I tillverkningens föränderliga landskap är den transformativa kraften hos AI och maskininlärning (ML) uppenbar, vilket driver en digital revolution som effektiviserar verksamheten och ökar produktiviteten. Men dessa framsteg introducerar unika utmaningar för företag som navigerar i datadrivna lösningar. Industriella anläggningar brottas med stora volymer ostrukturerad data, hämtad från sensorer, telemetrisystem och utrustning spridda över produktionslinjer. Realtidsdata är avgörande för applikationer som förutsägande underhåll och avvikelsedetektering, men att utveckla anpassade ML-modeller för varje industriellt användningsfall med sådana tidsseriedata kräver avsevärd tid och resurser från dataforskare, vilket hindrar en bred användning.
Generativ AI med hjälp av stora förtränade grundmodeller (FM) som t.ex Claude kan snabbt generera en mängd olika innehåll från konversationstext till datorkod baserat på enkla textuppmaningar, så kallade nollskottsuppmaning. Detta eliminerar behovet för datavetare att manuellt utveckla specifika ML-modeller för varje användningsfall, och demokratiserar därför AI-åtkomst, vilket gynnar även små tillverkare. Arbetare får produktivitet genom AI-genererade insikter, ingenjörer kan proaktivt upptäcka avvikelser, leverantörskedjechefer optimerar lager och fabriksledarskap fattar välgrundade, datadrivna beslut.
Icke desto mindre möter fristående FM begränsningar när det gäller att hantera komplexa industriella data med kontextstorleksbegränsningar (vanligtvis mindre än 200,000 XNUMX tokens), vilket innebär utmaningar. För att ta itu med detta kan du använda FM:s förmåga att generera kod som svar på naturliga språkfrågor (NLQ). Agenter gillar PandasAI kommer till spel, kör den här koden på högupplösta tidsseriedata och hanterar fel med hjälp av FM:er. PandasAI är ett Python-bibliotek som lägger till generativa AI-funktioner till pandor, det populära verktyget för dataanalys och manipulation.
Komplexa NLQ:er, såsom tidsseriedatabehandling, aggregering på flera nivåer och pivot- eller gemensamma tabelloperationer, kan dock ge inkonsekvent Python-skriptnoggrannhet med en noll-shot-prompt.
För att förbättra kodgenereringsnoggrannheten föreslår vi dynamisk konstruktion flerbildsuppmaningar för NLQs. Multi-shot prompt ger ytterligare sammanhang till FM genom att visa den flera exempel på önskade utgångar för liknande prompter, vilket ökar noggrannheten och konsekvensen. I det här inlägget hämtas prompter med flera bilder från en inbäddning som innehåller framgångsrik Python-kod som körs på en liknande datatyp (till exempel högupplöst tidsseriedata från Internet of Things-enheter). Den dynamiskt konstruerade multi-shot prompten ger det mest relevanta sammanhanget för FM, och ökar FM:s förmåga i avancerad matematisk beräkning, tidsseriedatabehandling och förståelse av dataakronymer. Detta förbättrade svar gör det lättare för företagsarbetare och operativa team att engagera sig med data och få insikter utan att kräva omfattande datavetenskapliga färdigheter.
Utöver analys av tidsseriedata visar sig FM:er värdefulla i olika industriella tillämpningar. Underhållsteam bedömer tillgångens hälsa, ta bilder för Amazon-erkännande-baserade funktionalitetssammanfattningar och anomali rotorsaksanalys med hjälp av intelligenta sökningar med Retrieval Augmented Generation (TRASA). För att förenkla dessa arbetsflöden har AWS introducerat Amazonas berggrund, vilket gör att du kan bygga och skala generativa AI-applikationer med toppmoderna förutbildade FM:er som Claude v2. Med Kunskapsbaser för Amazon Bedrock, kan du förenkla RAG-utvecklingsprocessen för att ge en mer exakt analys av anomali rotorsak för fabriksarbetare. Vårt inlägg visar upp en intelligent assistent för industriella användningsfall som drivs av Amazon Bedrock, som tar itu med NLQ-utmaningar, genererar delsammanfattningar från bilder och förbättrar FM-svar för utrustningsdiagnos genom RAG-metoden.
Lösningsöversikt
Följande diagram illustrerar lösningsarkitekturen.

Arbetsflödet inkluderar tre distinkta användningsfall:
Användningsfall 1: NLQ med tidsseriedata
Arbetsflödet för NLQ med tidsseriedata består av följande steg:
- Vi använder ett tillståndsövervakningssystem med ML-möjligheter för avvikelsedetektering, som t.ex Amazon Monitron, för att övervaka industriutrustningens hälsa. Amazon Monitron kan upptäcka potentiella utrustningsfel från utrustningens vibrations- och temperaturmätningar.
- Vi samlar in tidsseriedata genom bearbetning Amazon Monitron data genom Amazon Kinesis dataströmmar och Amazon Data Firehose, konvertera det till ett tabellformat CSV-format och spara det i en Amazon enkel lagringstjänst (Amazon S3) hink.
- Slutanvändaren kan börja chatta med sin tidsseriedata i Amazon S3 genom att skicka en fråga på naturligt språk till Streamlit-appen.
- Streamlit-appen vidarebefordrar användarfrågor till Amazon Bedrock Titan textinbäddningsmodell för att bädda in den här frågan och utför en likhetssökning inom en Amazon OpenSearch Service index, som innehåller tidigare NLQ:er och exempelkoder.
- Efter likhetssökningen infogas de vanligaste liknande exemplen, inklusive NLQ-frågor, dataschema och Python-koder, i en anpassad prompt.
- PandasAI skickar denna anpassade uppmaning till Amazon Bedrock Claude v2-modellen.
- Appen använder PandasAI-agenten för att interagera med Amazon Bedrock Claude v2-modellen och genererar Python-kod för Amazon Monitron-dataanalys och NLQ-svar.
- Efter att Amazon Bedrock Claude v2-modellen returnerar Python-koden, kör PandasAI Python-frågan på Amazon Monitron-data som laddats upp från appen, samlar in kodutdata och adresserar eventuella återförsök för misslyckade körningar.
- Streamlit-appen samlar in svaret via PandasAI och ger utdata till användarna. Om resultatet är tillfredsställande kan användaren markera det som användbart och spara NLQ- och Claude-genererad Python-kod i OpenSearch Service.
Användningsfall 2: Sammanfattning generering av felaktiga delar
Vårt användningsfall för sammanfattningsgenerering består av följande steg:
- Efter att användaren vet vilken industritillgång som uppvisar avvikande beteende, kan de ladda upp bilder av den felaktiga delen för att identifiera om det är något fysiskt fel på denna del enligt dess tekniska specifikation och drifttillstånd.
- Användaren kan använda Amazon Recognition DetectText API för att extrahera textdata från dessa bilder.
- Den extraherade textdatan ingår i prompten för Amazon Bedrock Claude v2-modellen, vilket gör att modellen kan generera en sammanfattning på 200 ord av den felaktiga delen. Användaren kan använda denna information för att utföra ytterligare inspektion av delen.
Användningsfall 3: Rotorsaksdiagnos
Vårt fall för grundorsaksdiagnos består av följande steg:
- Användaren skaffar företagsdata i olika dokumentformat (PDF, TXT och så vidare) relaterat till felaktiga tillgångar och laddar upp dem till en S3-hink.
- En kunskapsbas av dessa filer genereras i Amazon Bedrock med en Titan-textinbäddningsmodell och en standard OpenSearch Service-vektorbutik.
- Användaren ställer frågor relaterade till grundorsaksdiagnosen för felaktig utrustning. Svar genereras genom kunskapsbasen Amazon Bedrock med en RAG-strategi.
Förutsättningar
För att följa det här inlägget måste du uppfylla följande förutsättningar:
Distribuera lösningens infrastruktur
Utför följande steg för att ställa in dina lösningsresurser:
- Distribuera AWS molnformation mall opensearchsagemaker.yml, som skapar en samling och index för OpenSearch Service, Amazon SageMaker notebook-instans och S3-hink. Du kan namnge denna AWS CloudFormation-stack som:
genai-sagemaker. - Öppna SageMaker notebook-instansen i JupyterLab. Du hittar följande GitHub repo redan laddat ned på denna instans: låsa upp-potentialen-av-generativ-ai-in-industriell-verksamhet.
- Kör anteckningsboken från följande katalog i det här arkivet: låsa upp-potentialen-av-generativ-ai-in-industrial-operations/SagemakerNotebook/nlq-vector-rag-embedding.ipynb. Den här anteckningsboken laddar OpenSearch Service-index med SageMaker-anteckningsboken för att lagra nyckel-värdepar från befintliga 23 NLQ-exempel.
- Ladda upp dokument från datamappen assetpartdoc i GitHub-förvaret till S3-bucketen som listas i CloudFormations stackutgångar.

Därefter skapar du kunskapsbasen för dokumenten i Amazon S3.
- Välj på Amazon Bedrock-konsolen Kunskapsbas i navigeringsfönstret.
- Välja Skapa kunskapsbas.
- För Kunskapsbasens namn, ange ett namn.
- För Runtime-roll, Välj Skapa och använd en ny tjänstroll.
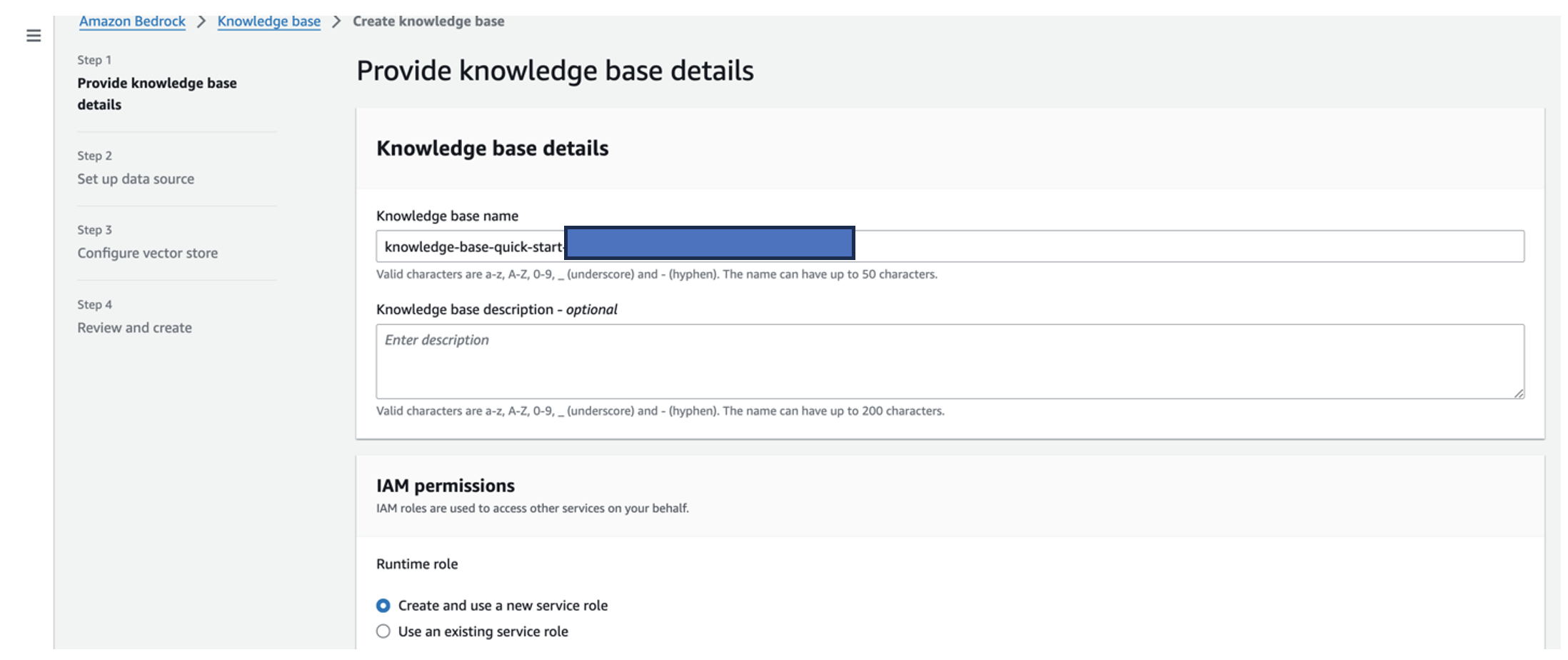
- För Datakällans namn, ange namnet på din datakälla.
- För S3 URI, ange S3-sökvägen för den bucket där du laddade upp grundorsaksdokumenten.
- Välja Nästa.
 Titan-inbäddningsmodellen väljs automatiskt.
Titan-inbäddningsmodellen väljs automatiskt. - Välja Skapa snabbt en ny vektorbutik.
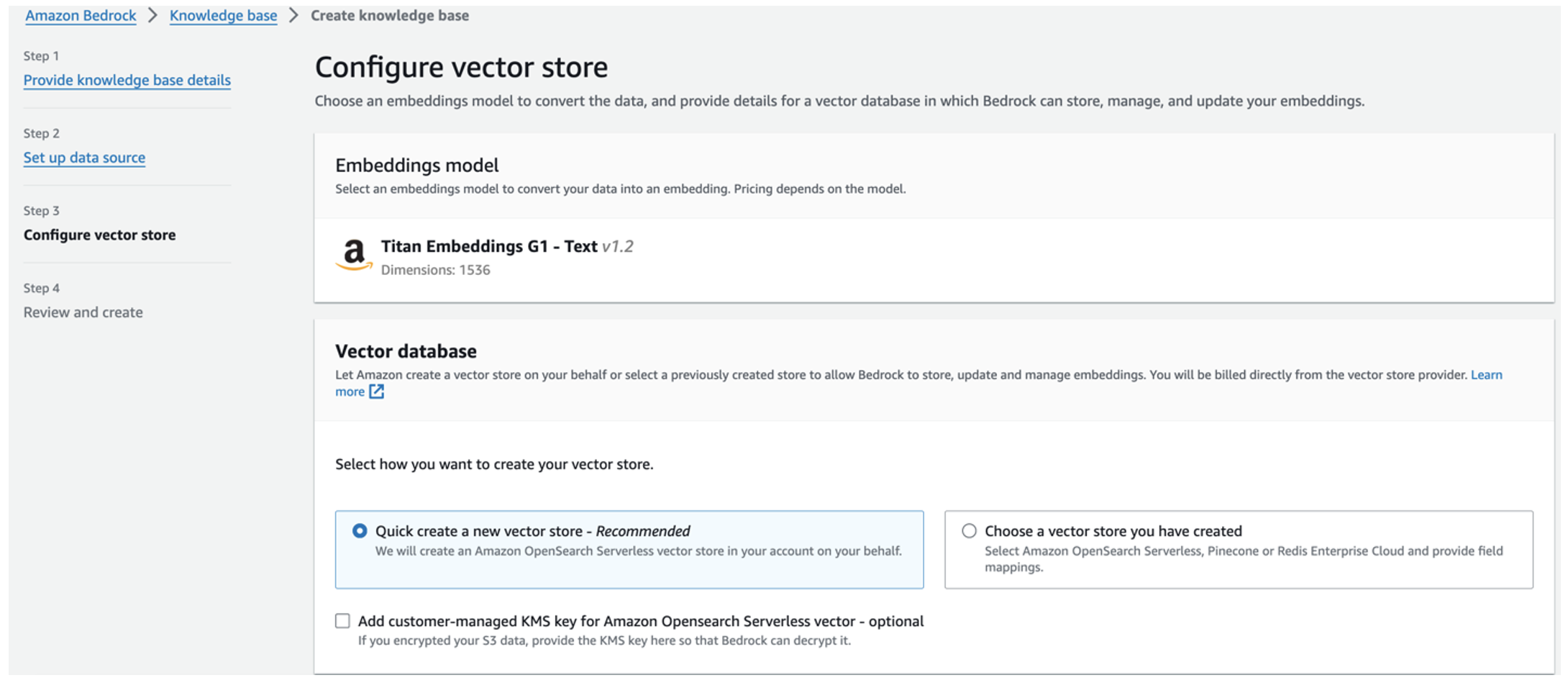
- Granska dina inställningar och skapa kunskapsbasen genom att välja Skapa kunskapsbas.
- När kunskapsbasen har skapats, välj Synkronisera för att synkronisera S3-bucket med kunskapsbasen.

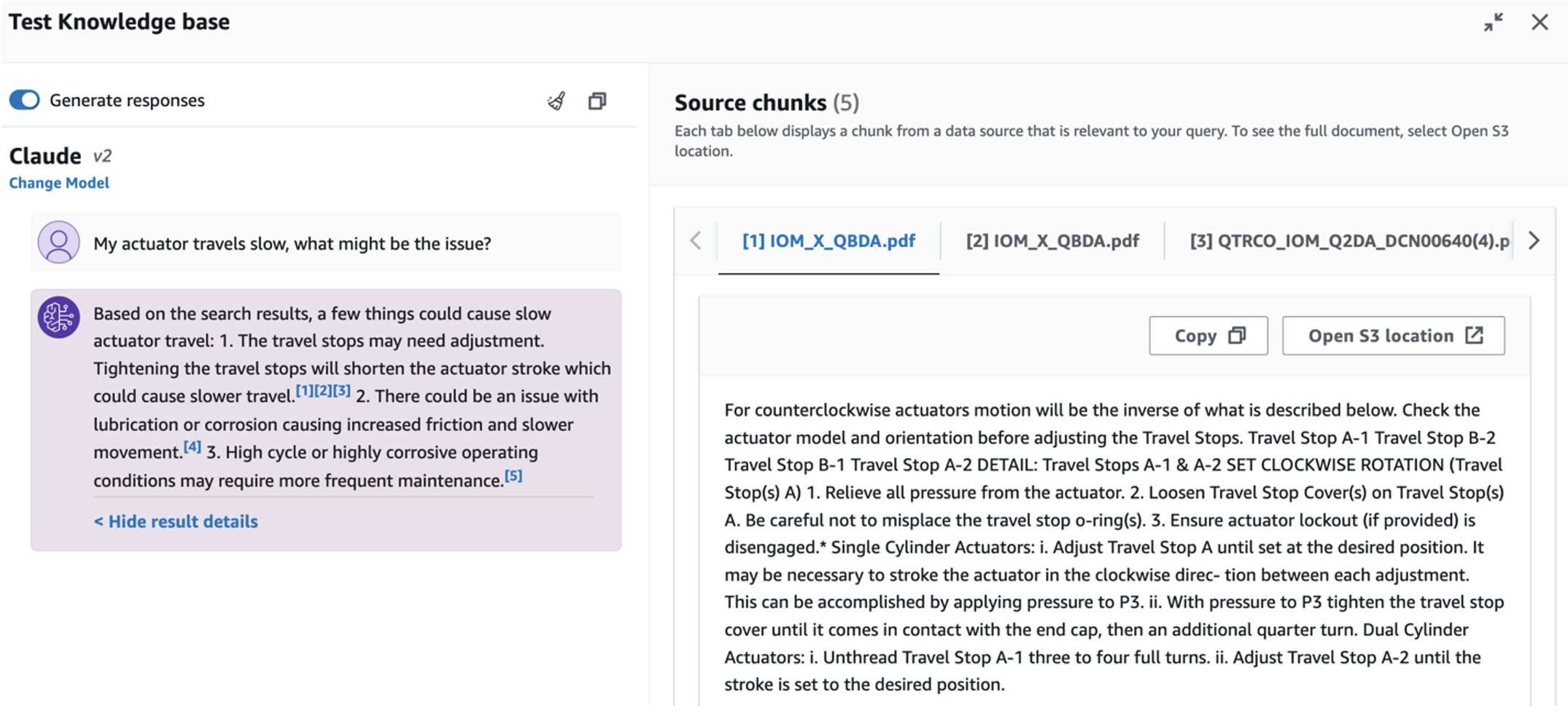
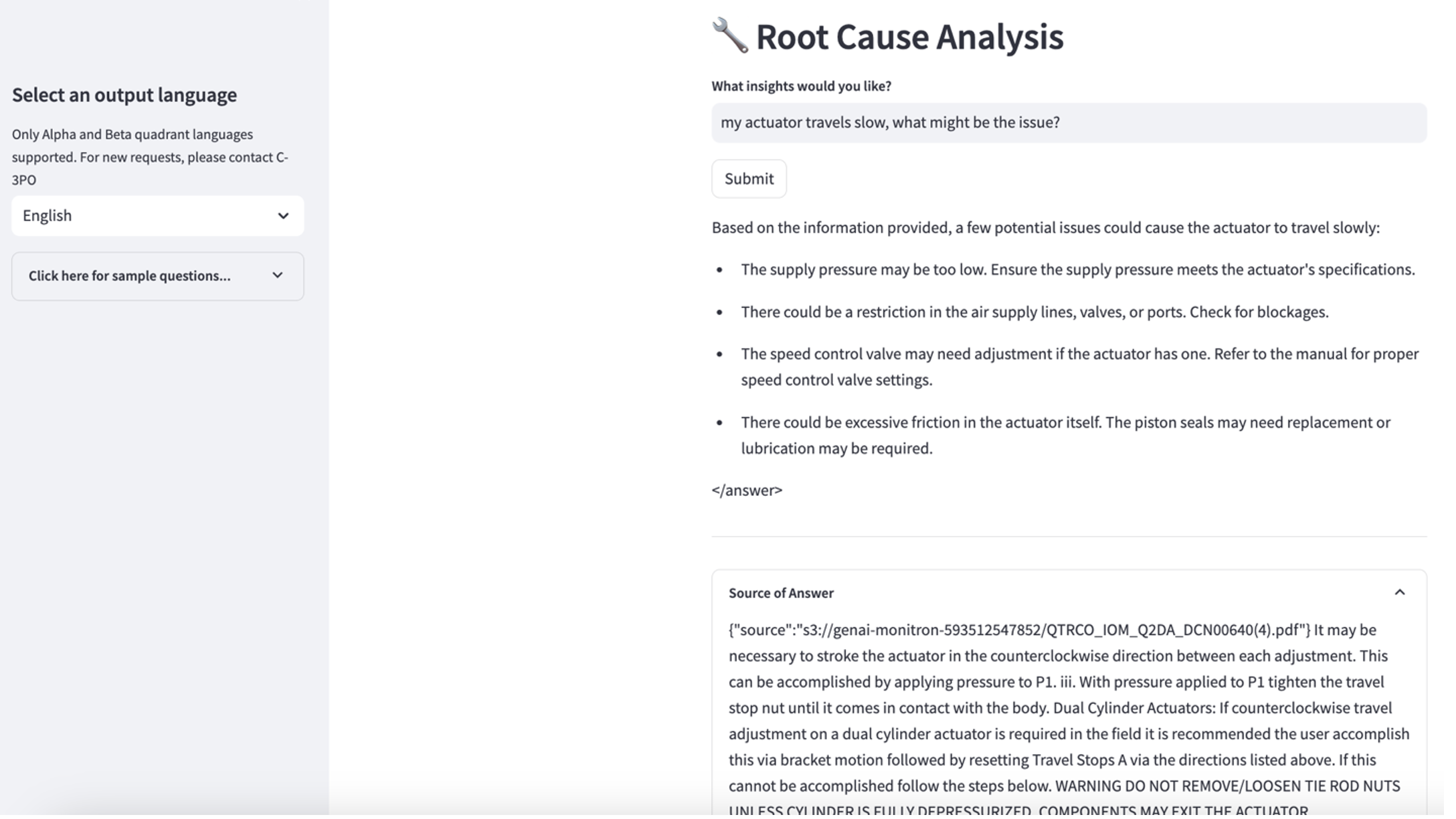
- När du har ställt in kunskapsbasen kan du testa RAG-metoden för rotorsaksdiagnos genom att ställa frågor som "Mitt ställdon går långsamt, vad kan vara problemet?"
Nästa steg är att distribuera appen med de nödvändiga bibliotekspaketen på antingen din PC eller en EC2-instans (Ubuntu Server 22.04 LTS).
- Ställ in dina AWS-uppgifter med AWS CLI på din lokala PC. För enkelhetens skull kan du använda samma administratörsroll som du använde för att distribuera CloudFormation-stacken. Om du använder Amazon EC2, koppla en lämplig IAM-roll till instansen.
- klon GitHub repo:
- Ändra katalogen till
unlocking-the-potential-of-generative-ai-in-industrial-operations/srcoch springasetup.shskript i den här mappen för att installera de nödvändiga paketen, inklusive LangChain och PandasAI:cd unlocking-the-potential-of-generative-ai-in-industrial-operations/src chmod +x ./setup.sh ./setup.sh - Kör Streamlit-appen med följande kommando:
source monitron-genai/bin/activate python3 -m streamlit run app_bedrock.py <REPLACE WITH YOUR BEDROCK KNOWLEDGEBASE ARN>
Tillhandahåll OpenSearch Service-samlingen ARN som du skapade i Amazon Bedrock från föregående steg.
Chatta med din tillgångshälsoassistent
När du har slutfört end-to-end-distributionen kan du komma åt appen via localhost på port 8501, som öppnar ett webbläsarfönster med webbgränssnittet. Om du distribuerade appen på en EC2-instans, tillåt port 8501-åtkomst via säkerhetsgruppens inkommande regel. Du kan navigera till olika flikar för olika användningsfall.
Utforska användningsfall 1
För att utforska det första användningsfallet, välj Datainsikt och diagram. Börja med att ladda upp din tidsseriedata. Om du inte har en befintlig tidsseriedatafil att använda kan du ladda upp följande exempel på CSV-fil med anonyma Amazon Monitron-projektdata. Om du redan har ett Amazon Monitron-projekt, se Generera praktiska insikter för prediktiv underhållshantering med Amazon Monitron och Amazon Kinesis för att strömma din Amazon Monitron-data till Amazon S3 och använda din data med denna applikation.
När uppladdningen är klar anger du en fråga för att initiera en konversation med dina data. Det vänstra sidofältet erbjuder en rad exempelfrågor för din bekvämlighet. Följande skärmdumpar illustrerar svaret och Python-koden som genereras av FM när man matar in en fråga som "Berätta för mig det unika antalet sensorer för varje plats som visas som varning respektive larm?" (en fråga på svår nivå) eller "Kan du beräkna tidslängden i dagar för varje sensor som visas med onormal vibrationssignal för sensorer som visas som INTE friska?" (en fråga på utmaningsnivå). Appen kommer att svara på din fråga och kommer också att visa Python-skriptet för dataanalys som den utförde för att generera sådana resultat.


Om du är nöjd med svaret kan du markera det som Hjälpsam, sparar den NLQ och Claude-genererade Python-koden till ett OpenSearch Service-index.

Utforska användningsfall 2
För att utforska det andra användningsfallet, välj Sammanfattning av tagna bilder fliken i Streamlit-appen. Du kan ladda upp en bild av din industritillgång och applikationen genererar en sammanfattning på 200 ord av dess tekniska specifikationer och drifttillstånd baserat på bildinformationen. Följande skärmdump visar sammanfattningen som genereras från en bild av en remmotordrift. För att testa denna funktion, om du saknar en lämplig bild, kan du använda följande exempelbild.
Hydraulisk hissmotoretikett” av Clarence Risher är licensierad under CC BY-SA 2.0.

Utforska användningsfall 3
För att utforska det tredje användningsfallet, välj Rotorsaksdiagnos flik. Ange en fråga relaterad till din trasiga industriella tillgång, till exempel "Mitt ställdon går långsamt, vad kan vara problemet?" Som visas i följande skärmdump, levererar applikationen ett svar med källdokumentutdraget som används för att generera svaret.
Användningsfall 1: Designdetaljer
I det här avsnittet diskuterar vi designdetaljerna för applikationsarbetsflödet för det första användningsfallet.
Anpassad snabb byggnad
Användarens naturliga språkfråga kommer med olika svåra nivåer: lätt, svårt och utmaning.
Enkla frågor kan inkludera följande förfrågningar:
- Välj unika värden
- Räkna totalt antal
- Sortera värden
För dessa frågor kan PandasAI interagera direkt med FM för att generera Python-skript för bearbetning.
Svåra frågor kräver grundläggande aggregeringsoperation eller tidsserieanalys, som följande:
- Välj värde först och gruppera resultaten hierarkiskt
- Utför statistik efter första rekordval
- Antal tidsstämplar (till exempel min och max)
För svåra frågor hjälper en snabb mall med detaljerade steg-för-steg-instruktioner FM:er att ge korrekta svar.
Frågor på utmaningsnivå kräver avancerad matematisk beräkning och tidsseriebearbetning, till exempel följande:
- Beräkna anomaliens varaktighet för varje sensor
- Beräkna anomalisensorer för platsen på månadsbasis
- Jämför sensoravläsningar under normal drift och onormala förhållanden
För dessa frågor kan du använda flera bilder i en anpassad prompt för att förbättra svarsnoggrannheten. Sådana multi-shots visar exempel på avancerad tidsseriebearbetning och matematisk beräkning, och kommer att ge sammanhang för FM att göra relevanta slutsatser om liknande analys. Att dynamiskt infoga de mest relevanta exemplen från en NLQ-frågebank i prompten kan vara en utmaning. En lösning är att konstruera inbäddningar från befintliga NLQ frågeprov och spara dessa inbäddningar i en vektorbutik som OpenSearch Service. När en fråga skickas till Streamlit-appen kommer frågan vektoriseras av BedrockInbäddningar. De N mest relevanta inbäddningarna för den frågan hämtas med hjälp av opensearch_vector_search.similarity_search och infogas i promptmallen som en multi-shot prompt.
Följande diagram illustrerar detta arbetsflöde.
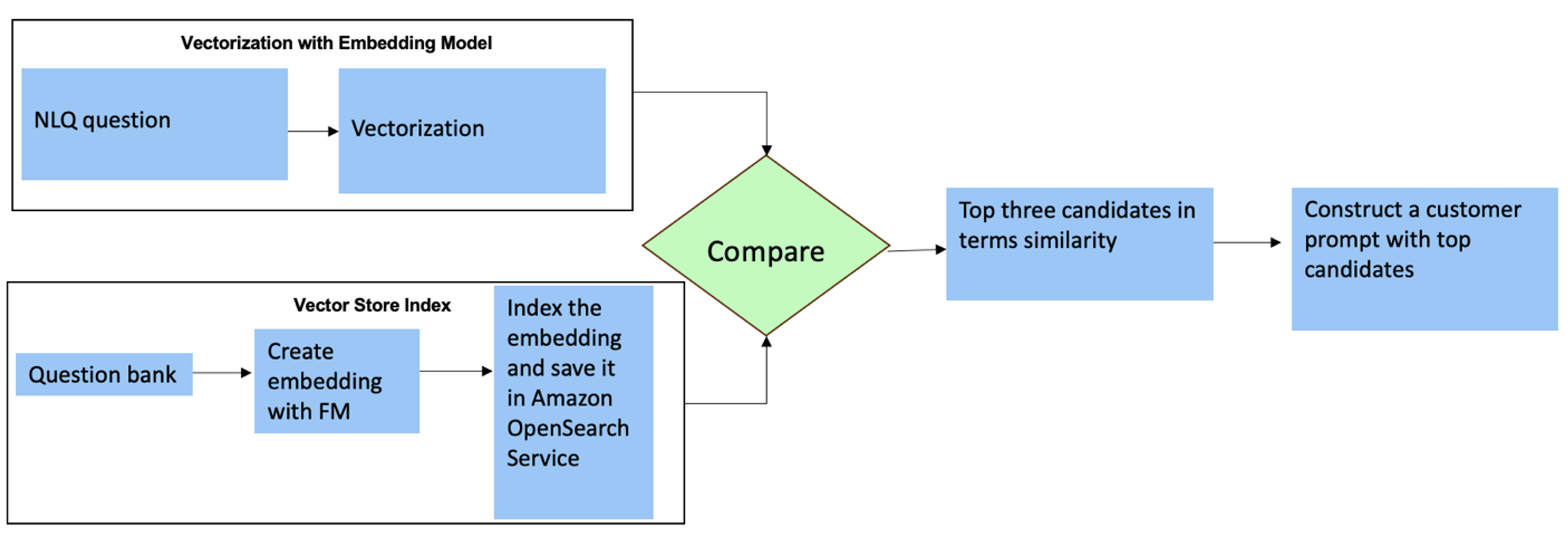
Inbäddningsskiktet är konstruerat med hjälp av tre nyckelverktyg:
- Inbäddningsmodell – Vi använder Amazon Titan Embeddings tillgängliga via Amazon Bedrock (amazon.titan-embed-text-v1) för att generera numeriska representationer av textdokument.
- Vektor butik – För vår vektorbutik använder vi OpenSearch Service via LangChain-ramverket, vilket effektiviserar lagringen av inbäddningar som genereras från NLQ-exempel i den här anteckningsboken.
- index – OpenSearch Service-indexet spelar en avgörande roll när det gäller att jämföra inbäddningar av indata med dokumentinbäddningar och underlättar hämtning av relevanta dokument. Eftersom Python-exempelkoderna sparades som en JSON-fil, indexerades de i OpenSearch Service som vektorer via en OpenSearchVevtorSearch.fromtexts API-samtal.
Kontinuerlig insamling av mänskligt granskade exempel via Streamlit
I början av apputvecklingen började vi med endast 23 sparade exempel i OpenSearch Service-index som inbäddningar. När appen går live i fält börjar användarna mata in sina NLQ via appen. Men på grund av de begränsade exemplen som finns i mallen, kanske vissa NLQ inte hittar liknande uppmaningar. För att kontinuerligt berika dessa inbäddningar och erbjuda mer relevanta användarmeddelanden kan du använda Streamlit-appen för att samla in mänskliga granskade exempel.
Inom appen tjänar följande funktion detta syfte. När slutanvändare tycker att resultatet är användbart och väljer Hjälpsam, applikationen följer dessa steg:
- Använd återuppringningsmetoden från PandasAI för att samla in Python-skriptet.
- Formatera om Python-skriptet, inmatningsfrågan och CSV-metadata till en sträng.
- Kontrollera om detta NLQ-exempel redan finns i det aktuella OpenSearch Service-indexet med hjälp av opensearch_vector_search.similarity_search_with_score.
- Om det inte finns något liknande exempel läggs denna NLQ till i OpenSearch Service-index med hjälp av opensearch_vector_search.add_texts.
I händelse av att en användare väljer Inte hjälpsam, ingen åtgärd vidtas. Denna iterativa process säkerställer att systemet ständigt förbättras genom att ta med exempel från användare.
def addtext_opensearch(input_question, generated_chat_code, df_column_metadata, opensearch_vector_search,similarity_threshold,kexamples, indexname):
#######build the input_question and generated code the same format as existing opensearch index##########
reconstructed_json = {}
reconstructed_json["question"]=input_question
reconstructed_json["python_code"]=str(generated_chat_code)
reconstructed_json["column_info"]=df_column_metadata
json_str = ''
for key,value in reconstructed_json.items():
json_str += key + ':' + value
reconstructed_raw_text =[]
reconstructed_raw_text.append(json_str)
results = opensearch_vector_search.similarity_search_with_score(str(reconstructed_raw_text[0]), k=kexamples) # our search query # return 3 most relevant docs
if (dumpd(results[0][1])<similarity_threshold): ###No similar embedding exist, then add text to embedding
response = opensearch_vector_search.add_texts(texts=reconstructed_raw_text, engine="faiss", index_name=indexname)
else:
response = "A similar embedding is already exist, no action."
return response
Genom att införliva mänsklig granskning, ökar mängden exempel i OpenSearch Service som är tillgängliga för snabb inbäddning i takt med att appen används. Denna utökade inbäddningsdatauppsättning resulterar i förbättrad söknoggrannhet över tiden. Närmare bestämt, för utmanande NLQ:er, når FM:s svarsnoggrannhet ungefär 90 % när man dynamiskt infogar liknande exempel för att konstruera anpassade uppmaningar för varje NLQ-fråga. Detta representerar en anmärkningsvärd ökning på 28 % jämfört med scenarier utan flerbildsuppmaningar.
Användningsfall 2: Designdetaljer
På Streamlit-appen Sammanfattning av tagna bilder fliken kan du ladda upp en bildfil direkt. Detta initierar Amazon Rekognition API (detektera_text API), extraherar text från bildetiketten som beskriver maskinspecifikationer. Därefter skickas den extraherade textdatan till Amazon Bedrock Claude-modellen som sammanhanget för en prompt, vilket resulterar i en sammanfattning på 200 ord.
Ur ett användarupplevelseperspektiv är det av största vikt att aktivera strömningsfunktioner för en textsammanfattningsuppgift, vilket gör det möjligt för användare att läsa den FM-genererade sammanfattningen i mindre bitar istället för att vänta på hela resultatet. Amazon Bedrock underlättar streaming via sitt API (bedrock_runtime.invoke_model_with_response_stream).
Användningsfall 3: Designdetaljer
I det här scenariot har vi utvecklat en chatbot-applikation fokuserad på rotorsaksanalys, med RAG-metoden. Denna chatbot hämtar från flera dokument relaterade till lagerutrustning för att underlätta analys av rotorsak. Denna RAG-baserade rotorsaksanalyschattbot använder kunskapsbaser för att generera vektortextrepresentationer eller inbäddningar. Kunskapsbaser för Amazon Bedrock är en helt hanterad funktion som hjälper dig att implementera hela RAG-arbetsflödet, från inmatning till hämtning och snabb ökning, utan att behöva bygga anpassade integrationer till datakällor eller hantera dataflöden och RAG-implementeringsdetaljer.
När du är nöjd med kunskapsbassvaret från Amazon Bedrock kan du integrera grundorsaksvaret från kunskapsbasen till Streamlit-appen.
Städa upp
För att spara kostnader, ta bort resurserna du skapade i det här inlägget:
- Ta bort kunskapsbasen från Amazon Bedrock.
- Ta bort OpenSearch Service-index.
- Ta bort genai-sagemaker CloudFormation-stacken.
- Stoppa EC2-instansen om du använde en EC2-instans för att köra Streamlit-appen.
Slutsats
Generativa AI-tillämpningar har redan förändrat olika affärsprocesser, vilket förbättrat arbetarnas produktivitet och färdigheter. Emellertid har FMs begränsningar i hanteringen av tidsseriedataanalys hindrat deras fulla utnyttjande av industriella kunder. Denna begränsning har hindrat tillämpningen av generativ AI på den dominerande datatypen som behandlas dagligen.
I det här inlägget introducerade vi en generativ AI-applikationslösning utformad för att lindra denna utmaning för industriella användare. Denna applikation använder en öppen källkodsagent, PandasAI, för att stärka en FM:s förmåga att analysera tidsserier. Istället för att skicka tidsseriedata direkt till FM:er använder appen PandasAI för att generera Python-kod för analys av ostrukturerad tidsseriedata. För att förbättra noggrannheten i Python-kodgenereringen har ett anpassat arbetsflöde för promptgenerering med mänsklig revision implementerats.
Med insikter i deras tillgångshälsa kan industriarbetare till fullo utnyttja potentialen hos generativ AI i olika användningsfall, inklusive diagnostik av grundorsak och planering av byte av delar. Med Knowledge Bases for Amazon Bedrock är RAG-lösningen enkel för utvecklare att bygga och hantera.
Banan för företagsdatahantering och drift går otvetydigt mot djupare integration med generativ AI för omfattande insikter om operativ hälsa. Denna förändring, med Amazon Bedrock i spetsen, förstärks avsevärt av den växande robustheten och potentialen hos LLM:er som Amazonas berggrund Claude 3 för att ytterligare lyfta lösningarna. För att lära dig mer, besök konsultera Amazon Bedrock-dokumentation, och komma igång med Amazon Bedrock workshop.
Om författarna
 Julia Hu är Sr. AI/ML Solutions Architect på Amazon Web Services. Hon är specialiserad på generativ AI, tillämpad datavetenskap och IoT-arkitektur. För närvarande är hon en del av Amazon Q-teamet och en aktiv medlem/mentor i Machine Learning Technical Field Community. Hon arbetar med kunder, allt från nystartade företag till företag, för att utveckla AWSome generativa AI-lösningar. Hon brinner särskilt för att utnyttja stora språkmodeller för avancerad dataanalys och utforska praktiska tillämpningar som hanterar verkliga utmaningar.
Julia Hu är Sr. AI/ML Solutions Architect på Amazon Web Services. Hon är specialiserad på generativ AI, tillämpad datavetenskap och IoT-arkitektur. För närvarande är hon en del av Amazon Q-teamet och en aktiv medlem/mentor i Machine Learning Technical Field Community. Hon arbetar med kunder, allt från nystartade företag till företag, för att utveckla AWSome generativa AI-lösningar. Hon brinner särskilt för att utnyttja stora språkmodeller för avancerad dataanalys och utforska praktiska tillämpningar som hanterar verkliga utmaningar.
 Sudeesh Sasidharan är Senior Solutions Architect på AWS, inom energiteamet. Sudeesh älskar att experimentera med ny teknik och bygga innovativa lösningar som löser komplexa affärsutmaningar. När han inte designar lösningar eller pysslar med den senaste tekniken kan du hitta honom på tennisbanan som arbetar med sin backhand.
Sudeesh Sasidharan är Senior Solutions Architect på AWS, inom energiteamet. Sudeesh älskar att experimentera med ny teknik och bygga innovativa lösningar som löser komplexa affärsutmaningar. När han inte designar lösningar eller pysslar med den senaste tekniken kan du hitta honom på tennisbanan som arbetar med sin backhand.
 Neil Desai är en teknikchef med över 20 års erfarenhet av artificiell intelligens (AI), datavetenskap, mjukvaruteknik och företagsarkitektur. På AWS leder han ett team av världsomspännande AI-tjänster specialistlösningsarkitekter som hjälper kunder att bygga innovativa generativa AI-drivna lösningar, dela bästa praxis med kunder och driva produktplan. I sina tidigare roller på Vestas, Honeywell och Quest Diagnostics har Neil haft ledande roller i att utveckla och lansera innovativa produkter och tjänster som har hjälpt företag att förbättra sin verksamhet, minska kostnaderna och öka intäkterna. Han brinner för att använda teknik för att lösa verkliga problem och är en strategisk tänkare med en bevisad meritlista av framgång.
Neil Desai är en teknikchef med över 20 års erfarenhet av artificiell intelligens (AI), datavetenskap, mjukvaruteknik och företagsarkitektur. På AWS leder han ett team av världsomspännande AI-tjänster specialistlösningsarkitekter som hjälper kunder att bygga innovativa generativa AI-drivna lösningar, dela bästa praxis med kunder och driva produktplan. I sina tidigare roller på Vestas, Honeywell och Quest Diagnostics har Neil haft ledande roller i att utveckla och lansera innovativa produkter och tjänster som har hjälpt företag att förbättra sin verksamhet, minska kostnaderna och öka intäkterna. Han brinner för att använda teknik för att lösa verkliga problem och är en strategisk tänkare med en bevisad meritlista av framgång.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoData.Network Vertical Generative Ai. Styrka dig själv. Tillgång här.
- PlatoAiStream. Web3 Intelligence. Kunskap förstärkt. Tillgång här.
- Platoesg. Kol, CleanTech, Energi, Miljö, Sol, Avfallshantering. Tillgång här.
- PlatoHealth. Biotech och kliniska prövningar Intelligence. Tillgång här.
- Källa: https://aws.amazon.com/blogs/machine-learning/unlock-the-potential-of-generative-ai-in-industrial-operations/

