Med Kunskapsbaser för Amazon Bedrock, kan du säkert ansluta grundmodeller (FM) i Amazonas berggrund till din företagsdata för Retrieval Augmented Generation (RAG). Tillgång till ytterligare data hjälper modellen att generera mer relevanta, kontextspecifika och korrekta svar utan att omskola FM:erna.
I det här inlägget diskuterar vi två nya funktioner i Knowledge Bases for Amazon Bedrock som är specifika för RetrieveAndGenerate API: konfigurera det maximala antalet resultat och skapa anpassade meddelanden med en informationsbasmall. Du kan nu välja dessa som frågealternativ vid sidan av söktypen.
Översikt och fördelar med nya funktioner
Alternativet för det maximala antalet resultat ger dig kontroll över antalet sökresultat som ska hämtas från vektorlagret och skickas till FM för att generera svaret. Detta gör att du kan anpassa mängden bakgrundsinformation som tillhandahålls för generering, vilket ger mer sammanhang för komplexa frågor eller mindre för enklare frågor. Det låter dig hämta upp till 100 resultat. Det här alternativet hjälper till att förbättra sannolikheten för relevant sammanhang, och förbättrar därigenom noggrannheten och minskar hallucinationerna i det genererade svaret.
Den anpassade informationsbasmallen låter dig ersätta standardpromptmallen med din egen för att anpassa prompten som skickas till modellen för svarsgenerering. Detta gör att du kan anpassa tonen, utdataformatet och beteendet för FM:n när den svarar på en användares fråga. Med det här alternativet kan du finjustera terminologin för att bättre matcha din bransch eller domän (som sjukvård eller juridik). Dessutom kan du lägga till anpassade instruktioner och exempel skräddarsydda för dina specifika arbetsflöden.
I följande avsnitt förklarar vi hur du kan använda dessa funktioner med antingen AWS Management Console eller SDK.
Förutsättningar
För att följa dessa exempel måste du ha en befintlig kunskapsbas. För instruktioner om hur du skapar en, se Skapa en kunskapsbas.
Konfigurera det maximala antalet resultat med hjälp av konsolen
Utför följande steg för att använda alternativet för maximalt antal resultat med konsolen:
- Välj på Amazon Bedrock-konsolen Kunskapsbaser i den vänstra navigationsfönstret.
- Välj den kunskapsbas du skapade.
- Välja Testa kunskapsbas.
- Välj konfigurationsikonen.
- Välja Synkronisera datakälla innan du börjar testa din kunskapsbas.

- Enligt konfigurationer, För Söktyp, välj en söktyp baserat på ditt användningsfall.
För det här inlägget använder vi hybridsökning eftersom den kombinerar semantisk och textsökning för att ge större noggrannhet. För att lära dig mer om hybridsökning, se Kunskapsbaser för Amazon Bedrock stöder nu hybridsökning.
- Bygga ut Maximalt antal källbitar och ställ in ditt maximala antal resultat.

För att visa värdet av den nya funktionen visar vi exempel på hur du kan öka noggrannheten i det genererade svaret. Vi använde Amazon 10K-dokument för 2023 som källdata för att skapa kunskapsbasen. Vi använder följande fråga för experiment: "I vilket år ökade Amazons årliga intäkter från $245B till $434B?"
Det korrekta svaret på denna fråga är "Amazons årliga intäkter ökade från 245 miljarder USD 2019 till 434 miljarder USD 2022", baserat på dokumenten i kunskapsbasen. Vi använde Claude v2 som FM för att generera det slutliga svaret baserat på den kontextuella informationen som hämtats från kunskapsbasen. Claude 3 Sonnet och Claude 3 Haiku stöds också som generationens FMs.
Vi körde en annan fråga för att demonstrera jämförelsen av hämtning med olika konfigurationer. Vi använde samma indatafråga ("I vilket år ökade Amazons årliga intäkter från $245B till $434B?") och satte det maximala antalet resultat till 5.
Som visas i följande skärmdump var det genererade svaret "Tyvärr, jag kan inte hjälpa dig med denna begäran."

Därefter ställer vi in det maximala resultatet till 12 och ställer samma fråga. Det genererade svaret är "Amazons årliga intäktsökning från 245 miljarder USD 2019 till 434 miljarder USD 2022."

Som visas i det här exemplet kan vi hämta rätt svar baserat på antalet hämtade resultat. Om du vill lära dig mer om källattributionen som utgör den slutliga utdatan, välj Visa källinformation för att validera det genererade svaret baserat på kunskapsbasen.
Anpassa en mall för kunskapsbasmeddelanden med hjälp av konsolen
Du kan också anpassa standardprompten med din egen prompt baserat på användningsfallet. För att göra det på konsolen, slutför följande steg:
- Upprepa stegen i föregående avsnitt för att börja testa din kunskapsbas.
- aktivera Generera svar.

- Välj den modell du väljer för svarsgenerering.
Vi använder Claude v2-modellen som exempel i det här inlägget. Modellen Claude 3 Sonnet och Haiku är också tillgänglig för generation.
- Välja Ansök att fortsätta.

När du har valt modell kallas en ny sektion Kunskapsbas-promptmall visas under konfigurationer.
- Välja Redigera för att börja anpassa prompten.
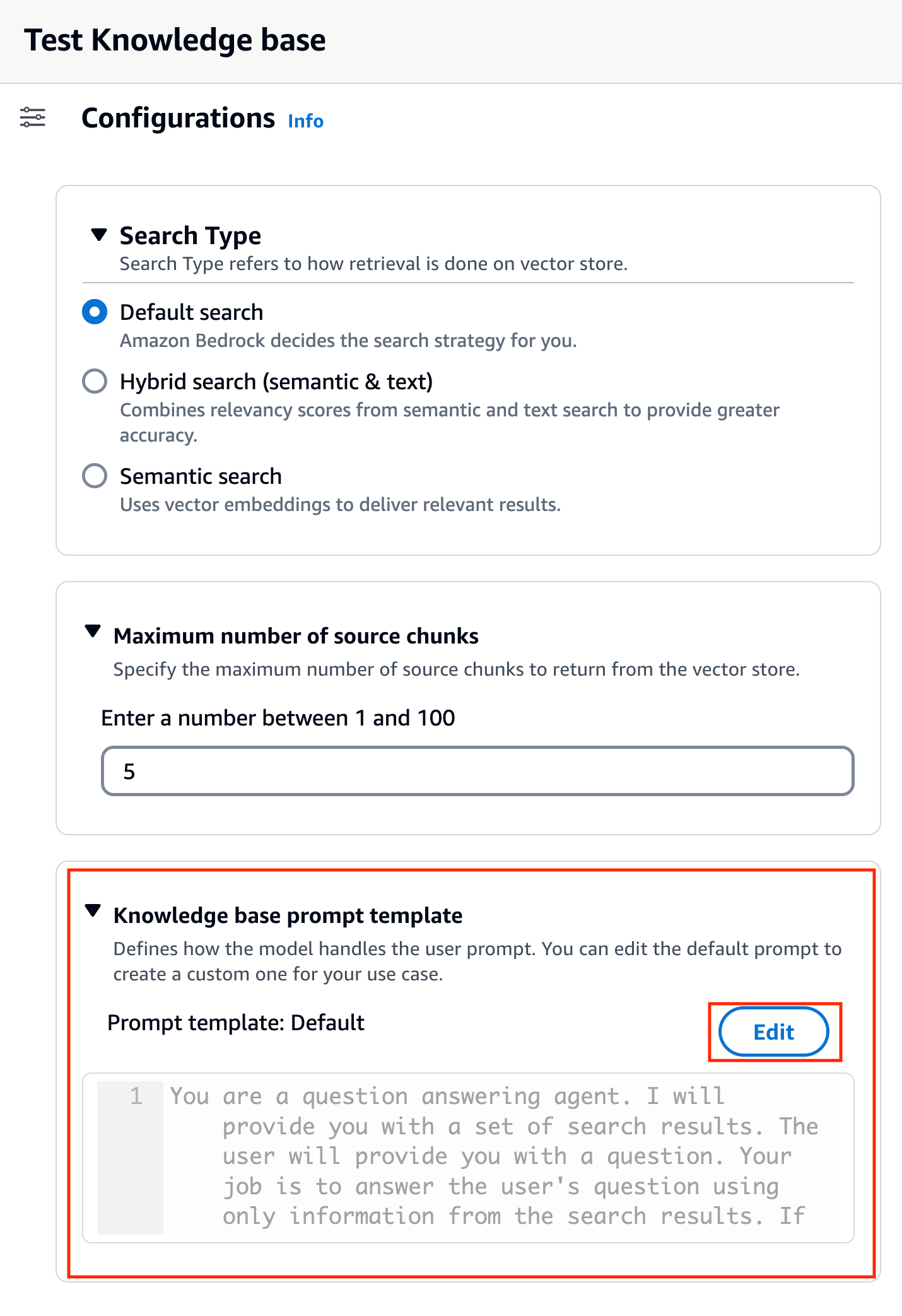
- Justera uppmaningsmallen för att anpassa hur du vill använda de hämtade resultaten och generera innehåll.
För det här inlägget gav vi några exempel för att skapa ett "Financial Advisor AI-system" med hjälp av Amazons finansiella rapporter med anpassade uppmaningar. För bästa praxis för snabb konstruktion, se Snabba tekniska riktlinjer.
Vi anpassar nu standardpromptmallen på flera olika sätt och observerar svaren.
Låt oss först prova en fråga med standardprompten. Vi frågar "Vilka var Amazonas intäkter 2019 och 2021?" Följande visar våra resultat.

Från utdatan finner vi att det genererar det fria svaret baserat på den hämtade kunskapen. Citaten är också listade som referens.
Låt oss säga att vi vill ge extra instruktioner om hur man formaterar det genererade svaret, som att standardisera det som JSON. Vi kan lägga till dessa instruktioner som ett separat steg efter att ha hämtat informationen, som en del av promptmallen:
Det slutliga svaret har den struktur som krävs.

Genom att anpassa prompten kan du också ändra språket för det genererade svaret. I följande exempel instruerar vi modellen att ge ett svar på spanska.

Efter borttagning $output_format_instructions$ från standardprompten tas citatet från det genererade svaret bort.
I följande avsnitt förklarar vi hur du kan använda dessa funktioner med SDK:n.
Konfigurera det maximala antalet resultat med SDK:n
För att ändra det maximala antalet resultat med SDK:n, använd följande syntax. För det här exemplet är frågan "I vilket år ökade Amazons årliga intäkter från $245B till $434B?" Det korrekta svaret är "Amazons årliga intäktsökning från 245 miljarder USD 2019 till 434 miljarder USD 2022."
Den "numberOfResults' alternativ under 'retrievalConfiguration' låter dig välja antalet resultat du vill hämta. Utgången av RetrieveAndGenerate API inkluderar det genererade svaret, källattribution och de hämtade textbitarna.
Följande är resultaten för olika värden av 'numberOfResults' parametrar. Först ställer vi in numberOfResults = 5.
Sedan sätter vi numberOfResults = 12.
Anpassa kunskapsbas-promptmallen med hjälp av SDK
För att anpassa prompten med hjälp av SDK:n använder vi följande fråga med olika promptmallar. För det här exemplet är frågan "Vilka var Amazonas intäkter 2019 och 2021?"
Följande är standardpromptmallen:
Följande är den anpassade promptmallen:
Med standardpromptmallen får vi följande svar:
![]()
Om du vill ge ytterligare instruktioner kring utdataformatet för svarsgenereringen, som att standardisera svaret i ett specifikt format (som JSON), kan du anpassa den befintliga prompten genom att ge mer vägledning. Med vår anpassade promptmall får vi följande svar.

Den "promptTemplate'alternativ i'generationConfiguration' låter dig anpassa uppmaningen för bättre kontroll över svarsgenereringen.
Slutsats
I det här inlägget introducerade vi två nya funktioner i Knowledge Bases for Amazon Bedrock: justering av det maximala antalet sökresultat och anpassning av standardpromptmallen för RetrieveAndGenerate API. Vi visade hur man konfigurerar dessa funktioner på konsolen och via SDK för att förbättra prestandan och noggrannheten i det genererade svaret. Att öka de maximala resultaten ger mer omfattande information, medan anpassning av promptmallen gör att du kan finjustera instruktionerna för grundmodellen för att bättre passa specifika användningsfall. Dessa förbättringar ger större flexibilitet och kontroll, vilket gör att du kan leverera skräddarsydda upplevelser för RAG-baserade applikationer.
För ytterligare resurser för att börja implementera i din AWS-miljö, se följande:
Om författarna
 Sandeep Singh är Senior Generative AI Data Scientist på Amazon Web Services, som hjälper företag att förnya sig med generativ AI. Han är specialiserad på generativ AI, artificiell intelligens, maskininlärning och systemdesign. Han brinner för att utveckla toppmoderna AI/ML-drivna lösningar för att lösa komplexa affärsproblem för olika branscher, optimera effektivitet och skalbarhet.
Sandeep Singh är Senior Generative AI Data Scientist på Amazon Web Services, som hjälper företag att förnya sig med generativ AI. Han är specialiserad på generativ AI, artificiell intelligens, maskininlärning och systemdesign. Han brinner för att utveckla toppmoderna AI/ML-drivna lösningar för att lösa komplexa affärsproblem för olika branscher, optimera effektivitet och skalbarhet.
 Suyin Wang är en AI/ML Specialist Solutions Architect på AWS. Hon har en tvärvetenskaplig utbildningsbakgrund inom maskininlärning, finansiell informationstjänst och ekonomi, tillsammans med många års erfarenhet av att bygga datavetenskap och maskininlärningsapplikationer som löste verkliga affärsproblem. Hon tycker om att hjälpa kunder att identifiera rätt affärsfrågor och bygga rätt AI/ML-lösningar. På fritiden älskar hon att sjunga och laga mat.
Suyin Wang är en AI/ML Specialist Solutions Architect på AWS. Hon har en tvärvetenskaplig utbildningsbakgrund inom maskininlärning, finansiell informationstjänst och ekonomi, tillsammans med många års erfarenhet av att bygga datavetenskap och maskininlärningsapplikationer som löste verkliga affärsproblem. Hon tycker om att hjälpa kunder att identifiera rätt affärsfrågor och bygga rätt AI/ML-lösningar. På fritiden älskar hon att sjunga och laga mat.
 Sherry Ding är en senior arkitekt för artificiell intelligens (AI) och maskininlärning (ML) specialistlösningar på Amazon Web Services (AWS). Hon har lång erfarenhet av maskininlärning med en doktorsexamen i datavetenskap. Hon arbetar främst med kunder i den offentliga sektorn med olika AI/ML-relaterade affärsutmaningar, och hjälper dem att påskynda sin maskininlärningsresa i AWS-molnet. När hon inte hjälper kunder tycker hon om utomhusaktiviteter.
Sherry Ding är en senior arkitekt för artificiell intelligens (AI) och maskininlärning (ML) specialistlösningar på Amazon Web Services (AWS). Hon har lång erfarenhet av maskininlärning med en doktorsexamen i datavetenskap. Hon arbetar främst med kunder i den offentliga sektorn med olika AI/ML-relaterade affärsutmaningar, och hjälper dem att påskynda sin maskininlärningsresa i AWS-molnet. När hon inte hjälper kunder tycker hon om utomhusaktiviteter.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoData.Network Vertical Generative Ai. Styrka dig själv. Tillgång här.
- PlatoAiStream. Web3 Intelligence. Kunskap förstärkt. Tillgång här.
- Platoesg. Kol, CleanTech, Energi, Miljö, Sol, Avfallshantering. Tillgång här.
- PlatoHealth. Biotech och kliniska prövningar Intelligence. Tillgång här.
- Källa: https://aws.amazon.com/blogs/machine-learning/knowledge-bases-for-amazon-bedrock-now-supports-custom-prompts-for-the-retrieveandgenerate-api-and-configuration-of-the-maximum-number-of-retrieved-results/

