Det här inlägget är skrivet tillsammans med Santosh Waddi och Nanda Kishore Thatikonda från BigBasket.
BigBasket är Indiens största mat- och livsmedelsbutik online. De verkar i flera e-handelskanaler som snabb handel, slitsad leverans och dagliga prenumerationer. Du kan också köpa från deras fysiska butiker och varuautomater. De erbjuder ett stort sortiment av över 50,000 1,000 produkter från 500 10 varumärken och är verksamma i mer än XNUMX städer och städer. BigBasket servar över XNUMX miljoner kunder.
I det här inlägget diskuterar vi hur BigBasket använde Amazon SageMaker för att träna sin datorseende modell för produktidentifiering av snabbrörliga konsumentvaror (FMCG), vilket hjälpte dem att minska utbildningstiden med cirka 50 % och spara kostnader med 20 %.
Kundens utmaningar
Idag tillhandahåller de flesta stormarknader och fysiska butiker i Indien manuell utcheckning vid kassadisken. Detta har två problem:
- Det kräver ytterligare arbetskraft, viktklistermärken och upprepad träning för det operativa teamet i butiken när de skalar.
- I de flesta butiker skiljer sig kassadisken från vägningsdiskarna, vilket ökar friktionen i kundens köpresa. Kunder tappar ofta viktdekalen och måste gå tillbaka till vägningsdiskarna för att hämta en igen innan de går vidare med kassaprocessen.
Självutcheckningsprocess
BigBasket introducerade ett AI-drivet kassasystem i sina fysiska butiker som använder kameror för att särskilja föremål unikt. Följande bild ger en översikt över kassaprocessen.
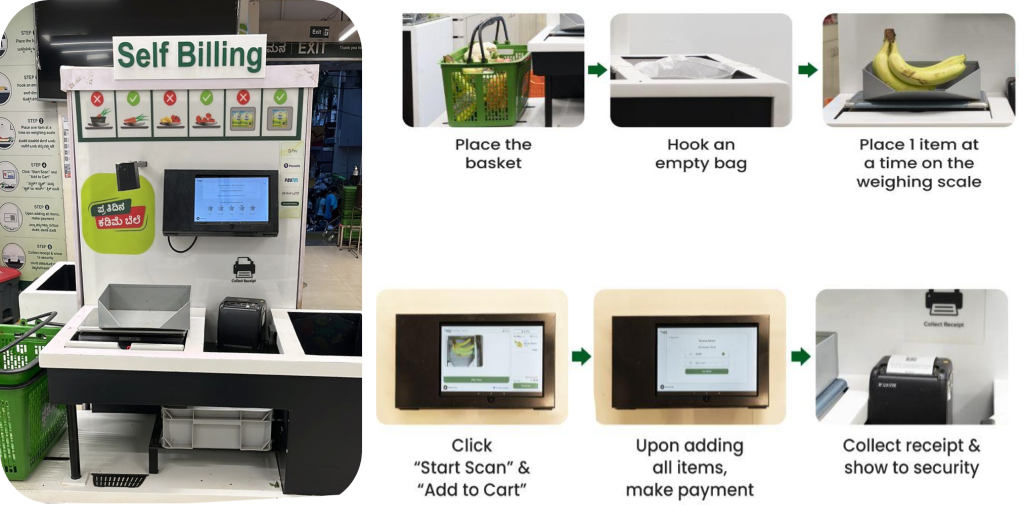
BigBasket-teamet körde interna ML-algoritmer med öppen källkod för objektigenkänning för datorseende för att driva AI-aktiverad utcheckning vid deras fresho (fysiska) butiker. Vi stod inför följande utmaningar för att driva deras befintliga installation:
- Med den kontinuerliga introduktionen av nya produkter behövde datorseendemodellen kontinuerligt införliva ny produktinformation. Systemet behövde hantera en stor katalog med över 12,000 600 lagerhållningsenheter (SKUs), med nya SKU:er som kontinuerligt läggs till med en hastighet av över XNUMX per månad.
- För att hålla jämna steg med nya produkter producerades en ny modell varje månad med den senaste träningsdatan. Det var kostsamt och tidskrävande att träna modellerna ofta för att anpassa sig till nya produkter.
- BigBasket ville också minska träningscykeltiden för att förbättra tiden till marknaden. På grund av ökningar av SKU:er ökade tiden som tog modellen linjärt, vilket påverkade deras tid till marknaden eftersom träningsfrekvensen var mycket hög och tog lång tid.
- Dataökning för modellträning och manuell hantering av hela träningscykeln från början tillförde betydande omkostnader. BigBasket körde detta på en tredjepartsplattform, vilket medförde betydande kostnader.
Lösningsöversikt
Vi rekommenderade att BigBasket omarbetar sin befintliga FMCG-produktdetekterings- och klassificeringslösning med SageMaker för att hantera dessa utmaningar. Innan BigBasket gick över till fullskalig produktion provade en pilot på SageMaker för att utvärdera prestanda, kostnad och bekvämlighetsmått.
Deras mål var att finjustera en befintlig modell för datorseende maskininlärning (ML) för SKU-detektering. Vi använde en CNN-arkitektur (convolutional neural network) med ResNet152 för bildklassificering. En ansenlig datauppsättning på cirka 300 bilder per SKU uppskattades för modellträning, vilket resulterade i över 4 miljoner totalt träningsbilder. För vissa SKU:er utökade vi data för att omfatta ett bredare spektrum av miljöförhållanden.
Följande diagram illustrerar lösningsarkitekturen.

Hela processen kan sammanfattas i följande steg på hög nivå:
- Utför datarensning, anteckningar och förstärkning.
- Lagra data i en Amazon enkel lagringstjänst (Amazon S3) hink.
- Använd SageMaker och Amazon FSx för Luster för effektiv dataökning.
- Dela upp data i tåg-, validerings- och testset. Vi använde FSx för Luster och Amazon Relational Databas Service (Amazon RDS) för snabb parallell dataåtkomst.
- Använd en anpassad PyTorch Docker-container inklusive andra öppen källkodsbibliotek.
- Använda SageMaker distribuerad dataparallellism (SMDDP) för accelererad distribuerad träning.
- Logga modellträningsmått.
- Kopiera den slutliga modellen till en S3 hink.
BigBasket används SageMaker anteckningsböcker för att träna sina ML-modeller och kunde enkelt porta sina befintliga PyTorch med öppen källkod och andra beroenden av öppen källkod till en SageMaker PyTorch-behållare och köra pipelinen sömlöst. Detta var den första fördelen som sågs av BigBasket-teamet, eftersom det knappt behövdes några ändringar av koden för att göra den kompatibel att köra på en SageMaker-miljö.
Modellnätverket består av en ResNet 152-arkitektur följt av helt anslutna lager. Vi frös funktionslagren på låg nivå och behöll vikterna som förvärvats genom överföringsinlärning från ImageNet-modellen. De totala modellparametrarna var 66 miljoner, bestående av 23 miljoner träningsbara parametrar. Detta överföringsinlärningsbaserade tillvägagångssätt hjälpte dem att använda färre bilder vid träningstillfället, och möjliggjorde även snabbare konvergens och minskade den totala träningstiden.
Bygga och träna modellen inom Amazon SageMaker Studio tillhandahållit en integrerad utvecklingsmiljö (IDE) med allt som behövs för att förbereda, bygga, träna och ställa in modeller. Att utöka träningsdatan med hjälp av tekniker som att beskära, rotera och vända bilder bidrog till att förbättra modellens träningsdata och modellnoggrannhet.
Modellutbildningen accelererades med 50 % genom användningen av SMDDP-biblioteket, som inkluderar optimerade kommunikationsalgoritmer designade specifikt för AWS-infrastruktur. För att förbättra dataläs/skrivprestanda under modellträning och dataförstärkning använde vi FSx för Luster för högpresterande genomströmning.
Deras startträningsdatastorlek var över 1.5 TB. Vi använde två Amazon Elastic Compute Cloud (Amazon EC2) p4d.24 stora instanser med 8 GPU och 40 GB GPU-minne. För SageMaker distribuerad utbildning måste instanserna vara i samma AWS-region och tillgänglighetszon. Träningsdata som lagras i en S3-skopa måste också vara i samma tillgänglighetszon. Denna arkitektur tillåter också BigBasket att byta till andra instanstyper eller lägga till fler instanser till den nuvarande arkitekturen för att tillgodose eventuell betydande datatillväxt eller uppnå ytterligare minskning av träningstiden.
Hur SMDDP-biblioteket hjälpte till att minska utbildningstid, kostnad och komplexitet
I traditionell distribuerad dataträning tilldelar utbildningsramverket rankningar till GPU:er (arbetare) och skapar en kopia av din modell på varje GPU. Under varje träningsiteration delas den globala databatchen upp i bitar (batchskärvor) och en bit distribueras till varje arbetare. Varje arbetare fortsätter sedan med fram- och bakåtpassningen som definieras i ditt träningsskript på varje GPU. Slutligen synkroniseras modellvikter och gradienter från de olika modellreplikerna i slutet av iterationen genom en kollektiv kommunikationsoperation som kallas AllReduce. När varje arbetare och GPU har en synkroniserad kopia av modellen börjar nästa iteration.
SMDDP-biblioteket är ett kollektivt kommunikationsbibliotek som förbättrar prestandan för denna parallellträningsprocess för distribuerad data. SMDDP-biblioteket minskar kommunikationsoverheaden för viktiga kollektiva kommunikationsoperationer som AllReduce. Dess implementering av AllReduce är designad för AWS-infrastruktur och kan påskynda träningen genom att överlappa AllReduce-operationen med bakåtpassningen. Detta tillvägagångssätt uppnår nästan linjär skalningseffektivitet och snabbare träningshastighet genom att optimera kärnoperationer mellan CPU:er och GPU:er.
Observera följande beräkningar:
- Storleken på den globala batchen är (antal noder i ett kluster) * (antal GPU per nod) * (per batch shard)
- En batch shard (liten batch) är en delmängd av datamängden som tilldelats varje GPU (arbetare) per iteration
BigBasket använde SMDDP-biblioteket för att minska sin totala träningstid. Med FSx for Lustre minskade vi läs-/skrivkapaciteten för data under modellträning och dataökning. Med dataparallellism kunde BigBasket uppnå nästan 50 % snabbare och 20 % billigare träning jämfört med andra alternativ, vilket gav den bästa prestandan på AWS. SageMaker stänger automatiskt av träningspipeline efter avslutad. Projektet slutfördes framgångsrikt med 50 % snabbare träningstid i AWS (4.5 dagar i AWS mot 9 dagar på deras äldre plattform).
När detta inlägg skrevs har BigBasket kört den kompletta lösningen i produktion i mer än 6 månader och skalat systemet genom att catering till nya städer, och vi lägger till nya butiker varje månad.
"Vårt partnerskap med AWS om migrering till distribuerad utbildning med deras SMDDP-erbjudande har varit en stor vinst. Det minskade inte bara våra träningstider med 50 %, det var också 20 % billigare. I hela vårt partnerskap har AWS satt ribban för kundbesatthet och att leverera resultat – och arbetat med oss hela vägen för att realisera utlovade fördelar.”
– Keshav Kumar, Head of Engineering på BigBasket.
Slutsats
I det här inlägget diskuterade vi hur BigBasket använde SageMaker för att träna sin datorseendemodell för FMCG-produktidentifiering. Implementeringen av ett AI-drivet automatiserat självutcheckningssystem ger en förbättrad detaljhandelskundupplevelse genom innovation, samtidigt som mänskliga fel i kassaprocessen elimineras. Att accelerera introduktionen av nya produkter genom att använda SageMaker distribuerad utbildning minskar SKU-onboardingstid och kostnad. Att integrera FSx for Luster möjliggör snabb parallell dataåtkomst för effektiv modellomskolning med hundratals nya SKU:er varje månad. Sammantaget ger denna AI-baserade självutcheckningslösning en förbättrad shoppingupplevelse utan gränskontrollfel. Automatiseringen och innovationen har förändrat deras kassa- och onboardingverksamhet.
SageMaker tillhandahåller end-to-end ML-utveckling, distribution och övervakningsfunktioner som en SageMaker Studio-anteckningsbokmiljö för att skriva kod, datainsamling, datataggning, modellträning, modellinställning, driftsättning, övervakning och mycket mer. Om ditt företag står inför någon av de utmaningar som beskrivs i det här inlägget och vill spara tid på marknaden och förbättra kostnaderna, kontakta AWS-kontoteamet i din region och kom igång med SageMaker.
Om författarna
 Santosh Waddi är huvudingenjör på BigBasket, har över ett decennium av expertis för att lösa AI-utmaningar. Med en stark bakgrund inom datorseende, datavetenskap och djupinlärning har han en doktorsexamen från IIT Bombay. Santosh har skrivit anmärkningsvärda IEEE-publikationer och som en erfaren teknikbloggförfattare har han också gjort betydande bidrag till utvecklingen av datorseendelösningar under sin tid på Samsung.
Santosh Waddi är huvudingenjör på BigBasket, har över ett decennium av expertis för att lösa AI-utmaningar. Med en stark bakgrund inom datorseende, datavetenskap och djupinlärning har han en doktorsexamen från IIT Bombay. Santosh har skrivit anmärkningsvärda IEEE-publikationer och som en erfaren teknikbloggförfattare har han också gjort betydande bidrag till utvecklingen av datorseendelösningar under sin tid på Samsung.
 Nanda Kishore Thatikonda är en ingenjörschef som leder datateknik och analys på BigBasket. Nanda har byggt flera applikationer för upptäckt av anomali och har ett patent inlämnat i ett liknande utrymme. Han har arbetat med att bygga applikationer i företagsklass, bygga dataplattformar i flera organisationer och rapporteringsplattformar för att effektivisera beslut som stöds av data. Nanda har över 18 års erfarenhet av att arbeta med Java/J2EE, Spring-teknologier och big data-ramverk med Hadoop och Apache Spark.
Nanda Kishore Thatikonda är en ingenjörschef som leder datateknik och analys på BigBasket. Nanda har byggt flera applikationer för upptäckt av anomali och har ett patent inlämnat i ett liknande utrymme. Han har arbetat med att bygga applikationer i företagsklass, bygga dataplattformar i flera organisationer och rapporteringsplattformar för att effektivisera beslut som stöds av data. Nanda har över 18 års erfarenhet av att arbeta med Java/J2EE, Spring-teknologier och big data-ramverk med Hadoop och Apache Spark.
 Sudhanshu hatar är en primär AI & ML-specialist med AWS och arbetar med kunder för att ge dem råd om deras MLOps och generativa AI-resa. I sin tidigare roll konceptualiserade, skapade och ledde han team för att bygga en grundbaserad, öppen källkodsbaserad AI och gamification-plattform, och framgångsrikt kommersialiserade den med över 100 kunder. Sudhanshu har till sin kredit ett par patent; har skrivit 2 böcker, flera tidningar och bloggar; och har framfört sin synpunkt i olika forum. Han har varit en tankeledare och talare och har varit i branschen i nästan 25 år. Han har arbetat med Fortune 1000-kunder över hela världen och arbetar senast med digitala infödda kunder i Indien.
Sudhanshu hatar är en primär AI & ML-specialist med AWS och arbetar med kunder för att ge dem råd om deras MLOps och generativa AI-resa. I sin tidigare roll konceptualiserade, skapade och ledde han team för att bygga en grundbaserad, öppen källkodsbaserad AI och gamification-plattform, och framgångsrikt kommersialiserade den med över 100 kunder. Sudhanshu har till sin kredit ett par patent; har skrivit 2 böcker, flera tidningar och bloggar; och har framfört sin synpunkt i olika forum. Han har varit en tankeledare och talare och har varit i branschen i nästan 25 år. Han har arbetat med Fortune 1000-kunder över hela världen och arbetar senast med digitala infödda kunder i Indien.
 Ayush Kumar är Solutions Architect på AWS. Han arbetar med en mängd olika AWS-kunder och hjälper dem att ta till sig de senaste moderna applikationerna och förnya sig snabbare med molnbaserade teknologier. Du hittar honom experimentera i köket på fritiden.
Ayush Kumar är Solutions Architect på AWS. Han arbetar med en mängd olika AWS-kunder och hjälper dem att ta till sig de senaste moderna applikationerna och förnya sig snabbare med molnbaserade teknologier. Du hittar honom experimentera i köket på fritiden.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoData.Network Vertical Generative Ai. Styrka dig själv. Tillgång här.
- PlatoAiStream. Web3 Intelligence. Kunskap förstärkt. Tillgång här.
- Platoesg. Kol, CleanTech, Energi, Miljö, Sol, Avfallshantering. Tillgång här.
- PlatoHealth. Biotech och kliniska prövningar Intelligence. Tillgång här.
- Källa: https://aws.amazon.com/blogs/machine-learning/how-bigbasket-improved-ai-enabled-checkout-at-their-physical-stores-using-amazon-sagemaker/

