Opensearch är en skalbar, flexibel och utökningsbar mjukvarusvit med öppen källkod för sökning, analys, säkerhetsövervakning och observerbarhetsapplikationer, licensierad under Apache 2.0-licensen. Amazon OpenSearch Service är en helt hanterad tjänst som gör det enkelt att distribuera, skala och driva OpenSearch i AWS-molnet.
OpenSearch använder ett probabilistiskt rankningsramverk som kallas BM-25 för att beräkna relevanspoäng. Om ett distinkt nyckelord förekommer oftare i ett dokument, tilldelar BM-25 ett högre relevanspoäng till det dokumentet. Detta ramverk tar dock inte hänsyn till användarbeteende som klick- eller köpdata, vilket ytterligare kan förbättra relevansen för enskilda användare.
Att förbättra sökfunktionaliteten är en integrerad aspekt av att förbättra den övergripande användarupplevelsen och engagemanget på en webbplats eller applikation. Söktrafik anses ha hög avsikt eftersom användare aktivt söker efter ett visst objekt, och de har visat sig konvertera upp till två gånger fler än besökare som inte söker på webbplatsen i genomsnitt. Genom att använda användarinteraktionsdata som klick, gilla-markeringar och köp kan företag förbättra sökrelevansen för att dra fördel av denna trafik och minska antalet användare som överger sina sessioner på grund av svårigheter att hitta de önskade föremålen. Genom att förfina kvaliteten på sökresultaten kan företag avsevärt förbättra sitt kundengagemang, nöjdhet och lojalitet, samt öka sin omvandlingsfrekvens, vilket i slutändan leder till större lönsamhet och framgång.
Amazon Anpassa låter dig lägga till sofistikerade personaliseringsmöjligheter till dina applikationer genom att använda samma maskininlärningsteknik (ML) som används på Amazon.com i över 20 år. Ingen ML-expertis krävs.
Amazon Personalize stöder automatisk justering av rekommendationer baserat på kontextuell information om din användare, såsom enhetstyp, plats, tid på dagen eller annan information du tillhandahåller. Du förser Amazon Personalize med historisk data om dina användare och deras interaktioner inom din applikation, såsom köphistorik, betyg och gilla-markeringar. Du kan lägga till data till Amazon Personalize i bulk genom att importera stora historiska datamängder på en gång från en Amazon enkel lagringstjänst (Amazon S3) CSV-fil, med ett format som krävs av Amazon Personalize. Du kan också lägga till data stegvis genom att importera poster med Amazon Personalize-konsolen eller API. Efter att din historiska data har importerats kan du fortsätta att tillhandahålla ny data i realtid genom att skicka användarinteraktionshändelser. Baserat på det användningsfall du vill ta itu med, såsom produktrekommendationer, väljer du ett förbyggt recept som är optimerat för det målet. Amazon Personalize analyserar din data och tränar en anpassad ML-modell baserat på parametrarna i receptet för att generera personliga rekommendationer optimerade för dina användare och applikation. Efter att modellen har tränats kan du generera personliga rekommendationer i realtid för dina användare.
Med den nyligen lanserade Amazon Personalized Search Plugin för Amazon OpenSearch Service, kan du använda användarinteraktionshistorik och intressen för att förbättra deras sökresultat. Genom att använda en Amazon anpassa recept såsom Personlig rangordning, kan du hjälpa till att öka sökresultaten för relevanta objekt baserat på användarnas intressen när du hämtar sökresultat från OpenSearch Service.
Det här inlägget förklarar hur man integrerar Amazon Personalize Search Ranking-plugin med OpenSearch Service för att möjliggöra personliga sökupplevelser. För att bygga Amazon Personalize-artefakter i det här inlägget använder vi en datauppsättning från IMDb, världens mest auktoritativa källa för film-, TV- och kändisinnehåll, tillgänglig på AWS Marketplace, samt MovieLens dataset utarbetad av GroupLens research vid University of Minnesota, bestående av användarrankningar för olika filmer.
Lösningsöversikt
Följande diagram illustrerar lösningsarkitekturen.
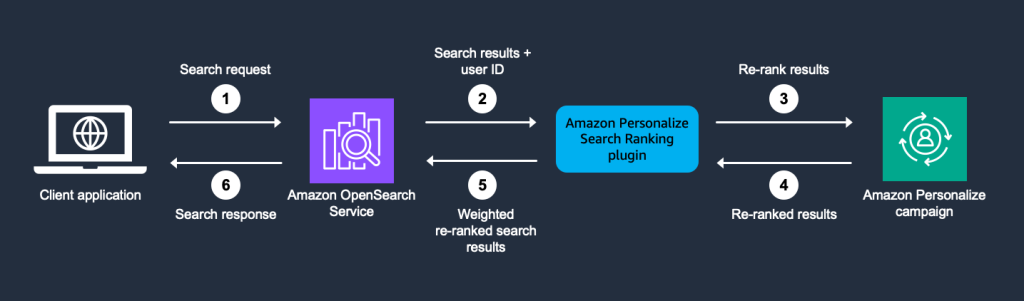
Arbetsflödet innehåller följande steg:
- En användare skickar en sökförfrågan via sin webbplats eller portal. Denna sökförfrågan skickas till OpenSearch Service.
- De översta N sökresultaten returneras från OpenSearch Service-index och skickas till plugin-programmet för att förbearbeta och förbereda indata för en Amazon Personalize-kampanj.
- Begäran skickas till Amazon Personalize för att få de omrangerade sökresultaten.
- Amazon Personalize returnerar den personliga rankningen av sökresultaten med relevant poäng för varje resultat.
- De omrankade träffarna returneras av plugin-programmet till OpenSearch Service, med en viktning mellan OpenSearch Service-relevanspoängen och Amazon Personalizes personliga rankingpoäng. Du anger en viktparameter (mellan 0.0–1.0) som styr balansen mellan OpenSearch Service och Amazon Personalize vid omrangering av resultat. En högre vikt betyder mer inflytande från Amazon Personalize-rankingpoängen jämfört med OpenSearch Service-poängen. Detta låter dig anpassa hur mycket de personliga rekommendationerna påverkar den slutliga sökresultatrankningen som returneras till användaren.
- Användaren får personliga sökresultat baserat på sina preferenser och interaktioner.
Förutsättningar
Du bör ha följande förutsättningar:
- An AWS-konto.
- An AWS identitets- och åtkomsthantering (IAM) roll med lämplig åtkomstbehörighet. Vi tillhandahåller AWS molnformation mallar och Jupyter-anteckningsböcker för att hjälpa till att ställa in den nödvändiga IAM-rollen och åtkomsten.
- För att aktivera personalisering i OpenSearch Service måste du ställa in de nödvändiga Amazon Personalize-resurserna, inklusive en datauppsättningsgrupp, lösningsversion och kampanj. Vi har tillhandahållit en Jupyter anteckningsbok som skapar alla Amazon Personalize-resurser och drar fördel av de fullt hanterade Jupyter notebook-instansernas funktioner för Amazon SageMaker.
Distribuera CloudFormation -stacken
CloudFormation-stacken automatiserar distributionen av OpenSearch Service-domänen och SageMaker Notebook-instansen. Utför följande steg för att distribuera stacken:
- Logga in på AWS Management Console med dina referenser på kontot där du vill distribuera CloudFormation-stacken.
- Starta CloudFormation-stacken direkt.
- På Ange detaljer sida, ange alla parametrar som krävs av mallen, såsom OpenSearch Service och SageMaker-instansstorlekar.
- På Konfigurera stackalternativ sida, ange ett stacknamn och eventuella andra alternativ du vill ställa in.
- Slutför skapandet av stacken och övervaka statusen på sidan med stackens detaljer.
- När stacken har skapats öppnar du SageMaker-anteckningsbokförekomsten från konsolen.
Notebook-instansen kommer redan att vara förladdad med de nödvändiga anteckningsböckerna.
Ställ in och slutför Amazon Personalize-arbetsflödet
Öppna 1.Configure_Amazon_Personalize.ipynb anteckningsbok för att ställa in Amazon Personalize-artefakter. Den här anteckningsboken leder dig genom följande steg:
- Ladda ner datauppsättningen och förbehandla data för att skapa de nödvändiga indatafilerna för att skapa datauppsättningarna.
- Skapa en datagrupp.
- Skapa datauppsättningar och scheman.
- Förbered och importera data.
- Skapa en lösning och en lösningsversion.
- Skapa en kampanj för lösningsversionen.
Installera Amazon Personalize Search Ranking-plugin med en Jupyter-anteckningsbok
Öppna 2.Configure_Amazon_OpenSearch.ipynb anteckningsboken och gå igenom instruktionerna. Den här anteckningsboken leder dig genom följande steg:
- Ta in exempelindexdata i OpenSearch Service-instansen. Att fylla indexet med representativa data underlättar noggrann testning och validering av plugin-programmet.
- Installera plugin-paketet i OpenSearch Service-domänen. Detta integrerar anpassningsmöjligheterna i OpenSearch-miljön.
- Ställ in sökpipelines för att aktivera insticksprogrammets funktionalitet. Sökpipelines innehåller begärandeförbehandlare och svarsefterbehandlare som transformerar frågor och resultat. När du bygger en pipeline, ange Amazon Personalize-kampanjen ARN som skapats tidigare i en
personalized_search_rankingpostprocessor för att möjliggöra personlig omrangering. Detta konfigurerar plugin-programmet för att hämta personaliseringsresultat i realtid från Amazon Personalize för tillämpning under resultatbearbetning. Genom att definiera pipelines kan plugin-programmet öka sökrelevansen baserat på användarens preferenser.
Installera Amazon Personalize Search Ranking-plugin med hjälp av konsolen
Du kan också ställa in Amazon Personalize sökplugin från konsolen. Du behöver bara göra detta om du inte har installerat plugin-programmet med Jupyter-anteckningsboken från tidigare.
För att installera Amazon Personalize Search Ranking-plugin på OpenSearch Service, utför följande steg:
- På OpenSearch Service-konsolen navigerar du till din domän.
- På Paket fliken, välj Associerat paket för att associera Amazon Personalize Search Ranking-plugin med din OpenSearch Service-domän. Pluginversionen måste matcha OpenSearch Service-domänversionen.
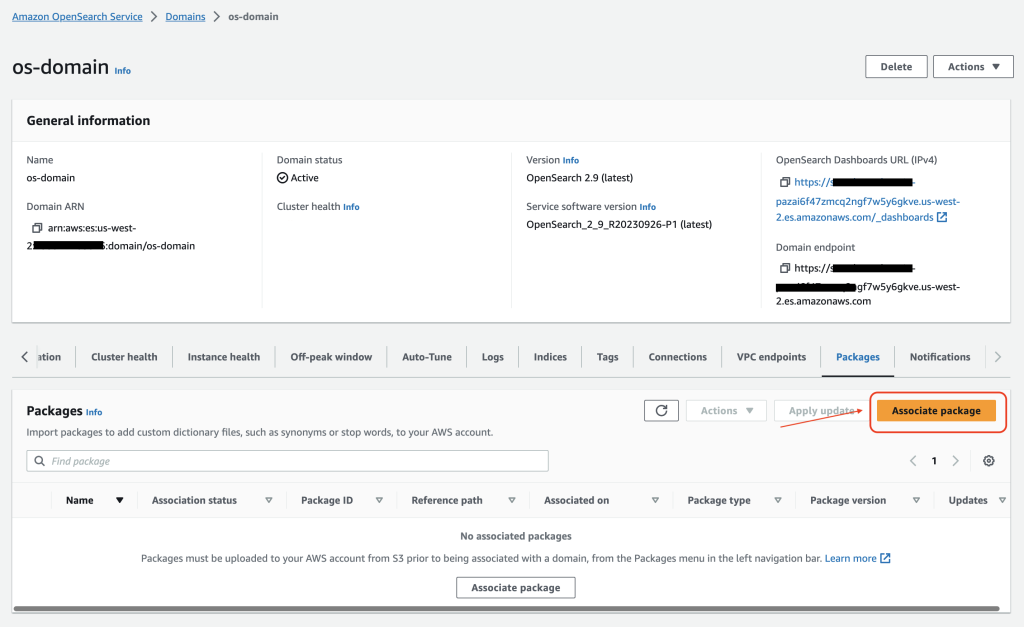
Amazon Personalize Search Ranking-plugin kan installeras på OpenSearch Service version 2.9 och senare.
- Leta reda på Amazon Personalize Search Ranking-plugin i listan över tillgängliga plugins.
- Välja Associate bredvid plugin-programmet för att installera det och associera det med din befintliga OpenSearch Service-domän.

Efter att du har anslutit plugin-programmet kommer det att visas i listan över paket som en plugin-typ. När plugin-programmet är installerat är installationsprocessen nu klar.
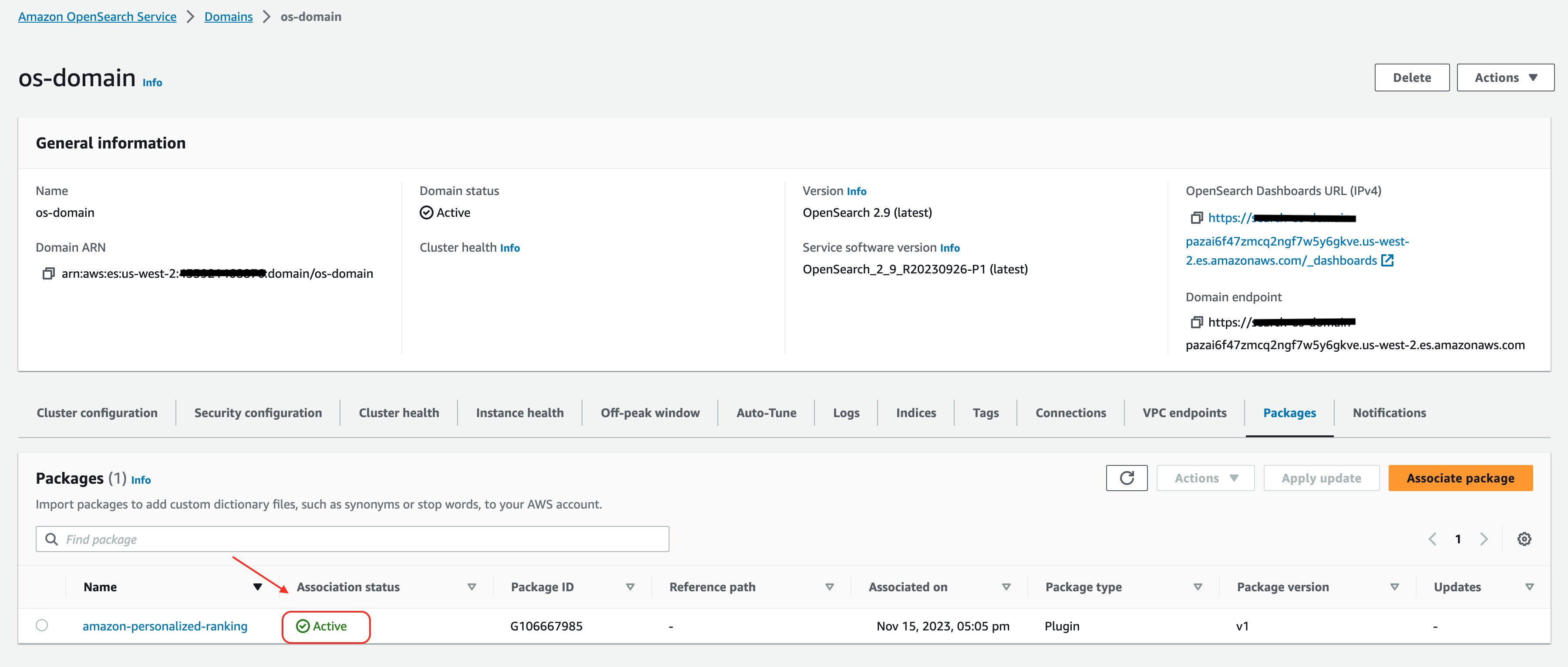
Aktivera Amazon Personalize Search Ranking-plugin
Amazon Personalize Search Ranking-plugin använder search-pipeline funktion i OpenSearch Service, släppt från och med version 2.9. Plugin-programmet beror på search-pipeline funktion för att tillämpa Amazon personlig rankning på sökresultat som tillhandahålls av OpenSearch Service och måste också ställas in som en search-pipeline svarsprocessor. Den här pipelinedefinitionen kommer att innehålla konfigurationen för Amazon Personalize-plugin, som inkluderar Amazon Personalize-kampanjen för att få Amazon Personalize-rankning, IAM-rollen för att komma åt Amazon Personalize-resurser, samt parametrarna som definieras i följande tabell.
| Inställningar | Krävs | Standard | Beskrivning |
campaign |
Ja | Ingen | Ange ARN för Amazon Personalize-kampanjen som ska användas för att anpassa resultat. |
recipe |
Ja | Ingen | Ange namnet på Amazon Personalize-receptet som ska användas. När detta skrivs, aws-personalized-ranking är det enda värdet som stöds. |
item_id_field |
Nej | "_id" | Om _id fältet för ett indexerat dokument i OpenSearch överensstämmer inte med din Amazon Personalize itemId, ange namnet på fältet som gör det. |
weight |
Ja | Ingen | Ange vilken tonvikt som svarsprocessorn lägger på personalisering när den omrangerar resultaten. Ange ett värde inom intervallet 0.0–1.0. Ju närmare 1.0 det är, desto mer sannolikt är det att resultat från Amazon Personalize rankas högre. Om du anger 0.0 sker ingen anpassning och OpenSearch Service har företräde. |
tag |
Nej | Ingen | Ange en identifierare för processorn. |
iam_role_arn |
Ja | Ingen | Ange IAM-rollen för att komma åt Amazon Personalize-resurser. Detta krävs för OpenSearch Service och valfritt för OpenSearch med öppen källkod. |
aws_region |
Ja | Ingen | Ange AWS-regionen där du skapade din Amazon Personalize-kampanj. |
ignore_failure |
Nej | Ingen | Ange om plugin-programmet ignorerar eventuella processorfel. För värden, specificera true or false. För dina produktionsmiljöer rekommenderar vi att du anger true för att undvika avbrott för frågesvar. För testmiljöer kan du ange false för att se eventuella fel som insticksprogrammet genererar. |
external_account_iam_role_arn |
Nej | Ingen | Om du använder OpenSearch Service och dina Amazon Personalize- och OpenSearch Service-resurser finns på olika konton, ange ARN för rollen som har behörighet att komma åt Amazon Personalize. |
Följande Python-kodavsnitt skapar en sökpipeline med en personalized_search_ranking svarsprocessor på en OpenSearch Service-domän. Du kör det här steget en gång som en del av anteckningsboken som följer med det här inlägget:
Definiera sökpipeline för personlig rankning
Du kan använda följande Python-kod för att skapa en sökpipeline med en personalized_search_ranking svarsprocessor på en OpenSearch Service-domän. Ersätt domänändpunkt med din domänslutpunkts-URL. Till exempel: https://<domain name>.<AWS region>.es.amazonaws.com.
Tillämpa en sökpipeline på en enskild fråga
När du har konfigurerat en sökpipeline med en personalized_search_ranking svarsprocessor kan du applicera Amazon Personalize Search Ranking-plugin på dina OpenSearch-frågor och se de omrangerade resultaten. Uppdatera koden för att ange din domänslutpunkt, ditt OpenSearch Service-index, namnet på din pipeline (du konfigurerade ovan) och din fråga (vi använder "Tom Cruise" för fråga). För user_id, ange ID för användaren som du får sökresultat för. Denna användare måste finnas i den information som du använde för att skapa din Amazon Personalize-lösningsversion.
Utvärdera resultaten
Öppna 3.Testing.ipynb notebook och gå igenom stegen för att testa och jämföra resultaten för frågor som använder anpassning och de som inte gör det. Amazon Personalize Search Ranking-plugin rankar om sökresultaten i OpenSearch-tjänstens frågesvar. Den tar hänsyn till både rankningen från Amazon Personalize och rankningen från OpenSearch Service. Den här anteckningsboken leder dig genom följande steg:
- Definiera de nödvändiga anslutningsparametrarna för att upprätta en anslutning till din OpenSearch Service-domän. Detta innebär att du specificerar domänens slutpunkt, autentiseringsuppgifter och eventuella ytterligare konfigurationsinställningar som krävs för din specifika OpenSearch Service-inställning.
- Skapa en uppsättning exempelfrågor, inklusive frågor med anpassningsparametrar och frågor utan anpassningsparametrar. Dessa frågor kommer att användas för att utvärdera effekten av personalisering på sökresultaten.
- Kör och jämför resultaten för frågor som använder anpassning och de som inte gör det.
För vårt exempel använde vi en fråga för "Tom Cruise" och för personaliseringsparametern använde vi en användare med en ny historik av att se genrer för drama och romantik. De efterföljande sökresultaten visar hur pluginet skräddarsyr och prioriterar rekommendationer baserade på användarens observerade tittarbeteende. Detta exemplifierar pluginens förmåga att leverera en anpassad, kurerad upplevelse genom att överväga individuella användarpreferenser och engagemangsmönster. Möjligheten att förfina och justera sökresultat baserat på slutsatser av en användares preferenser gör det möjligt att leverera ökad relevans och användbarhet.
Personliga vs icke-personliga resultat
Låt oss överväga att anpassa resultat för en användare med ID 12. Först kontrollerar vi denna användares senaste interaktioner genom att köra koden i 3.Testing.ipynb anteckningsbok för att hämta sin interaktionshistorik. Detta gör att vi kan se vilka typer av filmer den här användaren har recenserat nyligen, vilket kan informera om hur vi anpassar rekommendationer för dem.
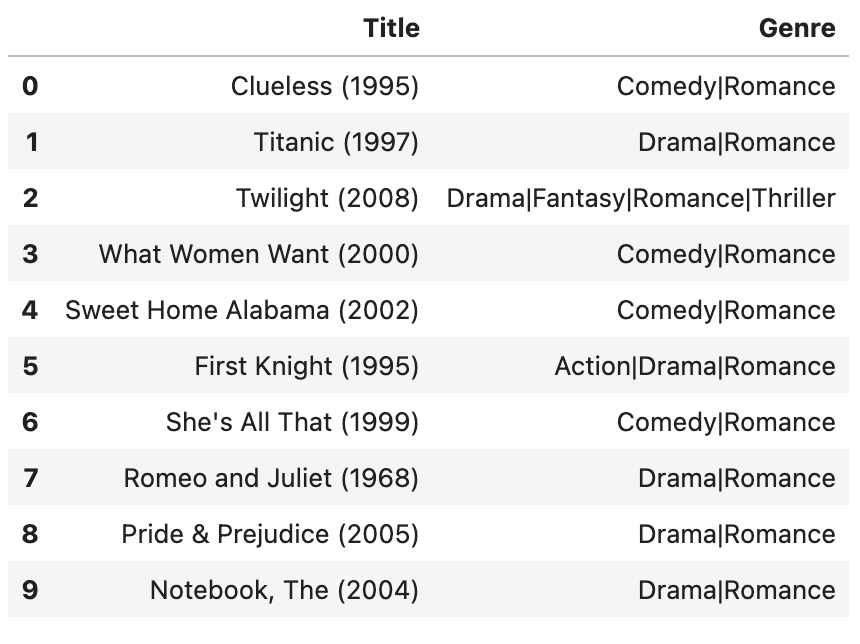
I det här exemplet ser vi att användaren har uttryckt intresse för genrer för drama, romantik och thriller. För att ge personliga rekommendationer kör vi först frågor med anpassningsparametrar aktiverade, med hjälp av användarens genrepreferenser. Vi kör sedan samma frågor utan anpassning aktiverad, för jämförelse. Följande resultat visar skillnaden mellan de icke-personliga och personliga rekommendationerna.
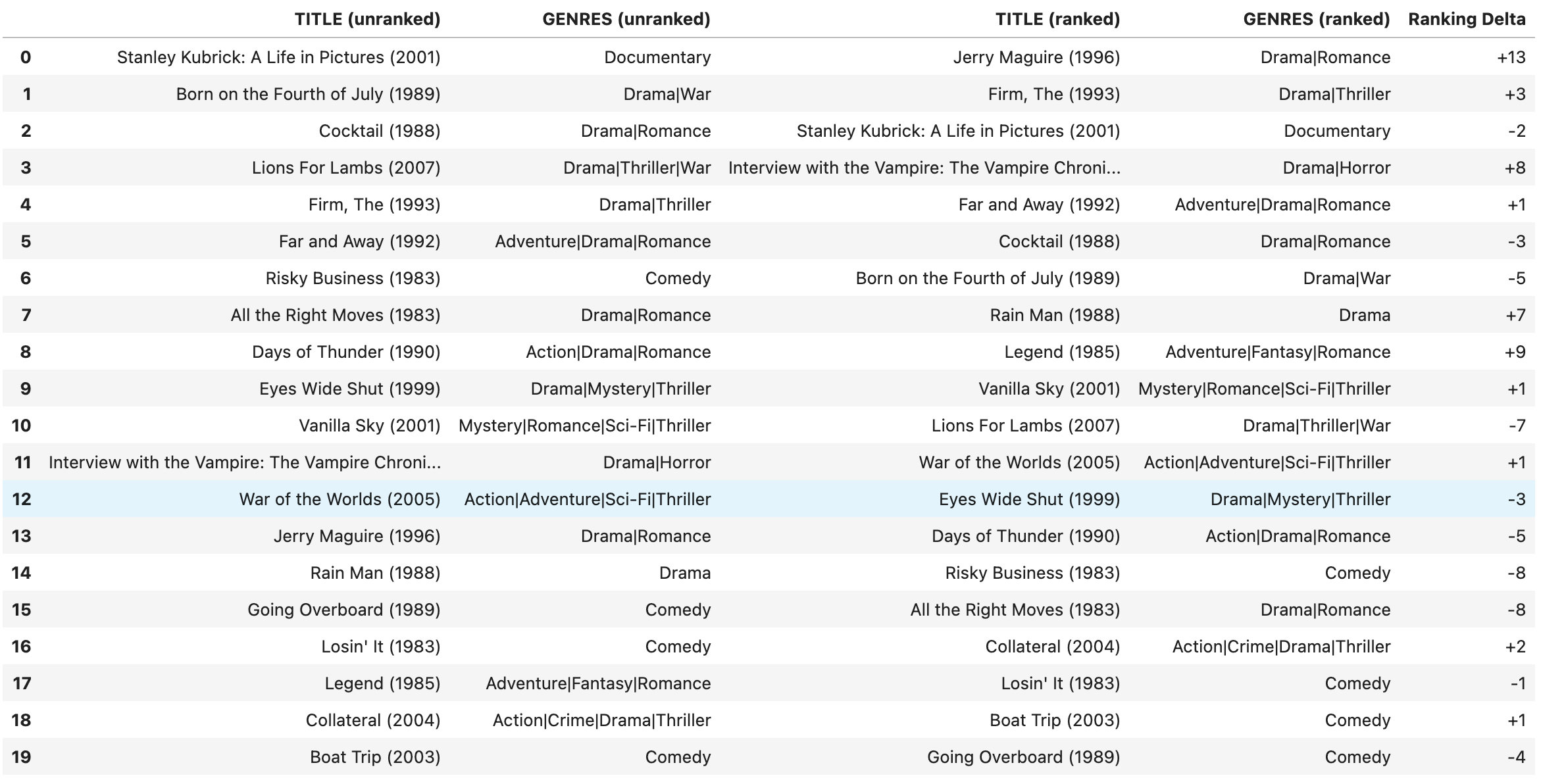
De två första kolumnerna visar standardresultaten för OpenSearch Service för frågan "Tom Cruise" på ett filmindex, som visar en mängd olika Tom Cruise-filmer i olika genrer. De följande två kolumnerna visar personliga resultat från OpenSearch Service för samma "Tom Cruise"-fråga, men anpassade för en användare som är intresserad av drama, romantik och thrillergenrer. Jämfört med de generiska resultaten har de personliga resultaten framträdande Tom Cruise-filmer i användarens föredragna genrer för drama, romantik och thriller. Deltat belyser hur de personliga resultaten har rankats om i förhållande till de icke-personliga resultaten, och prioriterar filmer som matchar användarens genrepreferenser. Detta visar hur personalisering kan skräddarsy resultat från OpenSearch Service efter individuella användares smak och intressen.
Den här jämförelsen visar hur Amazon Personalize kan anpassa filmresultat från OpenSearch Service för att matcha en enskild användares intressen. Även om standard OpenSearch-tjänst syftar till att tillhandahålla relevanta filmresultat för Tom Cruise, skräddarsyr Amazon Personalize resultaten för att fokusera på Tom Cruise-filmer som den förutspår att användaren kommer att njuta av baserat på sin unika visningshistorik och preferenser.
Resultaten sida vid sida illustrerar hur Amazon Personalize ger en mer riktad, användarcentrerad sökupplevelse genom att anpassa filmresultaten till individen.
Städa upp
Utför följande steg för att rensa upp dina resurser:
- Följ stegen i 4.Cleanup.ipynb anteckningsbok för att rensa upp resurserna som skapats genom anteckningsboken.
- Ta bort stacken som du skapade på AWS CloudFormation-konsolen.
Slutsats
Amazon Personalize Search Ranking-plugin integreras sömlöst med OpenSearch Service för att möjliggöra personliga sökupplevelser. Genom att använda data om användarbeteende och Amazon Personalizes ML-funktioner kan plugin-programmet omordna resultatrankningar för OpenSearch Service för att öka relevansen för varje unik användare. Detta skapar en skräddarsydd sökupplevelse som visar det mest relevanta innehållet högre upp i resultaten. Insticksprogrammet är konfigurerbart för att balansera personalisering med OpenSearch Service inbyggd poängsättning för att passa olika användningsfall. Sammantaget är Amazon Personalize Search Ranking-plugin ett kraftfullt sätt att förbättra OpenSearch Service sökrelevans och engagemang genom att ta hänsyn till dina användares individuella intressen och preferenser. Med bara några konfigurationssteg kan du börja visa hyperrelevanta resultat som resonerar starkt hos dina användare.
Ytterligare resurser
Om författarna
 James Jory är en Principal Solutions Architect i tillämpad AI med AWS. Han har ett speciellt intresse för personalisering och rekommendationssystem och en bakgrund inom e-handel, marknadsföringsteknologi och kunddataanalys. På fritiden tycker han om camping och simuleringar av bilracing.
James Jory är en Principal Solutions Architect i tillämpad AI med AWS. Han har ett speciellt intresse för personalisering och rekommendationssystem och en bakgrund inom e-handel, marknadsföringsteknologi och kunddataanalys. På fritiden tycker han om camping och simuleringar av bilracing.
 Reagan Rosario är en lösningsarkitekt på AWS, specialiserad på att bygga skalbara, högt tillgängliga och säkra molnlösningar för företag inom utbildningsteknik. Med över 10 års erfarenhet inom mjukvaruteknik och arkitekturroller älskar Reagan att använda sin tekniska kunskap för att hjälpa AWS-kunder att bygga robusta molnlösningar som drar nytta av bredden och djupet av AWS.
Reagan Rosario är en lösningsarkitekt på AWS, specialiserad på att bygga skalbara, högt tillgängliga och säkra molnlösningar för företag inom utbildningsteknik. Med över 10 års erfarenhet inom mjukvaruteknik och arkitekturroller älskar Reagan att använda sin tekniska kunskap för att hjälpa AWS-kunder att bygga robusta molnlösningar som drar nytta av bredden och djupet av AWS.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoData.Network Vertical Generative Ai. Styrka dig själv. Tillgång här.
- PlatoAiStream. Web3 Intelligence. Kunskap förstärkt. Tillgång här.
- Platoesg. Kol, CleanTech, Energi, Miljö, Sol, Avfallshantering. Tillgång här.
- PlatoHealth. Biotech och kliniska prövningar Intelligence. Tillgång här.
- Källa: https://aws.amazon.com/blogs/machine-learning/unlock-personalized-experiences-powered-by-ai-using-amazon-personalize-and-amazon-opensearch-service/

