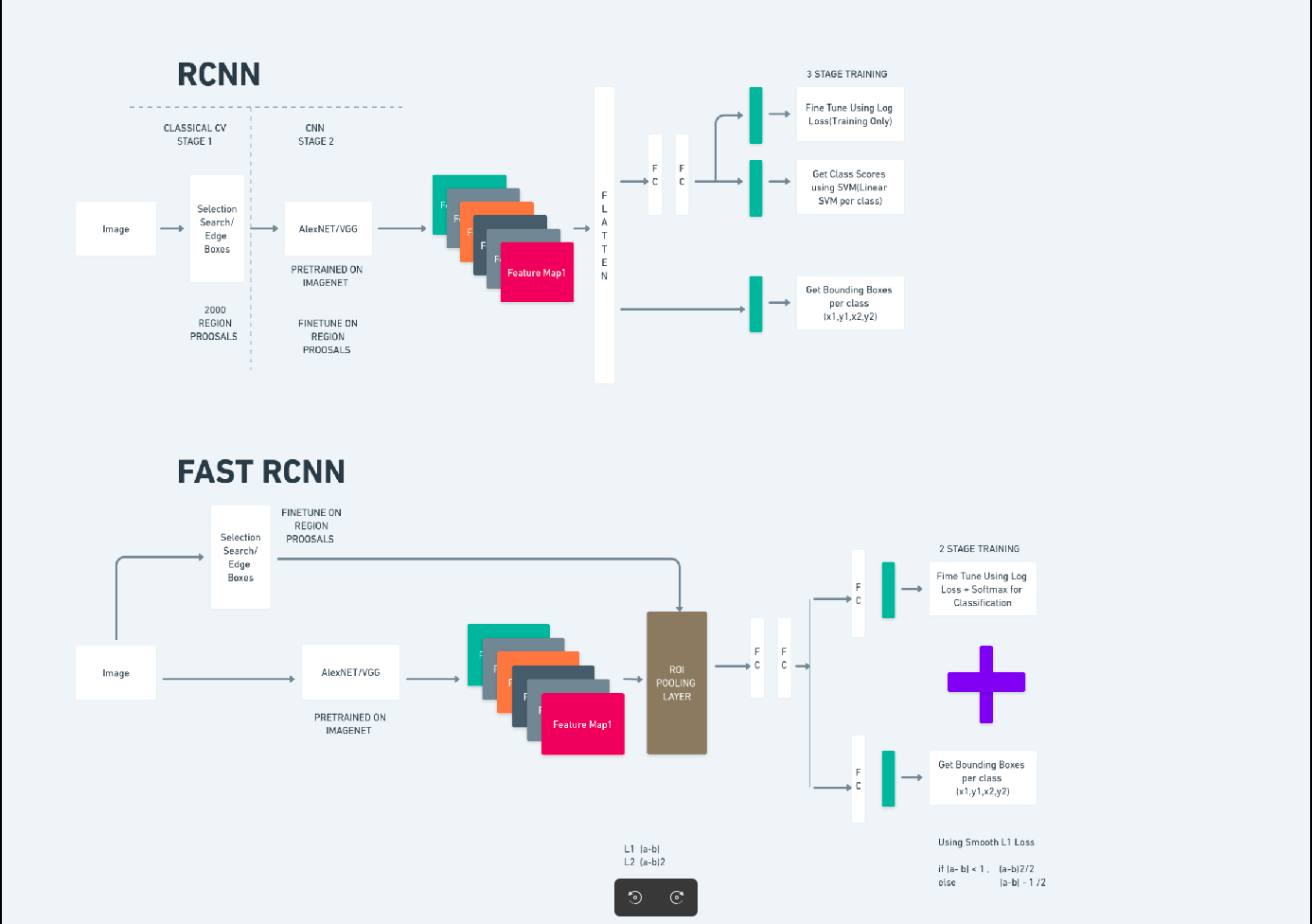
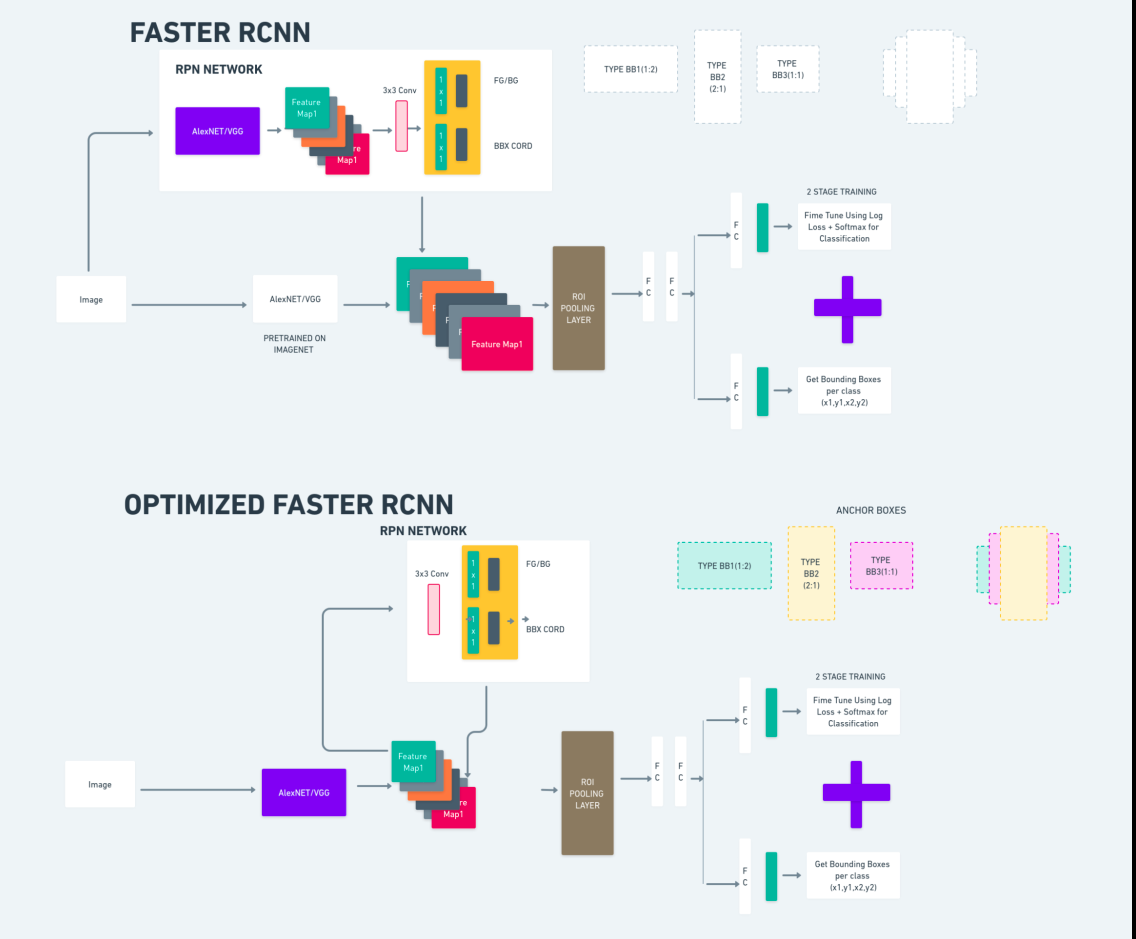
Diagrammet ovan illustrerar Faster R-CNN-familjen på ett heltäckande sätt och är lätt att förstå för att utvärdera varje algoritm.
Single Shot MultiBox Detector (SSD)
Smakämnen Single Shot MultiBox-detektor (SSD) är populär inom objektdetektering och används främst i datorseende uppgifter. I den tidigare metoden, Faster R-CNN, följde vi två steg: det första steget involverade detektionsdelen och det andra involverade regression. Men med SSD utför vi bara ett enda detekteringssteg. SSD introducerades 2016 för att möta behovet av en snabb och exakt objektdetekteringsmodell.

SSD har flera fördelar jämfört med tidigare objektdetekteringsmetoder som Faster R-CNN:
- Effektivitet: SSD är en enstegsdetektor, vilket innebär att den direkt förutsäger begränsningsrutor och klasspoäng utan att behöva ett separat steg för att generera förslag. Detta gör den snabbare jämfört med tvåstegsdetektorer som Faster R-CNN.
- End-to-end-träning: SSD kan tränas från början till slut, vilket optimerar både basnätverket och detektionshuvudet tillsammans, vilket förenklar träningsprocessen.
- Multi-scale Feature Fusion: SSD fungerar på funktionskartor i flera skalor, vilket gör att den kan upptäcka objekt av varierande storlek mer effektivt.
SSD har en bra balans mellan hastighet och noggrannhet, vilket gör den lämplig för realtidsapplikationer där både prestanda och effektivitet är avgörande.
Du tittar bara en gång (YOLOv8)
2015 introducerades You Only Look Once (YOLO) som en objektdetekteringsalgoritm i en forskningsartikel av Joseph Redmon, Santosh Divvala, Ross Girshick och Ali Farhadi. YOLO är en single-shot-algoritm som direkt klassificerar ett objekt i ett enda pass genom att endast ett neuralt nätverk förutsäger begränsningsrutor och klasssannolikheter med hjälp av en hel bild som indata.
Låt oss nu förstå YOLOv8 som toppmoderna framsteg inom objektdetektering i realtid med förbättrad noggrannhet och hastighet. YOLOv8 låter dig utnyttja förtränade modeller, som redan är tränade på ett stort dataset som COCO (Common Objects in Context). Bildsegmentering ger information på pixelnivå om varje objekt, vilket möjliggör mer detaljerad analys och förståelse av bildinnehållet.
Även om bildsegmentering kan vara beräkningsmässigt dyrt, integrerar YOLOv8 denna metod i sin neurala nätverksarkitektur, vilket möjliggör effektiv och exakt objektsegmentering.
Arbetsprincipen för YOLOv8
YOLOv8 fungerar genom att först dela in inmatningsbilden i rutnätsceller. Med hjälp av dessa rutnätsceller förutsäger YOLOv8 begränsningsrutorna (bbox) med sannolikheter för klass.
Efteråt använder YOLOv8 NMS-algoritmen för att minska överlappning. Till exempel, om det finns flera bilar närvarande i bilden vilket resulterar i överlappande begränsningsrutor, hjälper NMS-algoritmen till att minska denna överlappning.
Skillnad mellan varianter av Yolo V8: YOLOv8 finns i tre varianter: YOLOv8, YOLOv8-L och YOLOv8-X. Den största skillnaden mellan varianterna är storleken på stamnätet. YOLOv8 har det minsta stamnätet, medan YOLOv8-X har det största stamnätet.
Skillnaden mellan Faster R-CNN, SSD och YOLO
| Aspect | Snabbare R-CNN | SSD | YOLO |
|---|---|---|---|
| arkitektur | Tvåstegsdetektor med RPN och Fast R-CNN | Enstegsdetektor | Enstegsdetektor |
| Regionförslag | Ja | Nej | Nej |
| Detektionshastighet | Långsammare jämfört med SSD och YOLO | Snabbare jämfört med Faster R-CNN, långsammare än YOLO | Mycket snabb |
| Noggrannhet | Generellt högre noggrannhet | Balanserad noggrannhet och hastighet | Anständig noggrannhet, särskilt för realtidsapplikationer |
| Flexibilitet | Flexibel, kan hantera olika objektstorlekar och bildförhållanden | Kan hantera flera skalor av objekt | Kan kämpa med exakt lokalisering av små föremål |
| Unified Detection | Nej | Nej | Ja |
| Avvägning mellan hastighet och noggrannhet | Offrar i allmänhet hastighet för noggrannhet | Balanserar hastighet och precision | Prioriterar hastigheten med bibehållen anständig noggrannhet |
Vad är segmentering?
Som vi vet innebär segmentering att vi delar upp den stora bilden i mindre grupper baserat på vissa egenskaper. Låt oss förstå bildsegmentering som är datorseendetekniken som används för att dela upp en bild i olika flera segment eller regioner. Eftersom bilderna är gjorda av pixlar och In Image-segmentering, grupperas pixlar efter likheten i färg, intensitet, struktur eller andra visuella egenskaper.
Till exempel, om en bild innehåller träd, bilar eller människor kommer bildsegmenteringen att dela upp bilden i olika klasser som representerar meningsfulla objekt eller delar av bilden. Bildsegmentering används ofta inom olika områden som medicinsk bildbehandling, satellitbildsanalys, objektigenkänning i datorseende och mer.

I segmenteringsdelen skapar vi initialt den första YOLOv8-segmenteringsmodellen med hjälp av Robflow. Sedan importerar vi segmenteringsmodellen för att utföra segmenteringsuppgiften. Frågan uppstår: varför skapar vi segmenteringsmodellen när uppgiften kunde slutföras med enbart en detektionsalgoritm?
Segmentering gör att vi kan få hela kroppsbilden av en klass. Medan detekteringsalgoritmer fokuserar på att upptäcka närvaron av objekt, ger segmentering en mer exakt förståelse genom att avgränsa objektens exakta gränser. Detta leder till mer exakt lokalisering och förståelse av objekten som finns i bilden.
Segmentering innebär dock vanligtvis högre tidskomplexitet jämfört med detekteringsalgoritmer eftersom det kräver ytterligare steg som att separera annoteringar och skapa modellen. Trots denna nackdel kan den ökade precisionen som erbjuds av segmentering uppväga beräkningskostnaden i uppgifter där exakt objektavgränsning är avgörande.
Steg-för-steg livedetektering och bildsegmentering med YOLOv8
I det här konceptet utforskar vi stegen för att skapa en virtuell miljö med hjälp av conda, aktivera venv och installera kravpaketen med pip. först skapar vi det normala python-skriptet och sedan skapar vi den strömbelysta applikationen.
Steg 1: Skapa en virtuell miljö med Conda
conda create -p ./venv python=3.8 -ySteg 2: Aktivera den virtuella miljön
conda activate ./venv
Steg 3: Skapa requirements.txt
Öppna terminalen och klistra in nedanstående skript:
touch requirements.txtSteg 4: Använd Nano-kommandot och redigera requirements.txt
Efter att ha skapat requirements.txt, skriv följande kommando för att redigera requirements.txt
nano requirements.txtEfter att ha kört ovanstående skript kan du se detta användargränssnitt.
Skriv hennes nödvändiga paket.
ultralytics==8.0.32
supervision==0.2.1
streamlitTryck sedan på "ctrl+o"(det här kommandot sparar redigeringsdelen) och tryck sedan på "Stiga på"
Efter att ha tryckt på "Ctrl+x”. du kan avsluta filen. och går till huvudvägen.
Steg 5: Installera requirements.txt
pip install -r requirements.txtSteg 6: Skapa Python-skriptet
Skriv följande skript i terminalen eller så kan vi säga kommando.
touch main.pyEfter att ha skapat main.py, öppna vs-koden du använder kommandot write in terminal,
code Steg 7: Skriva Python-skriptet
import cv2
from ultralytics import YOLO
import supervision as sv
# Define the frame width and height for video capture
frame_width = 1280
frame_height = 720
def main():
# Initialize video capture from default camera
cap = cv2.VideoCapture(0)
cap.set(cv2.CAP_PROP_FRAME_WIDTH, frame_width)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, frame_height)
# Load YOLOv8 model
model = YOLO("yolov8l.pt")
# Initialize box annotator for visualization
box_annotator = sv.BoxAnnotator(
thickness=2,
text_thickness=2,
text_scale=1
)
# Main loop for video processing
while True:
# Read frame from video capture
ret, frame = cap.read()
# Perform object detection using YOLOv8
result = model(frame, agnostic_nms=True)[0]
detections = sv.Detections.from_yolov8(result)
# Prepare labels for detected objects
labels = [
f"{model.model.names[class_id]} {confidence:0.2f}"
for _, confidence, class_id, _
in detections
]
# Annotate frame with bounding boxes and labels
frame = box_annotator.annotate(
scene=frame,
detections=detections,
labels=labels
)
# Display annotated frame
cv2.imshow("yolov8", frame)
# Check for quit key
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# Release video capture
cap.release()
cv2.destroyAllWindows()
if __name__ == "__main__":
main()
Efter att ha kört det här kommandot kan du se att din kamera är öppen och känner av en del av dig. som kön och bakgrundsdelar.
Steg 7: Skapa strömbelyst app
import cv2
import streamlit as st
from ultralytics import YOLO
import supervision as sv
# Define the frame width and height for video capture
frame_width = 1280
frame_height = 720
def main():
# Set page title and header
st.title("Live Object Detection with YOLOv8")
# Button to start the camera
start_camera = st.button("Start Camera")
if start_camera:
# Initialize video capture from default camera
cap = cv2.VideoCapture(0)
cap.set(cv2.CAP_PROP_FRAME_WIDTH, frame_width)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, frame_height)
# Load YOLOv8 model
model = YOLO("yolov8l.pt")
# Initialize box annotator for visualization
box_annotator = sv.BoxAnnotator(
thickness=2,
text_thickness=2,
text_scale=1
)
# Main loop for video processing
while True:
# Read frame from video capture
ret, frame = cap.read()
# Perform object detection using YOLOv8
result = model(frame, agnostic_nms=True)[0]
detections = sv.Detections.from_yolov8(result)
# Prepare labels for detected objects
labels = [
f"{model.model.names[class_id]} {confidence:0.2f}"
for _, confidence, class_id, _
in detections
]
# Annotate frame with bounding boxes and labels
frame = box_annotator.annotate(
scene=frame,
detections=detections,
labels=labels
)
# Display annotated frame
st.image(frame, channels="BGR", use_column_width=True)
# Check for quit key
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# Release video capture
cap.release()
if __name__ == "__main__":
main()
I det här skriptet skapar vi den strömbelysta applikationen och skapar knappen så att din enhetskamera är öppen efter att ha tryckt på knappen och upptäcker delen i ramen.
Kör det här skriptet med det här kommandot.
streamlit run app.py
# first create the app.py then paste the above code and run this script.Efter att ha kört kommandot ovan antar du att du fick nå-out-felet som,
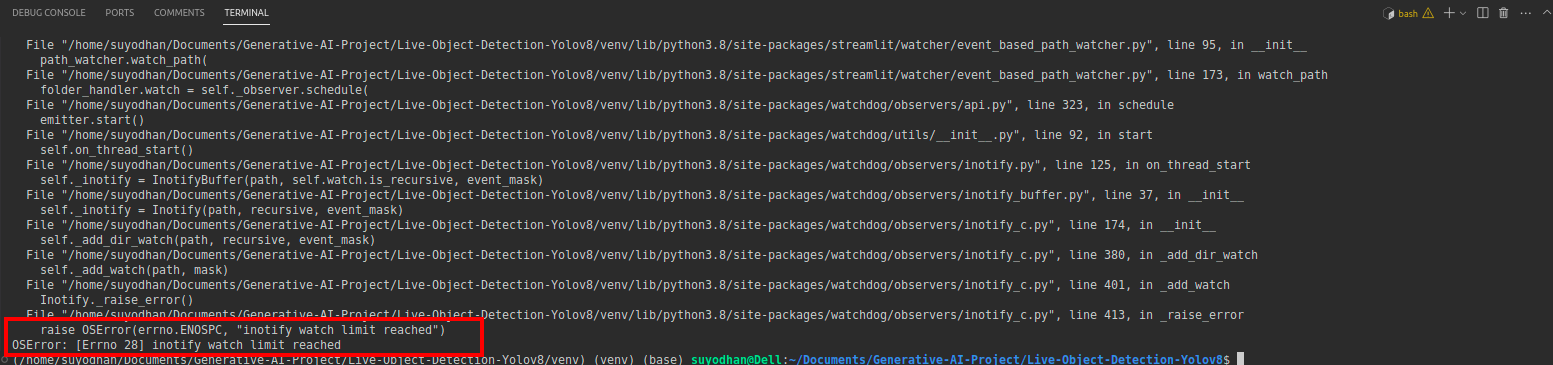
tryck sedan på detta kommando,
sudo sysctl fs.inotify.max_user_watches=524288Efter att ha tryckt på kommandot vill du skriva ditt lösenord med eftersom vi använder sudo-kommandot sudo is god:)
Kör skriptet igen. och du kan se den strömbelysta applikationen.
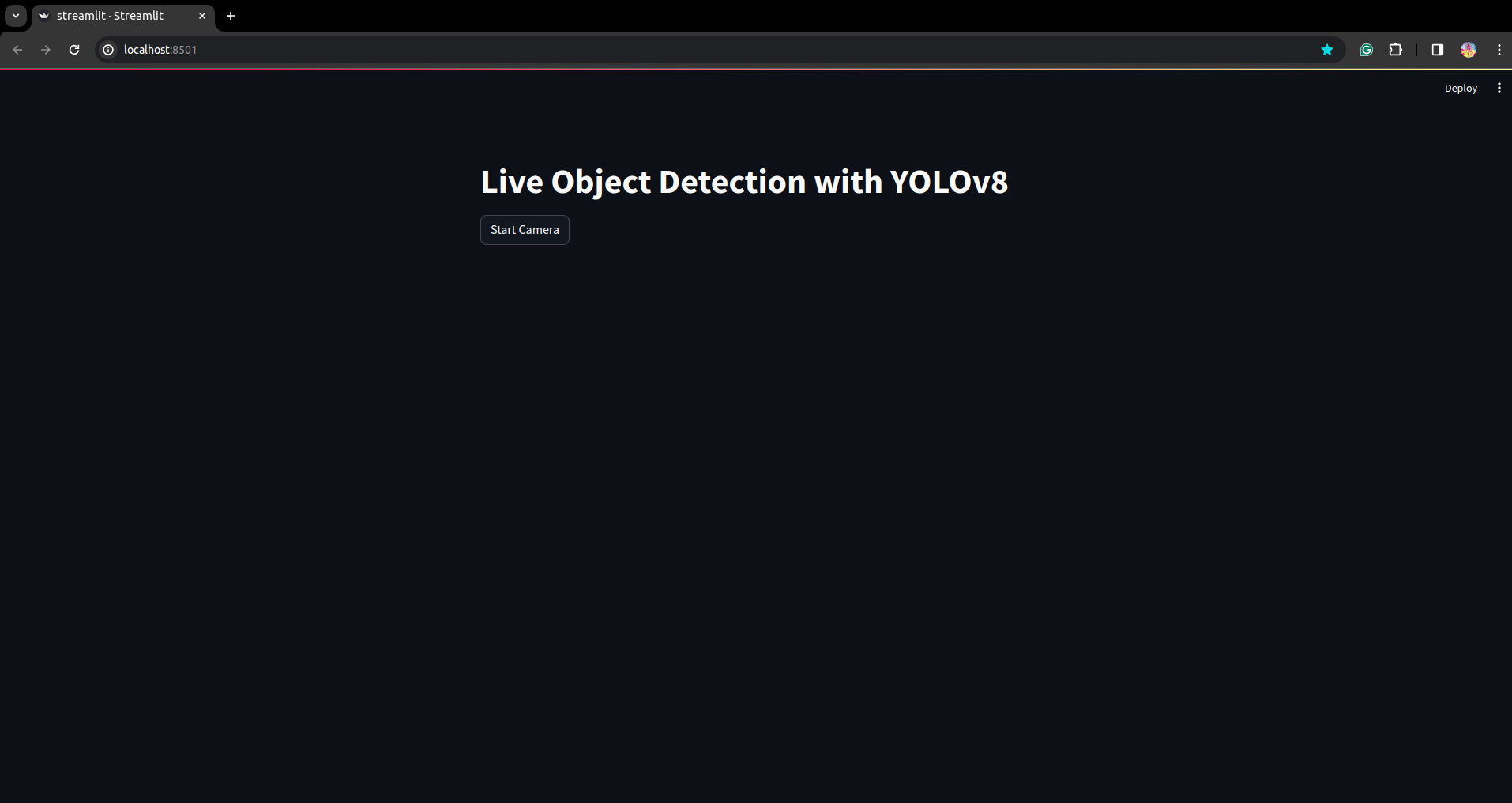
Här kan vi skapa en framgångsrik livedetektionsapplikation i nästa del kommer vi att se segmenteringsdelen.
Steg för anteckning
Steg 1: Roboflow-inställning
Efter att ha signerat "Skapa projekt”. här kan du skapa projektet och anteckningsgruppen.

Steg 2: Nedladdning av datauppsättningar
Här överväger vi det enkla exemplet men du vill använda det på din problemformulering så jag använder här duck dataset.
Gå den här länk och ladda ner ankadatasetet.

Extrahera mappen där kan du se de tre mapparna: tåg, test och val.
Steg 3: Ladda upp datamängden på roboflow
Efter att ha skapat projektet i roboflow kan du se det här användargränssnittet här kan du ladda upp din datauppsättning så laddar du bara upp bilder på tågdelar välj "Välj mapp" alternativ.
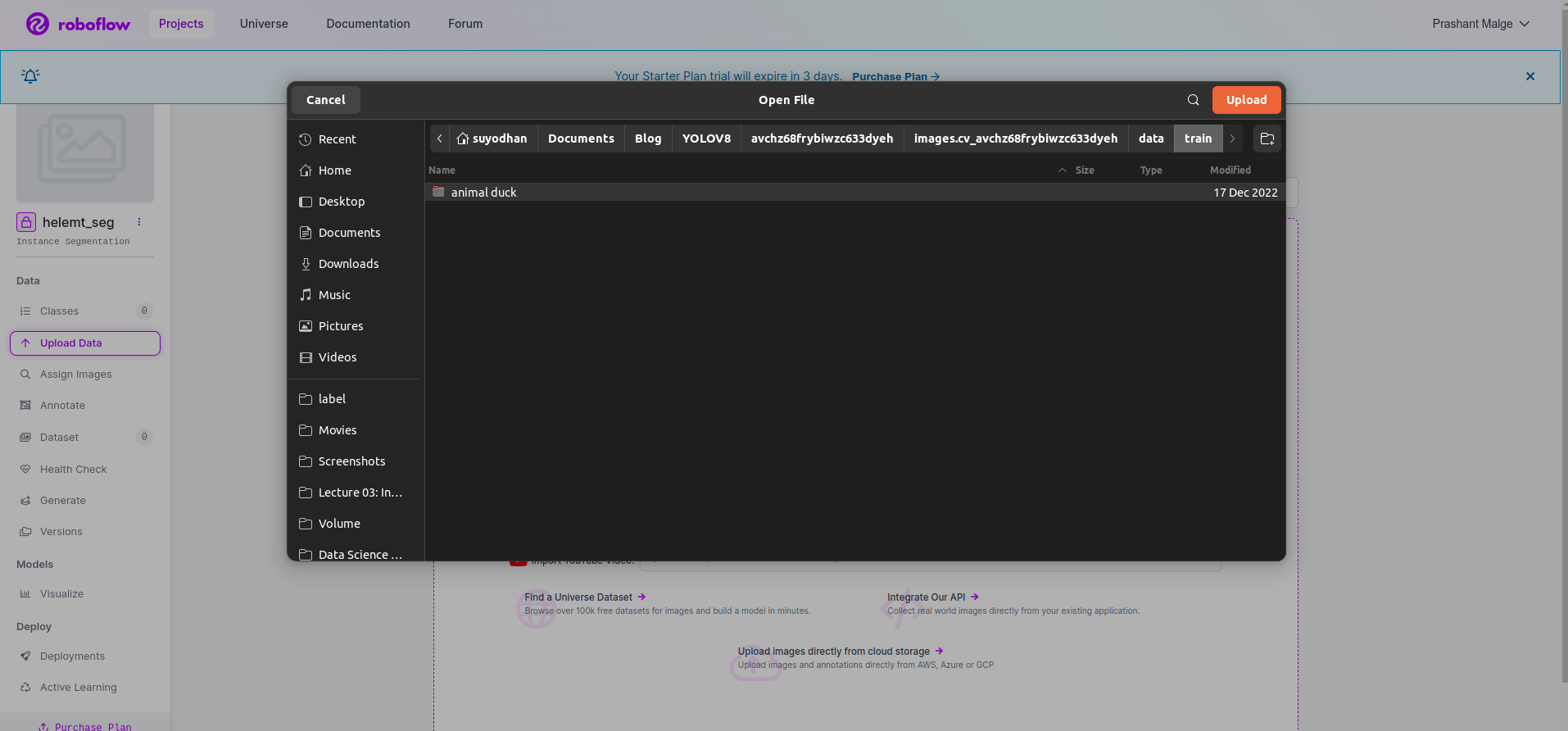
Klicka sedan på “spara och fortsätt" alternativ som jag markerar i en röd rektangelruta
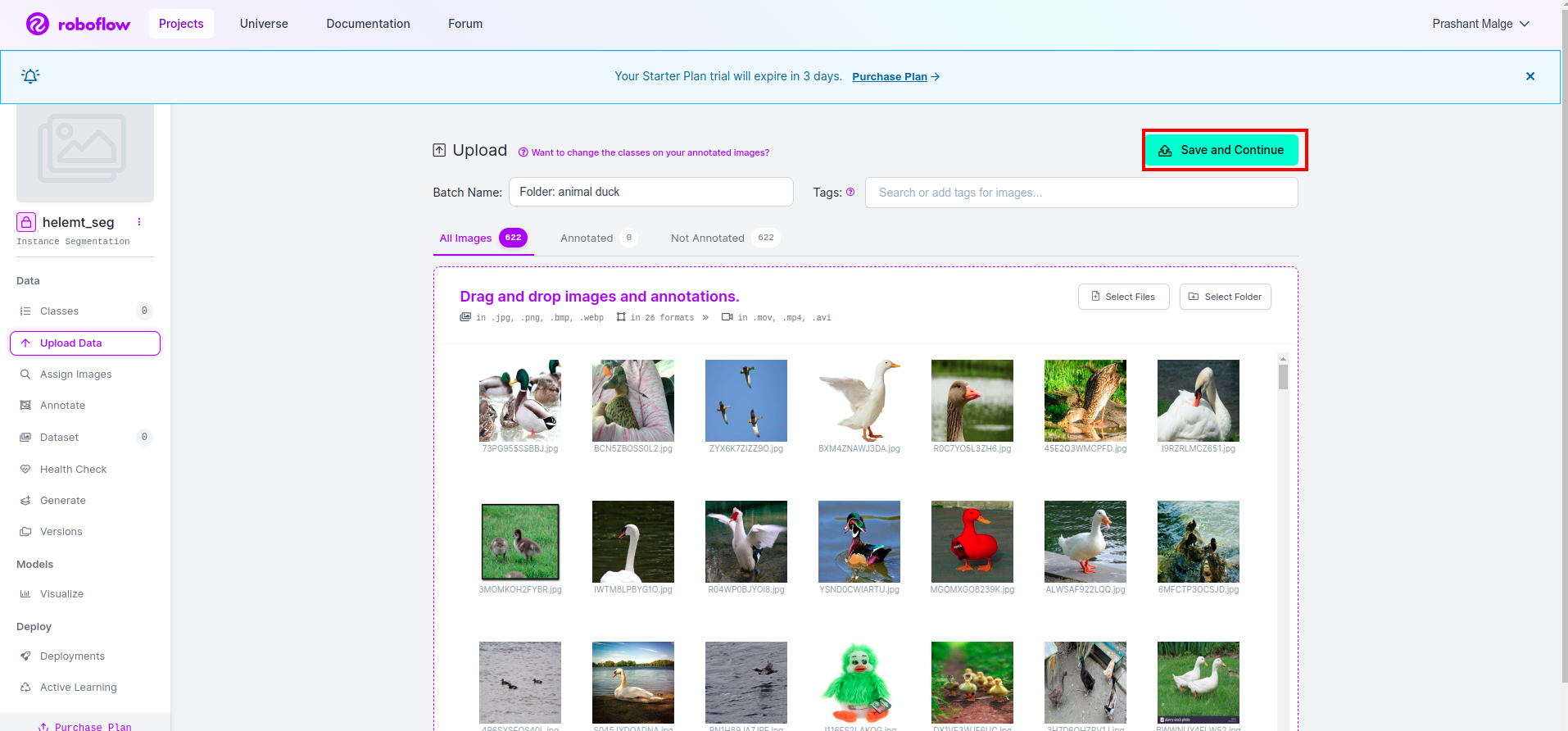
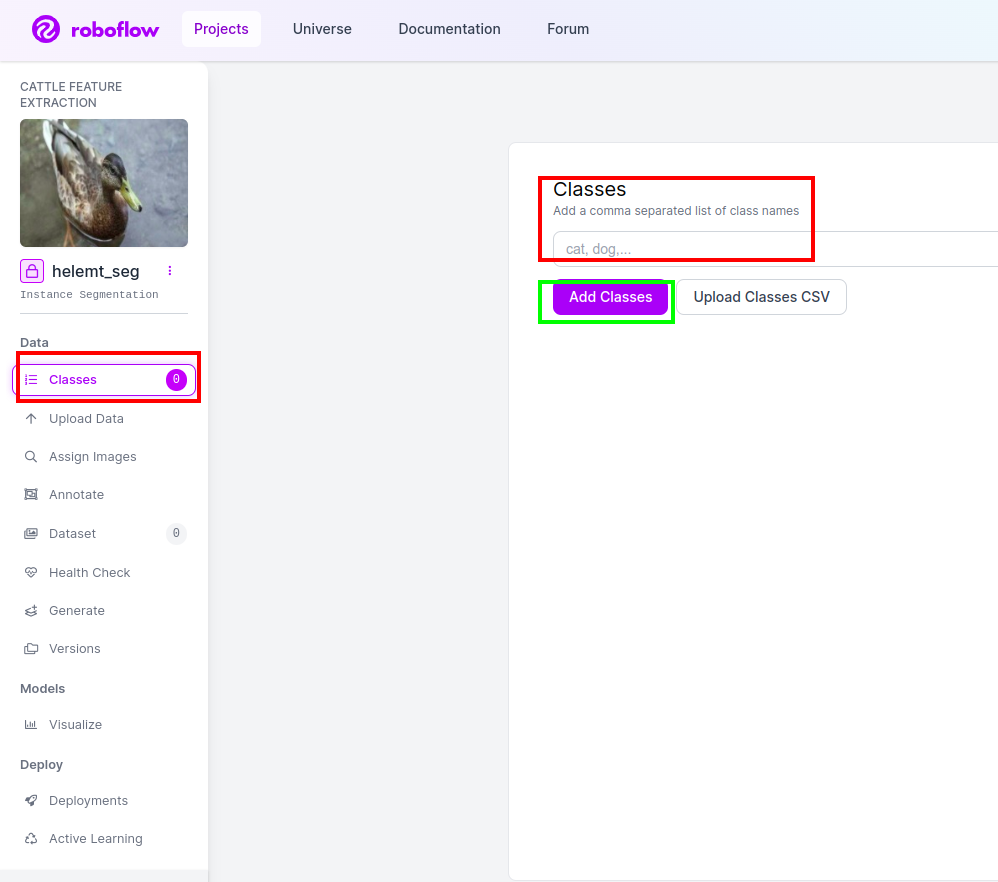
Steg 4: Lägg till klassnamnet
Gå sedan till klassdel på vänster sida av kryssa i den röda rutan. och skriv klassnamnet som Anka, efter att ha klickat på den gröna rutan.
Nu är vår installation klar och nästa del som anteckningsdelen är också enkel.
Steg 5: Starta anteckningsdelen
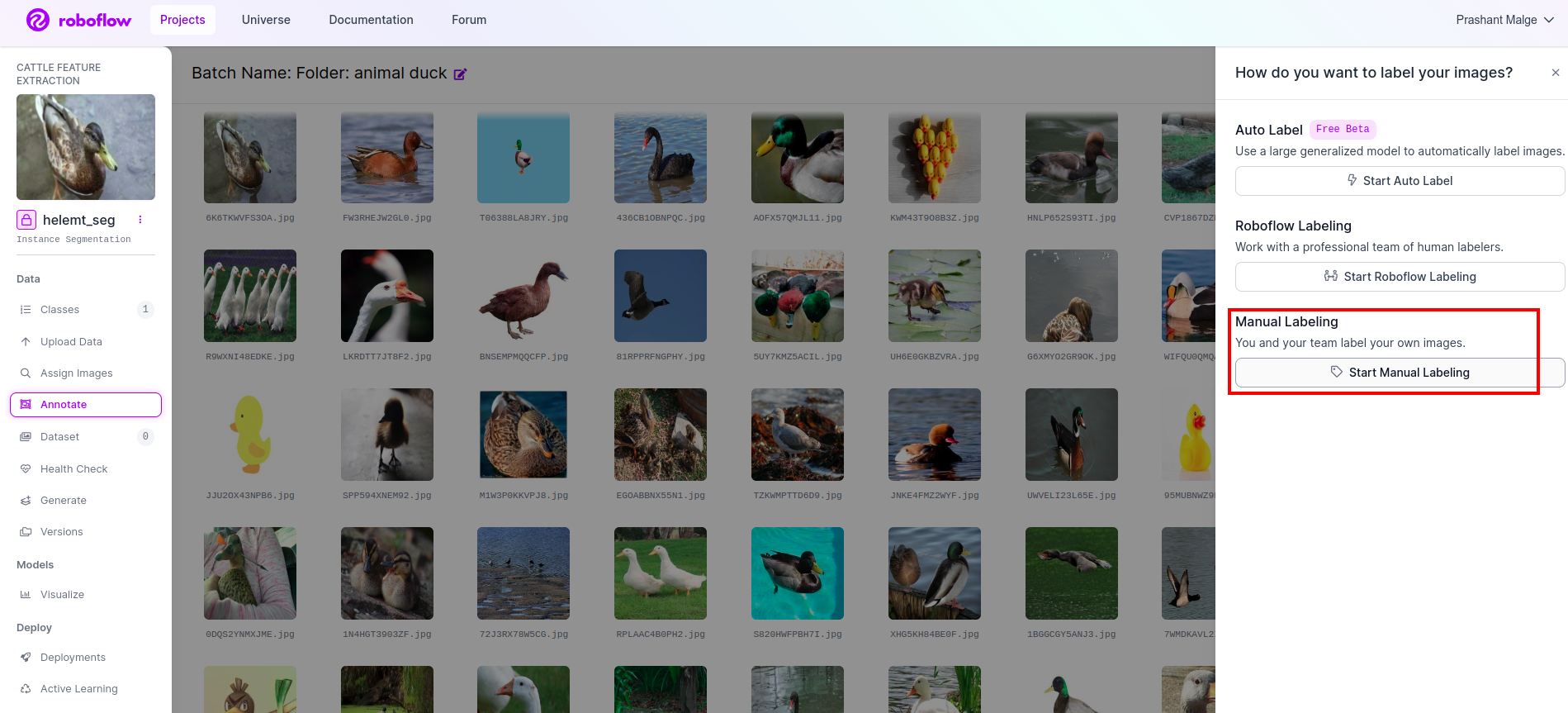
Gå till anteckningsalternativ Jag markerade i den röda rutan och klickade sedan på start annotaion-delen som jag markerade i den gröna rutan.
Klicka på den första bilden så kan du se detta användargränssnitt. När du har sett detta klickar du på alternativet för manuell anteckning.
Lägg sedan till ditt e-post-ID eller din lagkamrats namn så att du kan tilldela uppgiften.
Klicka på den första bilden så kan du se detta användargränssnitt. klicka här på den röda rutan så att du kan välja multipolynommodellen.
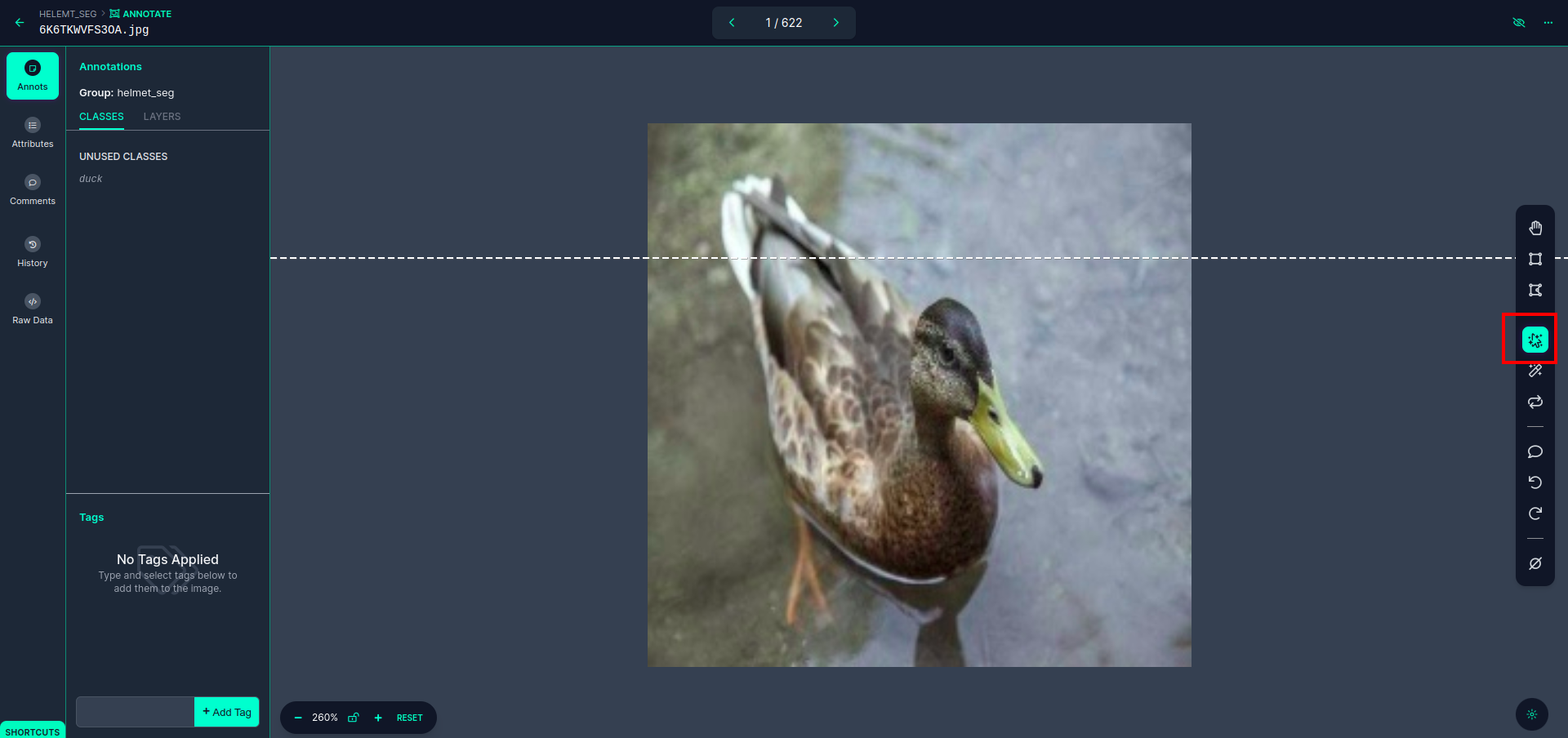
Efter att ha klickat på den röda rutan, välj standardmodellen och klicka på ankaobjektet. Detta segmenterar bilden automatiskt. Klicka sedan på nästa del och spara den. Du kommer då att se vänster sida markerad i en röd ruta, där du kan se klassnamnet.
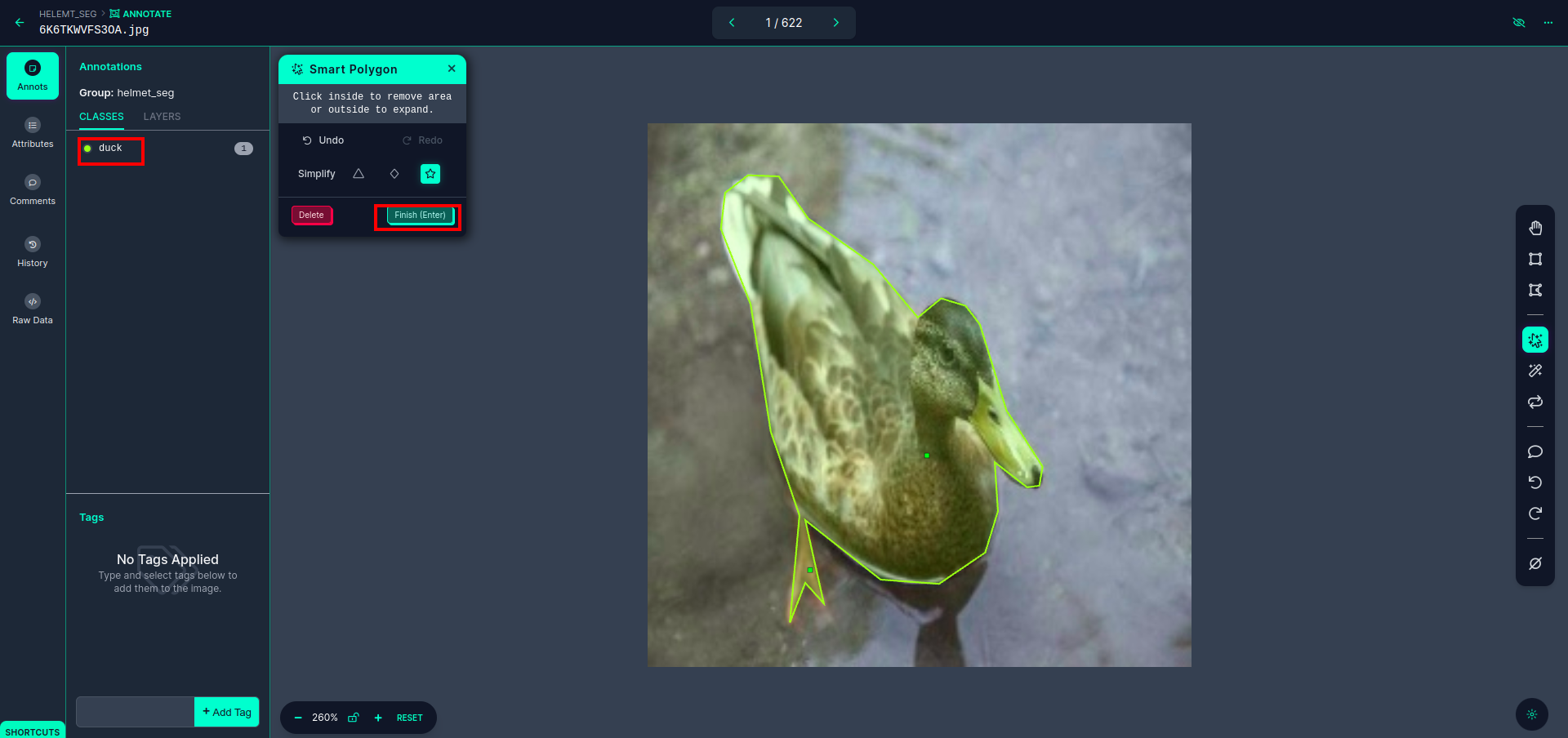
Klicka på spara&skriv in alternativ. kommentera alla bilder.
Lägg till bilderna för formatet YOLOv8. På höger sida ser du alternativet att lägga till bilder i kommentarsektionen. Här skapas två delar: en för kommenterade bilder och en för omärkta bilder.
- Klicka först på vänster sida "kommentera" alternativ då lägga till bilderna till datasetet.
- Klicka sedan på nästa "Lägg till bilder".
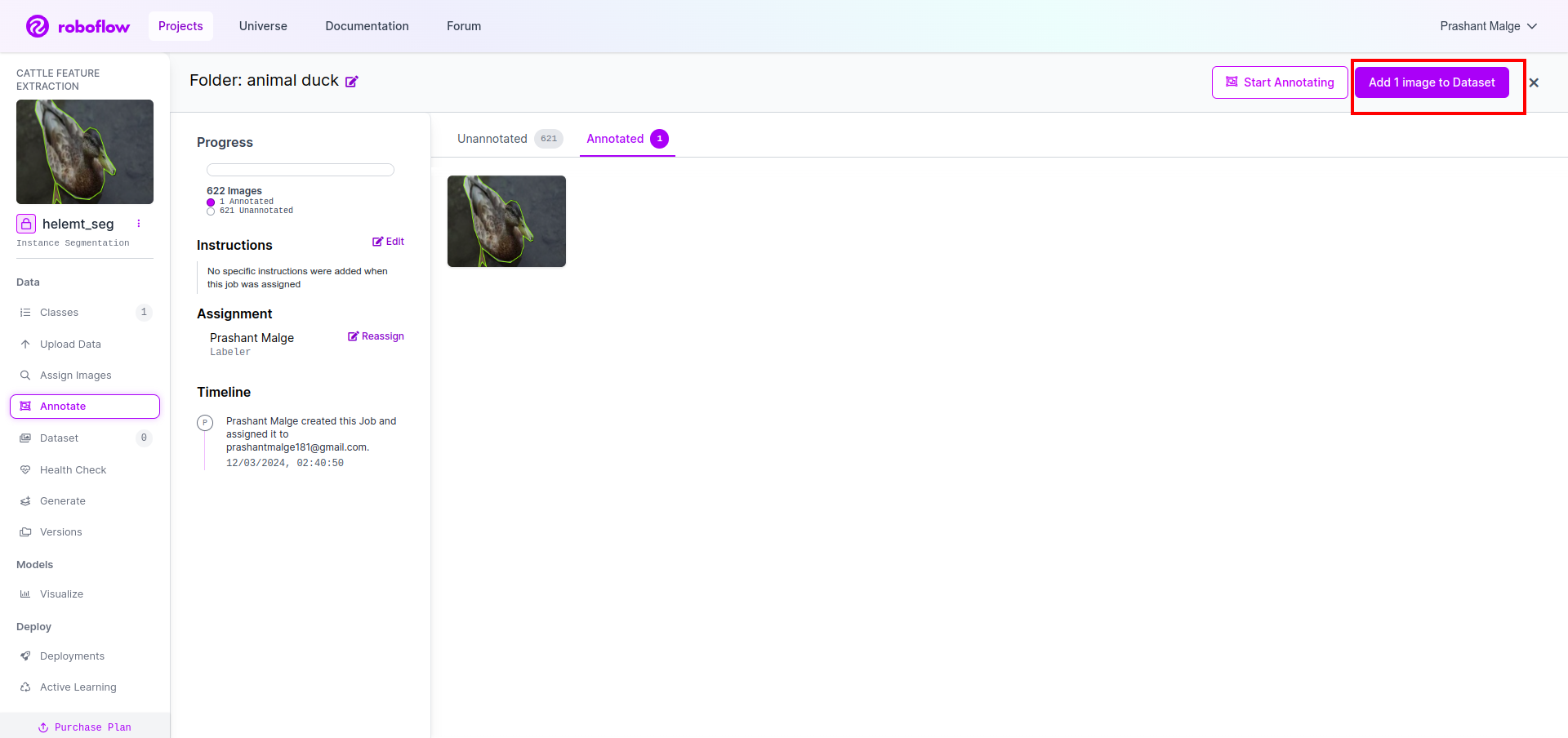
Nu sist, vi skapar datasetet så klicka på alternativet "Generera" på vänster sida, markera sedan alternativet och tryck på alternativet fortsätt.
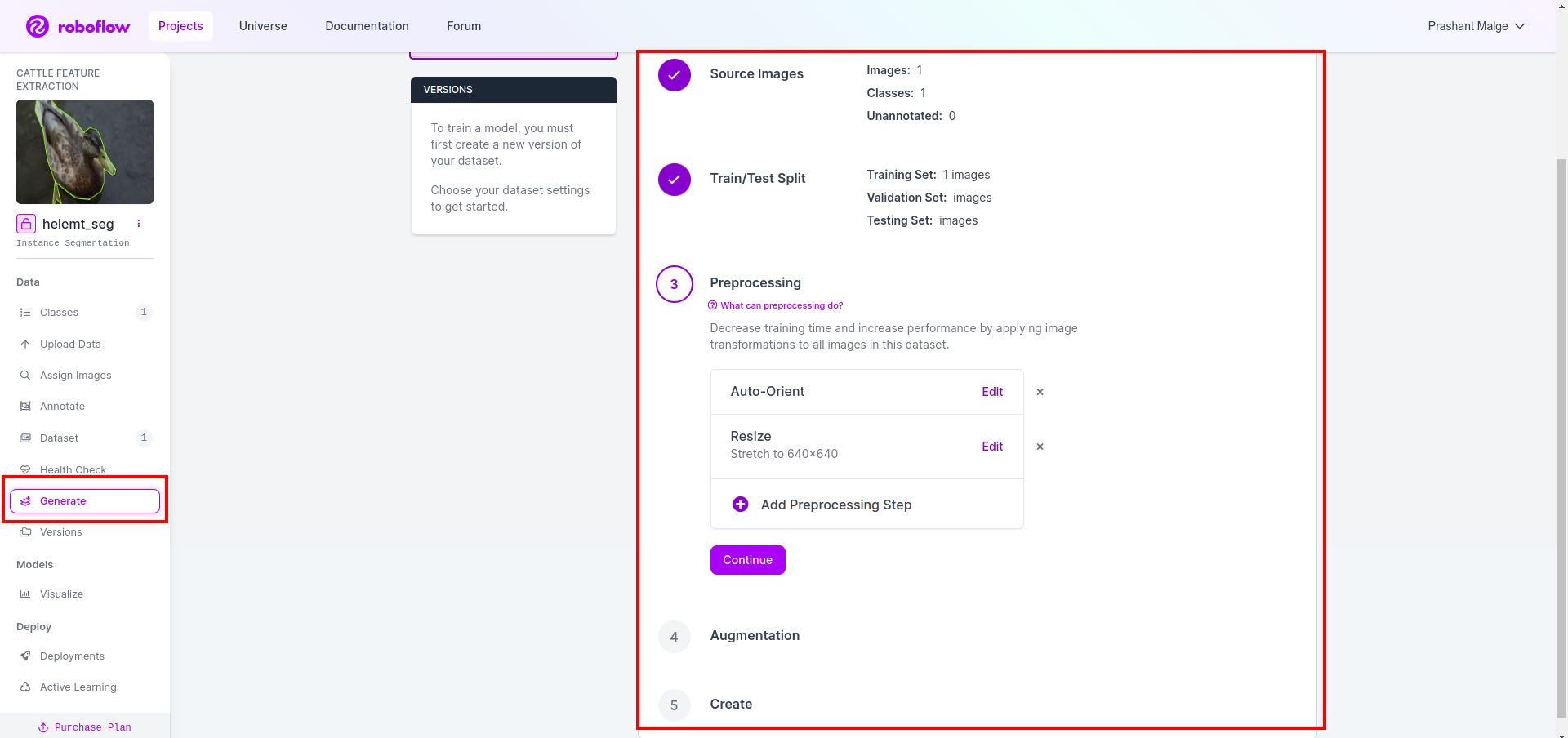
Sedan får du användargränssnittet för datauppdelningsalternativet här kan du kontrollera tåg-, test- och valmapparna som deras bilder delas automatiskt. och klicka på den röda rutan ovan Alternativet Exportera datauppsättning och ladda ner zip-filen. zip-filens mappstruktur är som...
root_file.zip
│
├── test
│ ├── Images
│ └── labels
│
├── train
│ ├── Images
│ └── labels
│
├── val
│ ├── Images
│ └── labels
│
├── data.yaml
└── Readme.roboflow.txt
Steg 6: Skriv skriptet för att träna bildsegmenteringsmodellen
I den här delen skapar du först Google Collab-filen med Drive och laddar sedan upp din datauppsättning. och flytta Google Drive med Google Collab.
1. Använd detta kommando för Montera Google Drive
from google.colab import drive
drive.mount('/content/gdrive')2. Definiera datakatalog Använd variabeln konstant.
DATA_DIR = '/content/drive/MyDrive/YoloV8/Data/'3. Installera det nödvändiga paketet, Installera ultralytics
!pip install ultralytics4. Importera biblioteken
import os
from ultralytics import YOLO5. Ladda förtränad YOLOv8 modell (här har vi olika modeller, kolla även den officiella dokumentationen där kan du se olika modeller)
model = YOLO('yolov8n-seg.pt')
# load a pretrained model (recommended for training)
6. Träna modellen
model.train(data='/content/drive/MyDrive/YoloV8/Data/data.yaml', epochs=2, imgsz=640)
# Update the path & and join this line together Nej kontrollera din enhet. Mappen modellnamn skapas och modellen sparas för den förutsägelse vi vill ha denna modell.
7. Förutsäg modellen
#Update the path
model_path = '/content/drive/MyDrive/YoloV8/Model/train2/weights/last.pt'
#Update the path
image_path = '/content/drive/MyDrive/YoloV8/Data/val/1be566eccffe9561.png'
img = cv2.imread(image_path)
H, W, _ = img.shape
model = YOLO(model_path)
results = model(img)
for result in results:
for j, mask in enumerate(result.masks.data):
mask = mask.numpy() * 255
mask = cv2.resize(mask, (W, H))
cv2.imwrite('./output.png', mask)Här kan du se att segmenteringsbilden är sparad.

Nu äntligen kan vi bygga modeller för både livedetektering och bildsegmentering.
Slutsats
I den här bloggen utforskar vi levande objektdetektering och bildsegmentering med YOLOv8. För livedetektering importerar vi en förtränad YOLOv8-modell och använder datorseendebiblioteket, OpenCV, för att öppna kameran och upptäcka objekt. Dessutom skapar vi en Streamlit-applikation för ett attraktivt användargränssnitt.
Därefter fördjupar vi oss i bildsegmentering med YOLOv8. Vi importerar en förtränad modell och utför överföringsinlärning på en anpassad datauppsättning. Dessförinnan utforskade vi Roboflow för datauppsättningsannotering, vilket gav ett lättanvänt alternativ till verktyg som LabelImg.
Slutligen förutspår vi en bild som innehåller en anka. Även om objektet i bilden verkar vara en fågel, anger vi klassnamnet som "anka” i demonstrationssyfte.
Key Takeaways
- Lär dig om objektdetekteringsmodeller som Faster R-CNN, SSD och den senaste YOLOv8.
- Förstå anteckningsverktyget Roboflow och dess roll i att skapa datauppsättningar för YOLOv8 segmenteringsmodeller.
- Utforska levande objektdetektering med OpenCV (cv2) och Supervision, vilket förbättrar praktiska färdigheter.
- Utbildning och implementering av en segmenteringsmodell med hjälp av YOLOv8, få praktisk erfarenhet.
Vanliga frågor
S. Objektdetektering innebär att identifiera och lokalisera flera objekt i en bild, vanligtvis genom att rita avgränsande rutor runt dem. Bildsegmentering, å andra sidan, delar upp en bild i segment eller regioner baserat på pixellikhet, vilket ger en mer detaljerad förståelse av objektgränser.
S. YOLOv8 förbättrar tidigare versioner genom att införliva framsteg inom nätverksarkitektur, träningstekniker och optimering. Det kan erbjuda bättre noggrannhet, hastighet och effektivitet jämfört med YOLOv3.
S. YOLOv8 kan användas för objektdetektering i realtid på inbäddade enheter, beroende på maskinvarukapacitet och modelloptimering. Det kan dock kräva optimeringar som modellbeskärning eller kvantisering för att uppnå realtidsprestanda på enheter med begränsade resurser.
S. Roboflow erbjuder intuitiva annoteringsverktyg, datauppsättningshanteringsfunktioner och stöd för olika annoteringsformat. Det effektiviserar anteckningsprocessen, möjliggör samarbete och ger versionskontroll, vilket gör det enklare att skapa och hantera datauppsättningar för datorseendeprojekt.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoData.Network Vertical Generative Ai. Styrka dig själv. Tillgång här.
- PlatoAiStream. Web3 Intelligence. Kunskap förstärkt. Tillgång här.
- Platoesg. Kol, CleanTech, Energi, Miljö, Sol, Avfallshantering. Tillgång här.
- PlatoHealth. Biotech och kliniska prövningar Intelligence. Tillgång här.
- Källa: https://www.analyticsvidhya.com/blog/2024/03/live-object-detection-and-image-segmentation-with-yolov8/

