I takt med att Roblox har vuxit under de senaste 16 åren, har även skalan och komplexiteten hos den tekniska infrastrukturen som stöder miljontals uppslukande 3D-samupplevelser. Antalet maskiner som vi stöder har mer än tredubblats under de senaste två åren, från cirka 36,000 30 den 2021 juni 145,000 till nästan 1,000 XNUMX idag. Att stödja dessa alltid-på-upplevelser för människor över hela världen kräver mer än XNUMX XNUMX interna tjänster. För att hjälpa oss att kontrollera kostnader och nätverkslatens distribuerar och hanterar vi dessa maskiner som en del av en specialbyggd och hybrid privat molninfrastruktur som huvudsakligen körs i lokaler.
Vår infrastruktur stöder för närvarande mer än 70 miljoner dagliga aktiva användare runt om i världen, inklusive de skapare som förlitar sig på Roblox's ekonomi för sina företag. Alla dessa miljoner människor förväntar sig en mycket hög nivå av tillförlitlighet. Med tanke på den uppslukande karaktären hos våra upplevelser finns det en extremt låg tolerans för fördröjningar eller latens, än mindre avbrott. Roblox är en plattform för kommunikation och anslutning, där människor möts i uppslukande 3D-upplevelser. När människor kommunicerar som sina avatarer i ett uppslukande utrymme är till och med mindre förseningar eller problem mer märkbara än de är i en texttråd eller ett konferenssamtal.
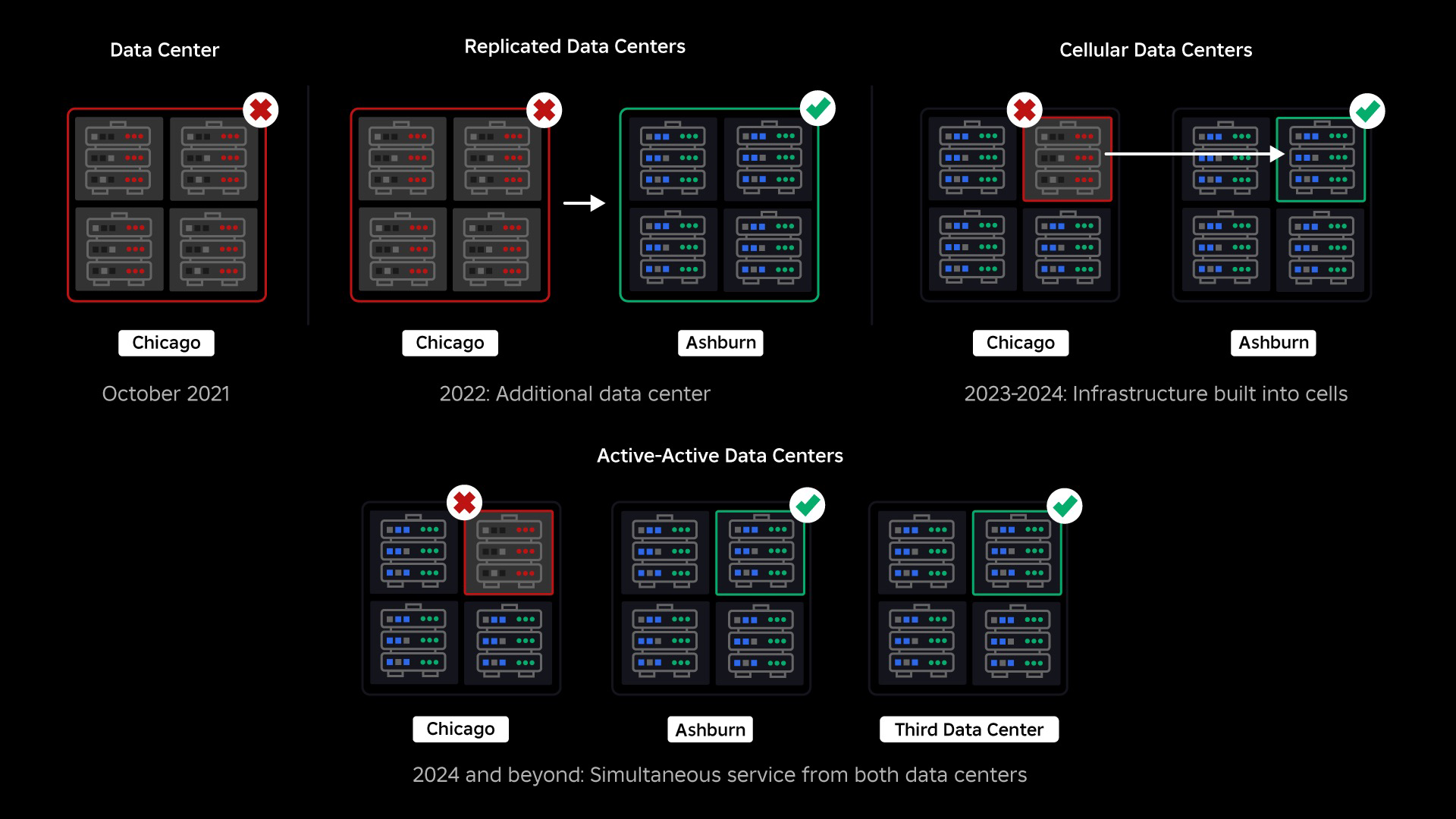
I oktober 2021 upplevde vi ett systemomfattande avbrott. Det började smått, med ett problem i en komponent i ett datacenter. Men det spred sig snabbt medan vi undersökte och resulterade i slutändan i ett 73-timmarsavbrott. På den tiden delade vi båda detaljer om vad som hände och några av våra tidiga lärdomar från frågan. Sedan dess har vi studerat dessa lärdomar och arbetat för att öka vår infrastrukturs motståndskraft mot de typer av fel som uppstår i alla storskaliga system på grund av faktorer som extrema trafiktoppar, väder, hårdvarufel, programvarubuggar eller bara människor gör misstag. När dessa fel inträffar, hur säkerställer vi att ett problem i en enskild komponent, eller grupp av komponenter, inte sprider sig till hela systemet? Denna fråga har varit vårt fokus de senaste två åren och medan arbetet pågår har det vi gjort hittills redan gett resultat. Till exempel, under första halvåret 2023 sparade vi 125 miljoner engagemangstimmar per månad jämfört med första halvåret 2022. Idag delar vi med oss av det arbete vi redan har gjort, såväl som vår långsiktiga vision för att bygga ett mer motståndskraftigt infrastruktursystem.
Att bygga en backstop
Inom storskaliga infrastruktursystem inträffar småskaliga fel många gånger om dagen. Om en maskin har ett problem och måste tas ur drift är det hanterbart eftersom de flesta företag har flera instanser av sina back-end-tjänster. Så när en enskild instans misslyckas tar andra upp arbetsbördan. För att åtgärda dessa frekventa misslyckanden är förfrågningar i allmänhet inställda på att automatiskt försöka igen om de får ett fel.
Detta blir utmanande när ett system eller en person försöker igen för aggressivt, vilket kan bli ett sätt för dessa småskaliga misslyckanden att spridas genom hela infrastrukturen till andra tjänster och system. Om nätverket eller en användare försöker tillräckligt ihållande igen, kommer det så småningom att överbelasta varje instans av den tjänsten, och potentiellt andra system, globalt. Vårt avbrott 2021 var resultatet av något som är ganska vanligt i storskaliga system: Ett fel börjar i det små och sprider sig sedan genom systemet och blir stort så snabbt att det är svårt att lösa innan allt går ner.
Vid tidpunkten för vårt avbrott hade vi ett aktivt datacenter (med komponenter i det som fungerade som backup). Vi behövde möjligheten att manuellt misslyckas med ett nytt datacenter när ett problem gjorde att det befintliga gick ner. Vår första prioritet var att säkerställa att vi hade en backup-distribution av Roblox, så vi byggde den backupen i ett nytt datacenter, beläget i en annan geografisk region. Det extra skyddet för det värsta scenariot: ett avbrott som sprider sig till tillräckligt många komponenter i ett datacenter så att det blir helt obrukbart. Vi har nu ett datacenter som hanterar arbetsbelastningar (aktivt) och ett i standby, som fungerar som backup (passivt). Vårt långsiktiga mål är att gå från denna aktiv-passiva konfiguration till en aktiv-aktiv konfiguration, där båda datacentren hanterar arbetsbelastningar, med en lastbalanserare som fördelar förfrågningar mellan dem baserat på latens, kapacitet och hälsa. När detta väl är på plats förväntar vi oss att ha ännu högre tillförlitlighet för hela Roblox och kunna misslyckas nästan omedelbart snarare än under flera timmar. 
Flytta till en cellulär infrastruktur
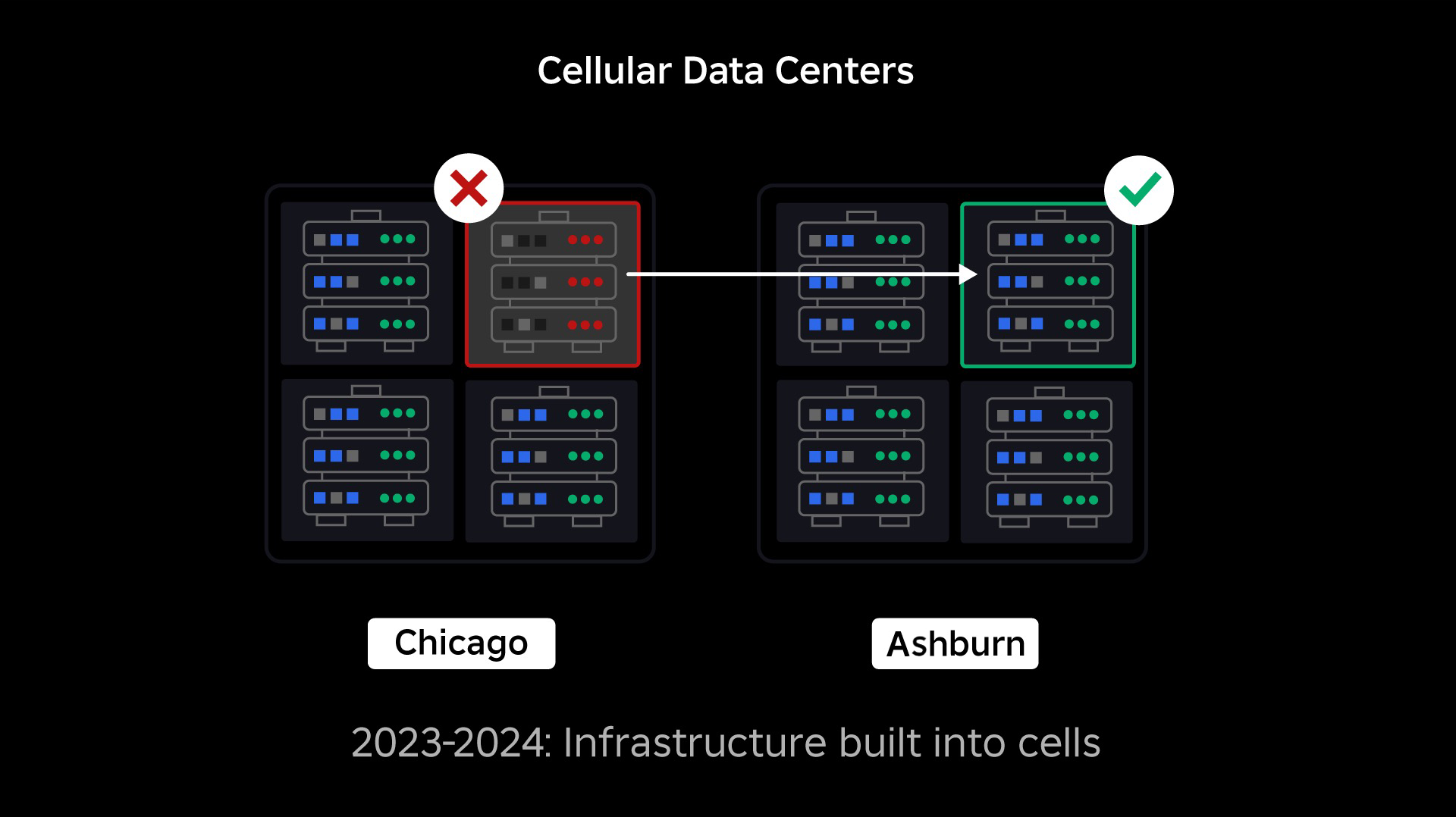
Vår nästa prioritet var att skapa starka sprängväggar inuti varje datacenter för att minska risken för att ett helt datacenter skulle gå sönder. Celler (vissa företag kallar dem kluster) är i huvudsak en uppsättning maskiner och det är hur vi skapar dessa väggar. Vi replikerar tjänster både inom och över celler för extra redundans. I slutändan vill vi att alla tjänster på Roblox ska köras i celler så att de kan dra nytta av både starka sprängväggar och redundans. Om en cell inte längre fungerar kan den säkert avaktiveras. Replikering över celler gör att tjänsten kan fortsätta att köras medan cellen repareras. I vissa fall kan cellreparation innebära en fullständig omprovisionering av cellen. I branschen är det ganska vanligt att torka och installera om en enskild maskin, eller en liten uppsättning maskiner, men att göra detta för en hel cell, som innehåller ~1,400 XNUMX maskiner, är det inte.
För att detta ska fungera måste dessa celler vara i stort sett enhetliga, så att vi snabbt och effektivt kan flytta arbetsbelastningar från en cell till en annan. Vi har ställt upp vissa krav som tjänster måste uppfylla innan de körs i en cell. Till exempel måste tjänster vara containeriserade, vilket gör dem mycket mer portabla och hindrar någon från att göra konfigurationsändringar på OS-nivå. Vi har antagit en infrastruktur-som-kod-filosofi för celler: I vårt källkodsförråd inkluderar vi definitionen av allt som finns i en cell så att vi snabbt kan bygga om den från grunden med hjälp av automatiserade verktyg.
Alla tjänster uppfyller för närvarande inte dessa krav, så vi har arbetat för att hjälpa tjänsteägare att uppfylla dem där det är möjligt, och vi har byggt nya verktyg för att göra det enkelt att migrera tjänster till celler när de är klara. Till exempel "stripar" vårt nya distributionsverktyg automatiskt en tjänstedistribution över celler, så att tjänsteägare inte behöver tänka på replikeringsstrategin. Denna rigoritetsnivå gör migreringsprocessen mycket mer utmanande och tidskrävande, men den långsiktiga vinsten kommer att vara ett system där:
- Det är mycket lättare att begränsa ett fel och förhindra att det sprids till andra celler;
- Våra infrastrukturingenjörer kan bli effektivare och röra sig snabbare; och
- Ingenjörerna som bygger tjänsterna på produktnivå som i slutändan distribueras i celler behöver inte veta eller oroa sig för vilka celler deras tjänster körs i.
Att lösa större utmaningar
På samma sätt som branddörrar används för att hålla lågor, fungerar celler som starka sprängväggar i vår infrastruktur för att hjälpa till att begränsa det problem som utlöser ett fel i en enskild cell. Så småningom kommer alla tjänster som utgör Roblox att distribueras redundant inuti och över celler. När detta arbete är klart kan problem fortfarande spridas tillräckligt brett för att göra en hel cell inoperabel, men det skulle vara extremt svårt för ett problem att sprida sig utanför den cellen. Och om vi lyckas göra celler utbytbara kommer återhämtningen att gå betydligt snabbare eftersom vi kommer att kunna misslyckas till en annan cell och förhindra att problemet påverkar slutanvändarna.
Där detta blir knepigt är att separera dessa celler tillräckligt för att minska möjligheten att sprida fel, samtidigt som saker och ting hålls fungerande och funktionella. I ett komplext infrastruktursystem måste tjänsterna kommunicera med varandra för att dela frågor, information, arbetsbelastningar etc. När vi replikerar dessa tjänster till celler måste vi tänka på hur vi hanterar korskommunikation. I en idealisk värld omdirigerar vi trafik från en ohälsosam cell till andra friska celler. Men hur hanterar vi en "förfrågan om döden" - en så orsakar en cell vara ohälsosam? Om vi omdirigerar den frågan till en annan cell kan det göra att den cellen blir ohälsosam på precis det sätt som vi försöker undvika. Vi måste hitta mekanismer för att flytta "bra" trafik från ohälsosamma celler samtidigt som vi upptäcker och släcker den trafik som gör att cellerna blir ohälsosamma.
På kort sikt har vi distribuerat kopior av datortjänster till varje beräkningscell så att de flesta förfrågningar till datacentret kan betjänas av en enda cell. Vi arbetar också med lastbalanserande trafik över celler. När vi tittar längre ut har vi börjat bygga en nästa generations tjänsteupptäcktsprocess som kommer att utnyttjas av ett servicenät, som vi hoppas kunna slutföra 2024. Detta kommer att göra det möjligt för oss att implementera sofistikerade policyer som tillåter kommunikation över celler endast när det kommer inte att påverka failover-cellerna negativt. Under 2024 kommer också en metod att dirigera beroende förfrågningar till en tjänstversion i samma cell, vilket kommer att minimera korscellstrafik och därigenom minska risken för korscellspridning av fel.
På toppen betjänas mer än 70 procent av vår back-end-tjänsttrafik utanför cellerna och vi har lärt oss mycket om hur man skapar celler, men vi förväntar oss mer forskning och testning när vi fortsätter att migrera våra tjänster fram till 2024 och bortom. Allt eftersom vi går framåt kommer dessa sprängväggar att bli allt starkare.
Migrera en alltid-på-infrastruktur
Roblox är en global plattform som stöder användare över hela världen, så vi kan inte flytta tjänster under lågtrafik eller "stopptid", vilket ytterligare komplicerar processen att migrera alla våra maskiner till celler och våra tjänster för att köras i dessa celler . Vi har miljontals alltid-på-upplevelser som måste fortsätta att stödjas, även när vi flyttar maskinerna de körs på och tjänsterna som stöder dem. När vi startade den här processen hade vi inte tiotusentals maskiner som bara stod oanvända och tillgängliga för att migrera dessa arbetsbelastningar till.
Vi hade dock ett litet antal ytterligare maskiner som köptes in i väntan på framtida tillväxt. Till att börja med byggde vi nya celler med dessa maskiner och migrerade sedan arbetsbelastningar till dem. Vi värdesätter effektivitet såväl som tillförlitlighet, så istället för att gå ut och köpa fler maskiner när vi väl fick slut på "reservmaskiner" byggde vi fler celler genom att torka och omprovisionera de maskiner vi hade migrerat från. Vi migrerade sedan arbetsbelastningar till de omprovisionerade datorerna och startade processen om igen. Denna process är komplex – eftersom maskiner byts ut och frigörs för att byggas in i celler frigörs de inte på ett idealiskt, ordnat sätt. De är fysiskt fragmenterade över datahallar, vilket gör att vi kan tillhandahålla dem på ett bitvis sätt, vilket kräver en defragmenteringsprocess på hårdvarunivå för att hålla hårdvaruplatserna i linje med storskaliga fysiska feldomäner.
En del av vårt infrastrukturteknikteam är fokuserade på att migrera befintliga arbetsbelastningar från vår gamla, eller "förcells"-miljö till celler. Detta arbete kommer att fortsätta tills vi har migrerat tusentals olika infrastrukturtjänster och tusentals back-end-tjänster till nybyggda celler. Vi förväntar oss att detta kommer att ta hela nästa år och möjligen in i 2025, på grund av vissa komplicerande faktorer. För det första kräver detta arbete robusta verktyg för att byggas. Till exempel behöver vi verktyg för att automatiskt balansera ett stort antal tjänster när vi distribuerar en ny cell – utan att påverka våra användare. Vi har också sett tjänster som byggts med antaganden om vår infrastruktur. Vi måste revidera dessa tjänster så att de inte är beroende av saker som kan förändras i framtiden när vi flyttar in i celler. Vi har också implementerat både ett sätt att söka efter kända designmönster som inte fungerar bra med cellulär arkitektur, såväl som en metodisk testprocess för varje tjänst som migreras. Dessa processer hjälper oss att avvärja alla användarproblem som orsakas av att en tjänst är inkompatibel med celler.
Idag hanteras närmare 30,000 99.99 maskiner av celler. Det är bara en bråkdel av vår totala flotta, men det har varit en mycket smidig övergång hittills utan någon negativ inverkan på spelarna. Vårt slutgiltiga mål är att våra system ska uppnå 0.01 procents drifttid för användare varje månad, vilket innebär att vi inte skulle störa mer än XNUMX procent av engagemangstimmarna. I hela branschen kan driftstopp inte helt elimineras, men vårt mål är att minska alla Roblox-avbrott i en sådan grad att det nästan inte märks.
Framtidssäkrar när vi skalar
Även om våra tidiga ansträngningar visar sig vara framgångsrika, är vårt arbete med celler långt ifrån klart. När Roblox fortsätter att skala kommer vi att fortsätta arbeta för att förbättra effektiviteten och motståndskraften i våra system genom denna och andra tekniker. När vi går kommer plattformen att bli allt mer motståndskraftig mot problem, och alla problem som uppstår bör gradvis bli mindre synliga och störande för människorna på vår plattform.
Sammanfattningsvis har vi hittills:
- Byggde ett andra datacenter och uppnådde framgångsrikt aktiv/passiv status.
- Skapat celler i våra aktiva och passiva datacenter och framgångsrikt migrerat mer än 70 procent av vår back-end-tjänsttrafik till dessa celler.
- Sätt på plats de krav och bästa praxis vi måste följa för att hålla alla celler enhetliga när vi fortsätter att migrera resten av vår infrastruktur.
- Startade en kontinuerlig process med att bygga starkare "sprängväggar" mellan celler.
När dessa celler blir mer utbytbara blir det mindre överhörning mellan cellerna. Detta öppnar upp några mycket intressanta möjligheter för oss när det gäller att öka automatiseringen kring övervakning, felsökning och till och med automatisk förskjutning av arbetsbelastningar.
I september började vi också köra aktiva/aktiva experiment i våra datacenter. Detta är en annan mekanism vi testar för att förbättra tillförlitligheten och minimera failover-tider. Dessa experiment hjälpte till att identifiera ett antal systemdesignmönster, till stor del kring dataåtkomst, som vi måste omarbeta när vi strävar mot att bli fullt aktiva. Sammantaget var experimentet tillräckligt framgångsrikt för att låta det köras för trafik från ett begränsat antal av våra användare.
Vi är glada över att fortsätta driva detta arbete framåt för att ge plattformen större effektivitet och motståndskraft. Detta arbete med celler och aktiv aktiv infrastruktur, tillsammans med våra andra ansträngningar, kommer att göra det möjligt för oss att växa till ett pålitligt, högpresterande verktyg för miljontals människor och fortsätta att skala när vi arbetar för att koppla ihop en miljard människor i verkligheten tid.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoData.Network Vertical Generative Ai. Styrka dig själv. Tillgång här.
- PlatoAiStream. Web3 Intelligence. Kunskap förstärkt. Tillgång här.
- Platoesg. Kol, CleanTech, Energi, Miljö, Sol, Avfallshantering. Tillgång här.
- PlatoHealth. Biotech och kliniska prövningar Intelligence. Tillgång här.
- Källa: https://blog.roblox.com/2023/12/making-robloxs-infrastructure-efficient-resilient/

