Detta är ett gästinlägg skrivet av Axfood AB.
I det här inlägget delar vi med oss av hur Axfood, en stor svensk livsmedelshandlare, förbättrade driften och skalbarheten av sin befintliga verksamhet med artificiell intelligens (AI) och maskininlärning (ML) genom att ta prototyper i nära samarbete med AWS-experter och använda Amazon SageMaker.
Axfood är Sveriges näst största dagligvaruhandlare med över 13,000 300 anställda och fler än XNUMX butiker. Axfood har en struktur med flera decentraliserade datavetenskapsteam med olika ansvarsområden. Tillsammans med ett centralt dataplattformsteam tillför datavetenskapsteamen innovation och digital transformation genom AI- och ML-lösningar till organisationen. Axfood har använt Amazon SageMaker för att odla sin data med hjälp av ML och har haft modeller i produktion i många år. På senare tid har nivån på sofistikering och det stora antalet modeller i produktion ökat exponentiellt. Men även om innovationstakten är hög, hade de olika teamen utvecklat sina egna sätt att arbeta och letade efter en ny MLOps bästa praxis.
Vår utmaning
För att förbli konkurrenskraftiga vad gäller molntjänster och AI/ML valde Axfood att samarbeta med AWS och har samarbetat med dem i många år.
Under en av våra återkommande brainstormingsessioner med AWS diskuterade vi hur vi bäst kan samarbeta mellan team för att öka innovationstakten och effektiviteten för datavetenskap och ML-utövare. Vi bestämde oss för att göra en gemensam ansträngning för att bygga en prototyp på en bästa praxis för MLOps. Syftet med prototypen var att bygga en modellmall för alla datavetenskapsteam för att bygga skalbara och effektiva ML-modeller – grunden till en ny generation av AI- och ML-plattformar för Axfood. Mallen ska överbrygga och kombinera bästa praxis från AWS ML-experter och företagsspecifika modeller för bästa praxis – det bästa av två världar.
Vi bestämde oss för att bygga en prototyp från en av de för närvarande mest utvecklade ML-modellerna inom Axfood: prognostisera försäljningen i butikerna. Mer specifikt, prognosen för frukt och grönsaker för kommande kampanjer för livsmedelsbutiker. Noggranna dagliga prognoser stödjer beställningsprocessen för butikerna, vilket ökar hållbarheten genom att minimera matsvinnet som ett resultat av att optimera försäljningen genom att exakt förutsäga de nödvändiga lagernivåerna i butik. Detta var det perfekta stället att börja för vår prototyp – inte bara skulle Axfood få en ny AI/ML-plattform, utan vi skulle också få en chans att benchmarka våra ML-förmågor och lära av ledande AWS-experter.
Vår lösning: En ny ML-mall på Amazon SageMaker Studio
Att bygga en komplett ML-pipeline som är designad för ett verkligt affärscase kan vara utmanande. I det här fallet utvecklar vi en prognosmodell, så det finns två huvudsteg att slutföra:
- Träna modellen att göra förutsägelser med hjälp av historiska data.
- Tillämpa den tränade modellen för att göra förutsägelser om framtida händelser.
I Axfoods fall har en väl fungerande pipeline för detta ändamål redan upprättats med SageMaker anteckningsböcker och orkestrerad av den tredje partens arbetsflödeshanteringsplattform Airflow. Det finns dock många tydliga fördelar med att modernisera vår ML-plattform och flytta till Amazon SageMaker Studio och Amazon SageMaker-rörledningar. Att flytta till SageMaker Studio ger många fördefinierade funktioner som är färdiga:
- Övervakning av modell och datakvalitet samt modellförklaring
- Inbyggda verktyg för integrerad utvecklingsmiljö (IDE) såsom felsökning
- Uppföljning av kostnad/prestanda
- Modellacceptansramverk
- Modellregister
Det viktigaste incitamentet för Axfood är dock möjligheten att skapa anpassade projektmallar med hjälp av Amazon SageMaker-projekt att användas som en plan för alla datavetenskapsteam och ML-utövare. Axfood-teamet hade redan en robust och mogen nivå av ML-modellering, så huvudfokus låg på att bygga den nya arkitekturen.
Lösningsöversikt
Axfoods föreslagna nya ML-ramverk är uppbyggt kring två huvudpipelines: modellbyggnadspipeline och batchinferenspipeline:
- Dessa pipelines är versionerade inom två separata Git-förråd: ett byggförråd och ett utbyggnadsförråd (inferens). Tillsammans bildar de en robust pipeline för att prognostisera frukt och grönsaker.
- Pipelinesna paketeras i en anpassad projektmall med hjälp av SageMaker Projects i integration med ett tredjeparts Git-repository (Bitbucket) och Bitbucket-pipelines för kontinuerlig integration och kontinuerlig distribution (CI/CD)-komponenter.
- SageMaker-projektmallen inkluderar startkod som motsvarar varje steg i bygg- och distributionspipelines (vi diskuterar dessa steg mer i detalj senare i det här inlägget) såväl som pipelinedefinitionen – receptet för hur stegen ska köras.
- Automatisering av att bygga nya projekt baserat på mallen effektiviseras AWS servicekatalog, där en portfölj skapas, som fungerar som en abstraktion för flera produkter.
- Varje produkt översätts till en AWS molnformation mall, som används när en dataforskare skapar ett nytt SageMaker-projekt med vår MLOps-ritning som grund. Detta aktiverar en AWS Lambda funktion som skapar ett Bitbucket-projekt med två förråd – modellbygge och modellinstallation – som innehåller frökoden.
Följande diagram illustrerar lösningsarkitekturen. Arbetsflöde A skildrar det komplicerade flödet mellan de två modellrörledningarna – konstruktion och slutledning. Arbetsflöde B visar flödet för att skapa ett nytt ML-projekt.

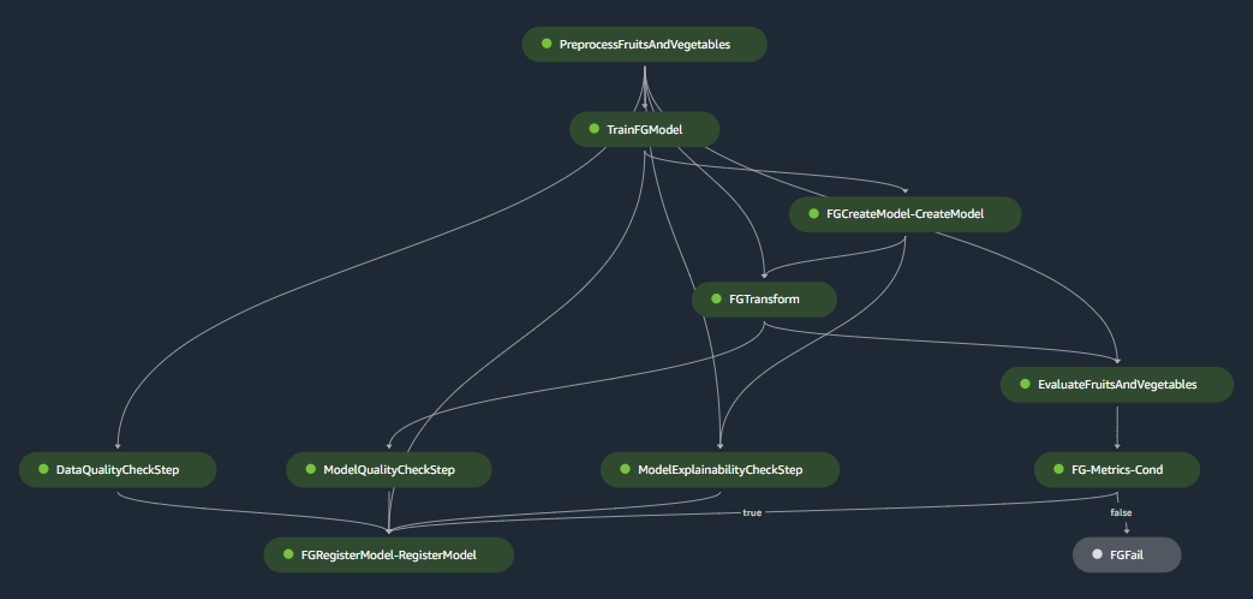
Modellbyggd pipeline
Modellbyggets pipeline orkestrerar modellens livscykel, med början från förbearbetning, förflyttning genom utbildning och som kulminerar med att registreras i modellregistret:
- förbehandling – Här, SageMakern
ScriptProcessorklass används för funktionsteknik, vilket resulterar i datamängden som modellen kommer att tränas på. - Utbildning och batchtransformation – Anpassade utbildnings- och slutledningsbehållare från SageMaker utnyttjas för att träna modellen på historisk data och skapa förutsägelser om utvärderingsdata med hjälp av en SageMaker Estimator och Transformer för respektive uppgifter.
- Utvärdering – Den tränade modellen genomgår utvärdering genom att jämföra de genererade förutsägelserna på utvärderingsdata med grundsanningen med hjälp av
ScriptProcessor. - Baslinjejobb – Pipelinen skapar baslinjer baserat på statistik i indata. Dessa är viktiga för att övervaka data och modellkvalitet, såväl som funktionstillskrivningar.
- Modellregister – Den utbildade modellen är registrerad för framtida bruk. Modellen kommer att godkännas av utsedda dataforskare för att distribuera modellen för användning i produktionen.
För produktionsmiljöer hanteras dataintag och triggermekanismer via en primär Airflow-orkestrering. Samtidigt, under utvecklingen, aktiveras pipelinen varje gång en ny commit introduceras till modellbygget Bitbucket-förvaret. Följande figur visualiserar modellbyggets pipeline.
Batch slutledning pipeline
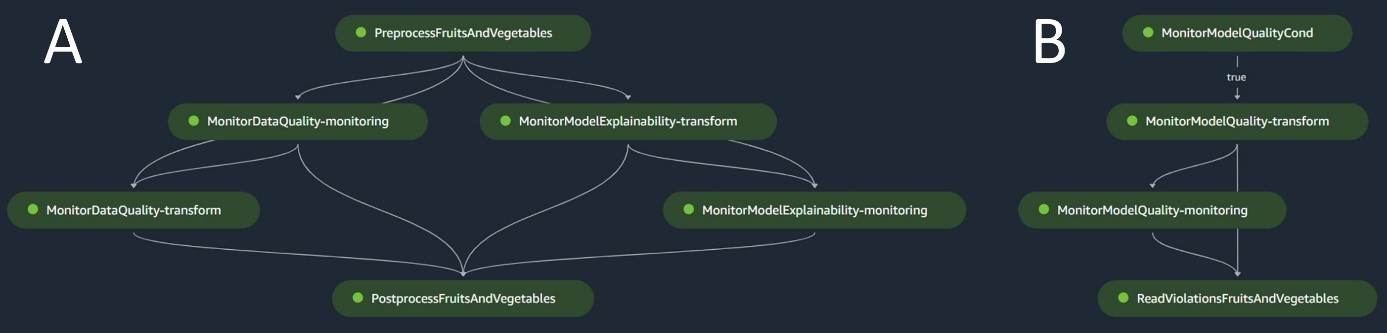
Batchinferenspipelinen hanterar slutledningsfasen, som består av följande steg:
- förbehandling – Data förbehandlas med hjälp av
ScriptProcessor. - Batchtransformation – Modellen använder den anpassade slutledningsbehållaren med en SageMaker-transformator och genererar förutsägelser givet ingående förbearbetade data. Modellen som används är den senast godkända utbildade modellen i modellregistret.
- Efterbehandling – Förutsägelserna genomgår en serie efterbearbetningssteg med hjälp av
ScriptProcessor. - Övervakning – Kontinuerlig övervakning slutför kontroller för drifter relaterade till datakvalitet, modellkvalitet och funktionstillskrivning.
Om avvikelser uppstår, bedömer en affärslogik i efterbehandlingsskriptet om omskolning av modellen är nödvändig. Rörledningen är planerad att köras med jämna mellanrum.
Följande diagram illustrerar batchinferenspipelinen. Arbetsflöde A motsvarar förbearbetning, datakvalitet och funktionstillskrivningsdriftkontroller, slutledningar och efterbearbetning. Arbetsflöde B motsvarar modellkvalitetsdriftkontroller. Dessa pipelines är uppdelade eftersom modellkvalitetsavdriftskontrollen endast kommer att köras om ny marksanningsdata finns tillgänglig.
SageMaker modellmonitor
Med Amazon SageMaker modellmonitor integrerade drar rörledningarna nytta av realtidsövervakning på följande:
- Datakvalitet – Övervakar eventuell drift eller inkonsekvens i data
- Modellkvalitet – Håller koll på eventuella fluktuationer i modellens prestanda
- Funktionstillskrivning – Kontrollerar om det finns avvikelser i egenskapsattribution
Övervakning av modellkvalitet kräver tillgång till markens sanningsdata. Även om det ibland kan vara utmanande att få fram sanning, fungerar användningen av data- eller funktionstillskrivningsdriftsövervakning som en kompetent proxy för modellkvalitet.
Specifikt, i fallet med datakvalitetsdrift, ser systemet upp för följande:
- Konceptdrift – Det här handlar om förändringar i korrelationen mellan input och output, vilket kräver marksanning
- Kovariatskifte – Här ligger tyngdpunkten på förändringar i fördelningen av oberoende indatavariabler
SageMaker Model Monitors funktionalitet för datadrift fångar och granskar noggrant indata, distribuerar regler och statistiska kontroller. Varningar höjs när avvikelser upptäcks.
Parallellt med att använda datakvalitetsdriftkontroller som en proxy för att övervaka modellförsämring, övervakar systemet också funktionstillskrivningsdrift med hjälp av den normaliserade diskonterade kumulativa förstärkningen (NDCG). Den här poängen är känslig för både förändringar i funktionstillskrivningens rankningsordning såväl som för funktionernas råa tillskrivningspoäng. Genom att övervaka avvikelser i tillskrivning för individuella egenskaper och deras relativa betydelse är det enkelt att upptäcka försämring av modellkvalitet.
Modellförklarlighet
Modellförklaring är en central del av ML-distributioner, eftersom det säkerställer transparens i förutsägelser. För en detaljerad förståelse använder vi Amazon SageMaker Clarify.
Den erbjuder både globala och lokala modellförklaringar genom en modellagnostisk egenskapstillskrivningsteknik baserad på Shapleys värdekoncept. Detta används för att avkoda varför en viss förutsägelse gjordes under slutledning. Sådana förklaringar, som i sig är kontrastiva, kan variera baserat på olika baslinjer. SageMaker Clarify hjälper till att bestämma denna baslinje med hjälp av K-medel eller K-prototyper i indatadataset, som sedan läggs till i modellbyggledningen. Denna funktionalitet gör det möjligt för oss att bygga generativa AI-applikationer i framtiden för ökad förståelse för hur modellen fungerar.
Industrialisering: Från prototyp till produktion
MLOps-projektet inkluderar en hög grad av automatisering och kan fungera som en plan för liknande användningsfall:
- Infrastrukturen kan återanvändas helt, medan startkoden kan anpassas för varje uppgift, med de flesta ändringar begränsade till pipelinedefinitionen och affärslogiken för förbearbetning, utbildning, slutledning och efterbearbetning.
- Utbildnings- och slutledningsskripten lagras med hjälp av SageMaker anpassade behållare, så en mängd olika modeller kan hanteras utan ändringar av data och modellövervakning eller modellförklaringssteg, så länge som data är i tabellformat.
Efter att ha avslutat arbetet med prototypen gick vi över till hur vi skulle använda den i produktionen. För att göra det kände vi ett behov av att göra några ytterligare justeringar av MLOps-mallen:
- Den ursprungliga frökoden som användes i prototypen för mallen inkluderade förbearbetnings- och efterbearbetningssteg som körs före och efter ML-kärnstegen (träning och slutledning). Men när du skalar upp för att använda mallen för flera användningsfall i produktionen, kan de inbyggda förbearbetnings- och efterbearbetningsstegen leda till minskad generalitet och reproduktion av kod.
- För att förbättra allmänheten och minimera repetitiv kod valde vi att banta ner pipelines ytterligare. Istället för att köra förbearbetnings- och efterbearbetningsstegen som en del av ML-pipeline, kör vi dessa som en del av den primära Airflow-orkestreringen före och efter triggning av ML-pipeline.
- På detta sätt abstraheras användningsfallsspecifika bearbetningsuppgifter från mallen, och det som återstår är en kärn-ML-pipeline som utför uppgifter som är generella för flera användningsfall med minimal upprepning av kod. Parametrar som skiljer sig åt mellan olika användningsfall levereras som input till ML-pipeline från den primära Airflow-orkestreringen.
Resultatet: Ett snabbt och effektivt sätt att bygga och implementera modeller
Prototypen i samarbete med AWS har resulterat i en MLOps-mall som följer nuvarande bästa praxis som nu är tillgänglig för användning för alla Axfoods datavetenskapsteam. Genom att skapa ett nytt SageMaker-projekt inom SageMaker Studio kan datavetare komma igång med nya ML-projekt snabbt och sömlöst övergå till produktion, vilket möjliggör effektivare tidshantering. Detta görs möjligt genom att automatisera tråkiga, repetitiva MLOps-uppgifter som en del av mallen.
Dessutom har flera nya funktioner lagts till på ett automatiserat sätt till vår ML-setup. Dessa vinster inkluderar:
- Modellövervakning – Vi kan utföra driftkontroller för modell- och datakvalitet samt modellförklaring
- Modell- och datalinje – Det är nu möjligt att spåra exakt vilken data som har använts för vilken modell
- Modellregister – Detta hjälper oss att katalogisera modeller för produktion och hantera modellversioner
Slutsats
I det här inlägget diskuterade vi hur Axfood förbättrade driften och skalbarheten av vår befintliga AI- och ML-verksamhet i samarbete med AWS-experter och genom att använda SageMaker och dess relaterade produkter.
Dessa förbättringar kommer att hjälpa Axfoods datavetenskapsteam att bygga ML-arbetsflöden på ett mer standardiserat sätt och kommer att avsevärt förenkla analys och övervakning av modeller i produktionen – vilket säkerställer kvaliteten på ML-modeller som byggs och underhålls av våra team.
Lämna feedback eller frågor i kommentarsfältet.
Om författarna
 doktor Björn Blomqvist är chef för AI-strategi på Axfood AB. Innan han började på Axfood AB ledde han ett team av Data Scientists på Dagab, en del av Axfood, som byggde innovativa maskininlärningslösningar med uppdraget att tillhandahålla god och hållbar mat till människor över hela Sverige. Björn är född och uppvuxen i norra Sverige och på fritiden beger sig Björn till snöiga berg och öppet hav.
doktor Björn Blomqvist är chef för AI-strategi på Axfood AB. Innan han började på Axfood AB ledde han ett team av Data Scientists på Dagab, en del av Axfood, som byggde innovativa maskininlärningslösningar med uppdraget att tillhandahålla god och hållbar mat till människor över hela Sverige. Björn är född och uppvuxen i norra Sverige och på fritiden beger sig Björn till snöiga berg och öppet hav.
 Oskar Klang är Senior Data Scientist på analysavdelningen på Dagab, där han tycker om att arbeta med allt analytiskt och maskininlärning, t.ex. att optimera supply chain-operationer, bygga prognosmodeller och på senare tid GenAI-applikationer. Han är engagerad i att bygga mer strömlinjeformade pipelines för maskininlärning, förbättra effektiviteten och skalbarheten.
Oskar Klang är Senior Data Scientist på analysavdelningen på Dagab, där han tycker om att arbeta med allt analytiskt och maskininlärning, t.ex. att optimera supply chain-operationer, bygga prognosmodeller och på senare tid GenAI-applikationer. Han är engagerad i att bygga mer strömlinjeformade pipelines för maskininlärning, förbättra effektiviteten och skalbarheten.
 Pavel Maslov är senior DevOps- och ML-ingenjör i Analytic Platforms-teamet. Pavel har lång erfarenhet av utveckling av ramverk, infrastruktur och verktyg inom domänerna DevOps och ML/AI på AWS-plattformen. Pavel har varit en av nyckelaktörerna i att bygga grundförmågan inom ML på Axfood.
Pavel Maslov är senior DevOps- och ML-ingenjör i Analytic Platforms-teamet. Pavel har lång erfarenhet av utveckling av ramverk, infrastruktur och verktyg inom domänerna DevOps och ML/AI på AWS-plattformen. Pavel har varit en av nyckelaktörerna i att bygga grundförmågan inom ML på Axfood.
 Joakim Berg är Team Lead och Product Owner Analytic Platforms, baserat i Stockholm, Sverige. Han leder ett team av Data Platform end DevOps/MLOps-ingenjörer som tillhandahåller Data och ML-plattformar för Data Science-teamen. Joakim har mångårig erfarenhet av att leda seniora utvecklings- och arkitektteam från olika branscher.
Joakim Berg är Team Lead och Product Owner Analytic Platforms, baserat i Stockholm, Sverige. Han leder ett team av Data Platform end DevOps/MLOps-ingenjörer som tillhandahåller Data och ML-plattformar för Data Science-teamen. Joakim har mångårig erfarenhet av att leda seniora utvecklings- och arkitektteam från olika branscher.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoData.Network Vertical Generative Ai. Styrka dig själv. Tillgång här.
- PlatoAiStream. Web3 Intelligence. Kunskap förstärkt. Tillgång här.
- Platoesg. Kol, CleanTech, Energi, Miljö, Sol, Avfallshantering. Tillgång här.
- PlatoHealth. Biotech och kliniska prövningar Intelligence. Tillgång här.
- Källa: https://aws.amazon.com/blogs/machine-learning/how-axfood-enables-accelerated-machine-learning-throughout-the-organization-using-amazon-sagemaker/

