Beskrivning
Data är bränsle för IT-branschen och Datavetenskapsprojekt i dagens onlinevärld. IT-industrier är mycket beroende av realtidsinsikter som härrör från strömmande data källor. Att hantera och bearbeta strömmande data är det svåraste arbetet för Dataanalys. Vi vet att strömmande data är data som sänds ut med hög volym i en kontinuerlig bearbetning vilket innebär att datan ändras varje sekund. För att hantera denna data använder vi Confluent plattform – En självstyrd distribution av företagsklass Apache Kafka.
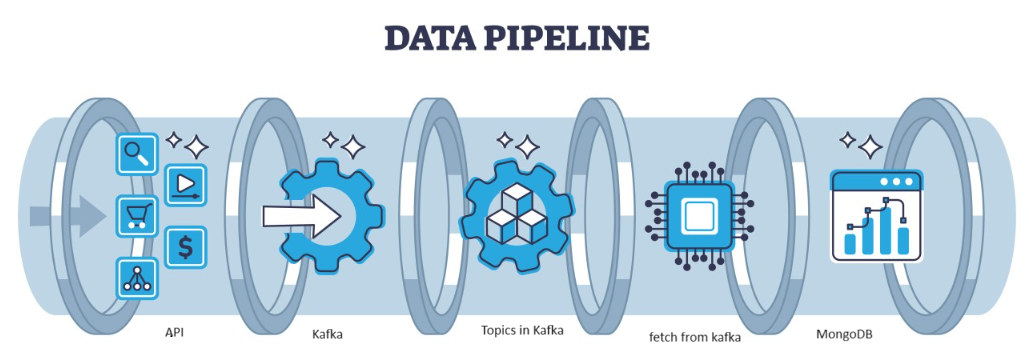
Kafka är ett distribuerat, fel som kan hanteras av arkitektur, vilket fungerar som ett populärt val för att hantera dataströmmar med hög genomströmning. Uppgifterna från Kafka samlas sedan in i MongoDB i form av samlingar. I den här artikeln kommer vi att skapa end-to-end pipeline där data hämtas med hjälp av API i Pipeline och sedan samlas in i Kafka i form av ämnen och sedan lagras i MongoDB därifrån vi kan använda den i projektet eller gör funktionstekniken.
Inlärningsmål
- Lär dig vad som är strömmande data och hur du hanterar strömmande data med hjälp av Kafka.
- Förstå Confluent Platform – En självstyrd distribution av Apache Kafka i företagsklass.
- Lagra data som samlas in av Kafka i MongoDB som är en NoSQL-databas som lagrar ostrukturerad data.
- Skapa en komplett pipeline för att hämta och lagra data i databasen.
Denna artikel publicerades som en del av Data Science Blogathon.
Innehållsförteckning
Identifiera problemet
För att hantera strömmande data som kommer från sensorn produceras fordon som innehåller sensordata per sekund och det är svårt att hantera och förbearbeta data för att använda i Data Science-projekt. Så för att ta itu med det här problemet skapar vi en end-to-end pipeline som hanterar data och lagrar data.
Vad är strömmande data?
Strömmande data är data som kontinuerligt genereras av olika källor som är ostrukturerad data. Det hänvisar till ett kontinuerligt flöde av data som genereras från olika källor i realtid eller nära realtid. I traditionell batchbehandling där data samlas in och denna strömmande data bearbetas allt eftersom den genereras. Strömmande data kan vara IOT-data som temperatursensorer och GPS-spårare, eller maskindata liknande data som genereras av maskiner och industriell utrustning som telemetridata från fordon och tillverkningsmaskiner. Det finns strömmande databehandlingsplattformar som Apache-Kafka.
Vad är Kafka?
Apache Kafka är en plattform som används för att bygga realtidsdatapipelines och streamingapplikationer. Kafka Streams API är ett kraftfullt bibliotek som möjliggör bearbetning i farten, som låter dig samla in och skapa fönsterparametrar, utföra kopplingar av data i en ström och mer. Apache Kafka består av ett lagringsskikt och ett beräkningsskikt som kombinerar effektiv dataintag i realtid, strömmande datapipelines och lagring över olika system.
Vad blir tillvägagångssättet?
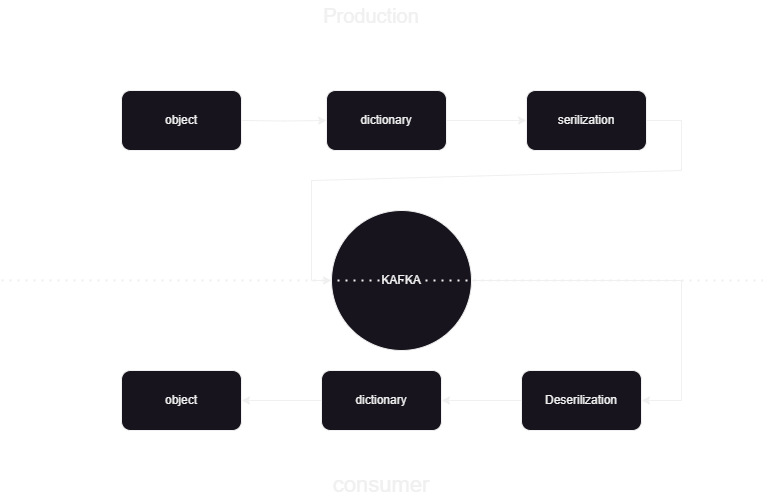
Det här är en pipeline för maskininlärning som hjälper oss att veta hur man publicerar och bearbetar data till och från Kafka confluent i JSON-format. Det finns två delar av kafka databehandling konsument och producent. För att lagra strömmande data från de olika producenterna och lagra den i konfluent och sedan görs deserialisering på data och den data lagras i Databas.
Systemarkitektur översikt
Vi bearbetar strömmande data med hjälp av confluent kafka och Kafka är uppdelad i två tvådelade:
- Kafka-producent: Kafka-producenten ansvarar för att producera och skicka data till Kafka-ämnen.
- Kafka Consumer: Kafka Consumer är att läsa och bearbeta data från Kafka-ämnena.
Start
│
├─ Kafka Consumer (Read from Kafka Topic)
│ ├─ Process Message
│ └─ Store Data in MongoDB
│
├─ Kafka Producer (Generate Sensor Data)
│ ├─ Send Data to Kafka Topic
│ └─ Repeat
│
End
Vad är komponenter?
- ämnen: Ämnen är logiska kanaler eller kategorier som publiceras av producenter. Varje ämne är uppdelat i en eller flera partitioner, och varje ämne replikeras över flera mäklare för feltolerans. Producenter publicerar data om specifika ämnen och konsumenter prenumererar på ämnen för att använda data.
- producenter: En Apache Kafka Producer är en klientapplikation som publicerar (skriver) händelser till ett Kafka-kluster. Applikationer som skickar data till ämnen kallas Kafka-producenter. Detta avsnitt ger en översikt över Kafka-producenten.
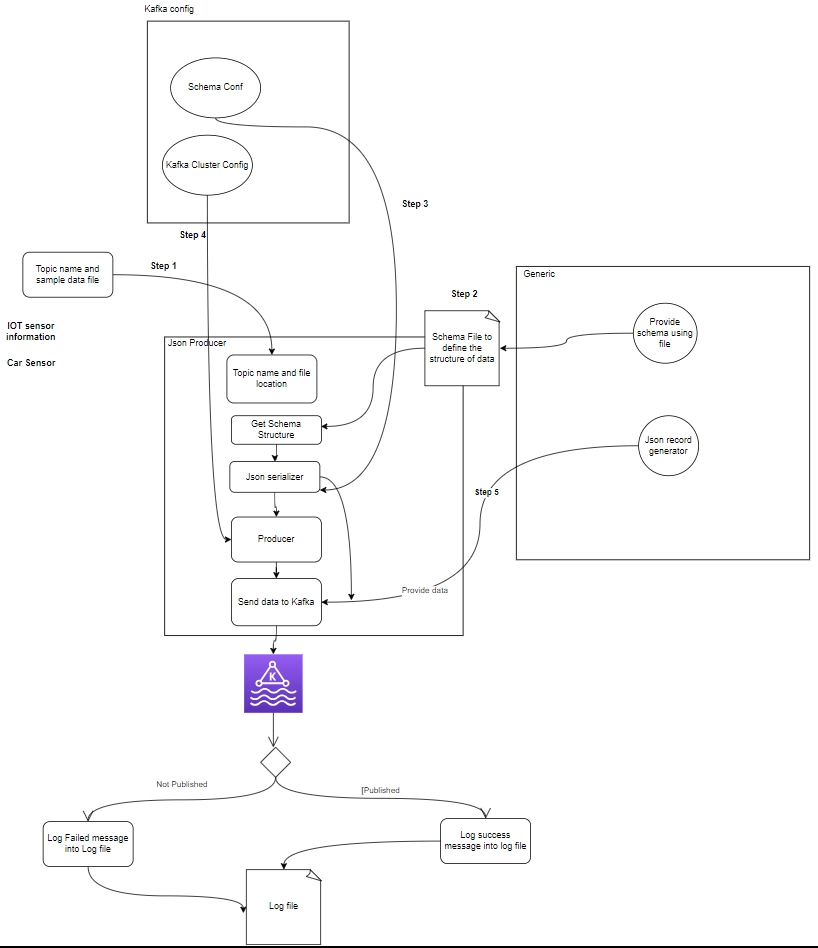
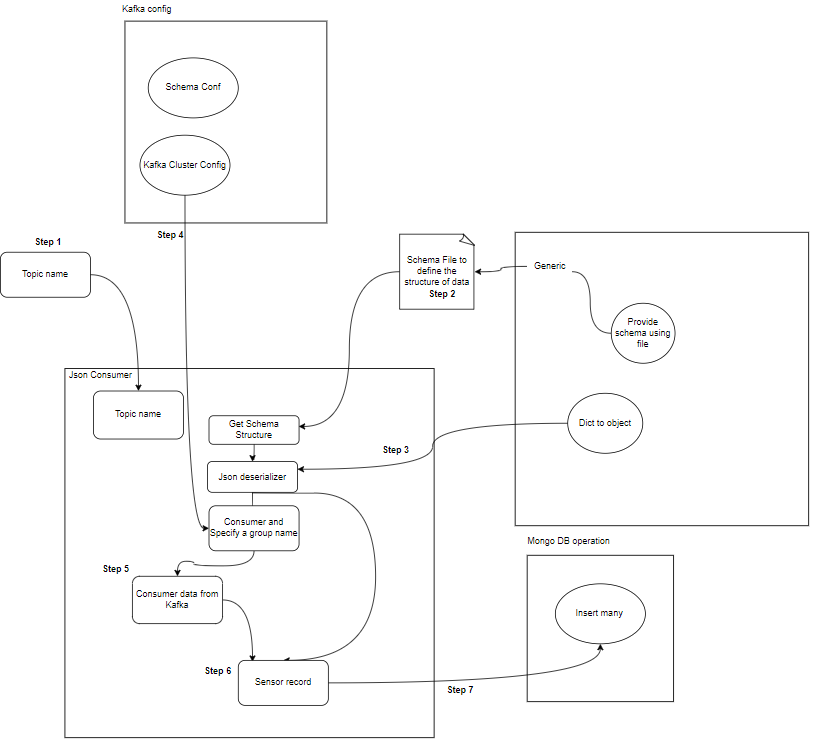
- Konsument: Kafka-konsumenter är ansvariga för att läsa data och bearbeta från Kafka-ämnen och bearbeta dem. Konsumenter kan vara en del av alla program som behöver använda och reagera på data från Kafka. De prenumererar på ett eller flera ämnen och data från Kafka-mäklare. Konsumenter kan organiseras i konsumentgrupper, där varje konsumentgrupp har en eller flera konsumenter och varje ämne i ett ämne konsumeras av endast en konsument inom gruppen. Detta möjliggör parallell bearbetning och lastbalansering av dataförbrukning.
Vad är projektstrukturen?
Detta visar flödesschemat för projektet hur mappen och filerna är uppdelade i projektet:
flowchart/
│
├── consumer.drawio.svg
├── flow of kafka.drawio
└── producer.drawio.svg
sample_data/
│
└── aps_failure_training_set1.csv
env/
sensor_data-pipeline_kafka
/
│
├── src/
│ ├── database/
│ │ ├── mongodb.py
│ │
│ ├── kafka_config/
│ │ └──__init__.py/
│ │
│ │
│ ├── constant/
│ │ ├── __init__.py
│ │
│ │
│ ├── data_access/
│ │ ├── user_data.py
│ │ └── user_embedding_data.py
│ │
│ ├── entity/
│ │ ├── __init__.py
│ │ └── generic.py
│ │
│ ├── exception/
│ │ └── (exception handling)
│ │
│ ├── kafka_logger/
│ │ └── (logging configuration)
│ │
│ ├── kafka_consumer/
│ │ └── util.py
│ │
│ └── __init__.py
│
└── logs/
└── (log files)
.dockerignore
.gitignore
Dockerfile
schema.json
consumer_main.py
producer_main.py
requirments.txt
setup.py- Kafka producent: Producenten är huvuddelen som genererar sensordata (t.ex. från CSV-filer i sample_data/) och publicerar den till ett Kafka-ämne. feltillstånd som kan uppstå under datagenerering eller publicering.
- Kafka mäklare: Kafka-mäklare lagrar och replikerar data över Kafka-klustret, hanterar datapartitionering och säkerställer feltolerans och hög tillgänglighet.
- Kafka konsument(er): Konsumenter läser data från Kafka-ämnen, bearbetar dem (t.ex. transformationer, aggregationer) och lagrar dem i MongoDB. De övervakar också feltillstånd som kan uppstå under databehandling.
- MongoDB: MongoDB lagrar sensordata som tas emot från Kafka-konsumenter. Den tillhandahåller en fråga för datahämtning och säkerställer datahållbarhet genom replikering och feltoleransmekanismer.
Start
│
├── Kafka Producer ──────────────────┐
│ ├── Generate Sensor Data │
│ └── Publish Data to Kafka Topic │
│ │
│ └── Error Handling
│ │
├── Kafka Broker(s) ─────────────────┤
│ ├── Store and Replicate Data │
│ └── Handle Data Partitioning │
│ │
├── Kafka Consumer(s) ───────────────┤
│ ├── Read Data from Kafka Topic │
│ ├── Process Data │
│ └── Store Data in MongoDB │
│ │
│ └── Error Handling
│ │
├── MongoDB ────────────────────────┤
│ ├── Store Sensor Data │
│ ├── Provide Query Interface │
│ └── Ensure Data Durability │
│ │
└── End │
Förutsättningar för datalagring
Sammanflytande Kafka
- Skapa konto: För att förstå Kafka behöver du Confluent Du älskar Apache Kafka®, men inte hantera det. Molnbaserad, komplett och helt hanterad tjänst går utöver Kafka så att dina bästa människor kan fokusera på att leverera värde till ditt företag.
- Skapa ämnen:
- Gå till startsidan och på sidofältet
- Gå till Miljö och klicka sedan på Standard
- Gå till ämnena

- välj Nytt ämne ange namnet på ämnet

MongoDB
Skapa registrering och logga sedan in på MongoDB Atlas och spara anslutningslänken till Mongodb Atlas för vidare användning.
Steg-för-steg-guide för projektinställning
- Python-installation: Se till att Python är installerat på din maskin. Du kan ladda ner och installera Python från den officiella hemsidan.
- Conda version: Kontrollera conda versionen i terminalen.
- Skapande av virtuell miljö: Skapa en virtuell miljö med hjälp av venv.
conda create -p venv python==3.10 -y- Aktivering av virtuell miljö: Aktivera den virtuella miljön:
conda activate venv/- Installera nödvändiga paket: Använd pip för att installera de nödvändiga beroenden som anges i filen requirements.txt:
pip install -r requirements.txt- vi måste ställa in några av miljövariablerna i det lokala systemet. Detta är den sammanflytande molnet Cluster Environment Variable
API_KEY
API_SECRET_KEY
BOOTSTRAP_SERVER
SCHEMA_REGISTRY_API_KEY
SCHEMA_REGISTRY_API_SECRET
ENDPOINT_SCHEMA_URL
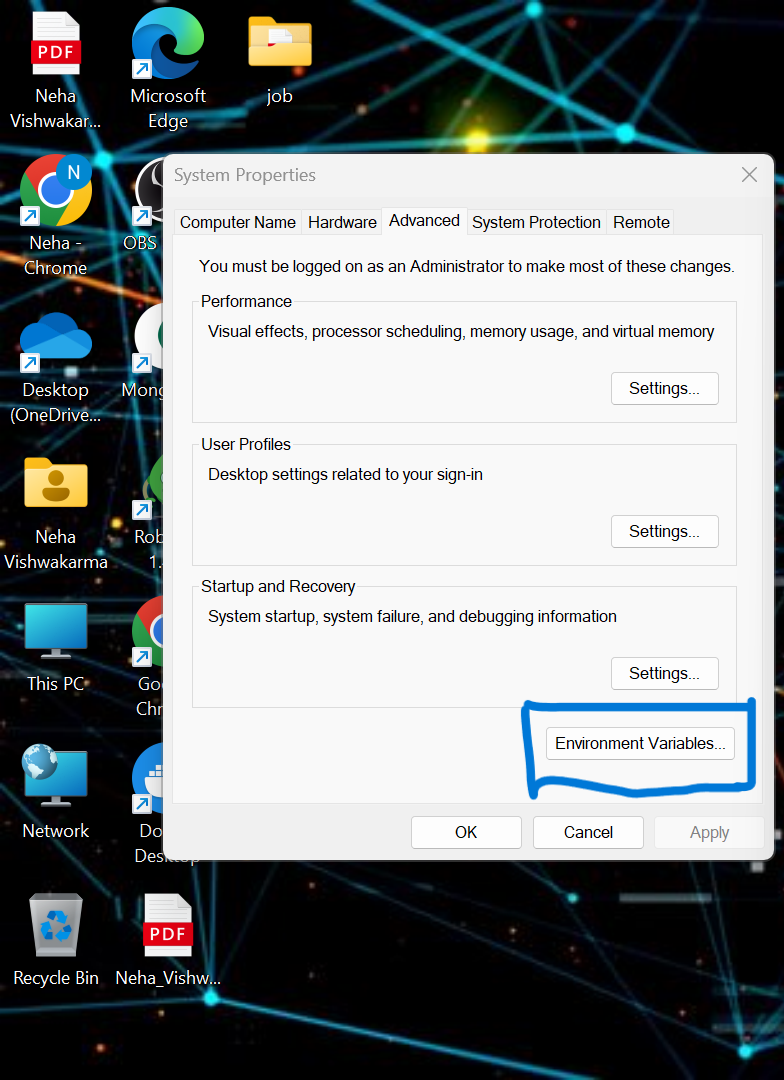
Uppdatera referensen i .env-filen och kör kommandot nedan för att köra din applikation i docker.
- Skapa .env-fil i root dir för ditt projekt om den inte är tillgänglig, klistra in innehållet nedan och uppdatera referenserna
API_KEY=asgdakhlsa
API_SECRET_KEY=dsdfsdf
BOOTSTRAP_SERVER=sdfasd
SCHEMA_REGISTRY_API_KEY=sdfsaf
SCHEMA_REGISTRY_API_SECRET=sdfasdf
ENDPOINT_SCHEMA_URL=sdafasf
MONGO_DB_URL=sdfasdfas
- Köra producent- och konsumentfilen:
python producer_main.py
python consumer_main.pyHur implementerar man kod?
- src/: Denna katalog är huvudmappen för alla källkodsfiler. I den här katalogen har vi följande underkataloger:
konsument/: Denna katalog innehåller koden för Kafka_konsumenten, ansvarig för att läsa data från Kafka-ämnen och bearbeta den.
producent/: Denna katalog innehåller koden för Kafka_producer, ansvarig för att generera och skicka sensordata till Kafka-ämnen. - README.md: Denna Markdown-fil innehåller dokumentation och instruktioner för projektet, inklusive en översikt över dess syfte, instruktioner, riktlinjer för användning och all information.
- requirements.txt: Den här filen listar Python-biblioteket som krävs för projektet. Varje beroende listas tillsammans med dess versionsnummer. Verktyg som pip kan använda den här filen för att installera nödvändiga beroenden automatiskt.
sensor_data-pipeline_kafka/
│
├── src/
│ ├── consumer/
│ │ ├── __init__.py
│ │ └── kafka_consumer.py
│ │
│ ├── producer/
│ │ ├── __init__.py
│ │ └── kafka_producer.py
│ │
│ └── __init__.py
│
├── README.md
└── requirements.txt
mongodb.py: För att ansluta MongoDB Altas via länken skriver vi python-skriptet
import pymongo
import os
import certifi
ca = certifi.where()
db_link ="mongodb+srv://Neha:<password>@cluster0.jsogkox.mongodb.net/"
class MongodbOperation:
def __init__(self) -> None:
#self.client = pymongo.MongoClient(os.getenv('MONGO_DB_URL'),tlsCAFile=ca)
self.client = pymongo.MongoClient(db_link,tlsCAFile=ca)
self.db_name="NehaDB"
def insert_many(self,collection_name,records:list):
self.client[self.db_name][collection_name].insert_many(records)
def insert(self,collection_name,record):
self.client[self.db_name][collection_name].insert_one(record)
ange din URL som är en kopia från MongoDb Altas
Produktion:
from src.kafka_producer.json_producer import product_data_using_file
from src.constant import SAMPLE_DIR
import os
if __name__ == '__main__':
topics = os.listdir(SAMPLE_DIR)
print(f'topics: [{topics}]')
for topic in topics:
sample_topic_data_dir = os.path.join(SAMPLE_DIR,topic)
sample_file_path = os.path.join(sample_topic_data_dir,os.listdir(sample_topic_data_dir)[0])
product_data_using_file(topic=topic,file_path=sample_file_path)
Den här filen körs sedan vi anropar den python producer_main.py och detta kommer att anropa nedanstående fil:
import argparse
from uuid import uuid4
from src.kafka_config import sasl_conf, schema_config
from six.moves import input
from src.kafka_logger import logging
from confluent_kafka import Producer
from confluent_kafka.serialization import StringSerializer, SerializationContext, MessageField
from confluent_kafka.schema_registry import SchemaRegistryClient
from confluent_kafka.schema_registry.json_schema import JSONSerializer
import pandas as pd
from typing import List
from src.entity.generic import Generic, instance_to_dict
FILE_PATH = "C:/Users/RAJIV/Downloads/ml-data-pipeline-main/sample_data/kafka-sensor-topic.csv"
def delivery_report(err, msg):
"""
Reports the success or failure of a message delivery.
Args:
err (KafkaError): The error that occurred on None on success.
msg (Message): The message that was produced or failed.
"""
if err is not None:
logging.info("Delivery failed for User record {}: {}".format(msg.key(), err))
return
logging.info('User record {} successfully produced to {} [{}] at offset {}'
.format(
msg.key(), msg.topic(), msg.partition(), msg.offset()))
def product_data_using_file(topic,file_path):
logging.info(f"Topic: {topic} file_path:{file_path}")
schema_str = Generic.get_schema_to_produce_consume_data(file_path=file_path)
schema_registry_conf = schema_config()
schema_registry_client = SchemaRegistryClient(schema_registry_conf)
string_serializer = StringSerializer('utf_8')
json_serializer = JSONSerializer(schema_str, schema_registry_client,
instance_to_dict)
producer = Producer(sasl_conf())
print("Producing user records to topic {}. ^C to exit.".format(topic))
# while True:
# Serve on_delivery callbacks from previous calls to produce()
producer.poll(0.0)
try:
for instance in Generic.get_object(file_path=file_path):
print(instance)
logging.info(f"Topic: {topic} file_path:{instance.to_dict()}")
producer.produce(topic=topic,
key=string_serializer(str(uuid4()), instance.to_dict()),
value=json_serializer(instance,
SerializationContext(topic, MessageField.VALUE)),
on_delivery=delivery_report)
print("nFlushing records...")
producer.flush()
except KeyboardInterrupt:
pass
except ValueError:
print("Invalid input, discarding record...")
pass
Produktion:

from src.kafka_consumer.json_consumer import consumer_using_sample_file
from src.constant import SAMPLE_DIR
import os
if __name__=='__main__':
topics = os.listdir(SAMPLE_DIR)
print(f'topics: [{topics}]')
for topic in topics:
sample_topic_data_dir = os.path.join(SAMPLE_DIR,topic)
sample_file_path = os.path.join(sample_topic_data_dir,os.listdir(sample_topic_data_dir)[0])
consumer_using_sample_file(topic="kafka-sensor-topic",file_path = sample_file_path)
Den här filen körs sedan vi anropar den python consumer_main.py och detta kommer att anropa nedanstående fil:
import argparse
from confluent_kafka import Consumer
from confluent_kafka.serialization import SerializationContext, MessageField
from confluent_kafka.schema_registry.json_schema import JSONDeserializer
from src.entity.generic import Generic
from src.kafka_config import sasl_conf
from src.database.mongodb import MongodbOperation
def consumer_using_sample_file(topic,file_path):
schema_str = Generic.get_schema_to_produce_consume_data(file_path=file_path)
json_deserializer = JSONDeserializer(schema_str,
from_dict=Generic.dict_to_object)
consumer_conf = sasl_conf()
consumer_conf.update({
'group.id': 'group7',
'auto.offset.reset': "earliest"})
consumer = Consumer(consumer_conf)
consumer.subscribe([topic])
mongodb = MongodbOperation()
records = []
x = 0
while True:
try:
# SIGINT can't be handled when polling, limit timeout to 1 second.
msg = consumer.poll(1.0)
if msg is None:
continue
record: Generic = json_deserializer(msg.value(),
SerializationContext(msg.topic(), MessageField.VALUE))
# mongodb.insert(collection_name="car",record=car.record)
if record is not None:
records.append(record.to_dict())
if x % 5000 == 0:
mongodb.insert_many(collection_name="sensor", records=records)
records = []
x = x + 1
except KeyboardInterrupt:
break
consumer.close()Produktion:

När vi kör både konsument och producent så körs systemet på kafkan och informationen/data samlas in snabbare

Produktion:
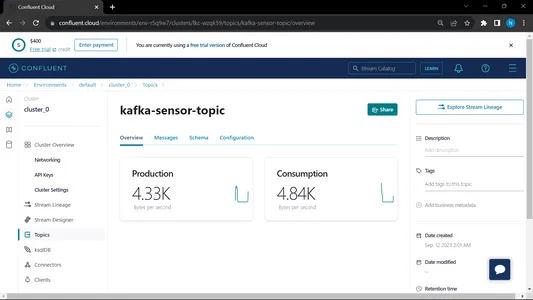
Från MongoDB använder vi dessa data för att förbearbeta i EDA, funktionsteknik och dataanalysarbete utförs på dessa data.
[Inbäddat innehåll]
Slutsats
I den här artikeln förstår vi hur vi lagrar och bearbetar strömmande data från sensorn till Kafka i form av JSON-format och sedan lagrar vi data till MongoDB. Vi vet att strömmande data är data som sänds ut med hög volym i en kontinuerlig bearbetning vilket innebär att datan ändras varje sekund. Vi har skapat end-to-end pipeline där data hämtas med hjälp av API i Pipeline och sedan samlas in i Kafka i form av ämnen och sedan lagras i MongoDB därifrån vi kan använda den i projektet eller göra funktionsteknik.
Key Takeaways
- Lär dig vad som är strömmande data och hur du hanterar strömmande data med hjälp av Kafka.
- förstå Confluent Platform – En självstyrd distribution av Apache Kafka i företagsklass.
- lagra data som samlas in av Kafka i MongoDB som är en NoSQL-databas som lagrar ostrukturerad data.
- Skapa en komplett pipeline för att hämta och lagra data i databasen.
- förstå funktionaliteten för varje komponent i projektet implementera den på docker och implementera den på ett moln att använda när som helst.
Resurser
Vanliga frågor
A. MongoDB lagrar data i ostrukturerad data. strömmande data är ostrukturerade former av data för minnesanvändning vi använder MongoDB som databas.
S. Syftet är att skapa en databearbetningspipeline i realtid där data som tas in i Kafka-ämnen kan konsumeras, bearbetas och lagras i MongoDB för vidare analys, rapportering eller användning av applikationer.
S. Användningsfall inkluderar realtidsanalys, IoT-databearbetning, loggaggregation, övervakning av sociala medier och rekommendationssystem, där strömmande data behöver bearbetas och lagras för vidare analys eller användning av applikationer.
Medierna som visas i den här artikeln ägs inte av Analytics Vidhya och används efter författarens gottfinnande.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoData.Network Vertical Generative Ai. Styrka dig själv. Tillgång här.
- PlatoAiStream. Web3 Intelligence. Kunskap förstärkt. Tillgång här.
- Platoesg. Kol, CleanTech, Energi, Miljö, Sol, Avfallshantering. Tillgång här.
- PlatoHealth. Biotech och kliniska prövningar Intelligence. Tillgång här.
- Källa: https://www.analyticsvidhya.com/blog/2024/02/kafka-to-mongodb-building-a-streamlined-data-pipeline/

