Beskrivning
I dagens digitala landskap är det ytterst viktigt att följa Know Your Customer-reglerna (KYC) för företag som verkar inom finansiella tjänster, onlinemarknadsplatser och andra sektorer som kräver användaridentifiering. Traditionellt har KYC-processer förlitat sig på manuell dokumentverifiering, en tidskrävande och felbenägen metod. Den här guiden går in på hur Amazon Rekognition, en kraftfull molnbaserad AI-tjänst från AWS, specialiserad på ansiktsigenkänning och analys, kan revolutionera din online-KYC-strategi och omvandla den till en strömlinjeformad, säker och kostnadseffektiv process.

Inlärningsmål
- Förstå vikten av Know Your Customer-regler (KYC) i olika branscher och utmaningarna i samband med manuella verifieringsprocesser.
- Utforska funktionerna hos Amazon Rekognition som en molnbaserad AI-tjänst som specialiserar sig på ansiktsigenkänning och analys.
- Lär dig stegen som är involverade i att implementera identitetsverifiering med Amazon Rekognition, inklusive användarintroduktion, text extraktion, detektering av livlighet, ansiktsanalys och ansiktsmatchning.
- Förstå betydelsen av att utnyttja AI-driven identitetsverifiering för att förbättra säkerhetsåtgärder, effektivisera användarautentiseringsprocesser och förbättra användarupplevelser.
Denna artikel publicerades som en del av Data Science Blogathon.
Innehållsförteckning
Förstå KYC-utmaningar
KYC-regler kräver att företag verifierar sina användares identitet mildra bedrägeri, penningtvätt och andra ekonomiska brott. Denna verifiering involverar vanligtvis insamling och validering av statligt utfärdade identifieringsdokument. Även om dessa regler är viktiga för att upprätthålla ett säkert finansiellt ekosystem skapar manuella verifieringsprocesser utmaningar:
- Pandemipåverkan: Under pandemin stod finanssektorn inför betydande utmaningar när det gäller att ta in nya kunder eftersom rörelsen var begränsad. Därför är manuell verifiering i bulk inte möjlig. Så genom att implementera online-KYC är ditt företag redo för sådana framtida evenemang.
- Mänskliga fel: Manuell verifiering är känslig för fel, vilket potentiellt gör att bedrägliga registreringar kan glida igenom stolarna.
- Hantera ID:n: Eftersom dokumentationen är en tryckt kopia är det en växande utmaning att hantera detsamma. Kopiorna kan gå vilse, brännas, stjälas, missbrukas osv.
Vad är Amazon Recognition?
Amazon Rekognition är en kraftfull bild- och videoanalystjänst som erbjuds av Amazon Web Services (AWS). Den använder avancerade maskininlärningsalgoritmer för att analysera visuellt innehåll i bilder och videor, vilket gör det möjligt för utvecklare att extrahera värdefulla insikter och utföra olika uppgifter som objektdetektering, ansiktsigenkänning och identitetsverifiering. Det förenklade diagrammet nedan ger en god uppfattning om funktionerna och tjänsterna som är involverade.
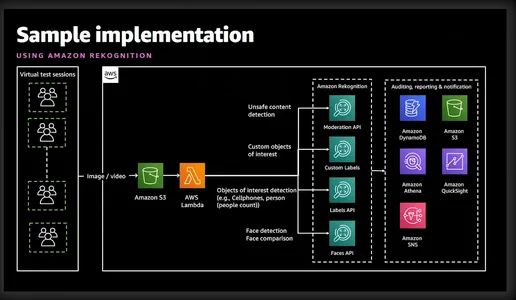
Identitetsverifiering med Amazon Rekognition
Innan jag tar dig till implementeringen, låt mig ge dig en idé på hög nivå och steg som är involverade i implementeringen av identitetsverifiering för vår Online KYC.
- Användarintroduktion: Denna process kommer att vara specifik för verksamheten. Däremot kommer företaget som ett minimum att behöva förnamn, mellannamn, efternamn, födelsedatum, utgångsdatum för ID-kort och foto i passstorlek. All denna information kan samlas in genom att be användaren att ladda upp en bild av ett nationellt ID-kort.
- Extrahera text: AWS Textract-tjänsten kan prydligt extrahera all ovanstående information från det uppladdade ID-kortet. Inte bara detta kan vi också fråga Textract för att hämta specifik information från ID-kortet.
- Livlighet och ansiktsigenkänning: För att se till att användaren som försöker göra sin KYC är aktiv på skärmen och är live när liveness-sessionen startar. Amazon Rekognition kan exakt upptäcka och jämföra ansikten i bilder eller videoströmmar.
- Ansiktsanalys: När ett ansikte är fångat ger det detaljerade insikter i ansiktsegenskaper som ålder, kön, känslor och ansikts landmärken. Inte bara detta, det kommer också att validera om användaren har solglasögon eller om deras ansikte är täckt av andra föremål.
- Ansiktsmatchning: Efter att ha verifierat Liveness kan vi utföra ansiktsmatchning för att verifiera identiteten på individer baserat på referensbilder som extraherats från det nationella ID-kortet och den aktuella bilden från Liveness-sessionen.
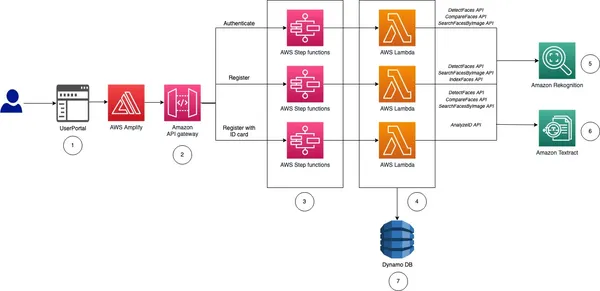
Som du kan se underlättar Rekognition snabb användarregistrering genom att analysera en taggen selfie och jämföra den med ett myndighetsutfärdat ID som laddats upp av användaren. Funktioner för att upptäcka livlighet inom Rekognition hjälper till att motverka spoofingförsök genom att uppmana användare att utföra specifika åtgärder som att blinka eller vända på huvudet. Detta säkerställer att användaren som registrerar sig är en riktig person och inte ett smart förklädd foto eller djupt falskt. Denna automatiserade process minskar avsevärt introduktionstider, vilket förbättrar användarupplevelsen. Erkännande eliminerar risken för mänskliga fel som är inneboende i manuell verifiering. Dessutom uppnår ansiktsigenkänningsalgoritmer höga noggrannhetsgrader, vilket säkerställer tillförlitlig identitetsverifiering.
Jag vet att du nu är väldigt exalterad över att se den i aktion, så låt oss genast börja med det.
Implementering av identitetsverifiering: Den automatiserade KYC-lösningen
Steg 1: Konfigurera AWS-kontot
Innan du börjar, se till att du har ett aktivt AWS-konto. Du kan registrera dig för ett AWS-konto på AWS-webbplatsen om du inte redan har gjort det. När du har registrerat dig, aktivera erkännandetjänster. AWS tillhandahåller omfattande dokumentation och handledning för att underlätta denna process.
Steg 2: Konfigurera IAM-behörigheter
Om du vill använda Python eller AWS CLI är detta steg obligatoriskt. Du måste ge tillstånd för att komma åt Rekognition, S3 och Textract. Detta kan göras från konsolen.
Steg 3: Ladda upp användarens nationella ID
Jag kommer att demonstrera detta genom CLI, Python och ett grafiskt gränssnitt. Om du letar efter en kod för ett grafiskt gränssnitt så har AWS laddat upp en snygg exempel på git. Den här artikeln har distribuerat samma kod för att visa ett grafiskt gränssnitt.
aws textract analyze-id --document-pages
'{"S3Object":{"Bucket":"bucketARN","Name":"id.jpg"}}'"IdentityDocuments": [
{
"DocumentIndex": 1,
"IdentityDocumentFields": [
{
"Type": {
"Text": "FIRST_NAME"
},
"ValueDetection": {
"Text": "xyz",
"Confidence": 93.61839294433594
}
},
{
"Type": {
"Text": "LAST_NAME"
},
"ValueDetection": {
"Text": "abc",
"Confidence": 96.3537826538086
}
},
{
"Type": {
"Text": "MIDDLE_NAME"
},
"ValueDetection": {
"Text": "",
"Confidence": 99.16631317138672
}
},
{
"Type": {
"Text": "SUFFIX"
},
"ValueDetection": {
"Text": "",
"Confidence": 99.16964721679688
}
},
{
"Type": {
"Text": "CITY_IN_ADDRESS"
},
"ValueDetection": {
"Text": "",
"Confidence": 99.17261505126953
}
},
{
"Type": {
"Text": "ZIP_CODE_IN_ADDRESS"
},
"ValueDetection": {
"Text": "",
"Confidence": 99.17854309082031
}
},
{
"Type": {
"Text": "STATE_IN_ADDRESS"
},
"ValueDetection": {
"Text": "",
"Confidence": 99.15782165527344
}
},
{
"Type": {
"Text": "STATE_NAME"
},
"ValueDetection": {
"Text": "",
"Confidence": 99.16664123535156
}
},
{
"Type": {
"Text": "DOCUMENT_NUMBER"
},
"ValueDetection": {
"Text": "123456",
"Confidence": 95.29527282714844
}
},
{
"Type": {
"Text": "EXPIRATION_DATE"
},
"ValueDetection": {
"Text": "22 OCT 2024",
"NormalizedValue": {
"Value": "2024-10-22T00:00:00",
"ValueType": "Date"
},
"Confidence": 95.7198486328125
}
},
{
"Type": {
"Text": "DATE_OF_BIRTH"
},
"ValueDetection": {
"Text": "1 SEP 1994",
"NormalizedValue": {
"Value": "1994-09-01T00:00:00",
"ValueType": "Date"
},
"Confidence": 97.41930389404297
}
},
{
"Type": {
"Text": "DATE_OF_ISSUE"
},
"ValueDetection": {
"Text": "23 OCT 2004",
"NormalizedValue": {
"Value": "2004-10-23T00:00:00",
"ValueType": "Date"
},
"Confidence": 96.1384506225586
}
},
{
"Type": {
"Text": "ID_TYPE"
},
"ValueDetection": {
"Text": "PASSPORT",
"Confidence": 98.65157318115234
}
}Ovanstående kommando använder AWS Textract analys-id-kommandot för att extrahera information från bilden som redan laddats upp i S3. Utdata-JSON innehåller också begränsningsrutor så jag har trunkerat för att bara visa nyckelinformationen. Som du kan se har den extraherat all nödvändig information tillsammans med konfidensnivån för textvärdet.
Använder Python-funktioner
textract_client = boto3.client('textract', region_name='us-east-1')
def analyze_id(document_file_name)->dict:
if document_file_name is not None:
with open(document_file_name, "rb") as document_file:
idcard_bytes = document_file.read()
'''
Analyze the image using Amazon Textract.
'''
try:
response = textract_client.analyze_id(
DocumentPages=[
{'Bytes': idcard_bytes},
])
return response
except textract_client.exceptions.UnsupportedDocumentException:
logger.error('User %s provided an invalid document.' % inputRequest.user_id)
raise InvalidImageError('UnsupportedDocument')
except textract_client.exceptions.DocumentTooLargeException:
logger.error('User %s provided document too large.' % inputRequest.user_id)
raise InvalidImageError('DocumentTooLarge')
except textract_client.exceptions.ProvisionedThroughputExceededException:
logger.error('Textract throughput exceeded.')
raise InvalidImageError('ProvisionedThroughputExceeded')
except textract_client.exceptions.ThrottlingException:
logger.error('Textract throughput exceeded.')
raise InvalidImageError('ThrottlingException')
except textract_client.exceptions.InternalServerError:
logger.error('Textract Internal Server Error.')
raise InvalidImageError('ProvisionedThroughputExceeded')
result = analyze_id('id.jpeg')
print(result) # print raw outputAnvända grafiskt gränssnitt
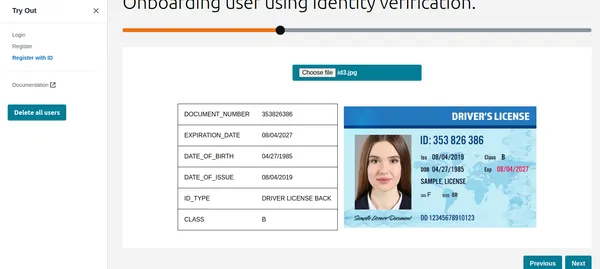

Som du kan se har Textract hämtat all relevant information och visar även ID-typen. Denna information kan användas för att registrera kunden eller användaren. Men innan dess låt oss göra en Liveness-kontroll för att verifiera att det är en riktig person.
Liveness Check
När användaren klickar på börja checka i bilden nedan kommer den först att upptäcka ansiktet, och om bara ett ansikte är på skärmen startar den Liveness-sessionen. Av integritetsskäl kan jag inte visa hela Liveness-sessionen. Du kan dock kontrollera detta demo videolänk. Liveness-sessionen ger resultat i % förtroende. Vi kan också ställa in en tröskel under vilken Liveness-sessionen kommer att misslyckas. För kritiska applikationer som denna bör man hålla tröskeln till 95 %.
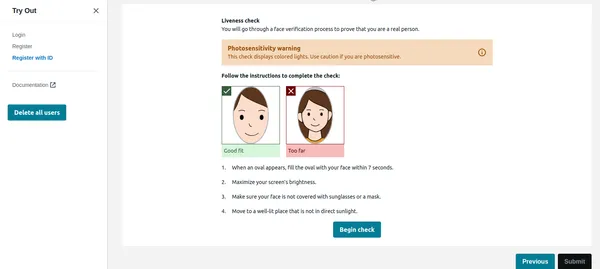
Förutom självförtroendet kommer Liveness-sessionen också att ge känslor och främmande föremål som upptäcks i ansiktet. Om användaren har solglasögon eller visar uttryck som ilska etc. kan applikationen avvisa bilden.
Python-kod
rek_client = boto3.client('rekognition', region_name='us-east-1')
sessionid = rek_client.create_face_liveness_session(Settings={'AuditImagesLimit':1,
'OutputConfig': {"S3Bucket": 'IMAGE_BUCKET_NAME'}})
session = rek_client.get_face_liveness_session_results(
SessionId=sessionid)
Ansiktsjämförelse
När användaren har slutfört Liveness-sessionen måste applikationen jämföra ansiktet med ansiktet som identifierats från ID:t. Detta är den mest kritiska delen av vår ansökan. Vi vill inte registrera en användare vars ansikte inte matchar ID. Ansiktet som detekteras från det uppladdade ID:t är redan lagrat i S3 av koden som kommer att fungera som en referensbild. Liknande ansikte från liveness-sessionen lagras också i S3. Låt oss först kontrollera CLI-implementeringen.
CLI kommando
aws rekognition compare-faces
--source-image '{"S3Object":{"Bucket":"imagebucket","Name":"reference.jpg"}}'
--target-image '{"S3Object":{"Bucket":"imagebucket","Name":"liveness.jpg"}}'
--similarity-threshold 0.9
Produktion
{
"UnmatchedFaces": [],
"FaceMatches": [
{
"Face": {
"BoundingBox": {
"Width": 0.12368916720151901,
"Top": 0.16007372736930847,
"Left": 0.5901257991790771,
"Height": 0.25140416622161865
},
"Confidence": 99.0,
"Pose": {
"Yaw": -3.7351467609405518,
"Roll": -0.10309021919965744,
"Pitch": 0.8637830018997192
},
"Quality": {
"Sharpness": 95.51618957519531,
"Brightness": 65.29893493652344
},
"Landmarks": [
{
"Y": 0.26721030473709106,
"X": 0.6204193830490112,
"Type": "eyeLeft"
},
{
"Y": 0.26831310987472534,
"X": 0.6776827573776245,
"Type": "eyeRight"
},
{
"Y": 0.3514654338359833,
"X": 0.6241428852081299,
"Type": "mouthLeft"
},
{
"Y": 0.35258132219314575,
"X": 0.6713621020317078,
"Type": "mouthRight"
},
{
"Y": 0.3140771687030792,
"X": 0.6428444981575012,
"Type": "nose"
}
]
},
"Similarity": 100.0
}
],
"SourceImageFace": {
"BoundingBox": {
"Width": 0.12368916720151901,
"Top": 0.16007372736930847,
"Left": 0.5901257991790771,
"Height": 0.25140416622161865
},
"Confidence": 99.0
}
}
Som du kan se ovan har det visat att det inte finns något oöverträffat ansikte och ansiktet matchar med 99% konfidensnivå. Den har också returnerat begränsningsrutor som en extra utgång. Låt oss nu se Python-implementeringen.
Python-kod
rek_client = boto3.client('rekognition', region_name='us-east-1')
response = rek_client.compare_faces(
SimilarityThreshold=0.9,
SourceImage={
'S3Object': {
'Bucket': bucket,
'Name': idcard_name
}
},
TargetImage={
'S3Object': {
'Bucket': bucket,
'Name': name
}
})
if len(response['FaceMatches']) == 0:
IsMatch = 'False'
Reason = 'Property FaceMatches is empty.'
facenotMatch = False
for match in response['FaceMatches']:
similarity:float = match['Similarity']
if similarity > 0.9:
IsMatch = True,
Reason = 'All checks passed.'
else:
facenotMatch = True
Ovanstående kod kommer att jämföra ansiktet som identifierats från ID-kortet och Liveness-sessionen och håller tröskeln till 90 %. Om ansiktet matchar kommer det att ställa in IsMatch-variabeln till True. Så med bara ett funktionsanrop kan vi jämföra de två ansiktena, båda är redan uppladdade i S3-hinken.
Så äntligen kan vi registrera den giltiga användaren och slutföra hans KYC. Som du kan se är detta helt automatiserat och användarinitierat, och ingen annan person är inblandad. Processen har också förkortat användarintroduktionen jämfört med den nuvarande manuella processen.
Steg 4: Fråga efter dokument som GPT
Jag gillade en av de mycket användbara funktionerna i Textract, du kan ställa specifika frågor, säg "Vad är identitetsnumret". Låt mig visa dig hur du gör detta med AWS CLI.
aws textract analyze-document --document '{"S3Object":{"Bucket":"ARN","Name":"id.jpg"}}'
--feature-types '["QUERIES"]' --queries-config '{"Queries":[{"Text":"What is the Identity No"}]}'Observera att jag tidigare använde analys-id-funktionen medan jag nu har använt analys-dokument för att fråga dokumentet. Detta är mycket användbart om det finns specifika fält i ID-kortet som inte extraheras av analys-id-funktionen. Analys-id-funktionen fungerar bra för alla amerikanska ID-kort, men den fungerar också bra med indiska statliga ID-kort. Ändå, om några av fälten inte extraheras kan frågefunktionen användas.
AWS använder kognitotjänst för att hantera användaridentitet, användar-ID och ansikts-ID lagrade i DynamoDB. AWS exempelkod jämför också bilderna från den befintliga databasen så att samma användare inte kan registrera sig om med ett annat ID eller användarnamn. Denna typ av validering är ett måste för ett robust automatiserat KYC-system.
Slutsats
Genom att anamma AWS Rekognition for Automated Self KYC kan du förvandla din användarintroduktionsprocess från ett mödosamt hinder till en smidig och säker upplevelse. Amazon Rekognition tillhandahåller en robust lösning för att implementera identitetsverifieringssystem med avancerade ansiktsigenkänningsfunktioner. Genom att utnyttja dess funktioner kan utvecklare förbättra säkerhetsåtgärderna, effektivisera användarautentiseringsprocesser och leverera sömlösa användarupplevelser över olika applikationer och branscher.
Med den omfattande guiden som beskrivs ovan är du väl rustad att ge dig ut på din resa för att implementera identitetsverifiering effektivt med hjälp av Amazon Rekognition. Omfamna kraften i AI-driven identitetsverifiering och lås upp nya möjligheter inom området för digital identitetshantering.
Key Takeaways
- Amazon Rekognition erbjuder avancerad ansiktsigenkänning och analysfunktioner, vilket underlättar strömlinjeformade och säkra identitetsverifieringsprocesser.
- Det möjliggör automatisk introduktion av användare genom att extrahera viktig information från statligt utfärdade ID-kort och utföra kontroller av livlighet.
- Implementeringsstegen inkluderar att ställa in AWS-tjänster, konfigurera IAM-behörigheter och använda Python-funktioner eller grafiska gränssnitt för textextraktion och ansiktsjämförelser.
- Realtidskontroller av livlighet ökar säkerheten genom att se till att användare är närvarande under verifieringen, medan ansiktsjämförelser validerar identiteter mot referensbilder.
Medierna som visas i den här artikeln ägs inte av Analytics Vidhya och används efter författarens gottfinnande.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoData.Network Vertical Generative Ai. Styrka dig själv. Tillgång här.
- PlatoAiStream. Web3 Intelligence. Kunskap förstärkt. Tillgång här.
- Platoesg. Kol, CleanTech, Energi, Miljö, Sol, Avfallshantering. Tillgång här.
- PlatoHealth. Biotech och kliniska prövningar Intelligence. Tillgång här.
- Källa: https://www.analyticsvidhya.com/blog/2024/03/how-to-implement-identity-verification-using-amazon-rekognition/

