Kronor förser bryggerier, drycketappare och livsmedelsproducenter över hela världen med individuella maskiner och kompletta produktionslinjer. Varje dag går miljontals glasflaskor, burkar och PET-behållare genom en Krones-linje. Produktionslinjer är komplexa system med många möjliga fel som kan stoppa linjen och minska produktionsutbytet. Krones vill upptäcka felet så tidigt som möjligt (ibland även innan det inträffar) och meddela produktionslinjeoperatörerna för att öka tillförlitligheten och produktionen. Så hur upptäcker man ett fel? Krones utrustar sina linjer med sensorer för datainsamling, som sedan kan utvärderas mot regler. Krones, som linjetillverkare, såväl som linjeoperatör har möjlighet att skapa övervakningsregler för maskiner. Därför kan dryckestappare och andra operatörer definiera sin egen felmarginal för linjen. Tidigare använde Krones ett system baserat på en tidsseriedatabas. De största utmaningarna var att det här systemet var svårt att felsöka och även frågor representerade maskinernas nuvarande tillstånd men inte tillståndsövergångarna.
Det här inlägget visar hur Krones byggde en streaminglösning för att övervaka sina linjer, baserat på Amazon Kinesis och Amazon Managed Service för Apache Flink. Dessa fullt hanterade tjänster minskar komplexiteten i att bygga streamingapplikationer med Apache Flink. Managed Service för Apache Flink hanterar de underliggande Apache Flink-komponenterna som ger hållbart applikationstillstånd, mätvärden, loggar och mer, och Kinesis gör att du kan bearbeta strömmande data på ett kostnadseffektivt sätt i alla skala. Om du vill komma igång med din egen Apache Flink-applikation, kolla in GitHub repository för exempel som använder Flinks Java-, Python- eller SQL-API:er.
Översikt över lösningen
Krones linjeövervakning är en del av Krones Shopfloor Guidning systemet. Det ger stöd i organisation, prioritering, ledning och dokumentation av alla aktiviteter i företaget. Det gör att de kan meddela en operatör om maskinen stoppas eller om material krävs, oavsett var operatören befinner sig i kön. Beprövade regler för tillståndsövervakning är redan inbyggda men kan också användardefinieras via användargränssnittet. Till exempel, om en viss datapunkt som övervakas bryter mot ett tröskelvärde, kan det finnas ett textmeddelande eller utlösare för en underhållsorder på linjen.
Systemet för tillståndsövervakning och regelutvärdering är byggt på AWS, med hjälp av AWS-analystjänster. Följande diagram illustrerar arkitekturen.
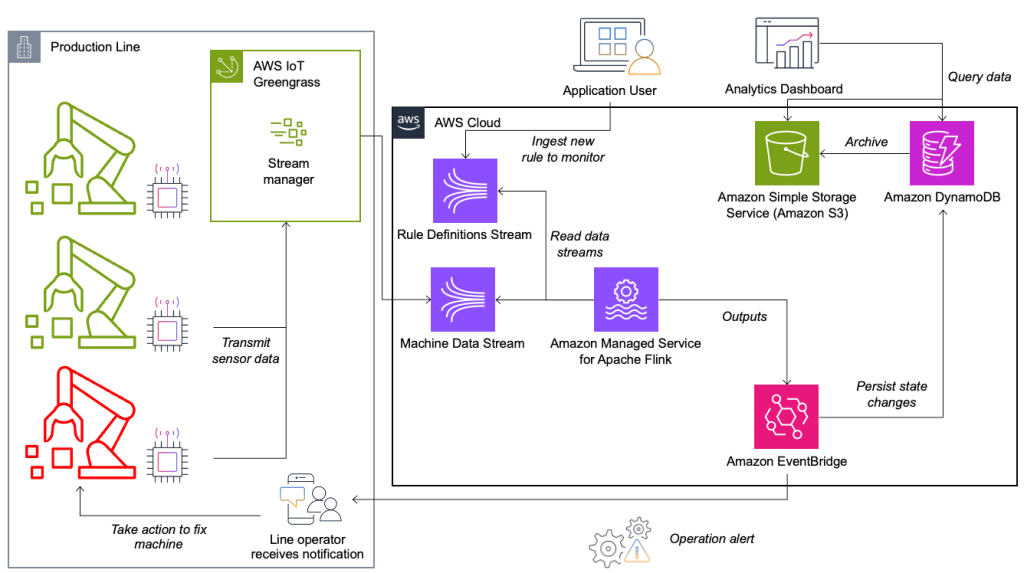
Nästan varje dataströmningsapplikation består av fem lager: datakälla, strömintag, strömlagring, strömbearbetning och en eller flera destinationer. I de följande avsnitten dyker vi djupare in i varje lager och hur linjeövervakningslösningen, byggd av Krones, fungerar i detalj.
Datakälla
Datan samlas in av en tjänst som körs på en edge-enhet som läser flera protokoll som Siemens S7 eller OPC/UA. Rådata förbehandlas för att skapa en enhetlig JSON-struktur, vilket gör det lättare att bearbeta senare i regelmotorn. Ett exempel på nyttolast som konverterats till JSON kan se ut så här:
{
"version": 1,
"timestamp": 1234,
"equipmentId": "84068f2f-3f39-4b9c-a995-d2a84d878689",
"tag": "water_temperature",
"value": 13.45,
"quality": "Ok",
"meta": {
"sequenceNumber": 123,
"flags": ["Fst", "Lst", "Wmk", "Syn", "Ats"],
"createdAt": 12345690,
"sourceId": "filling_machine"
}
}Strömintag
AWS IoT Greengrass är en öppen källkod för Internet of Things (IoT) edge runtime och molntjänst. Detta gör att du kan agera på data lokalt och aggregera och filtrera enhetsdata. AWS IoT Greengrass tillhandahåller förbyggda komponenter som kan distribueras till kanten. Produktionslinjelösningen använder stream manager-komponenten, som kan bearbeta data och överföra den till AWS-destinationer som t.ex AWS IoT Analytics, Amazon enkel lagringstjänst (Amazon S3) och Kinesis. Strömhanteraren buffrar och aggregerar poster och skickar dem sedan till en Kinesis-dataström.
Streama lagring
Streamlagringens uppgift är att buffra meddelanden på ett feltolerant sätt och göra det tillgängligt för konsumtion till en eller flera konsumentapplikationer. För att uppnå detta på AWS är de vanligaste teknikerna Kinesis och Amazon Managed Streaming för Apache Kafka (Amazon MSK). För att lagra våra sensordata från produktionslinjer väljer Krones Kinesis. Kinesis är en serverlös strömningsdatatjänst som fungerar i alla skala med låg latens. Skärvor i en Kinesis-dataström är en unikt identifierad sekvens av dataposter, där en ström är sammansatt av en eller flera skärvor. Varje skärva har 2 MB/s läskapacitet och 1 MB/s skrivkapacitet (med max 1,000 XNUMX poster/s). För att undvika att nå dessa gränser bör data fördelas mellan skärvor så jämnt som möjligt. Varje post som skickas till Kinesis har en partitionsnyckel, som används för att gruppera data i en skärva. Därför vill du ha ett stort antal partitionsnycklar för att fördela belastningen jämnt. Streamhanteraren som körs på AWS IoT Greengrass stöder slumpmässiga partitionsnyckeltilldelningar, vilket innebär att alla poster hamnar i en slumpmässig skärva och belastningen fördelas jämnt. En nackdel med slumpmässiga partitionsnyckeltilldelningar är att poster inte lagras i ordning i Kinesis. Vi förklarar hur du löser detta i nästa avsnitt, där vi pratar om vattenstämplar.
Vattenstämplar
A vattenmärke är en mekanism som används för att spåra och mäta förloppet av händelsetid i en dataström. Händelsetiden är tidsstämpeln från när händelsen skapades vid källan. Vattenstämpeln indikerar strömbehandlingsapplikationens framsteg i rätt tid, så alla händelser med en tidigare eller likadan tidsstämpel anses vara bearbetade. Denna information är viktig för att Flink ska kunna föra fram händelsetid och utlösa relevanta beräkningar, såsom fönsterutvärderingar. Den tillåtna fördröjningen mellan händelsetid och vattenstämpel kan konfigureras för att bestämma hur länge man ska vänta på sena data innan man betraktar ett fönster som färdigt och förflyttar vattenstämpeln.
Krones har system över hela världen och behövde hantera sena ankomster på grund av anslutningsbortfall eller andra nätverksbegränsningar. De började med att övervaka sena ankomster och ställa in standard Flink sena hantering till det maximala värdet de såg i detta mått. De upplevde problem med tidssynkronisering från edge-enheterna, vilket ledde dem till ett mer sofistikerat sätt att vattenmärka. De byggde en global vattenstämpel för alla avsändare och använde det lägsta värdet som vattenstämpel. Tidsstämplarna lagras i en HashMap för alla inkommande händelser. När vattenstämplarna sänds ut regelbundet används det minsta värdet av denna HashMap. För att undvika att vattenstämplar fastnar på grund av att data saknas konfigurerade de en idleTimeOut parameter, som ignorerar tidsstämplar som är äldre än en viss tröskel. Detta ökar latensen men ger stark datakonsistens.
public class BucketWatermarkGenerator implements WatermarkGenerator<DataPointEvent> {
private HashMap <String, WatermarkAndTimestamp> lastTimestamps;
private Long idleTimeOut;
private long maxOutOfOrderness;
}
Strömbehandling
Efter att data har samlats in från sensorer och matats in i Kinesis måste den utvärderas av en regelmotor. En regel i detta system representerar tillståndet för ett enskilt mått (som temperatur) eller en samling mått. För att tolka ett mått används mer än en datapunkt, vilket är en statistisk beräkning. I det här avsnittet dyker vi djupare in i nyckeltillståndet och sändningsläget i Apache Flink och hur de används för att bygga Krones-regelmotorn.
Styr ström och sändningstillståndsmönster
I Apache Flink, tillstånd hänvisar till systemets förmåga att lagra och hantera information varaktigt över tid och operationer, vilket möjliggör bearbetning av strömmande data med stöd för statistiska beräkningar.
Smakämnen sändningstillståndsmönster tillåter distribution av en stat till alla parallella instanser av en operatör. Därför har alla operatörer samma tillstånd och data kan bearbetas med samma tillstånd. Denna skrivskyddade data kan tas in med hjälp av en kontrollström. En kontrollström är en vanlig dataström, men vanligtvis med en mycket lägre datahastighet. Detta mönster låter dig uppdatera tillståndet dynamiskt för alla operatörer, vilket gör det möjligt för användaren att ändra applikationens tillstånd och beteende utan att behöva en omdistribuering. Närmare bestämt sker fördelningen av staten genom användning av en kontrollström. Genom att lägga till en ny post i kontrollströmmen får alla operatörer denna uppdatering och använder det nya tillståndet för bearbetning av nya meddelanden.
Detta tillåter användare av Krones-applikationen att mata in nya regler i Flink-applikationen utan att starta om den. Detta undviker driftstopp och ger en fantastisk användarupplevelse när förändringar sker i realtid. En regel täcker ett scenario för att upptäcka en processavvikelse. Ibland är maskindata inte så lätta att tolka som det kan se ut vid första anblicken. Om en temperatursensor sänder höga värden kan detta indikera ett fel, men också vara effekten av ett pågående underhållsprocedur. Det är viktigt att sätta statistik i sitt sammanhang och filtrera vissa värden. Detta uppnås genom ett koncept som kallas gruppering.
Gruppering av mått
Grupperingen av data och mätvärden låter dig definiera relevansen av inkommande data och producera korrekta resultat. Låt oss gå igenom exemplet i följande figur.
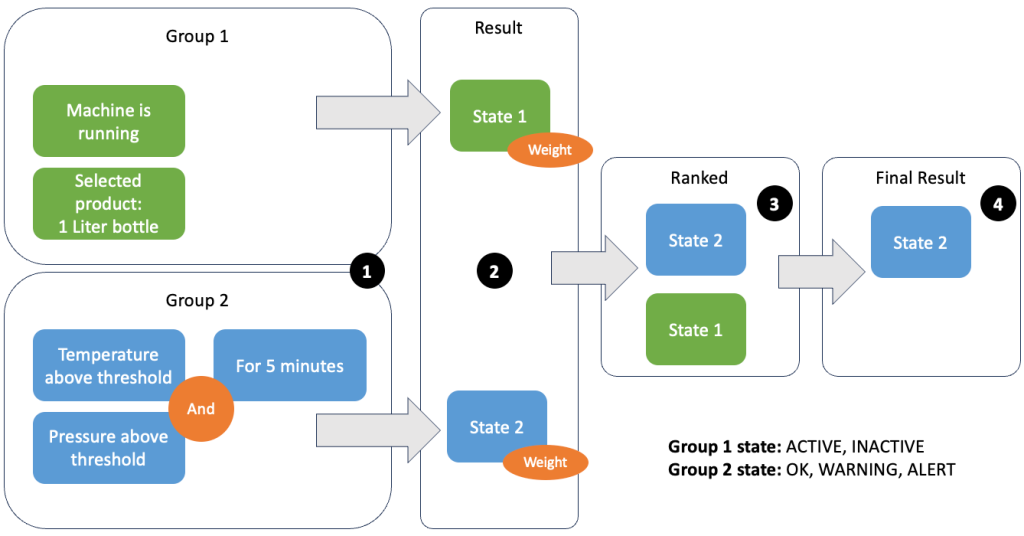
I steg 1 definierar vi två tillståndsgrupper. Grupp 1 samlar in maskintillståndet och vilken produkt som går genom linjen. Grupp 2 använder värdet på temperatur- och trycksensorerna. En tillståndsgrupp kan ha olika tillstånd beroende på vilka värden den får. I det här exemplet får grupp 1 data om att maskinen är igång och enlitersflaskan väljs som produkt; detta ger denna grupp staten ACTIVE. Grupp 2 har mått för temperatur och tryck; båda mätvärdena är över sina tröskelvärden i mer än 5 minuter. Detta resulterar i att grupp 2 är i en WARNING stat. Det betyder att grupp 1 rapporterar att allt är bra och grupp 2 inte. I steg 2 läggs vikter till grupperna. Detta behövs i vissa situationer, eftersom grupper kan rapportera motstridig information. I det här scenariot rapporterar grupp 1 ACTIVE och grupp 2 rapporter WARNING, så det är inte klart för systemet vad linjens tillstånd är. Efter att ha lagt till vikterna kan tillstånden rangordnas, som visas i steg 3. Slutligen väljs den högst rankade staten som vinnande, som visas i steg 4.
Efter att reglerna har utvärderats och det slutliga maskintillståndet har definierats, kommer resultaten att bearbetas ytterligare. Åtgärden som vidtas beror på regelkonfigurationen; detta kan vara ett meddelande till linjeoperatören om att fylla på material, göra lite underhåll eller bara en visuell uppdatering på instrumentpanelen. Denna del av systemet, som utvärderar mått och regler och vidtar åtgärder baserat på resultaten, kallas en regelmotor.
Skala regelmotorn
Genom att låta användare bygga sina egna regler kan regelmotorn ha ett stort antal regler som den behöver utvärdera, och vissa regler kan använda samma sensordata som andra regler. Flink är ett distribuerat system som skalar väldigt bra horisontellt. För att distribuera en dataström till flera uppgifter kan du använda keyBy() metod. Detta gör att du kan partitionera en dataström på ett logiskt sätt och skicka delar av datan till olika uppgiftshanterare. Detta görs ofta genom att man väljer en godtycklig nyckel så man får en jämnt fördelad belastning. I det här fallet lade Krones till en ruleId till datapunkten och använde den som en nyckel. Annars bearbetas datapunkter som behövs av en annan uppgift. Den nyckeldataströmmen kan användas över alla regler precis som en vanlig variabel.
Resmål
När en regel ändrar tillstånd skickas informationen till en Kinesis-ström och sedan via Amazon EventBridge till konsumenterna. En av konsumenterna skapar en avisering från händelsen som sänds till produktionslinjen och varnar personalen att agera. För att kunna analysera regeltillståndsförändringarna skriver en annan tjänst data till en Amazon DynamoDB tabell för snabb åtkomst och en TTL finns på plats för att ladda ner långtidshistorik till Amazon S3 för vidare rapportering.
Slutsats
I det här inlägget visade vi dig hur Krones byggde ett produktionslinjeövervakningssystem i realtid på AWS. Managed Service för Apache Flink gjorde att Krones-teamet kunde komma igång snabbt genom att fokusera på applikationsutveckling snarare än infrastruktur. Flinks realtidsfunktioner gjorde det möjligt för Krones att minska maskinens stilleståndstid med 10 % och öka effektiviteten med upp till 5 %.
Om du vill bygga dina egna streamingapplikationer, kolla in de tillgängliga exemplen på GitHub repository. Om du vill utöka din Flink-applikation med anpassade kontakter, se Gör det enklare att bygga anslutningar med Apache Flink: Introduktion av Async Sink. Async Sink är tillgänglig i Apache Flink version 1.15.1 och senare.
Om författarna
 Florian Mair är senior lösningsarkitekt och dataströmningsexpert på AWS. Han är en teknolog som hjälper kunder i Europa att lyckas och förnya sig genom att lösa affärsutmaningar med hjälp av AWS Cloud-tjänster. Förutom att arbeta som Solutions Architect är Florian en passionerad bergsbestigare och har klättrat på några av de högsta bergen i Europa.
Florian Mair är senior lösningsarkitekt och dataströmningsexpert på AWS. Han är en teknolog som hjälper kunder i Europa att lyckas och förnya sig genom att lösa affärsutmaningar med hjälp av AWS Cloud-tjänster. Förutom att arbeta som Solutions Architect är Florian en passionerad bergsbestigare och har klättrat på några av de högsta bergen i Europa.
 Emil Dietl är en Senior Tech Lead på Krones specialiserad på datateknik, med ett nyckelområde inom Apache Flink och mikrotjänster. Hans arbete omfattar ofta utveckling och underhåll av verksamhetskritisk programvara. Utanför sitt yrkesliv värdesätter han djupt att spendera kvalitetstid med sin familj.
Emil Dietl är en Senior Tech Lead på Krones specialiserad på datateknik, med ett nyckelområde inom Apache Flink och mikrotjänster. Hans arbete omfattar ofta utveckling och underhåll av verksamhetskritisk programvara. Utanför sitt yrkesliv värdesätter han djupt att spendera kvalitetstid med sin familj.
 Simon Peyer är en lösningsarkitekt på AWS baserad i Schweiz. Han är en praktisk doer och brinner för att koppla ihop teknik och människor som använder AWS Cloud-tjänster. Ett speciellt fokus för honom är dataströmning och automatiseringar. Förutom jobbet tycker Simon om sin familj, att vara utomhus och att vandra i bergen.
Simon Peyer är en lösningsarkitekt på AWS baserad i Schweiz. Han är en praktisk doer och brinner för att koppla ihop teknik och människor som använder AWS Cloud-tjänster. Ett speciellt fokus för honom är dataströmning och automatiseringar. Förutom jobbet tycker Simon om sin familj, att vara utomhus och att vandra i bergen.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoData.Network Vertical Generative Ai. Styrka dig själv. Tillgång här.
- PlatoAiStream. Web3 Intelligence. Kunskap förstärkt. Tillgång här.
- Platoesg. Kol, CleanTech, Energi, Miljö, Sol, Avfallshantering. Tillgång här.
- PlatoHealth. Biotech och kliniska prövningar Intelligence. Tillgång här.
- Källa: https://aws.amazon.com/blogs/big-data/krones-real-time-production-line-monitoring-with-amazon-managed-service-for-apache-flink/

