Beskrivning
I det ständigt föränderliga landskapet av artificiell intelligens har två nyckelspelare gått samman för att bryta ny mark: Generativ AI och Reinforcement Learning. Dessa banbrytande teknologier, Generative AI och Reinforcement Learning, har potential att skapa självförbättrande AI-system, vilket tar oss ett steg närmare att förverkliga drömmen om maskiner som lär sig och anpassar sig autonomt. Dessa verktyg banar väg för AI-system som kan förbättra sig själva och för oss närmare idén om maskiner som kan lära sig och anpassa sig på egen hand.

AI har gjort anmärkningsvärda underverk de senaste åren, från att förstå mänskligt språk till att hjälpa datorer att se och tolka världen runt dem. Generativa AI-modeller som GPT-3 och Reinforcement Learning-algoritmer som Deep Q-Networks står i spetsen för detta framsteg. Även om dessa teknologier har varit transformativa individuellt, öppnar deras konvergens upp nya dimensioner av AI-kapacitet och tänjer på världens gränser till lätthet.
Inlärningsmål
- Skaffa erforderlig och djupgående kunskap om Reinforcement Learning och dess algoritmer, belöningsstrukturer, det allmänna ramverket för Reinforcement Learning och statliga åtgärder för att förstå hur agenter fattar beslut.
- Undersök hur dessa två grenar kan kombineras symbiotiskt för att skapa mer adaptiva, intelligenta system, särskilt i beslutsfattande scenarier.
- Studera och analysera olika fallstudier som visar effektiviteten och anpassningsförmågan av att integrera Generativ AI med Reinforcement Learning inom områden som hälsovård, autonoma fordon och innehållsskapande.
- Bekanta dig med Python-bibliotek som TensorFlow, PyTorch, OpenAI's Gym och Googles TF-Agents för att få praktisk kodningserfarenhet av att implementera dessa tekniker.
Denna artikel publicerades som en del av Data Science Blogathon.
Innehållsförteckning
Generativ AI: Ge maskiner kreativitet
Generativ AI modeller, som OpenAI:s GPT-3, är designade för att generera innehåll, oavsett om det är naturligt språk, bilder eller till och med musik. Dessa modeller bygger på principen att förutsäga vad som kommer härnäst i ett givet sammanhang. De har använts för allt från automatiserad innehållsgenerering till chatbots som kan efterlikna mänskliga samtal. Kännetecknet för Generativ AI är dess förmåga att skapa något nytt utifrån mönstren den lär sig.
Förstärkningsinlärning: Lära AI att fatta beslut
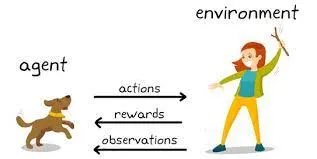
Förstärkningslärande (RL) är ett annat banbrytande område. Det är tekniken som gör att artificiell intelligens kan lära sig av försök och misstag, precis som en människa skulle göra. Det har använts för att lära AI att spela komplexa spel som Dota 2 och Go. RL-agenter lär sig genom att få belöningar eller straff för sina handlingar och använder denna feedback för att förbättra sig över tid. På sätt och vis ger RL AI en form av autonomi, vilket gör att den kan fatta beslut i dynamiska miljöer.
Ramen för förstärkt lärande
I det här avsnittet kommer vi att avmystifiera nyckelramen för förstärkt lärande:
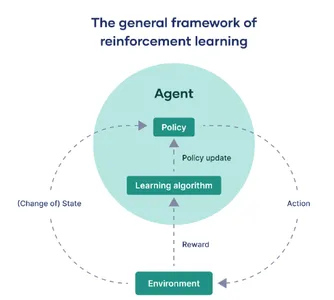
Den tillförordnade enheten: Agenten
Inom området för artificiell intelligens och maskininlärning hänvisar termen "agent" till den beräkningsmodell som har till uppgift att interagera med en utsedd extern miljö. Dess primära roll är att fatta beslut och vidta åtgärder för att antingen uppnå ett definierat mål eller samla maximala belöningar över en sekvens av steg.
Världen runt: Miljön
"Miljön" betyder det externa sammanhanget eller systemet där agenten verkar. I grund och botten utgör den varje faktor som ligger utanför agentens kontroll, men ändå observerbar. Detta kan variera från ett virtuellt spelgränssnitt till en verklig miljö, som en robot som navigerar genom en labyrint. Miljön är "grundsanningen" mot vilken agentens prestation utvärderas.
Navigera övergångar: Tillståndsändringar
På jargongen för förstärkningsinlärning beskriver "tillstånd" eller betecknat med "s", de olika scenarier som agenten kan hamna i när han interagerar med omgivningen. Dessa tillståndsövergångar är avgörande; de informerar agentens observationer och påverkar i hög grad dess framtida beslutsmekanismer.
Beslutsregelboken: Policy
Termen "policy" kapslar in agentens strategi för att välja åtgärder som motsvarar olika tillstånd. Det fungerar som en funktion som kartlägger från staternas domän till en uppsättning handlingar, som definierar agentens modus operandi i sin strävan att uppnå sina mål.
Förfining över tid: Policyuppdateringar
"Policyuppdatering" hänvisar till den iterativa processen att justera agentens befintliga policy. Detta är en dynamisk aspekt av förstärkningsinlärning, vilket gör att agenten kan optimera sitt beteende baserat på historiska belöningar eller nyvunna erfarenheter. Det underlättas genom specialiserade algoritmer som omkalibrerar agentens strategi.
Anpassningsmotorn: Inlärningsalgoritmer
Inlärningsalgoritmer tillhandahåller det matematiska ramverket som gör det möjligt för agenten att förfina sin policy. Beroende på sammanhanget kan dessa algoritmer brett kategoriseras i modellfria metoder, som lär sig direkt från verkliga interaktioner, och modellbaserade tekniker som utnyttjar en simulerad modell av miljön för lärande.
Måttet på framgång: belöningar
Slutligen är "belöningar" kvantifierbara mätvärden, dispenserade av omgivningen, som mäter den omedelbara effekten av en åtgärd som utförs av agenten. Agentens övergripande mål är att maximera summan av dessa belöningar under en period, vilket effektivt fungerar som dess prestationsmått.
I ett nötskal kan förstärkningsinlärning destilleras till en kontinuerlig interaktion mellan agenten och dess omgivning. Agenten går igenom olika tillstånd, fattar beslut baserat på en specifik policy och får belöningar som fungerar som feedback. Inlärningsalgoritmer används för att iterativt finjustera denna policy, vilket säkerställer att agenten alltid är på väg mot optimerat beteende inom ramen för sin omgivning.
Synergin: Generativ AI möter förstärkningsinlärning

Den verkliga magin händer när Generativ AI möter Reinforcement Learning. AI-forskare har experimenterat och forskat med att kombinera dessa två domäner AI och Reinforcement learning för att skapa system eller anordningar som inte bara kan generera innehåll utan också lära sig av användarfeedback för att förbättra sin produktion och få bättre AI-innehåll.
- Inledande innehållsgenerering: Generativ AI, som GPT-3, genererar innehåll baserat på en given input eller kontext. Detta innehåll kan vara allt från artiklar till konst.
- Användarfeedback loop: När innehållet har genererats och presenterats för användaren blir all feedback som ges en värdefull tillgång för att träna AI-systemet ytterligare.
- Förstärkningsinlärning (RL) Mekanism: Med hjälp av denna feedback från användare går Reinforcement Learning-algoritmer in för att utvärdera vilka delar av innehållet som uppskattades och vilka delar som behöver förfinas.
- Adaptivt innehållsgenerering: Informerad av denna analys anpassar Generative AI sedan sina interna modeller för att bättre anpassa sig till användarnas preferenser. Den förfinar sin produktion iterativt och inkluderar lärdomar från varje interaktion.
- Fusion of Technology: Kombinationen av Generativ AI och Reinforcement Learning skapar ett dynamiskt ekosystem där genererat innehåll fungerar som en lekplats för RL-agenten. Användarfeedback fungerar som en belöningssignal som styr AI:n om hur man kan förbättra sig.
Denna kombination av generativ AI och förstärkningsinlärning möjliggör ett mycket adaptivt system och kan även lära sig av mänsklig feedback från verkliga återkopplingar, vilket möjliggör mer användaranpassade och effektiva resultat och för att få bättre resultat som överensstämmer med mänskliga behov.
Kodavsnittssynergi
Låt oss förstå synergin mellan Generativ AI och Reinforcement Learning:
import torch
import torch.nn as nn
import torch.optim as optim # Simulated Generative AI model (e.g., a text generator)
class GenerativeAI(nn.Module): def __init__(self): super(GenerativeAI, self).__init__() # Model layers self.fc = nn.Linear(10, 1) # Example layer def forward(self, input): output = self.fc(input) # Generate content, for this example, a number return output # Simulated User Feedback
def user_feedback(content): return torch.rand(1) # Mock user feedback # Reinforcement Learning Update
def rl_update(model, optimizer, reward): loss = -torch.log(reward) optimizer.zero_grad() loss.backward() optimizer.step() # Initialize model and optimizer
gen_model = GenerativeAI()
optimizer = optim.Adam(gen_model.parameters(), lr=0.001) # Iterative improvement
for epoch in range(100): content = gen_model(torch.randn(1, 10)) # Mock input reward = user_feedback(content) rl_update(gen_model, optimizer, reward)
Kodförklaring
- Generativ AI-modell: Det är som en maskin som försöker generera innehåll, som en textgenerator. I det här fallet är den utformad för att ta lite input och producera en output.
- Användarfeedback: Föreställ dig att användare ger feedback om innehållet som AI genererar. Denna feedback hjälper AI att lära sig vad som är bra eller dåligt. I den här koden använder vi slumpmässig feedback som exempel.
- Uppdatering av förstärkningsinlärning: Efter att ha fått feedback uppdaterar AI sig själv för att bli bättre. Den justerar sina interna inställningar för att förbättra innehållsgenereringen.
- Iterativ förbättring: AI:n går igenom många cykler (100 gånger i den här koden) för att generera innehåll, få feedback och lära av det. Med tiden blir den bättre på att skapa önskat innehåll.
Denna kod definierar en grundläggande generativ AI-modell och en återkopplingsslinga. AI:n genererar innehåll, får slumpmässig feedback och justerar sig själv över 100 iterationer för att förbättra dess förmåga att skapa innehåll.
I en verklig applikation skulle du använda en mer sofistikerad modell och mer nyanserad användarfeedback. Det här kodavsnittet fångar dock essensen av hur Generative AI och Reinforcement Learning kan harmonisera för att bygga ett system som inte bara genererar innehåll utan också lär sig att förbättra det baserat på feedback.
Verkliga applikationer
Möjligheterna som uppstår från synergin mellan Generative AI och Reinforcement Learning är oändliga. Låt oss ta en titt på de verkliga tillämpningarna:
Innehållsgenerering
Innehåll skapat av AI kan bli allt mer personligt anpassat, anpassat efter individuella användares smaker och preferenser.
Tänk på ett scenario där en RL-agent använder GPT-3 för att generera ett personligt nyhetsflöde. Efter varje läst artikel ger användaren feedback. Låt oss här föreställa oss att feedback helt enkelt är "gilla" eller "ogilla", som omvandlas till numeriska belöningar.
from transformers import GPT2LMHeadModel, GPT2Tokenizer
import torch # Initialize GPT-2 model and tokenizer
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
model = GPT2LMHeadModel.from_pretrained('gpt2') # RL update function
def update_model(reward, optimizer): loss = -torch.log(reward) optimizer.zero_grad() loss.backward() optimizer.step() # Initialize optimizer
optimizer = torch.optim.Adam(model.parameters(), lr=0.001) # Example RL loop
for epoch in range(10): input_text = "Generate news article about technology." input_ids = tokenizer.encode(input_text, return_tensors='pt') with torch.no_grad(): output = model.generate(input_ids) article = tokenizer.decode(output[0]) print(f"Generated Article: {article}") # Get user feedback (1 for like, 0 for dislike) reward = float(input("Did you like the article? (1 for yes, 0 for no): ")) update_model(torch.tensor(reward), optimizer)Konst och musik
AI kan generera konst och musik som resonerar med mänskliga känslor och utvecklar sin stil baserat på feedback från publiken. En RL-agent kan optimera parametrarna för en neural stilöverföringsalgoritm baserat på feedback för att skapa konst eller musik som bättre resonerar med mänskliga känslor.
# Assuming a function style_transfer(image, style) exists
# RL update function similar to previous example # Loop through style transfers
for epoch in range(10): new_art = style_transfer(content_image, style_image) show_image(new_art) reward = float(input("Did you like the art? (1 for yes, 0 for no): ")) update_model(torch.tensor(reward), optimizer)Konversations AI
Chatbots och virtuella assistenter kan delta i mer naturliga och sammanhangsmedvetna konversationer, vilket gör dem otroligt användbara i kundtjänst. Chatbots kan använda förstärkningsinlärning för att optimera sina samtalsmodeller baserat på konversationshistoriken och användarfeedback.
# Assuming a function chatbot_response(text, model) exists
# RL update function similar to previous examples for epoch in range(10): user_input = input("You: ") bot_response = chatbot_response(user_input, model) print(f"Bot: {bot_response}") reward = float(input("Was the response helpful? (1 for yes, 0 for no): ")) update_model(torch.tensor(reward), optimizer)Autonoma fordon
AI-system i autonoma fordon kan lära sig av verkliga körupplevelser, vilket ökar säkerheten och effektiviteten. En RL-agent i ett autonomt fordon kan justera sin väg i realtid baserat på olika belöningar som bränsleeffektivitet, tid eller säkerhet.
# Assuming a function drive_car(state, policy) exists
# RL update function similar to previous examples for epoch in range(10): state = get_current_state() # e.g., traffic, fuel, etc. action = drive_car(state, policy) reward = get_reward(state, action) # e.g., fuel saved, time taken, etc. update_model(torch.tensor(reward), optimizer)Dessa kodavsnitt är illustrativa och förenklade. De hjälper till att manifestera konceptet att Generative AI och RL kan samarbeta för att förbättra användarupplevelsen över olika domäner. Varje utdrag visar hur agenten iterativt förbättrar sin policy baserat på de mottagna belöningarna, liknande hur man iterativt kan förbättra en djupinlärningsmodell som Unet för radarbildssegmentering.
Fallstudier
Sjukvårdsdiagnos och behandlingsoptimering
- Problem: Inom vården är korrekt och snabb diagnos avgörande. Det är ofta utmanande för läkare att hålla jämna steg med stora mängder medicinsk litteratur och utvecklande bästa praxis.
- Lösning: Generativa AI-modeller som BERT kan extrahera insikter från medicinska texter. En RL-agent kan optimera behandlingsplaner baserat på historiska patientdata och ny forskning.
- Fallstudie: IBM:s Watson for Oncology använder Generativ AI och RL för att hjälpa onkologer att fatta behandlingsbeslut genom att analysera en patients journal mot omfattande medicinsk litteratur. Detta har förbättrat noggrannheten i behandlingsrekommendationerna.
Detaljhandel och personlig shopping
- Problem: Inom e-handel är det viktigt att anpassa shoppingupplevelser för kunderna för att öka försäljningen.
- Lösning: Generativ AI, som GPT-3, kan generera produktbeskrivningar, recensioner och rekommendationer. En RL-agent kan optimera dessa rekommendationer baserat på användarinteraktioner och feedback.
- Fallstudie: Amazon använder Generativ AI för att generera produktbeskrivningar och använder RL för att optimera produktrekommendationer. Detta har lett till en betydande ökning av försäljning och kundnöjdhet.
Skapande och marknadsföring av innehåll
- Problem: Marknadsförare måste skapa engagerande innehåll i stor skala. Det är utmanande att veta vad som kommer att få resonans hos publiken.
- Lösning: Generativ AI, som GPT-2, kan generera blogginlägg, innehåll i sociala medier och reklamtexter. RL kan optimera innehållsgenerering baserat på engagemangsstatistik.
- Fallstudie: HubSpot, en marknadsföringsplattform, använder generativ AI för att hjälpa till att skapa innehåll. De använder RL för att finjustera innehållsstrategier baserat på användarengagemang, vilket resulterar i effektivare marknadsföringskampanjer.
Utveckling av videospel
- Problem: Att skapa icke-spelare karaktärer (NPC) med realistiska beteenden och spelmiljöer som anpassar sig till spelarnas handlingar är komplext och tidskrävande.
- Lösning: Generativ AI kan designa spelnivåer, karaktärer och dialogrutor. RL-agenter kan optimera NPC-beteende baserat på spelarinteraktioner.
- Fallstudie: I spelindustrin använder studior som Ubisoft Generative AI för världsbyggande och RL för NPC AI. Detta tillvägagångssätt har resulterat i mer dynamiska och engagerande spelupplevelser.
Finansiell handel
- Problem: I den mycket konkurrensutsatta världen av finansiell handel kan det vara en utmaning att hitta lönsamma strategier.
- Lösning: Generativ AI kan hjälpa till med dataanalys och strategigenerering. RL-agenter kan lära sig och optimera handelsstrategier baserat på marknadsdata och användardefinierade mål.
- Fallstudie: Hedgefonder som Renaissance Technologies utnyttjar Generative AI och RL för att upptäcka lönsamma handelsalgoritmer. Detta har lett till betydande avkastning på investeringar.
Dessa fallstudier visar hur kombinationen av Generativ AI och Reinforcement Learning förändrar olika branscher genom att automatisera uppgifter, anpassa upplevelser och optimera beslutsprocesser.
Etiska betänkligheter
Rättvisa i AI
Att säkerställa rättvisa i AI-system är avgörande för att förhindra fördomar eller diskriminering. AI-modeller måste tränas på olika och representativa datauppsättningar. Att upptäcka och mildra bias i AI-modeller är en pågående utmaning. Detta är särskilt viktigt i domäner som utlåning eller uthyrning, där partiska algoritmer kan få allvarliga verkliga konsekvenser.
Ansvar och ansvar
När AI-systemen fortsätter att utvecklas blir ansvar och ansvar centralt. Utvecklare, organisationer och tillsynsmyndigheter måste definiera tydliga ansvarslinjer. Etiska riktlinjer och standarder måste upprättas för att hålla individer och organisationer ansvariga för AI-systemens beslut och åtgärder. Inom sjukvården, till exempel, är ansvarsskyldighet avgörande för att säkerställa patientsäkerhet och förtroende för AI-assisterad diagnos.
Transparens och förklaring
Den "svarta lådan" hos vissa AI-modeller är ett problem. För att säkerställa etisk och ansvarsfull AI är det viktigt att AI-beslutsprocesser är transparenta och begripliga. Forskare och ingenjörer bör arbeta med att utveckla AI-modeller som är förklarliga och ger insikt om varför ett specifikt beslut togs. Detta är avgörande för områden som straffrätt, där beslut som fattas av AI-system kan påverka individers liv avsevärt.
Datasekretess och samtycke
Att respektera dataintegriteten är en hörnsten i etisk AI. AI-system förlitar sig ofta på användardata, och att få informerat samtycke för dataanvändning är avgörande. Användare bör ha kontroll över sina uppgifter och det måste finnas mekanismer på plats för att skydda känslig information. Det här problemet är särskilt viktigt i AI-drivna personaliseringssystem, som rekommendationsmotorer och virtuella assistenter.
Skadebegränsning
AI-system bör utformas för att förhindra skapandet av skadlig, vilseledande eller falsk information. Detta är särskilt relevant inom området för innehållsgenerering. Algoritmer bör inte generera innehåll som främjar hatretorik, felaktig information eller skadligt beteende. Strängare riktlinjer och övervakning är avgörande på plattformar där användargenererat innehåll är utbrett.
Mänsklig tillsyn och etisk expertis
Mänsklig tillsyn är fortfarande avgörande. Även när AI blir mer autonom bör mänskliga experter inom olika områden arbeta tillsammans med AI. De kan göra etiska bedömningar, finjustera AI-system och ingripa när det behövs. Till exempel i autonoma fordon måste en mänsklig säkerhetsförare vara redo att ta kontroll i komplexa eller oförutsedda situationer.
Dessa etiska överväganden är i framkanten av AI-utveckling och implementering, vilket säkerställer att AI-tekniker gynnar samhället samtidigt som de upprätthåller principerna om rättvisa, ansvarsskyldighet och transparens. Att ta itu med dessa frågor är avgörande för en ansvarsfull och etisk integration av AI i våra liv.
Slutsats
Vi bevittnar en spännande era där Generativ AI och Reinforcement Learning börjar smälta samman. Denna konvergens banar vägen mot självförbättrande AI-system, kapabla till både innovativt skapande och effektivt beslutsfattande. Men med stor makt kommer ett stort ansvar. De snabba framstegen inom AI för med sig etiska överväganden som är avgörande för dess ansvarsfulla implementering. När vi ger oss ut på denna resa för att skapa AI som inte bara förstår utan också lär sig och anpassar sig, öppnar vi för gränslösa möjligheter för innovation. Icke desto mindre är det viktigt att gå framåt med etisk integritet och se till att den teknologi vi skapar tjänar som en kraft för det goda och gynnar mänskligheten som helhet.
Key Takeaways
- Generativ AI och Reinforcement Learning (RL) konvergerar för att skapa självförbättrande system, med det förra fokuserat på innehållsgenerering och det senare på beslutsfattande genom försök och misstag.
- I RL inkluderar nyckelkomponenter agenten, som fattar beslut; miljön som agenten interagerar med; och belöningar, som fungerar som prestationsmått. Policyer och inlärningsalgoritmer gör att agenten kan förbättras med tiden.
- Föreningen av Generativ AI och RL möjliggör system som genererar innehåll och anpassar sig baserat på användarfeedback, och därigenom förbättrar deras produktion iterativt.
- Ett Python-kodavsnitt illustrerar denna synergi genom att kombinera en simulerad Generativ AI-modell för innehållsgenerering med RL för att optimera baserat på användarfeedback.
- Verkliga applikationer är enorma, inklusive generering av personligt innehåll, skapande av konst och musik, konversations-AI och till och med autonoma fordon.
- Dessa kombinerade teknologier kan revolutionera hur AI interagerar med och anpassar sig till mänskliga behov och preferenser, vilket leder till mer personliga och effektiva lösningar.
Vanliga frågor
S. Genom att kombinera Generativ AI och Reinforcement Learning skapas intelligenta system som inte bara genererar ny data utan också optimerar dess effektivitet. Detta synergetiska förhållande breddar omfattningen och effektiviteten av AI-applikationer, vilket gör dem mer mångsidiga och anpassningsbara.
A. Reinforcement Learning fungerar som systemets kärna för beslutsfattande. Genom att använda en återkopplingsslinga centrerad kring belöningar utvärderar och anpassar den det genererade innehållet från Generative AI-modulen. Denna iterativa process optimerar datagenereringsstrategin över tid.
A. De praktiska tillämpningarna är breda. Inom vården kan denna teknik dynamiskt skapa och förfina behandlingsplaner med hjälp av patientdata i realtid. Samtidigt kan det inom fordonssektorn göra det möjligt för självkörande bilar att justera sin rutt i realtid som svar på fluktuerande vägförhållanden.
A. Python förblir det vanliga språket på grund av dess omfattande ekosystem. Bibliotek som TensorFlow och PyTorch används ofta för generativa AI-uppgifter, medan OpenAIs Gym och Googles TF-Agents är typiska val för implementering av Reinforcement Learning.
Medierna som visas i den här artikeln ägs inte av Analytics Vidhya och används efter författarens gottfinnande.
Relaterad
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoData.Network Vertical Generative Ai. Styrka dig själv. Tillgång här.
- PlatoAiStream. Web3 Intelligence. Kunskap förstärkt. Tillgång här.
- Platoesg. Kol, CleanTech, Energi, Miljö, Sol, Avfallshantering. Tillgång här.
- PlatoHealth. Biotech och kliniska prövningar Intelligence. Tillgång här.
- Källa: https://www.analyticsvidhya.com/blog/2023/10/generative-ai-and-reinforcement-learning/

